Rust Programlama Dili
Steve Klabnik, Carol Nichols ve Chris Krycho tarafından, Rust Topluluğunun katkılarıyla yazılmıştır.
Metnin bu sürümü, projelerinizi Rust 2024 Sürümü (Edition) kurallarını kullanacak şekilde yapılandırmak için tüm projelerin Cargo.toml dosyasında edition = "2024" ayarı ile Rust 1.90.0 (2025-09-18 sürümü) veya üzerini kullandığınızı varsayar. Rust’ı yükleme veya güncelleme talimatları için Bölüm 1’deki “Kurulum” bölümüne ve sürümler (editions) hakkında bilgi için Ek E’ye bakın.
HTML formatı https://doc.rust-lang.org/stable/book/ adresinde çevrimiçi olarak ve rustup ile yapılan Rust kurulumlarında çevrimdışı (offline) olarak mevcuttur; açmak için rustup doc --book komutunu çalıştırın.
Birçok topluluk çevirisi de mevcuttur.
Bu metin, No Starch Press’ten ciltsiz (paperback) ve e-kitap formatında edinilebilir.
🚨 Daha etkileşimli bir öğrenme deneyimi mi istiyorsunuz? Testler, vurgulama (highlighting), görselleştirmeler ve daha fazlasını içeren farklı bir Rust Kitabı sürümünü deneyin: https://rust-book.cs.brown.edu
Önsöz
Rust programlama dili, meraklılardan oluşan küçük ve yeni gelişen bir topluluk tarafından yaratılıp kuluçkaya yatırılmasından bu yana, dünyanın en sevilen ve en çok talep gören programlama dillerinden biri haline gelerek kısa birkaç yıl içinde uzun bir yol kat etti. Geriye dönüp bakıldığında, Rust’ın gücünün ve vaatlerinin dikkat çekmesi ve sistem programlamada bir yer edinmesi kaçınılmazdı. Kaçınılmaz olmayan şey ise, açık kaynak topluluklarına nüfuz eden ve endüstriler çapında geniş ölçekli benimsenmeyi hızlandıran ilgi ve inovasyondaki küresel büyümeydi.
Şu noktada, ilgi ve benimsenmedeki bu patlamayı açıklamak için Rust’ın sunduğu harika özellikleri işaret etmek kolaydır. Diğer harika özelliklerin yanı sıra kim bellek güvenliği (memory safety) ve yüksek performans ve dost canlısı bir derleyici (compiler) ve harika araçlar (tooling) istemez ki? Bugün gördüğünüz Rust dili, sistem programlamasındaki yıllarca süren araştırmaları canlı ve tutkulu bir topluluğun pratik bilgeliğiyle birleştiriyor. Bu dil amaca yönelik tasarlandı ve özenle işlendi, geliştiricilere güvenli, hızlı ve güvenilir kod yazmayı kolaylaştıran bir araç sundu.
Ancak Rust’ı gerçekten özel kılan şey, hedeflerinize ulaşmanız için siz kullanıcıyı güçlendirme köklerine sahip olmasıdır. Bu, başarılı olmanızı isteyen bir dildir ve güçlendirme ilkesi, bu dili inşa eden, sürdüren ve savunan topluluğun özünde yer alır. Bu temel metnin önceki sürümünden bu yana Rust, gerçekten küresel ve güvenilir bir dil olarak daha da gelişti. Rust Projesi, artık Rust’ın güvenli, istikrarlı ve sürdürülebilir olmasını sağlamak için önemli girişimlere yatırım yapan Rust Vakfı (Rust Foundation) tarafından güçlü bir şekilde desteklenmektedir.
Rust Programlama Dili kitabının bu baskısı, dilin yıllar içindeki evrimini yansıtan ve değerli yeni bilgiler sağlayan kapsamlı bir güncellemedir. Ancak bu sadece sözdizimi (syntax) ve kütüphaneler için bir rehber değil, aynı zamanda kaliteye, performansa ve düşünceli tasarıma değer veren bir topluluğa katılmaya davettir. İster Rust’ı ilk kez keşfetmek isteyen deneyimli bir geliştirici olun, ister becerilerini geliştirmek isteyen deneyimli bir Rustacean (Rust kullanıcısı) olun, bu baskı herkese uygun bir şeyler sunuyor.
Rust yolculuğu işbirliği, öğrenme ve yineleme (iteration) yolculuğu olmuştur. Dilin ve ekosisteminin büyümesi, arkasındaki canlı ve çeşitli topluluğun doğrudan bir yansımasıdır. Çekirdek dil tasarımcılarından sıradan katılımcılara kadar binlerce geliştiricinin katkıları, Rust’ı bu kadar benzersiz ve güçlü bir araç yapan şeydir. Bu kitabı elinize alarak sadece yeni bir programlama dili öğrenmiyorsunuz; yazılımı daha iyi, daha güvenli ve çalışması daha keyifli hale getiren bir harekete katılıyorsunuz.
Rust topluluğuna hoş geldiniz!
- Bec Rumbul, Rust Vakfı (Rust Foundation) İcra Direktörü
Giriş
Not: Kitabın bu sürümü, No Starch Press tarafından basılı ve e-kitap formatında sunulan The Rust Programming Language kitabı ile aynıdır.
Rust hakkında giriş seviyesinde bir kitap olan Rust Programlama Dili (The Rust Programming Language) kitabına hoş geldiniz. Rust programlama dili, daha hızlı ve daha güvenilir yazılımlar geliştirmenize yardımcı olur. Programlama dili tasarımında üst düzey ergonomi ile alt düzey kontrol genellikle birbirine ters düşer; Rust bu çatışmaya meydan okuyor. Güçlü teknik kapasite ile harika bir geliştirici deneyimini dengeleyen Rust, geleneksel olarak bu tür bir kontrolle ilişkilendirilen tüm zorluklar olmadan alt düzey detayları (örneğin bellek kullanımı gibi) kontrol etme seçeneği sunar.
Rust Kimler İçin?
Rust, birçok farklı nedenden ötürü pek çok insan için idealdir. Gelin en önemli gruplardan birkaçına bakalım.
Geliştirici Ekipleri
Rust, farklı düzeylerde sistem programlama bilgisine sahip geliştiricilerden oluşan büyük ekipler arasında işbirliği yapmak için üretken bir araç olduğunu kanıtlıyor. Alt düzey kodlar, diğer çoğu dilde ancak kapsamlı testler ve deneyimli geliştiriciler tarafından yapılan dikkatli kod incelemeleriyle yakalanabilen çeşitli ince hatalara eğilimlidir. Rust’ta ise derleyici, eşzamanlılık (concurrency) hataları da dahil olmak üzere bu yakalaması zor hatalara sahip kodları derlemeyi reddederek bir bekçi (gatekeeper) rolü üstlenir. Ekip, derleyiciyle birlikte çalışarak zamanını hataların peşinden koşmak yerine programın mantığına odaklanarak geçirebilir.
Rust ayrıca sistem programlama dünyasına çağdaş geliştirici araçları da getirir:
- Rust ile birlikte gelen bağımlılık yöneticisi ve derleme aracı olan Cargo, Rust ekosistemi genelinde bağımlılıkları eklemeyi, derlemeyi ve yönetmeyi zahmetsiz ve tutarlı hale getirir.
rustfmtformatlama aracı, geliştiriciler arasında tutarlı bir kodlama stili sağlar.- Rust Language Server, kod tamamlama ve satır içi hata mesajları için entegre geliştirme ortamı (IDE) entegrasyonuna güç verir.
Geliştiriciler, Rust ekosistemindeki bu ve diğer araçları kullanarak sistem düzeyinde kod yazarken dahi üretken olabilirler.
Öğrenciler
Rust, sistem kavramları hakkında bilgi edinmek isteyen öğrenciler ve meraklılar içindir. Birçok kişi işletim sistemi geliştirme gibi konuları Rust kullanarak öğrendi. Topluluk çok misafirperverdir ve öğrencilerin sorularını yanıtlamaktan mutluluk duyar. Bu kitap gibi çabalar aracılığıyla Rust ekipleri, sistem kavramlarını özellikle programlamaya yeni başlayanlar olmak üzere daha fazla insan için daha erişilebilir hale getirmek istiyor.
Şirketler
İrili ufaklı yüzlerce şirket; komut satırı araçları, web servisleri, DevOps araçları, gömülü cihazlar, ses ve video analizi ve dönüştürmesi, kripto paralar, biyoinformatik, arama motorları, Nesnelerin İnterneti (IoT) uygulamaları, makine öğrenimi ve hatta Firefox web tarayıcısının önemli parçaları da dahil olmak üzere çok çeşitli görevler için üretim ortamında (production) Rust kullanıyor.
Açık Kaynak Geliştiricileri
Rust; Rust programlama dilini, topluluğunu, geliştirici araçlarını ve kütüphanelerini inşa etmek isteyenler içindir. Rust diline katkıda bulunmanızdan mutluluk duyarız.
Hıza ve Kararlılığa Önem Verenler
Rust, bir dilde hız ve kararlılık (stability) arzulayanlar içindir. Hız derken, hem Rust kodunun ne kadar hızlı çalışabildiğini hem de Rust’ın size ne kadar hızlı program yazdırdığını kastediyoruz. Rust derleyicisinin kontrolleri, özellik eklemeleri ve yeniden yapılandırma yoluyla kararlılığı sağlar. Bu durum, geliştiricilerin genellikle değiştirmekten korktuğu, bu tür kontrollere sahip olmayan dillerdeki kırılgan eski (legacy) kodlarla tam bir tezat oluşturur. Rust, sıfır maliyetli soyutlamalar için çabalayarak (elle yazılmış kod kadar hızlı bir şekilde alt düzey koda derlenen üst düzey özellikler), güvenli kodun aynı zamanda hızlı kod olmasını sağlamaya çalışır.
Rust dili, diğer birçok kullanıcıyı da desteklemeyi umuyor; burada bahsedilenler sadece en büyük paydaşlardan bazıları. Genel olarak Rust’ın en büyük hedefi, güvenlik ve üretkenlik, hız ve ergonomi sunarak programcıların on yıllardır kabul ettiği ödünleşimleri (trade-offs) ortadan kaldırmaktır. Rust’a bir şans verin ve seçimlerinin sizin için işe yarayıp yaramadığına bakın.
Bu Kitap Kimler İçin?
Bu kitap, başka bir programlama dilinde kod yazdığınızı varsayar, ancak hangisi olduğu konusunda herhangi bir varsayımda bulunmaz. Materyali çok çeşitli programlama altyapılarından gelenler için geniş ölçüde erişilebilir hale getirmeye çalıştık. Programlamanın ne olduğu veya onun hakkında nasıl düşünülmesi gerektiği hakkında konuşarak çok fazla zaman harcamıyoruz. Programlamaya tamamen yeniyseniz, özellikle programlamaya giriş sağlayan bir kitap okumanız sizin için daha faydalı olacaktır.
Bu Kitap Nasıl Kullanılır?
Genel olarak, bu kitap sizin onu baştan sona sırayla okuduğunuzu varsayar. İlerleyen bölümler önceki bölümlerdeki kavramlar üzerine inşa edilir ve önceki bölümler belirli bir konudaki ayrıntılara inmeyebilir, ancak bu konuyu ilerleyen bölümlerde tekrar ele alacaktır.
Bu kitapta iki tür bölüm bulacaksınız: kavram bölümleri ve proje bölümleri. Kavram bölümlerinde Rust’ın bir yönü hakkında bilgi edineceksiniz. Proje bölümlerinde ise şu ana kadar öğrendiklerinizi uygulayarak birlikte küçük programlar geliştireceğiz. Bölüm 2, Bölüm 12 ve Bölüm 21 proje bölümleridir; geri kalanlar ise kavram bölümleridir.
Bölüm 1, Rust’ın nasıl kurulacağını, “Merhaba, dünya!” programının nasıl yazılacağını ve Rust’ın paket yöneticisi ve derleme aracı olan Cargo’nun nasıl kullanılacağını açıklar. Bölüm 2, bir sayı tahmin oyunu geliştirmenizi sağlayarak Rust’ta program yazmaya yönelik uygulamalı bir giriştir. Burada kavramları üst düzeyde ele alıyoruz; sonraki bölümler ek ayrıntılar sağlayacaktır. Eğer hemen ellerinizi kirletmek (pratik yapmak) istiyorsanız, Bölüm 2 tam size göre. Eğer bir sonrakine geçmeden önce her ayrıntıyı öğrenmeyi tercih eden, özellikle titiz bir öğreniciyseniz, Bölüm 2’yi atlayıp diğer programlama dillerindekine benzer Rust özelliklerini kapsayan Bölüm 3’e geçmek isteyebilirsiniz; daha sonra, öğrendiğiniz ayrıntıları uygulayacağınız bir proje üzerinde çalışmak istediğinizde Bölüm 2’ye dönebilirsiniz.
Bölüm 4’te Rust’ın sahiplik sistemini öğreneceksiniz.
Bölüm 5 struct’ları ve metotları tartışıyor.
Bölüm 6 enum’ları, match ifadelerini ve if let ile let...else kontrol akışı (control flow) yapılarını kapsıyor. Özel türler (custom types) oluşturmak için struct’ları ve enum’ları kullanacaksınız.
Bölüm 7’de Rust’ın modül sistemini, kodunuzu ve genel uygulama programlama arayüzünü (API) düzenlemek için gizlilik kurallarını öğreneceksiniz. Bölüm 8, standart kütüphanenin sağladığı bazı yaygın koleksiyon veri yapılarını tartışır: vektörler, string’ler ve hash map’ler. Bölüm 9, Rust’ın hata yönetimi (error-handling) felsefesini ve tekniklerini inceler.
Bölüm 10, birden fazla türe uygulanan kod tanımlama gücü veren generic’leri (jenerikler), trait’leri (özellikler) ve lifetime’ları (yaşam süreleri) derinlemesine inceler.
Bölüm 11 tamamen test etme ile ilgilidir, ki bu Rust’ın güvenlik garantilerinde bile programınızın mantığının doğru olduğundan emin olmak için gereklidir.
Bölüm 12’de, dosyalar içinde metin arayan grep komut satırı aracının işlevlerinin bir alt kümesinin kendi uygulamamızı geliştireceğiz. Bunun için önceki bölümlerde tartıştığımız birçok kavramı kullanacağız.
Bölüm 13, fonksiyonel programlama dillerinden gelen Rust özellikleri olan closure’ları (kapanışlar) ve iterator’leri (yineleyiciler) inceler. Bölüm 14’te Cargo’yu daha derinlemesine inceleyecek ve kütüphanelerinizi başkalarıyla paylaşmak için en iyi uygulamalar hakkında konuşacağız. Bölüm 15, standart kütüphanenin sağladığı akıllı işaretçileri (smart pointers) ve onların işlevselliğini sağlayan trait’leri tartışır.
Bölüm 16’da farklı eşzamanlı (concurrent) programlama modellerini gözden geçirecek ve Rust’ın birden fazla thread’de (iş parçacığı) korkusuzca programlama yapmanıza nasıl yardımcı olduğunu konuşacağız. Bölüm 17’de, Rust’ın async ve await sözdizimini; task’lar (görevler), future’lar ve stream’ler (akışlar) ve bunların sağladığı hafif eşzamanlılık modeliyle birlikte inceleyerek bu konuyu daha da ileri taşıyoruz.
Bölüm 18, Rust’ın deyimlerinin (idioms) aşina olabileceğiniz nesne yönelimli programlama (OOP) ilkeleriyle nasıl karşılaştırıldığına bakar. Bölüm 19, Rust programları boyunca fikirleri ifade etmenin güçlü yolları olan pattern’ler (desenler) ve pattern matching (desen eşleştirme) üzerine bir referanstır. Bölüm 20, unsafe (güvensiz) Rust, makrolar ve lifetime’lar, trait’ler, türler, fonksiyonlar ve closure’lar hakkında daha fazlasını içeren, ilgi çekici ileri düzey konuların bir karışımını içerir.
Bölüm 21’de alt düzey, çoklu iş parçacıklı (multithreaded) bir web sunucusu uygulayacağımız bir projeyi tamamlayacağız!
Son olarak, bazı ekler dil hakkında daha referans benzeri bir formatta faydalı bilgiler içerir. Ek A Rust’ın anahtar kelimelerini, Ek B Rust’ın operatörlerini ve sembollerini, Ek C standart kütüphane tarafından sağlanan türetilebilir (derivable) trait’leri, Ek D bazı yararlı geliştirme araçlarını ve Ek E Rust sürümlerini (editions) kapsar. Ek F’de kitabın çevirilerini bulabilirsiniz ve Ek G’de Rust’ın nasıl yapıldığını ve gecelik (nightly) Rust’ın ne olduğunu ele alacağız.
Bu kitabı okumanın yanlış bir yolu yoktur: Eğer ileri atlamak istiyorsanız, durmayın! Herhangi bir kafa karışıklığı yaşarsanız önceki bölümlere geri dönmeniz gerekebilir. Ancak sizin için ne işe yarıyorsa onu yapın.
Rust öğrenme sürecinin önemli bir parçası, derleyicinin görüntülediği hata mesajlarını nasıl okuyacağınızı öğrenmektir: Bunlar sizi çalışan koda doğru yönlendirecektir. Bu nedenle, derleyicinin her durumda size göstereceği hata mesajıyla birlikte, derlenmeyen birçok örnek sunacağız. Rastgele bir örnek girip çalıştırırsanız, derlenmeyebileceğini bilin! Çalıştırmaya çalıştığınız örneğin hata verip vermeyeceğini görmek için etrafındaki metni okuduğunuzdan emin olun. Çoğu durumda, sizi derlenmeyen herhangi bir kodun doğru sürümüne yönlendireceğiz. Ferris ayrıca, çalışması amaçlanmayan kodu ayırt etmenize yardımcı olacaktır:
| Ferris | Anlamı |
|---|---|
 | Bu kod derlenmez! |
 | Bu kod panik yaratır! |
 | Bu kod istenen davranışı üretmez. |
Çoğu durumda, sizi derlenmeyen herhangi bir kodun doğru sürümüne yönlendireceğiz.
Kaynak Kod
Bu kitabın oluşturulduğu kaynak dosyalar GitHub’ta bulunabilir.
Başlangıç
Rust yolculuğunuza başlayalım! Öğrenecek çok şey var, ancak her yolculuk bir yerden başlar. Bu bölümde şunları ele alacağız:
- Linux, macOS ve Windows üzerinde Rust kurulumu
- Ekrana
Hello, world!yazdıran bir program yazmak - Rust’ın paket yöneticisi ve derleme sistemi olan
cargo’yu kullanmak
Kurulum
Kurulum
İlk adım Rust’ı kurmaktır. Rust’ı, Rust sürümlerini ve ilişkili araçları yönetmek için kullanılan bir komut satırı aracı olan rustup aracılığıyla indireceğiz. İndirme işlemi için internet bağlantısına ihtiyacınız olacak.
Not: Herhangi bir nedenden dolayı
rustupkullanmayı tercih etmezseniz, daha fazla seçenek için lütfen Diğer Rust Kurulum Yöntemleri sayfasına bakın.
Aşağıdaki adımlar, Rust derleyicisinin en son kararlı (stable) sürümünü kurar. Rust’ın kararlılık garantileri, kitaptaki derlenen tüm örneklerin daha yeni Rust sürümleriyle de derlenmeye devam edeceğini garanti eder. Çıktı, sürümler arasında biraz farklılık gösterebilir çünkü Rust hata mesajlarını ve uyarıları sıklıkla iyileştirir. Başka bir deyişle, bu adımları kullanarak kurduğunuz daha yeni, kararlı herhangi bir Rust sürümü, bu kitabın içeriğiyle beklendiği gibi çalışmalıdır.
Komut Satırı Gösterimi
Bu bölümde ve kitabın geri kalanında terminalde kullanılan bazı komutları göstereceğiz. Terminale girmeniz gereken satırların tümü $ ile başlar. $ karakterini yazmanıza gerek yoktur; bu, her komutun başlangıcını göstermek için kullanılan komut satırı istemidir (prompt). $ ile başlamayan satırlar genellikle bir önceki komutun çıktısını gösterir. Ek olarak, PowerShell’e özgü örnekler $ yerine > kullanacaktır.
Linux veya macOS Üzerinde rustup Kurulumu
Eğer Linux veya macOS kullanıyorsanız, bir terminal açın ve aşağıdaki komutu girin:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Bu komut bir betik indirir ve en son kararlı Rust sürümünü kuran rustup aracının kurulumunu başlatır. Şifreniz istenebilir. Eğer kurulum başarılı olursa, şu satır görünecektir:
Rust is installed now. Great!
Ayrıca bir bağlayıcıya (linker) ihtiyacınız olacaktır; bu, Rust’ın derlenmiş çıktılarını tek bir dosyada birleştirmek için kullandığı bir programdır. Büyük ihtimalle sisteminizde zaten bir tane vardır. Eğer bağlayıcı hataları alırsanız, genellikle bir bağlayıcı da içeren bir C derleyicisi kurmalısınız. Bir C derleyicisi aynı zamanda faydalıdır çünkü bazı yaygın Rust paketleri C koduna bağımlıdır ve bir C derleyicisine ihtiyaç duyacaktır.
macOS üzerinde, şu komutu çalıştırarak bir C derleyicisi edinebilirsiniz:
$ xcode-select --install
Linux kullanıcıları genel olarak kendi dağıtımlarının belgelerine göre GCC veya Clang kurmalıdır. Örneğin, Ubuntu kullanıyorsanız build-essential paketini kurabilirsiniz.
Windows Üzerinde rustup Kurulumu
Windows üzerinde https://www.rust-lang.org/tools/install adresine gidin ve Rust’ı kurmak için talimatları izleyin. Kurulumun bir noktasında sizden Visual Studio’yu kurmanız istenecektir. Bu, programları derlemek için gereken bağlayıcıyı (linker) ve yerel kütüphaneleri (native libraries) sağlar. Bu adımda daha fazla yardıma ihtiyacınız olursa https://rust-lang.github.io/rustup/installation/windows-msvc.html adresine bakın.
Bu kitabın geri kalanı hem cmd.exe hem de PowerShell’de çalışan komutlar kullanır. Eğer belirli farklılıklar varsa, hangisini kullanmanız gerektiğini açıklayacağız.
Sorun Giderme
Rust’ı doğru bir şekilde kurup kurmadığınızı kontrol etmek için bir terminal açın ve şu satırı girin:
$ rustc --version
Yayınlanmış olan en son kararlı sürüme ait sürüm numarasını, commit hash’ini ve commit tarihini şu formatta görmelisiniz:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Eğer bu bilgiyi görüyorsanız, Rust’ı başarıyla kurmuşsunuz demektir! Eğer bu bilgiyi görmüyorsanız, Rust’ın sisteminizin %PATH% değişkeninde olup olmadığını aşağıdaki gibi kontrol edin.
Windows CMD’de şunu kullanın:
> echo %PATH%
PowerShell’de şunu kullanın:
> echo $env:Path
Linux ve macOS’te şunu kullanın:
$ echo $PATH
Eğer tüm bunlar doğruysa ve Rust hala çalışmıyorsa, yardım alabileceğiniz birkaç yer var. Diğer Rustacean’larla (kendimize taktığımız komik bir lakap) nasıl iletişime geçeceğinizi topluluk sayfasında bulabilirsiniz.
Güncelleme ve Kaldırma
Rust rustup aracılığıyla kurulduktan sonra, yeni yayınlanan bir sürüme güncellemek kolaydır. Terminalinizden şu güncelleme betiğini çalıştırın:
$ rustup update
Rust’ı ve rustup’ı kaldırmak için, terminalinizden şu kaldırma betiğini çalıştırın:
$ rustup self uninstall
Yerel Belgeleri Okumak
Rust kurulumu, çevrimdışı okuyabilmeniz için belgelerin yerel bir kopyasını da içerir. Yerel belgeleri tarayıcınızda açmak için rustup doc komutunu çalıştırın.
Standart kütüphane tarafından sağlanan bir türün veya fonksiyonun ne yaptığından veya nasıl kullanılacağından emin olmadığınızda, bunu öğrenmek için uygulama programlama arayüzü (API) belgelerini kullanın!
Metin Düzenleyiciler ve IDE’leri Kullanmak
Bu kitap, Rust kodu yazmak için hangi araçları kullandığınız konusunda hiçbir varsayımda bulunmaz. Hemen hemen her metin düzenleyici (text editor) işinizi görecektir! Ancak, birçok metin düzenleyicisinin ve entegre geliştirme ortamının (IDE) yerleşik Rust desteği vardır. Rust web sitesindeki araçlar sayfasında her zaman birçok düzenleyici ve IDE’nin oldukça güncel bir listesini bulabilirsiniz.
Bu Kitapla Çevrimdışı Çalışmak
Birçok örnekte, standart kütüphanenin ötesindeki Rust paketlerini kullanacağız. Bu örnekler üzerinde çalışabilmek için ya internet bağlantınızın olması ya da bu bağımlılıkları (dependencies) önceden indirmiş olmanız gerekir. Bağımlılıkları önceden indirmek için aşağıdaki komutları çalıştırabilirsiniz. (cargo’nun ne olduğunu ve bu komutların her birinin ne işe yaradığını daha sonra ayrıntılı olarak açıklayacağız.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Bu işlem, bu paketlerin indirmelerini önbelleğe alacak (cache) ve böylece bunları daha sonra indirmeniz gerekmeyecektir. Bu komutu çalıştırdıktan sonra, get-dependencies klasörünü tutmanıza gerek yoktur. Bu komutu çalıştırdıysanız, ağ kullanmaya çalışmak yerine önbelleğe alınmış bu sürümleri kullanmak için kitabın geri kalanındaki tüm cargo komutlarıyla birlikte --offline bayrağını (flag) kullanabilirsiniz.
Merhaba, Dünya!
Merhaba, Dünya!
Artık Rust’ı kurduğunuza göre, ilk Rust programınızı yazmanın zamanı geldi. Yeni bir dil öğrenirken ekrana Merhaba, dünya! metnini yazdıran küçük bir program yazmak bir gelenektir, bu yüzden biz de burada aynısını yapacağız!
Not: Bu kitap, komut satırına temel düzeyde aşina olduğunuzu varsayar. Rust, kullandığınız düzenleyici, araçlar veya kodunuzun nerede bulunduğu konusunda herhangi bir özel talepte bulunmaz; bu nedenle komut satırı yerine bir IDE kullanmayı tercih ederseniz, favori IDE’nizi kullanmaktan çekinmeyin. Günümüzde pek çok IDE’nin belirli düzeyde Rust desteği vardır; detaylar için IDE’nin kendi dokümantasyonunu inceleyin. Rust ekibi,
rust-analyzerüzerinden mükemmel bir IDE desteği sunmaya odaklanmıştır. Daha fazla detay için Ek D bölümüne bakabilirsiniz.
Proje Dizinini Ayarlamak
İşe, Rust kodunuzu saklayacağınız bir dizin oluşturarak başlayacaksınız. Kodunuzun nerede bulunduğu Rust için fark etmez, ancak bu kitaptaki egzersizler ve projeler için, ev dizininizde bir projects dizini oluşturmanızı ve tüm projelerinizi orada tutmanızı öneririz.
Bir terminal açın ve bir projects dizini ile bu projects dizini içinde “Merhaba, dünya!” projesi için bir dizin oluşturmak üzere aşağıdaki komutları girin.
Linux, macOS ve Windows’ta PowerShell için şunu girin:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir merhaba_dunya
$ cd merhaba_dunya
Windows CMD için şunu girin:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir merhaba_dunya
> cd merhaba_dunya
Rust Programlamanın Temelleri
Ardından, yeni bir kaynak dosya oluşturun ve adını main.rs koyun. Rust dosyaları her zaman .rs uzantısıyla biter. Dosya adınızda birden fazla kelime kullanıyorsanız, bunları ayırmak için alt çizgi (underscore) kullanmak bir gelenektir. Örneğin, merhabadunya.rs yerine merhaba_dunya.rs kullanın.
Şimdi yeni oluşturduğunuz main.rs dosyasını açın ve Liste 1-1’deki kodu girin.
fn main() {
println!("Merhaba, dünya!");
}Merhaba, dünya! yazdıran bir programDosyayı kaydedin ve ~/projects/merhaba_dunya dizinindeki terminal pencerenize geri dönün. Linux veya macOS üzerinde, dosyayı derlemek ve çalıştırmak için aşağıdaki komutları girin:
$ rustc main.rs
$ ./main
Merhaba, dünya!
Windows’ta, ./main yerine .\main komutunu girin:
> rustc main.rs
> .\main
Merhaba, dünya!
İşletim sisteminiz ne olursa olsun, terminale Merhaba, dünya! metni (string) yazdırılmalıdır. Eğer bu çıktıyı göremiyorsanız, yardım alma yolları için Kurulum bölümündeki “Sorun Giderme” kısmına tekrar başvurun.
Eğer Merhaba, dünya! yazdırıldıysa, tebrikler! Resmen bir Rust programı yazdınız. Bu sizi bir Rust programcısı yapar; aramıza hoş geldiniz!
Bir Rust Programının Anatomisi
Hadi bu “Merhaba, dünya!” programını detaylıca inceleyelim. İşte yapbozun ilk parçası:
fn main() {
}Bu satırlar main adında bir fonksiyon tanımlar. main fonksiyonu özeldir: Çalıştırılabilir (executable) her Rust programında her zaman çalışan ilk koddur. Burada, ilk satır hiçbir parametresi olmayan ve hiçbir şey döndürmeyen main adında bir fonksiyonu bildirir (declare). Eğer parametreleri olsaydı, bunlar parantezlerin (()) içine yazılırdı.
Fonksiyonun gövdesi {} içine sarılmıştır. Rust, tüm fonksiyon gövdelerinin etrafında süslü parantezler (curly brackets) gerektirir. Açılış süslü parantezini fonksiyon bildirimiyle aynı satıra yerleştirmek ve aralarına bir boşluk eklemek iyi bir stil olarak kabul edilir.
Not: Rust projeleri genelinde standart bir stile bağlı kalmak isterseniz, kodunuzu belirli bir stilde biçimlendirmek için
rustfmtadı verilen otomatik bir biçimlendirme aracı kullanabilirsiniz (rustfmthakkında daha fazla bilgi için Ek D’ye bakın). Rust ekibi bu aracı tıpkırustcgibi standart Rust dağıtımına dahil etmiştir, bu yüzden bilgisayarınızda halihazırda kurulu olmalıdır!
main fonksiyonunun gövdesi şu kodu barındırır:
#![allow(unused)]
fn main() {
println!("Merhaba, dünya!");
}Bu satır bu küçük programdaki tüm işi yapar: Ekrana metin yazdırır. Burada fark edilmesi gereken üç önemli detay vardır.
Birincisi, println! bir Rust makrosunu çağırır. Eğer bunun yerine bir fonksiyon çağırsaydı, println olarak (sonunda ! olmadan) girilirdi. Rust makroları, Rust sözdizimini (syntax) genişletmek için kod üreten kod yazmanın bir yoludur ve bunları Bölüm 20’de daha detaylı tartışacağız. Şimdilik, sadece bir ! kullanmanın normal bir fonksiyon yerine bir makro çağırdığınız anlamına geldiğini ve makroların her zaman fonksiyonlarla aynı kurallara uymadığını bilmeniz yeterlidir.
İkincisi, "Merhaba, dünya!" metnini (string) görüyorsunuz. Bu metni println!’e bir argüman olarak aktarıyoruz ve metin ekrana yazdırılıyor.
Üçüncüsü, satırı bu ifadenin bittiğini ve bir sonrakinin başlamaya hazır olduğunu belirten bir noktalı virgülle (;) sonlandırıyoruz. Rust kod satırlarının çoğu noktalı virgülle biter.
Derleme ve Çalıştırma
Az önce yeni oluşturduğunuz bir programı çalıştırdınız, şimdi bu süreçteki her bir adımı inceleyelim.
Bir Rust programını çalıştırmadan önce, onu Rust derleyicisini (compiler) kullanarak, rustc komutunu girip kaynak dosyanızın adını vererek şu şekilde derlemelisiniz:
$ rustc main.rs
Eğer C veya C++ altyapınız varsa, bunun gcc veya clang’e benzediğini fark edeceksiniz. Başarılı bir şekilde derlendikten sonra, Rust çalıştırılabilir bir ikili dosya (binary executable) çıktısı verir.
Linux, macOS ve Windows’ta PowerShell’de, shell’inizde ls komutunu girerek çalıştırılabilir dosyayı görebilirsiniz:
$ ls
main main.rs
Linux ve macOS’te iki dosya göreceksiniz. Windows’ta PowerShell ile, CMD kullanarak göreceğiniz aynı üç dosyayı göreceksiniz. Windows’ta CMD ile şunu girerdiniz:
> dir /B %= /B seçeneği sadece dosya adlarını göster demektir =%
main.exe
main.pdb
main.rs
Bu çıktı; .rs uzantılı kaynak kod dosyasını, çalıştırılabilir dosyayı (Windows’ta main.exe, ancak diğer tüm platformlarda main) ve Windows kullanırken .pdb uzantılı hata ayıklama bilgilerini içeren bir dosyayı gösterir. Buradan main veya main.exe dosyasını şu şekilde çalıştırırsınız:
$ ./main # veya Windows'ta .\main
Eğer main.rs dosyanız “Merhaba, dünya!” programınızsa, bu satır terminalinize Merhaba, dünya! yazdırır.
Ruby, Python veya JavaScript gibi dinamik bir dile daha aşinaysanız, bir programı derleme ve çalıştırmayı ayrı adımlar olarak gerçekleştirmeye alışkın olmayabilirsiniz. Rust, önceden derlenen (ahead-of-time compiled) bir dildir; yani bir programı derleyip çalıştırılabilir dosyasını başka birine verebilirsiniz ve o kişi, bilgisayarında Rust kurulu olmasa bile programı çalıştırabilir. Birine bir .rb, .py veya .js dosyası verirseniz, (sırasıyla) bir Ruby, Python veya JavaScript implementasyonunun sistemlerinde kurulu olması gerekir. Ancak o dillerde, programınızı derlemek ve çalıştırmak için sadece bir komuta ihtiyacınız vardır. Dil tasarımında her şey bir ödünleşimdir.
Sadece rustc ile derlemek basit programlar için iyidir, ancak projeniz büyüdükçe tüm seçenekleri yönetmek ve kodunuzu paylaşmayı kolaylaştırmak isteyeceksiniz. Bir sonraki bölümde, gerçek dünyadaki Rust programlarını yazmanıza yardımcı olacak Cargo aracını size tanıtacağız.
Merhaba, Cargo!
Merhaba, Cargo!
Cargo, Rust’ın derleme (build) sistemi ve paket yöneticisidir. Çoğu Rustacean (Rust programcısı) projelerini yönetmek için bu aracı kullanır; çünkü Cargo, kodunuzu derlemek, kodunuzun bağımlı olduğu kütüphaneleri indirmek ve o kütüphaneleri derlemek gibi sizin için pek çok işi halleder. (Kodunuzun ihtiyaç duyduğu bu kütüphanelere bağımlılıklar (dependencies) diyoruz.)
Şu ana kadar yazdığımız gibi en basit Rust programlarının herhangi bir bağımlılığı yoktur. “Merhaba, dünya!” projesini Cargo ile oluştursaydık, Cargo’nun yalnızca kodunuzu derlemeyle ilgilenen kısmını kullanırdı. Daha karmaşık Rust programları yazdıkça bağımlılıklar ekleyeceksiniz ve eğer bir projeye Cargo kullanarak başlarsanız, bağımlılık eklemek çok daha kolay olacaktır.
Rust projelerinin büyük çoğunluğu Cargo kullandığı için, bu kitabın geri kalanı da sizin Cargo kullandığınızı varsayar. “Kurulum” bölümünde bahsedilen resmi yükleyicileri kullandıysanız Cargo, Rust ile birlikte kurulu gelir. Eğer Rust’ı başka bir yolla kurduysanız, terminalinize şunu yazarak Cargo’nun kurulu olup olmadığını kontrol edin:
$ cargo --version
Bir sürüm numarası görüyorsanız, Cargo kuruludur! Eğer command not found (komut bulunamadı) gibi bir hata görürseniz, Cargo’yu nasıl ayrı olarak kuracağınızı belirlemek için kullandığınız kurulum yönteminin belgelerine bakın.
Cargo ile Proje Oluşturmak
Cargo’yu kullanarak yeni bir proje oluşturalım ve orijinal “Merhaba, dünya!” projemizden nasıl farklı olduğuna bakalım. projects dizininize (veya kodunuzu nerede saklamaya karar verdiyseniz oraya) geri dönün. Ardından, herhangi bir işletim sisteminde aşağıdakini çalıştırın:
$ cargo new merhaba_cargo
$ cd merhaba_cargo
İlk komut merhaba_cargo adında yeni bir dizin ve proje oluşturur. Projemize merhaba_cargo adını verdik ve Cargo, dosyalarını aynı isimde bir dizin içinde oluşturur.
merhaba_cargo dizinine gidin ve dosyaları listeleyin. Cargo’nun bizim için iki dosya ve bir dizin oluşturduğunu göreceksiniz: bir Cargo.toml dosyası ve içinde main.rs dosyası bulunan bir src dizini.
Ayrıca bir .gitignore dosyası ile birlikte yeni bir Git deposu (repository) da başlatmıştır (initialize). Eğer mevcut bir Git deposunun içinde cargo new komutunu çalıştırırsanız Git dosyaları oluşturulmaz; cargo new --vcs=git kullanarak bu davranışı geçersiz kılabilirsiniz.
Not: Git yaygın bir sürüm kontrol sistemidir (version control system).
--vcsbayrağını (flag) kullanarakcargo newkomutunun farklı bir sürüm kontrol sistemi kullanmasını sağlayabilir veya hiçbir sürüm kontrol sistemi kullanmamasını belirtebilirsiniz. Mevcut seçenekleri görmek içincargo new --helpkomutunu çalıştırın.
Cargo.toml dosyasını tercih ettiğiniz metin düzenleyicide açın. Liste 1-2’deki koda benzer görünmelidir.
[package]
name = "merhaba_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
cargo new tarafından oluşturulan Cargo.toml dosyasının içeriğiBu dosya, Cargo’nun yapılandırma formatı olan TOML (Tom’s Obvious, Minimal Language) formatındadır.
İlk satır olan [package], aşağıdaki ifadelerin bir paketi yapılandırdığını belirten bir bölüm başlığıdır. Bu dosyaya daha fazla bilgi ekledikçe, başka bölümler de ekleyeceğiz.
Sonraki üç satır, Cargo’nun programınızı derlemek için ihtiyaç duyduğu yapılandırma bilgilerini ayarlar: isim, sürüm (version) ve kullanılacak Rust sürümü (edition). edition anahtarından Ek E’de bahsedeceğiz.
Son satır olan [dependencies], projenizin bağımlılıklarından herhangi birini listelemeniz için bir bölümün başlangıcıdır. Rust’ta kod paketlerine crate (kasa) adı verilir. Bu proje için başka bir crate’e ihtiyacımız olmayacak, ancak Bölüm 2’deki ilk projede olacak, bu yüzden o zaman bu bağımlılıklar (dependencies) bölümünü kullanacağız.
Şimdi src/main.rs dosyasını açın ve bir göz atın:
Dosya adı: src/main.rs
fn main() {
println!("Merhaba, dünya!");
}Cargo, tıpkı Liste 1-1’de yazdığımız gibi, sizin için bir “Merhaba, dünya!” programı oluşturdu! Şu ana kadar projemiz ile Cargo’nun oluşturduğu proje arasındaki farklar; Cargo’nun kodu src dizinine koyması ve en üst (top-level) dizinde bir Cargo.toml yapılandırma dosyamızın olmasıdır.
Cargo, kaynak dosyalarınızın src dizini içinde bulunmasını bekler. En üst düzey proje dizini yalnızca README dosyaları, lisans bilgileri, yapılandırma dosyaları ve kodunuzla ilgisi olmayan diğer şeyler içindir. Cargo kullanmak projelerinizi düzenlemenize yardımcı olur. Her şeyin bir yeri vardır ve her şey yerli yerindedir.
“Merhaba, dünya!” projesinde yaptığımız gibi Cargo kullanmayan bir projeye başladıysanız, onu Cargo kullanan bir projeye dönüştürebilirsiniz. Proje kodunu src dizinine taşıyın ve uygun bir Cargo.toml dosyası oluşturun. Bu Cargo.toml dosyasını elde etmenin kolay bir yolu, onu sizin için otomatik olarak oluşturacak olan cargo init komutunu çalıştırmaktır.
Bir Cargo Projesini Derlemek ve Çalıştırmak
Şimdi “Merhaba, dünya!” programını Cargo ile derleyip çalıştırdığımızda nelerin farklı olduğuna bakalım! merhaba_cargo dizininizden şu komutu girerek projenizi derleyin:
$ cargo build
Compiling merhaba_cargo v0.1.0 (file:///projects/merhaba_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Bu komut, çalıştırılabilir dosyayı geçerli dizininizde oluşturmak yerine target/debug/merhaba_cargo (veya Windows’ta target\debug\merhaba_cargo.exe) konumunda oluşturur. Varsayılan (default) derleme bir hata ayıklama derlemesi olduğundan, Cargo ikili dosyayı debug adlı bir dizine koyar. Çalıştırılabilir dosyayı şu komutla çalıştırabilirsiniz:
$ ./target/debug/merhaba_cargo # veya Windows'ta .\target\debug\merhaba_cargo.exe
Merhaba, dünya!
Eğer her şey yolunda giderse, terminale Merhaba, dünya! yazdırılmalıdır. cargo build komutunu ilk kez çalıştırmak, Cargo’nun en üst düzeyde (top-level) yeni bir dosya oluşturmasına da neden olur: Cargo.lock. Bu dosya projenizdeki bağımlılıkların kesin (exact) sürümlerini takip eder. Bu projenin bağımlılığı yoktur, bu nedenle dosya biraz boştur. Bu dosyayı hiçbir zaman manuel olarak değiştirmenize gerek kalmayacaktır; Cargo içeriğini sizin yerinize yönetir.
Az önce cargo build ile bir proje derledik ve ./target/debug/merhaba_cargo ile çalıştırdık, ancak kodu derlemek ve ardından ortaya çıkan çalıştırılabilir dosyayı tek bir komutla çalıştırmak için cargo run komutunu da kullanabiliriz:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/merhaba_cargo`
Merhaba, dünya!
cargo run kullanmak, cargo build komutunu çalıştırmayı ve ardından ikili dosyanın tüm yolunu kullanmayı hatırlamak zorunda kalmaktan daha uygundur, bu yüzden çoğu geliştirici cargo run kullanır.
Dikkat ederseniz bu kez Cargo’nun merhaba_cargo projesini derlediğini (compiling) belirten bir çıktı görmedik. Cargo dosyaların değişmediğini anladı, bu yüzden yeniden derlemek yerine sadece ikili dosyayı çalıştırdı. Eğer kaynak kodunuzu değiştirmiş olsaydınız, Cargo çalıştırmadan önce projeyi yeniden derlerdi ve şu çıktıyı görürdünüz:
$ cargo run
Compiling merhaba_cargo v0.1.0 (file:///projects/merhaba_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/merhaba_cargo`
Merhaba, dünya!
Cargo ayrıca cargo check adında bir komut da sağlar. Bu komut, kodunuzun derlendiğinden emin olmak için kodunuzu hızlıca kontrol eder ancak çalıştırılabilir bir dosya (executable) üretmez:
$ cargo check
Checking merhaba_cargo v0.1.0 (file:///projects/merhaba_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Neden çalıştırılabilir bir dosya istemeyesiniz? Çoğu zaman cargo check, çalıştırılabilir bir dosya üretme adımını atladığı için cargo build’den çok daha hızlıdır. Kodu yazarken çalışmanızı sürekli olarak kontrol ediyorsanız, cargo check kullanmak projenizin hala derlenip derlenmediğini bilme sürecinizi hızlandıracaktır! Bu nedenle pek çok Rustacean programlarını yazarken derlendiğinden emin olmak için periyodik olarak cargo check çalıştırır. Daha sonra, çalıştırılabilir dosyayı kullanmaya hazır olduklarında cargo build komutunu çalıştırırlar.
Cargo hakkında şu ana kadar öğrendiklerimizi özetleyelim:
cargo newkullanarak bir proje oluşturabiliriz.cargo buildkullanarak bir projeyi derleyebiliriz.cargo runkullanarak bir projeyi tek adımda derleyip çalıştırabiliriz.- Hataları kontrol etmek için bir ikili dosya üretmeden
cargo checkkullanarak bir projeyi derleyebiliriz. - Cargo derleme sonucunu kodumuzla aynı dizine kaydetmek yerine, onu target/debug dizininde saklar.
Cargo kullanmanın bir diğer avantajı da, hangi işletim sisteminde çalışırsanız çalışın komutların aynı olmasıdır. Dolayısıyla, bu noktada artık Linux ve macOS ile Windows için özel (farklı) talimatlar sunmayacağız.
Yayın (Release) İçin Derlemek
Projeniz sonunda yayınlanmaya (release) hazır olduğunda, optimizasyonlarla derlemek için cargo build --release komutunu kullanabilirsiniz. Bu komut, çalıştırılabilir dosyayı target/debug yerine target/release dizininde oluşturacaktır. Optimizasyonlar Rust kodunuzun daha hızlı çalışmasını sağlar, ancak bunları açmak programınızın derlenmesi için geçen süreyi uzatır. İşte bu yüzden iki farklı profil vardır: biri geliştirme için, yani hızlı ve sık bir şekilde yeniden derlemek istediğiniz zaman; diğeri ise bir kullanıcıya vereceğiniz, tekrar tekrar derlenmeyecek ve mümkün olduğunca hızlı çalışacak son programı derlemek içindir. Eğer kodunuzun çalışma süresini test ediyorsanız (benchmarking), cargo build --release komutunu çalıştırdığınızdan ve target/release dizinindeki çalıştırılabilir dosya ile test ettiğinizden emin olun.
Cargo Geleneklerinden Yararlanmak
Basit projelerde Cargo sadece rustc kullanmaya kıyasla çok fazla bir değer (fayda) sağlamaz, ancak programlarınız daha karmaşık hale geldikçe değerini kanıtlayacaktır. Programlar birden fazla dosyaya yayıldığında veya bir bağımlılığa (dependency) ihtiyaç duyduğunda, derlemeyi Cargo’nun koordine etmesine izin vermek çok daha kolaydır.
merhaba_cargo projesi basit olsa da, artık Rust kariyerinizin geri kalanında kullanacağınız gerçek araçların çoğunu kullanıyor. Aslında, mevcut herhangi bir proje üzerinde çalışmak için Git kullanarak kodu almak, o projenin dizinine gitmek ve derlemek için aşağıdaki komutları kullanabilirsiniz:
$ git clone example.org/bazi_projeler
$ cd bazi_projeler
$ cargo build
Cargo hakkında daha fazla bilgi için kendi dokümantasyonuna göz atın.
Özet
Rust yolculuğunuza şimdiden harika bir başlangıç yaptınız! Bu bölümde şunları nasıl yapacağınızı öğrendiniz:
rustupkullanarak en son kararlı Rust sürümünü kurmak.- Daha yeni bir Rust sürümüne güncellemek.
- Yerel olarak yüklenmiş dokümantasyonu açmak.
- Doğrudan
rustckullanarak bir “Merhaba, dünya!” programı yazmak ve çalıştırmak. - Cargo’nun geleneklerini kullanarak yeni bir proje oluşturmak ve çalıştırmak.
Rust kodu okumaya ve yazmaya alışmak adına daha kapsamlı bir program geliştirmek için şimdi harika bir zaman. Bu yüzden, 2. Bölüm’de bir tahmin oyunu programı geliştireceğiz. Eğer öncelikle genel programlama kavramlarının Rust’ta nasıl çalıştığını öğrenerek başlamayı tercih ederseniz, Bölüm 3’e bakabilir ve ardından Bölüm 2’ye geri dönebilirsiniz.
Tahmin Oyunu Programlama
Birlikte uygulamalı bir proje üzerinde çalışarak Rust’a giriş yapalım! Bu bölüm,
bazı yaygın Rust kavramlarını gerçek bir programda nasıl kullanacağınızı göstererek
size tanıtır. let, match, metotlar, ilişkili fonksiyonlar (associated functions),
harici crate’ler ve daha fazlası hakkında bilgi edineceksiniz! İlerleyen bölümlerde bu
fikirleri daha ayrıntılı olarak inceleyeceğiz. Bu bölümde sadece temel bilgilerin pratiğini
yapacaksınız.
Klasik bir başlangıç programlama problemini uygulayacağız: bir tahmin oyunu. Şöyle çalışıyor: Program 1 ile 100 arasında rastgele bir tam sayı üretecek. Daha sonra oyuncudan bir tahmin girmesini isteyecek. Bir tahmin girildikten sonra, program tahminin çok düşük veya çok yüksek olduğunu belirtecek. Tahmin doğruysa, oyun bir tebrik mesajı yazdıracak ve kapanacak.
Yeni Bir Proje Kurulumu
Yeni bir proje kurmak için, Bölüm 1’de oluşturduğunuz projects dizinine gidin ve Cargo’yu kullanarak yeni bir proje oluşturun, örneğin:
$ cargo new tahmin_oyunu
$ cd tahmin_oyunu
İlk komut olan cargo new, projenin adını (tahmin_oyunu) ilk argüman olarak alır.
İkinci komut ise dizini yeni projenin dizinine değiştirir.
Oluşturulan Cargo.toml dosyasına bakın:
Dosya adı: Cargo.toml
[package]
name = "tahmin_oyunu"
version = "0.1.0"
edition = "2024"
[dependencies]
Bölüm 1’de gördüğünüz gibi, cargo new sizin için bir “Merhaba, dünya!” programı üretir.
src/main.rs dosyasına göz atın:
Dosya adı: src/main.rs
fn main() {
println!("Merhaba, dünya!");
}Şimdi bu “Merhaba, dünya!” programını derleyelim ve aynı adımda cargo run komutunu
kullanarak çalıştıralım:
$ cargo run
Compiling tahmin_oyunu v0.1.0 ($PROJE/listings/ch02-guessing-game-tutorial/no-listing-01-cargo-new)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.10s
Running `target/debug/tahmin_oyunu`
Merhaba, dünya!
run komutu, bu oyunda da yapacağımız gibi, bir projede hızlıca ardışık geliştirmeler
yapmanız ve bir sonrakine geçmeden önce her iterasyonu hızlıca test etmeniz gerektiğinde çok işe yarar.
src/main.rs dosyasını tekrar açın. Tüm kodu bu dosyaya yazacaksınız.
Bir Tahmini İşlemek
Tahmin oyunu programının ilk bölümü kullanıcıdan girdi isteyecek, bu girdiyi işleyecek ve girdinin beklenen biçimde olup olmadığını kontrol edecektir. Başlamak için, oyuncunun bir tahmin girmesine izin vereceğiz. Liste 2-1’deki kodu src/main.rs dosyasına girin.
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Bu kod pek çok bilgi içeriyor, bu yüzden satır satır üzerinden geçelim.
Kullanıcı girdisini almak ve ardından sonucu çıktı olarak yazdırmak için
io (girdi/çıktı) kütüphanesini kapsama dahil etmemiz gerekir.
io kütüphanesi, std olarak bilinen standart kütüphaneden gelir:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Varsayılan olarak Rust, standart kütüphanede tanımlanmış ve her programın kapsamına dahil ettiği bir dizi öğeye sahiptir. Bu diziye prelude (başlangıç) denir ve içindeki her şeyi standart kütüphane dokümantasyonunda görebilirsiniz.
Eğer kullanmak istediğiniz bir tür prelude içinde değilse, o türü bir use
ifadesi ile açıkça kapsama dahil etmeniz gerekir. std::io kütüphanesini
kullanmak, kullanıcı girdisini kabul etme yeteneği de dahil olmak üzere size
bir dizi yararlı özellik sağlar.
Bölüm 1’de gördüğünüz gibi, main fonksiyonu programa giriş noktasıdır:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}fn sözdizimi (syntax) yeni bir fonksiyon tanımlar; () parantezleri
parametre olmadığını gösterir; ve { süslü parantezi fonksiyonun gövdesini başlatır.
Yine Bölüm 1’de öğrendiğiniz gibi, println! ekrana bir metin (string) yazdıran
bir makrodur:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Bu kod, oyunun ne olduğunu belirten bir metin yazdırıyor ve kullanıcıdan girdi talep ediyor.
Değerleri Değişkenlerle Saklamak
Sırada, kullanıcı girdisini saklamak için aşağıdaki gibi bir değişken (variable) oluşturacağız:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Şimdi program ilginçleşmeye başlıyor! Bu küçük satırda pek çok şey oluyor. Değişkeni
oluşturmak için let ifadesini kullanıyoruz. İşte başka bir örnek:
let elmalar = 5;Bu satır elmalar adında yeni bir değişken oluşturur ve onu 5 değerine bağlar (bind).
Rust’ta değişkenler varsayılan olarak değiştirilemezdir, yani değişkene
bir değer verdiğimizde bu değer değişmez. Bu kavramı Bölüm 3’teki
“Değişkenler ve Değiştirilebilirlik” kısmında
ayrıntılı olarak tartışacağız. Bir değişkeni değiştirilebilir yapmak için
değişken adından önce mut ekleriz:
let elmalar = 5; // değiştirilemez
let mut muzlar = 5; // değiştirilebilirNot:
//sözdizimi, satırın sonuna kadar devam eden bir yorum (comment) başlatır. Rust, yorumlardaki her şeyi görmezden gelir. Yorumları Bölüm 3’te daha ayrıntılı olarak tartışacağız.
Tahmin oyunu programına dönecek olursak, artık let mut tahmin’in tahmin adında
değiştirilebilir bir değişken tanıtacağını biliyorsunuz. Eşittir işareti (=),
Rust’a değişkeni şu an bir şeye bağlamak istediğimizi söyler. Eşittir işaretinin
sağında, tahmin değişkeninin bağlandığı değer bulunur; bu değer, yeni bir String
örneği döndüren bir fonksiyon olan String::new’i çağırmanın sonucudur.
String, standart kütüphane tarafından sağlanan; genişleyebilir,
UTF-8 kodlu bir metin türüdür.
::new satırındaki :: sözdizimi, new’in String türünün ilişkili (associated) bir
fonksiyonu olduğunu gösterir. Bir ilişkili fonksiyon, bir tür (burada String)
üzerinde uygulanan (implemented) fonksiyondur. Bu new fonksiyonu yeni ve boş bir
metin (string) oluşturur. Birçok türde bir new fonksiyonu bulacaksınız, çünkü bu,
yeni bir değer üreten bir fonksiyon için yaygın olarak kullanılan bir isimdir.
Özetle, let mut tahmin = String::new(); satırı, şu anda yeni ve boş bir String
örneğine bağlı olan, değiştirilebilir bir değişken oluşturmuştur. Vay canına!
Kullanıcı Girdisini Almak
Programın ilk satırında standart kütüphaneden girdi/çıktı işlevselliğini use std::io; ile
dahil ettiğimizi hatırlayın. Şimdi io modülünden stdin fonksiyonunu çağıracağız,
bu da kullanıcı girdisini ele almamızı sağlayacak:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Eğer io modülünü programın başında use std::io; ile içe aktarmasaydık (import),
yine de bu fonksiyon çağrısını std::io::stdin olarak yazarak kullanabilirdik.
stdin fonksiyonu, terminaliniz için standart girdiye erişimi temsil eden
bir tür olan std::io::Stdin örneğini döndürür.
Ardından gelen .read_line(&mut tahmin) satırı, kullanıcıdan girdi almak için
standart girdi arayüzünde read_line metotunu çağırır.
Ayrıca, kullanıcı girdisinin hangi metne (string) kaydedileceğini söylemek için &mut tahmin
ifadesini read_line’a argüman olarak veriyoruz. read_line’ın tüm işi, kullanıcının
standart girdiye yazdıklarını almak ve bunu bir metne eklemektir (içeriğinin üzerine yazmadan).
Bu nedenle o metni bir argüman olarak aktarıyoruz. Metin argümanı değiştirilebilir olmalıdır,
böylece metot metnin içeriğini değiştirebilir.
& işareti, bu argümanın bir referans olduğunu gösterir. Bu, veriyi belleğe birden fazla
kez kopyalamanıza gerek kalmadan kodunuzun birden fazla parçasının aynı veriye
erişmesine izin veren bir yoldur. Referanslar karmaşık bir özelliktir ve Rust’ın en büyük
avantajlarından biri referansları kullanmanın ne kadar güvenli ve kolay olmasıdır. Bu programı
bitirmek için bu detayların çoğunu bilmenize gerek yoktur. Şimdilik bilmeniz gereken tek şey,
tıpkı değişkenler gibi, referansların da varsayılan olarak değiştirilemez olduğudur.
Bu nedenle onu değiştirilebilir yapmak için &tahmin yerine &mut tahmin
yazmanız gerekir. (Bölüm 4, referansları daha kapsamlı bir şekilde açıklayacaktır.)
Potansiyel Bir Hatayı Result ile Ele Almak
Hala aynı kod satırı üzerinde çalışıyoruz. Şimdi kodun üçüncü satırını tartışıyoruz, ancak bunun hala tek bir mantıksal kod satırının bir parçası olduğunu unutmayın. Sonraki kısım bu metottur:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Bu kodu şu şekilde de yazabilirdik:
io::stdin().read_line(&mut tahmin).expect("Satır okunamadı");Ancak tek bir uzun satırı okumak zordur, bu yüzden onu bölmek en iyisidir.
.method_adi() sözdizimi ile bir metot çağırdığınızda uzun satırları bölmeye yardımcı
olması için yeni bir satır (newline) ve diğer boşlukları (whitespace) kullanmak
genellikle akıllıcadır. Şimdi bu satırın ne işe yaradığını tartışalım.
Daha önce bahsedildiği gibi, read_line kullanıcının girdiği her şeyi
ona aktardığımız metne (string) koyar, ancak aynı zamanda bir Result değeri döndürür.
Result, çoğunlukla bir enum olarak adlandırılan
bir enumeration’dır. Bu, birden fazla olası durumdan
birinde olabilen bir türdür. Her olası duruma varyant (variant) diyoruz.
Bölüm 6 enum’ları daha ayrıntılı olarak ele alacaktır.
Bu Result türlerinin amacı, hata ayıklama bilgilerini kodlamaktır.
Result’ın varyantları Ok ve Err’dir. Ok varyantı işlemin başarılı olduğunu
gösterir ve başarıyla üretilen değeri içerir. Err varyantı işlemin başarısız olduğu
anlamına gelir ve işlemin nasıl veya neden başarısız olduğuna dair bilgiler içerir.
Result türündeki değerler, tıpkı herhangi bir türdeki değerler gibi, üzerlerinde
tanımlanmış metotlara sahiptir. Bir Result örneğinin çağırabileceğiniz bir
expect metodu vardır. Eğer bu Result örneği bir
Err değeriyse, expect programın çökmesine (crash) neden olur ve
expect’e argüman olarak verdiğiniz mesajı görüntüler. Eğer read_line
metodu bir Err döndürdüyse, bu muhtemelen altta yatan işletim sisteminden kaynaklanan
bir hatanın sonucu olacaktır. Eğer bu Result örneği bir Ok değeriyse,
expect, Ok’un barındırdığı dönüş değerini alacak ve kullanabilmeniz
için sadece bu değeri size döndürecektir. Bu durumda, bu değer kullanıcının
girdisindeki bayt (byte) sayısıdır.
Eğer expect’i çağırmazsanız, program derlenecektir ancak bir uyarı (warning)
alacaksınız:
$ cargo build
Compiling tahmin_oyunu v0.1.0 ($PROJE/listings/ch02-guessing-game-tutorial/no-listing-02-without-expect)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut tahmin);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` (part of `#[warn(unused)]`) on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut tahmin);
| +++++++
warning: `tahmin_oyunu` (bin "tahmin_oyunu") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.18s
Rust, read_line’dan dönen Result değerini kullanmadığınız konusunda sizi
uyararak programın olası bir hatayı ele almadığını belirtir.
Uyarıyı bastırmanın doğru yolu, aslında hata yönetimi (error-handling)
kodunu yazmaktır; ancak bizim durumumuzda bir sorun oluştuğunda programın
çökmesini istiyoruz, bu nedenle expect kullanabiliriz. Hatalardan kurtulmayı
(recovering from errors) Bölüm 9’da öğreneceksiniz.
println! Yer Tutucuları (Placeholders) ile Değerleri Yazdırmak
Kapanış süslü parantezini saymazsak, şu ana kadarki kodda tartışılacak sadece bir satır daha kaldı:
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Bu satır, artık kullanıcının girdisini içeren metni yazdırır. {} şeklindeki
süslü parantez takımı bir yer tutucudur (placeholder): {}’yi, bir değeri
yerinde tutan küçük yengeç kıskaçları gibi düşünün. Bir değişkenin değerini
yazdırırken, değişken adı süslü parantezlerin içine gidebilir. Bir ifadenin
değerlendirilmesinin sonucunu yazdırırken, format dizisine (format string) boş süslü
parantezler yerleştirin, ardından format dizisinden sonra virgülle ayrılmış bir
ifadeler listesi (list of expressions) ekleyin; bu ifadeler her bir boş süslü
parantez yer tutucusunda aynı sırayla yazdırılacaktır. Bir değişkeni ve bir ifadenin
sonucunu tek bir println! çağrısıyla yazdırmak şu şekilde görünecektir:
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} ve y + 2 = {}", y + 2);
}Bu kod x = 5 ve y + 2 = 12 yazdıracaktır.
İlk Kısmı Test Etmek
Tahmin oyununun ilk bölümünü test edelim. cargo run komutunu kullanarak çalıştırın:
$ cargo run
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/tahmin_oyunu`
Sayıyı tahmin et!
Lütfen tahmininizi girin.
6
Tahmininiz: 6
Bu noktada, oyunun ilk kısmı tamamlandı: Klavyeden girdi alıyoruz ve ardından onu yazdırıyoruz.
Gizli Bir Sayı Üretmek
Sırada, kullanıcının tahmin etmeye çalışacağı gizli bir sayı üretmemiz gerekiyor.
Oyunun birden fazla kez oynanmasının eğlenceli olması için gizli sayı her seferinde
farklı olmalıdır. Oyunun çok zor olmaması için 1 ile 100 arasında rastgele bir
sayı kullanacağız. Rust henüz standart kütüphanesinde rastgele sayı işlevselliği
içermiyor. Ancak Rust ekibi, söz konusu işlevselliğe sahip bir rand crate’i
sağlıyor.
Bir Crate ile İşlevselliği Artırmak
Bir crate’in, Rust kaynak kodu dosyalarından oluşan bir koleksiyon olduğunu hatırlayın.
Geliştirdiğimiz proje çalıştırılabilir bir crate’tir. rand crate’i ise,
başka programlarda kullanılması amaçlanan ve kendi başına çalıştırılamayan kodlar içeren bir
kütüphane (library) crate’idir.
Harici crate’lerin koordinasyonu, Cargo’nun gerçekten parladığı yerdir. rand kullanan
bir kod yazabilmemiz için önce Cargo.toml dosyasını değiştirip rand crate’ini
bir bağımlılık (dependency) olarak eklememiz gerekir. Şimdi o dosyayı açın ve Cargo’nun
sizin için oluşturduğu [dependencies] bölüm başlığının hemen altına şu satırı ekleyin.
rand’i bu sürüm numarasıyla birlikte aynen burada verdiğimiz gibi belirttiğinizden emin
olun, aksi takdirde bu öğreticideki kod örnekleri çalışmayabilir:
Dosya adı: Cargo.toml
[dependencies]
rand = "0.8.5"
Cargo.toml dosyasında, bir başlıktan sonra gelen her şey, başka bir bölüm
başlayana kadar devam eden o bölümün parçasıdır. [dependencies] bölümünde
Cargo’ya, projenizin hangi harici crate’lere bağımlı olduğunu ve bu crate’lerin
hangi sürümlerini gerektirdiğinizi söylersiniz. Bu örnekte, rand crate’ini semantik (anlamsal)
sürüm belirteci 0.8.5 ile belirtiyoruz. Cargo, sürüm numaralarını yazmak için bir
standart olan Semantik Sürümlemeyi (bazen SemVer olarak
adlandırılır) anlar. 0.8.5 belirteci aslında ^0.8.5 için bir kısaltmadır ve
bu da en az 0.8.5 olan ancak 0.9.0’ın altında kalan tüm sürümleri kapsadığı anlamına gelir.
Cargo bu sürümlerin 0.8.5 sürümüyle uyumlu genel API’lere sahip olduğunu kabul eder ve bu spesifikasyon, bu bölümdeki kodla hâlâ derlenebilecek en son yama sürümünü (patch release) almanızı garanti eder. Sürümü 0.9.0 veya daha büyük olanların ise aşağıdaki örneklerin kullandığıyla aynı API’ye sahip olması garanti edilmez.
Şimdi koddaki hiçbir şeyi değiştirmeden Liste 2-2’de gösterildiği gibi projeyi derleyelim.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
rand crate’ini bağımlılık olarak ekledikten sonra cargo build çalıştırmanın çıktısıFarklı sürüm numaraları görebilirsiniz (ancak SemVer sayesinde hepsi kodla uyumlu olacaktır!) ve farklı satırlar (işletim sistemine bağlı olarak) olabilir, ve satırlar farklı bir sırada olabilir.
Harici bir bağımlılığı dahil ettiğimizde, Cargo o bağımlılığın ihtiyaç duyduğu her şeyin en son sürümlerini, Crates.io’daki verilerin bir kopyası olan kayıt defterinden (registry) getirir (fetch). Crates.io, Rust ekosistemindeki insanların başkalarının kullanması için açık kaynaklı Rust projelerini yayınladıkları yerdir.
Cargo, kayıt defterini güncelledikten sonra [dependencies] bölümünü kontrol
eder ve listelenen fakat henüz indirilmemiş crate’leri indirir. Bu örnekte
sadece rand’i bir bağımlılık olarak listelemiş olsak da, Cargo ayrıca rand’in
çalışması için bağımlı olduğu diğer crate’leri de alır. Crate’leri indirdikten sonra,
Rust bunları derler ve ardından bağımlılıklar mevcut olacak şekilde projeyi
derler.
Eğer hiçbir değişiklik yapmadan cargo build komutunu hemen tekrar çalıştırırsanız,
Finished satırı haricinde herhangi bir çıktı almazsınız. Cargo, bağımlılıkları daha
önceden indirip derlediğini ve sizin Cargo.toml dosyanızda bunlar hakkında hiçbir şeyi
değiştirmediğinizi bilir. Ayrıca kodunuz hakkında da hiçbir şeyi değiştirmediğinizi bilir,
bu yüzden onu da yeniden derlemez. Yapacak bir şeyi olmadığı için basitçe çıkış yapar.
Eğer src/main.rs dosyasını açıp önemsiz bir değişiklik yaparsanız ve ardından kaydedip tekrar derlerseniz, yalnızca iki satır çıktı görürsünüz:
$ cargo build
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Bu satırlar, Cargo’nun derlemeyi yalnızca src/main.rs dosyanızdaki ufak değişikliğinizle güncellediğini gösterir. Bağımlılıklarınız değişmedi, bu yüzden Cargo, bunlar için zaten indirip derlediği şeyleri yeniden kullanabileceğini biliyor.
Tekrarlanabilir Derlemeleri Sağlamak (Reproducible Builds)
Cargo, siz veya başka herhangi bir kişi kodunuzu her derlediğinde aynı artefaktı
(artifact) yeniden derleyebilmenizi sağlayan bir mekanizmaya sahiptir: Cargo, siz
aksi bir şey belirtene kadar yalnızca belirttiğiniz bağımlılık sürümlerini
kullanacaktır. Örneğin, gelecek hafta rand crate’inin 0.8.6 sürümünün çıktığını,
ve bu sürümün önemli bir hata düzeltmesi içerdiğini, ancak kodunuzu bozacak bir
gerileme (regression) de barındırdığını varsayalım. Bunun üstesinden gelmek için,
Rust ilk cargo build komutunu çalıştırdığınızda Cargo.lock dosyasını oluşturur,
ve biz şu an tahmin_oyunu dizinimizde buna sahibiz.
Bir projeyi ilk kez derlediğinizde, Cargo kriterlere uyan bağımlılıkların tüm sürümlerini belirler (figures out) ve daha sonra bunları Cargo.lock dosyasına yazar. Projenizi gelecekte derlediğinizde Cargo, Cargo.lock dosyasının mevcut olduğunu görecek ve sürümleri yeniden belirleme işini yapmaktansa orada belirtilen sürümleri kullanacaktır. Bu, tekrarlanabilir bir derlemeye otomatik olarak sahip olmanızı sağlar. Başka bir deyişle, siz açıkça yükseltme (upgrade) yapana kadar, Cargo.lock dosyası sayesinde projeniz 0.8.5 sürümünde kalacaktır. Cargo.lock dosyası, tekrarlanabilir derlemeler için önemli olduğundan, genellikle projenizdeki geri kalan kodlarla birlikte sürüm kontrolüne (source control) dahil edilir.
Yeni Bir Sürüm Almak İçin Bir Crate’i Güncellemek
Bir crate’i güncellemek istediğinizde, Cargo update komutunu sağlar;
bu komut Cargo.lock dosyasını yok sayacak ve Cargo.toml dosyasındaki
spesifikasyonlarınıza uyan en son sürümleri belirleyecektir. Ardından Cargo,
bu sürümleri Cargo.lock dosyasına yazacaktır. Aksi takdirde, varsayılan olarak Cargo
yalnızca 0.8.5’ten büyük ve 0.9.0’dan küçük sürümleri arayacaktır. Eğer rand crate’i
iki yeni sürüm olan 0.8.6 ve 0.999.0’ı yayınlamışsa, cargo update çalıştırdığınızda
şunu görürdünüz:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.999.0)
Cargo, 0.999.0 sürümünü yok sayar. Bu noktada Cargo.lock dosyanızda artık kullandığınız
rand crate sürümünün 0.8.6 olduğunu belirten bir değişiklik fark edersiniz. rand 0.999.0 sürümünü
veya 0.999.x serisindeki herhangi bir sürümü kullanmak için, bunun yerine Cargo.toml dosyanızı
şu şekilde güncellemeniz gerekir (bu değişikliği yapmayın çünkü aşağıdaki örnekler
rand 0.8 kullandığınızı varsayıyor):
[dependencies]
rand = "0.999.0"
cargo build’i bir sonraki çalıştırışınızda, Cargo, mevcut crate’lerin kayıt
defterini güncelleyecek ve belirttiğiniz yeni sürüme göre rand gereksinimlerinizi
yeniden değerlendirecektir.
Cargo ve ekosistemi hakkında söylenecek çok daha fazla şey var ve bunları Bölüm 14’te tartışacağız; ancak şimdilik bilmeniz gerekenler bunlar. Cargo, kütüphaneleri yeniden kullanmayı çok kolaylaştırdığı için, Rust geliştiricileri (Rustaceans) bir dizi paketten birleştirilmiş daha küçük projeler yazabilirler.
Rastgele Bir Sayı Üretmek
Tahmin edilecek sayıyı üretmek için rand kullanmaya başlayalım. Bir sonraki
adım, Liste 2-3’te gösterildiği gibi src/main.rs dosyasını güncellemektir.
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Öncelikle, use rand::Rng; satırını ekliyoruz. Rng trait’i (özelliği),
rastgele sayı üreteçlerinin (generators) uyguladığı metotları
tanımlar ve bu metotları kullanabilmemiz için bu trait kapsamda olmalıdır.
Bölüm 10, trait’leri detaylı bir şekilde ele alacaktır.
Sonrasında ortaya iki satır ekliyoruz. İlk satırda, kullanacağımız belirli
rastgele sayı üretecini bize veren rand::thread_rng fonksiyonunu çağırıyoruz:
Bu üreteç, yürütmenin mevcut iş parçacığına özeldir (local)
ve işletim sistemi tarafından tohumlanır (seeded). Sonra da rastgele sayı
üreteci üzerinde gen_range metodunu çağırıyoruz. Bu metot, use rand::Rng;
ifadesi ile kapsama dahil ettiğimiz Rng trait’i tarafından tanımlanmıştır.
gen_range metodu argüman olarak bir aralık ifadesi (range expression) alır
ve o aralıkta rastgele bir sayı üretir. Burada kullandığımız aralık ifadesi türü
baslangic..=bitis (start..=end) formundadır ve alt ile üst sınırları dahil
eder; bu nedenle 1 ile 100 arasında bir sayı talep etmek için 1..=100 belirtmemiz gerekir.
Not: Bir crate’ten hangi trait’leri kullanacağınızı ve hangi metotları ile fonksiyonları çağıracağınızı hemen bilemezsiniz; bu yüzden her crate’in kullanımı ile ilgili talimatları içeren dokümantasyonları vardır. Cargo’nun başka bir şık özelliği de,
cargo doc --openkomutunu çalıştırmanın tüm bağımlılıklarınız tarafından sağlanan belgeleri yerel olarak oluşturması (build) ve bunları tarayıcınızda açmasıdır. Örneğin,randcrate’indeki diğer işlevlerle ilgileniyorsanız,cargo doc --opençalıştırın ve soldaki kenar çubuğundan (sidebar)rand’a tıklayın.
İkinci yeni satır gizli sayıyı yazdırır. Bu, programı geliştirirken onu test edebilmek için kullanışlıdır, ancak nihai sürümden bunu sileceğiz. Program, başlar başlamaz cevabı yazdırıyorsa pek de bir oyun sayılmaz!
Programı birkaç kez çalıştırmayı deneyin:
$ cargo run
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/tahmin_oyunu`
Sayıyı tahmin et!
Gizli sayı: 7
Lütfen tahmininizi girin.
4
Tahmininiz: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/tahmin_oyunu`
Sayıyı tahmin et!
Gizli sayı: 83
Lütfen tahmininizi girin.
5
Tahmininiz: 5
Farklı rastgele sayılar almalısınız ve hepsi de 1 ile 100 arasında sayılar olmalıdır. Harika iş çıkardınız!
Tahmini Gizli Sayıyla Karşılaştırmak
Artık kullanıcı girdisine ve rastgele bir sayıya sahip olduğumuza göre, onları karşılaştırabiliriz. Bu adım Liste 2-4’te gösterilmektedir. Not: Bu kod daha sonra açıklayacağımız nedenlerden ötürü henüz derlenmeyecektir.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => println!("Kazandınız!"),
}
}Öncelikle, standart kütüphaneden std::cmp::Ordering adlı bir türü kapsama
dahil eden başka bir use ifadesi ekliyoruz. Ordering türü başka bir enum’dur
ve Less (Daha Küçük), Greater (Daha Büyük) ve Equal (Eşit) varyantlarına
sahiptir. Bunlar, iki değeri karşılaştırdığınızda mümkün olan üç sonuçtur.
Sonra en alta Ordering türünü kullanan beş yeni satır ekliyoruz. cmp
metodu iki değeri karşılaştırır ve karşılaştırılabilen herhangi bir şey üzerinde
çağrılabilir. Ne ile karşılaştırma yapmak istiyorsanız onun bir referansını
alır: Burada tahmin’i gizli_sayi ile karşılaştırıyor. Sonrasında, use
ifadesiyle kapsama dahil ettiğimiz Ordering enum’ının bir varyantını döndürür.
cmp çağrısından, tahmin ve gizli_sayi değerleriyle hangi Ordering
varyantının döndüğüne bağlı olarak bundan sonra ne yapacağımıza karar
vermek için bir match ifadesi kullanıyoruz.
Bir match ifadesi kollardan (arms) oluşur. Bir kol (arm), eşleştirilecek
bir desenden (pattern) ve match’e verilen değer o kolun desenine uyduğunda
çalıştırılması gereken koddan oluşur. Rust, match’e verilen değeri alır
ve sırayla her bir kolun deseni boyunca bakar. Desenler (patterns) ve
match yapısı çok güçlü Rust özellikleridir: Kodunuzun karşılaşabileceği
çeşitli durumları ifade etmenizi ve hepsini ele aldığınızdan emin olmanızı sağlarlar.
Bu özellikler sırasıyla Bölüm 6 ve Bölüm 19’da ayrıntılı olarak ele alınacaktır.
Burada kullandığımız match ifadesi ile bir örnek üzerinden gidelim.
Diyelim ki kullanıcı 50 tahmininde bulundu ve bu kez rastgele üretilen gizli sayı 38.
Kod 50’yi 38 ile karşılaştırdığında, cmp metodu Ordering::Greater (Daha Büyük)
döndürecektir, çünkü 50, 38’den büyüktür. match ifadesi Ordering::Greater
değerini alır ve her bir kolun desenini (pattern) kontrol etmeye başlar.
İlk kolun deseni olan Ordering::Less’e bakar ve Ordering::Greater
değerinin Ordering::Less (Daha Küçük) ile eşleşmediğini görür; bu yüzden
o koldaki kodu yok sayar ve bir sonraki kola geçer. Sonraki kolun
deseni Ordering::Greater’dır, ki bu da Ordering::Greater ile eşleşir!
O koldaki ilişkili kod çalıştırılacak ve ekrana Çok büyük! yazdıracaktır.
match ifadesi ilk başarılı eşleşmeden sonra sona erer, bu senaryoda
artık son kola bakmayacaktır.
Fakat Liste 2-4’teki kod henüz derlenmeyecektir. Deneyelim:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling tahmin_oyunu v0.1.0 ($PROJE/listings/ch02-guessing-game-tutorial/listing-02-04)
error[E0308]: mismatched types
--> src/main.rs:27:22
|
27 | match tahmin.cmp(&gizli_sayi) {
| --- ^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> $HOME/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/cmp.rs:991:8
|
991 | fn cmp(&self, other: &Self) -> Ordering;
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `tahmin_oyunu` (bin "tahmin_oyunu") due to 1 previous error
Hatanın özü uyumsuz türler (mismatched types) olduğunu belirtiyor.
Rust güçlü, statik bir tür sistemine (static type system) sahiptir. Ancak,
aynı zamanda tür çıkarımı (type inference) da vardır. let mut tahmin = String::new()
yazdığımızda, Rust tahmin’in bir String olması gerektiği çıkarımını
yapabildi ve bizim türü yazmamıza gerek bırakmadı. Öte yandan, gizli_sayi
bir sayı türüdür. Rust’ın 1 ile 100 arasında değer alabilen birkaç
sayı türü vardır: 32 bitlik bir sayı olan i32; işaretsiz (unsigned) 32 bitlik
bir sayı olan u32; 64 bitlik bir sayı olan i64; ve diğerleri. Aksi
belirtilmediği sürece Rust varsayılan olarak i32 kullanır. Eğer Rust’ın
başka bir sayısal tür çıkarımı yapmasına neden olacak tür bilgisini
başka bir yere eklemediyseniz, gizli_sayi’nın türü budur. Hatanın nedeni,
Rust’ın bir metin türü (string) ile bir sayı türünü karşılaştıramamasıdır.
Nihayetinde, programın girdi olarak okuduğu String’i bir sayı türüne
dönüştürmek istiyoruz, böylece onu gizli sayıyla sayısal olarak
karşılaştırabileceğiz. Bunu main fonksiyonunun gövdesine
şu satırı ekleyerek yapıyoruz:
Dosya adı: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
println!("Lütfen tahmininizi girin.");
// --snip--
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
let tahmin: u32 = tahmin.trim().parse().expect("Lütfen bir sayı yazın!");
println!("Tahmininiz: {tahmin}");
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => println!("Kazandınız!"),
}
}O satır şudur:
let tahmin: u32 = tahmin.trim().parse().expect("Lütfen bir sayı yazın!");tahmin adında bir değişken oluşturuyoruz. Ama bir dakika, programda zaten
tahmin adında bir değişken yok muydu? Var, ancak Rust yararlı bir şekilde
tahmin’in önceki değerini yenisiyle gölgelendirmemize (shadow) olanak tanır.
Gölgelendirme, bizi örneğin tahmin_str ve tahmin gibi
iki farklı değişken oluşturmaya zorlamak yerine tahmin değişken adını
yeniden kullanmamıza olanak tanır. Bunu Bölüm 3’te
daha ayrıntılı ele alacağız, ancak şimdilik bu özelliğin genellikle
bir değeri bir türden diğerine dönüştürmek istediğinizde kullanıldığını bilin.
Bu yeni değişkeni tahmin.trim().parse() ifadesine bağlıyoruz.
İfadedeki tahmin, girdiyi metin (string) olarak barındıran
orijinal tahmin değişkenine işaret eder. Bir String örneği üzerindeki
trim metodu, metnin başındaki ve sonundaki tüm boşlukları ortadan kaldıracaktır.
Metni (string) yalnızca sayısal veri içerebilen bir u32’ye dönüştürmeden önce
bunu yapmamız gerekir. Kullanıcının read_line’ı tamamlamak ve tahminini
girmek için enter (giriş) tuşuna basması gerekir; bu da metne
bir yeni satır (newline) karakteri ekler. Örneğin, kullanıcı 5 yazıp
enter’a basarsa, tahmin şöyle görünür: 5\n. \n “yeni satırı”
temsil eder. (Windows’ta enter’a basmak satır başı ve yeni satır,
\r\n ile sonuçlanır.) trim metodu \n veya \r\n’i ortadan kaldırarak
sadece 5 olmasını sağlar.
Metinler (strings) üzerindeki parse metodu,
bir metni başka bir türe dönüştürür. Burada, onu bir metinden bir sayıya
dönüştürmek için kullanıyoruz. let tahmin: u32 diyerek Rust’a tam
olarak istediğimiz sayı türünü söylemeliyiz. tahmin’den sonraki
iki nokta üst üste (:), Rust’a değişkenin türünü belirteceğimizi söyler.
Rust’ın birkaç yerleşik sayı türü vardır; burada gördüğünüz u32 işaretsiz,
32 bitlik bir tam sayıdır. Küçük pozitif bir sayı için iyi bir
varsayılan seçimdir. Diğer sayı türlerini Bölüm 3’te
öğreneceksiniz.
Ek olarak, bu örnek programdaki u32 bildirmi (annotation) ve gizli_sayi ile
yapılan karşılaştırma, Rust’ın gizli_sayi’nın da bir u32 olması gerektiği
çıkarımını yapacağı anlamına gelir. Yani, artık karşılaştırma aynı
türden iki değer arasında olacaktır!
parse metodu yalnızca mantıksal olarak sayılara dönüştürülebilen
karakterler üzerinde çalışacaktır ve bu nedenle kolayca hatalara neden olabilir.
Örneğin, metin A👍% içerseydi, bunu bir sayıya dönüştürmenin hiçbir yolu olmazdı.
Başarısız olabileceği için parse metodu da read_line metodunun yaptığı gibi
(daha önce “Potansiyel Bir Hatayı Result ile Ele Almak” kısmında tartışılmıştı) bir Result
türü döndürür. Bu Result’ı, expect metodunu tekrar kullanarak aynı
şekilde ele alacağız. Eğer parse metodu, metinden bir sayı oluşturamadığı
için bir Err Result varyantı döndürürse, expect çağrısı oyunu çökertecek
(crash) ve ona verdiğimiz mesajı yazdıracaktır. Eğer parse, metni
başarıyla bir sayıya dönüştürebilirse, Result’ın Ok varyantını döndürür;
ve expect, Ok değerinden istediğimiz numarayı döndürecektir.
Programı şimdi çalıştıralım:
$ cargo run
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/tahmin_oyunu`
Sayıyı tahmin et!
Gizli sayı: 58
Lütfen tahmininizi girin.
76
Tahmininiz: 76
Çok büyük!
Güzel! Tahminden önce boşluklar eklenmiş olmasına rağmen, program yine de kullanıcının 76 tahmininde bulunduğunu anladı (figured out). Farklı türdeki girdilerle farklı davranışları doğrulamak için programı birkaç kez çalıştırın: Sayıyı doğru tahmin edin, çok büyük bir sayı tahmin edin ve çok küçük bir sayı tahmin edin.
Şu anda oyunun büyük bir kısmı çalışıyor, ancak kullanıcı yalnızca bir tahmin yapabiliyor. Bir döngü (loop) ekleyerek bunu değiştirelim!
Döngüyle Birden Fazla Tahmine İzin Vermek
loop anahtar kelimesi sonsuz bir döngü oluşturur. Kullanıcılara sayıyı tahmin
etmeleri için daha fazla şans vermek adına bir döngü ekleyeceğiz:
Dosya adı: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("Gizli sayı: {gizli_sayi}");
loop {
println!("Lütfen tahmininizi girin.");
// --snip--
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
let tahmin: u32 = tahmin.trim().parse().expect("Lütfen bir sayı yazın!");
println!("Tahmininiz: {tahmin}");
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => println!("Kazandınız!"),
}
}
}Gördüğünüz gibi, tahmini giriş isteminden itibaren her şeyi bir döngü içine taşıdık. Döngünün içindeki satırların her birini fazladan dört boşluk (space) girintilediğinizden (indent) emin olun ve programı tekrar çalıştırın. Program artık sonsuza dek başka bir tahmin isteyecektir, ki bu aslında yeni bir sorun ortaya çıkarır. Kullanıcı çıkamayacak gibi görünüyor!
Kullanıcı her zaman ctrl-C klavye kısayolunu
kullanarak programı durdurabilir. Ancak, “Tahmini Gizli Sayıyla Karşılaştırmak” kısmındaki parse
tartışmasında bahsedildiği gibi, bu doyumsuz canavardan kaçmanın başka bir yolu daha var:
Eğer kullanıcı sayı olmayan bir girdi girerse, program çökecektir (crash).
Aşağıda gösterildiği gibi kullanıcının çıkabilmesini (quit) sağlamak için
bundan faydalanabiliriz:
$ cargo run
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/tahmin_oyunu`
Sayıyı tahmin et!
Gizli sayı: 59
Lütfen tahmininizi girin.
45
Tahmininiz: 45
Çok küçük!
Lütfen tahmininizi girin.
60
Tahmininiz: 60
Çok büyük!
Lütfen tahmininizi girin.
59
Tahmininiz: 59
Kazandınız!
Lütfen tahmininizi girin.
cikis
thread 'main' panicked at src/main.rs:28:47:
Lütfen bir sayı yazın!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
cikis (quit) yazmak oyundan çıkmanızı sağlayacaktır, ancak
fark edeceğiniz üzere başka herhangi bir sayısal olmayan girdi de aynısını yapacaktır.
Bu, en hafif tabirle ideal bir durum değildir (suboptimal); oyunun, doğru
sayı tahmin edildiğinde de durmasını istiyoruz.
Doğru Tahminden Sonra Çıkmak
Kullanıcı kazandığında oyundan çıkmasını sağlamak için bir break
(kır) ifadesi ekleyerek oyunu programlayalım:
Dosya adı: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
loop {
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
let tahmin: u32 = tahmin.trim().parse().expect("Lütfen bir sayı yazın!");
println!("Tahmininiz: {tahmin}");
// --snip--
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => {
println!("Kazandınız!");
break;
}
}
}
}Kazandınız! ifadesinden sonra break satırını eklemek, kullanıcı gizli
sayıyı doğru tahmin ettiğinde programın döngüden çıkmasını sağlar.
Döngüden çıkmak aynı zamanda programdan çıkmak anlamına da gelir,
çünkü döngü main’in son kısmıdır.
Geçersiz Girdiyi Ele Almak
Oyunun davranışını daha da iyileştirmek için, kullanıcı sayısal olmayan
bir girdi girdiğinde programı çökertmek (crash) yerine, kullanıcının tahmin etmeye
devam edebilmesi için oyunun sayı olmayan veriyi görmezden gelmesini sağlayalım.
Bunu Liste 2-5’te gösterildiği gibi, tahmin’in String’den u32’ye
dönüştürüldüğü satırı değiştirerek yapabiliriz.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
loop {
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
// --snip--
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
let tahmin: u32 = match tahmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Tahmininiz: {tahmin}");
// --snip--
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => {
println!("Kazandınız!");
break;
}
}
}
}Bir hata durumunda programı çökertmekten ziyade hatayı yönetmeye (handle the error)
geçmek için, bir expect çağrısından çıkıp match ifadesine geçiş yapıyoruz.
parse’ın bir Result türü döndürdüğünü ve Result’ın Ok ile Err varyantlarına
sahip bir enum olduğunu hatırlayın. Burada, tıpkı cmp metodunun Ordering sonucunda
yaptığımız gibi bir match ifadesi kullanıyoruz.
Eğer parse metni başarıyla bir sayıya dönüştürebilirse, elde edilen
sayıyı içeren bir Ok değeri döndürür. O Ok değeri, ilk kolun deseniyle
eşleşecek ve match ifadesi, sadece parse’ın ürettiği ve Ok değerinin
içine koyduğu sayi (num) değerini döndürecektir. Bu sayı, oluşturduğumuz yeni
tahmin değişkeninde tam da istediğimiz yere gelecektir.
Eğer parse metni bir sayıya dönüştüremezse (not able), hata hakkında daha
fazla bilgi barındıran bir Err değeri döndürür. Err değeri, ilk match kolundaki
Ok(sayi) deseni ile eşleşmez, ancak ikinci koldaki Err(_) deseni ile eşleşir.
Alt çizgi (_), her şeyi yakalayan (catch-all) bir değerdir; bu örnekte, içlerinde
ne bilgi olursa olsun tüm Err değerleriyle eşleşmek istediğimizi söylüyoruz. Böylece,
program ikinci kolun kodu olan continue’yu (devam et) çalıştırır; bu da
programa loop’un bir sonraki döngüsüne (iteration) geçmesini ve
başka bir tahmin istemesini söyler. Yani etkin olarak, program
parse’ın karşılaşabileceği tüm hataları yok sayar!
Artık programdaki her şey beklendiği gibi çalışmalıdır. Deneyelim:
$ cargo run
Compiling tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/tahmin_oyunu`
Sayıyı tahmin et!
Gizli sayı: 61
Lütfen tahmininizi girin.
10
Tahmininiz: 10
Çok küçük!
Lütfen tahmininizi girin.
99
Tahmininiz: 99
Çok büyük!
Lütfen tahmininizi girin.
foo
Lütfen tahmininizi girin.
61
Tahmininiz: 61
Kazandınız!
Harika! Son bir küçük ayarlama (tweak) ile tahmin oyununu bitireceğiz. Programın hâlâ
gizli sayıyı yazdırdığını hatırlayın. Bu, test için iyi çalıştı, ancak oyunu
mahvediyor. Gizli sayıyı çıktı olarak veren println! ifadesini silelim.
Liste 2-6 son kodu göstermektedir.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
loop {
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
let tahmin: u32 = match tahmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Tahmininiz: {tahmin}");
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => {
println!("Kazandınız!");
break;
}
}
}
}Bu noktada tahmin oyununu başarıyla inşa ettiniz. Tebrikler!
Özet
Bu proje sizi birçok yeni Rust kavramıyla uygulamalı olarak
tanıştırmanın bir yoluydu: let, match, fonksiyonlar, harici crate’lerin
kullanımı ve daha fazlası. Sonraki birkaç bölümde bu kavramlar
hakkında daha fazla ayrıntı öğreneceksiniz. Bölüm 3, çoğu
programlama dilinin sahip olduğu değişkenler, veri türleri ve
fonksiyonlar gibi kavramları ele alır ve bunların Rust’ta
nasıl kullanılacağını gösterir. Bölüm 4, Rust’ı diğer dillerden
farklı kılan bir özellik olan sahipliği araştırır.
Bölüm 5 struct’ları (yapıları) ve metot sözdizimini (method syntax) tartışırken,
Bölüm 6 enum’ların nasıl çalıştığını açıklar.
Yaygın Programlama Kavramları
Bu bölüm, neredeyse her programlama dilinde ortaya çıkan kavramları ve bunların Rust’ta nasıl çalıştığını kapsar. Çoğu programlama dili temelinde birbiriyle pek çok ortak noktaya sahiptir. Bu bölümde sunulan kavramların hiçbiri Rust’a özgü değildir, ancak bunları Rust bağlamında tartışacağız ve bunların kullanımı etrafındaki gelenekleri (conventions) açıklayacağız.
Özellikle değişkenler, temel veri türleri (basic types), fonksiyonlar (functions), yorumlar (comments) ve kontrol akışı (control flow) hakkında bilgi edineceksiniz. Bu temeller her Rust programında bulunacaktır ve bunları erkenden öğrenmek size başlamanız için güçlü bir temel sağlayacaktır.
Anahtar Kelimeler (Keywords)
Rust dili, tıpkı diğer dillerde olduğu gibi, yalnızca dilin kendisi tarafından kullanılmak üzere ayrılmış bir dizi anahtar kelimeye (keywords) sahiptir. Bu kelimeleri değişken veya fonksiyon isimleri olarak kullanamayacağınızı unutmayın. Anahtar kelimelerin çoğunun özel anlamları vardır ve bunları Rust programlarınızda çeşitli görevleri yerine getirmek için kullanacaksınız; birkaçının ise şu an onlarla ilişkili bir işlevselliği yoktur ancak gelecekte Rust’a eklenebilecek işlevsellikler için ayrılmıştır (reserved). Anahtar kelimelerin listesini Ek A’da bulabilirsiniz.
Değişkenler ve Değiştirilebilirlik
Değişkenler ve Değiştirilebilirlik (Mutability)
“Değerleri Değişkenlerle Saklamak” bölümünde bahsedildiği gibi, değişkenler varsayılan olarak değiştirilemezdir. Bu, kodunuzu Rust’ın sunduğu güvenlik ve kolay eşzamanlılık (concurrency) avantajlarından yararlanacak şekilde yazmanız için Rust’ın size verdiği birçok küçük dürtmeden biridir. Ancak yine de değişkenlerinizi değiştirilebilir yapma seçeneğiniz vardır. Rust’ın sizi neden değiştirilemezliği tercih etmeye teşvik ettiğini ve neden bazen bundan vazgeçmek isteyebileceğinizi keşfedelim.
Bir değişken değiştirilemez olduğunda, bir değere bir isim bağlandığında,
o değeri bir daha değiştiremezsiniz. Bunu göstermek için,
cargo new degiskenler komutunu kullanarak projects dizininizde
degiskenler adında yeni bir proje oluşturun.
Ardından, yeni degiskenler dizininizde src/main.rs dosyasını açın ve kodunu henüz derlenmeyecek olan şu kodla değiştirin:
Dosya adı: src/main.rs
fn main() {
let x = 5;
println!("x'in değeri: {x}");
x = 6;
println!("x'in değeri: {x}");
}Programı kaydedin ve cargo run kullanarak çalıştırın. Aşağıdaki çıktıda gösterildiği
gibi, değiştirilemezlik (immutability) hatasıyla ilgili bir hata mesajı almalısınız:
$ cargo run
Compiling variables v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-01-variables-are-immutable)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("x'in değeri: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Bu örnek derleyicinin programlarınızdaki hataları bulmanıza nasıl yardımcı olduğunu gösterir. Derleyici hataları sinir bozucu olabilir, ancak aslında yalnızca programınızın sizin istediğiniz şeyi henüz güvenli bir şekilde yapmadığı anlamına gelirler; sizin iyi bir programcı olmadığınız anlamına gelmezler! Deneyimli Rustacean’lar bile hâlâ derleyici hataları almaktadır.
cannot assign twice to immutable variable `x` (x değiştirilemez değişkenine
ikinci kez atama yapılamaz) hata mesajını aldınız çünkü değiştirilemez x değişkenine
ikinci bir değer atamaya çalıştınız.
Değiştirilemez olarak belirlenmiş bir değeri değiştirmeye çalıştığımızda derleme zamanı (compile-time) hataları almamız önemlidir, çünkü bizzat bu durum hatalara (bug) yol açabilir. Kodumuzun bir kısmı bir değerin asla değişmeyeceği varsayımıyla çalışırsa ve kodumuzun başka bir kısmı o değeri değiştirirse, kodun ilk kısmının tasarlandığı şeyi yapmaması mümkündür. Bu tür bir hatanın nedenini oluştuktan sonra takip etmek zor olabilir, özellikle de kodun ikinci parçası değeri yalnızca bazen değiştiriyorsa. Rust derleyicisi, bir değerin değişmeyeceğini belirttiğinizde gerçekten değişmeyeceğini garanti eder, bu nedenle bunu kendiniz takip etmek zorunda kalmazsınız. Böylece kodunuzun mantığını anlamak daha kolaydır.
Ancak değiştirilebilirlik (mutability) çok faydalı olabilir ve kod yazmayı daha
kullanışlı hale getirebilir. Değişkenler varsayılan olarak değiştirilemez olsa da,
Bölüm 2’de yaptığınız gibi değişken
adının önüne mut ekleyerek onları değiştirilebilir yapabilirsiniz. mut
eklemek aynı zamanda kodun diğer kısımlarının bu değişkenin değerini değiştireceğini
belirterek, kodu gelecekte okuyacak kişilere niyetinizi iletir.
Örneğin, src/main.rs dosyasını şu şekilde değiştirelim:
Dosya adı: src/main.rs
fn main() {
let mut x = 5;
println!("x'in değeri: {x}");
x = 6;
println!("x'in değeri: {x}");
}Şimdi programı çalıştırdığımızda şunu elde ederiz:
$ cargo run
Compiling variables v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-02-adding-mut)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/variables`
x'in değeri: 5
x'in değeri: 6
mut kullanıldığında x’e bağlı olan değeri 5’ten 6’ya değiştirmemize izin verilir.
Nihayetinde, değiştirilebilirliği kullanıp kullanmamaya karar vermek size bağlıdır ve
o belirli durumda neyin en açık (anlaşılır) olduğunu düşündüğünüze göre değişir.
Sabitleri Bildirmek (Constants)
Değiştirilemez değişkenler gibi, sabitler de bir isme bağlı olan ve değiştirilmesine izin verilmeyen değerlerdir, ancak sabitler ile değişkenler arasında birkaç fark vardır.
İlk olarak, sabitlerle birlikte mut kullanmanıza izin verilmez. Sabitler sadece
varsayılan olarak değiştirilemez değildirler; onlar her zaman değiştirilemezdirler.
Sabitleri let anahtar kelimesi yerine const anahtar kelimesini kullanarak
bildirirsiniz (declare) ve değerin türü mutlaka belirtilmelidir (annotated).
Türleri ve tür bildirimlerini (type annotations) bir sonraki bölüm olan
“Veri Türleri” kısmında ele alacağız, bu yüzden
şu anda ayrıntılar için endişelenmeyin. Sadece her zaman türü belirtmeniz
gerektiğini bilin.
Sabitler, küresel kapsam (global scope) da dahil olmak üzere herhangi bir kapsamda bildirilebilirler; bu durum onları, kodun birçok parçasının bilmesi gereken değerler için kullanışlı hale getirir.
Son fark ise sabitlerin, sadece çalışma zamanında hesaplanabilecek bir değere değil, yalnızca sabit bir ifadeye (constant expression) ayarlanabilmesidir.
İşte bir sabit bildirimi örneği:
#![allow(unused)]
fn main() {
const SANIYE_CINSINDEN_UC_SAAT: u32 = 60 * 60 * 3;
}Sabitin adı SANIYE_CINSINDEN_UC_SAAT’tir (THREE_HOURS_IN_SECONDS) ve değeri,
60 (bir dakikadaki saniye sayısı), 60 (bir saatteki dakika sayısı) ve
3’ün (bu programda saymak istediğimiz saat sayısı) çarpılması sonucuna ayarlanmıştır.
Rust’ın sabitler için adlandırma geleneği, tüm harfleri
büyük yazmak ve kelimeler arasında alt çizgi kullanmaktır. Derleyici, derleme
zamanında sınırlı bir dizi işlemi değerlendirebilir; bu da sabiti doğrudan
10.800 değerine ayarlamak yerine, bu değeri anlaması ve doğrulaması daha kolay
bir şekilde yazmayı seçmemizi sağlar. Sabitleri bildirirken hangi işlemlerin
kullanılabileceği hakkında daha fazla bilgi için Rust Referansı’nın sabit değerlendirme bölümüne bakın.
Sabitler, bildirildikleri kapsam içinde, program çalıştığı süre boyunca geçerlidirler. Bu özellik, bir oyundaki herhangi bir oyuncunun kazanabileceği maksimum puan sayısı veya ışık hızı gibi, programın birden fazla bölümünün bilmesi gerekebilecek uygulama alanınızdaki (application domain) değerler için sabitleri yararlı kılar.
Programınız boyunca kullanılan sabit (hardcoded) değerleri const (sabit) olarak
adlandırmak, bu değerin anlamını kodun gelecekteki bakımcılarına
iletmek açısından faydalıdır. Ayrıca, sabit kodlanmış değerin gelecekte
güncellenmesi gerektiğinde kodunuzda değiştirmeniz gereken yalnızca bir yer
olmasına da yardımcı olur.
Gölgelendirme (Shadowing)
Bölüm 2’deki tahmin
oyunu eğitiminde gördüğünüz gibi, önceki bir değişkenle aynı isimde yeni bir
değişken bildirebilirsiniz (declare). Rust geliştiricileri (Rustaceans) ilk değişkenin
ikincisi tarafından gölgelendiğini (shadowed) söyler; bu, değişkenin adını
kullandığınızda derleyicinin göreceği şeyin ikinci değişken olduğu anlamına gelir.
Aslında ikinci değişken, kendisi gölgelenene veya kapsam sona erene kadar
değişken adının tüm kullanımlarını kendine alarak ilkini gölgede bırakır (overshadows).
Bir değişkeni aynı değişkenin adını kullanarak ve let anahtar kelimesinin
kullanımını tekrarlayarak aşağıdaki gibi gölgelendirebiliriz:
Dosya adı: src/main.rs
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("İç kapsamdaki x'in değeri: {x}");
}
println!("x'in değeri: {x}");
}Bu program önce x’i 5 değerine bağlar. Ardından, let x = komutunu
tekrarlayarak yeni bir x değişkeni oluşturur, orijinal değeri alır ve
1 ekler, böylece x’in değeri 6 olur. Sonra, süslü parantezlerle (curly brackets)
oluşturulan bir iç kapsamda (inner scope), üçüncü let ifadesi de x’i
gölgelendirir ve önceki değeri 2 ile çarparak x’e 12 değerini veren
yeni bir değişken oluşturur. O kapsam sona erdiğinde iç gölgelendirme biter
ve x tekrar 6 olur. Bu programı çalıştırdığımızda şu çıktıyı verecektir:
$ cargo run
Compiling variables v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-03-shadowing)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/variables`
İç kapsamdaki x'in değeri: 12
x'in değeri: 6
Gölgelendirme, bir değişkeni mut olarak işaretlemekten farklıdır;
çünkü let anahtar kelimesini kullanmadan kazara bu değişkene yeniden atama (reassign)
yapmaya çalışırsak derleme zamanı (compile-time) hatası alırız. let kullanarak,
bir değer üzerinde birkaç dönüştürme (transformation) işlemi gerçekleştirebiliriz, ancak
bu dönüştürmeler tamamlandıktan sonra değişkenin değiştirilemez kalmasını
sağlayabiliriz.
mut ve gölgelendirme arasındaki diğer fark ise şudur: let anahtar kelimesini
tekrar kullandığımızda etkili bir şekilde yeni bir değişken oluşturduğumuz için,
değerin türünü değiştirebilir ancak aynı ismi yeniden kullanabiliriz.
Örneğin, programımızın bir kullanıcıdan biraz metin arasına ne kadar boşluk
istediğini boşluk karakterleri girerek göstermesini istediğini, ve ardından bu
girdiyi bir sayı olarak saklamak istediğimizi varsayalım:
fn main() {
let bosluklar = " ";
let bosluklar = bosluklar.len();
}İlk bosluklar değişkeni bir metin (string) türüdür ve ikinci bosluklar değişkeni
bir sayı türüdür. Gölgelendirme böylece bizi bosluklar_str ve
bosluklar_sayi gibi farklı isimler bulmak zorunda kalmaktan kurtarır; bunun yerine
daha basit olan bosluklar ismini yeniden kullanabiliriz. Ancak, burada gösterildiği
gibi bunun için mut kullanmaya çalışırsak, derleme zamanı (compile-time) hatası alırız:
fn main() {
let mut bosluklar = " ";
bosluklar = bosluklar.len();
}Hata, bir değişkenin türünü değiştirmemize (mutate) izin verilmediğini söylüyor:
$ cargo run
Compiling variables v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-05-mut-cant-change-types)
error[E0308]: mismatched types
--> src/main.rs:4:17
|
3 | let mut bosluklar = " ";
| ----- expected due to this value
4 | bosluklar = bosluklar.len();
| ^^^^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Artık değişkenlerin nasıl çalıştığını keşfettiğimize göre, sahip olabilecekleri daha fazla veri türüne (data types) bakalım.
Veri Türleri
Veri Türleri
Rust’taki her değer, Rust’a ne tür bir veri belirtildiğini söyleyen belirli bir veri türüne (data type) sahiptir, böylece o veriyle nasıl çalışacağını bilir. İki veri türü alt kümesini inceleyeceğiz: skaler (scalar) ve bileşik (compound).
Rust’ın statik tipli (statically typed) bir dil olduğunu aklınızda bulundurun; bu, derleme zamanında tüm değişkenlerin türlerini bilmesi gerektiği anlamına gelir. Derleyici genellikle değere ve onu nasıl kullandığımıza bağlı olarak hangi türü kullanmak istediğimizi çıkarabilir. Bölüm 2’deki “Tahmini Gizli Sayıyla Karşılaştırmak” kısmında parse kullanarak bir String’i sayısal bir türe dönüştürdüğümüz zaman olduğu gibi birçok türün mümkün olduğu durumlarda, şu şekilde bir tür bildirimi eklemeliyiz:
#![allow(unused)]
fn main() {
let tahmin: u32 = "42".parse().expect("Bir sayı değil!");
}Önceki kodda gösterilen : u32 tür bildirimini eklemezsek, Rust aşağıdaki hatayı görüntüler; bu da derleyicinin hangi türü kullanmak istediğimizi bilmek için bizden daha fazla bilgiye ihtiyacı olduğu anlamına gelir:
$ cargo build
Compiling no_type_annotations v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/output-only-01-no-type-annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let tahmin = "42".parse().expect("Bir sayı değil!");
| ^^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `tahmin` an explicit type
|
2 | let tahmin: /* Type */ = "42".parse().expect("Bir sayı değil!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Diğer veri türleri için farklı tür bildirimleri göreceksiniz.
Skaler Türler (Scalar Types)
Bir skaler tür, tek bir değeri temsil eder. Rust’ın dört ana skaler türü vardır: tam sayılar (integers), kayan noktalı sayılar (floating-point numbers), Boolean’lar ve karakterler. Bunları diğer programlama dillerinden tanıyabilirsiniz. Rust’ta nasıl çalıştıklarına bir göz atalım.
Tam Sayı Türleri (Integer Types)
Bir tam sayı, kesirli bileşeni olmayan bir sayıdır. Bölüm 2’de bir tam sayı türü kullandık: u32 türü. Bu tür bildirimi, ilişkilendirildiği değerin 32 bitlik alan kaplayan işaretsiz (unsigned) bir tam sayı olması gerektiğini gösterir (işaretli (signed) tam sayı türleri u yerine i ile başlar). Tablo 3-1, Rust’taki yerleşik tam sayı türlerini gösterir. Bir tam sayı değerinin türünü bildirmek için bu varyantlardan (variants) herhangi birini kullanabiliriz.
Tablo 3-1: Rust’taki Tam Sayı Türleri
| Uzunluk | İşaretli | İşaretsiz |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| Mimariye bağlı | isize | usize |
Her varyant işaretli veya işaretsiz olabilir ve açık bir boyuta sahiptir. İşaretli ve işaretsiz terimleri, sayının negatif olmasının mümkün olup olmadığını ifade eder; diğer bir deyişle, sayının bir işaret alması gerekip gerekmediğini (işaretli) veya sadece pozitif olup bu nedenle işaretsiz olarak temsil edilip edilemeyeceğini (işaretsiz) belirtir. Tıpkı kağıt üzerine sayı yazmak gibidir: İşaret önemli olduğunda bir sayı artı veya eksi işaretiyle gösterilir; ancak sayının pozitif olduğunu varsaymak güvenliyse, herhangi bir işaret olmadan gösterilir. İşaretli sayılar ikiye tümleyen (two’s complement) temsili kullanılarak saklanır.
Her işaretli varyant −(2n − 1) ile 2n − 1 − 1 (dahil) arasında sayılar saklayabilir; buradaki n, o varyantın kullandığı bit sayısıdır. Dolayısıyla, bir i8, −(27) ile 27 − 1 arasında sayılar saklayabilir, bu da -128 ile 127 arasına eşittir. İşaretsiz varyantlar ise 0 ile 2n − 1 arasında sayılar saklayabilir, yani bir u8, 0 ile 28 − 1 arasında sayılar saklayabilir ki bu da 0 ile 255 arasına eşittir.
Ek olarak, isize ve usize türleri, programınızın çalıştığı bilgisayarın mimarisine bağlıdır: 64 bitlik bir mimarideyseniz 64 bit ve 32 bitlik bir mimarideyseniz 32 bittir.
Tam sayı sabitlerini (literals) Tablo 3-2’de gösterilen formlardan herhangi birinde yazabilirsiniz. Birden fazla sayısal tür olabilen sayı sabitlerinin, türü belirlemek için 57u8 gibi bir tür son ekine (suffix) izin verdiğini unutmayın. Sayı sabitleri, sayıyı okumayı kolaylaştırmak için görsel bir ayırıcı olarak _ kullanabilir; örneğin 1_000, 1000 belirtmişsiniz gibi aynı değere sahip olacaktır.
Tablo 3-2: Rust’taki Tam Sayı Sabitleri
| Sayı sabitleri | Örnek |
|---|---|
| Onluk (Decimal) | 98_222 |
| Onaltılık (Hex) | 0xff |
| Sekizlik (Octal) | 0o77 |
| İkilik (Binary) | 0b1111_0000 |
Bayt (sadece u8) | b'A' |
Peki hangi tür tam sayıyı kullanacağınızı nasıl bileceksiniz? Eğer emin değilseniz, Rust’ın varsayılanları genellikle başlamak için iyi yerlerdir: Tam sayı türleri varsayılan olarak i32’dir. isize veya usize kullanacağınız ana durum, bir çeşit koleksiyonu indekslediğiniz zamandır.
Tam Sayı Taşması (Integer Overflow)
Diyelim ki 0 ile 255 arasında değerler alabilen u8 türünde bir değişkeniniz var. Değişkeni bu aralığın dışındaki bir değere (örneğin 256’ya) değiştirmeye çalışırsanız, tam sayı taşması (integer overflow) meydana gelir ve bu da iki davranıştan biriyle sonuçlanabilir. Hata ayıklama modunda derleme yaptığınızda Rust, tam sayı taşması için kontroller içerir ve bu davranış gerçekleştiğinde programınızın çalışma zamanında panik yapmasına neden olur. Rust, bir program bir hatayla çıktığında (exits) panikleme (panicking) terimini kullanır; panikleri Bölüm 9’daki “panic! ile Kurtarılamaz Hatalar” kısmında daha derinlemesine tartışacağız.
--release bayrağıyla yayın (release) modunda derleme yaptığınızda, Rust paniğe neden olan tam sayı taşması kontrollerini içermez. Bunun yerine, taşma meydana gelirse Rust ikiye tümleyerek sarma (two’s complement wrapping) işlemi gerçekleştirir. Kısacası, türün alabileceği maksimum değerden daha büyük değerler, türün alabileceği değerlerin minimumuna “sarılır” (wrap around). Bir u8 durumunda, 256 değeri 0 olur, 257 değeri 1 olur ve bu böyle devam eder. Program panik yapmaz, ancak değişkenin muhtemelen olmasını beklediğiniz gibi olmayan bir değeri olur. Tam sayı taşmasının sarma davranışına güvenmek bir hata olarak kabul edilir.
Taşma olasılığını açıkça (explicitly) yönetmek için, ilkel sayısal türler için standart kütüphane tarafından sağlanan şu metot ailelerini kullanabilirsiniz:
wrapping_addgibiwrapping_*metotlarıyla tüm modlarda sarma.- Taşma varsa
checked_*metotlarıylaNonedeğerini döndürme. overflowing_*metotlarıyla değeri ve taşma olup olmadığını gösteren bir Boolean döndürme.saturating_*metotlarıyla değerin minimum veya maksimum değerlerinde doygunluğa ulaşma (saturate).
Kayan Noktalı (Floating-Point) Türler
Rust ayrıca ondalık noktaları olan kayan noktalı sayılar için iki ilkel (primitive) türe sahiptir. Rust’ın kayan noktalı türleri, sırasıyla 32 bit ve 64 bit boyutunda olan f32 ve f64’tür. Varsayılan tür f64’tür çünkü modern CPU’larda kabaca f32 ile aynı hızdadır ancak daha fazla hassasiyete (precision) sahiptir. Tüm kayan noktalı türler işaretlidir (signed).
İşte kayan noktalı sayıları iş başında gösteren bir örnek:
Dosya adı: src/main.rs
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}Kayan noktalı sayılar IEEE-754 standardına göre temsil edilir.
Sayısal İşlemler
Rust, tüm sayı türleri için beklediğiniz temel matematiksel işlemleri destekler: toplama, çıkarma, çarpma, bölme ve kalan (remainder). Tam sayı bölmesi (integer division) en yakın tam sayıya doğru (sıfıra doğru) keser (truncate). Aşağıdaki kod, let ifadesinde her bir sayısal işlemi nasıl kullanacağınızı gösterir:
Dosya adı: src/main.rs
fn main() {
// toplama
let toplam = 5 + 10;
// çıkarma
let fark = 95.5 - 4.3;
// çarpma
let carpim = 4 * 30;
// bölme
let bolum = 56.7 / 32.2;
let kesilmis = -5 / 3; // Results in -1
// kalan
let kalan = 43 % 5;
}Bu ifadelerdeki (statements) her bir ifade matematiksel bir operatör kullanır ve tek bir değere dönüşür (evaluates), bu değer daha sonra bir değişkene bağlanır. Ek B, Rust’ın sağladığı tüm operatörlerin bir listesini içerir.
Boolean Türü
Çoğu diğer programlama dilinde olduğu gibi, Rust’taki Boolean türünün iki olası değeri vardır: true ve false. Boolean’ların boyutu bir bayttır. Rust’taki Boolean türü bool kullanılarak belirtilir. Örneğin:
Dosya adı: src/main.rs
fn main() {
let t = true;
let f: bool = false; // with explicit type annotation
}Boolean değerlerini kullanmanın ana yolu if ifadesi gibi koşullu yapılardır (conditionals). if ifadelerinin Rust’ta nasıl çalıştığını “Kontrol Akışı” bölümünde ele alacağız.
Karakter (Character) Türü
Rust’ın char türü, dilin en temel alfabetik türüdür. İşte char değerlerini bildirmeye ilişkin bazı örnekler:
Dosya adı: src/main.rs
fn main() {
let c = 'z';
let z: char = 'ℤ'; // with explicit type annotation
let kalp_gozlu_kedi = '😻';
}Çift tırnak kullanan metin sabitlerinin (string literals) aksine, char sabitlerini tek tırnakla belirttiğimize dikkat edin. Rust’ın char türü 4 bayt boyutundadır ve bir Unicode skaler değerini temsil eder; bu da onun sadece ASCII’den çok daha fazlasını temsil edebileceği anlamına gelir. Aksanlı harfler; Çince, Japonca ve Korece karakterler; emojiler; ve sıfır genişlikli boşluklar (zero-width spaces) Rust’ta geçerli char değerleridir. Unicode skaler değerleri U+0000 ile U+D7FF ve U+E000 ile U+10FFFF (dahil) arasında değişir. Ancak, “karakter” aslında Unicode’da tam olarak karşılığı olan bir kavram değildir, dolayısıyla bir “karakterin” ne olduğuna dair insani sezginiz (intuition) Rust’taki bir char ile örtüşmeyebilir. Bu konuyu Bölüm 8’deki “Metinleri (Strings) Kullanarak UTF-8 Kodlu Metinleri Saklamak” kısmında ayrıntılı olarak tartışacağız.
Bileşik Türler (Compound Types)
Bileşik türler birden fazla değeri tek bir türde gruplayabilir. Rust’ın iki ilkel bileşik türü vardır: tuple’lar ve array’ler (diziler).
Tuple Türü
Bir tuple, çeşitli türlere sahip bir dizi değeri tek bir bileşik türde (compound type) bir arada gruplamanın genel bir yoludur. Tuple’ların sabit bir uzunluğu vardır: Bir kez bildirildiklerinde boyutları büyüyemez veya küçülemez.
Değerlerin virgülle ayrılmış bir listesini parantez içine yazarak bir tuple oluştururuz. Tuple’daki her pozisyonun (konum) bir türü vardır ve tuple’daki farklı değerlerin türlerinin aynı olması gerekmez. Bu örnekte isteğe bağlı tür bildirimleri ekledik:
Dosya adı: src/main.rs
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}Bir tuple tek bir bileşik eleman olarak kabul edildiği için tup değişkeni tüm tuple’a bağlanır (binds). Bireysel değerleri tuple’dan çıkarmak için, bir tuple değerini parçalamak (destructure) amacıyla desen eşleştirmeyi şu şekilde kullanabiliriz:
Dosya adı: src/main.rs
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("y'nin değeri: {y}");
}Bu program önce bir tuple oluşturur ve onu tup değişkenine bağlar. Daha sonra tup’ı alıp onu üç ayrı değişkene (x, y ve z) dönüştürmek için let ile birlikte bir desen kullanır. Tek bir tuple’ı üç parçaya böldüğü için buna parçalama (destructuring) denir. Son olarak program, 6.4 olan y değerini yazdırır.
Bir tuple elemanına doğrudan bir nokta (.) ve ardından erişmek istediğimiz değerin indeksini (index) kullanarak da erişebiliriz. Örneğin:
Dosya adı: src/main.rs
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let bes_yuz = x.0;
let alti_nokta_dort = x.1;
let bir = x.2;
}Bu program x tuple’ını oluşturur ve daha sonra kendi indekslerini kullanarak tuple’ın her bir elemanına erişir. Çoğu programlama dilinde olduğu gibi, tuple’daki ilk indeks 0’dır.
Hiçbir değere sahip olmayan tuple’ın özel bir adı vardır, birim (unit). Bu değer ve onun karşılık gelen türü de () olarak yazılır ve boş bir değeri veya boş bir dönüş türünü temsil eder. İfadeler (expressions), başka bir değer döndürmezlerse kapalı olarak (implicitly) birim değerini döndürürler.
Array (Dizi) Türü
Birden fazla değere sahip bir koleksiyon oluşturmanın başka bir yolu da array (dizi) kullanmaktır. Bir tuple’dan farklı olarak, bir array’in her elemanı aynı türde olmalıdır. Diğer bazı dillerdeki array’lerin aksine, Rust’taki array’lerin sabit bir uzunluğu vardır.
Bir array’deki değerleri köşeli parantezler içinde virgülle ayrılmış bir liste olarak yazarız:
Dosya adı: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
}Array’ler, verilerinizin şimdiye kadar gördüğümüz diğer türlerdeki gibi heap (yığın) alanı yerine stack (yığıt) üzerinde tahsis edilmesini (allocated) istediğinizde (Bölüm 4’te stack ve heap’i daha ayrıntılı tartışacağız) veya her zaman sabit sayıda elemana sahip olduğunuzdan emin olmak istediğinizde kullanışlıdır. Ancak bir array, bir vektör (vector) türü kadar esnek değildir. Bir vektör, standart kütüphane tarafından sağlanan ve boyutu büyüyebilen veya küçülebilen benzer bir koleksiyon türüdür çünkü içeriği heap üzerinde yaşar. Array mi yoksa vektör mü kullanacağınızdan emin değilseniz, büyük olasılıkla bir vektör kullanmalısınız. Bölüm 8 vektörleri daha detaylı tartışır.
Bununla birlikte, eleman sayısının değişmeyeceğini bildiğiniz durumlarda array’ler daha kullanışlıdır. Örneğin, bir programda ayların isimlerini kullanıyor olsaydınız, her zaman 12 eleman içereceğini bildiğiniz için muhtemelen bir vektör yerine bir array kullanırdınız:
#![allow(unused)]
fn main() {
let aylar = ["Ocak", "Şubat", "Mart", "Nisan", "Mayıs", "Haziran", "Temmuz",
"Ağustos", "Eylül", "Ekim", "Kasım", "Aralık"];
}Bir array’in türünü yazarken köşeli parantezler içinde her bir elemanın türünü, ardından noktalı virgül ve dizideki eleman sayısını şu şekilde yazarsınız:
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}Burada, her elemanın türü i32’dir. Noktalı virgülden sonra gelen 5 sayısı, dizinin beş eleman içerdiğini belirtir.
Her bir eleman için aynı değere sahip bir array’i şu şekilde başlatabilirsiniz: önce başlangıç değerini, ardından bir noktalı virgülü ve ardından köşeli parantezler içindeki dizinin uzunluğunu belirtebilirsiniz:
#![allow(unused)]
fn main() {
let a = [3; 5];
}a adındaki dizi, başlangıçta tamamı 3 değerine ayarlanacak olan 5 eleman içerecektir. Bu, let a = [3, 3, 3, 3, 3]; yazmakla aynı şeydir ancak daha kısa bir yoldur.
Array Elemanlarına Erişim
Bir array, stack üzerinde tahsis edilebilen bilinen, sabit boyutlu tek bir bellek yığınıdır (chunk of memory). İndekslemeyi kullanarak array elemanlarına şu şekilde erişebilirsiniz:
Dosya adı: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
let ilk = a[0];
let ikinci = a[1];
}Bu örnekte, ilk adındaki değişken dizideki [0] indeksindeki değer olduğu için 1 değerini alacaktır. ikinci adındaki değişken dizideki [1] indeksinden 2 değerini alacaktır.
Geçersiz Array Elemanlarına Erişim (Invalid Array Element Access)
Bir array’in sonundan daha ileri bir noktasındaki (past the end of the array) bir elemanına erişmeye çalışırsanız ne olacağına bakalım. Kullanıcıdan bir array indeksi almak için Bölüm 2’deki tahmin oyununa benzer şekilde bu kodu çalıştırdığınızı varsayalım:
Dosya adı: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Lütfen bir dizi indeksi girin.");
let mut indeks = String::new();
io::stdin()
.read_line(&mut indeks)
.expect("Satırı okuyamadı!");
let indeks: usize = indeks
.trim()
.parse()
.expect("Girilen indeks bir sayi değildi!");
let element = a[indeks];
println!("{indeks} indeksindeki elemanın değeri: {element}");
}Bu kod başarıyla derlenir. Bu kodu cargo run komutunu kullanarak çalıştırırsanız ve 0, 1, 2, 3 veya 4 değerlerinden birini girerseniz, program array’deki o indekse karşılık gelen değeri yazdıracaktır. Eğer dizinin sonunu geçen bir sayı (örneğin 10) girerseniz, şöyle bir çıktı göreceksiniz:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Program, indeksleme işleminde geçersiz bir değer kullanıldığı noktada bir çalışma zamanı hatası verdi. Program bir hata mesajıyla kapandı ve son println! ifadesini çalıştırmadı. İndekslemeyi kullanarak bir elemana erişmeye çalıştığınızda Rust, belirttiğiniz indeksin dizi uzunluğundan daha az olup olmadığını kontrol edecektir. İndeks dizi uzunluğundan büyük veya ona eşitse, Rust paniğe neden olur. Bu kontrolün çalışma zamanında gerçekleşmesi gerekir, özellikle de bu durumda, çünkü derleyicinin bir kullanıcının kodu çalıştırdığında ne değer gireceğini bilmesi imkansızdır.
Bu, Rust’ın bellek güvenliği prensiplerinin iş başındaki bir örneğidir. Birçok alt seviye dilde bu tür bir kontrol yapılmaz ve yanlış bir indeks sağladığınızda geçersiz belleğe erişilebilir. Rust, bellek erişimine izin verip devam etmek yerine hemen programdan çıkarak sizi bu tür hatalara karşı korur. Bölüm 9, Rust’ın hata yönetimini ve panik yaratmayan ya da geçersiz bellek erişimine izin vermeyen okunabilir, güvenli kodu nasıl yazabileceğinizi daha ayrıntılı tartışacaktır.
Fonksiyonlar
Fonksiyonlar
Fonksiyonlar Rust kodunda çok yaygındır. Dildeki en önemli fonksiyonlardan birini zaten gördünüz: birçok programın giriş noktası olan main fonksiyonu. Ayrıca, yeni fonksiyonlar bildirmenizi sağlayan fn anahtar kelimesini de gördünüz.
Rust kodu, fonksiyon ve değişken isimleri için geleneksel stil olarak snake_case (yılan stili) kullanır; bu stilde tüm harfler küçüktür ve kelimeler alt çizgiyle ayrılır. İşte örnek bir fonksiyon tanımı içeren bir program:
Dosya adı: src/main.rs
fn main() {
println!("Merhaba, dünya!");
baska_bir_fonksiyon();
}
fn baska_bir_fonksiyon() {
println!("Baska bir fonksiyon.");
}Rust’ta bir fonksiyonu, fn ifadesini, ardından fonksiyon adını ve bir çift parantezi yazarak tanımlarız. Süslü parantezler, derleyiciye fonksiyon gövdesinin nerede başlayıp nerede bittiğini söyler.
Tanımladığımız herhangi bir fonksiyonu, adını ve ardından bir çift parantez yazarak çağırabiliriz. baska_bir_fonksiyon programda tanımlandığı için main fonksiyonunun içinden çağrılabilir. baska_bir_fonksiyon’u kaynak kodunda main fonksiyonundan sonra tanımladığımıza dikkat edin; ondan önce de tanımlayabilirdik. Rust, fonksiyonlarınızı nerede tanımladığınızla ilgilenmez, yalnızca çağırıcı tarafından görülebilen bir kapsamda bir yerlerde tanımlanmış olmalarına bakar.
Fonksiyonları daha fazla keşfetmek için fonksiyonlar adında yeni bir ikili proje başlatalım. baska_bir_fonksiyon örneğini src/main.rs dosyasına yerleştirin ve çalıştırın. Aşağıdaki çıktıyı görmelisiniz:
$ cargo run
Compiling functions v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-16-functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/functions`
Merhaba, dünya!
Baska bir fonksiyon.
Satırlar, main fonksiyonunda göründükleri sıraya göre çalıştırılır. Önce “Merhaba, dünya!” mesajı yazdırılır ve ardından baska_bir_fonksiyon çağrılır ve onun mesajı yazdırılır.
Parametreler
Fonksiyonları, bir fonksiyonun imzasının bir parçası olan özel değişkenler olan parametreleri olacak şekilde tanımlayabiliriz. Bir fonksiyonun parametreleri olduğunda, o parametreler için fonksiyona somut (concrete) değerler sağlayabilirsiniz. Teknik olarak, somut değerlere argümanlar denir, ancak günlük konuşmada insanlar parametre ve argüman kelimelerini bir fonksiyonun tanımındaki değişkenler veya bir fonksiyonu çağırdığınızda iletilen somut değerler için birbirinin yerine kullanma eğilimindedir.
baska_bir_fonksiyon’un bu versiyonunda bir parametre ekliyoruz:
Dosya adı: src/main.rs
fn main() {
baska_bir_fonksiyon(5);
}
fn baska_bir_fonksiyon(x: i32) {
println!("x'in değeri: {x}");
}Bu programı çalıştırmayı deneyin; aşağıdaki çıktıyı almalısınız:
$ cargo run
Compiling functions v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-17-functions-with-parameters)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/functions`
x'in değeri: 5
baska_bir_fonksiyon bildiriminin x adında bir parametresi vardır. x’in türü i32 olarak belirtilmiştir. baska_bir_fonksiyon’a 5 değerini verdiğimizde, println! makrosu 5’i, biçim dizisinde (format string) x içeren süslü parantez çiftinin bulunduğu yere koyar.
Fonksiyon imzalarında, her parametrenin türünü mutlaka bildirmelisiniz. Bu, Rust’ın tasarımında alınmış bilinçli bir karardır: Fonksiyon tanımlarında tür bildirimi gerektirmek, derleyicinin kodun başka bir yerinde ne tür bir veri demek istediğinizi anlamak için bu bildirimleri kullanmanıza neredeyse hiç ihtiyaç duymayacağı anlamına gelir. Derleyici ayrıca, fonksiyonun hangi türleri beklediğini bilirse daha yararlı hata mesajları da verebilir.
Birden fazla parametre tanımlarken, parametre bildirimlerini şu şekilde virgüllerle ayırın:
Dosya adı: src/main.rs
fn main() {
etiketli_olcum_yazdir(5, 'h');
}
fn etiketli_olcum_yazdir(deger: i32, birim_etiketi: char) {
println!("Ölçüm değeri: {deger}{birim_etiketi}");
}Bu örnek, iki parametreye sahip etiketli_olcum_yazdir adında bir fonksiyon oluşturur. İlk parametre deger olarak adlandırılır ve bir i32’dir. İkincisi birim_etiketi (unit_label) olarak adlandırılır ve char türündedir. Fonksiyon daha sonra hem deger hem de birim_etiketi’ni içeren bir metin yazdırır.
Hadi bu kodu çalıştırmayı deneyelim. fonksiyonlar projenizin src/main.rs dosyasında bulunan mevcut programı yukarıdaki örnekle değiştirin ve cargo run komutunu kullanarak çalıştırın:
$ cargo run
Compiling functions v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-18-functions-with-multiple-parameters)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/functions`
Ölçüm değeri: 5h
Fonksiyonu deger için 5 ve birim_etiketi için 'h' ile çağırdığımız için, program çıktısı bu değerleri içerir.
İfadeler (Statements) ve İbareler (Expressions)
Fonksiyon gövdeleri, isteğe bağlı olarak bir ibare ile biten bir dizi ifadeden (statements) oluşur. Şimdiye kadar ele aldığımız fonksiyonlar bitirici bir ibare (ending expression) içermiyordu, ancak bir ifadenin bir parçası olarak bir ibare gördünüz. Rust ibare tabanlı bir dil olduğu için, bu anlaşılması gereken önemli bir ayrımdır. Diğer dillerin aynı ayrımları yoktur, bu yüzden ifadelerin ve ibarelerin ne olduğuna ve farklılıklarının fonksiyonların gövdelerini nasıl etkilediğine bir bakalım.
- İfadeler (Statements), bir eylem gerçekleştiren ancak bir değer döndürmeyen talimatlardır.
- İbareler (Expressions) ise bir değer üretecek şekilde hesaplanan kod parçalarıdır.
Bazı örneklere bakalım.
Aslında daha önce de ifadeler (statements) ve ibareler (expressions) kullandık. Bir değişken oluşturmak ve let anahtar kelimesiyle ona bir değer atamak bir ifadedir. Liste 3-1’de, let y = 6; bir ifadedir.
fn main() {
let y = 6;
}main fonksiyonu bildirimiFonksiyon tanımları da ifadelerdir; önceki örneğin tamamı başlı başına bir ifadedir. (Kısaca göreceğimiz gibi, bir fonksiyon çağırmak bir ifade (statement) değildir.)
İfadeler (statements) değer döndürmezler. Bu nedenle, aşağıdaki kodun yapmaya çalıştığı gibi bir let ifadesini başka bir değişkene atayamazsınız; bir hata alırsınız:
Dosya adı: src/main.rs
fn main() {
let x = (let y = 6);
}Bu programı çalıştırdığınızda alacağınız hata şu şekilde görünecektir:
$ cargo run
Compiling functions v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-19-statements-vs-expressions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` (part of `#[warn(unused)]`) on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6 ;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
let y = 6 ifadesi bir değer döndürmez, bu yüzden x’in bağlanacağı bir şey yoktur. Bu durum, atamanın (assignment) atamanın kendi değerini döndürdüğü C ve Ruby gibi diğer dillerde olanlardan farklıdır. Bu dillerde, x = y = 6 yazarak hem x hem de y’nin 6 değerine sahip olmasını sağlayabilirsiniz; Rust’ta ise durum böyle değildir.
İbareler (Expressions) ise bir değere dönüşür ve Rust’ta yazacağınız kodun büyük bir bölümünü oluştururlar. Örneğin 5 + 6 gibi, 11 değerini üreten matematiksel bir işlemi (ibareyi) ele alalım. İbareler, ifadelerin parçası olabilir: Liste 3-1’de, let y = 6; ifadesindeki 6, 6 değerini üreten bir ibaredir. Bir fonksiyonu çağırmak bir ibaredir. Bir makroyu çağırmak bir ibaredir. Süslü parantezlerle oluşturulan yeni bir kapsam bloğu da bir ibaredir, örneğin:
Dosya adı: src/main.rs
fn main() {
let y = {
let x = 3;
x + 1
};
println!("y'nin değeri: {y}");
}Şu ibare:
{
let x = 3;
x + 1
}Bu örnekte 4 değerini üreten (evaluates) bir bloktur. Bu değer, let ifadesinin bir parçası olarak y’ye bağlanır. x + 1 satırının sonunda, şimdiye kadar gördüğünüz çoğu satırın aksine noktalı virgül (;) olmadığına dikkat edin. İbarelerin (expressions) sonunda noktalı virgül bulunmaz. Bir ibarenin sonuna noktalı virgül eklerseniz, onu bir ifadeye (statement) dönüştürürsünüz ve bu durumda bir değer döndürmez. Sırada, fonksiyonların dönüş değerlerini (return values) ve ibareleri incelerken bunu aklınızda bulundurun.
Dönüş Değerleri Olan Fonksiyonlar (Functions with Return Values)
Fonksiyonlar, kendilerini çağıran koda değerler döndürebilirler. Dönüş değerlerini adlandırmayız, ancak türlerini bir ok işaretinden (->) sonra bildirmemiz (declare) gerekir. Rust’ta, bir fonksiyonun dönüş değeri, fonksiyonun gövdesinin bloğundaki son ibarenin değeriyle eş anlamlıdır. return anahtar kelimesini kullanarak ve bir değer belirterek bir fonksiyondan erkenden dönebilirsiniz (return early), ancak çoğu fonksiyon son ibareyi örtük olarak (implicitly) döndürür. İşte bir değer döndüren bir fonksiyon örneği:
Dosya adı: src/main.rs
fn bes() -> i32 {
5
}
fn main() {
let x = bes();
println!("x'in değeri: {x}");
}bes (five) fonksiyonunun içinde hiçbir fonksiyon çağrısı, makro ve hatta let ifadesi (statement) yoktur—sadece 5 sayısı vardır. Bu, Rust’ta tamamen geçerli bir fonksiyondur. Fonksiyonun dönüş türünün de -> i32 olarak belirtildiğine dikkat edin. Bu kodu çalıştırmayı deneyin; çıktı şu şekilde görünmelidir:
$ cargo run
Compiling functions v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-21-function-return-values)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/functions`
x'in değeri: 5
bes fonksiyonundaki 5, fonksiyonun dönüş değeridir ve bu yüzden dönüş türü i32’dir. Bunu biraz daha detaylı inceleyelim. İki önemli kısım vardır: İlk olarak, let x = bes(); satırı bir değişkeni başlatmak (initialize) için bir fonksiyonun dönüş değerini kullandığımızı gösterir. bes fonksiyonu 5 döndürdüğü için, bu satır şununla aynıdır:
#![allow(unused)]
fn main() {
let x = 5;
}İkincisi, bes fonksiyonunun hiçbir parametresi yoktur ve dönüş değerinin türünü tanımlar, ancak fonksiyonun gövdesi, döndürmek istediğimiz değere sahip bir ibare olduğu için, noktalı virgülü olmayan yalnız bir 5’tir.
Başka bir örneğe bakalım:
Dosya adı: src/main.rs
fn main() {
let x = arti_bir(5);
println!("x'in değeri: {x}");
}
fn arti_bir(x: i32) -> i32 {
x + 1
}Bu kod çalıştırıldığında x'in değeri: 6 (The value of x is: 6) yazdıracaktır. Peki x + 1 içeren satırın sonuna bir noktalı virgül koyarsak ve onu bir ibareden bir ifadeye (statement) çevirirsek ne olur?
Dosya adı: src/main.rs
fn main() {
let x = arti_bir(5);
println!("x'in değeri: {x}");
}
fn arti_bir(x: i32) -> i32 {
x + 1;
}Bu kodu derlemek aşağıdaki gibi bir hata üretecektir:
$ cargo run
Compiling functions v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-23-statements-dont-return-values)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn arti_bir(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Ana hata mesajı olan mismatched types (uyumsuz türler), bu kodun temel sorununu ortaya koyar. arti_bir (plus_one) fonksiyonunun tanımı bir i32 döndüreceğini söyler, ancak ifadeler (statements) bir değer üretmez; bu durum birim türü olan () ile ifade edilir. Bu nedenle, hiçbir şey döndürülmez, bu da fonksiyon tanımıyla çelişir ve bir hataya neden olur. Bu çıktıda Rust, muhtemelen bu sorunu düzeltmeye yardımcı olacak bir mesaj sağlar: Noktalı virgülün kaldırılmasını önerir, ki bu da hatayı düzeltecektir.
Yorumlar
Yorumlar
Tüm programcılar kodlarının kolay anlaşılır olması için çaba gösterir, ancak bazen fazladan açıklamaya gerek duyulur. Bu gibi durumlarda programcılar, kaynak kodlarına derleyicinin (compiler) görmezden geleceği, ancak kaynak kodunu okuyan kişilerin yararlı bulabileceği yorumlar (comments) bırakırlar.
İşte basit bir yorum:
#![allow(unused)]
fn main() {
// merhaba, dünya
}Rust’ta, geleneksel yorum stili, bir yoruma iki eğik çizgi (slash) ile başlar ve yorum satır sonuna kadar devam eder. Tek bir satırı aşan yorumlar için, şu şekilde her satıra // eklemeniz gerekecektir:
#![allow(unused)]
fn main() {
// Burada çok karmaşık bir şey yapıyoruz, o kadar uzun ki
// bunu yapmak için birden fazla yorum satırına ihtiyacımız var! Vay canına!
// Umarım bu yorum neler olup bittiğini açıklar.
}Yorumlar, kod içeren satırların sonuna da yerleştirilebilir:
Dosya adı: src/main.rs
fn main() {
let sanli_sayi = 7; // I'm feeling lucky today
}Ancak yorumların daha çok bu formatta, yani not düştüğü kodun üstünde ayrı bir satırda kullanıldığını göreceksiniz:
Dosya adı: src/main.rs
fn main() {
// Bugün kendimi şanslı hissediyorum.
let sansli_sayi = 7;
}Rust’ın ayrıca Bölüm 14’teki “Crates.io’da Crate Yayınlamak” kısmında tartışacağımız dokümantasyon yorumları (documentation comments) adında başka bir yorum türü daha vardır.
Kontrol Akışı
Kontrol Akışı (Control Flow)
Bir koşulun true (doğru) olup olmadığına bağlı olarak bazı kodları çalıştırabilme veya bir koşul true olduğu sürece bazı kodları tekrar tekrar çalıştırabilme yeteneği, çoğu programlama dilinde temel yapı taşlarıdır. Rust kodunun yürütme akışını kontrol etmenizi sağlayan en yaygın yapılar if ifadeleri ve döngülerdir (loops).
if İfadeleri (Expressions)
Bir if ifadesi, koşullara bağlı olarak kodunuzu dallandırmanıza (branch) olanak tanır. Bir koşul sağlarsınız ve ardından, “Eğer bu koşul karşılanırsa, bu kod bloğunu çalıştır. Eğer koşul karşılanmazsa, bu kod bloğunu çalıştırma” dersiniz.
if ifadesini keşfetmek için projects dizininizde dallanmalar (branches) adında yeni bir proje oluşturun. src/main.rs dosyasına aşağıdakini girin:
Dosya adı: src/main.rs
fn main() {
let sayi = 3;
if sayi < 5 {
println!("koşul doğru");
} else {
println!("koşul yanlış");
}
}Tüm if ifadeleri if anahtar kelimesiyle başlar ve ardından bir koşul gelir. Bu durumda koşul, sayi (number) değişkeninin 5’ten küçük bir değere sahip olup olmadığını kontrol eder. Koşul true (doğru) ise çalıştırılacak kod bloğunu, hemen koşuldan sonra süslü parantezler içine yerleştiririz. if ifadelerindeki koşullarla ilişkili kod bloklarına bazen Bölüm 2’nin “Tahmini Gizli Sayıyla Karşılaştırmak” kısmında tartıştığımız match ifadelerindeki kollar gibi kollar (arms) denir.
İsteğe bağlı olarak (ki burada yapmayı seçtik), koşulun false (yanlış) çıkması durumunda programa çalıştırılması için alternatif bir kod bloğu vermek üzere bir else ifadesi de ekleyebiliriz. Eğer bir else ifadesi sağlamazsanız ve koşul false ise, program sadece if bloğunu atlar ve bir sonraki kod parçasına geçer.
Bu kodu çalıştırmayı deneyin; aşağıdaki çıktıyı görmelisiniz:
$ cargo run
Compiling branches v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-26-if-true)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/branches`
koşul doğru
Ne olacağını görmek için sayi değişkeninin değerini koşulu false yapacak bir değerle değiştirmeyi deneyelim:
fn main() {
let sayi = 7;
if sayi < 5 {
println!("koşul doğru");
} else {
println!("koşul yanlış");
}
}Programı tekrar çalıştırın ve çıktıya bakın:
$ cargo run
Compiling branches v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-27-if-false)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/branches`
koşul yanlış
Ayrıca bu koddaki koşulun mutlaka bir bool (Boolean) olması gerektiğini de belirtmekte fayda var. Eğer koşul bir bool değilse bir hata alırız. Örneğin, şu kodu çalıştırmayı deneyin:
Dosya adı: src/main.rs
fn main() {
let sayi = 3;
if sayi {
println!("sayi'nın değeri üç");
}
}if koşulu bu sefer 3 değerini üretiyor ve Rust bir hata fırlatıyor:
$ cargo run
Compiling branches v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-28-if-condition-must-be-bool)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if sayi {
| ^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Hata, Rust’ın bir bool beklediğini ancak bir tam sayı aldığını gösterir. Ruby ve JavaScript gibi dillerin aksine Rust, Boolean olmayan türleri otomatik olarak bir Boolean’a dönüştürmeye çalışmaz. Açık olmalısınız ve if’e koşul olarak her zaman bir Boolean sağlamalısınız. Örneğin if kod bloğunun yalnızca bir sayı 0’a eşit olmadığında çalışmasını istiyorsak, if ifadesini şu şekilde değiştirebiliriz:
Dosya adı: src/main.rs
fn main() {
let sayi = 3;
if sayi != 0 {
println!("Sayi sıfırdan farklı bir şeydi.");
}
}Bu kodu çalıştırmak sayı sıfırdan farklı bir şeydi (number was something other than zero) yazdıracaktır.
else if İle Birden Fazla Koşulu Ele Almak
if ve else’i bir else if ifadesinde birleştirerek birden fazla koşul kullanabilirsiniz. Örneğin:
Dosya adı: src/main.rs
fn main() {
let sayi = 6;
if sayi % 4 == 0 {
println!("sayi 4'e bölünebilir");
} else if sayi % 3 == 0 {
println!("sayi 3'e bölünebilir");
} else if sayi % 2 == 0 {
println!("sayi 2'ye bölünebilir");
} else {
println!("sayi 4'e, 3'e veya 2'ye bölünemez");
}
}Bu programın izleyebileceği dört olası yol vardır. Çalıştırdıktan sonra aşağıdaki çıktıyı görmelisiniz:
$ cargo run
Compiling branches v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-30-else-if)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/branches`
sayi 3'e bölünebilir
Bu program çalıştığında, her bir if ifadesini sırayla kontrol eder ve koşulun true olduğu ilk gövdeyi çalıştırır. 6 sayısının 2’ye bölünebilmesine rağmen, sayı 2'ye bölünebilir (number is divisible by 2) çıktısını ya da else bloğundan gelen sayı 4'e, 3'e veya 2'ye bölünemez (number is not divisible by 4, 3, or 2) metnini görmediğimize dikkat edin. Bunun nedeni, Rust’ın bloğu yalnızca true olan ilk koşul için çalıştırmasıdır ve bir tane bulduğunda geri kalanları kontrol dahi etmez.
Çok fazla else if ifadesi kullanmak kodunuzu karmaşıklaştırabilir, bu nedenle birden fazla varsa kodunuzu yeniden yapılandırmak isteyebilirsiniz. Bölüm 6, bu tür durumlar için match adında güçlü bir Rust dallanma yapısını açıklamaktadır.
Bir let İfadesinde (Statement) if Kullanmak
if bir ibare olduğundan, Liste 3-2’de olduğu gibi sonucunu bir değişkene atamak (assign) için onu bir let ifadesinin sağ tarafında kullanabiliriz.
fn main() {
let durum = true;
let sayi = if durum { 5 } else { 6 };
println!("sayi'nin değeri: {sayi}");
}if ibaresinin sonucunu bir değişkene atamaksayi değişkeni, if ifadesinin sonucuna bağlı olarak bir değere bağlanacaktır (bound). Ne olduğunu görmek için bu kodu çalıştırın:
$ cargo run
Compiling branches v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/listing-03-02)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/branches`
sayi'nin değeri: 5
Kod bloklarının, içlerindeki son ibarenin değerine dönüştüğünü ve sayıların da kendi başlarına birer ibare olduğunu unutmayın. Bu durumda, tüm if ifadesinin değeri hangi kod bloğunun çalıştırıldığına bağlıdır. Bu da if’in her bir kolundan (arm) sonuç olma potansiyeline sahip olan değerlerin aynı türde olması gerektiği anlamına gelir; Liste 3-2’de hem if kolunun hem de else kolunun sonuçları i32 tam sayılarıydı. Eğer türler uyumsuzsa (mismatched), aşağıdaki örnekte olduğu gibi bir hata alırız:
Dosya adı: src/main.rs
fn main() {
let durum = true;
let sayi = if durum { 5 } else { "altı" };
println!("sayi'nin değeri: {sayi}");
}Bu kodu derlemeye çalıştığımızda bir hata alırız. if ve else kollarının uyumsuz değer türleri vardır ve Rust, sorunun programda tam olarak nerede bulunacağını gösterir:
$ cargo run
Compiling branches v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-31-arms-must-return-same-type)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:42
|
4 | let sayi = if condition { 5 } else { "altı" };
| - ^^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
if bloğundaki ibare bir tam sayı üretirken, else bloğundaki ibare bir metin (string) üretir. Bu işe yaramaz, çünkü değişkenler tek bir türe sahip olmalıdır ve Rust’ın derleme zamanında sayi değişkeninin hangi türde olduğunu kesin olarak bilmesi gerekir. sayi’nin türünü bilmek, derleyicinin sayi’yi kullandığımız her yerde türün geçerli olduğunu doğrulamasını sağlar. sayi’nin türü yalnızca çalışma zamanında belirlenirse Rust bunu yapamazdı; derleyicinin herhangi bir değişken için birden fazla varsayımsal türü izlemesi gerekseydi, derleyici daha karmaşık olurdu ve kod hakkında daha az garanti verebilirdi.
Döngülerle (Loops) Tekrar
Bir kod bloğunu birden fazla kez çalıştırmak genellikle faydalıdır. Bu görev için Rust, döngü gövdesindeki kodu sonuna kadar çalıştıracak ve ardından hemen tekrar başa dönecek çeşitli döngüler (loops) sağlar. Döngülerle denemeler yapmak için donguler (loops) adında yeni bir proje oluşturalım.
Rust’ın üç çeşit döngüsü vardır: loop, while ve for. Her birini deneyelim.
loop İle Kodu Tekrarlamak
loop anahtar kelimesi, Rust’a bir kod bloğunu sonsuza kadar veya siz onu açıkça durdurana kadar tekrar tekrar çalıştırmasını söyler.
Bir örnek olarak, donguler dizininizdeki src/main.rs dosyasını şu şekilde görünecek biçimde değiştirin:
Dosya adı: src/main.rs
fn main() {
loop {
println!("tekrar!");
}
}Bu programı çalıştırdığımızda, programı manuel olarak durdurana kadar sürekli olarak tekrar! (again!) yazdırıldığını göreceğiz. Çoğu terminal, sürekli bir döngüde sıkışmış bir programı kesintiye uğratmak (interrupt) için ctrl-C klavye kısayolunu destekler. Bir deneyin:
$ cargo run
Compiling donguler v0.1.0 (file:///projects/donguler)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/donguler`
tekrar!
tekrar!
tekrar!
tekrar!
^Ctekrar!
^C sembolü, ctrl-C tuşlarına bastığınız yeri temsil eder.
Kesme (interrupt) sinyalini aldığında kodun döngünün neresinde olduğuna bağlı olarak, ^C’den sonra tekrar! kelimesinin yazdırıldığını görebilir veya görmeyebilirsiniz.
Neyse ki Rust, kodu kullanarak bir döngüden çıkmanın bir yolunu da sağlar. Programa döngüyü yürütmeyi ne zaman durduracağını söylemek için döngünün içine break (kır) anahtar kelimesini yerleştirebilirsiniz. Bölüm 2’nin “Doğru Tahminden Sonra Çıkmak” kısmındaki tahmin oyununda, kullanıcı doğru sayıyı tahmin edip oyunu kazandığında programdan çıkmak için bunu yaptığımızı hatırlayın.
Tahmin oyununda ayrıca continue (devam et) kullandık, bu kelime bir döngü içinde programa o döngü adımındaki (iteration) geri kalan tüm kodu atlamasını ve bir sonraki adıma (iteration) geçmesini söyler.
Döngülerden Değer Döndürmek
loop’un kullanım alanlarından biri, bir iş parçacığının işini tamamlayıp tamamlamadığını kontrol etmek gibi, başarısız olabileceğini bildiğiniz bir işlemi yeniden denemektir. Ayrıca bu işlemin sonucunu döngüden çıkarıp kodunuzun geri kalanına aktarmanız gerekebilir. Bunu yapmak için, döngüyü durdurmak amacıyla kullandığınız break ifadesinden sonra döndürülmesini istediğiniz değeri ekleyebilirsiniz; burada gösterildiği gibi, bu değer daha sonra kullanabilmeniz için döngüden dışarı döndürülecektir:
fn main() {
let mut sayac = 0;
let sonuc = loop {
sayac += 1;
if sayac == 10 {
break sayac * 2;
}
};
println!("sonuc değeri: {sonuc}");
}Döngüden önce, sayac (counter) adında bir değişken bildiriyor ve onu 0’a ayarlıyoruz. Sonra, döngüden dönen değeri tutması için sonuc (result) adında bir değişken bildiriyoruz. Döngünün her adımında (iteration) sayac değişkenine 1 ekliyor ve ardından sayac’ın 10’a eşit olup olmadığını kontrol ediyoruz. Eşit olduğunda, break anahtar kelimesini sayac * 2 değeriyle kullanıyoruz. Döngüden sonra, sonuc değişkenine değer atayan ifadeyi (statement) sonlandırmak için bir noktalı virgül kullanıyoruz. Son olarak sonuc değişkenindeki değeri yazdırıyoruz, ki bu örnekte bu 20’dir.
Bir döngünün içinden de return (dön) yapabilirsiniz. break yalnızca mevcut (içinde bulunulan) döngüden çıkarken, return her zaman mevcut fonksiyondan çıkar.
Döngü Etiketleri (Loop Labels) ile Belirsizliği Gidermek
Eğer iç içe geçmiş döngüleriniz varsa, break ve continue o noktadaki en içteki (innermost) döngüye uygulanır. İsteğe bağlı olarak bir döngüde bir döngü etiketi (loop label) belirtebilirsiniz; daha sonra bu etiketi break veya continue ile kullanarak bu anahtar kelimelerin en içteki döngü yerine etiketlenmiş döngüye uygulanacağını belirtebilirsiniz. Döngü etiketleri tek bir tırnak (single quote) ile başlamalıdır. İşte içi içe iki döngü içeren bir örnek:
fn main() {
let mut ileri_sayim = 0;
'yukari_sayma: loop {
println!("İleri ayım = {ileri_sayim}");
let mut geri_sayim = 10;
loop {
println!("Geri sayım = {geri_sayim}");
if geri_sayim == 9 {
break;
}
if ileri_sayim == 2 {
break 'yukari_sayma;
}
geri_sayim -= 1;
}
ileri_sayim += 1;
}
println!("Son İlerleme = {ileri_sayim}");
}Dıştaki döngü 'yukari_sayma ('counting_up) etiketine sahiptir ve 0’dan 2’ye kadar yukarı sayacaktır. Etiketi olmayan içteki döngü ise 10’dan 9’a kadar geriye sayar. Etiket belirtmeyen ilk break sadece iç döngüden çıkacaktır. break 'yukari_sayma; ifadesi ise dış döngüden çıkacaktır. Bu kod şunu yazdırır:
$ cargo run
Compiling loops v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/no-listing-32-5-loop-labels)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.06s
Running `target/debug/loops`
İleri ayım = 0
Geri sayım = 10
Geri sayım = 9
İleri ayım = 1
Geri sayım = 10
Geri sayım = 9
İleri ayım = 2
Geri sayım = 10
Son İlerleme = 2
while İle Koşullu Döngüleri Düzene Sokmak (Streamlining)
Bir programın genellikle bir döngü içinde bir koşulu değerlendirmesi gerekecektir. Koşul true olduğu sürece (while) döngü çalışır. Koşul true olmayı bıraktığında, program break çağrısı yaparak döngüyü durdurur. Bunun gibi bir davranışı loop, if, else ve break kombinasyonu kullanarak uygulamak mümkündür; isterseniz bunu şimdi bir programda deneyebilirsiniz. Ancak bu kalıp (pattern) o kadar yaygındır ki, Rust bunun için while döngüsü adı verilen yerleşik (built-in) bir dil yapısına sahiptir. Liste 3-3’te, programı üç kez döngüye sokmak, her seferinde geriye doğru saymak ve ardından döngüden sonra bir mesaj yazdırıp çıkmak için while kullanıyoruz.
fn main() {
let mut sayi = 3;
while sayi != 0 {
println!("{sayi}!");
sayi -= 1;
}
println!("KALKIŞ!!!");
}true olarak değerlendirildiği (evaluates) sürece kod çalıştırmak için while döngüsü kullanmakBu yapı, loop, if, else ve break kullansaydınız gerekli olacak olan çok sayıda iç içe geçmeyi (nesting) ortadan kaldırır ve daha açıktır (clearer). Bir koşul true olarak değerlendirildiği sürece kod çalışır; aksi halde döngüden çıkar.
for İle Bir Koleksiyon Üzerinde Döngü Kurmak (Looping Through)
Bir array (dizi) gibi bir koleksiyonun elemanları üzerinde döngü kurmak için while yapısını kullanmayı seçebilirsiniz. Örneğin Liste 3-4’teki döngü, a dizisindeki her bir elemanı yazdırır.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut indeks = 0;
while indeks < 5 {
println!("değer: {}", a[indeks]);
indeks += 1;
}
}while döngüsü kullanarak bir koleksiyonun her bir elemanı üzerinden geçmekBurada kod, dizideki elemanlar üzerinden yukarı doğru sayar. 0 indeksinden (index) başlar ve dizideki son indekse ulaşana kadar (yani, indeks < 5 artık true olmayana kadar) döngüye devam eder. Bu kodu çalıştırmak, dizideki her bir elemanı yazdıracaktır:
$ cargo run
Compiling loops v0.1.0 ($PROJE/listings/ch03-common-programming-concepts/listing-03-04)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/loops`
değer: 10
değer: 20
değer: 30
değer: 40
değer: 50
Beklendiği gibi beş dizi değerinin tümü terminalde belirir. indeks (index) bir noktada 5 değerine ulaşacak olsa da, döngü diziden altıncı bir değeri getirmeye çalışmadan önce çalışmayı durdurur.
Bununla birlikte, bu yaklaşım hataya açıktır (error-prone); indeks değeri veya test koşulu yanlışsa programın panik yapmasına neden olabiliriz. Örneğin, a dizisinin tanımını dört elemanı olacak şekilde değiştirdiyseniz ancak durumu while indeks < 4 olarak güncellemeyi unuttuysanız, kod panikler. Ayrıca derleyici, döngüdeki her bir adımda (iteration) indeksin dizinin sınırları içinde olup olmadığına dair koşullu kontrolü gerçekleştirmek için çalışma zamanı kodu eklediği için yavaştır.
Daha öz bir alternatif olarak, bir for döngüsü kullanabilir ve bir koleksiyondaki her öğe için biraz kod çalıştırabilirsiniz. Bir for döngüsü, Liste 3-5’teki kod gibi görünür.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("değer: {element}");
}
}for döngüsü kullanarak bir koleksiyonun her bir elemanı üzerinden geçmekBu kodu çalıştırdığımızda Liste 3-4’teki ile aynı çıktıyı göreceğiz. Daha da önemlisi, artık kodun güvenliğini artırdık ve dizinin sonunun ötesine geçmekten veya yeterince ileri gitmeyip bazı öğeleri kaçırmaktan kaynaklanabilecek hata (bug) olasılığını ortadan kaldırdık. İndeksin her adımda dizinin uzunluğuyla karşılaştırılmasına gerek olmadığı için, for döngülerinden üretilen makine kodu (machine code) da daha verimli olabilir.
for döngüsünü kullanırsanız, Liste 3-4’te kullanılan yöntemde yapacağınız gibi, dizideki değerlerin sayısını değiştirdiğinizde başka herhangi bir kodu değiştirmeyi hatırlamanız gerekmez.
for döngülerinin güvenliği ve kısalığı (conciseness), onları Rust’ta en sık kullanılan döngü yapısı yapar. Liste 3-3’te while döngüsünü kullanan geri sayım örneğinde olduğu gibi, bir kodu belirli bir sayıda çalıştırmak istediğiniz durumlarda bile çoğu Rustacean bir for döngüsü kullanır. Bunu yapmanın yolu, standart kütüphane tarafından sağlanan ve bir sayıdan başlayıp başka bir sayıdan önce bitecek şekilde sırayla (in sequence) tüm sayıları üreten bir Aralık (Range) kullanmaktır.
Aralığı (range) tersine çevirmek için henüz bahsetmediğimiz başka bir metot olan rev’i ve bir for döngüsünü kullanan geri sayımın nasıl görüneceği aşağıda verilmiştir:
Dosya adı: src/main.rs
fn main() {
for sayi in (1..4).rev() {
println!("{sayi}!");
}
println!("KALKIŞ!!!");
}Bu kod biraz daha güzel, değil mi?
Özet
Başardınız! Bu epey büyük bir bölümdü: Değişkenler, skaler ve bileşik veri türleri, fonksiyonlar, yorumlar, if ifadeleri ve döngüler hakkında bilgi edindiniz! Bu bölümde tartışılan kavramlarla pratik yapmak için, şunları yapacak programlar oluşturmayı deneyin:
- Sıcaklıkları Fahrenheit ve Santigrat arasında dönüştürün.
- n. Fibonacci sayısını üretin.
- Şarkıdaki tekrarı avantajınıza kullanarak “The Twelve Days of Christmas” (Noel’in On İki Günü) şarkısının sözlerini yazdırın.
İlerlemeye hazır olduğunuzda, Rust’ta diğer programlama dillerinde yaygın olarak bulunmayan bir konudan bahsedeceğiz: Sahiplik.
Sahipliği Anlamak
Sahiplik, Rust’ın en özgün özelliğidir ve dilin geri kalanı üzerinde derin etkilere sahiptir. Rust’ın bir çöp toplayıcıya (garbage collector) ihtiyaç duymadan bellek güvenliği (memory safety) garantisi sağlamasına olanak tanır, bu yüzden sahipliğin nasıl çalıştığını anlamak çok önemlidir. Bu bölümde, sahipliğin yanı sıra bununla bağlantılı bazı özellikleri de konuşacağız: ödünç alma, dilimler ve Rust’ın verileri bellekte nasıl düzenlediği.
Sahiplik Nedir?
Sahiplik Nedir?
Sahiplik, bir Rust programının belleği nasıl yönettiğini belirleyen kurallar bütünüdür. Tüm programlar, çalışırken bilgisayarın belleğini nasıl kullanacaklarını yönetmek zorundadır. Bazı dillerde, program çalışırken artık kullanılmayan belleği düzenli olarak arayan bir çöp toplayıcı (garbage collection) bulunur; diğer dillerde ise programcı belleği açıkça ayırmalı ve serbest bırakmalıdır. Rust üçüncü bir yaklaşım kullanır: Bellek, derleyicinin kontrol ettiği bir dizi kuralla sahiplik sistemi üzerinden yönetilir. Kurallardan herhangi biri ihlal edilirse, program derlenmez. Sahiplik özelliklerinin hiçbiri, programınız çalışırken onu yavaşlatmaz.
Sahiplik birçok programcı için yeni bir kavram olduğundan, alışmak biraz zaman alabilir. İyi haber şu ki, Rust’ta ve sahiplik sisteminin kurallarında ne kadar deneyim kazanırsanız, güvenli ve verimli kod geliştirmeyi o kadar doğal bulacaksınız. Üzerinde çalışmaya devam edin!
Sahipliği anladığınızda, Rust’ı benzersiz yapan özellikleri anlamak için sağlam bir temele sahip olacaksınız. Bu bölümde, çok yaygın bir veri yapısına odaklanan bazı örnekler üzerinde çalışarak sahipliği öğreneceksiniz: stringler (metinler).
Yığın ve Yığın Bellek (The Stack and the Heap)
Birçok programlama dili, yığın (stack) ve yığın bellek (heap) hakkında çok sık düşünmenizi gerektirmez. Ancak Rust gibi bir sistem programlama dilinde, bir değerin stack’te mi yoksa heap’te mi olduğu, dilin nasıl davrandığını ve neden belirli kararlar almanız gerektiğini etkiler. Bu bölümün ilerleyen kısımlarında sahipliğin bazı kısımları stack ve heap ile ilişkili olarak açıklanacaktır, bu yüzden hazırlık olarak burada kısa bir açıklama yer almaktadır.
Hem stack hem de heap, kodunuzun çalışma zamanında kullanabileceği belleğin kısımlarıdır, ancak farklı şekillerde yapılandırılmışlardır. Stack, değerleri aldığı sırayla depolar ve ters sırayla çıkarır. Buna son giren ilk çıkar (LIFO) denir. Üst üste dizilmiş tabakları düşünün: Daha fazla tabak eklediğinizde, onları yığının en üstüne koyarsınız ve bir tabağa ihtiyacınız olduğunda, en üsttekinden bir tane alırsınız. Ortadan veya alttan tabak eklemek veya çıkarmak o kadar iyi çalışmazdı! Veri eklemeye stack’e itme (pushing onto the stack), veri çıkarmaya ise stack’ten çekme (popping off the stack) denir. Stack’te depolanan tüm verilerin bilinen, sabit bir boyutu olmalıdır. Derleme zamanında boyutu bilinmeyen veya boyutu değişebilecek veriler, bunun yerine heap’te saklanmalıdır.
Heap daha az düzenlidir: Heap’e veri koyduğunuzda, belirli bir miktarda alan talep edersiniz. Bellek ayırıcı (memory allocator), heap’te yeterince büyük boş bir yer bulur, kullanımda olarak işaretler ve o konumun adresi olan bir işaretçi (pointer) döndürür. Bu sürece heap üzerinde ayırma (allocating on the heap) denir ve bazen sadece ayırma olarak kısaltılır (değerleri stack’e itmek ayırma olarak kabul edilmez). Heap işaretçisi bilinen, sabit bir boyuta sahip olduğu için işaretçiyi stack’te saklayabilirsiniz, ancak asıl veriyi istediğinizde işaretçiyi takip etmeniz gerekir. Bir restoranda oturduğunuzu düşünün. Girdiğinizde, grubunuzdaki kişi sayısını belirtirsiniz ve görevli herkese uygun boş bir masa bulup sizi oraya yönlendirir. Grubunuzdan biri geç gelirse, sizi bulmak için nereye oturduğunuzu sorabilir.
Stack’e itmek, heap üzerinde ayırmaktan daha hızlıdır çünkü ayırıcı hiçbir zaman yeni veriyi depolamak için bir yer aramak zorunda kalmaz; bu konum her zaman stack’in en üstündedir. Karşılaştırmalı olarak, heap’te yer ayırmak daha fazla iş gerektirir çünkü ayırıcı önce veriyi tutacak kadar büyük bir alan bulmalı ve ardından bir sonraki ayırma işlemi için hazırlık yapmak üzere kayıt tutmalıdır.
Heap’teki verilere erişmek, stack’teki verilere erişmekten genellikle daha yavaştır çünkü oraya ulaşmak için bir işaretçiyi takip etmeniz gerekir. Modern işlemciler bellekte daha az zıpladıklarında daha hızlıdırlar. Analojiye devam edersek, birçok masadan sipariş alan bir restoran görevlisini düşünün. Bir sonraki masaya geçmeden önce tek bir masadaki tüm siparişleri almak en verimlisidir. A masasından bir sipariş alıp, ardından B masasından, sonra tekrar A’dan ve sonra tekrar B’den sipariş almak çok daha yavaş bir süreç olacaktır. Aynı şekilde, bir işlemci veriler diğer verilere (stack’te olduğu gibi) daha yakın olduğunda görevini daha iyi yapabilir (heap’te olabileceği gibi) uzak olduğundan ziyade.
Kodunuz bir fonksiyonu çağırdığında, fonksiyona geçirilen değerler (muhtemelen heap’teki verilere yönelik işaretçiler de dahil) ve fonksiyonun yerel değişkenleri stack’e itilir. Fonksiyon sona erdiğinde, bu değerler stack’ten çekilir.
Kodun hangi kısımlarının heap üzerinde hangi verileri kullandığını takip etmek, heap’teki kopya verilerin miktarını en aza indirmek ve boş yerinizin bitmemesi için heap’teki kullanılmayan verileri temizlemek, sahipliğin ele aldığı sorunlardır. Sahipliği bir kez anladığınızda, stack ve heap hakkında çok sık düşünmenize gerek kalmayacaktır. Ancak sahipliğin asıl amacının heap verilerini yönetmek olduğunu bilmek, onun neden bu şekilde çalıştığını açıklamaya yardımcı olabilir.
Sahiplik Kuralları
Öncelikle, sahiplik kurallarına bir göz atalım. Onları gösteren örnekler üzerinde çalışırken bu kuralları aklınızda bulundurun:
- Rust’taki her değerin bir sahibi vardır.
- Aynı anda sadece bir sahip olabilir.
- Sahip kapsamın dışına çıktığında, değer düşürülecektir (drop).
Değişken Kapsamı (Variable Scope)
Temel Rust sözdizimini geçtiğimize göre, örneklerdeki tüm fn main() { kodlarını dahil etmeyeceğiz, bu yüzden takip ediyorsanız, aşağıdaki örnekleri manuel olarak bir main fonksiyonunun içine koyduğunuzdan emin olun. Sonuç olarak, örneklerimiz biraz daha özlü olacak ve klişe kodlardan (boilerplate) ziyade asıl detaylara odaklanmamızı sağlayacak.
Sahipliğin ilk örneği olarak, bazı değişkenlerin kapsamına bakacağız. Bir kapsam, bir öğenin program içinde geçerli olduğu aralıktır. Aşağıdaki değişkeni ele alalım:
#![allow(unused)]
fn main() {
let metin = "merhaba";
}metin değişkeni, stringin değerinin programımızın metnine doğrudan (hardcoded) yazıldığı bir string literalini (sabit metni) ifade eder. Değişken, tanımlandığı andan mevcut kapsamın sonuna kadar geçerlidir. Liste 4-1, metin değişkeninin nerede geçerli olacağını açıklayan yorumlarla birlikte bir programı göstermektedir.
fn main() {
{
// metin burada geçerli değil, henüz tanımlanmadı
let metin = "merhaba"; // metin bu noktadan itibaren geçerlidir
// metin ile ilgili işlemler yap
} // bu kapsam biter ve metin artık geçerli değildir
}Başka bir deyişle, burada iki önemli zaman noktası vardır:
metinkapsama girdiğinde geçerlidir.- Kapsamdan çıkana kadar geçerliliğini korur.
Bu noktada, kapsamlar ve değişkenlerin ne zaman geçerli olduğu arasındaki ilişki diğer programlama dillerindekine benzer. Şimdi String türünü tanıtarak bu anlayışın üzerine inşa edeceğiz.
String Türü
Sahiplik kurallarını göstermek için, Bölüm 3’teki “Veri Türleri” bölümünde ele aldıklarımızdan daha karmaşık bir veri türüne ihtiyacımız var. Daha önce ele alınan türlerin boyutu bilinmektedir, stack’te saklanabilir ve kapsamları sona erdiğinde stack’ten çıkarılabilirler. Kodun başka bir bölümünün aynı değeri farklı bir kapsamda kullanması gerekiyorsa yeni, bağımsız bir örnek oluşturmak için hızlı ve kolay bir şekilde kopyalanabilirler. Ancak, heap’te depolanan verilere bakmak ve Rust’ın bu verileri ne zaman temizleyeceğini nasıl bildiğini keşfetmek istiyoruz ve String türü bunun için harika bir örnektir.
String’in sahiplikle ilgili olan kısımlarına yoğunlaşacağız. Bu yönler, standart kütüphane tarafından sağlanmış veya sizin tarafınızdan oluşturulmuş olsun, diğer karmaşık veri türleri için de geçerlidir. String’in sahiplik dışı yönlerini Bölüm 8’de tartışacağız.
Bir string değerinin programımıza doğrudan kodlandığı string literallerini (sabit metinleri) zaten görmüştük. Sabit metinler kullanışlıdır, ancak metin kullanmak isteyebileceğimiz her durum için uygun değillerdir. Bunun bir nedeni değişmez olmalarıdır. Bir diğeri ise kodumuzu yazarken her metin değerinin bilinememesidir: Örneğin, ya kullanıcı girdisini alıp saklamak istiyorsak? Rust’ın bu tür durumlar için String türü vardır. Bu tür, heap üzerinde ayrılan verileri yönetir ve bu nedenle derleme zamanında bize bilinmeyen miktarda metni depolayabilir. from fonksiyonunu kullanarak bir string literalinden bir String oluşturabilirsiniz, örneğin:
#![allow(unused)]
fn main() {
let metin = String::from("merhaba");
}Çift iki nokta üst üste :: operatörü, bu özel from fonksiyonunu string_from gibi bir isim kullanmak yerine String türü altında isimlendirmemize (namespace) olanak tanır. Bu sözdizimini Bölüm 5’teki “Metotlar” bölümünde ve Bölüm 7’deki modüllerle isimlendirme uzaylarından bahsederken “Modül Ağacındaki Bir Öğeye Başvurmak İçin Yollar” bölümünde daha fazla tartışacağız.
Bu tür bir string değiştirilebilir (mutated):
fn main() {
let mut metin = String::from("merhaba");
metin.push_str(", dünya!"); // push_str() bir String'e sabit metin ekler
println!("{metin}"); // bu `merhaba, dünya!` yazdıracak
}Peki buradaki fark nedir? Neden String değiştirilebilirken literaller değiştirilemez? Fark, bu iki türün bellekle nasıl başa çıktığına bağlıdır.
Bellek ve Ayırma (Memory and Allocation)
Sabit bir metin söz konusu olduğunda, içeriği derleme zamanında biliyoruz, bu yüzden metin doğrudan son çalıştırılabilir dosyanın içine yerleştirilir (hardcoded). String literallerinin hızlı ve verimli olmasının nedeni budur. Ancak bu özellikler yalnızca metin literalinin değişmezliğinden (immutability) gelir. Ne yazık ki, derleme zamanında boyutu bilinmeyen ve program çalışırken boyutu değişebilecek her bir metin parçası için ikili dosyanın içine bir bellek yığını koyamayız.
String türüyle, değiştirilebilir, büyüyebilir bir metin parçasını desteklemek için, içerikleri tutmak üzere derleme zamanında bilinmeyen miktarda bir belleği heap’te ayırmamız gerekir. Bu şu anlama gelir:
- Çalışma zamanında bellek ayırıcıdan (memory allocator) bellek talep edilmelidir.
String’imizle işimiz bittiğinde bu belleği ayırıcıya iade etmenin bir yoluna ihtiyacımız var.
İlk kısım bizim tarafımızdan yapılır: String::from’u çağırdığımızda, onun uygulaması ihtiyaç duyduğu belleği talep eder. Bu, programlama dillerinde neredeyse evrenseldir.
Ancak ikinci kısım farklıdır. Bir çöp toplayıcısına (GC - garbage collector) sahip olan dillerde, GC artık kullanılmayan belleği takip eder, temizler ve bizim bunu düşünmemize gerek kalmaz. GC’si olmayan çoğu dilde ise, belleğin ne zaman artık kullanılmadığını belirlemek ve tıpkı onu talep ettiğimiz gibi, açıkça serbest bırakacak (free) kodu çağırmak bizim sorumluluğumuzdadır. Bunu doğru yapmak tarihsel olarak zor bir programlama problemi olmuştur. Unutursak, bellek israf ederiz. Çok erken yaparsak, geçersiz bir değişkenimiz olur. İki kez yaparsak, o da bir bug’dır (hata). Tam olarak bir allocate (ayırma) işlemi ile tam olarak bir free (serbest bırakma) işlemini eşleştirmemiz gerekir.
Rust farklı bir yol izler: Sahip olan değişken kapsam dışına çıktığında bellek otomatik olarak iade edilir. İşte Liste 4-1’deki kapsam örneğimizin bir sabit metin yerine String kullanan versiyonu:
fn main() {
{
let metin = String::from("merhaba"); // metin bu noktadan itibaren geçerlidir
// metin ile ilgili işlemler yap
} // bu kapsam artık bitti ve metin artık
// geçerli değil
}String’imizin ihtiyaç duyduğu belleği ayırıcıya iade edebileceğimiz doğal bir an vardır: metin kapsam dışına çıktığında. Bir değişken kapsam dışına çıktığında, Rust bizim için özel bir fonksiyon çağırır. Bu fonksiyona drop denir ve String’in yazarının belleği iade edecek kodu koyabileceği yer burasıdır. Rust, süslü kapanış parantezinde drop’u otomatik olarak çağırır.
Not: C++’ta, bir öğenin ömrünün sonunda kaynakları serbest bırakma (deallocating) pattern’ine bazen Resource Acquisition Is Initialization (RAII) - Kaynak Edinimi Başlatmadır denir. Rust’taki
dropfonksiyonu, daha önce RAII kalıplarını kullandıysanız size tanıdık gelecektir.
Bu kalıbın Rust kodunun yazılma şekli üzerinde derin bir etkisi vardır. Şu anda basit gibi görünebilir, ancak heap üzerinde ayırdığımız verileri birden fazla değişkenin kullanmasını istediğimiz daha karmaşık durumlarda kodun davranışı beklenmedik olabilir. Şimdi o durumlardan bazılarını inceleyelim.
Değişkenlerin ve Verilerin Move (Taşıma) ile Etkileşimi
Rust’ta birden fazla değişken aynı verilerle farklı yollarla etkileşime girebilir. Liste 4-2, bir tamsayı kullanan bir örneği göstermektedir.
fn main() {
let x = 5;
let y = x;
}x değişkeninin tamsayı değerini y’ye atamaBunun ne yaptığını muhtemelen tahmin edebiliriz: “5 değerini x’e bağla; sonra, x’teki değerin bir kopyasını çıkar ve onu y’ye bağla.” Artık x ve y olmak üzere iki değişkenimiz var ve ikisi de 5’e eşit. Gerçekten olan da tam olarak budur, çünkü tamsayılar bilinen, sabit bir boyuta sahip basit değerlerdir ve bu iki 5 değeri stack’e itilir.
Şimdi String versiyonuna bakalım:
fn main() {
let metin1 = String::from("merhaba");
let metin2 = metin1;
}Bu çok benzer görünüyor, bu yüzden çalışma şeklinin aynı olacağını varsayabiliriz: Yani, ikinci satır metin1’deki değerin bir kopyasını oluşturur ve onu metin2’ye bağlar. Ancak olan şey tam olarak bu değildir.
String’in arka planda neler yaptığına bakmak için Şekil 4-1’e göz atın. Bir String, solda gösterildiği gibi üç bölümden oluşur: stringin içeriğini tutan belleğe yönelik bir işaretçi (pointer), bir uzunluk ve bir kapasite (capacity). Bu veri grubu stack’te saklanır. Sağda ise içerikleri tutan heap üzerindeki bellek yer alır.

Şekil 4-1: "merhaba" değerini tutan metin1’e bağlı bir String’in bellekteki temsili
Uzunluk, String’in içeriğinin şu anda bayt cinsinden ne kadar bellek kullandığıdır. Kapasite (capacity), String’in ayırıcıdan aldığı toplam bellek miktarının bayt cinsinden değeridir. Uzunluk ve kapasite arasındaki fark önemlidir, ancak bu bağlamda değil; o yüzden şimdilik kapasiteyi görmezden gelmek sorun olmaz.
metin1’i metin2’ye atadığımızda, String verileri kopyalanır, yani stack’teki işaretçiyi, uzunluğu ve kapasiteyi kopyalarız. İşaretçinin (pointer) referans verdiği heap üzerindeki verileri kopyalamayız. Başka bir deyişle, bellekteki veri gösterimi Şekil 4-2’deki gibi görünür.

Şekil 4-2: metin1’in işaretçisinin, uzunluğunun ve kapasitesinin bir kopyasına sahip olan metin2 değişkeninin bellekteki gösterimi
Gösterim Şekil 4-3’teki gibi görünmez, ki bu Rust heap verilerini de kopyalasaydı belleğin nasıl görüneceğiydi. Eğer Rust bunu yapsaydı, heap üzerindeki veriler büyük olsaydı metin2 = metin1 işlemi çalışma zamanı performansı açısından çok maliyetli olabilirdi.

Şekil 4-3: Rust heap verilerini de kopyalasaydı metin2 = metin1’in ne yapabileceğine dair başka bir olasılık
Daha önce, bir değişken kapsam dışına çıktığında Rust’ın otomatik olarak drop fonksiyonunu çağırdığını ve o değişkenin heap belleğini temizlediğini söylemiştik. Ancak Şekil 4-2 her iki veri işaretçisinin de aynı konumu gösterdiğini gösteriyor. Bu bir sorundur: metin2 ve metin1 kapsam dışına çıktığında, ikisi de aynı belleği serbest bırakmaya (free) çalışacaktır. Bu, double free (çifte serbest bırakma) hatası olarak bilinir ve daha önce bahsettiğimiz bellek güvenliği (memory safety) hatalarından biridir. Belleği iki kez serbest bırakmak bellek bozulmasına yol açabilir ve bu da potansiyel olarak güvenlik açıklarına neden olabilir.
Bellek güvenliğini sağlamak için, let metin2 = metin1; satırından sonra Rust, metin1’i artık geçerli olarak görmez. Bu nedenle, metin1 kapsam dışına çıktığında Rust’ın hiçbir şeyi serbest bırakması gerekmez. metin2 oluşturulduktan sonra metin1’i kullanmaya çalıştığınızda ne olduğuna bir bakın; çalışmayacaktır:
fn main() {
let metin1 = String::from("merhaba");
let metin2 = metin1;
println!("{metin1}, dünya!");
}Şuna benzer bir hata alırsınız çünkü Rust geçersiz kılınmış (invalidated) referansı kullanmanızı engeller:
$ cargo run
Compiling ownership v0.1.0 ($PROJE/listings/ch04-understanding-ownership/no-listing-04-cant-use-after-move)
error[E0382]: borrow of moved value: `metin1`
--> src/main.rs:6:16
|
3 | let metin1 = String::from("merhaba");
| ------ move occurs because `metin1` has type `String`, which does not implement the `Copy` trait
4 | let metin2 = metin1;
| ------ value moved here
5 |
6 | println!("{metin1}, dünya!");
| ^^^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
4 | let metin2 = metin1.clone();
| ++++++++
warning: unused variable: `metin2`
--> src/main.rs:4:9
|
4 | let metin2 = metin1;
| ^^^^^^ help: if this is intentional, prefix it with an underscore: `_metin2`
|
= note: `#[warn(unused_variables)]` (part of `#[warn(unused)]`) on by default
For more information about this error, try `rustc --explain E0382`.
warning: `ownership` (bin "ownership") generated 1 warning
error: could not compile `ownership` (bin "ownership") due to 1 previous error; 1 warning emitted
Diğer dillerle çalışırken shallow copy (sığ kopya) ve deep copy (derin kopya) terimlerini duyduysanız, verileri kopyalamadan işaretçiyi, uzunluğu ve kapasiteyi kopyalama konsepti muhtemelen sığ bir kopya (shallow copy) yapmak gibi gelebilir. Ancak Rust ilk değişkeni de geçersiz kıldığından, sığ kopya olarak adlandırılmak yerine buna move (taşıma) adı verilir. Bu örnekte, metin1’in metin2’nin içine taşındığını söyleyebiliriz. Yani gerçekte ne olduğu Şekil 4-4’te gösterilmektedir.

Şekil 4-4: metin1 geçersiz kılındıktan sonra bellekteki gösterim
Bu sorunumuzu çözer! Sadece metin2 geçerli olduğunda, kapsam dışına çıktığında yalnız o belleği serbest bırakacak ve işimiz bitecek.
Ek olarak, bunun ima ettiği bir tasarım tercihi vardır: Rust verilerinizin asla otomatik olarak “derin” (deep) kopyalarını oluşturmaz. Bu nedenle, herhangi bir otomatik kopyalamanın çalışma zamanı performansı açısından ucuz (maliyetsiz) olduğu varsayılabilir.
Kapsam ve Atama (Scope and Assignment)
Bunun tersi, kapsam belirleme (scoping), sahiplik ve belleğin drop fonksiyonu aracılığıyla serbest bırakılması arasındaki ilişki için de geçerlidir. Var olan bir değişkene tamamen yeni bir değer atadığınızda, Rust derhal orijinal değer üzerinde drop’u çağıracak ve onun belleğini serbest bırakacaktır. Örneğin şu kodu inceleyin:
fn main() {
let mut metin = String::from("merhaba");
metin = String::from("selam");
println!("{metin}, dünya!");
}Başlangıçta bir metin değişkeni tanımlarız ve ona "merhaba" değerine sahip bir String bağlarız. Sonra hemen "selam" değerine sahip yeni bir String oluştururuz ve bunu metin’e atarız. Bu noktada, artık heap’teki orijinal değeri gösteren hiçbir şey (referans) yoktur. Şekil 4-5 stack ve heap verilerinin şu anki halini göstermektedir:

Şekil 4-5: Başlangıç değeri bütünüyle değiştirildikten sonra bellekteki gösterimi
Orijinal string böylece derhal kapsam dışına çıkar. Rust bunun üzerinde drop fonksiyonunu çalıştıracak ve belleği hemen serbest bırakılacaktır. En sonunda değeri ekrana yazdırdığımızda "selam, dünya!" olacaktır.
Değişkenlerin ve Verilerin Clone ile Etkileşimi
Eğer String’in stack verisiyle yetinmeyip, heap verisini derinlemesine (deep copy) kopyalamak istiyorsak, clone adında yaygın bir metot kullanabiliriz. Metot sözdizimini Bölüm 5’te ele alacağız, ancak metotlar birçok programlama dilinde ortak bir özellik olduğundan muhtemelen onları daha önce görmüşsünüzdür.
İşte clone metodunun çalışırken bir örneği:
fn main() {
let metin1 = String::from("merhaba");
let metin2 = metin1.clone();
println!("metin1 = {metin1}, metin2 = {metin2}");
}Bu, hiçbir sorun çıkarmadan çalışır ve açıkça heap verisinin kopyalandığı Şekil 4-3’te gösterilen davranışı üretir.
clone fonksiyonuna yapılan bir çağrı gördüğünüzde, bazı rastgele kodların çalıştırıldığını ve bu kodun pahalı (yüksek maliyetli) olabileceğini bilirsiniz. Bu, farklı bir şeylerin olup bittiğine dair görsel bir göstergedir.
Sadece Stack Verisi (Stack-Only Data): Copy
Henüz konuşmadığımız bir pürüz (ayrıntı) daha var. Liste 4-2’de gösterilen, tamsayıları kullanan bu kod çalışır ve geçerlidir:
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}Ancak bu kod az önce öğrendiklerimizle çelişiyor gibi görünmektedir: clone çağrımız yok, ancak x hala geçerlidir ve y’nin içine taşınmamıştır (move edilmemiştir).
Bunun nedeni, derleme zamanında bilinen bir boyuta sahip olan tamsayı gibi türlerin tamamen stack üzerinde saklanmasıdır, bu nedenle gerçek değerlerin kopyalarını oluşturmak hızlıdır. Bu, y değişkenini oluşturduktan sonra x’in geçerli olmasını engellemek istememiz için hiçbir neden olmadığı anlamına gelir. Başka bir deyişle, burada derin ve sığ kopyalama arasında hiçbir fark yoktur, bu yüzden clone’u çağırmak olağan sığ kopyalamadan farklı bir şey yapmaz ve onu dışarıda bırakabiliriz.
Rust’ın, tamsayılar gibi stack’te depolanan türlere yerleştirebileceğimiz Copy trait’i adında özel bir anotasyonu vardır (trait’ler hakkında Bölüm 10’da daha fazla konuşacağız). Bir tür Copy trait’ini uyguluyorsa, onu kullanan değişkenler move edilmez, bunun yerine kolayca (trivially) kopyalanarak başka bir değişkene atandıktan sonra bile geçerli kalırlar.
Eğer türün kendisi veya parçalarından herhangi biri Drop trait’ini uygulamışsa, Rust bir türü Copy ile işaretlememize izin vermez. Türün değeri kapsam dışına çıktığında özel bir şey olması gerekiyorsa ve o türe Copy anotasyonunu eklersek derleme zamanı hatası (compile-time error) alırız. Türünüze trait’i uygulamak için Copy anotasyonunu nasıl ekleyeceğinizi öğrenmek için Ek C’deki “Türetilebilir Traitler (Derivable Traits)” bölümüne bakın.
Peki, hangi türler Copy trait’ini uygular? Emin olmak için ilgili türün dokümantasyonunu kontrol edebilirsiniz, ancak genel bir kural olarak, herhangi bir basit skaler (tekil) değer grubu Copy’yi uygulayabilir; tahsisat gerektiren veya bir tür kaynak olan hiçbir şey Copy’yi uygulayamaz. İşte Copy’yi uygulayan bazı türler:
u32gibi tüm tamsayı türleri.truevefalsedeğerlerine sahip Boolean türü,bool.f64gibi tüm kayan noktalı sayı türleri (floating-point types).- Karakter türü,
char. - Demetler (Tuples), yalnızca
Copyuygulayan türleri içeriyorlarsa. Örneğin(i32, i32)Copy’yi uygular, ancak(i32, String)uygulamaz.
Sahiplik ve Fonksiyonlar (Ownership and Functions)
Bir değeri bir fonksiyona geçirmenin mekaniği, bir değişkene bir değer atarken uygulananla benzerdir. Bir değişkeni bir fonksiyona geçirmek, tıpkı atama işleminde olduğu gibi taşıyacak (move) veya kopyalayacaktır (copy). Liste 4-3’te, değişkenlerin ne zaman kapsama girip çıktığını gösteren bazı notlara sahip bir örnek yer almaktadır.
fn main() {
let metin = String::from("merhaba"); // metin kapsama girer
sahipligi_alir(metin); // metin'in değeri fonksiyona taşınır...
// ... ve bu yüzden burada artık geçerli değildir
let x = 5; // x kapsama girer
kopyasini_olustur(x); // i32 Copy trait'ini uyguladığı için,
// x fonksiyona TAŞINMAZ,
// bu yüzden x'i daha sonra kullanmak sorun olmaz.
} // Burada x kapsamdan çıkar, sonra da metin. Ancak metin'in değeri taşındığı için,
// özel bir şey olmaz.
fn sahipligi_alir(bir_metin: String) {
// bir_metin kapsama girer
println!("{bir_metin}");
} // Burada bir_metin kapsamdan çıkar ve `drop` çağrılır. Arkadaki
// bellek serbest bırakılır.
fn kopyasini_olustur(bir_tamsayi: i32) {
// bir_tamsayi kapsama girer
println!("{bir_tamsayi}");
} // Burada bir_tamsayi kapsamdan çıkar. Özel bir şey olmaz.Eğer sahipligi_alir çağrısından sonra metin’i kullanmaya çalışsaydık, Rust bir derleme zamanı hatası fırlatırdı (throw). Bu statik kontroller bizi hatalardan korur. metin ve x’i nerelerde kullanabileceğinizi ve sahiplik kurallarının sizi nerelerde engellediğini görmek için main’e metin ve x kullanan kodlar eklemeyi deneyin.
Dönüş Değerleri ve Kapsam (Return Values and Scope)
Değer döndürmek de sahipliği aktarabilir. Liste 4-4, Liste 4-3’tekine benzer açıklamalarla bazı değerler döndüren bir fonksiyonun örneğini göstermektedir.
fn main() {
let metin1 = sahiplik_verir(); // sahiplik_verir dönüş değerini
// metin1'e taşır
let metin2 = String::from("merhaba"); // metin2 kapsama girer
let metin3 = alir_ve_geri_verir(metin2); // metin2, alir_ve_geri_verir'e taşınır,
// o da dönüş değerini
// metin3'e taşır
} // Burada metin3 kapsamdan çıkar ve düşürülür (drop). metin2 taşındığı için hiçbir şey
// olmaz. metin1 kapsamdan çıkar ve düşürülür.
fn sahiplik_verir() -> String {
// sahiplik_verir dönüş değerini
// onu çağıran fonksiyona
// taşıyacaktır
let bir_metin = String::from("senin"); // bir_metin kapsama girer
bir_metin // bir_metin döndürülür ve
// çağıran fonksiyona
// taşınır
}
// Bu fonksiyon bir String alır ve bir String döndürür.
fn alir_ve_geri_verir(bir_metin: String) -> String {
// bir_metin kapsama
// girer
bir_metin // bir_metin döndürülür ve çağıran fonksiyona taşınır
}Bir değişkenin sahipliği her zaman aynı kalıbı (pattern) izler: Başka bir değişkene değer atamak onu taşır (moves). Heap üzerinde veri içeren bir değişken kapsam dışına çıktığında, verinin sahipliği başka bir değişkene taşınmadığı sürece bu değer drop ile temizlenir.
Bu işe yarasa da, sahipliği almak ve ardından her fonksiyonla sahipliği geri döndürmek biraz yorucudur. Peki ya bir fonksiyonun bir değeri kullanmasına izin verip sahipliği almasını istemiyorsak? Bir fonksiyona geçirdiğimiz herhangi bir şeyi, onu tekrar kullanmak istiyorsak geriye döndürmek zorunda olmamız oldukça can sıkıcıdır; buna fonksiyonun gövdesinden kaynaklanan ve döndürmek isteyebileceğimiz diğer veriler de dahildir.
Rust, Liste 4-5’te gösterildiği gibi, bir demet kullanarak birden fazla değeri döndürmemize olanak tanır.
fn main() {
let metin1 = String::from("merhaba");
let (metin2, uzunluk) = uzunlugu_hesapla(metin1);
println!("'{metin2}' metninin uzunluğu: {uzunluk}.");
}
fn uzunlugu_hesapla(metin: String) -> (String, usize) {
let uzunluk = metin.len(); // len() bir String'in uzunluğunu döndürür
(metin, uzunluk)
}Ancak bu, yaygın olması gereken bir konsept için çok fazla seremoni (angarya) ve epey bir iştir. Neyse ki, Rust’ın sahipliği aktarmadan bir değeri kullanmak için sahip olduğu bir özellik var: referanslar.
Referanslar ve Ödünç Alma
Referanslar ve Ödünç Alma (References and Borrowing)
Liste 4-5’teki demet kodunun sorunu, String’in uzunlugu_hesapla fonksiyonuna taşınmış (moved) olması ve uzunlugu_hesapla çağrısından sonra bu String’i hala kullanabilmek için çağıran fonksiyona geri döndürmek zorunda kalmamızdır. Bunun yerine, String değerine bir referans sağlayabiliriz. Referans, bir işaretçiye (pointer) benzer; yani, o adreste depolanan verilere erişmek için takip edebileceğimiz bir adrestir; ancak o veriler başka bir değişkene aittir. İşaretçiden farklı olarak, bir referansın ömrü boyunca belirli bir türden geçerli bir değere işaret edeceği garanti edilir.
Bir değerin sahipliğini almak yerine nesneye referans olan bir parametreye sahip uzunlugu_hesapla fonksiyonunu nasıl tanımlayacağınız ve kullanacağınız aşağıda açıklanmıştır:
fn main() {
let metin1 = String::from("merhaba");
let uzunluk = uzunlugu_hesapla(&metin1);
println!("'{metin1}' metninin uzunluğu: {uzunluk}.");
}
fn uzunlugu_hesapla(metin: &String) -> usize {
metin.len()
}İlk olarak, değişken tanımındaki ve fonksiyon dönüş değerindeki tüm demet kodlarının gittiğine dikkat edin. İkinci olarak, uzunlugu_hesapla’ya &metin1 ilettiğimize ve tanımında String yerine &String aldığımıza dikkat edin. Bu ampersanlar (ve işaretleri, &) referansları temsil eder ve bir değerin sahipliğini almadan ona atıfta bulunmanıza olanak tanır. Şekil 4-6 bu konsepti tasvir etmektedir.

Şekil 4-6: String metin1’e işaret eden &String metin diyagramı
Not:
&kullanarak referans almanın (referencing) zıttı dereferencing (referansın değerini alma) olarak adlandırılır ve bu, dereference operatörü olan*ile gerçekleştirilir. Dereference operatörünün bazı kullanımlarını Bölüm 8’de göreceğiz ve detaylarını Bölüm 15’te tartışacağız.
Şimdi buradaki fonksiyon çağrısına daha yakından bakalım:
fn main() {
let metin1 = String::from("merhaba");
let uzunluk = uzunlugu_hesapla(&metin1);
println!("'{metin1}' metninin uzunluğu: {uzunluk}.");
}
fn uzunlugu_hesapla(metin: &String) -> usize {
metin.len()
}&metin1 sözdizimi, metin1 değerine atıfta bulunan ancak ona sahip olmayan bir referans oluşturmamızı sağlar. Referans ona sahip olmadığı için, referansın kullanımı durduğunda işaret ettiği değer düşürülmeyecektir (drop edilmeyecektir).
Aynı şekilde, fonksiyonun imzası da metin parametresinin türünün bir referans olduğunu belirtmek için & kullanır. Gelin açıklayıcı birkaç not ekleyelim:
fn main() {
let metin1 = String::from("merhaba");
let uzunluk = uzunlugu_hesapla(&metin1);
println!("'{metin1}' metninin uzunluğu: {uzunluk}.");
}
fn uzunlugu_hesapla(metin: &String) -> usize {
// metin bir String'e referanstır
metin.len()
} // Burada, metin kapsam dışına çıkar. Ancak metin referans verdiği şeyin
// sahipliğine sahip olmadığı için String düşürülmez (drop edilmez).metin değişkeninin geçerli olduğu kapsam, herhangi bir fonksiyon parametresinin kapsamıyla aynıdır, ancak referansın işaret ettiği değer metin kullanımı durduğunda düşürülmez, çünkü metin sahipliğe sahip değildir. Fonksiyonlar, asıl değerler yerine referansları parametre olarak aldıklarında, sahipliği geri vermek için değerleri döndürmemize gerek kalmaz, çünkü sahipliğe hiçbir zaman sahip olmadık.
Bir referans oluşturma eylemine ödünç alma diyoruz. Gerçek hayatta olduğu gibi, bir kişinin sahip olduğu bir şeyi ondan ödünç alabilirsiniz. İşiniz bittiğinde onu geri vermek zorundasınızdır. Ona sahip olmazsınız.
Peki, ödünç aldığımız bir şeyi değiştirmeye çalışırsak ne olur? Liste 4-6’daki kodu deneyin. Sürprizbozan: Çalışmıyor!
fn main() {
let metin = String::from("merhaba");
degistir(&metin);
}
fn degistir(bir_metin: &String) {
bir_metin.push_str(", dünya");
}İşte hata:
$ cargo run
Compiling ownership v0.1.0 ($PROJE/listings/ch04-understanding-ownership/listing-04-06)
error[E0596]: cannot borrow `*bir_metin` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | bir_metin.push_str(", dünya");
| ^^^^^^^^^ `bir_metin` is a `&` reference, so it cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn degistir(bir_metin: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Tıpkı değişkenlerin varsayılan olarak değiştirilemez olduğu gibi, referanslar da öyledir. Referansına sahip olduğumuz bir şeyi değiştirmemize izin verilmez.
Değiştirilebilir Referanslar (Mutable References)
Bunun yerine bir değiştirilebilir referans kullanarak sadece birkaç küçük ayarla ödünç alınan bir değeri değiştirmemize izin vermesi için Liste 4-6’daki kodu düzeltebiliriz:
fn main() {
let mut metin = String::from("merhaba");
degistir(&mut metin);
}
fn degistir(bir_metin: &mut String) {
bir_metin.push_str(", dünya");
}Önce, metin’i mut olacak şekilde değiştiririz. Ardından, degistir fonksiyonunu çağırdığımız yerde &mut metin ile değiştirilebilir bir referans oluştururuz ve fonksiyon imzasını bir_metin: &mut String ile değiştirilebilir bir referans kabul edecek şekilde güncelleriz. Bu, degistir fonksiyonunun ödünç aldığı değeri değiştireceğini çok net bir şekilde belirtir.
Değiştirilebilir referansların büyük bir kısıtlaması vardır: Bir değere değiştirilebilir bir referansınız varsa, o değere başka hiçbir referansınız olamaz. metin’e iki tane değiştirilebilir referans oluşturmaya çalışan bu kod başarısız olacaktır:
fn main() {
let mut metin = String::from("merhaba");
let r1 = &mut metin;
let r2 = &mut metin;
println!("{r1}, {r2}");
}İşte hata:
$ cargo run
Compiling ownership v0.1.0 ($PROJE/listings/ch04-understanding-ownership/no-listing-10-multiple-mut-not-allowed)
error[E0499]: cannot borrow `metin` as mutable more than once at a time
--> src/main.rs:6:14
|
5 | let r1 = &mut metin;
| ---------- first mutable borrow occurs here
6 | let r2 = &mut metin;
| ^^^^^^^^^^ second mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Bu hata, kodun geçersiz olduğunu çünkü metin’i aynı anda birden fazla kez değiştirilebilir olarak ödünç alamayacağımızı söylüyor. İlk değiştirilebilir ödünç alma r1’dedir ve println! içinde kullanılana kadar sürmelidir, ancak bu değiştirilebilir referansın oluşturulmasıyla kullanımı arasında, r1 ile aynı veriyi ödünç alan r2’de başka bir değiştirilebilir referans oluşturmaya çalıştık.
Aynı verilere aynı anda birden fazla değiştirilebilir referans yapılmasını engelleyen bu kısıtlama, değişime izin verir ancak bunu çok kontrollü bir şekilde yapar. Çoğu dil istediğiniz zaman değiştirmenize izin verdiği için bu, yeni Rust geliştiricilerinin (Rustaceans) zorlandığı bir konudur. Bu kısıtlamaya sahip olmanın faydası, Rust’ın derleme zamanında veri yarışlarını (data races) önleyebilmesidir. Veri yarışı (data race), yarış koşuluna (race condition) benzer ve şu üç davranış meydana geldiğinde ortaya çıkar:
- İki veya daha fazla işaretçi aynı anda aynı verilere erişir.
- İşaretçilerden en az biri verilere yazmak için kullanılmaktadır.
- Verilere erişimi senkronize etmek için hiçbir mekanizma kullanılmamaktadır.
Veri yarışları tanımsız davranışlara (undefined behavior) neden olur ve bunları çalışma zamanında izlemeye çalışırken teşhis edip düzeltmek zor olabilir; Rust, veri yarışları içeren kodları derlemeyi reddederek bu sorunu baştan engeller!
Her zamanki gibi, yalnızca eşzamanlı (simultaneous) olmayan, birden çok değiştirilebilir referansa izin veren yeni bir kapsam oluşturmak için süslü parantezleri kullanabiliriz:
fn main() {
let mut metin = String::from("merhaba");
{
let r1 = &mut metin;
} // r1 burada kapsam dışına çıkar, bu yüzden hiçbir sorun olmadan yeni bir referans yapabiliriz.
let r2 = &mut metin;
}Rust, değiştirilebilir ve değiştirilemez referansları birleştirmek için de benzer bir kural uygular. Bu kod bir hatayla sonuçlanır:
fn main() {
let mut metin = String::from("merhaba");
let r1 = &metin; // sorun yok
let r2 = &metin; // sorun yok
let r3 = &mut metin; // BÜYÜK SORUN
println!("{r1}, {r2}, ve {r3}");
}İşte hata:
$ cargo run
Compiling ownership v0.1.0 ($PROJE/listings/ch04-understanding-ownership/no-listing-12-immutable-and-mutable-not-allowed)
error[E0502]: cannot borrow `metin` as mutable because it is also borrowed as immutable
--> src/main.rs:7:14
|
5 | let r1 = &metin; // sorun yok
| ------ immutable borrow occurs here
6 | let r2 = &metin; // sorun yok
7 | let r3 = &mut metin; // BÜYÜK SORUN
| ^^^^^^^^^^ mutable borrow occurs here
8 |
9 | println!("{r1}, {r2}, ve {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Vay canına! Aynı değere değiştirilemez bir referansımız varken, aynı zamanda değiştirilebilir bir referansımız da olamaz.
Değiştirilemez referans kullananlar, değerin aniden altlarından değişmesini beklemezler! Ancak, birden çok değiştirilemez referansa izin verilir çünkü sadece verileri okuyan hiç kimsenin, başka birinin verileri okumasını etkileme yeteneği yoktur.
Bir referansın kapsamının, tanıtıldığı yerden başladığına ve referansın son kullanıldığı zamana kadar devam ettiğine dikkat edin. Örneğin, değiştirilemez referansların son kullanımı, değiştirilebilir referans tanıtılmadan önce println! içinde olduğundan bu kod derlenecektir:
fn main() {
let mut metin = String::from("merhaba");
let r1 = &metin; // sorun yok
let r2 = &metin; // sorun yok
println!("{r1} ve {r2}");
// r1 ve r2 değişkenleri bu noktadan sonra kullanılmayacak.
let r3 = &mut metin; // sorun yok
println!("{r3}");
}Değiştirilemez referanslar r1 ve r2’nin kapsamları, en son kullanıldıkları println!’den sonra biter; bu da değiştirilebilir referans r3’ün yaratılmasından öncedir. Bu kapsamlar örtüşmez (overlap), dolayısıyla bu koda izin verilir: Derleyici, referansın kapsamın bitiminden önceki bir noktada artık kullanılmadığını anlayabilir.
Ödünç alma hataları zaman zaman sinir bozucu olsa da, bunun Rust derleyicisinin potansiyel bir bug’ı erkenden (çalışma zamanından ziyade derleme zamanında) göstermesi ve size tam olarak nerede sorun olduğunu bildirmesi olduğunu unutmayın. Böylece verilerinizin neden düşündüğünüz gibi olmadığını bulmak için iz sürmek zorunda kalmazsınız.
Sarkan Referanslar (Dangling References)
İşaretçileri olan dillerde, bazı bellekleri serbest bırakırken o belleğe giden bir işaretçiyi koruyarak yanlışlıkla bir sarkan işaretçi (dangling pointer) (muhtemelen başkasına verilmiş olan bellekteki bir konuma başvuran bir işaretçi) oluşturmak kolaydır. Rust’ta ise bunun aksine, derleyici referansların asla sarkan referanslar olmayacağını garanti eder: Bazı verilere bir referansınız varsa, derleyici verilere olan referansın kapsam dışına çıkmasından önce verilerin kapsam dışına çıkmamasını sağlayacaktır.
Rust’ın derleme zamanı hatasıyla bunları nasıl engellediğini görmek için sarkan bir referans oluşturmayı deneyelim:
fn main() {
let hicbire_referans = sarkan_isaretci();
}
fn sarkan_isaretci() -> &String {
let metin = String::from("merhaba");
&metin
}İşte hata:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn sarkan_isaretci() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn sarkan_isaretci() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn sarkan_isaretci() -> &String {
5 + fn sarkan_isaretci() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Bu hata mesajı henüz ele almadığımız bir özelliği ifade eder: ömürler. Ömürleri Bölüm 10’da ayrıntılı olarak tartışacağız. Ancak, ömürlerle ilgili kısımları göz ardı ederseniz, mesaj gerçekten de bu kodun neden sorun olduğuna dair temel ipucunu içerir:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
(bu fonksiyonun dönüş türü ödünç alınan bir değer içeriyor, ancak ödünç alınacağı bir değer yok)
sarkan_isaretci kodumuzun her aşamasında tam olarak ne olduğuna daha yakından bakalım:
fn main() {
let hicbire_referans = sarkan_isaretci();
}
fn sarkan_isaretci() -> &String {
// sarkan_isaretci, bir String'e referans döndürür
let metin = String::from("merhaba"); // metin yeni bir String'dir
&metin // String'e, yani metin'e bir referans döndürüyoruz
} // Burada metin kapsam dışına çıkar ve düşürülür (drop edilir), bu yüzden belleği gider.
// Tehlike!metin değişkeni sarkan_isaretci içinde oluşturulduğu için, sarkan_isaretci kodu bittiğinde metin’in bellekten tahsisi kaldırılacaktır (deallocated). Ancak ona bir referans döndürmeye çalıştık. Bu, bu referansın geçersiz bir String’e işaret edeceği anlamına gelir. Bu hiç iyi değil! Rust bunu yapmamıza izin vermeyecektir.
Buradaki çözüm doğrudan String’i döndürmektir:
fn main() {
let metin = sarkmayan_isaretci();
}
fn sarkmayan_isaretci() -> String {
let metin = String::from("merhaba");
metin
}Bu hiçbir sorun olmadan çalışır. Sahiplik dışarı taşınır ve hiçbir şeyin tahsisi kaldırılmaz.
Referans Kuralları
Referanslar hakkında tartıştıklarımızı özetleyelim:
- Herhangi bir zamanda, ya bir tane değiştirilebilir referansa ya da istediğiniz sayıda değiştirilemez referansa sahip olabilirsiniz.
- Referanslar her zaman geçerli olmalıdır.
Sırada, farklı bir referans türüne bakacağız: dilimler.
Dilim (Slice) Türü
Dilim Türü (The Slice Type)
Dilimler, bir koleksiyondaki bitişik bir eleman dizisine referans vermenizi sağlar. Bir dilim bir tür referanstır, bu nedenle sahipliği yoktur.
İşte küçük bir programlama problemi: Boşluklarla ayrılmış kelimelerden oluşan bir metin (string) alan ve o metinde bulduğu ilk kelimeyi döndüren bir fonksiyon yazın. Eğer fonksiyon metin içinde boşluk bulamazsa, tüm metin tek bir kelime olmalıdır, bu yüzden metnin tamamı döndürülmelidir.
Not: Dilimleri tanıtmak amacıyla, bu bölümde yalnızca ASCII karakterleri olduğunu varsayıyoruz; UTF-8 kullanımı ile ilgili daha kapsamlı bir tartışma Bölüm 8’deki “UTF-8 Kodlanmış Metni Stringler ile Saklamak” bölümünde yer almaktadır.
Dilimlerin çözeceği problemi anlamak için, dilim kullanmadan bu fonksiyonun imzasını nasıl yazacağımız üzerinde çalışalım:
fn ilk_kelime(metin: &String) -> ?ilk_kelime fonksiyonunun &String türünde bir parametresi var. Sahipliğe ihtiyacımız yok, o yüzden bu gayet uygundur. (İdiyomatik Rust’ta, fonksiyonlar ihtiyaç duymadıkça argümanlarının sahipliğini almazlar ve bunun nedenleri ilerledikçe netleşecektir.) Peki ne döndürmeliyiz? Bir metnin bir kısmından bahsetmenin gerçekten bir yolu yok. Ancak, bir boşlukla belirtilen kelimenin sonunun indeksini döndürebiliriz. Liste 4-7’de gösterildiği gibi bunu deneyelim.
fn ilk_kelime(metin: &String) -> usize {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return i;
}
}
metin.len()
}
fn main() {}String parametresine karşılık bir bayt indeksi değeri döndüren ilk_kelime fonksiyonuString’i eleman eleman incelememiz ve bir değerin boşluk olup olmadığını kontrol etmemiz gerektiğinden, as_bytes metodunu kullanarak String’imizi bir bayt dizisine dönüştürüyoruz.
fn ilk_kelime(metin: &String) -> usize {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return i;
}
}
metin.len()
}
fn main() {}Daha sonra, iter metodunu kullanarak bayt dizisi üzerinde bir yineleyici oluşturuyoruz:
fn ilk_kelime(metin: &String) -> usize {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return i;
}
}
metin.len()
}
fn main() {}Yineleyicileri Bölüm 13’te daha detaylı tartışacağız. Şimdilik iter’in bir koleksiyondaki her elemanı döndüren bir metot olduğunu ve enumerate’in iter sonucunu sarmaladığını ve bunun yerine her elemanı bir demetin parçası olarak döndürdüğünü bilin. enumerate’ten döndürülen demetin ilk elemanı indekstir ve ikinci eleman elemana bir referanstır. Bu, indeksi kendimiz hesaplamaktan biraz daha uygundur.
enumerate metodu bir demet döndürdüğü için, o demeti ayrıştırmak (destructure) amacıyla desenleri (patterns) kullanabiliriz. Desenler hakkında Bölüm 6’da daha fazla konuşacağız. for döngüsünde, demetteki indeks için i ve demetteki tek bayt için &oge olan bir desen belirtiyoruz. .iter().enumerate()’ten elemanın bir referansını aldığımız için desende & kullanırız.
for döngüsünün içinde, bayt literali (byte literal) sözdizimini kullanarak boşluğu temsil eden baytı ararız. Eğer bir boşluk bulursak, o konumu döndürürüz. Aksi takdirde, metin.len() kullanarak metnin uzunluğunu döndürürüz.
fn ilk_kelime(metin: &String) -> usize {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return i;
}
}
metin.len()
}
fn main() {}Artık metindeki ilk kelimenin sonunun indeksini bulmanın bir yoluna sahibiz, ancak bir sorun var. Tek başına bir usize döndürüyoruz, ancak bu yalnızca &String bağlamında anlamlı bir sayıdır. Başka bir deyişle, String’den ayrı bir değer olduğu için gelecekte de geçerli kalacağının garantisi yoktur. Liste 4-7’deki ilk_kelime fonksiyonunu kullanan Liste 4-8’deki programı inceleyelim.
fn ilk_kelime(metin: &String) -> usize {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return i;
}
}
metin.len()
}
fn main() {
let mut metin = String::from("merhaba dünya");
let kelime = ilk_kelime(&metin); // kelime 7 değerini alacak
metin.clear(); // bu, String'i boşaltır ve onu "" değerine eşitler
// kelime burada hala 7 değerine sahip, ancak metin'in 7 değeriyle
// anlamlı bir şekilde kullanabileceğimiz hiçbir içeriği kalmadı,
// yani kelime artık tamamen geçersiz!
}ilk_kelime fonksiyonunu çağırmaktan dönen sonucu saklayıp ardından String içeriğini değiştirmekBu program hiçbir hata olmadan derlenir ve metin.clear() çağırdıktan sonra kelime’yi kullansaydık da derlenirdi. kelime metin’in durumuna hiç bağlı olmadığı için, kelime hala 7 (veya "merhaba" kelimesinin uzunluğu) değerini içerir. İlk kelimeyi çıkarmayı denemek için metin değişkeni ile birlikte bu 7 değerini kullanabilirdik, ancak bu bir bug olurdu çünkü kelime’de 7’yi kaydettiğimizden bu yana metin’in içerikleri değişmiştir.
kelime’deki indeksin metin’deki verilerle senkronizasyonunun (uyumunun) bozulması konusunda endişelenmek yorucu ve hataya açıktır! Eğer bir ikinci_kelime fonksiyonu yazarsak bu indeksleri yönetmek daha da kırılgan (brittle) bir hal alır. İmzası şuna benzerdi:
fn ikinci_kelime(metin: &String) -> (usize, usize) {Artık bir başlangıç ve bir bitiş indeksini izliyoruz; belirli bir durumdaki verilerden hesaplanmış ancak o duruma hiçbir şekilde bağlı olmayan daha da fazla değerimiz var. Etrafta dolaşan ve senkronize tutulması gereken, birbiriyle ilgisiz üç değişkenimiz var.
Neyse ki Rust’ın bu soruna bir çözümü var: string dilimleri.
String Dilimleri (String Slices)
Bir string dilimi, bir String’in elemanlarının bitişik bir dizisine referanstır ve şuna benzer:
fn main() {
let metin = String::from("merhaba dünya");
let merhaba = &metin[0..7];
let dunya = &metin[8..13];
}Tüm String’e referans vermek yerine, merhaba, ekstra [0..7] bölümünde belirtilen String’in bir kısmına referanstır. Dilimleri [başlangıç_indeksi..bitiş_indeksi] belirterek köşeli parantezler içinde bir aralık kullanarak oluştururuz; burada başlangıç_indeksi dilimdeki ilk konumdur ve bitiş_indeksi dilimdeki son konumun bir fazlasıdır. Dahili olarak, dilim veri yapısı dilimin başlangıç konumunu ve uzunluğunu depolar; bu uzunluk bitiş_indeksi eksi başlangıç_indeksi değerine karşılık gelir. Yani, let dunya = &metin[8..13]; durumunda dunya, metin’in 8. indeksindeki bayta bir işaretçi ve 5 uzunluk değeri içeren bir dilim olacaktır.
Şekil 4-7 bunu bir diyagram halinde göstermektedir.

Şekil 4-7: String’in bir parçasına atıfta bulunan bir string dilimi
Rust’ın .. aralık sözdizimi ile, eğer indeks 0’dan başlamak istiyorsanız, iki noktadan önceki değeri bırakabilirsiniz. Başka bir deyişle, bunlar birbirine eşittir:
#![allow(unused)]
fn main() {
let metin = String::from("merhaba");
let dilim = &metin[0..2];
let dilim = &metin[..2];
}Aynı şekilde, diliminiz String’in son baytını içeriyorsa, sondaki sayıyı da bırakabilirsiniz. Bu, şunların eşit olduğu anlamına gelir:
#![allow(unused)]
fn main() {
let metin = String::from("merhaba");
let uzunluk = metin.len();
let dilim = &metin[3..uzunluk];
let dilim = &metin[3..];
}Tüm metnin bir dilimini almak için her iki değeri de bırakabilirsiniz. Dolayısıyla bunlar da eşittir:
#![allow(unused)]
fn main() {
let metin = String::from("merhaba");
let uzunluk = metin.len();
let dilim = &metin[0..uzunluk];
let dilim = &metin[..];
}Not: String dilim aralığı indeksleri geçerli UTF-8 karakter sınırlarında gerçekleşmelidir. Çok baytlı (multibyte) bir karakterin ortasında bir string dilimi oluşturmaya çalışırsanız, programınız bir hatayla çıkış yapacaktır.
Tüm bu bilgileri göz önünde bulundurarak, ilk_kelime’yi bir dilim döndürecek şekilde yeniden yazalım. “String dilimi“ni ifade eden tür &str olarak yazılır:
fn ilk_kelime(metin: &String) -> &str {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return &metin[0..i];
}
}
&metin[..]
}
fn main() {}Kelimenin sonu için indeksi Liste 4-7’de yaptığımız gibi, bir boşluğun ilk geçtiği yeri arayarak elde ederiz. Bir boşluk bulduğumuzda, metnin başlangıcını ve boşluğun indeksini sırasıyla başlangıç ve bitiş indeksleri olarak kullanarak bir string dilimi döndürürüz.
Artık ilk_kelime’yi çağırdığımızda, temel alınan (underlying) verilere bağlı tek bir değer geri alıyoruz. Bu değer, dilimin başlangıç noktasına yönelik bir referans ile dilimdeki eleman sayısından oluşur.
Bir dilim döndürmek ikinci_kelime fonksiyonu için de işe yarayacaktır:
fn ikinci_kelime(metin: &String) -> &str {Derleyici String içindeki referansların geçerli kalmasını sağlayacağından artık bozması çok daha zor olan basit bir API’ye sahibiz. Liste 4-8’deki programda yer alan ve ilk kelimenin sonunun indeksini aldığımız, ancak daha sonra metni boşalttığımızda indeksimizin geçersiz hale geldiği hatayı hatırlıyor musunuz? O kod mantıksal olarak yanlıştı ancak anında herhangi bir hata göstermemişti. İlk kelime indeksini boşaltılmış bir metinle birlikte kullanmaya devam etseydik, sorunlar daha sonra ortaya çıkacaktı. Dilimler bu hatayı imkansız kılar ve kodumuzla ilgili bir sorunumuz olduğunu çok daha erken bilmemizi sağlar. ilk_kelime’nin dilim sürümünü kullanmak bir derleme zamanı hatası fırlatır:
fn ilk_kelime(metin: &String) -> &str {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return &metin[0..i];
}
}
&metin[..]
}
fn main() {
let mut metin = String::from("merhaba dünya");
let kelime = ilk_kelime(&metin);
metin.clear(); // hata!
println!("ilk kelime: {kelime}");
}İşte derleyici hatası:
$ cargo run
Compiling ownership v0.1.0 ($PROJE/listings/ch04-understanding-ownership/no-listing-19-slice-error)
error[E0502]: cannot borrow `metin` as mutable because it is also borrowed as immutable
--> src/main.rs:19:5
|
17 | let kelime = ilk_kelime(&metin);
| ------ immutable borrow occurs here
18 |
19 | metin.clear(); // hata!
| ^^^^^^^^^^^^^ mutable borrow occurs here
20 |
21 | println!("ilk kelime: {kelime}");
| ------ immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ödünç alma kurallarını hatırlayın: Eğer bir şeye değiştirilemez bir referansımız varsa, ona ayrıca değiştirilebilir bir referans alamayız. clear’ın String’i kesmesi (truncate) gerektiği için değiştirilebilir bir referans alması gerekir. clear çağrısından sonraki println!, kelime’deki referansı kullanır, dolayısıyla o noktada değiştirilemez referansın hala aktif olması gerekir. Rust, clear’daki değiştirilebilir referans ile kelime’deki değiştirilemez referansın aynı anda var olmasına izin vermez ve derleme başarısız olur. Rust yalnızca API’mizi daha kolay kullanılır hale getirmekle kalmadı, aynı zamanda bütün bir hata sınıfını derleme zamanında ortadan kaldırdı!
Dilim Olarak Sabit Metinler (String Literals as Slices)
Sabit metinlerin (string literals) ikili dosya içinde saklandığından bahsettiğimizi hatırlayın. Artık dilimleri bildiğimize göre sabit metinleri uygun bir şekilde anlayabiliriz:
#![allow(unused)]
fn main() {
let metin = "Merhaba, dünya!";
}Buradaki metin değişkeninin türü &str’dir: İkili dosyanın belirli bir noktasına işaret eden bir dilimdir. Sabit metinlerin değiştirilemez olmasının nedeni de budur; &str değiştirilemez bir referanstır.
Parametre Olarak String Dilimleri
Sabitlerin (literals) ve String değerlerinin dilimlerini alabileceğinizi bilmek, ilk_kelime üzerinde yapacağımız bir iyileştirmeye, yani onun imzasına yönlendirir bizi:
fn ilk_kelime(metin: &String) -> &str {Daha tecrübeli bir Rust geliştiricisi bunun yerine Liste 4-9’da gösterilen imzayı yazardı, çünkü bu imza aynı fonksiyonu hem &String hem de &str değerleri üzerinde kullanmamıza olanak tanır.
fn ilk_kelime(metin: &str) -> &str {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return &metin[0..i];
}
}
&metin[..]
}
fn main() {
let benim_metnim = String::from("merhaba dünya");
// `ilk_kelime` `String`lerin dilimleri (kısmi veya tam) üzerinde çalışır.
let kelime = ilk_kelime(&benim_metnim[0..7]);
let kelime = ilk_kelime(&benim_metnim[..]);
// `ilk_kelime` ayrıca, `String`lerin tam dilimlerine eşdeğer olan
// `String` referansları üzerinde de çalışır.
let kelime = ilk_kelime(&benim_metnim);
let sabit_metnim = "merhaba dünya";
// `ilk_kelime` sabit metinlerin dilimleri (kısmi veya tam) üzerinde çalışır.
let kelime = ilk_kelime(&sabit_metnim[0..7]);
let kelime = ilk_kelime(&sabit_metnim[..]);
// Sabit metinler zaten metin dilimleri (string slices) olduğu için,
// bu da dilim sözdizimi olmadan çalışır!
let kelime = ilk_kelime(sabit_metnim);
}metin parametresi için bir string dilimi kullanarak ilk_kelime fonksiyonunu iyileştirmeEğer elimizde bir string dilimi varsa, bunu doğrudan geçirebiliriz. Eğer bir String’imiz varsa, bu String’in bir dilimini veya String’in referansını geçirebiliriz. Bu esneklik, Bölüm 15’teki “Fonksiyonlarda ve Metotlarda Deref Zorlamalarını Kullanma (Using Deref Coercions in Functions and Methods)” bölümünde ele alacağımız deref zorlamaları (deref coercions) özelliğinden yararlanır.
Bir fonksiyonu String referansı yerine bir string dilimi alacak şekilde tanımlamak, API’mizi hiçbir işlevselliğini kaybetmeden daha genel ve kullanışlı hale getirir:
fn ilk_kelime(metin: &str) -> &str {
let baytlar = metin.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return &metin[0..i];
}
}
&metin[..]
}
fn main() {
let benim_metnim = String::from("merhaba dünya");
// `ilk_kelime` `String`lerin dilimleri (kısmi veya tam) üzerinde çalışır.
let kelime = ilk_kelime(&benim_metnim[0..7]);
let kelime = ilk_kelime(&benim_metnim[..]);
// `ilk_kelime` ayrıca, `String`lerin tam dilimlerine eşdeğer olan
// `String` referansları üzerinde de çalışır.
let kelime = ilk_kelime(&benim_metnim);
let sabit_metnim = "merhaba dünya";
// `ilk_kelime` sabit metinlerin dilimleri (kısmi veya tam) üzerinde çalışır.
let kelime = ilk_kelime(&sabit_metnim[0..7]);
let kelime = ilk_kelime(&sabit_metnim[..]);
// Sabit metinler zaten metin dilimleri (string slices) olduğu için,
// bu da dilim sözdizimi olmadan çalışır!
let kelime = ilk_kelime(sabit_metnim);
}Diğer Dilimler (Other Slices)
String dilimleri tahmin edebileceğiniz gibi stringlere özgüdür. Ancak daha genel bir dilim türü de vardır. Şu diziyi (array) ele alalım:
#![allow(unused)]
fn main() {
let d = [1, 2, 3, 4, 5];
}Tıpkı bir stringin bir kısmına başvurmak (referans vermek) isteyebileceğimiz gibi, bir dizinin bir kısmına da başvurmak isteyebiliriz. Bunu şu şekilde yapardık:
#![allow(unused)]
fn main() {
let d = [1, 2, 3, 4, 5];
let dilim = &d[1..3];
assert_eq!(dilim, &[2, 3]);
}Bu dilim &[i32] türündedir. İlk elemana bir referans ve bir uzunluk depolayarak tıpkı string dilimlerinin çalıştığı gibi çalışır. Bu tür dilimleri her türlü diğer koleksiyon için kullanacaksınız. Bu koleksiyonları, Bölüm 8’de vektörler hakkında konuştuğumuzda ayrıntılı olarak tartışacağız.
Özet
Sahiplik, ödünç alma ve dilimler kavramları Rust programlarında bellek güvenliğini (memory safety) derleme zamanında sağlar. Rust dili, tıpkı diğer sistem programlama dilleri gibi bellek kullanımınız üzerinde size kontrol verir. Ancak, veri sahibinin kapsam dışına çıktığında o veriyi otomatik olarak temizlemesi, bu kontrolü elde etmek için ekstra kod yazıp ayıklamak zorunda olmadığınız anlamına gelir.
Sahiplik, Rust’ın diğer pek çok parçasının çalışma şeklini etkiler, bu nedenle kitabın geri kalanında bu kavramlar hakkında daha fazla konuşacağız. Şimdi Bölüm 5’e geçelim ve veri parçalarını bir struct içinde gruplandırmaya bakalım.
İlgili Verileri Yapılandırmak İçin Struct Kullanımı
Bir struct veya yapı, anlamlı bir grup oluşturan birden fazla ilgili değeri bir araya getirip isimlendirmenizi sağlayan özel bir veri türüdür. Nesne yönelimli (object-oriented) bir programlama diline aşinaysanız, struct bir nesnenin veri özelliklerine (data attributes) benzer. Bu bölümde, halihazırda bildiklerinizi geliştirmek için demetleri (tuples) struct’larla karşılaştıracak ve verileri gruplandırmak için struct’ların ne zaman daha iyi bir yol olduğunu göstereceğiz.
Struct’ların nasıl tanımlanacağını ve örnekleneceğini (instantiate) göstereceğiz. Bir struct türüyle ilişkili davranışları belirtmek için ilişkili fonksiyonların (associated functions), özellikle de metot (method) olarak adlandırılan türünün nasıl tanımlanacağını tartışacağız. Struct’lar ve enum’lar (Bölüm 6’da tartışılacaktır), Rust’ın derleme zamanı tür kontrolünden (compile-time type checking) tam anlamıyla yararlanmak üzere programınızın etki alanında (domain) yeni türler oluşturmak için temel yapı taşlarıdır.
Struct Tanımlama ve Örnekleme
Struct’ları Tanımlama ve Örnekleme (Defining and Instantiating Structs)
Struct’lar, “Demet Türü (The Tuple Type)” bölümünde tartışılan demetlere benzerler, her ikisi de birden fazla ilgili değeri bir arada tutar. Demetler gibi, bir struct’ın parçaları da farklı türlerde olabilir. Demetlerden farklı olarak, bir struct’ta her bir veri parçasını isimlendirirsiniz, böylece değerlerin ne anlama geldiği açıkça belli olur. Bu isimleri eklemek, struct’ların demetlerden daha esnek olduğu anlamına gelir: Bir örneğin değerlerini belirtmek veya onlara erişmek için verilerin sırasına güvenmek zorunda kalmazsınız.
Bir struct tanımlamak için struct anahtar kelimesini girer ve tüm struct’a bir isim veririz. Bir struct’ın adı, gruplandırılan veri parçalarının önemini (anlamını) açıklamalıdır. Daha sonra, süslü parantezler içinde, alanlar (fields) olarak adlandırdığımız veri parçalarının isimlerini ve türlerini tanımlarız. Örneğin, Liste 5-1 bir kullanıcı hesabı hakkında bilgi depolayan bir struct’ı göstermektedir.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn main() {}Kullanici struct’ı tanımıTanımladıktan sonra bir struct’ı kullanmak için, alanların her biri için somut değerler belirterek o struct’ın bir örneğini oluştururuz. Bir örnek oluştururken struct’ın adını belirtiriz ve ardından anahtar: değer (key: value) çiftlerini içeren süslü parantezler ekleriz; burada anahtarlar alanların adlarıdır ve değerler o alanlarda saklamak istediğimiz verilerdir. Alanları, struct’ta tanımladığımız sırayla belirtmek zorunda değiliz. Başka bir deyişle, struct tanımı tür için genel bir şablon gibidir ve örnekler, o türün değerlerini oluşturmak için bu şablonu belirli verilerle doldurur. Örneğin, Liste 5-2’de gösterildiği gibi belirli bir kullanıcı bildirebiliriz.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn main() {
let kullanici1 = Kullanici {
aktif: true,
kullanici_adi: String::from("birkullaniciadi123"),
eposta: String::from("birisi@example.com"),
giris_sayisi: 1,
};
}Kullanici struct’ının bir örneğini oluşturmakBir struct’tan belirli bir değeri almak için nokta gösterimini (dot notation) kullanırız. Örneğin, bu kullanıcının e-posta adresine erişmek için kullanici1.eposta kullanırız. Örnek değiştirilebilir ise, nokta gösterimini kullanıp belirli bir alana atama yaparak bir değeri değiştirebiliriz. Liste 5-3, değiştirilebilir bir Kullanici örneğinin eposta alanındaki değerin nasıl değiştirileceğini göstermektedir.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn main() {
let mut kullanici1 = Kullanici {
aktif: true,
kullanici_adi: String::from("birkullaniciadi123"),
eposta: String::from("birisi@example.com"),
giris_sayisi: 1,
};
kullanici1.eposta = String::from("baskaeposta@example.com");
}Kullanici örneğinin eposta alanındaki değeri değiştirmekTüm örneğin değiştirilebilir olması gerektiğine dikkat edin; Rust yalnızca belirli alanları değiştirilebilir olarak işaretlememize izin vermez. Herhangi bir ifadede olduğu gibi, bu yeni örneği örtük olarak (implicitly) döndürmek için fonksiyon gövdesindeki son ifade olarak struct’ın yeni bir örneğini oluşturabiliriz.
Liste 5-4, verilen e-posta ve kullanıcı adıyla bir Kullanici örneği döndüren bir kullanici_olustur fonksiyonunu göstermektedir. aktif alanı true değerini ve giris_sayisi 1 değerini alır.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn kullanici_olustur(eposta: String, kullanici_adi: String) -> Kullanici {
Kullanici {
aktif: true,
kullanici_adi: kullanici_adi,
eposta: eposta,
giris_sayisi: 1,
}
}
fn main() {
let kullanici1 = kullanici_olustur(
String::from("birisi@example.com"),
String::from("birkullaniciadi123"),
);
}Kullanici örneği döndüren bir kullanici_olustur fonksiyonuFonksiyon parametrelerine struct alanlarıyla aynı adı vermek mantıklıdır, ancak eposta ve kullanici_adi alan adlarını ve değişkenlerini tekrarlamak zorunda kalmak biraz yorucudur. Struct’ın daha fazla alanı olsaydı, her bir adı tekrarlamak daha da sinir bozucu olurdu. Neyse ki, kullanışlı bir kısaltma var!
Alan Başlatma Kısaltmasını Kullanmak (Using the Field Init Shorthand)
Liste 5-4’te parametre adları ve struct alan adları tam olarak aynı olduğundan, kullanici_olustur’u Liste 5-5’te gösterildiği gibi kullanici_adi ve eposta tekrarları olmadan tam olarak aynı davranacak şekilde yeniden yazmak için alan başlatma kısaltması (field init shorthand) sözdizimini kullanabiliriz.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn kullanici_olustur(eposta: String, kullanici_adi: String) -> Kullanici {
Kullanici {
aktif: true,
kullanici_adi,
eposta,
giris_sayisi: 1,
}
}
fn main() {
let kullanici1 = kullanici_olustur(
String::from("birisi@example.com"),
String::from("birkullaniciadi123"),
);
}kullanici_adi ve eposta parametreleri struct alanlarıyla aynı ada sahip olduğu için alan başlatma kısaltmasını kullanan bir kullanici_olustur fonksiyonuBurada, eposta adında bir alanı olan Kullanici struct’ının yeni bir örneğini oluşturuyoruz. eposta alanının değerini kullanici_olustur fonksiyonunun eposta parametresindeki değere ayarlamak istiyoruz. eposta alanı ve eposta parametresi aynı ada sahip olduğundan, eposta: eposta yerine sadece eposta yazmamız yeterlidir.
Struct Güncelleme Sözdizimi İle Örnekler Oluşturmak (Creating Instances with Struct Update Syntax)
Aynı türdeki başka bir örneğin değerlerinin çoğunu içeren, ancak bazılarını değiştiren yeni bir struct örneği oluşturmak genellikle yararlıdır. Bunu struct güncelleme sözdizimi (struct update syntax) kullanarak yapabilirsiniz.
İlk olarak, Liste 5-6’da güncelleme sözdizimi olmadan, kullanici2 içinde düzenli bir yolla nasıl yeni bir Kullanici örneği oluşturulacağını gösteriyoruz. eposta için yeni bir değer belirliyoruz ancak bunun dışında Liste 5-2’de oluşturduğumuz kullanici1’deki değerlerin aynısını kullanıyoruz.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn main() {
// --snip--
let kullanici1 = Kullanici {
eposta: String::from("birisi@example.com"),
kullanici_adi: String::from("birkullaniciadi123"),
aktif: true,
giris_sayisi: 1,
};
let kullanici2 = Kullanici {
aktif: kullanici1.aktif,
kullanici_adi: kullanici1.kullanici_adi,
eposta: String::from("baska@example.com"),
giris_sayisi: kullanici1.giris_sayisi,
};
}kullanici1’deki değerlerden biri hariç tümünü kullanarak yeni bir Kullanici örneği oluşturmakStruct güncelleme sözdizimini kullanarak, Liste 5-7’de gösterildiği gibi aynı etkiyi daha az kodla elde edebiliriz. .. sözdizimi, açıkça ayarlanmayan geri kalan alanların verilen örnekteki alanlarla aynı değere sahip olması gerektiğini belirtir.
struct Kullanici {
aktif: bool,
kullanici_adi: String,
eposta: String,
giris_sayisi: u64,
}
fn main() {
// --snip--
let kullanici1 = Kullanici {
eposta: String::from("birisi@example.com"),
kullanici_adi: String::from("birkullaniciadi123"),
aktif: true,
giris_sayisi: 1,
};
let kullanici2 = Kullanici {
eposta: String::from("baska@example.com"),
..kullanici1
};
}Kullanici örneği için yeni bir eposta değeri ayarlamak, ancak geri kalan değerleri kullanici1’den kullanmak için struct güncelleme sözdizimini kullanmakListe 5-7’deki kod, kullanici2’de eposta için farklı bir değere sahip olan ancak kullanici1’den alınan kullanici_adi, aktif ve giris_sayisi alanları için aynı değerlere sahip bir örnek oluşturur. ..kullanici1, kalan tüm alanların değerlerini kullanici1’deki karşılık gelen alanlardan alması gerektiğini belirtmek için en sona gelmelidir, ancak struct tanımındaki alanların sırasına bakılmaksızın istediğimiz kadar alan için herhangi bir sırada değer belirtebiliriz.
Struct güncelleme sözdiziminin tıpkı bir atama (assignment) işlemi gibi = kullandığına dikkat edin; bunun nedeni, veriyi “Değişkenlerin ve Verilerin Move İle Etkileşimi” bölümünde gördüğümüz gibi taşımasıdır (move). Bu örnekte, kullanici2 oluşturulduktan sonra artık kullanici1’i kullanamayız çünkü kullanici1’in kullanici_adi alanındaki String kullanici2’ye taşınmıştır. Eğer kullanici2’ye hem eposta hem de kullanici_adi için yeni String değerleri verseydik ve dolayısıyla kullanici1’den yalnızca aktif ve giris_sayisi değerlerini kullansaydık, o zaman kullanici2 oluşturulduktan sonra kullanici1 hala geçerli olurdu. Hem aktif hem de giris_sayisi, Copy trait’ini uygulayan türlerdir, bu nedenle “Sadece Stack Verisi: Copy (Stack-Only Data: Copy)” bölümünde tartıştığımız davranış uygulanacaktır. Ayrıca bu örnekte hala kullanici1.eposta kullanabiliriz çünkü değeri kullanici1’den dışarı taşınmamıştır (moved out).
Demet Struct’lar ile Farklı Türler Oluşturmak (Creating Different Types with Tuple Structs)
Rust ayrıca, demet struct’lar (tuple structs) olarak adlandırılan ve demetlere (tuples) benzeyen struct’ları da destekler. Demet struct’lar, struct adının sağladığı ek anlama sahiptir, ancak alanlarıyla ilişkili adları yoktur; bunun yerine, yalnızca alanların türlerine sahiptirler. Demet struct’lar, tüm demete bir isim vermek, demeti diğer demetlerden farklı bir tür yapmak istediğinizde ve her bir alanı normal bir struct’taki gibi isimlendirmenin gereksiz veya fazlalık (verbose) olacağı durumlarda kullanışlıdır.
Bir demet struct’ı tanımlamak için, struct anahtar kelimesiyle başlayın ve ardından struct adına ek olarak demetteki türleri belirtin. Örneğin, burada Renk ve Nokta adında iki demet struct tanımlayıp kullanıyoruz:
struct Renk(i32, i32, i32);
struct Nokta(i32, i32, i32);
fn main() {
let siyah = Renk(0, 0, 0);
let orijin = Nokta(0, 0, 0);
}siyah ve orijin değerlerinin, farklı demet struct’larının örnekleri oldukları için farklı türlerde olduklarına dikkat edin. Tanımladığınız her struct, kendi içinde yer alan alanlar aynı türlerde olsa bile, kendine has (kendi başına) bir türdür. Örneğin, Renk türünde bir parametre alan bir fonksiyon argüman olarak bir Nokta alamaz, her iki tür de üç i32 değerinden oluşsa bile. Bunun dışında demet struct örnekleri, bireysel parçalarına ayrıştırılabilmeleri (destructure) ve belirli bir değere erişmek için noktadan (.) sonra indeksi kullanılabilmeleri bakımından demetlere benzerler. Demetlerden farklı olarak, demet struct’ları ayrıştırdığınızda (destructure) struct’ın türünü belirtmenizi gerektirir. Örneğin, orijin noktasındaki değerleri x, y ve z adlı değişkenlere ayrıştırmak için let Nokta(x, y, z) = orijin; yazardık.
Birim Benzeri Struct’ları Tanımlamak (Defining Unit-Like Structs)
Hiçbir alanı olmayan struct’lar da tanımlayabilirsiniz! Bunlara “Demet Türü (The Tuple Type)” bölümünde bahsettiğimiz birim türe () benzer şekilde davrandıkları için birim benzeri struct’lar (unit-like structs) denir. Birim benzeri struct’lar, bazı türler üzerinde bir trait uygulamanız gerektiğinde ancak türün kendisinde saklamak istediğiniz herhangi bir veri olmadığında yararlı olabilir. Trait’leri Bölüm 10’da tartışacağız. İşte HerZamanEsit adında bir birim struct tanımlama ve örnekleme (instantiate) örneği:
struct HerZamanEsit;
fn main() {
let ozne = HerZamanEsit;
}HerZamanEsit’i tanımlamak için, struct anahtar kelimesini, istediğimiz ismi ve ardından bir noktalı virgül kullanırız. Süslü parantezlere veya normal parantezlere gerek yoktur! Daha sonra, benzer bir yolla (herhangi bir süslü veya normal parantez olmadan tanımladığımız adı kullanarak) ozne değişkeninde HerZamanEsit örneğini alabiliriz. Daha sonra bu tür için bir davranış (behavior) uygulayacağımızı, öyle ki HerZamanEsit’in her örneğinin başka herhangi bir türün her örneğine her zaman eşit olacağını hayal edin, belki de test amacıyla bilinen bir sonuca sahip olmak için. Bu davranışı uygulamak için hiçbir veriye ihtiyacımız olmazdı! Bölüm 10’da trait’leri nasıl tanımlayacağınızı ve bunları birim benzeri struct’lar dahil herhangi bir tür üzerinde nasıl uygulayacağınızı göreceksiniz.
Struct Verisinin Sahipliği (Ownership of Struct Data)
Liste 5-1’deki Kullanici struct tanımında, &str string dilimi türünden ziyade sahipliği olan String türünü kullandık. Bu bilinçli bir seçimdir çünkü bu struct’ın her bir örneğinin tüm verilerine sahip olmasını ve o verinin, tüm struct geçerli olduğu sürece geçerli olmasını istiyoruz.
Struct’ların başka bir şeye ait verilere referans depolaması da mümkündür, ancak bunu yapmak, Bölüm 10’da tartışacağımız bir Rust özelliği olan ömürlerin kullanılmasını gerektirir. Ömürler, bir struct tarafından referans verilen verilerin struct var olduğu sürece geçerli olmasını sağlar. Diyelim ki ömürleri belirtmeden bir struct içinde, src/main.rs dosyasındaki gibi bir referans saklamaya çalışıyorsunuz; bu çalışmayacaktır:
struct Kullanici {
aktif: bool,
kullanici_adi: &str,
eposta: &str,
giris_sayisi: u64,
}
fn main() {
let kullanici1 = Kullanici {
aktif: true,
kullanici_adi: "birkullaniciadi123",
eposta: "birisi@example.com",
giris_sayisi: 1,
};
}Derleyici ömür (lifetime) belirteçlerine ihtiyacı olduğundan şikayet edecektir:
$ cargo run
Compiling structs v0.1.0 (file:///projects/structs)
error[E0106]: missing lifetime specifier
--> src/main.rs:3:15
|
3 | kullanici_adi: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct Kullanici<'a> {
2 | aktif: bool,
3 ~ kullanici_adi: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:4:12
|
4 | eposta: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct Kullanici<'a> {
2 | aktif: bool,
3 | kullanici_adi: &str,
4 ~ eposta: &'a str,
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `structs` (bin "structs") due to 2 previous errors
Bölüm 10’da struct’lar içinde referans depolayabilmeniz için bu hataları nasıl düzelteceğinizi tartışacağız, ancak şimdilik &str gibi referanslar yerine String gibi sahip olunan türleri kullanarak bu gibi hataları düzelteceğiz.
Struct Kullanan Örnek Bir Program
Struct Kullanan Örnek Bir Program (An Example Program Using Structs)
Struct’ları ne zaman kullanmak isteyebileceğimizi anlamak için bir dikdörtgenin alanını hesaplayan bir program yazalım. Tekil değişkenler kullanarak başlayacağız ve ardından bunun yerine struct kullanana kadar programı yeniden düzenleyeceğiz.
Cargo ile dikdortgenler adında yeni bir ikili proje (binary project) oluşturalım; bu proje, piksel cinsinden belirtilen bir dikdörtgenin genişliğini ve yüksekliğini alıp dikdörtgenin alanını hesaplayacak. Liste 5-8, projemizin src/main.rs dosyasında tam olarak bunu yapmanın bir yolunu içeren kısa bir programı göstermektedir.
fn main() {
let genislik1 = 30;
let yukseklik1 = 50;
println!(
"Dikdörtgenin alanı {} kare pikseldir.",
alan(genislik1, yukseklik1)
);
}
fn alan(genislik: u32, yukseklik: u32) -> u32 {
genislik * yukseklik
}Şimdi bu programı cargo run komutunu kullanarak çalıştırın:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
Dikdörtgenin alanı 1500 kare pikseldir.
Bu kod, her bir boyutu parametre alan alan fonksiyonunu çağırarak dikdörtgenin alanını bulmada başarılıdır, ancak bu kodu net ve okunaklı hale getirmek için daha fazlasını yapabiliriz.
Bu kodun sorunu alan fonksiyonunun imzasında açıktır:
fn main() {
let genislik1 = 30;
let yukseklik1 = 50;
println!(
"Dikdörtgenin alanı {} kare pikseldir.",
alan(genislik1, yukseklik1)
);
}
fn alan(genislik: u32, yukseklik: u32) -> u32 {
genislik * yukseklik
}alan fonksiyonunun bir dikdörtgenin alanını hesaplaması gerekiyordu, ancak yazdığımız fonksiyonun iki parametresi var ve programımızın hiçbir yerinde parametrelerin birbiriyle ilişkili olduğu açık değil. Genişlik ve yüksekliği gruplandırmak çok daha okunaklı ve daha yönetilebilir olacaktır. Bölüm 3’teki “Demet Türü (The Tuple Type)” kısmında bunu yapmanın bir yolunu (demetleri kullanarak) tartışmıştık.
Demetlerle Yeniden Düzenleme (Refactoring with Tuples)
Liste 5-9 programımızın demet kullanan başka bir sürümünü gösterir.
fn main() {
let dikdortgen1 = (30, 50);
println!("Dikdörtgenin alanı {} kare pikseldir.", alan(dikdortgen1));
}
fn alan(boyutlar: (u32, u32)) -> u32 {
boyutlar.0 * boyutlar.1
}Bir bakıma bu program daha iyidir. Demetler biraz daha fazla yapı eklememize izin verir ve artık sadece tek bir argüman geçiriyoruz. Ancak başka bir açıdan bu sürüm daha az nettir: Demetler öğelerini isimlendirmez, bu nedenle demetin parçalarına indeksle ulaşmamız gerekir, bu da hesaplamamızı daha az açık hale getirir.
Genişlik ve yüksekliği karıştırmak alan hesaplaması için önemli olmaz, ancak dikdörtgeni ekrana çizmek isteseydik önemli olurdu! genislik’in demet indeksi 0 ve yukseklik’in demet indeksi 1 olduğunu akılda tutmamız gerekirdi. Kodu başkası kullansaydı, bunu anlaması ve aklında tutması onun için daha da zor olurdu. Kodumuzda verilerimizin anlamını yansıtmadığımız için artık hata yapmak daha kolaydır.
Struct’larla Yeniden Düzenleme (Refactoring with Structs)
Verileri etiketleyerek anlam katmak için struct’ları kullanırız. Liste 5-10’da gösterildiği gibi, kullandığımız demeti bütünü için bir ad ve parçaları için adlar olan bir struct’a dönüştürebiliriz.
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
println!("Dikdörtgenin alanı {} kare pikseldir.", alan(&dikdortgen1));
}
fn alan(dikdortgen: &Dikdortgen) -> u32 {
dikdortgen.genislik * dikdortgen.yukseklik
}Dikdortgen struct’ını tanımlamakBurada bir struct tanımladık ve ona Dikdortgen adını verdik. Süslü parantezler içinde alanları her ikisi de u32 türünde olan genislik ve yukseklik olarak tanımladık. Daha sonra, main içinde genişliği 30 ve yüksekliği 50 olan özel bir Dikdortgen örneği oluşturduk.
alan fonksiyonumuz artık türü bir Dikdortgen struct örneğinin değiştirilemez ödünç alınmış hali (immutable borrow) olan ve dikdortgen olarak adlandırdığımız tek bir parametreyle tanımlanmıştır. Bölüm 4’te bahsedildiği gibi, struct’ın sahipliğini almak yerine onu ödünç almak istiyoruz. Bu yolla main, dikdortgen1’in sahipliğini korur ve kullanmaya devam edebilir; işte bu yüzden fonksiyon imzasında ve fonksiyonu çağırdığımız yerde & işaretini kullanıyoruz.
alan fonksiyonu, Dikdortgen örneğinin genislik ve yukseklik alanlarına erişir (ödünç alınan bir struct örneğinin alanlarına erişmenin alan değerlerini taşımadığına dikkat edin, bu yüzden struct’ların sık sık ödünç alındığını görürsünüz). alan için fonksiyon imzamız artık tam olarak ne demek istediğimizi ifade eder: genislik ve yukseklik alanlarını kullanarak Dikdortgen’in alanını hesapla. Bu, genişlik ve yüksekliğin birbiriyle ilişkili olduğunu gösterir ve demet indeks değerleri 0 ve 1 kullanmak yerine değerlere açıklayıcı (descriptive) adlar verir. Bu durum, kodun netliği için büyük bir kazanımdır.
Türetilen Traitlerle Yararlı İşlevsellik Ekleme (Adding Functionality with Derived Traits)
Programımızı debug ederken (hata ayıklarken) bir Dikdortgen örneğini ekrana yazdırabilmek ve tüm alanlarının değerlerini görmek faydalı olurdu. Liste 5-11’de önceki bölümlerde kullandığımız gibi println! makrosunu kullanmayı deniyoruz. Ancak bu çalışmayacaktır.
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
println!("dikdortgen1 şöyledir: {dikdortgen1}");
}Dikdortgen örneğini ekrana yazdırmayı denemekBu kodu derlediğimizde şu ana mesajı içeren bir hata alırız:
error[E0277]: `Dikdortgen` doesn't implement `std::fmt::Display`
println! makrosu birçok çeşit biçimlendirme yapabilir ve varsayılan olarak süslü parantezler, println! makrosuna Display olarak bilinen biçimlendirmeyi (doğrudan son kullanıcı tüketimi için tasarlanmış çıktı) kullanmasını söyler. Şimdiye kadar gördüğümüz ilkel türler varsayılan olarak Display trait’ini uygular çünkü bir kullanıcıya 1’i veya diğer herhangi bir ilkel türü göstermenin yalnızca tek bir yolu vardır. Ancak struct’lar söz konusu olduğunda println! makrosunun çıktıyı biçimlendirme şekli daha az nettir, çünkü daha fazla görüntüleme olasılığı vardır: Virgül istiyor musunuz yoksa istemiyor musunuz? Süslü parantezleri yazdırmak ister misiniz? Tüm alanlar gösterilmeli mi? Bu belirsizlik (ambiguity) nedeniyle Rust ne istediğimizi tahmin etmeye çalışmaz ve struct’lar println! ve {} yer tutucusu (placeholder) ile kullanılacak, hali hazırda sağlanmış bir Display uygulamasına sahip değildir.
Hataları okumaya devam edersek şu yararlı notu (yardımcı notu) buluruz:
| |`Dikdortgen` cannot be formatted with the default formatter
| required by this formatting parameter
Hadi deneyelim! println! makro çağrısı artık şu şekilde görünecek: println!("dikdortgen1 şöyledir: {dikdortgen1:?}");. Süslü parantezlerin içine :? belirtecini (specifier) koymak, println!’e Debug adında bir çıktı biçimi kullanmak istediğimizi söyler. Debug trait’i, kodumuzu hata ayıklama sırasında değerini görebilmemiz için struct’ımızı geliştiriciler için yararlı olacak bir şekilde yazdırmamızı sağlar.
Kodu bu değişiklikle derleyin. Olamaz! Hâlâ hata alıyoruz:
error[E0277]: `Dikdortgen` doesn't implement `Debug`
Fakat derleyici bize yine de faydalı bir not veriyor:
| required by this formatting parameter
|
Rust hata ayıklama bilgilerini yazdırmak için işlevsellik içerir, ancak bu işlevselliği struct’ımız için kullanılabilir hale getirmek adına bunu (açıkça) kendimiz seçmeliyiz. Bunu yapmak için, Liste 5-12’de gösterildiği gibi struct tanımından hemen önce dış özniteliği (outer attribute) #[derive(Debug)] ekleriz.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
println!("dikdortgen1 şöyledir: {dikdortgen1:?}");
}Debug trait’ini türetmek için öznitelik eklemek ve hata ayıklama biçimlendirmesi kullanarak Dikdortgen örneğini yazdırmakArtık programı çalıştırdığımızda hiçbir hata almayacağız ve şu çıktıyı göreceğiz:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
dikdortgen1 şöyledir: Dikdortgen { genislik: 30, yukseklik: 50 }
Harika! En güzel çıktı olmayabilir, ancak bu örnekteki tüm alanların değerlerini gösterir, ki bu da hata ayıklama sırasında kesinlikle yardımcı olacaktır. Daha büyük struct’larımız olduğunda, okuması biraz daha kolay bir çıktıya sahip olmak yararlıdır; bu durumlarda, println! dizesinde {:?} yerine {:#?} kullanabiliriz. Bu örnekte {:#?} stilini kullanmak şu çıktıyı üretecektir:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
dikdortgen1 şöyledir: Dikdortgen {
genislik: 30,
yukseklik: 50,
}
Debug formatını kullanarak bir değeri yazdırmanın başka bir yolu da, bir ifadenin sahipliğini alan (println! referans alırken) ve kodunuzda söz konusu dbg! makro çağrısının nerede (dosya ve satır numarası olarak) gerçekleştiğini o ifadenin sonucunda elde edilen değerle birlikte ekrana yazdıran ve değerin sahipliğini geri döndüren dbg! makrosunu kullanmaktır.
Not:
dbg!makrosunu çağırmak, standart çıktı konsolu akışına (stdout) yazdıranprintln!’in aksine, standart hata konsolu akışına (stderr) yazdırır. Bölüm 12’deki “Hataları Standart Hata Çıktısına (Standard Error) Yönlendirmek” bölümündestderrvestdouthakkında daha fazla konuşacağız.
Burada, tüm dikdortgen1 struct’ının değerinin yanı sıra, genislik alanına atanan değere de ilgi duyduğumuz bir örnek var:
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let olcek = 2;
let dikdortgen1 = Dikdortgen {
genislik: dbg!(30 * olcek),
yukseklik: 50,
};
dbg!(&dikdortgen1);
}30 * olcek ifadesinin etrafına dbg! koyabiliriz ve dbg! ifadenin değerinin sahipliğini geri döndürdüğü için, genislik alanı sanki orada dbg! çağrısı yokmuş gibi aynı değeri alacaktır. dbg!’in dikdortgen1’in sahipliğini almasını istemiyoruz, bu yüzden bir sonraki çağrıda dikdortgen1’e bir referans kullanıyoruz. İşte bu örneğin çıktısının nasıl göründüğü:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * olcek = 60
[src/main.rs:14:5] &dikdortgen1 = Dikdortgen {
genislik: 60,
yukseklik: 50,
}
Çıktının ilk bölümünün, 30 * olcek ifadesinde hata ayıklaması yaptığımız src/main.rs dosyasındaki 10. satırdan geldiğini ve bu ifadenin sonucunun 60 olduğunu görebiliriz (tamsayılar için uygulanan Debug biçimlendirmesi yalnızca değerlerini yazdırmaktır). src/main.rs dosyasının 14. satırındaki dbg! çağrısı, Dikdortgen struct’ı olan &dikdortgen1’in değerini çıkarır. Bu çıktı, Dikdortgen türünün güzel (pretty) Debug biçimlendirmesini kullanır. dbg! makrosu, kodunuzun ne yaptığını anlamaya çalışırken gerçekten yararlı olabilir!
Debug trait’ine ek olarak, Rust, özel türlerimize yararlı davranışlar ekleyebilen, derive niteliğiyle birlikte kullanmamız için bize birkaç trait sağlamıştır. Bu trait’ler ve davranışları Ek C’de listelenmiştir. Özel davranışa sahip bu trait’lerin nasıl uygulanacağının yanı sıra Bölüm 10’da kendi trait’lerinizi nasıl oluşturacağınızı da ele alacağız. Ayrıca derive dışında birçok başka öznitelik de vardır; daha fazla bilgi için Rust Referansındaki “Öznitelikler (Attributes)” bölümüne bakın.
alan fonksiyonumuz çok spesifiktir: Sadece dikdörtgenlerin alanını hesaplar. Bu davranışı Dikdortgen yapımıza (struct) daha yakından bağlamak (tie) faydalı olacaktır çünkü başka hiçbir türle çalışmayacaktır. Şimdi alan fonksiyonunu Dikdortgen türümüzde tanımlanan bir alan metoduna dönüştürerek bu kodu yeniden düzenlemeye nasıl devam edebileceğimize bakalım.
Metotlar
Metotlar (Methods)
Metotlar fonksiyonlara oldukça benzer: Onları da fn anahtar kelimesi ve bir isimle tanımlarız, parametre alabilirler, bir değer döndürebilirler ve başka bir yerden çağrıldıklarında çalıştırılacak bazı kodlar barındırırlar. Ancak fonksiyonlardan farklı olarak metotlar, bir yapının (struct) (veya Bölüm 6 ve Bölüm 18’de göreceğimiz üzere bir enum veya trait nesnesinin) bağlamı içinde tanımlanırlar. Metotların ilk parametresi her zaman self olmalıdır; bu parametre, metodun üzerinde çağrıldığı yapı (struct) örneğini temsil eder.
Metot Sözdizimi (Method Syntax)
Hadi parametre olarak bir Dikdortgen örneği alan eski alan fonksiyonumuzu değiştirelim ve bunun yerine Liste 5-13’te gösterildiği gibi Dikdortgen yapısı (struct) üzerinde tanımlı bir alan metodu oluşturalım.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn alan(&self) -> u32 {
self.genislik * self.yukseklik
}
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
println!("Dikdörtgenin alanı {} metrekaredir.", dikdortgen1.alan());
}Dikdortgen struct’ı üzerinde bir alan metodu tanımlanmasıFonksiyonu Dikdortgen bağlamında tanımlamak için, Dikdortgen adına bir impl (uygulama/implementation) bloğu başlatıyoruz. Bu impl bloğu içindeki her şey Dikdortgen tipiyle ilişkilendirilecektir. Daha sonra alan fonksiyonunu impl süslü parantezlerinin içine taşıyoruz ve imzadaki ilk (ve bu durumda tek) parametreyi hem tanımda hem de gövdede self olacak şekilde değiştiriyoruz. Önceden alan fonksiyonunu çağırıp dikdortgen1’i argüman olarak ilettiğimiz main fonksiyonunun içinde, artık Dikdortgen örneğimiz üzerinde alan metodunu çağırmak için metot sözdizimini (method syntax) kullanabiliriz. Metot sözdizimi doğrudan örneğin adından sonra gelir: Bir nokta ekleriz, ardından metodun adını, parantezleri ve varsa argümanları yazarız.
alan metodunun imzasında dikdortgen: &Dikdortgen yerine &self kullanıyoruz. Buradaki &self, aslında self: &Self ifadesinin kısaltmasıdır. Bir impl bloğu içerisinde Self tipi, o impl bloğunun ait olduğu tipin kısa adıdır. Metotların ilk parametresinin adı self ve tipi Self olmak zorundadır; bu nedenle Rust, ilk parametre alanında bunu sadece self ismiyle kısaltmanıza olanak tanır. Ancak tıpkı dikdortgen: &Dikdortgen kullanımında olduğu gibi, bu metodun Self örneğini ödünç aldığını belirtmek için self kısaltmasının önüne & işareti koymamız gerektiğini unutmayın. Metotlar; aynen diğer parametrelerde olduğu gibi self’in sahipliğini alabilir, burada yaptığımız gibi self’i değiştirilemez şekilde ödünç alabilir veya self’i değiştirilebilir şekilde ödünç alabilirler.
Fonksiyon versiyonunda neden &Dikdortgen kullandıysak, burada da aynı nedenden ötürü &self kullandık: Sahipliği almak istemiyoruz; yalnızca yapıdaki verileri okumak istiyoruz, onlara yazmak istemiyoruz. Eğer metodun, çağrıldığı örneği değiştirmesini isteseydik, ilk parametre olarak &mut self kullanırdık. İlk parametre olarak sadece self kullanarak örneğin sahipliğini tamamen alan bir metot yazmak nadir görülen bir durumdur; bu teknik genellikle metot self’i başka bir şeye dönüştürdüğünde ve dönüşümden sonra çağıran kişinin orijinal örneği kullanmasını engellemek istediğinizde kullanılır.
Metot sözdiziminin sağladığı kolaylıklar ve her metodun imzasında self tipini tekrar etme zorunluluğunun ortadan kalkmasının yanı sıra, fonksiyonlar yerine metotları kullanmanın asıl ana nedeni kod organizasyonudur. Bir tipin örneğiyle yapabileceğimiz her şeyi tek bir impl bloğunda topladık. Böylece kodumuzu kullanacak kişilerin, Dikdortgen’in yeteneklerini kütüphanemizin çeşitli yerlerinde aramak zorunda kalmalarını engellemiş olduk.
Ayrıca, bir metoda yapının (struct) alanlarından (field) biriyle aynı ismi vermeyi de seçebiliriz. Örneğin, Dikdortgen üzerinde aynı zamanda genislik adında bir metot tanımlayabiliriz:
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn genislik(&self) -> bool {
self.genislik > 0
}
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
if dikdortgen1.genislik() {
println!(
"Dikdörtgenin sıfırdan büyük bir genişliği var; değeri: {}",
dikdortgen1.genislik
);
}
}Burada genislik metodunun, örnekteki genislik alanının değeri 0’dan büyükse true, 0 ise false döndürmesini istedik: Kısacası, bir alanı aynı isimli bir metot içinde herhangi bir amaçla kullanabiliriz. main fonksiyonunda, dikdortgen1.genislik ifadesinden sonra parantez kullandığımızda, Rust bizim genislik metodunu kastettiğimizi anlar. Parantez kullanmadığımızda ise Rust bizim genislik alanını (field) kastettiğimizi bilir.
Sıklıkla (ama her zaman değil), bir metoda yapıdaki alanla aynı ismi verdiğimizde, bu metodun yalnızca o alandaki değeri döndürmesini ve başka hiçbir şey yapmamasını isteriz. Bu tür metotlara alıcılar (getters) denir. Bazı diğer dillerin aksine Rust, yapı alanları için alıcıları (getter) otomatik olarak uygulamaz. Alıcılar faydalıdır, çünkü alanı gizli (private), ancak metodu açık yapabilirsiniz. Böylece bu alana sadece okunabilir (read-only) bir erişim sağlayarak onu tipin genel API’sinin bir parçası haline getirebilirsiniz. “Açık” ve “gizli” (private) kavramlarının ne olduğunu ve bir alanın veya metodun nasıl bu şekilde tasarlanacağını Bölüm 7’de tartışacağız.
-> Operatörüne Ne Oldu?
C ve C++ dillerinde metot çağırmak için iki farklı operatör kullanılır: Eğer metodu doğrudan obje üzerinde çağırıyorsanız ., eğer metodu objeye işaret eden bir işaretçi (pointer) üzerinden çağırıyorsanız ve önce işaretçinin referansını kaldırmanız (dereference) gerekiyorsa -> kullanırsınız. Diğer bir deyişle, eğer obje bir işaretçiyse, obje->bir_seyler_yap() ifadesi aslında (*obje).bir_seyler_yap() ifadesine benzer.
Rust’ta -> operatörünün doğrudan bir karşılığı yoktur; bunun yerine Rust’ta otomatik referans alma ve kaldırma (automatic referencing and dereferencing) adı verilen bir özellik vardır. Metot çağırma işlemi, Rust’ta bu davranışın görüldüğü nadir yerlerden biridir.
Sistem şu şekilde işler: Siz obje.bir_seyler_yap() şeklinde bir metot çağırdığınızda, Rust otomatik olarak &, &mut veya * işaretlerini ekleyerek obje’nin metodun imzasına uymasını sağlar. Yani, aşağıdaki iki ifade aslında tamamen aynıdır:
#![allow(unused)]
fn main() {
#[derive(Debug,Copy,Clone)]
struct Nokta {
x: f64,
y: f64,
}
impl Nokta {
fn mesafe(&self, diger: &Nokta) -> f64 {
let x_karesi = f64::powi(diger.x - self.x, 2);
let y_karesi = f64::powi(diger.y - self.y, 2);
f64::sqrt(x_karesi + y_karesi)
}
}
let n1 = Nokta { x: 0.0, y: 0.0 };
let n2 = Nokta { x: 5.0, y: 6.5 };
n1.mesafe(&n2);
(&n1).mesafe(&n2);
}İlk ifade göze çok daha temiz görünür. Bu otomatik referans alma davranışı sorunsuz çalışır çünkü metotların net bir alıcısı (receiver) vardır: self’in tipi. Metodun ismine ve alıcısına bakan Rust, bu metodun okuma (&self), değiştirme (&mut self) veya tüketme (self) işlemi yapıp yapmadığını kesin olarak anlayabilir. Rust’ın, metot alıcıları için ödünç almayı örtülü (implicit) hale getirmesi, sahiplik kurallarının pratikte çok daha ergonomik kullanılabilmesinin büyük bir parçasıdır.
Daha Fazla Parametre Alan Metotlar
Şimdi Dikdortgen yapımız üzerinde ikinci bir metot yazarak pratik yapalım. Bu kez, bir Dikdortgen örneğinin başka bir Dikdortgen örneğini parametre olarak almasını istiyoruz. Eğer ikinci Dikdortgen, tamamen self’in (yani birinci Dikdortgen’in) içine sığabiliyorsa true, sığamıyorsa false döndürmeli. Yani, kapsayabilir_mi metodunu tanımladığımızda, Liste 5-14’te gösterilen programı yazabilmek istiyoruz.
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
let dikdortgen2 = Dikdortgen {
genislik: 10,
yukseklik: 40,
};
let dikdortgen3 = Dikdortgen {
genislik: 60,
yukseklik: 45,
};
println!(
"dikdortgen1, dikdortgen2'yi kapsayabilir mi? {}",
dikdortgen1.kapsayabilir_mi(&dikdortgen2)
);
println!(
"dikdortgen1, dikdortgen3'ü kapsayabilir mi? {}",
dikdortgen1.kapsayabilir_mi(&dikdortgen3)
);
}kapsayabilir_mi metodunun kullanımıBeklenen çıktı aşağıdaki gibi olmalıdır; çünkü dikdortgen2’nin her iki boyutu da dikdortgen1’den küçüktür, ancak dikdortgen3 dikdortgen1’den daha geniştir:
dikdortgen1, dikdortgen2'yi kapsayabilir mi? true
dikdortgen1, dikdortgen3'ü kapsayabilir mi? false
Bir metot tanımlamak istediğimizi biliyoruz, bu yüzden bunu impl Dikdortgen bloğunun içine yazacağız. Metodun adı kapsayabilir_mi olacak ve parametre olarak başka bir Dikdortgen’in değiştirilemez referansını alacak. Parametrenin tipinin ne olması gerektiğini, metodu çağıran koda bakarak da anlayabiliriz: dikdortgen1.kapsayabilir_mi(&dikdortgen2) satırı argüman olarak &dikdortgen2’yi iletiyor, ki bu da bir Dikdortgen örneği olan dikdortgen2’nin değiştirilemez bir ödünç alımıdır. Bu oldukça mantıklı; çünkü sadece dikdortgen2’yi okumaya ihtiyacımız var (eğer yazmaya/değiştirmeye ihtiyacımız olsaydı değiştirilebilir -mutable- bir referans alırdık) ve kapsayabilir_mi metodunu çağırdıktan sonra dikdortgen2’yi tekrar kullanabilmek için main fonksiyonunun onun sahipliğini elinde tutmasını istiyoruz.
kapsayabilir_mi metodunun dönüş değeri bir Boolean (mantıksal değer) olacak ve metodun gövdesinde self’in genişlik ve yüksekliğinin, diğer Dikdortgen’in genişlik ve yüksekliğinden büyük olup olmadığını kontrol edeceğiz. Hadi Liste 5-13’teki impl bloğumuza yeni kapsayabilir_mi metodunu ekleyelim (Liste 5-15).
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn alan(&self) -> u32 {
self.genislik * self.yukseklik
}
fn kapsayabilir_mi(&self, diger: &Dikdortgen) -> bool {
self.genislik > diger.genislik && self.yukseklik > diger.yukseklik
}
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
let dikdortgen2 = Dikdortgen {
genislik: 10,
yukseklik: 40,
};
let dikdortgen3 = Dikdortgen {
genislik: 60,
yukseklik: 45,
};
println!(
"dikdortgen1, dikdortgen2'yi kapsayabilir mi? {}",
dikdortgen1.kapsayabilir_mi(&dikdortgen2)
);
println!(
"dikdortgen1, dikdortgen3'ü kapsayabilir mi? {}",
dikdortgen1.kapsayabilir_mi(&dikdortgen3)
);
}Dikdortgen üzerinde başka bir Dikdortgen örneğini parametre olarak alan kapsayabilir_mi metodunun uygulanmasıBu kodu Liste 5-14’teki main fonksiyonu ile birlikte çalıştırdığımızda istediğimiz çıktıyı alacağız. Metotlar, self parametresinden sonra eklediğimiz birden fazla parametreyi alabilirler ve bu parametreler tıpkı standart fonksiyonlardaki parametreler gibi çalışır.
İlişkili Fonksiyonlar (Associated Functions)
Bir impl bloğu içinde tanımlanan tüm fonksiyonlara ilişkili fonksiyonlar (associated functions) denir; çünkü bu fonksiyonlar impl kelimesinden sonra adı yazılan tiple ilişkilendirilmişlerdir. İlk parametresi self olmayan (ve dolayısıyla metot olmayan) ilişkili fonksiyonlar da tanımlayabiliriz. Bunlar metot değildir çünkü çalışmak için ilgili tipin bir örneğine ihtiyaç duymazlar. Biz zaten bu tarz bir fonksiyonu daha önce kullandık: String tipi üzerinde tanımlı olan String::from fonksiyonu.
Metot olmayan ilişkili fonksiyonlar genellikle, yapının yeni bir örneğini döndürecek “kurucular” (constructors) olarak kullanılırlar. Bunlara çoğunlukla new adı verilir, ancak new dilde yerleşik olarak bulunan veya özel bir anlam taşıyan bir kelime değildir. Örneğin, genişlik ve yükseklik için aynı değeri kullanan ve böylece bir kare oluşturmayı kolaylaştıran kare adında bir ilişkili fonksiyon tanımlayabiliriz. Bu sayede aynı değeri iki kez girmek zorunda kalmayız:
Dosya adı: src/main.rs
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn kare(boyut: u32) -> Self {
Self {
genislik: boyut,
yukseklik: boyut,
}
}
}
fn main() {
let k = Dikdortgen::kare(3);
}Dönüş tipindeki ve fonksiyon gövdesindeki Self anahtar kelimesi, impl anahtar kelimesinden sonra görünen tip için bir kısaltmadır; yani bu durumda Dikdortgen’i temsil eder.
Bu ilişkili fonksiyonu çağırmak için yapının (struct) adıyla birlikte :: sözdizimini kullanırız; let kare_obje = Dikdortgen::kare(3); buna güzel bir örnektir. Bu fonksiyon, yapı tarafından isim alanına (namespace) dahil edilmiştir: :: sözdizimi hem ilişkili fonksiyonlar hem de modüllerin oluşturduğu isim alanları (namespaces) için kullanılır. Modülleri Bölüm 7’de detaylıca tartışacağız.
Birden Fazla impl Bloğu
Her yapının (struct) birden fazla impl bloğuna sahip olmasına izin verilir. Örneğin, Liste 5-15, her metodun kendi ayrı impl bloğunda yer aldığı Liste 5-16’daki kodla tamamen eşdeğerdir.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn alan(&self) -> u32 {
self.genislik * self.yukseklik
}
}
impl Dikdortgen {
fn kapsayabilir_mi(&self, diger: &Dikdortgen) -> bool {
self.genislik > diger.genislik && self.yukseklik > diger.yukseklik
}
}
fn main() {
let dikdortgen1 = Dikdortgen {
genislik: 30,
yukseklik: 50,
};
let dikdortgen2 = Dikdortgen {
genislik: 10,
yukseklik: 40,
};
let dikdortgen3 = Dikdortgen {
genislik: 60,
yukseklik: 45,
};
println!(
"dikdortgen1, dikdortgen2'yi kapsayabilir mi? {}",
dikdortgen1.kapsayabilir_mi(&dikdortgen2)
);
println!(
"dikdortgen1, dikdortgen3'ü kapsayabilir mi? {}",
dikdortgen1.kapsayabilir_mi(&dikdortgen3)
);
}impl bloğu kullanılarak yeniden yazılmasıBurada metotları birden fazla impl bloğuna ayırmak için geçerli bir nedenimiz olmasa da, bu tamamen geçerli bir sözdizimidir. Jenerik tipleri ve özellikleri (traits) tartışacağımız Bölüm 10’da, birden fazla impl bloğunun oldukça faydalı olduğu durumları göreceğiz.
Özet
Yapılar (Structs), çalıştığınız problem alanına (domain) uygun ve anlamlı özel tipler oluşturmanızı sağlar. Yapıları kullanarak, birbiriyle ilişkili veri parçalarını birbirine bağlı tutabilir ve kodunuzu netleştirmek için her bir parçaya anlamlı bir isim verebilirsiniz. impl bloklarında ise tipinizle ilişkili fonksiyonları tanımlayabilirsiniz. Metotlar da bir tür ilişkili fonksiyondur ve yapı örneklerinizin sergileyeceği davranışları (behavior) belirlemenize olanak tanır.
Ancak özel tipler (custom types) oluşturmanın tek yolu yapılar (structs) değildir: Şimdi araç çantanıza yeni bir araç daha eklemek için Rust’ın enum özelliğine geçelim.
Enum’lar ve Desen Eşleştirme
Bu bölümde, enum olarak da adlandırılan numaralandırmalara bakacağız.
Enum’lar, olası varyantlarını (seçeneklerini) numaralandırarak bir tür tanımlamanıza olanak tanır. Öncelikle, bir enum’ın verilerle birlikte nasıl bir anlam ifade edebileceğini göstermek için bir enum tanımlayıp kullanacağız. Daha sonra, bir değerin bir şey ya da hiçbir şey (something or nothing) olabileceğini ifade eden Option adlı özellikle yararlı bir enum’ı inceleyeceğiz. Ardından, match ifadesindeki desen eşleştirmenin, bir enum’ın farklı değerleri için farklı kodlar çalıştırmayı nasıl kolaylaştırdığına bakacağız. Son olarak, if let yapısının kodunuzdaki enum’ları işlemek için kullanılabilecek ne kadar uygun ve özlü bir başka ifade (idiom) olduğunu ele alacağız.
Bir Enum Tanımlama
Bir Enum Tanımlama
Struct’ların (yapıların) size ilgili alanları ve verileri birlikte gruplandırmanın bir yolunu sunduğu gibi (örneğin genislik ve yukseklik değerlerine sahip bir Dikdortgen gibi), enum’lar da bir değerin olası değerler kümesinden biri olduğunu söylemenin bir yolunu sunar. Örneğin, Dikdortgen’in Daire ve Ucgen’i de içeren olası şekiller kümesinden biri olduğunu söylemek isteyebiliriz. Bunu yapmak için Rust, bu olasılıkları bir enum olarak kodlamamıza (encode) olanak tanır.
Kodda ifade etmek isteyebileceğimiz bir duruma bakalım ve enum’ların neden yararlı olduğunu ve bu durumda struct’lardan neden daha uygun olduğunu görelim. Diyelim ki IP adresleriyle çalışmamız gerekiyor. Şu anda IP adresleri için iki ana standart kullanılıyor: sürüm dört ve sürüm altı. Programımızın karşılaşacağı bir IP adresi için yalnızca bu olasılıklar söz konusu olduğundan, olası tüm varyantları numaralandırabiliriz (enumerate); numaralandırma da adını buradan alır.
Herhangi bir IP adresi sürüm dört veya sürüm altı adres olabilir, ancak aynı anda ikisi birden olamaz. IP adreslerinin bu özelliği enum veri yapısını uygun hale getirir çünkü bir enum değeri varyantlarından yalnızca biri olabilir. Hem sürüm dört hem de sürüm altı adresler temelde hala IP adresleridir, bu nedenle kod herhangi bir IP adresi türüne uygulanan durumları işlerken her ikisine de aynı tür olarak davranılmalıdır.
Bu kavramı, kodda bir IpAdresTuru (IpAddrKind) numaralandırması tanımlayıp bir IP adresinin olabileceği olası türleri olan V4 ve V6’yı listeleyerek ifade edebiliriz. Bunlar enum’ın varyantlarıdır:
enum IpAdresTuru {
V4,
V6,
}
fn main() {
let dort = IpAdresTuru::V4;
let alti = IpAdresTuru::V6;
yonlendir(IpAdresTuru::V4);
yonlendir(IpAdresTuru::V6);
}
fn yonlendir(ip_turu: IpAdresTuru) {}IpAdresTuru, artık kodumuzun başka yerlerinde kullanabileceğimiz özel bir veri türüdür.
Enum Değerleri
IpAdresTuru’nün iki varyantının her birinin örneklerini şu şekilde oluşturabiliriz:
enum IpAdresTuru {
V4,
V6,
}
fn main() {
let dort = IpAdresTuru::V4;
let alti = IpAdresTuru::V6;
yonlendir(IpAdresTuru::V4);
yonlendir(IpAdresTuru::V6);
}
fn yonlendir(ip_turu: IpAdresTuru) {}Enum varyantlarının kendi tanımlayıcısı altında adlandırıldığına ve ikisini ayırmak için çift iki nokta üst üste (::) kullandığımıza dikkat edin. Bu faydalıdır çünkü artık IpAdresTuru::V4 ve IpAdresTuru::V6 değerlerinin her ikisi de aynı türdendir: IpAdresTuru. Daha sonra, örneğin, herhangi bir IpAdresTuru alan bir fonksiyon tanımlayabiliriz:
enum IpAdresTuru {
V4,
V6,
}
fn main() {
let dort = IpAdresTuru::V4;
let alti = IpAdresTuru::V6;
yonlendir(IpAdresTuru::V4);
yonlendir(IpAdresTuru::V6);
}
fn yonlendir(ip_turu: IpAdresTuru) {}Ve bu fonksiyonu her iki varyantla da çağırabiliriz:
enum IpAdresTuru {
V4,
V6,
}
fn main() {
let dort = IpAdresTuru::V4;
let alti = IpAdresTuru::V6;
yonlendir(IpAdresTuru::V4);
yonlendir(IpAdresTuru::V6);
}
fn yonlendir(ip_turu: IpAdresTuru) {}Enum kullanmanın daha da fazla avantajı vardır. IP adresi türümüz hakkında daha fazla düşünürsek, şu anda asıl IP adresi verisini depolamak için bir yolumuz yok; sadece hangi tür olduğunu biliyoruz. Bölüm 5’te struct’ları yeni öğrendiğiniz için, Liste 6-1’de gösterildiği gibi bu sorunu struct’larla çözmek isteyebilirsiniz.
fn main() {
enum IpAdresTuru {
V4,
V6,
}
struct IpAdres {
tur: IpAdresTuru,
adres: String,
}
let ev = IpAdres {
tur: IpAdresTuru::V4,
adres: String::from("127.0.0.1"),
};
let geridongu = IpAdres {
tur: IpAdresTuru::V6,
adres: String::from("::1"),
};
}IpAdresTuru varyantını struct kullanarak saklamaBurada, iki alana sahip bir IpAdres (IpAddr) struct’ı tanımladık: IpAdresTuru (daha önce tanımladığımız enum) türünde bir tur (kind) alanı ve String türünde bir adres alanı. Bu struct’ın iki örneği var. İlki ev’dir ve tur değeri olarak IpAdresTuru::V4’e, ilişkili adres verisi olarak da 127.0.0.1 değerine sahiptir. İkinci örnek ise geridongu’dur (loopback). Bu örnek, tur değeri olarak IpAdresTuru’nün diğer varyantı olan V6’ya sahiptir ve bununla ilişkili ::1 adresini barındırır. tur ve adres değerlerini bir araya toplamak için bir struct kullandık, böylece artık varyant değerle ilişkilendirilmiş oldu.
Bununla birlikte, aynı kavramı sadece bir enum kullanarak ifade etmek daha kısa ve özlüdür: Bir struct’ın içine bir enum koymak yerine, verileri doğrudan her bir enum varyantının içine koyabiliriz. IpAdres enum’ının bu yeni tanımı, hem V4 hem de V6 varyantlarının ilişkili String değerlerine sahip olacağını belirtir:
fn main() {
enum IpAdres {
V4(String),
V6(String),
}
let ev = IpAdres::V4(String::from("127.0.0.1"));
let geridongu = IpAdres::V6(String::from("::1"));
}Verileri doğrudan enum’ın her bir varyantına ekliyoruz, bu nedenle fazladan bir struct’a gerek kalmaz. Burada, enum’ların nasıl çalıştığına dair başka bir ayrıntıyı görmek de daha kolaydır: Tanımladığımız her enum varyantının adı, aynı zamanda o enum’ın bir örneğini oluşturan bir fonksiyon haline gelir. Yani, IpAdres::V4(), bir String argümanı alan ve IpAdres türünde bir örnek döndüren bir fonksiyon çağrısıdır. Enum’ı tanımladığımız için bu kurucu (constructor) fonksiyon otomatik olarak tanımlanmış olarak gelir.
Struct yerine enum kullanmanın başka bir avantajı daha vardır: Her varyant farklı türlerde ve miktarlarda ilişkili verilere sahip olabilir. Sürüm dört IP adresleri her zaman 0 ile 255 arasında değerlere sahip dört sayısal bileşene sahip olacaktır. V4 adreslerini dört u8 değeri olarak depolamak isteyip V6 adreslerini yine de tek bir String değeri olarak ifade etmek isteseydik, bunu bir struct ile yapamazdık. Enum’lar bu durumu kolaylıkla halleder:
fn main() {
enum IpAdres {
V4(u8, u8, u8, u8),
V6(String),
}
let ev = IpAdres::V4(127, 0, 0, 1);
let geridongu = IpAdres::V6(String::from("::1"));
}Sürüm dört ve sürüm altı IP adreslerini depolamak üzere veri yapılarını tanımlamanın birkaç farklı yolunu gösterdik. Ancak ortaya çıktığı üzere, IP adreslerini depolamak ve hangi türde olduklarını kodlamak o kadar yaygındır ki, standart kütüphanede kullanabileceğimiz bir tanım vardır! Gelin standart kütüphanenin IpAddr’ı nasıl tanımladığına bakalım. Bizim tanımladığımız ve kullandığımız enum ve varyantların aynısına sahiptir, ancak adres verilerini varyantların içine her varyant için farklı şekilde tanımlanan iki farklı struct biçiminde gömer:
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}Bu kod, bir enum varyantının içine her tür veriyi koyabileceğinizi göstermektedir: örneğin string’ler, sayısal türler veya struct’lar. Hatta içine başka bir enum bile ekleyebilirsiniz! Ayrıca, standart kütüphane türleri genellikle sizin bulacağınızdan çok daha karmaşık değildir.
Standart kütüphane IpAddr için bir tanım içerse de, standart kütüphanenin tanımını kapsamımıza dahil etmediğimiz için yine de kendi tanımımızı oluşturup çakışma olmadan kullanabileceğimizi unutmayın. Türleri kapsama getirme konusunu Bölüm 7’de daha ayrıntılı olarak ele alacağız.
Liste 6-2’de başka bir enum örneğine bakalım: Bunun varyantlarına gömülü çok çeşitli türleri vardır.
enum Mesaj {
Cik,
Tasi { x: i32, y: i32 },
Yaz(String),
RenkDegistir(i32, i32, i32),
}
fn main() {}Mesaj enum’ıBu enum’ın farklı türlere sahip dört varyantı vardır:
Cik: Kendisiyle ilişkili hiçbir veriye sahip değildir.Tasi: Tıpkı bir struct’ta olduğu gibi isimlendirilmiş alanlara sahiptir.Yaz: Tek birStringiçerir.RenkDegistir: Üç adeti32değeri içerir.
Liste 6-2’deki gibi varyantlara sahip bir enum tanımlamak, farklı türlerde struct tanımları tanımlamaya benzer, tek fark enum’ın struct anahtar kelimesini kullanmaması ve tüm varyantların Mesaj türü altında birlikte gruplandırılmasıdır. Aşağıdaki struct’lar önceki enum varyantlarının tuttuğu aynı verileri tutabilirdi:
struct CikMesaji; // birim (unit) struct
struct TasiMesaji {
x: i32,
y: i32,
}
struct YazMesaji(String); // demet (tuple) struct
struct RenkDegistirMesaji(i32, i32, i32); // demet (tuple) struct
fn main() {}Ancak her biri kendi türüne sahip olan bu farklı struct’ları kullansaydık, bu mesaj türlerinden herhangi birini alacak bir fonksiyonu, tek bir tür olan Liste 6-2’deki Mesaj enum’ı ile tanımladığımız kadar kolay tanımlayamazdık.
Enum’lar ve struct’lar arasında bir benzerlik daha vardır: Tıpkı struct’larda impl kullanarak metotlar tanımlayabildiğimiz gibi, enum’larda da metotlar tanımlayabiliriz. İşte Mesaj enum’ımızda tanımlayabileceğimiz cagir adlı bir metot:
fn main() {
enum Mesaj {
Cik,
Tasi { x: i32, y: i32 },
Yaz(String),
RenkDegistir(i32, i32, i32),
}
impl Mesaj {
fn cagir(&self) {
// metot gövdesi burada tanımlanabilir
}
}
let m = Mesaj::Yaz(String::from("merhaba"));
m.cagir();
}Metodun gövdesi, metodu çağırdığımız değeri elde etmek için self kullanacaktır. Bu örnekte, Mesaj::Yaz(String::from("merhaba")) değerine sahip bir m değişkeni oluşturduk; m.cagir() çalıştığında cagir metodunun gövdesinde self’in değeri bu olacaktır.
Standart kütüphanede çok yaygın ve kullanışlı olan başka bir enum’a bakalım: Option.
Option Enum’ı
Bu bölüm, standart kütüphane tarafından tanımlanan başka bir enum olan Option için bir örnek olay incelemesi yapmaktadır. Option türü, bir değerin bir şey olabileceği veya hiçbir şey olamayacağı son derece yaygın senaryoyu kodlar.
Örneğin, boş olmayan bir listedeki ilk öğeyi isterseniz, bir değer alırsınız. Boş bir listedeki ilk öğeyi isterseniz, hiçbir şey alamazsınız. Bu kavramı tür sistemi açısından ifade etmek, derleyicinin ele almanız gereken tüm durumları ele alıp almadığınızı kontrol edebileceği anlamına gelir; bu işlevsellik, diğer programlama dillerinde son derece yaygın olan hataları (bug) önleyebilir.
Programlama dili tasarımı genellikle hangi özellikleri dahil ettiğiniz açısından düşünülür, ancak hariç tuttuğunuz özellikler de önemlidir. Rust, diğer birçok dilin sahip olduğu null (boş) özelliğine sahip değildir. Null, orada hiçbir değer olmadığı anlamına gelen bir değerdir. Null içeren dillerde değişkenler her zaman iki durumdan birinde olabilir: null veya null olmayan (not-null).
Null değerinin mucidi Tony Hoare, 2009’daki “Null Referanslar: Milyar Dolarlık Hata” (“Null References: The Billion Dollar Mistake”) adlı sunumunda şunları söylemiştir:
Buna benim milyar dolarlık hatam diyorum. O zamanlar nesne yönelimli (object-oriented) bir dilde referanslar için ilk kapsamlı tür sistemini tasarlıyordum. Amacım, derleyici tarafından otomatik olarak gerçekleştirilen kontrollerle, referansların tüm kullanımlarının kesinlikle güvenli olmasını sağlamaktı. Ancak, uygulaması çok kolay olduğu için null referans ekleme cazibesine karşı koyamadım. Bu, muhtemelen son kırk yılda bir milyar dolarlık acıya ve hasara neden olan sayısız hataya, güvenlik açığına ve sistem çökmesine yol açtı.
Null değerleriyle ilgili sorun, null değerini null olmayan bir değer olarak kullanmaya çalışırsanız, bir tür hata almanızdır. Bu null veya null olmama özelliği yaygın olduğundan (pervasive), bu tür bir hata yapmak son derece kolaydır.
Ancak null’un ifade etmeye çalıştığı kavram hala yararlıdır: Null, şu anda herhangi bir nedenle geçersiz olan veya olmayan (absent) bir değerdir.
Sorun aslında kavramda değil, belirli uygulamadadır. Bu nedenle Rust’ta null yoktur, ancak bir değerin var veya yok olması kavramını kodlayabilen bir enum’a sahiptir. Bu enum Option<T>’dir ve standart kütüphane tarafından şu şekilde tanımlanır:
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}Option<T> enum’ı o kadar faydalıdır ki prelude (başlangıç) kütüphanesine bile dahil edilmiştir; açıkça (explicitly) kapsama dahil etmenize gerek yoktur. Varyantları da prelude kütüphanesine dahildir: Some ve None’ı Option:: öneki olmadan doğrudan kullanabilirsiniz. Option<T> enum’ı hala sadece normal bir enum’dır ve Some(T) ve None hala Option<T> türünün varyantlarıdır.
<T> sözdizimi, Rust’ın henüz bahsetmediğimiz bir özelliğidir. Bu genel (generic) bir tür parametresidir ve Bölüm 10’da jenerikleri daha ayrıntılı olarak ele alacağız. Şimdilik bilmeniz gereken tek şey, <T>’nin Option enum’ının Some varyantının herhangi bir türden bir veri tutabileceği anlamına geldiği ve T yerine kullanılan her somut (concrete) türün genel Option<T> türünü farklı bir tür haline getirdiğidir. Sayı türlerini ve karakter (char) türlerini tutmak için Option değerlerinin kullanıldığı bazı örnekler:
fn main() {
let bir_sayi = Some(5);
let bir_karakter = Some('e');
let olmayan_sayi: Option<i32> = None;
}bir_sayi değişkeninin türü Option<i32>’dir. bir_karakter değişkeninin türü ise farklı bir tür olan Option<char>’dır. Some varyantının içinde bir değer belirttiğimiz için Rust bu türleri çıkarabilir. olmayan_sayi için Rust bizden genel Option türünü açıklamamızı ister: Derleyici, yalnızca bir None değerine bakarak karşılık gelen Some varyantının tutacağı türü çıkaramaz. Burada, Rust’a olmayan_sayi’nın Option<i32> türünde olmasını kastettiğimizi söyleriz.
Bir Some değerimiz olduğunda, bir değerin mevcut olduğunu ve değerin Some içinde tutulduğunu biliriz. Bir None değerimiz olduğunda ise bu, bazı açılardan null ile aynı anlama gelir: Geçerli bir değerimiz yoktur. Peki, Option<T>’ye sahip olmak null’a sahip olmaktan neden daha iyidir?
Kısaca, Option<T> ve T (burada T herhangi bir tür olabilir) farklı türler olduğundan, derleyici bir Option<T> değerini sanki kesinlikle geçerli bir değermiş gibi kullanmamıza izin vermez. Örneğin, aşağıdaki kod derlenmeyecektir, çünkü bir Option<i8>’e bir i8 eklemeye çalışmaktadır:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let toplam = x + y;
}Eğer bu kodu çalıştırırsak, şuna benzer bir hata mesajı alırız:
$ cargo run
Compiling enums v0.1.0 ($PROJE/listings/ch06-enums-and-pattern-matching/no-listing-07-cant-use-option-directly)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:6:20
|
6 | let toplam = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
help: the following other types implement trait `Add<Rhs>`
--> $HOME/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/ops/arith.rs:99:9
|
99 | impl const Add for $t {
| ^^^^^^^^^^^^^^^^^^^^^ `i8` implements `Add`
...
114 | add_impl! { usize u8 u16 u32 u64 u128 isize i8 i16 i32 i64 i128 f16 f32 f64 f128 }
| ---------------------------------------------------------------------------------- in this macro invocation
|
::: $HOME/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/internal_macros.rs:22:9
|
22 | impl const $imp<$u> for &$t {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^ `&i8` implements `Add<i8>`
...
33 | impl const $imp<&$u> for $t {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^ `i8` implements `Add<&i8>`
...
44 | impl const $imp<&$u> for &$t {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `&i8` implements `Add`
= note: this error originates in the macro `add_impl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Sert! Aslında bu hata mesajı, Rust’ın farklı türlerde oldukları için bir i8 ile bir Option<i8>’i nasıl toplayacağını anlamadığı anlamına gelir. Rust’ta i8 gibi bir türde değere sahip olduğumuzda, derleyici her zaman geçerli bir değere sahip olduğumuzdan emin olur. Bu değeri kullanmadan önce null olup olmadığını kontrol etmek zorunda kalmadan güvenle devam edebiliriz. Yalnızca bir Option<i8>’e (veya üzerinde çalıştığımız değerin türü her neyse) sahip olduğumuzda bir değere sahip olmama ihtimalinden endişe duymalıyız; derleyici bu değeri kullanmadan önce bu durumu ele aldığımızdan emin olacaktır.
Başka bir deyişle, bir Option<T> ile T işlemleri gerçekleştirebilmeniz için onu bir T’ye dönüştürmeniz gerekir. Genellikle bu, null ile ilgili en yaygın sorunlardan birini yakalamaya yardımcı olur: Bir şeyin aslında null olduğu halde null olmadığını varsaymak.
Null olmayan (not-null) bir değeri yanlış varsayma riskini ortadan kaldırmak, kodunuza daha fazla güvenmenize yardımcı olur. Null olabilme ihtimali olan bir değere sahip olmak için, o değerin türünü Option<T> yaparak bu durumu açıkça (explicitly) belirtmeniz (opt in) gerekir. Daha sonra, o değeri kullandığınızda, değerin null olduğu durumu açıkça ele almanız istenir. Değerin Option<T> olmayan bir türe sahip olduğu her yerde, değerin null olmadığını güvenle varsayabilirsiniz. Bu, Rust’ta null’un yaygınlığını sınırlamak ve Rust kodunun güvenliğini artırmak için bilinçli (deliberate) olarak verilmiş bir tasarım kararıydı.
Peki, bu değeri kullanabilmek için Option<T> türünde bir değere sahip olduğunuzda T değerini bir Some varyantından nasıl çıkarırsınız? Option<T> enum’ı, çeşitli durumlarda yararlı olan çok sayıda metoda sahiptir; bunları belgelerinden inceleyebilirsiniz. Option<T> üzerindeki metotlara aşina olmak, Rust yolculuğunuzda son derece yararlı olacaktır.
Genel olarak, bir Option<T> değerini kullanmak için, her bir varyantı ele alacak bir koda sahip olmak istersiniz. Yalnızca Some(T) değeriniz olduğunda çalışacak bir kod istersiniz ve bu kodun içteki (inner) T’yi kullanmasına izin verilir. Yalnızca None değeriniz varsa çalışacak başka bir kod istersiniz ve bu kodda kullanılabilecek bir T değeri yoktur. match ifadesi, enum’larla kullanıldığında tam olarak bunu yapan bir kontrol akışı yapısıdır: Sahip olduğu enum’ın hangi varyantına bağlı olarak farklı kodlar çalıştıracaktır ve bu kod eşleşen değerin içindeki verileri kullanabilir.
match Kontrol Akışı Yapısı
match Kontrol Akışı Yapısı
Rust, bir değeri bir dizi desenle (pattern) karşılaştırmanıza ve ardından hangi desenin eşleştiğine bağlı olarak kod yürütmenize olanak tanıyan, match adı verilen son derece güçlü bir kontrol akışı (control flow) yapısına sahiptir. Desenler; sabit değerlerden (literal values), değişken adlarından, joker karakterlerden (wildcards) ve daha birçok şeyden oluşabilir; Bölüm 19 farklı desen türlerinin hepsini ve ne işe yaradıklarını ele almaktadır. match’in gücü, desenlerin ifade gücünden ve derleyicinin olası tüm durumların ele alındığını (handle edildiğini) doğrulamasından gelir.
Bir match ifadesini bozuk para ayırma makinesi gibi düşünün: Madeni paralar, üzerinde çeşitli boyutlarda delikler bulunan bir raydan aşağı kayar ve her bir para, sığdığı karşılaştığı ilk delikten aşağı düşer. Aynı şekilde, değerler de bir match içindeki her bir desenden geçer ve değerin “sığdığı” ilk desende, yürütme sırasında kullanılmak üzere ilişkili kod bloğuna düşer.
Madeni paralardan bahsetmişken, match kullanarak onları bir örnek olarak kullanalım! Liste 6-3’te gösterildiği gibi, bilinmeyen bir ABD madeni parasını alan ve sayma makinesine benzer bir şekilde hangi para olduğunu belirleyip değerini kuruş (cent) cinsinden döndüren bir fonksiyon yazabiliriz.
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus,
}
fn kurus_degeri(para: MadeniPara) -> u8 {
match para {
MadeniPara::Kurus => 1,
MadeniPara::BesKurus => 5,
MadeniPara::OnKurus => 10,
MadeniPara::YirmiBesKurus => 25,
}
}
fn main() {}match ifadesikurus_degeri fonksiyonundaki match’i parçalara ayıralım. İlk olarak, match anahtar kelimesini ve ardından bir ifadeyi listeliyoruz; bu durumda ifade para (coin) değeridir. Bu, if ile kullanılan bir koşul ifadesine çok benzer, ancak aralarında büyük bir fark vardır: if kullanıldığında koşulun bir Boolean değer üretmesi gerekirken, burada herhangi bir tür olabilir. Bu örnekteki para’nın türü, ilk satırda tanımladığımız MadeniPara (Coin) enum’ıdır.
Sırada match kolları (arms) var. Bir kol iki bölümden oluşur: bir desen ve bir kod. Buradaki ilk kolun deseni MadeniPara::Kurus (Coin::Penny) değeridir ve ardından desen ile çalıştırılacak kodu ayıran => operatörü gelir. Bu durumdaki kod sadece 1 değeridir. Her kol bir sonrakinden virgülle ayrılır.
match ifadesi yürütüldüğünde, ortaya çıkan değeri sırasıyla her bir kolun deseniyle karşılaştırır. Bir desen değerle eşleşirse, o desenle ilişkili kod yürütülür. Eğer desen değerle eşleşmezse, tıpkı bozuk para ayırma makinesinde olduğu gibi yürütme bir sonraki kola geçer. İhtiyacımız olduğu kadar kola sahip olabiliriz: Liste 6-3’te, match ifademizin dört kolu vardır.
Her kolla ilişkili kod bir ifadedir ve eşleşen koldaki ifadenin ortaya çıkan değeri, tüm match ifadesi için döndürülen (return) değerdir.
Liste 6-3’te olduğu gibi her bir kolun sadece bir değer döndürdüğü durumlarda, match kolu kodu kısaysa genellikle süslü parantezler kullanmayız. Bir match kolunda birden fazla satır kod çalıştırmak istiyorsanız süslü parantez kullanmanız gerekir ve bu durumda kolu takip eden virgül isteğe bağlıdır (opsiyoneldir). Örneğin, aşağıdaki kod metot bir MadeniPara::Kurus ile çağrıldığında her defasında “Şanslı kuruş!” (“Lucky penny!”) yazdırır, ancak yine de bloğun son değeri olan 1’i döndürür:
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus,
}
fn kurus_degeri(para: MadeniPara) -> u8 {
match para {
MadeniPara::Kurus => {
println!("Şanslı kuruş!");
1
}
MadeniPara::BesKurus => 5,
MadeniPara::OnKurus => 10,
MadeniPara::YirmiBesKurus => 25,
}
}
fn main() {}Değerlere Bağlanan Desenler
match kollarının bir diğer kullanışlı özelliği de, desenle eşleşen değerlerin parçalarına bağlanabilmeleridir. Enum varyantlarından değerleri bu şekilde çıkarabiliriz.
Örnek olarak, enum varyantlarımızdan birini içinde veri tutacak şekilde değiştirelim. 1999’dan 2008’e kadar Amerika Birleşik Devletleri, 50 eyaletin her biri için bir yüzünde farklı tasarımlara sahip çeyreklikler (quarter) bastı. Diğer hiçbir madeni para eyalet tasarımına sahip değildi, dolayısıyla bu ekstra değere sadece çeyreklikler sahiptir. Liste 6-4’te yaptığımız gibi, YirmiBesKurus (Quarter) varyantını içine depolanmış bir Eyalet (UsState) değeri içerecek şekilde değiştirerek bu bilgiyi enum’ımıza ekleyebiliriz.
#[derive(Debug)] // birazdan eyaleti inceleyebilmek için
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn main() {}YirmiBesKurus varyantının aynı zamanda bir Eyalet değeri tuttuğu bir MadeniPara enum’ıBir arkadaşımızın tüm 50 eyaletin çeyrekliklerini toplamaya çalıştığını hayal edelim. Bozuk paralarımızı para türüne göre ayırırken, her çeyreklikle ilişkili eyaletin adını da söyleyeceğiz ki arkadaşımızın sahip olmadığı bir eyaletse onu koleksiyonuna ekleyebilsin.
Bu kodun match ifadesinde, MadeniPara::YirmiBesKurus varyantının değerleriyle eşleşen desene eyalet (state) adında bir değişken ekliyoruz. Bir MadeniPara::YirmiBesKurus eşleştiğinde, eyalet değişkeni o çeyrekliğin eyaletinin değerine bağlanacaktır. Daha sonra, bu koldaki kodda eyalet değişkenini şu şekilde kullanabiliriz:
#[derive(Debug)]
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn kurus_degeri(para: MadeniPara) -> u8 {
match para {
MadeniPara::Kurus => 1,
MadeniPara::BesKurus => 5,
MadeniPara::OnKurus => 10,
MadeniPara::YirmiBesKurus(eyalet) => {
println!("{eyalet:?} eyaletinden çeyreklik!");
25
}
}
}
fn main() {
kurus_degeri(MadeniPara::YirmiBesKurus(Eyalet::Alaska));
}Eğer kurus_degeri(MadeniPara::YirmiBesKurus(Eyalet::Alaska)) şeklinde bir çağrı yapsaydık, para’nın değeri MadeniPara::YirmiBesKurus(Eyalet::Alaska) olurdu. Bu değeri her bir match koluyla karşılaştırdığımızda, MadeniPara::YirmiBesKurus(eyalet)’e ulaşana kadar hiçbiri eşleşmez. O noktada, eyalet için bağlama (binding) Eyalet::Alaska değeri olacaktır. Daha sonra bu bağlamayı println! ifadesinde kullanabilir ve böylece YirmiBesKurus için MadeniPara enum varyantının içindeki eyalet değerini elde edebiliriz.
Option<T> match Deseni
Önceki bölümde, Option<T> kullanırken Some durumundan içteki T değerini çıkarmak istemiştik; tıpkı MadeniPara enum’ında yaptığımız gibi, Option<T>’yi de match kullanarak ele alabiliriz! Madeni paraları karşılaştırmak yerine, Option<T> varyantlarını karşılaştıracağız, ancak match ifadesinin çalışma şekli aynı kalır.
Diyelim ki bir Option<i32> alan ve eğer içinde bir değer varsa o değere 1 ekleyen bir fonksiyon yazmak istiyoruz. Eğer içinde bir değer yoksa, fonksiyon None değerini döndürmeli ve herhangi bir işlem gerçekleştirmeye çalışmamalıdır.
match sayesinde bu fonksiyonu yazmak çok kolaydır ve Liste 6-5’teki gibi görünecektir.
fn main() {
fn bir_ekle(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let bes = Some(5);
let alti = bir_ekle(bes);
let hicbiri = bir_ekle(None);
}Option<i32> üzerinde match ifadesi kullanan bir fonksiyonbir_ekle fonksiyonunun ilk çalıştırılmasını daha ayrıntılı inceleyelim. bir_ekle(bes) çağrısı yaptığımızda, bir_ekle gövdesindeki x değişkeni Some(5) değerine sahip olacaktır. Daha sonra bunu her bir match koluyla karşılaştırırız:
fn main() {
fn bir_ekle(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let bes = Some(5);
let alti = bir_ekle(bes);
let hicbiri = bir_ekle(None);
}Some(5) değeri None deseniyle eşleşmez, bu yüzden bir sonraki kola devam ederiz:
fn main() {
fn bir_ekle(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let bes = Some(5);
let alti = bir_ekle(bes);
let hicbiri = bir_ekle(None);
}Some(5), Some(i) ile eşleşir mi? Evet, eşleşir! Aynı varyanta sahibiz. i, Some içinde bulunan değere bağlanır, böylece i 5 değerini alır. Daha sonra match kolundaki kod çalıştırılır, böylece i’nin değerine 1 ekleriz ve içinde 6 toplamı olan yeni bir Some değeri oluştururuz.
Şimdi Liste 6-5’teki bir_ekle fonksiyonunun ikinci çağrısını inceleyelim; burada x None’dır. match içine giriyoruz ve ilk kolla karşılaştırıyoruz:
fn main() {
fn bir_ekle(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let bes = Some(5);
let alti = bir_ekle(bes);
let hicbiri = bir_ekle(None);
}Eşleşiyor! Eklenecek hiçbir değer yok, bu yüzden program durur ve => işaretinin sağ tarafındaki None değerini döndürür. İlk kol eşleştiği için diğer kollar karşılaştırılmaz.
match ve enum’ları birleştirmek birçok durumda yararlıdır. Bu kalıbı (pattern) Rust kodlarında çokça göreceksiniz: bir enum ile match (eşleştirme) yapma, içindeki veriye bir değişken bağlama ve ardından buna dayalı olarak kod çalıştırma. Başlangıçta biraz zorlayıcı gelebilir, ancak alıştıktan sonra bunu tüm dillerde arayacaksınız. Tutarlı bir şekilde kullanıcıların favorisidir.
Eşleşmeler Kapsamlıdır (Exhaustive)
match ile ilgili tartışmamız gereken bir diğer yön daha var: Kolların desenleri tüm olasılıkları kapsamalıdır. bir_ekle fonksiyonumuzun bir hata (bug) içeren ve derlenmeyecek olan şu versiyonunu düşünün:
fn main() {
fn bir_ekle(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let bes = Some(5);
let alti = bir_ekle(bes);
let hicbiri = bir_ekle(None);
}None durumunu ele almadık, bu yüzden bu kod bir hataya neden olacaktır. Neyse ki, bu Rust’ın nasıl yakalayacağını bildiği bir hatadır. Bu kodu derlemeye çalışırsak şu hatayı alırız:
$ cargo run
Compiling enums v0.1.0 ($PROJE/listings/ch06-enums-and-pattern-matching/no-listing-10-non-exhaustive-match)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:4:15
|
4 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> $HOME/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/option.rs:600:1
|
600 | pub enum Option<T> {
| ^^^^^^^^^^^^^^^^^^
...
604 | None,
| ---- not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
5 ~ Some(i) => Some(i + 1),
6 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
warning: `enums` (bin "enums") generated 2 warnings
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust, olası her durumu kapsamadığımızı biliyor ve hatta hangi deseni unuttuğumuzu bile biliyor! Rust’ta eşleşmeler kapsamlıdır: Kodun geçerli olabilmesi için her bir olasılığı sonuna kadar tüketmeliyiz (exhaust). Özellikle Option<T> durumunda, Rust None durumunu açıkça ele almayı unutmamızı engellediğinde, aslında null olabilecekken bir değere sahip olduğumuzu varsaymamızdan bizi korur, böylece daha önce tartışılan milyar dolarlık hatayı imkansız hale getirir.
Hepsini Yakalayan (Catch-All) Desenler ve _ Yer Tutucusu
Enum’ları kullanarak, belirli birkaç değer için özel eylemler yapabilir, diğer tüm değerler için ise varsayılan (default) bir eylem alabiliriz. Şöyle bir oyun uyguladığımızı hayal edelim: Eğer zar attığınızda 3 gelirse, oyuncunuz hareket etmez ama bunun yerine süslü yeni bir şapka kazanır. Eğer 7 atarsanız, oyuncunuz süslü şapkasını kaybeder. Diğer tüm değerler için, oyuncunuz oyun tahtasında o sayı kadar kare ilerler. İşte bu mantığı uygulayan bir match; zar atışının sonucu rastgele bir değer olmak yerine koda gömülmüş (hardcoded) ve diğer tüm mantıklar gövdesi olmayan fonksiyonlarla temsil edilmiştir, çünkü bu fonksiyonları gerçekten uygulamak bu örneğin kapsamı dışındadır:
fn main() {
let zar_atisi = 9;
match zar_atisi {
3 => suslu_sapka_ekle(),
7 => suslu_sapkayi_cikar(),
diger => oyuncuyu_tasi(diger),
}
fn suslu_sapka_ekle() {}
fn suslu_sapkayi_cikar() {}
fn oyuncuyu_tasi(kare_sayisi: u8) {}
}İlk iki kol için desenler 3 ve 7 sabit değerleridir. Diğer olası tüm değerleri kapsayan son kol için desen ise, diger olarak adlandırdığımız değişkendir. diger kolu için çalışan kod, bu değişkeni oyuncuyu_tasi (move_player) fonksiyonuna aktararak kullanır.
Bu kod derlenir, her ne kadar bir u8’in alabileceği olası tüm değerleri listelememiş olsak da, çünkü son desen özel olarak listelenmeyen tüm değerlerle eşleşecektir. Hepsini yakalayan bu desen, match’in kapsamlı olması gerektiği koşulunu karşılar. Desenler sırayla değerlendirildiği için hepsini yakalayan kolu en sona koymamız gerektiğine dikkat edin. Hepsini yakalayan kolu daha önce koysaydık, diğer kollar asla çalışmazdı, bu yüzden eğer hepsini yakalayan bir koldan sonra kollar eklersek Rust bizi uyaracaktır!
Rust ayrıca, hepsini yakalayan bir kol istediğimizde ancak bu yakalanan değeri kullanmak istemediğimizde kullanabileceğimiz bir desene de sahiptir: _, her değerle eşleşen ve o değere bağlanmayan özel bir desendir. Bu, Rust’a değeri kullanmayacağımızı söyler, böylece Rust kullanılmayan bir değişken hakkında bizi uyarmaz.
Oyunun kurallarını değiştirelim: Artık 3 veya 7 dışında bir şey atarsanız, tekrar zar atmalısınız. Artık yakalanan değeri kullanmamıza gerek yok, bu yüzden kodumuzu diger adlı değişken yerine _ kullanacak şekilde değiştirebiliriz:
fn main() {
let zar_atisi = 9;
match zar_atisi {
3 => suslu_sapka_ekle(),
7 => suslu_sapkayi_cikar(),
_ => tekrar_zar_at(),
}
fn suslu_sapka_ekle() {}
fn suslu_sapkayi_cikar() {}
fn tekrar_zar_at() {}
}Bu örnek de kapsamlılık şartını karşılıyor çünkü son kolda diğer tüm değerleri açıkça görmezden geliyoruz; hiçbir şeyi unutmuş değiliz.
Son olarak, oyunun kurallarını bir kez daha değiştirelim: Eğer 3 veya 7 dışında bir şey atarsanız sıranızda başka hiçbir şey olmaz. Bunu, _ koluyla çalışan kod olarak birim değeri (unit value - “Demet (Tuple) Türü” bölümünde bahsettiğimiz boş demet türü) kullanarak ifade edebiliriz:
fn main() {
let zar_atisi = 9;
match zar_atisi {
3 => suslu_sapka_ekle(),
7 => suslu_sapkayi_cikar(),
_ => (),
}
fn suslu_sapka_ekle() {}
fn suslu_sapkayi_cikar() {}
}Burada Rust’a açıkça, önceki kolların desenleriyle eşleşmeyen başka hiçbir değeri kullanmayacağımızı ve bu durumda hiçbir kod çalıştırmak istemediğimizi söylüyoruz.
Desenler ve eşleştirme hakkında Bölüm 19’da ele alacağımız daha çok şey var. Şimdilik, match ifadesinin biraz uzun kaçabildiği durumlarda yararlı olabilecek if let sözdizimine geçeceğiz.
if let ve let...else ile Özlü Kontrol Akışı
if let ve let...else ile Özlü Kontrol Akışı
if let sözdizimi, geri kalanları görmezden gelirken yalnızca bir desenle (pattern) eşleşen değerleri ele almak için if ve let’i daha az ayrıntılı bir şekilde birleştirmenize olanak tanır. max_ayari (config_max) değişkenindeki bir Option<u8> değerini eşleştiren ancak yalnızca değer Some varyantıysa kod çalıştırmak isteyen Liste 6-6’daki programı düşünün.
fn main() {
let max_ayari = Some(3u8);
match max_ayari {
Some(max) => println!("Maksimum değer {max} olarak ayarlandı"),
_ => (),
}
}Some olduğunda kod çalıştırmayı önemseyen bir matchEğer değer Some ise, değeri desendeki max değişkenine bağlayarak Some varyantının içindeki değeri yazdırırız. None değeriyle hiçbir şey yapmak istemiyoruz. match ifadesini tatmin etmek için, yalnızca bir varyantı işledikten sonra _ => () eklemek zorundayız; bu da eklenmesi can sıkıcı ve gereksiz (boilerplate) bir koddur.
Bunun yerine, bunu if let kullanarak daha kısa bir şekilde yazabilirdik. Aşağıdaki kod Liste 6-6’daki match ile aynı şekilde davranır:
fn main() {
let max_ayari = Some(3u8);
if let Some(max) = max_ayari {
println!("Maksimum değer {max} olarak ayarlandı");
}
}if let sözdizimi, eşittir işaretiyle ayrılmış bir desen ve bir ifade alır. İfadenin match’e verildiği ve desenin onun ilk kolu olduğu bir match ile aynı şekilde çalışır. Bu durumda desen Some(max)’tir ve max, Some içindeki değere bağlanır. Daha sonra max’i, ilgili match kolunda kullandığımız gibi if let bloğunun gövdesinde de kullanabiliriz. if let bloğundaki kod yalnızca değer desenle eşleşirse çalışır.
if let kullanmak daha az kod yazmak, daha az girinti (indentation) yapmak ve daha az tekrarlayan (boilerplate) kod kullanmak anlamına gelir. Ancak, match’in hiçbir durumu ele almayı unutmamanızı sağlayan kapsamlı denetimini kaybedersiniz. match ve if let arasında seçim yapmak, bulunduğunuz durumda ne yaptığınıza ve kısalık kazanmanın kapsamlı kontrolü kaybetmek için uygun bir takas olup olmadığına bağlıdır.
Başka bir deyişle, if let’i değer bir desenle eşleştiğinde kodu çalıştıran ve diğer tüm değerleri yoksayan bir match için pratik bir sözdizimi (syntax sugar) olarak düşünebilirsiniz.
Bir if let ile birlikte bir else de ekleyebiliriz. else ile birlikte giden kod bloğu, if let ve else ile eşdeğer olan match ifadesindeki _ durumunda gidecek olan kod bloğuyla aynıdır. YirmiBesKurus (Quarter) varyantının da bir Eyalet (UsState) değeri tuttuğu Liste 6-4’teki MadeniPara (Coin) enum tanımını hatırlayın. Gördüğümüz çeyreklik olmayan tüm paraları sayarken aynı zamanda çeyrekliklerin eyaletini duyurmak isteseydik, bunu şöyle bir match ifadesi ile yapabilirdik:
#[derive(Debug)]
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn main() {
let para = MadeniPara::Kurus;
let mut sayac = 0;
match para {
MadeniPara::YirmiBesKurus(eyalet) => {
println!("{eyalet:?} eyaletinden çeyreklik!")
}
_ => sayac += 1,
}
}Veya bunun gibi bir if let ve else ifadesi kullanabilirdik:
#[derive(Debug)]
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn main() {
let para = MadeniPara::Kurus;
let mut sayac = 0;
if let MadeniPara::YirmiBesKurus(eyalet) = para {
println!("{eyalet:?} eyaletinden çeyreklik!");
} else {
sayac += 1;
}
}let...else ile “Mutlu Yolda” (Happy Path) Kalmak
Yaygın bir örüntü, bir değer mevcut olduğunda bazı hesaplamalar yapmak ve aksi takdirde varsayılan bir değer döndürmektir. Eyalet değerine sahip madeni paralar örneğimizle devam edersek, çeyrekliğin üzerindeki eyaletin ne kadar eski olduğuna bağlı olarak komik bir şey söylemek isteseydik, Eyalet üzerinde bir eyaletin yaşını kontrol etmek için şöyle bir metot tanıtabilirdik:
#[derive(Debug)] // birazdan eyaleti inceleyebilmek için
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
impl Eyalet {
fn su_tarihte_var_miydi(&self, yil: u16) -> bool {
match self {
Eyalet::Alabama => yil >= 1819,
Eyalet::Alaska => yil >= 1959,
// -- snip --
}
}
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn eyalet_ceyrekligini_tanimla(para: MadeniPara) -> Option<String> {
if let MadeniPara::YirmiBesKurus(eyalet) = para {
if eyalet.su_tarihte_var_miydi(1900) {
Some(format!("{eyalet:?} Amerika'ya göre oldukça eski!"))
} else {
Some(format!("{eyalet:?} nispeten yeni."))
}
} else {
None
}
}
fn main() {
if let Some(tanim) =
eyalet_ceyrekligini_tanimla(MadeniPara::YirmiBesKurus(Eyalet::Alaska))
{
println!("{tanim}");
}
}Daha sonra, Liste 6-7’de olduğu gibi koşulun gövdesi içinde bir eyalet (state) değişkeni tanıtarak madeni paranın türüyle eşleştirmek için if let kullanabiliriz.
#[derive(Debug)] // birazdan eyaleti inceleyebilmek için
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
impl Eyalet {
fn su_tarihte_var_miydi(&self, yil: u16) -> bool {
match self {
Eyalet::Alabama => yil >= 1819,
Eyalet::Alaska => yil >= 1959,
// -- snip --
}
}
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn eyalet_ceyrekligini_tanimla(para: MadeniPara) -> Option<String> {
if let MadeniPara::YirmiBesKurus(eyalet) = para {
if eyalet.su_tarihte_var_miydi(1900) {
Some(format!("{eyalet:?} Amerika'ya göre oldukça eski!"))
} else {
Some(format!("{eyalet:?} nispeten yeni."))
}
} else {
None
}
}
fn main() {
if let Some(tanim) =
eyalet_ceyrekligini_tanimla(MadeniPara::YirmiBesKurus(Eyalet::Alaska))
{
println!("{tanim}");
}
}if let içine yerleştirilmiş koşullar kullanarak bir eyaletin 1900’de var olup olmadığını kontrol etmeBu işi halleder, ancak işi if let ifadesinin gövdesine iter ve yapılacak iş daha karmaşıksa, üst düzey dalların (branches) birbiriyle tam olarak nasıl ilişkili olduğunu takip etmek zor olabilir. İfadelerin bir değer ürettiği gerçeğinden yararlanarak, Liste 6-8’de olduğu gibi if let’ten eyalet’i (state) üretebilir veya erken dönüş (return early) yapabiliriz. (Buna benzer bir şeyi match ile de yapabilirsiniz.)
#[derive(Debug)] // birazdan eyaleti inceleyebilmek için
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
impl Eyalet {
fn su_tarihte_var_miydi(&self, yil: u16) -> bool {
match self {
Eyalet::Alabama => yil >= 1819,
Eyalet::Alaska => yil >= 1959,
// -- snip --
}
}
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn eyalet_ceyrekligini_tanimla(para: MadeniPara) -> Option<String> {
let eyalet = if let MadeniPara::YirmiBesKurus(eyalet) = para {
eyalet
} else {
return None;
};
if eyalet.su_tarihte_var_miydi(1900) {
Some(format!("{eyalet:?} Amerika'ya göre oldukça eski!"))
} else {
Some(format!("{eyalet:?} nispeten yeni."))
}
}
fn main() {
if let Some(tanim) =
eyalet_ceyrekligini_tanimla(MadeniPara::YirmiBesKurus(Eyalet::Alaska))
{
println!("{tanim}");
}
}if let kullanmakYine de bunu takip etmek kendine göre biraz can sıkıcı! if let’in bir dalı bir değer üretir ve diğeri fonksiyondan tamamen geri döner.
Bu yaygın kalıbı (pattern) daha güzel ifade etmek için Rust’ta let...else vardır. let...else sözdizimi, if let’e çok benzer şekilde sol tarafta bir desen ve sağ tarafta bir ifade alır, ancak bir if dalı yoktur, yalnızca bir else dalı vardır. Eğer desen eşleşirse, desendeki değeri dış kapsama (outer scope) bağlar. Eğer desen eşleşmezse, program fonksiyondan dönmesi gereken else koluna akacaktır.
Liste 6-9’da, if let yerine let...else kullanıldığında Liste 6-8’in nasıl göründüğünü görebilirsiniz.
#[derive(Debug)] // birazdan eyaleti inceleyebilmek için
enum Eyalet {
Alabama,
Alaska,
// --snip--
}
impl Eyalet {
fn su_tarihte_var_miydi(&self, yil: u16) -> bool {
match self {
Eyalet::Alabama => yil >= 1819,
Eyalet::Alaska => yil >= 1959,
// -- snip --
}
}
}
enum MadeniPara {
Kurus,
BesKurus,
OnKurus,
YirmiBesKurus(Eyalet),
}
fn eyalet_ceyrekligini_tanimla(para: MadeniPara) -> Option<String> {
let MadeniPara::YirmiBesKurus(eyalet) = para else {
return None;
};
if eyalet.su_tarihte_var_miydi(1900) {
Some(format!("{eyalet:?} Amerika'ya göre oldukça eski!"))
} else {
Some(format!("{eyalet:?} nispeten yeni."))
}
}
fn main() {
if let Some(tanim) =
eyalet_ceyrekligini_tanimla(MadeniPara::YirmiBesKurus(Eyalet::Alaska))
{
println!("{tanim}");
}
}let...else kullanmakif let’in yaptığı gibi iki dal için önemli ölçüde farklı kontrol akışlarına sahip olmadan, fonksiyonun ana gövdesindeki “mutlu yolda” (happy path) kaldığına dikkat edin.
Programınızın match kullanarak ifade edilemeyecek kadar uzun veya karmaşık bir mantığa sahip olduğu bir durumla karşılaşırsanız, if let ve let...else yapılarının da Rust alet çantanızda (toolbox) olduğunu unutmayın.
Özet
Şimdi, numaralandırılmış (enumerated) değerler kümesinden biri olabilen özel türler oluşturmak için enum’ların nasıl kullanılacağını ele aldık. Standart kütüphanenin Option<T> türünün, hataları önlemek için tür sistemini kullanmanıza nasıl yardımcı olduğunu gösterdik. Enum değerlerinin içinde veriler olduğunda, ele almanız gereken durumların sayısına bağlı olarak bu değerleri çıkarmak ve kullanmak için match veya if let kullanabilirsiniz.
Rust programlarınız artık alanınızdaki (domain) kavramları struct’lar ve enum’lar kullanarak ifade edebilir. API’nizde kullanmak üzere özel türler (custom types) oluşturmak tip güvenliği (type safety) sağlar: Derleyici, fonksiyonlarınızın yalnızca her fonksiyonun beklediği türde değerler almasını garanti eder.
Kullanıcılarınıza kullanımı kolay ve yalnızca tam olarak ihtiyaç duyacakları şeyleri ortaya çıkaran iyi organize edilmiş bir API sağlamak için şimdi Rust’ın modüllerine (modules) dönelim.
Paketler, Crate’ler ve Modüller
Büyük programlar yazdıkça kodunuzu düzenlemek giderek daha önemli hale gelecektir. Birbiriyle ilgili işlevleri gruplandırarak ve belirli özelliklere sahip kodları birbirinden ayırarak, belirli bir özelliği uygulayan kodun nerede bulunacağını ve bir özelliğin çalışma şeklini değiştirmek için nereye gidilmesi gerektiğini daha net bir şekilde görebilirsiniz.
Şimdiye kadar yazdığımız programlar tek bir dosyadaki tek bir modül içindeydi. Bir proje büyüdükçe, kodu birden çok modüle ve ardından birden çok dosyaya bölerek düzenlemelisiniz. Bir paket birden fazla ikili crate ve isteğe bağlı olarak bir kütüphane (library) crate’i içerebilir. Bir paket büyüdükçe parçaları, dış bağımlılıklar (external dependencies) haline gelen ayrı crate’lere dönüştürebilirsiniz. Bu bölüm tüm bu teknikleri kapsar. Birlikte geliştirilen bir dizi birbiriyle ilişkili paketten oluşan çok büyük projeler için Cargo, Bölüm 14’teki “Cargo Çalışma Alanları” (Cargo Workspaces) kısmında ele alacağımız çalışma alanlarını (workspaces) sunar.
Ayrıca, kodunuzu daha üst düzeyde yeniden kullanmanızı sağlayan uygulama ayrıntılarını kapsülleme konusunu da tartışacağız: Bir işlemi uyguladıktan sonra, diğer kodlar uygulamanın nasıl çalıştığını bilmek zorunda kalmadan kodunuzu kendi açık arayüzü aracılığıyla çağırabilir. Kodunuzu yazma şekliniz, hangi kısımların diğer kodların kullanması için açık olduğunu ve hangi kısımların değiştirme hakkını saklı tuttuğunuz özel uygulama ayrıntıları olduğunu tanımlar. Bu, zihninizde tutmanız gereken detay miktarını sınırlandırmanın başka bir yoludur.
Bununla ilişkili bir diğer kavram da kapsamdır: Kodun içinde yazıldığı iç içe bağlamın (nested context), “kapsam içinde” (in scope) olarak tanımlanan bir dizi adı vardır. Kodu okurken, yazarken ve derlerken, programcıların ve derleyicilerin belirli bir noktadaki belirli bir adın bir değişkene, fonksiyona, struct’a, enum’a, modüle, sabite (constant) veya başka bir öğeye atıfta bulunup bulunmadığını ve bu öğenin ne anlama geldiğini bilmeleri gerekir. Kapsamlar oluşturabilir ve hangi adların kapsam içinde veya dışında olacağını değiştirebilirsiniz. Aynı kapsamda aynı ada sahip iki öğe bulunamaz; isim çakışmalarını (name conflicts) çözmek için kullanılabilecek araçlar mevcuttur.
Rust, hangi ayrıntıların açığa çıkarılacağı, hangi ayrıntıların gizli tutulacağı ve programlarınızdaki her kapsamda hangi adların bulunacağı da dâhil olmak üzere kodunuzun organizasyonunu yönetmenize olanak tanıyan bir dizi özelliğe sahiptir. Bazen topluca modül sistemi (module system) olarak anılan bu özellikler şunlardır:
- Paketler (Packages): Crate’leri derlemenize (build), test etmenize ve paylaşmanıza olanak tanıyan bir Cargo özelliğidir.
- Crate’ler: Kütüphane veya çalıştırılabilir (executable) dosya üreten bir modül ağacıdır.
- Modüller ve use: Yolların (paths) organizasyonunu, kapsamını ve gizliliğini kontrol etmenizi sağlar.
- Yollar (Paths): Bir struct, fonksiyon veya modül gibi bir öğeyi isimlendirmenin bir yoludur.
Bu bölümde, tüm bu özellikleri ele alacak, nasıl etkileşime girdiklerini tartışacak ve bunları kapsamı yönetmek için nasıl kullanacağınızı açıklayacağız. Bölümün sonunda, modül sistemini sağlam bir şekilde anlayacak ve kapsamlarla bir profesyonel gibi çalışabileceksiniz!
Paketler ve Crate'ler
Paketler ve Crate’ler
Modül sisteminin ele alacağımız ilk kısımları paketler (packages) ve crate’lerdir.
Bir crate, Rust derleyicisinin bir kerede ele aldığı en küçük kod miktarıdır. cargo yerine rustc çalıştırsanız ve tek bir kaynak kod dosyası geçirseniz bile (Bölüm 1’deki “Rust Programının Temelleri” kısmında yaptığımız gibi), derleyici bu dosyayı bir crate olarak kabul eder. Crate’ler modüller içerebilir ve ilerleyen bölümlerde göreceğimiz gibi bu modüller, crate ile birlikte derlenen başka dosyalarda tanımlanmış olabilir.
Bir crate iki formdan birinde olabilir: ikili crate veya kütüphane (library) crate’i.
İkili crate’ler, bir komut satırı programı veya bir sunucu gibi, çalıştırabileceğiniz çalıştırılabilir (executable) bir dosyaya derleyebildiğiniz programlardır. Her birinin, çalıştırılabilir dosya çalıştığında ne olacağını tanımlayan main adında bir fonksiyona sahip olması gerekir. Şimdiye kadar oluşturduğumuz tüm crate’ler ikili crate’lerdi.
Kütüphane crate’lerinin bir main fonksiyonu yoktur ve çalıştırılabilir bir dosyaya derlenmezler. Bunun yerine, birden fazla projeyle paylaşılması amaçlanan işlevleri tanımlarlar. Örneğin, Bölüm 2’de kullandığımız rand crate’i, rastgele sayılar üreten işlevsellik sağlar. Rust programcıları (Rustaceans) çoğu zaman “crate” dediklerinde kütüphane crate’ini kastederler ve “crate” kelimesini genel programlama kavramı olan “kütüphane” (library) ile eşanlamlı olarak kullanırlar.
Crate kökü, Rust derleyicisinin başladığı ve crate’inizin kök modülünü (root module) oluşturan kaynak dosyasıdır (modülleri “Modüllerle Kapsam ve Gizliliği Kontrol Etme” bölümünde derinlemesine açıklayacağız).
Bir paket, bir dizi işlevsellik sağlayan bir veya daha fazla crate’in paketlenmiş halidir. Bir paket, bu crate’lerin nasıl derleneceğini (build) açıklayan bir Cargo.toml dosyası içerir. Cargo’nun kendisi aslında, kodunuzu derlemek için kullandığınız komut satırı aracı için bir ikili crate içeren bir pakettir. Cargo paketi ayrıca, ikili crate’in bağlı olduğu (depends on) bir kütüphane crate’i içerir. Diğer projeler, Cargo komut satırı aracının kullandığı aynı mantığı kullanmak için Cargo kütüphane crate’ine bağımlı olabilir.
Bir paket istediğiniz kadar ikili crate içerebilir, ancak en fazla yalnızca bir kütüphane crate’i içerebilir. Bir paket, kütüphane veya ikili crate fark etmeksizin en az bir crate içermek zorundadır.
Bir paket oluşturduğumuzda neler olduğuna bir göz atalım. Önce şu komutu giriyoruz: cargo new benim-projem:
$ cargo new benim-projem
Created binary (application) `benim-projem` package
$ ls benim-projem
Cargo.toml
src
$ ls benim-projem/src
main.rs
cargo new benim-projem komutunu çalıştırdıktan sonra, Cargo’nun neleri oluşturduğunu görmek için ls komutunu kullanıyoruz. benim-projem dizininde, bize bir paket sağlayan bir Cargo.toml dosyası bulunur. Ayrıca main.rs dosyasını içeren bir src dizini de vardır. Metin düzenleyicinizde Cargo.toml dosyasını açın ve src/main.rs’den hiç bahsedilmediğine dikkat edin. Cargo, paketle aynı ada sahip bir ikili crate’in crate kökünün src/main.rs olduğuna dair bir geleneği izler. Aynı şekilde Cargo, eğer paket dizini src/lib.rs içeriyorsa, paketin, paketle aynı isme sahip bir kütüphane crate’i içerdiğini ve bu crate’in kökünün src/lib.rs olduğunu bilir. Cargo, kütüphaneyi veya ikili dosyayı derlemek için crate kök dosyalarını rustc’ye iletir.
Burada, yalnızca src/main.rs içeren bir paketimiz var; yani yalnızca benim-projem adında bir ikili crate içeriyor. Eğer bir paket hem src/main.rs hem de src/lib.rs içeriyorsa, iki crate’i vardır: paketle aynı isme sahip bir ikili ve bir kütüphane crate’i. Bir paket, src/bin dizinine dosyalar yerleştirilerek birden fazla ikili crate’e sahip olabilir: Bu dizindeki her bir dosya ayrı bir ikili crate olacaktır.
Modüllerle Kapsam ve Gizliliği Kontrol Etme
Modüllerle Kapsam ve Gizliliği Kontrol Etme
Bu bölümde modüllerden ve modül sisteminin diğer parçalarından, yani öğeleri isimlendirmenizi sağlayan yollardan (paths), bir yolu kapsama getiren use anahtar kelimesinden ve öğeleri herkese açık hale getiren pub anahtar kelimesinden bahsedeceğiz. Ayrıca as anahtar kelimesini, harici paketleri ve glob operatörünü de ele alacağız.
Modüller Kopya Kağıdı (Cheat Sheet)
Modüllerin ve yolların detaylarına girmeden önce, burada modüllerin, yolların, use anahtar kelimesinin ve pub anahtar kelimesinin derleyicide nasıl çalıştığına ve çoğu geliştiricinin kodlarını nasıl düzenlediğine dair hızlı bir başvuru kılavuzu (quick reference) sunuyoruz. Bu bölüm boyunca bu kuralların her birini örneklerle inceleyeceğiz, ancak modüllerin nasıl çalıştığını hatırlamak için burası harika bir başvuru noktasıdır.
- Crate kökünden başlayın: Bir crate’i derlerken, derleyici önce derlenecek kodu bulmak için crate kök dosyasına (genellikle bir kütüphane crate’i için src/lib.rs ve bir ikili crate için src/main.rs) bakar.
- Modülleri bildirmek (declaring modules): Crate kök dosyasında yeni modüller bildirebilirsiniz; diyelim ki
mod bahce;ile bir “bahce” modülü bildirdiniz. Derleyici, bu modülün kodunu şu konumlarda arayacaktır:- Satır içi,
mod bahce’den sonraki noktalı virgül yerine konulan süslü parantezlerin içinde - src/bahce.rs dosyasında
- src/bahce/mod.rs dosyasında
- Satır içi,
- Alt modülleri bildirmek (declaring submodules): Crate kökü dışındaki herhangi bir dosyada alt modüller bildirebilirsiniz. Örneğin, src/bahce.rs içinde
mod sebzeler;bildirebilirsiniz. Derleyici, alt modülün kodunu ana modülün adını taşıyan dizinde şu konumlarda arayacaktır:- Satır içi, doğrudan
mod sebzeler’den sonra, noktalı virgül yerine süslü parantezlerin içinde - src/bahce/sebzeler.rs dosyasında
- src/bahce/sebzeler/mod.rs dosyasında
- Satır içi, doğrudan
- Modüllerdeki kodların yolları: Bir modül crate’inizin bir parçası olduğunda, gizlilik kuralları izin verdiği sürece, kodun yolunu kullanarak o crate’in başka bir yerinden o modüldeki koda başvurabilirsiniz. Örneğin, bahce sebzeler modülündeki bir
Kuskonmaz(Asparagus) türücrate::bahce::sebzeler::Kuskonmazadresinde (yolunda) bulunacaktır. - Gizli ve açık: Bir modül içindeki kod varsayılan olarak üst modüllerinden gizlidir. Bir modülü açık hale getirmek için
modyerinepub modile bildirin. Açık bir modül içindeki öğeleri de açık hale getirmek için bildirimlerinden (declaration) öncepubkullanın. useanahtar kelimesi: Bir kapsam içinde,useanahtar kelimesi uzun yolların tekrarını azaltmak için öğelere kısayollar oluşturur.crate::bahce::sebzeler::Kuskonmaz’a başvurabilen herhangi bir kapsamda,use crate::bahce::sebzeler::Kuskonmaz;ile bir kısayol oluşturabilirsiniz; ve o andan itibaren bu türü o kapsamda kullanmak için yalnızcaKuskonmazyazmanız yeterlidir.
Burada, bu kuralları gösteren arka_bahce (backyard) adlı bir ikili crate oluşturuyoruz. Crate’in yine arka_bahce adını taşıyan dizini, şu dosyaları ve dizinleri içerir:
arka_bahce
├── Cargo.lock
├── Cargo.toml
└── src
├── bahce
│ └── sebzeler.rs
├── bahce.rs
└── main.rs
Bu durumda crate kök dosyası src/main.rs’dir ve şunları içerir:
use crate::bahce::sebzeler::Kuskonmaz;
pub mod bahce;
fn main() {
let bitki = Kuskonmaz {};
println!("{bitki:?} yetiştiriyorum!");
}pub mod bahce; satırı, derleyiciye src/bahce.rs dosyasında bulduğu kodu dahil etmesini söyler:
pub mod sebzeler;Burada, pub mod sebzeler;, src/bahce/sebzeler.rs dosyasındaki kodun da dahil edildiği anlamına gelir. O kod da şudur:
#[derive(Debug)]
pub struct Kuskonmaz {}Şimdi bu kuralların detaylarına girelim ve pratikte nasıl uygulandıklarını gösterelim!
İlgili Kodu Modüllerde Gruplama
Modüller, okunabilirlik ve kolay yeniden kullanım için bir crate içindeki kodu düzenlememize olanak tanır. Modüller aynı zamanda öğelerin gizliliğini kontrol etmemizi sağlar çünkü bir modül içindeki kod varsayılan olarak gizlidir. Gizli öğeler, dışarıdan kullanıma açık olmayan dahili (internal) uygulama ayrıntılarıdır. Modülleri ve içlerindeki öğeleri açık hale getirmeyi seçebiliriz, bu da onları açığa çıkararak harici kodların onları kullanmasına ve onlara bağımlı olmasına olanak tanır.
Örnek olarak, bir restoranın işlevselliğini sağlayan bir kütüphane (library) crate’i yazalım. Fonksiyonların imzalarını tanımlayacağız, ancak bir restoranın uygulanmasından ziyade kodun organizasyonuna odaklanmak için gövdelerini boş bırakacağız.
Restoran sektöründe, bir restoranın bazı bölümleri ön kısım (front of house), diğerleri ise arka kısım (back of house) olarak adlandırılır. Ön kısım müşterilerin bulunduğu yerdir; burası karşılamanın (hosts) müşterileri oturttuğu, servis elemanlarının (servers) siparişleri ve ödemeleri aldığı ve barmenlerin içecekleri hazırladığı yeri kapsar. Arka kısım ise şeflerin ve aşçıların mutfakta çalıştığı, bulaşıkçıların temizlik yaptığı ve yöneticilerin idari işleri yürüttüğü yerdir.
Crate’imizi bu şekilde yapılandırmak için, fonksiyonlarını iç içe geçmiş modüller halinde düzenleyebiliriz. cargo new restoran --lib komutunu çalıştırarak restoran adında yeni bir kütüphane oluşturun. Ardından, bazı modülleri ve fonksiyon imzalarını tanımlamak için Liste 7-1’deki kodu src/lib.rs dosyasına girin; bu kod restoranın ön kısmını temsil eder.
mod restoran_on_kisim {
mod karsilama {
fn bekleme_listesine_ekle() {}
fn masaya_oturt() {}
}
mod servis {
fn siparis_al() {}
fn siparis_servis_et() {}
fn odeme_al() {}
}
}restoran_on_kisim modülümod anahtar kelimesini ve ardından modülün adını (bu durumda restoran_on_kisim) kullanarak bir modül tanımlarız. Modülün gövdesi daha sonra süslü parantezlerin içine girer. Modüllerin içine, bu durumda karsilama ve servis modüllerinde olduğu gibi başka modüller yerleştirebiliriz. Modüller ayrıca struct’lar, enum’lar, sabitler (constants), trait’ler ve Liste 7-1’de olduğu gibi fonksiyonlar gibi diğer öğeler için tanımlar da barındırabilir.
Modülleri kullanarak, birbiriyle ilişkili tanımları bir arada gruplayabilir ve neden ilişkili olduklarını isimlendirebiliriz. Bu kodu kullanan programcılar, tüm tanımları okumak zorunda kalmadan, gruplara göre kod içinde gezinebilirler ve bu da onlarla alakalı tanımları bulmalarını kolaylaştırır. Bu koda yeni işlevsellik ekleyen programcılar, programın düzenli kalması için kodu nereye yerleştireceklerini bileceklerdir.
Daha önce, src/main.rs ve src/lib.rs dosyalarının crate kökleri (crate roots) olarak adlandırıldığından bahsetmiştik. Bu şekilde adlandırılmalarının nedeni, bu iki dosyadan herhangi birinin içeriğinin, crate’in modül yapısının kökünde (bu yapı modül ağacı - module tree olarak bilinir) crate adında bir modül oluşturmasıdır.
Liste 7-2, Liste 7-1’deki yapının modül ağacını göstermektedir.
crate
└── restoran_on_kisim
├── karsilama
│ ├── bekleme_listesine_ekle
│ └── masaya_oturt
└── servis
├── siparis_al
├── siparis_servis_et
└── odeme_al
Bu ağaç, bazı modüllerin diğer modüllerin içine nasıl yuvalandığını (iç içe geçtiğini) gösterir; örneğin, karsilama, restoran_on_kisim’in içine yuvalanmıştır. Ağaç ayrıca bazı modüllerin kardeş (siblings) olduğunu, yani aynı modül içinde tanımlandıklarını gösterir; karsilama ve servis, restoran_on_kisim içinde tanımlanmış kardeş modüllerdir. Eğer A modülü B modülünün içindeyse, A modülünün B modülünün çocuğu ve B modülünün A modülünün ebeveyni olduğunu söyleriz. Tüm modül ağacının, örtük (implicit) crate adlı modülün altında köklendiğine (rooted) dikkat edin.
Modül ağacı, bilgisayarınızdaki dosya sisteminin dizin ağacını hatırlatabilir; bu çok yerinde bir karşılaştırmadır! Tıpkı dosya sistemindeki dizinler gibi, kodunuzu düzenlemek için de modülleri kullanırsınız. Ve bir dizindeki dosyalar gibi, modüllerimizi bulmanın da bir yoluna ihtiyacımız var.
Modül Ağacındaki Bir Öğeye Başvurmak İçin Yollar
Modül Ağacındaki Bir Öğeye Başvurmak İçin Yollar (Paths)
Rust’a modül ağacında bir öğeyi nerede bulacağını göstermek için, dosya sisteminde gezinirken (navigate) bir yol (path) kullandığımız şekilde bir yol kullanırız. Bir fonksiyonu çağırmak için onun yolunu bilmemiz gerekir.
Bir yol iki şekilde olabilir:
- Mutlak yol, crate kökünden başlayan tam yoldur; harici bir crate’den gelen kod için mutlak yol crate adıyla başlar ve mevcut crate’ten gelen kod için değişmez
cratekelimesiyle başlar. - Göreceli yol, geçerli modülden başlar ve mevcut modüldeki
self,superveya bir tanımlayıcı kullanır.
Hem mutlak hem de göreceli yollar, birbirinden çift iki nokta üst üste (::) ile ayrılmış bir veya daha fazla tanımlayıcı tarafından takip edilir.
Liste 7-1’e dönecek olursak, bekleme_listesine_ekle (add_to_waitlist) fonksiyonunu çağırmak istediğimizi varsayalım. Bu aslında şu soruyu sormakla aynıdır: bekleme_listesine_ekle fonksiyonunun yolu nedir? Liste 7-3, bazı modülleri ve fonksiyonları çıkarılmış halde Liste 7-1’i içermektedir.
Crate kökünde tanımlanan restoranda_yemek_ye (eat_at_restaurant) adındaki yeni bir fonksiyondan bekleme_listesine_ekle fonksiyonunu çağırmanın iki yolunu göstereceğiz. Bu yollar doğrudur, ancak bu örneğin olduğu gibi derlenmesini engelleyecek başka bir sorun daha vardır. Nedenini birazdan açıklayacağız.
restoranda_yemek_ye fonksiyonu kütüphane (library) crate’imizin herkese açık API’sinin bir parçasıdır, bu yüzden onu pub anahtar kelimesiyle işaretliyoruz. “Yolları pub Anahtar Kelimesiyle Açığa Çıkarmak” (Exposing Paths with the pub Keyword) bölümünde pub hakkında daha fazla detaya gireceğiz.
mod restoran_on_kisim {
mod karsilama {
fn bekleme_listesine_ekle() {}
}
}
pub fn restoranda_yemek_ye() {
// Mutlak (absolute) yol
crate::restoran_on_kisim::karsilama::bekleme_listesine_ekle();
// Göreceli (relative) yol
restoran_on_kisim::karsilama::bekleme_listesine_ekle();
}bekleme_listesine_ekle fonksiyonunu mutlak ve göreceli yollar kullanarak çağırmakrestoranda_yemek_ye fonksiyonu içinde bekleme_listesine_ekle fonksiyonunu ilk çağırdığımızda mutlak (absolute) bir yol kullanıyoruz. bekleme_listesine_ekle fonksiyonu restoranda_yemek_ye ile aynı crate içinde tanımlanmıştır, yani mutlak bir yolu başlatmak için crate anahtar kelimesini kullanabiliriz. Daha sonra bekleme_listesine_ekle’ye ulaşana kadar ardışık (successive) modüllerin her birini dahil ederiz. Aynı yapıya sahip bir dosya sistemi hayal edebilirsiniz: bekleme_listesine_ekle programını çalıştırmak için /restoran_on_kisim/karsilama/bekleme_listesine_ekle yolunu belirtirdik; crate kökünden başlamak için crate adını kullanmak, kabuğunuzda dosya sistemi kökünden başlamak için / kullanmaya benzer.
restoranda_yemek_ye fonksiyonu içinde bekleme_listesine_ekle fonksiyonunu ikinci kez çağırdığımızda ise göreceli (relative) bir yol kullanırız. Yol, modül ağacında restoranda_yemek_ye ile aynı seviyede tanımlanmış olan modülün adı restoran_on_kisim ile başlar. Buradaki dosya sistemi karşılığı, restoran_on_kisim/karsilama/bekleme_listesine_ekle yolunu kullanmak olurdu. Bir modül adıyla başlamak, yolun göreceli olduğu anlamına gelir.
Göreceli veya mutlak bir yol kullanıp kullanmama seçimi projenize bağlı olarak vereceğiniz bir karardır ve bu seçim, öğe tanımlama kodunu, öğeyi kullanan koddan ayrı olarak mı yoksa birlikte mi taşıma (move) ihtimalinizin daha yüksek olduğuna bağlıdır. Örneğin, restoran_on_kisim modülünü ve restoranda_yemek_ye fonksiyonunu musteri_deneyimi (customer_experience) adında bir modüle taşırsak, bekleme_listesine_ekle’nin mutlak yolunu güncellememiz gerekir, ancak göreceli yol geçerliliğini korur. Bununla birlikte, eğer restoranda_yemek_ye fonksiyonunu ayrı olarak yemek (dining) adında bir modüle taşırsak, bekleme_listesine_ekle çağrısına giden mutlak yol aynı kalır, ancak göreceli yolun güncellenmesi gerekir. Genel tercihimiz mutlak yolları belirtmektir, çünkü kod tanımlarını ve öğe çağrılarını birbirinden bağımsız olarak taşımak isteme olasılığımız daha yüksektir.
Liste 7-3’ü derlemeye çalışalım ve henüz neden derlenmediğini öğrenelim! Aldığımız hatalar Liste 7-4’te gösterilmektedir.
$ cargo build
Compiling restaurant v0.1.0 ($PROJE/listings/ch07-managing-growing-projects/listing-07-03)
error[E0603]: module `karsilama` is private
--> src/lib.rs:9:31
|
9 | crate::restoran_on_kisim::karsilama::bekleme_listesine_ekle();
| ^^^^^^^^^ ---------------------- function `bekleme_listesine_ekle` is not publicly re-exported
| |
| private module
|
note: the module `karsilama` is defined here
--> src/lib.rs:2:5
|
2 | mod karsilama {
| ^^^^^^^^^^^^^
error[E0603]: module `karsilama` is private
--> src/lib.rs:12:24
|
12 | restoran_on_kisim::karsilama::bekleme_listesine_ekle();
| ^^^^^^^^^ ---------------------- function `bekleme_listesine_ekle` is not publicly re-exported
| |
| private module
|
note: the module `karsilama` is defined here
--> src/lib.rs:2:5
|
2 | mod karsilama {
| ^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Hata mesajları karsilama (hosting) modülünün gizli olduğunu söylüyor. Başka bir deyişle, karsilama modülü ve bekleme_listesine_ekle fonksiyonu için doğru yollara sahibiz, ancak Rust gizli bölümlere erişimi olmadığı için bunları kullanmamıza izin vermiyor. Rust’ta tüm öğeler (fonksiyonlar, metotlar, struct’lar, enum’lar, modüller ve sabitler) varsayılan olarak üst modüllere gizlidir. Eğer bir fonksiyon veya struct gibi bir öğeyi gizli yapmak isterseniz, onu bir modülün içine koyarsınız.
Üst bir modüldeki öğeler alt modüllerin içindeki gizli öğeleri kullanamaz, ancak alt modüllerdeki öğeler ata modüllerindeki öğeleri kullanabilir. Bunun nedeni alt modüllerin uygulama ayrıntılarını (implementation details) sarmalaması ve gizlemesidir, ancak alt modüller tanımlandıkları bağlamı görebilirler. Metaforumuzla devam edecek olursak, gizlilik kurallarının bir restoranın arka ofisi (back office) gibi olduğunu düşünün: Orada olup bitenler restoran müşterilerine gizlidir, ancak ofis yöneticileri (managers) işlettikleri restorandaki her şeyi görebilir ve yapabilirler.
Rust modül sisteminin bu şekilde çalışmasını seçti, böylece iç uygulama detaylarını (inner implementation details) gizlemek varsayılan oldu. Bu şekilde, içteki kodun (inner code) hangi kısımlarını dıştaki kodu (outer code) bozmadan değiştirebileceğinizi bilirsiniz. Ancak Rust, bir öğeyi açık hale getirmek için pub anahtar kelimesini kullanarak alt modüllerin kodunun iç kısımlarını dıştaki ata modüllere açma seçeneğini de sunar.
Yolları pub Anahtar Kelimesiyle Açığa Çıkarmak (Exposing)
Liste 7-4’te karsilama modülünün gizli olduğunu söyleyen hataya geri dönelim. Üst modüldeki restoranda_yemek_ye fonksiyonunun, alt modüldeki bekleme_listesine_ekle fonksiyonuna erişebilmesini istiyoruz, bu yüzden karsilama modülünü Liste 7-5’te gösterildiği gibi pub anahtar kelimesiyle işaretliyoruz.
mod restoran_on_kisim {
pub mod karsilama {
fn bekleme_listesine_ekle() {}
}
}
// -- snip --
pub fn restoranda_yemek_ye() {
// Mutlak (absolute) yol
crate::restoran_on_kisim::karsilama::bekleme_listesine_ekle();
// Göreceli (relative) yol
restoran_on_kisim::karsilama::bekleme_listesine_ekle();
}restoranda_yemek_ye fonksiyonundan kullanabilmek için karsilama modülünü pub olarak bildirmekNe yazık ki, Liste 7-5’teki kod Liste 7-6’da gösterildiği gibi hala derleyici hatalarına neden olur.
$ cargo build
Compiling restaurant v0.1.0 ($PROJE/listings/ch07-managing-growing-projects/listing-07-05)
error[E0603]: function `bekleme_listesine_ekle` is private
--> src/lib.rs:12:42
|
12 | crate::restoran_on_kisim::karsilama::bekleme_listesine_ekle();
| ^^^^^^^^^^^^^^^^^^^^^^ private function
|
note: the function `bekleme_listesine_ekle` is defined here
--> src/lib.rs:4:9
|
4 | fn bekleme_listesine_ekle() {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `bekleme_listesine_ekle` is private
--> src/lib.rs:15:35
|
15 | restoran_on_kisim::karsilama::bekleme_listesine_ekle();
| ^^^^^^^^^^^^^^^^^^^^^^ private function
|
note: the function `bekleme_listesine_ekle` is defined here
--> src/lib.rs:4:9
|
4 | fn bekleme_listesine_ekle() {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Ne oldu? mod karsilama’nın önüne pub anahtar kelimesini eklemek modülü açık hale getirir. Bu değişiklikle, eğer restoran_on_kisim modülüne erişebiliyorsak, karsilama modülüne de erişebiliriz. Ancak karsilama modülünün içerikleri hala gizlidir; modülü açık hale getirmek onun içeriğini de açık hale getirmez. Bir modül üzerindeki pub anahtar kelimesi sadece ata modüllerindeki kodların o modüle atıfta bulunmasına (refer to) izin verir, ancak içindeki (inner) kodlara erişmesini sağlamaz. Modüller kapsayıcılar (containers) olduğundan, sadece modülü açık hale getirerek yapabileceğimiz pek bir şey yoktur; daha ileri gitmeli ve modül içindeki öğelerden birini veya birkaçını da açık hale getirmeyi seçmeliyiz.
Liste 7-6’daki hatalar bekleme_listesine_ekle fonksiyonunun gizli olduğunu söylüyor. Gizlilik kuralları, struct’lar, enum’lar, fonksiyonlar ve metotlar ile birlikte modüller için de geçerlidir.
Liste 7-7’de olduğu gibi tanımından önce pub anahtar kelimesini ekleyerek bekleme_listesine_ekle fonksiyonunu da açık hale getirelim.
mod restoran_on_kisim {
pub mod karsilama {
pub fn bekleme_listesine_ekle() {}
}
}
// -- snip --
pub fn restoranda_yemek_ye() {
// Mutlak (absolute) yol
crate::restoran_on_kisim::karsilama::bekleme_listesine_ekle();
// Göreceli (relative) yol
restoran_on_kisim::karsilama::bekleme_listesine_ekle();
}mod karsilama ve fn bekleme_listesine_ekle tanımlarına pub anahtar kelimesini eklemek, bu fonksiyonu restoranda_yemek_ye fonksiyonundan çağırmamızı sağlar.Artık kod derlenecek! pub anahtar kelimesini eklemenin gizlilik kurallarına uygun olarak bu yolları restoranda_yemek_ye içinde kullanmamıza neden izin verdiğini görmek için, mutlak ve göreceli yollara (absolute and relative paths) bakalım.
Mutlak yolda, crate’imizin modül ağacının kökü (root) olan crate ile başlarız. restoran_on_kisim modülü crate kökünde tanımlanmıştır. restoran_on_kisim açık olmasa da, restoranda_yemek_ye fonksiyonu restoran_on_kisim ile aynı modülde tanımlandığı için (yani, restoranda_yemek_ye ve restoran_on_kisim kardeş modüllerdir), restoranda_yemek_ye içinden restoran_on_kisim modülüne atıfta bulunabiliriz. Sırada pub ile işaretlenmiş karsilama modülü var. karsilama’nın üst modülüne (parent module) erişebiliyoruz, dolayısıyla karsilama’ya erişebiliriz. Son olarak, bekleme_listesine_ekle fonksiyonu pub ile işaretlenmiştir ve bu fonksiyonun üst modülüne erişebiliriz, dolayısıyla bu fonksiyon çağrısı çalışır!
Göreceli (relative) yolda mantık, ilk adım hariç, mutlak yolla aynıdır: Yol, crate kökünden başlamak yerine restoran_on_kisim ile başlar. restoran_on_kisim modülü, restoranda_yemek_ye fonksiyonu ile aynı modülde tanımlanmıştır, bu nedenle restoranda_yemek_ye fonksiyonunun tanımlı olduğu modülden başlayan göreceli yol çalışır. Ardından, karsilama ve bekleme_listesine_ekle fonksiyonları pub ile işaretlendiği için yolun geri kalanı çalışır ve bu fonksiyon çağrısı geçerlidir!
Kütüphane crate’inizi diğer projelerin de kodunuzu kullanabilmesi için paylaşmayı planlıyorsanız, açık API’niz, crate’inizin kullanıcılarıyla yapacağınız ve kodunuzla nasıl etkileşime girebileceklerini belirleyen sözleşmenizdir (contract). İnsanların crate’inize bağımlı olmasını kolaylaştırmak için açık API’nizde yapılacak değişiklikleri yönetmekle ilgili pek çok husus vardır. Bu hususlar bu kitabın kapsamı dışındadır; eğer bu konuyla ilgileniyorsanız, Rust API Yönergeleri kılavuzuna bakabilirsiniz.
Bir İkili (Binary) ve Kütüphane (Library) İçeren Paketler İçin En İyi Pratikler
Bir paketin hem src/main.rs ikili crate kökünü hem de src/lib.rs kütüphane crate kökünü içerebileceğinden ve varsayılan olarak her iki crate’in de paket adına sahip olacağından bahsetmiştik. Tipik olarak, hem bir kütüphane hem de bir ikili crate içerme modeline sahip olan paketler, ikili crate’te, kütüphane crate’inde tanımlanan kodu çağıran bir çalıştırılabilir dosya başlatmaya yetecek kadar koda sahip olacaktır. Bu, kütüphane crate’inin kodunun paylaşılabileceği için diğer projelerin paketin sağladığı işlevlerin çoğundan yararlanmasını sağlar.
Modül ağacı src/lib.rs içinde tanımlanmalıdır. Ardından, paketin adıyla başlayan yollar kullanılarak herhangi bir açık öğe ikili crate içinde kullanılabilir. İkili crate, tıpkı tamamen dışarıdan bir crate’in kütüphane crate’ini kullanacağı gibi kütüphane crate’inin bir kullanıcısı haline gelir: Yalnızca açık API’yi kullanabilir. Bu sizin iyi bir API tasarlamanıza yardımcı olur; yalnızca yazar değil, aynı zamanda bir istemcisinizdir (client)!
Bölüm 12’de, hem ikili crate hem de kütüphane crate’i içeren bir komut satırı programı ile bu organizasyonel pratiği (organizational practice) göstereceğiz.
super İle Göreceli (Relative) Yollara Başlamak
Göreceli (relative) yollar oluştururken, yolun (path) başında super kullanarak geçerli modül veya crate kökü yerine üst modülden başlayabiliriz. Bu, dosya sistemindeki yollarda bir üst dizine gitmek anlamına gelen .. sözdizimi ile başlamaya benzer. super kullanmak, üst modülde (parent module) olduğunu bildiğimiz bir öğeye başvurmamızı sağlar; bu da, bir modül üst modülle yakından ilişkiliyken, üst modülün ileride modül ağacında başka bir yere taşınması ihtimaline karşı modül ağacını yeniden düzenlemeyi kolaylaştırabilir.
Liste 7-8’de bir şefin yanlış bir siparişi düzeltip bizzat müşteriye götürdüğü durumu modelleyen kodu düşünün. restoran_arka_kisim modülünde tanımlanan yanlis_siparisi_duzelt (fix_incorrect_order) fonksiyonu, siparisi_teslim_et (deliver_order) fonksiyonunun yolunu belirterek ve super ile başlayarak, üst modülde tanımlı olan siparisi_teslim_et fonksiyonunu çağırır.
fn siparisi_teslim_et() {}
mod restoran_arka_kisim {
fn yanlis_siparisi_duzelt() {
siparisi_pisir();
super::siparisi_teslim_et();
}
fn siparisi_pisir() {}
}super ile başlayan göreceli (relative) bir yolla çağrılmasıyanlis_siparisi_duzelt fonksiyonu restoran_arka_kisim modülü içindedir, bu yüzden restoran_arka_kisim’in üst modülüne (bu durumda kök (root) olan crate’tir) gitmek için super kullanabiliriz. Oradan itibaren siparisi_teslim_et fonksiyonunu arar ve buluruz. Başarılı! Crate’in modül ağacını yeniden düzenlemeye karar verirsek, restoran_arka_kisim modülünün ve siparisi_teslim_et fonksiyonunun birbirleriyle aynı ilişki içinde kalma ihtimalinin yüksek olduğunu ve birlikte taşınacaklarını düşünüyoruz. Bu nedenle, super kullandık ki bu kod başka bir modüle taşındığında gelecekte kodu güncelleyecek daha az yerimiz olsun.
Struct’ları ve Enum’ları Herkese Açık (Public) Yapmak
Struct’ları ve enum’ları da herkese açık olarak belirtmek için pub anahtar kelimesini kullanabiliriz, ancak struct’lar ve enum’lar ile pub kullanımının birkaç ek detayı vardır. Eğer bir struct tanımının öncesinde pub kullanırsak, struct’ı herkese açık yaparız, ancak struct’ın alanları hala gizli kalacaktır. Her bir alanı (field) duruma göre (case-by-case) herkese açık yapıp yapmamayı seçebiliriz. Liste 7-9’da, herkese açık bir tost alanı (field) ve gizli bir mevsim_meyvesi (seasonal_fruit) alanına sahip, açık bir restoran_arka_kisim::Kahvalti (Breakfast) struct’ı tanımladık. Bu durum, müşterinin yemekle birlikte gelen ekmek türünü seçebildiği, ancak şefin o mevsimde nelerin mevcut olduğuna ve stokta ne olduğuna göre hangi meyvenin eşlik edeceğine karar verdiği bir restorandaki durumu modeller. Mevcut olan meyve hızlı değiştiği için müşteriler meyveyi seçemezler ya da hangi meyveyi alacaklarını dahi göremezler.
mod restoran_arka_kisim {
pub struct Kahvalti {
pub tost: String,
mevsim_meyvesi: String,
}
impl Kahvalti {
pub fn yaz(tost: &str) -> Kahvalti {
Kahvalti {
tost: String::from(tost),
mevsim_meyvesi: String::from("şeftali"),
}
}
}
}
pub fn restoranda_yemek_ye() {
// Çavdar tostu ile bir yaz kahvaltısı sipariş edin.
let mut ogun = restoran_arka_kisim::Kahvalti::yaz("Çavdar");
// Hangi ekmeği istediğimiz konusundaki fikrimizi değiştirelim.
ogun.tost = String::from("Buğday");
println!("Lütfen {} tost istiyorum", ogun.tost);
// Aşağıdaki satırın yorumunu kaldırırsak derlenmeyecektir; öğünle birlikte gelen
// mevsim meyvesini görmemize veya değiştirmemize izin verilmez.
// ogun.mevsim_meyvesi = String::from("yaban mersini");
}restoran_arka_kisim::Kahvalti struct’ındaki tost alanı açık olduğu için, restoranda_yemek_ye fonksiyonunda nokta (dot) gösterimini kullanarak tost alanını yazabilir (değiştirebilir) veya okuyabiliriz. Dikkat edin ki mevsim_meyvesi alanı gizli olduğu için, onu restoranda_yemek_ye içinde kullanamayız. Nasıl bir hata aldığınızı görmek için mevsim_meyvesi alanının değerini değiştiren satırın (yorum satırının) yorumunu (uncomment) kaldırmayı deneyin!
Ayrıca, restoran_arka_kisim::Kahvalti struct’ı gizli bir alana sahip olduğu için, bu struct’ın Kahvalti’nın bir örneğini oluşturan herkese açık ilişkili bir fonksiyon sağlaması gerektiğine dikkat edin (burada onu yaz (summer) olarak adlandırdık). Kahvalti struct’ı böyle bir fonksiyona sahip olmasaydı, restoranda_yemek_ye içinde Kahvalti’nın bir örneğini oluşturamazdık, çünkü restoranda_yemek_ye içinde gizli olan mevsim_meyvesi alanının değerini ayarlayamazdık.
Buna karşın, bir enum’ı herkese açık yaparsak, tüm varyantları da açık olur. Liste 7-10’da gösterildiği gibi yalnızca enum anahtar kelimesinden önce pub kullanmamız yeterlidir.
mod restoran_arka_kisim {
pub enum Meze {
Corba,
Salata,
}
}
pub fn restoranda_yemek_ye() {
let siparis1 = restoran_arka_kisim::Meze::Corba;
let siparis2 = restoran_arka_kisim::Meze::Salata;
}Meze (Appetizer) enum’ını açık hale getirdiğimiz için, restoranda_yemek_ye içinde Corba (Soup) ve Salata (Salad) varyantlarını kullanabiliriz.
Varyantları herkese açık olmadıkça enum’lar pek yararlı olmazlar; her durumda tüm enum varyantlarına pub eklemek can sıkıcı olurdu, bu nedenle enum varyantları için varsayılan (default) durum açık olmalarıdır. Struct’lar alanları açık olmadan da çoğu zaman kullanışlıdır, bu nedenle struct alanları, aksi pub ile belirtilmedikçe her şeyin varsayılan olarak gizli olduğu genel kuralını takip eder.
Henüz ele almadığımız ve pub’ı ilgilendiren bir durum daha vardır; o da son modül sistemi özelliğimiz olan use anahtar kelimesidir. Önce use anahtar kelimesini tek başına ele alacağız ve ardından pub ve use’u birlikte nasıl kullanacağımızı göstereceğiz.
use Anahtar Kelimesi ile Yolları Kapsama Dahil Etme
use Anahtar Kelimesi ile Yolları Kapsama (Scope) Getirmek
Fonksiyonları çağırmak için yolları (paths) uzun uzun yazmak zorunda kalmak kullanışsız ve tekrarlayan bir iş gibi hissettirebilir. Liste 7-7’de, bekleme_listesine_ekle fonksiyonu için mutlak ya da göreceli yolu seçmiş olsak da, bekleme_listesine_ekle’yi her çağırmak istediğimizde restoran_on_kisim ve karsilama’yı da belirtmek zorundaydık. Neyse ki bu süreci basitleştirmenin bir yolu var: use anahtar kelimesiyle bir yolun kısayolunu bir kez oluşturabilir ve ardından daha kısa olan bu adı kapsamın diğer her yerinde kullanabiliriz.
Liste 7-11’de, bekleme_listesine_ekle fonksiyonunu restoranda_yemek_ye içinde çağırmak için yalnızca karsilama::bekleme_listesine_ekle belirtmemiz gerekecek şekilde, crate::restoran_on_kisim::karsilama modülünü restoranda_yemek_ye fonksiyonunun kapsamına dahil ediyoruz.
mod restoran_on_kisim {
pub mod karsilama {
pub fn bekleme_listesine_ekle() {}
}
}
use crate::restoran_on_kisim::karsilama;
pub fn restoranda_yemek_ye() {
karsilama::bekleme_listesine_ekle();
}use ile kapsama getirmekBir kapsama use ve bir yol eklemek, dosya sisteminde sembolik bir bağlantı (symbolic link) oluşturmaya benzer. Crate köküne use crate::restoran_on_kisim::karsilama ekleyerek, tıpkı karsilama modülü crate kökünde tanımlanmış gibi, karsilama artık o kapsamda geçerli bir isim haline gelir. use ile kapsama getirilen yollar da tıpkı diğer yollar gibi gizliliği kontrol eder.
use’un kısayolu yalnızca kullanıldığı belirli kapsam için oluşturduğuna dikkat edin. Liste 7-12, restoranda_yemek_ye fonksiyonunu musteri adlı yeni bir alt modüle taşır ve bu modül use ifadesinden farklı bir kapsam olduğu için fonksiyon gövdesi derlenmez.
mod restoran_on_kisim {
pub mod karsilama {
pub fn bekleme_listesine_ekle() {}
}
}
use crate::restoran_on_kisim::karsilama;
mod musteri {
pub fn restoranda_yemek_ye() {
karsilama::bekleme_listesine_ekle();
}
}use ifadesi yalnızca bulunduğu kapsamda geçerlidir.Derleyici hatası, kısayolun artık musteri modülü içinde geçerli olmadığını gösterir:
$ cargo build
Compiling restaurant v0.1.0 ($PROJE/listings/ch07-managing-growing-projects/listing-07-12)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `karsilama`
--> src/lib.rs:11:9
|
11 | karsilama::bekleme_listesine_ekle();
| ^^^^^^^^^ use of unresolved module or unlinked crate `karsilama`
|
= help: if you wanted to use a crate named `karsilama`, use `cargo add karsilama` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::karsilama;
|
warning: unused import: `crate::restoran_on_kisim::karsilama`
--> src/lib.rs:7:5
|
7 | use crate::restoran_on_kisim::karsilama;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` (part of `#[warn(unused)]`) on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Ayrıca use ifadesinin kendi kapsamında artık kullanılmadığına dair bir uyarı olduğuna da dikkat edin! Bu sorunu çözmek için use ifadesini de musteri modülünün içine taşıyın veya alt musteri modülünden, üst modüldeki kısayola super::karsilama ile başvurun.
İdiomatik use Yolları Oluşturmak
Liste 7-11’de, neden use crate::restoran_on_kisim::karsilama’yı belirtip ardından restoranda_yemek_ye içinde karsilama::bekleme_listesine_ekle’yi çağırdığımızı merak etmiş olabilirsiniz; Liste 7-13’teki gibi aynı sonucu elde etmek için use yolunu neden ta bekleme_listesine_ekle fonksiyonuna kadar belirtmedik?
mod restoran_on_kisim {
pub mod karsilama {
pub fn bekleme_listesine_ekle() {}
}
}
use crate::restoran_on_kisim::karsilama::bekleme_listesine_ekle;
pub fn restoranda_yemek_ye() {
bekleme_listesine_ekle();
}bekleme_listesine_ekle fonksiyonunu idiomatik olmayan bir şekilde use ile kapsama getirmekListe 7-11 ve Liste 7-13 aynı işi başarsa da, bir fonksiyonu use ile kapsama getirmenin idiomatik (dile özgü doğru kullanım) yolu Liste 7-11’dir. Fonksiyonun ebeveyn modülünü use ile kapsama getirmek, fonksiyonu çağırırken o ebeveyn modülü belirtmemiz gerektiği anlamına gelir. Fonksiyonu çağırırken ebeveyn modülü belirtmek, bir yandan tam yolun tekrarlanmasını en aza indirirken diğer yandan fonksiyonun yerel olarak tanımlanmadığını da açıkça belli eder. Liste 7-13’teki kodda ise bekleme_listesine_ekle fonksiyonunun nerede tanımlandığı belirsizdir.
Öte yandan, struct’ları, enum’ları ve diğer öğeleri use ile içe aktarırken, tam yolu belirtmek idiomatiktir. Liste 7-14, standart kütüphanenin HashMap struct’ını bir ikili crate’in kapsamına almanın idiomatik yolunu gösterir.
use std::collections::HashMap;
fn main() {
let mut harita = HashMap::new();
harita.insert(1, 2);
}HashMap’i idiomatik bir şekilde kapsama getirmekBu idiomatik kullanımın arkasında çok güçlü bir neden yoktur: Yalnızca ortaya çıkmış bir gelenektir ve insanlar Rust kodunu bu şekilde okuyup yazmaya alışmışlardır.
Bu idiomun (geleneğin) istisnası, use ifadeleriyle aynı ada sahip iki öğeyi kapsama getiriyorsak geçerlidir; çünkü Rust buna izin vermez. Liste 7-15, aynı isme fakat farklı üst modüllere sahip iki Result türünün kapsama nasıl getirileceğini ve bunlara nasıl atıfta bulunulacağını gösterir.
use std::fmt;
use std::io;
fn fonksiyon1() -> fmt::Result {
// --snip--
Ok(())
}
fn fonksiyon2() -> io::Result<()> {
// --snip--
Ok(())
}Gördüğünüz gibi, ebeveyn modülleri kullanmak iki Result türünü birbirinden ayırır. Bunun yerine use std::fmt::Result ve use std::io::Result ifadelerini belirtseydik, aynı kapsamda iki Result türümüz olurdu ve biz Result kelimesini kullandığımızda Rust hangisini kastettiğimizi bilemezdi.
as Anahtar Kelimesiyle Yeni İsimler Sağlamak
Aynı ada sahip iki türü use ile aynı kapsama getirme probleminin başka bir çözümü daha vardır: Yolun ardından, tür için as ve yeni bir yerel ad veya takma ad belirtebiliriz. Liste 7-16, Liste 7-15’teki kodu as kullanarak iki Result türünden birini yeniden adlandırmak suretiyle yazmanın başka bir yolunu gösterir.
use std::fmt::Result;
use std::io::Result as IoResult;
fn fonksiyon1() -> Result {
// --snip--
Ok(())
}
fn fonksiyon2() -> IoResult<()> {
// --snip--
Ok(())
}as anahtar kelimesi ile kapsama getirilen bir türü yeniden adlandırmaİkinci use ifadesinde std::io::Result türü için yeni IoResult adını seçtik; bu ad kapsama dahil ettiğimiz std::fmt içindeki Result ile çakışmayacaktır (conflict). Hem Liste 7-15 hem de Liste 7-16 idiomatik kabul edilir, dolayısıyla seçim size kalmış!
pub use ile İsimleri Yeniden Dışa Aktarmak (Re-exporting)
Bir adı use anahtar kelimesi ile kapsama aldığımızda, bu ad onu içe aktardığımız (import) kapsam için gizli olur. O kapsamın dışındaki kodların bu isme, sanki o kapsamda tanımlanmış gibi atıfta bulunmasını (refer to) sağlamak için pub ve use kelimelerini birleştirebiliriz. Bu tekniğe yeniden dışa aktarma denir çünkü biz bir öğeyi kendi kapsamımıza getirirken aynı zamanda diğerlerinin de o öğeyi kendi kapsamlarına getirebilmesi için onu kullanılabilir kılıyoruz.
Liste 7-17, Liste 7-11’deki kodda kök modüldeki (root module) use ifadesinin pub use olarak değiştirilmiş halini göstermektedir.
mod restoran_on_kisim {
pub mod karsilama {
pub fn bekleme_listesine_ekle() {}
}
}
pub use crate::restoran_on_kisim::karsilama;
pub fn restoranda_yemek_ye() {
karsilama::bekleme_listesine_ekle();
}pub use ile yeni bir kapsamdan herhangi bir kodun kullanabileceği bir ad yaratmakBu değişiklikten önce, harici kodların bekleme_listesine_ekle fonksiyonunu restoran::restoran_on_kisim::karsilama::bekleme_listesine_ekle() yolunu kullanarak çağırması gerekiyordu; ki bu da restoran_on_kisim modülünün pub olarak işaretlenmesini gerektirirdi. Şimdi bu pub use, kök modülden (root module) karsilama modülünü yeniden dışa aktardığı için, harici kodlar bunun yerine restoran::karsilama::bekleme_listesine_ekle() yolunu kullanabilir.
Yeniden dışa aktarma işlemi, kodunuzun iç yapısı (internal structure), kodunuzu çağıran programcıların alanı (domain) nasıl düşüneceğinden farklı olduğunda yararlıdır. Örneğin, bu restoran metaforunda, restoranı işleten kişiler “ön kısım” ve “arka kısım” hakkında düşünürler. Ancak bir restoranı ziyaret eden müşteriler büyük olasılıkla restoranın bölümleri hakkında bu terimlerle düşünmeyeceklerdir. pub use ile kodumuzu tek bir yapıyla yazabilir ancak farklı bir yapıyla açığa çıkarabiliriz. Bunu yapmak, kütüphanemizi hem kütüphane üzerinde çalışan programcılar hem de kütüphaneyi çağıran programcılar için iyi organize edilmiş hale getirir. Bölüm 14’teki “Kullanışlı Bir Genel API’yi Dışa Aktarmak” (Exporting a Convenient Public API) başlığında, pub use için başka bir örneğe ve bunun crate’inizin dokümantasyonunu nasıl etkilediğine bakacağız.
Harici (External) Paketleri Kullanmak
Bölüm 2’de, rastgele sayılar elde etmek için rand adlı harici bir paketi kullanan bir tahmin oyunu projesi programladık. rand paketini projemizde kullanmak için, Cargo.toml dosyamıza şu satırı ekledik:
rand = "0.8.5"
Cargo.toml dosyasına rand paketini bir bağımlılık (dependency) olarak eklemek, Cargo’ya rand paketini ve tüm bağımlılıklarını crates.io adresinden indirip projemiz için erişilebilir kılmasını söyler.
Ardından, rand tanımlarını paketimizin kapsamına dahil etmek için, crate’in adı olan rand ile başlayan bir use satırı ekledik ve kapsama dahil etmek istediğimiz öğeleri listeledik. Hatırlarsanız Bölüm 2’deki “Rastgele Bir Sayı Üretmek” kısmında Rng trait’ini kapsama almış ve rand::thread_rng fonksiyonunu çağırmıştık:
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
}Rust topluluğunun üyeleri crates.io adresinde pek çok paketi kullanıma sunmuştur ve bunlardan herhangi birini kendi paketinize çekmek de aynı adımları gerektirir: Onları paketinizin Cargo.toml dosyasında listelemek ve içerdikleri öğeleri kendi kapsamınıza almak için use kullanmak.
Standart std kütüphanesinin de paketimiz için harici bir crate olduğuna dikkat edin. Standart kütüphane Rust diliyle birlikte geldiğinden (shipped), Cargo.toml dosyamızı std’yi içerecek şekilde değiştirmemize gerek yoktur. Ancak yine de oradaki öğeleri paketimizin kapsamına dahil etmek için ona use ile başvurmamız gerekir. Örneğin, HashMap ile şu satırı kullanırdık:
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}Bu, standart kütüphane crate’inin adı olan std ile başlayan mutlak (absolute) bir yoldur.
Uzun use Listelerini Temizlemek İçin İç İçe (Nested) Yollar Kullanmak
Eğer aynı crate’te ya da aynı modülde tanımlanmış birden çok öğeyi kullanıyorsak, her bir öğeyi kendi satırında listelemek dosyalarımızda dikey olarak çok yer kaplayabilir. Örneğin, Liste 2-4’teki tahmin oyununda yer alan bu iki use ifadesi, öğeleri std’den kapsama getirmektedir:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin().read_line(&mut tahmin).expect("Satır okunamadı");
println!("Tahmininiz: {tahmin}");
match tahmin.cmp(&gizli_sayi.to_string()) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => println!("Kazandınız!"),
}
}Bunun yerine, aynı öğeleri tek bir satırda kapsama getirmek için iç içe yollar (nested paths) kullanabiliriz. Bunu, Liste 7-18’de gösterildiği gibi yolun ortak kısmını, ardından iki nokta üst üste işaretini (::) ve yolların farklılaşan kısımlarının bir listesini süslü parantezler içine alarak yaparız.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin().read_line(&mut tahmin).expect("Satır okunamadı");
let tahmin: u32 = tahmin.trim().parse().expect("Lütfen bir sayı yazın!");
println!("Tahmininiz: {tahmin}");
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => println!("Kazandınız!"),
}
}Büyük programlarda, aynı crate’ten ya da modülden birçok öğeyi iç içe yollar (nested paths) kullanarak kapsama getirmek, ihtiyaç duyulan ayrı use ifadelerinin sayısını büyük ölçüde azaltabilir!
Bir yolda herhangi bir seviyede iç içe yol kullanabiliriz; bu, ortak bir alt yolu (subpath) paylaşan iki use ifadesini birleştirirken yararlıdır. Örneğin, Liste 7-19 iki adet use ifadesi göstermektedir: biri std::io’yu kapsama getirirken, diğeri std::io::Write’ı kapsama getirir.
use std::io;
use std::io::Write;use ifadesiBu iki yolun ortak noktası std::io’dur ve bu tamamen ilk yola karşılık gelir. Bu iki yolu tek bir use ifadesinde birleştirmek için, Liste 7-20’de gösterildiği gibi iç içe yolda self kullanabiliriz.
use std::io::{self, Write};use ifadesinde birleştirmekBu satır std::io ve std::io::Write’ı kapsama alır.
Öğeleri Glob Operatörü ile İçe Aktarmak
Eğer bir yolda tanımlı tüm açık öğeleri kapsama almak istiyorsak, o yolu belirtebilir ve ardından * glob operatörünü koyabiliriz:
#![allow(unused)]
fn main() {
use std::collections::*;
}Bu use ifadesi, std::collections içinde tanımlı tüm açık öğeleri geçerli kapsama getirir. Glob operatörünü kullanırken dikkatli olun! Glob, hangi isimlerin kapsamda olduğunu ve programınızda kullanılan bir ismin nerede tanımlandığını anlamanızı zorlaştırabilir. Ayrıca, bağımlılık (dependency) kendi tanımlarını değiştirirse, içe aktardığınız (imported) şeyler de değişir; bu da örneğin, bağımlılık, aynı kapsamdaki sizin bir tanımınızla aynı isme sahip bir tanım eklerse, bağımlılığı güncellediğinizde derleyici hatalarına yol açabilir.
Glob operatörü, test yazarken test edilecek her şeyi tests modülü içine almak için sıkça kullanılır; bu konuyu Bölüm 11’deki “Nasıl Test Yazılır?” kısmında ele alacağız. Glob operatörü bazen prelude (ön hazırlık/başlangıç) kalıbının (pattern) bir parçası olarak da kullanılır: Bu kalıp hakkında daha fazla bilgi edinmek için standart kütüphane dokümantasyonuna bakabilirsiniz.
Modülleri Farklı Dosyalara Ayırma
Modülleri Farklı Dosyalara Ayırma
Şimdiye kadar bu bölümdeki tüm örnekler birden fazla modülü tek bir dosyada tanımladı. Modüller büyüdüğünde, kod içinde gezinmeyi (navigate) kolaylaştırmak için modül tanımlarını ayrı bir dosyaya taşımak isteyebilirsiniz.
Örneğin, birden çok restoran modülü içeren Liste 7-17’deki koddan başlayalım. Tüm modülleri crate kök dosyasında tanımlamak yerine, modülleri ayrı dosyalara çıkaracağız. Bu durumda crate kök dosyası src/lib.rs’dir, ancak bu prosedür, crate kök dosyası src/main.rs olan ikili crate’lerde de çalışır.
İlk olarak restoran_on_kisim modülünü kendi dosyasına çıkaracağız. restoran_on_kisim modülü için süslü parantezlerin içindeki kodu kaldırın ve src/lib.rs’in Liste 7-21’de gösterilen kodu içermesi için sadece mod restoran_on_kisim; bildirimini (declaration) bırakın. Liste 7-22’deki src/restoran_on_kisim.rs dosyasını oluşturana kadar bu kodun derlenmeyeceğini unutmayın.
mod restoran_on_kisim;
pub use crate::restoran_on_kisim::karsilama;
pub fn restoranda_yemek_ye() {
karsilama::bekleme_listesine_ekle();
}restoran_on_kisim modülünü bildirmekDaha sonra, Liste 7-22’de gösterildiği gibi, süslü parantezlerin içinde bulunan kodu src/restoran_on_kisim.rs adlı yeni bir dosyaya yerleştirin. Derleyici, bu dosyaya bakması gerektiğini bilir çünkü crate kökünde restoran_on_kisim adında bir modül bildirimiyle karşılaşmıştır.
pub mod karsilama {
pub fn bekleme_listesine_ekle() {}
}restoran_on_kisim modülünün tanımlarıModül ağacınızda bir dosyayı yüklemek için mod bildirimini yalnızca bir kez kullanmanız gerektiğini unutmayın. Derleyici, dosyanın projenin bir parçası olduğunu bildiğinde (ve mod ifadesini nereye koyduğunuzdan dolayı kodun modül ağacının neresinde bulunduğunu anladığında), projenizdeki diğer dosyalar yüklenen dosyanın koduna “Modül Ağacındaki Bir Öğeye Başvurmak İçin Yollar (Paths)” bölümünde anlatıldığı gibi o dosyanın nerede tanımlandığını gösteren bir yol kullanarak atıfta bulunmalıdır. Başka bir deyişle, mod diğer programlama dillerinde görmüş olabileceğiniz bir “include” (dahil etme) işlemi değildir.
Sonraki adımda, karsilama modülünü kendi dosyasına çıkaracağız. Bu süreç biraz farklıdır çünkü karsilama, kök (root) modülünün değil, restoran_on_kisim modülünün bir alt modülüdür. karsilama dosyasını modül ağacındaki ata modüllerine göre adlandırılacak yeni bir dizine, bu durumda src/restoran_on_kisim dizinine yerleştireceğiz.
karsilama modülünü taşımaya başlamak için src/restoran_on_kisim.rs dosyasını, yalnızca karsilama modülünün bildirimini içerecek şekilde değiştiriyoruz:
pub mod karsilama;Daha sonra, karsilama modülünde yapılan tanımları içermesi için src/restoran_on_kisim adlı bir dizin ve içinde bir karsilama.rs dosyası oluşturuyoruz:
pub fn bekleme_listesine_ekle() {}Eğer karsilama.rs dosyasını src dizinine koysaydık derleyici karsilama.rs kodunun, restoran_on_kisim modülünün bir alt modülü olarak değil de doğrudan crate kökünde bildirilen bir karsilama modülünde olmasını beklerdi. Derleyicinin hangi modüllerin kodu için hangi dosyaları kontrol edeceğine dair kuralları, dizinlerin ve dosyaların modül ağacıyla daha yakından eşleştiği anlamına gelir.
Alternatif Dosya Yolları
Şimdiye kadar Rust derleyicisinin kullandığı en idiomatik dosya yollarını ele aldık, ancak Rust daha eski bir dosya yolu stilini de destekler. Crate kökünde tanımlanan restoran_on_kisim adlı bir modül için derleyici modülün kodunu şurada arayacaktır:
- src/restoran_on_kisim.rs (bizim işlediğimiz)
- src/restoran_on_kisim/mod.rs (daha eski stil, hala desteklenen yol)
restoran_on_kisim modülünün alt modülü olan karsilama adlı bir modül için ise, derleyici modülün kodunu şurada arayacaktır:
- src/restoran_on_kisim/karsilama.rs (bizim işlediğimiz)
- src/restoran_on_kisim/karsilama/mod.rs (daha eski stil, hala desteklenen yol)
Aynı modül için her iki stili de kullanırsanız, derleyici hatası alırsınız. Aynı projedeki farklı modüller için her iki stili bir arada kullanmaya izin verilir ancak projenizde gezinen kişiler için kafa karıştırıcı olabilir.
mod.rs adlı dosyaları kullanan stilin ana dezavantajı, projenizde mod.rs adlı birçok dosyanın bulunması ve bu dosyaların editörünüzde aynı anda açık olduğunda kafa karışıklığı yaratabilmesidir.
Her modülün kodunu ayrı bir dosyaya taşıdık ve modül ağacı aynı kaldı. restoranda_yemek_ye içindeki fonksiyon çağrıları, tanımlar farklı dosyalarda yaşasa bile herhangi bir değişiklik olmadan çalışacaktır. Bu teknik, modüllerin boyutları büyüdükçe onları yeni dosyalara taşımanıza olanak tanır.
src/lib.rs içindeki pub use crate::restoran_on_kisim::karsilama ifadesinin de değişmediğine ve use anahtar kelimesinin crate’in bir parçası olarak hangi dosyaların derlendiği üzerinde hiçbir etkisinin olmadığına dikkat edin. mod anahtar kelimesi modülleri tanımlar (declare) ve Rust o modülün içine giren kod için modülle aynı ada sahip bir dosyaya bakar.
Özet
Rust, bir modülde tanımlanan öğelere başka bir modülden atıfta bulunabilmeniz (refer to) için bir paketi birden çok crate’e ve bir crate’i birden çok modüle bölmenizi sağlar. Bunu mutlak veya göreceli yollar (absolute or relative paths) belirterek yapabilirsiniz. Bu yollar, o kapsamda öğenin birden çok kullanımı için daha kısa bir yol kullanabilmeniz adına use ifadesiyle kapsama dahil edilebilir. Modül kodu varsayılan olarak gizlidir, ancak pub anahtar kelimesini ekleyerek tanımları açık hale getirebilirsiniz.
Bir sonraki bölümde, standart kütüphanede (standard library) bulunan ve kendi düzenli organize edilmiş kodunuzda kullanabileceğiniz bazı koleksiyon veri yapılarına (collection data structures) bakacağız.
Yaygın Koleksiyonlar
Rust’ın standart kütüphanesi, koleksiyonlar adı verilen çok kullanışlı bir dizi veri yapısı içerir. Diğer birçok veri türü tek bir spesifik değeri temsil ederken, koleksiyonlar birden fazla değeri barındırabilir. Gömülü dizi ve demet türlerinin aksine, bu koleksiyonların işaret ettiği veriler yığında saklanır; bu da veri miktarının derleme zamanında bilinmesine gerek olmadığı ve program çalışırken büyüyüp küçülebileceği anlamına gelir. Her koleksiyon türünün farklı yetenekleri ve maliyetleri vardır, mevcut durumunuz için en uygun olanı seçmek zamanla geliştireceğiniz bir yetenektir. Bu bölümde, Rust programlarında çok sık kullanılan üç koleksiyonu ele alacağız:
- Bir vektör, yan yana duran değişken sayıda değeri depolamanızı sağlar.
- Bir string (dizgi), karakterlerden oluşan bir koleksiyondur. Daha önce
Stringtüründen bahsetmiştik ancak bu bölümde onu derinlemesine inceleyeceğiz. - Bir hash map (karma harita), bir değeri belirli bir anahtarla ilişkilendirmenizi sağlar. Bu, harita adı verilen daha genel bir veri yapısının özel bir uygulamasıdır.
Standart kütüphane tarafından sağlanan diğer koleksiyon türleri hakkında bilgi edinmek için belgelere göz atabilirsiniz.
Vektörlerin, stringlerin ve hash maplerin nasıl oluşturulup güncelleneceğini ve her birini neyin özel kıldığını tartışacağız.
Vektörlerle Değer Listeleri Saklama
Vektörlerle Değer Listeleri Depolamak
Bakacağımız ilk koleksiyon türü, Vec<T>, diğer adıyla vektördür.
Vektörler, birden fazla değeri hafızada (bellekte) yan yana koyan tek bir veri yapısında depolamanızı sağlar. Vektörler sadece aynı türdeki değerleri depolayabilir. Bir dosyadaki metin satırları veya alışveriş sepetindeki ürünlerin fiyatları gibi bir öğe listeniz olduğunda kullanışlıdırlar.
Yeni Bir Vektör Oluşturmak
Yeni, boş bir vektör oluşturmak için Liste 8-1’de gösterildiği gibi Vec::new fonksiyonunu çağırırız.
fn main() {
let v: Vec<i32> = Vec::new();
}i32 türünden değerleri tutacak yeni, boş bir vektör oluşturmakBurada bir tür ek açıklaması eklediğimize dikkat edin. Bu vektöre herhangi bir değer eklemediğimiz için, Rust ne tür elemanları depolamak niyetinde olduğumuzu bilmez. Bu önemli bir noktadır. Vektörler jenerikler kullanılarak uygulanmıştır; kendi türlerinizle jenerikleri nasıl kullanacağınızı Bölüm 10’da ele alacağız. Şimdilik standart kütüphane tarafından sağlanan Vec<T> türünün herhangi bir türü barındırabileceğini bilin. Belirli bir türü tutması için bir vektör oluşturduğumuzda, bu türü açılı parantezler içinde belirtebiliriz. Liste 8-1’de, Rust’a v içerisindeki Vec<T>’nin i32 türünden elemanlar tutacağını söyledik.
Daha sıklıkla, başlangıç değerleriyle bir Vec<T> oluşturursunuz ve Rust depolamak istediğiniz değerin türünü çıkarsar, bu yüzden bu tür ek açıklamasına nadiren ihtiyaç duyarsınız. Rust, verdiğiniz değerleri tutan yeni bir vektör oluşturacak olan kullanışlı vec! makrosunu sağlar. Liste 8-2, 1, 2 ve 3 değerlerini tutan yeni bir Vec<i32> oluşturur. Tamsayı türü i32’dir, çünkü Bölüm 3’teki “Veri Türleri” bölümünde tartıştığımız gibi, bu varsayılan tamsayı türüdür.
fn main() {
let v = vec![1, 2, 3];
}Başlangıçta i32 değerleri verdiğimiz için Rust, v’nin türünün Vec<i32> olduğu sonucuna varabilir ve tür ek açıklamasına gerek kalmaz. Sırada, bir vektörün nasıl değiştirileceğine bakacağız.
Bir Vektörü Güncellemek
Bir vektör oluşturup ardından ona elemanlar eklemek için, Liste 8-3’te gösterildiği gibi push (it) metodunu kullanabiliriz.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}push metodunu kullanmakBölüm 3’te tartışıldığı gibi, herhangi bir değişkenle ilgili olduğu üzere, eğer değerini değiştirebilmek istiyorsak, onu mut anahtar kelimesini kullanarak değiştirilebilir yapmamız gerekir. İçine yerleştirdiğimiz sayıların hepsi i32 türündedir ve Rust bunu veriden anlar, bu yüzden Vec<i32> ek açıklamasına ihtiyacımız yoktur.
Vektörlerin Elemanlarını Okumak
Bir vektörde depolanan bir değere referans vermenin iki yolu vardır: indeksleme yoluyla veya get (al) metodunu kullanarak. Aşağıdaki örneklerde, ekstra netlik için bu fonksiyonlardan döndürülen değerlerin türlerini ek açıklama ile belirttik.
Liste 8-4, indeksleme sözdizimi ve get metodu ile bir vektördeki bir değere erişmenin her iki yolunu da gösterir.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let ucuncu: &i32 = &v[2];
println!("Üçüncü eleman: {ucuncu}");
let ucuncu: Option<&i32> = v.get(2);
match ucuncu {
Some(ucuncu) => println!("Üçüncü eleman: {ucuncu}"),
None => println!("Üçüncü bir eleman yok."),
}
}get metodunu kullanmakBurada birkaç detaya dikkat edin. Üçüncü elemanı almak için 2 indeks değerini kullanırız çünkü vektörler sıfırdan başlayarak sayılarla indekslenir. & ve [] kullanmak, indeks değerindeki elemanın referansını verir. get metodunu indeks bir argüman olarak geçirilmiş şekilde kullandığımızda, match ile kullanabileceğimiz bir Option<&T> elde ederiz.
Rust, mevcut elemanların aralığının dışındaki bir indeks değerini kullanmaya çalıştığınızda programın nasıl davranacağını seçebilmeniz için bir elemana referans vermenin bu iki yolunu sunar. Bir örnek olarak, beş elemanlı bir vektörümüz olduğunda ve ardından Liste 8-5’te gösterildiği gibi her iki teknikle 100. indeksteki bir elemana erişmeye çalıştığımızda ne olduğuna bakalım.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let olmayan_eleman = &v[100];
let olmayan_eleman = v.get(100);
}Bu kodu çalıştırdığımızda, ilk [] metodu programın panik yapmasına neden olacaktır çünkü var olmayan bir elemana referans verir. Bu yöntem, vektörün sonunu geçecek şekilde bir elemana erişilme girişimi olduğunda programınızın çökmesini istiyorsanız en iyi seçenektir.
get metoduna vektörün dışında bir indeks geçirildiğinde, panik yapmadan None döndürür. Normal şartlar altında vektör aralığının ötesindeki bir elemana erişim zaman zaman meydana gelebiliyorsa bu yöntemi kullanırsınız. Daha sonra kodunuz, Bölüm 6’da tartışıldığı gibi, Some(&eleman) veya None olma durumunu yönetecek bir mantığa sahip olacaktır. Örneğin, indeks, bir kullanıcının girdiği bir sayıdan geliyor olabilir. Yanlışlıkla çok büyük bir sayı girerlerse ve program bir None değeri alırsa, kullanıcıya mevcut vektörde kaç tane öğe olduğunu söyleyebilir ve geçerli bir değer girmeleri için bir şans daha verebilirsiniz. Bu, bir yazım hatası nedeniyle programın çökmesinden daha kullanıcı dostu olacaktır!
Programın geçerli bir referansı olduğunda, ödünç alma denetleyicisi bu referansın ve vektörün içeriğine yönelik diğer referansların geçerli kalmasını sağlamak için (Bölüm 4’te kapsanan) sahiplik ve ödünç alma kurallarını zorunlu tutar. Aynı kapsamda değiştirilebilir ve değiştirilemez referanslara sahip olamayacağınızı belirten kuralı hatırlayın. Bu kural, bir vektördeki ilk elemana değiştirilemez bir referans tuttuğumuz ve sonuna bir eleman eklemeye çalıştığımız Liste 8-6’da uygulanır. Eğer daha sonra fonksiyonda o elemana tekrar atıfta bulunmaya çalışırsak bu program çalışmayacaktır.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let ilk = &v[0];
v.push(6);
println!("İlk eleman: {ilk}");
}Bu kodun derlenmesi şu hatayla sonuçlanacaktır:
$ cargo run
Compiling koleksiyonlar v0.1.0 ($PROJE/listings/ch08-common-koleksiyonlar/listing-08-06)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:7:5
|
5 | let ilk = &v[0];
| - immutable borrow occurs here
6 |
7 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
8 |
9 | println!("İlk eleman: {ilk}");
| --- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `koleksiyonlar` (bin "koleksiyonlar") due to 1 previous error
Liste 8-6’daki kod çalışması gerekiyormuş gibi görünebilir: İlk elemana olan bir referans, vektörün sonundaki değişiklikleri neden umursasın ki? Bu hata vektörlerin çalışma şeklinden kaynaklanmaktadır: Vektörler değerleri bellekte yan yana yerleştirdiğinden, vektörün sonuna yeni bir eleman eklemek, eğer tüm elemanları vektörün şu anda depolandığı yerde yan yana koyacak kadar alan yoksa, yeni bir bellek ayırmayı ve eski elemanları yeni alana kopyalamayı gerektirebilir. Bu durumda, ilk elemana olan referans, ayrılmamış belleğe işaret ediyor olacaktır. Ödünç alma kuralları programların o duruma düşmesini engeller.
Not:
Vec<T>türünün uygulama ayrıntıları hakkında daha fazlası için “The Rustonomicon” kitabına bakın.
Bir Vektördeki Değerlerin Üzerinde Yineleme (Iterating) Yapmak
Bir vektördeki her bir elemana sırayla erişmek için, her defasında birine erişmek adına indeksleri kullanmak yerine, tüm elemanlar boyunca yineleme yapabiliriz. Liste 8-7, i32 değerlerinden oluşan bir vektördeki her bir elemanın değiştirilemez referanslarını almak ve onları yazdırmak için bir for döngüsünün nasıl kullanılacağını gösterir.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}for döngüsü kullanarak elemanların üzerinde yineleme yaparak bir vektördeki her elemanı yazdırmakTüm elemanlarda değişiklik yapmak için değiştirilebilir bir vektördeki her elemanın değiştirilebilir referansları üzerinde de yineleme yapabiliriz. Liste 8-8’deki for döngüsü her bir elemana 50 ekleyecektir.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}Değiştirilebilir referansın işaret ettiği değeri değiştirmek için, += operatörünü kullanmadan önce i’deki değere ulaşmak amacıyla * referansı kaldırma operatörünü kullanmalıyız. Referansı kaldırma operatörü hakkında daha fazla bilgiyi Bölüm 15’teki “Referansı Kaldırma Operatörü ile İşaretçiden Değere Ulaşmak” bölümünde konuşacağız.
Bir vektör üzerinde, ister değiştirilemez ister değiştirilebilir şekilde, yineleme yapmak ödünç alma denetleyicisinin kuralları sayesinde güvenlidir. Eğer Liste 8-7 ve Liste 8-8’deki for döngüsü gövdelerinde öğe eklemeye veya çıkarmaya kalkışsaydık, Liste 8-6’daki kodla aldığımıza benzer bir derleyici hatası alırdık. for döngüsünün tuttuğu vektöre olan referans, tüm vektörün eşzamanlı olarak değiştirilmesini engeller.
Birden Fazla Türü Depolamak için Enum Kullanmak
Vektörler sadece aynı türdeki değerleri depolayabilir. Bu rahatsız edici olabilir; farklı türlerdeki öğelerin bir listesini depolamaya kesinlikle ihtiyaç duyduğumuz kullanım durumları vardır. Neyse ki, bir enum’ın varyantları aynı enum türü altında tanımlanır, dolayısıyla farklı türlerdeki elemanları temsil etmek için tek bir türe ihtiyaç duyduğumuzda, bir enum tanımlayabilir ve kullanabiliriz!
Örneğin, bir elektronik tabloda, bir satırdaki bazı sütunların tam sayılar, bazılarının ondalıklı sayılar ve bazılarının da stringler içerdiği bir değer dizisini almak istediğimizi varsayalım. Varyantları farklı değer türlerini tutacak bir enum tanımlayabiliriz ve tüm enum varyantları aynı tür (enum’ın türü) kabul edilir. Ardından, o enum’ı tutacak ve böylece nihayetinde farklı türleri barındıracak bir vektör oluşturabiliriz. Bunu Liste 8-9’da gösterdik.
fn main() {
enum ElektronikTabloHucresi {
Tamsayi(i32),
Ondalikli(f64),
Metin(String),
}
let satir = vec![
ElektronikTabloHucresi::Tamsayi(3),
ElektronikTabloHucresi::Metin(String::from("mavi")),
ElektronikTabloHucresi::Ondalikli(10.12),
];
}Rust, her bir elemanı yığında depolamak için tam olarak ne kadar belleğe ihtiyaç duyulacağını bilmesi amacıyla, derleme zamanında vektörde hangi türlerin olacağını bilmek zorundadır. Ayrıca bu vektörde hangi türlere izin verildiği konusunda da açık olmalıyız. Eğer Rust bir vektörün herhangi bir türü barındırmasına izin verseydi, bir veya daha fazla türün vektörün elemanları üzerinde gerçekleştirilen operasyonlarda hatalara neden olma ihtimali olurdu. Bir enum ve match (eşleştirme) ifadesi kullanmak, Bölüm 6’da tartışıldığı gibi, Rust’ın her olası durumun ele alındığından derleme zamanında emin olması anlamına gelir.
Eğer bir programın çalışma zamanında bir vektörde depolamak üzere alacağı türlerin kapsamlı kümesini bilmiyorsanız, enum tekniği işe yaramayacaktır. Bunun yerine, Bölüm 18’de ele alacağımız bir trait nesnesi kullanabilirsiniz.
Vektörleri kullanmanın en yaygın yollarından bazılarını tartıştığımıza göre, standart kütüphane tarafından Vec<T> üzerinde tanımlanmış birçok kullanışlı metodun tamamı için API belgelerini mutlaka inceleyin. Örneğin, push (it) metoduna ek olarak, bir pop (çıkar) metodu son elemanı kaldırır ve döndürür.
Bir Vektörü Düşürmek (Dropping) Elemanlarını Da Düşürür
Diğer herhangi bir struct gibi, bir vektör de Liste 8-10’da belirtildiği gibi kapsam dışına çıktığında serbest bırakılır.
fn main() {
{
let v = vec![1, 2, 3, 4];
// v ile bir şeyler yapın
} // <- v kapsam dışına çıkar ve burada serbest bırakılır
}Vektör düşürüldüğünde, tüm içeriği de düşürülür, yani barındırdığı tamsayılar temizlenecektir. Ödünç alma denetleyicisi, bir vektörün içeriğine yapılan herhangi bir referansın yalnızca vektörün kendisi geçerliyken kullanılmasını sağlar.
Bir sonraki koleksiyon türüne geçelim: String!
String'lerle UTF-8 Kodlanmış Metin Saklama
Stringlerle UTF-8 Kodlanmış Metin Depolamak
Bölüm 4’te stringlerden (dizgilerden) bahsetmiştik, ancak şimdi onları daha derinlemesine inceleyeceğiz. Yeni Rustacean’lar genellikle üç nedenin birleşimi yüzünden stringlerde takılırlar: Rust’ın olası hataları açığa çıkarma eğilimi, stringlerin birçok programcının sandığından daha karmaşık bir veri yapısı olması ve UTF-8. Bu faktörler, başka programlama dillerinden geldiğinizde zor görünebilecek bir şekilde birleşir.
Stringleri koleksiyonlar bağlamında tartışıyoruz çünkü stringler bir bayt koleksiyonu ve o baytlar metin olarak yorumlandığında yararlı işlevsellik sağlamak için bazı metotlar olarak uygulanmıştır. Bu bölümde, her koleksiyon türünün sahip olduğu oluşturma, güncelleme ve okuma gibi String üzerindeki işlemlerden bahsedeceğiz. Ayrıca String’in diğer koleksiyonlardan farklı olduğu yolları, yani insanların ve bilgisayarların String verilerini yorumlama biçimleri arasındaki farklar nedeniyle bir String’e indeksleme yapmanın ne kadar karmaşık olduğunu da tartışacağız.
Stringleri Tanımlamak
Öncelikle string terimiyle ne kastettiğimizi tanımlayacağız. Rust, çekirdek dilinde yalnızca bir string türüne sahiptir: genellikle ödünç alınmış biçiminde &str olarak görülen string dilimi str. Bölüm 4’te, başka bir yerde depolanan bazı UTF-8 kodlanmış string verilerine referanslar olan string dilimlerinden bahsettik. Örneğin, string sabitleri programın ikili dosyasında saklanır ve bu nedenle string dilimleridirler.
Çekirdek dile kodlanmak yerine Rust’ın standart kütüphanesi tarafından sağlanan String türü, büyütülebilir, değiştirilebilir, sahiplenilmiş, UTF-8 kodlamalı bir string türüdür. Rustacean’lar Rust’ta “stringlerden” bahsettiklerinde, bu türlerden sadece birini değil, String veya string dilimi &str türlerinden herhangi birini kastediyor olabilirler. Bu bölüm büyük ölçüde String ile ilgili olsa da, her iki tür de Rust’ın standart kütüphanesinde yoğun bir şekilde kullanılır ve hem String hem de string dilimleri UTF-8 ile kodlanmıştır.
Yeni Bir String Oluşturmak
Vec<T> ile kullanılabilen aynı işlemlerin birçoğu String ile de mevcuttur, çünkü String aslında bazı ekstra garantiler, kısıtlamalar ve yeteneklerle bir bayt vektörünün etrafında bir sarmalayıcı olarak uygulanmıştır. Vec<T> ve String ile aynı şekilde çalışan bir fonksiyona örnek, Liste 8-11’de gösterildiği gibi, bir örnek oluşturmak için kullanılan new fonksiyonudur.
fn main() {
let mut s = String::new();
}String oluşturmakBu satır s adında yeni, boş bir string oluşturur ve daha sonra içine veri yükleyebiliriz. Genellikle string’i başlatmak istediğimiz bazı başlangıç verilerimiz olacaktır. Bunun için, string sabitlerinin yaptığı gibi Display trait’ini uygulayan herhangi bir türde kullanılabilen to_string metodunu kullanırız. Liste 8-12 iki örnek gösterir.
fn main() {
let veri = "başlangıç içeriği";
let s = veri.to_string();
// The method also works on a literal directly:
let s = "başlangıç içeriği".to_string();
}String oluşturmak için to_string metodunu kullanmakBu kod, başlangıç içeriği içeren bir string oluşturur.
Ayrıca bir string sabitinden String oluşturmak için String::from fonksiyonunu da kullanabiliriz. Liste 8-13’teki kod, to_string kullanan Liste 8-12’deki kodla eşdeğerdir.
fn main() {
let s = String::from("başlangıç içeriği");
}String oluşturmak için String::from fonksiyonunu kullanmakStringler pek çok şey için kullanıldığından, stringler için bize birçok seçenek sunan pek çok farklı jenerik API kullanabiliriz. Bazıları gereksiz (redundant) görünebilir, ancak hepsinin yeri vardır! Bu durumda, String::from ve to_string aynı şeyi yapar, bu nedenle hangisini seçeceğiniz bir stil ve okunabilirlik meselesidir.
Unutmayın stringler UTF-8 kodludur, bu yüzden Liste 8-14’te gösterildiği gibi uygun şekilde kodlanmış herhangi bir veriyi onlara dahil edebiliriz.
fn main() {
let merhaba = String::from("السلام عليكم");
let merhaba = String::from("Dobrý den");
let merhaba = String::from("Hello");
let merhaba = String::from("שלום");
let merhaba = String::from("नमस्ते");
let merhaba = String::from("こんにちは");
let merhaba = String::from("안녕하세요");
let merhaba = String::from("你好");
let merhaba = String::from("Olá");
let merhaba = String::from("Здравствуйте");
let merhaba = String::from("Hola");
}Bunların hepsi geçerli String değerleridir.
Bir String’i Güncellemek
Bir String boyutu büyüyebilir ve tıpkı Vec<T> içeriğinde olduğu gibi, içine daha fazla veri iterseniz (push) içeriği değişebilir. Ayrıca, String değerlerini birleştirmek için + operatörünü veya format! makrosunu rahatça kullanabilirsiniz.
push_str veya push ile Ekleme Yapmak
Liste 8-15’te gösterildiği gibi bir string dilimi eklemek için push_str metodunu kullanarak bir String’i büyütebiliriz.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}push_str metodu kullanılarak bir String’e bir string dilimi eklemekBu iki satırdan sonra s değişkeni foobar içerecektir. push_str metodu bir string dilimi alır çünkü parametrenin sahipliğini almak istemeyebiliriz. Örneğin, Liste 8-16’daki kodda, s2’nin içeriğini s1’e ekledikten sonra onu kullanabilmek istiyoruz.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 değeri: {s2}");
}String’e ekledikten sonra bir string dilimi kullanmakEğer push_str metodu s2’nin sahipliğini alsaydı, onun değerini son satırda yazdıramazdık. Ancak, bu kod beklediğimiz gibi çalışır!
push metodu tek bir karakteri parametre olarak alır ve onu String’e ekler. Liste 8-17, push metodu kullanarak bir String’e l harfini ekler.
fn main() {
let mut s = String::from("lo");
s.push('l');
}push kullanarak bir String değerine tek bir karakter eklemekSonuç olarak s, lol içerecektir.
+ veya format! ile Birleştirmek
Sıklıkla iki mevcut string’i birleştirmek istersiniz. Bunu yapmanın bir yolu Liste 8-18’de gösterildiği gibi + operatörünü kullanmaktır.
fn main() {
let s1 = String::from("Merhaba, ");
let s2 = String::from("dünya!");
let s3 = s1 + &s2; // not: s1 buraya taşındı ve artık kullanılamaz
}String değerini yeni bir String değerinde birleştirmek için + operatörünü kullanmaks3 string’i Merhaba, dünya! içerecektir. Ekledikten sonra s1’in artık geçerli olmamasının ve s2’ye bir referans kullanmamızın nedeni, + operatörünü kullandığımızda çağrılan metodun imzası ile ilgilidir. + operatörü, imzası şuna benzeyen add metodunu kullanır:
fn add(self, s: &str) -> String {Standart kütüphanede, add’in jenerikler ve ilişkili türler kullanılarak tanımlandığını göreceksiniz. Burada, somut türleri yerine koyduk ki bu, metodu String değerleriyle çağırdığımızda olan şeydir. Jenerikleri Bölüm 10’da tartışacağız. Bu imza, + operatörünün karmaşık kısımlarını anlamamız için gereken ipuçlarını bize verir.
İlk olarak, s2 bir &’e sahiptir, bu da ikinci string’in bir referansını ilk string’e eklediğimiz anlamına gelir. Bunun nedeni add fonksiyonundaki s parametresidir: Bir String’e sadece bir string dilimi ekleyebiliriz; iki String değerini birbirine ekleyemeyiz. Ama bir dakika, add’in ikinci parametresinde belirtildiği gibi &s2’nin türü &str değil, &String’dir. Öyleyse Liste 8-18 neden derleniyor?
add çağrısında &s2’yi kullanabilmemizin nedeni, derleyicinin &String argümanını bir &str’ye zorlayabilmesidir. add metodunu çağırdığımızda Rust, burada &s2’yi &s2[..] haline getiren bir deref zorlaması kullanır. Deref zorlamasını Bölüm 15’te daha derinlemesine tartışacağız. add fonksiyonu s parametresinin sahipliğini almadığı için, s2 bu operasyondan sonra hala geçerli bir String olacaktır.
İkinci olarak, imzada add fonksiyonunun self’in sahipliğini aldığını görebiliriz, çünkü self bir &’e sahip değildir. Bu, Liste 8-18’deki s1’in add çağrısının içine taşınacağı ve ondan sonra artık geçerli olmayacağı anlamına gelir. Yani, let s3 = s1 + &s2; ifadesi her iki string’i kopyalayıp yeni bir tane oluşturacakmış gibi görünse de, bu ifade aslında s1’in sahipliğini alır, s2’nin içeriğinin bir kopyasını ekler ve ardından sonucun sahipliğini döndürür. Başka bir deyişle, bir sürü kopya yapıyormuş gibi görünür ama yapmaz; bu uygulama kopyalamadan daha verimlidir.
Eğer birden fazla string’i birleştirmemiz gerekirse, + operatörünün davranışı hantal hale gelir:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}Bu noktada s, tic-tac-toe olacaktır. Tüm o + ve " karakterleriyle neler olup bittiğini görmek zordur. Stringleri daha karmaşık şekillerde birleştirmek için bunun yerine format! makrosunu kullanabiliriz:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}Bu kod da s’i tic-tac-toe olarak ayarlar. format! makrosu println! gibi çalışır, ancak çıktıyı ekrana yazdırmak yerine içeriklerle birlikte bir String döndürür. format! kullanan kod sürümünün okunması çok daha kolaydır ve format! makrosu tarafından oluşturulan kod referanslar kullandığından, bu çağrı parametrelerinin hiçbirinin sahipliğini almaz.
Stringleri İndekslemek
Diğer birçok programlama dilinde, bir string’deki tekil karakterlere indeksleriyle başvurarak erişmek geçerli ve yaygın bir işlemdir. Ancak, Rust’ta indeksleme sözdizimini kullanarak bir String’in parçalarına erişmeye çalışırsanız bir hata alırsınız. Liste 8-19’daki geçersiz kodu inceleyelim.
fn main() {
let s1 = String::from("merhaba");
let m = s1[0];
}String ile indeksleme sözdizimini kullanmaya çalışmakBu kod aşağıdaki hatayla sonuçlanacaktır:
$ cargo run
Compiling koleksiyonlar v0.1.0 ($PROJE/listings/ch08-common-koleksiyonlar/listing-08-19)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:4:16
|
4 | let m = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
help: the following other types implement trait `SliceIndex<T>`
--> $HOME/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/slice/index.rs:214:1
|
214 | unsafe impl<T> const SliceIndex<[T]> for usize {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `usize` implements `SliceIndex<[T]>`
|
::: $HOME/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/bstr/traits.rs:203:1
|
203 | unsafe impl SliceIndex<ByteStr> for usize {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `usize` implements `SliceIndex<ByteStr>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `koleksiyonlar` (bin "koleksiyonlar") due to 1 previous error
Hata hikayeyi anlatıyor: Rust stringleri indekslemeyi desteklemiyor. Peki ama neden? Bu soruyu cevaplamak için Rust’ın stringleri bellekte nasıl sakladığını tartışmamız gerekiyor.
İç Temsil (Internal Representation)
Bir String, bir Vec<u8> üzerinde sarmalayıcıdır. Liste 8-14’teki uygun şekilde kodlanmış UTF-8 örnek stringlerimizden bazılarına bakalım. Önce buna:
fn main() {
let merhaba = String::from("السلام عليكم");
let merhaba = String::from("Dobrý den");
let merhaba = String::from("Hello");
let merhaba = String::from("שלום");
let merhaba = String::from("नमस्ते");
let merhaba = String::from("こんにちは");
let merhaba = String::from("안녕하세요");
let merhaba = String::from("你好");
let merhaba = String::from("Olá");
let merhaba = String::from("Здравствуйте");
let merhaba = String::from("Hola");
}Bu durumda, uzunluk (len) 4 olacaktır, bu da "Hola" stringini saklayan vektörün 4 bayt uzunluğunda olduğu anlamına gelir. UTF-8 ile kodlandığında bu harflerin her biri 1 bayt yer kaplar. Ancak aşağıdaki satır sizi şaşırtabilir (bu string’in 3 rakamıyla değil, büyük Kiril harfi Ze ile başladığına dikkat edin):
fn main() {
let merhaba = String::from("السلام عليكم");
let merhaba = String::from("Dobrý den");
let merhaba = String::from("Hello");
let merhaba = String::from("שלום");
let merhaba = String::from("नमस्ते");
let merhaba = String::from("こんにちは");
let merhaba = String::from("안녕하세요");
let merhaba = String::from("你好");
let merhaba = String::from("Olá");
let merhaba = String::from("Здравствуйте");
let merhaba = String::from("Hola");
}Eğer size string’in ne kadar uzun olduğu sorulsaydı, 12 diyebilirdiniz. Aslında Rust’ın cevabı 24’tür: Bu, “Здравствуйте” stringini UTF-8’de kodlamak için gereken bayt sayısıdır, çünkü o string’deki her bir Unicode skaler değeri 2 bayt depolama alanı kaplar. Bu nedenle, string’in baytlarındaki bir indeks her zaman geçerli bir Unicode skaler değeri ile ilişkili olmayacaktır. Bunu göstermek için, şu geçersiz Rust kodunu inceleyin:
let merhaba = "Здравствуйте";
let cevap = &merhaba[0];cevap değişkeninin ilk harf olan З olmayacağını zaten biliyorsunuz. UTF-8 ile kodlandığında З harfinin ilk baytı 208, ikincisi ise 151’dir, bu yüzden görünüşe göre cevap aslında 208 olmalıdır, ancak 208 tek başına geçerli bir karakter değildir. Bir kullanıcı bu string’in ilk harfini istediğinde muhtemelen 208 döndürülmesini istemeyecektir; ancak Rust’ın bayt indeks 0’da sahip olduğu tek veri budur. String sadece Latin harfleri içerse bile kullanıcılar genellikle bayt değerinin döndürülmesini istemezler: Eğer &"hi"[0] bayt değerini döndüren geçerli bir kod olsaydı, h değil 104 döndürürdü.
O halde cevap, beklenmedik bir değer döndürmekten ve hemen keşfedilemeyecek hatalara neden olmaktan kaçınmak için Rust’ın bu kodu hiç derlememesi ve geliştirme sürecinin başlarında yanlış anlamaları önlemesidir.
Baytlar, Skaler Değerler ve Grafem Kümeleri (Grapheme Clusters)
UTF-8 ile ilgili bir diğer nokta da Rust’ın perspektifinden stringlere bakmanın aslında üç alakalı yolu olmasıdır: baytlar, skaler değerler ve grafem kümeleri (bizim harfler olarak adlandırdığımız şeye en yakın olan şey).
Devanagari alfabesiyle yazılmış Hintçe “नमस्ते” kelimesine bakarsak, şöyle görünen bir u8 değerleri vektörü olarak saklanır:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Bu 18 bayttır ve bilgisayarların bu veriyi nihayetinde saklama şeklidir. Onlara Rust’ın char türünün karşılığı olan Unicode skaler değerleri olarak bakarsak, bu baytlar şöyle görünür:
['न', 'म', 'स', '्', 'त', 'े']
Burada altı tane char değeri vardır, ancak dördüncü ve altıncı harf değildir: Onlar tek başlarına anlam ifade etmeyen aksan işaretleridir. Son olarak, onlara grafem kümeleri olarak bakarsak, bir insanın Hintçe kelimeyi oluşturan dört harf olarak adlandıracağı şeyi elde ederiz:
["न", "म", "स्", "ते"]
Rust, veri hangi insan dilinde olursa olsun, her programın ihtiyaç duyduğu yorumlamayı seçebilmesi için bilgisayarların sakladığı ham string verilerini yorumlamanın farklı yollarını sunar.
Rust’ın bir karakteri elde etmek için bir String’e indeksleme yapmamıza izin vermemesinin son bir nedeni de, indeksleme işlemlerinin her zaman sabit zaman (constant time, O(1)) almasının beklenmesidir. Ancak bir String ile bu performansı garanti etmek mümkün değildir, çünkü Rust’ın kaç tane geçerli karakter olduğunu belirlemek için içeriğin başından indekse kadar yürümesi gerekir.
Stringleri Dilimlemek (Slicing)
String indeksleme işleminin dönüş türünün ne olması gerektiği (bir bayt değeri mi, bir karakter mi, bir grafem kümesi mi yoksa bir string dilimi mi) net olmadığı için bir string içine indeksleme yapmak genellikle kötü bir fikirdir. Bu nedenle, string dilimleri oluşturmak için gerçekten indeksleri kullanmanız gerekiyorsa, Rust sizden daha spesifik olmanızı ister.
[] operatörünü tek bir numarayla kullanarak indeksleme yapmak yerine, belirli baytları içeren bir string dilimi oluşturmak için [] operatörünü bir aralık (range) ile kullanabilirsiniz:
#![allow(unused)]
fn main() {
let merhaba = "Здравствуйте";
let s = &merhaba[0..4];
}Burada s, stringin ilk 4 baytını barındıran bir &str olacaktır. Daha önce bu karakterlerin her birinin 2 bayt olduğundan bahsetmiştik, yani s, Зд olacaktır.
Eğer bir karakterin baytlarının sadece bir kısmını &merhaba[0..1] gibi bir şeyle dilimlemeye çalışsaydık, tıpkı bir vektörde geçersiz bir indekse erişilmiş gibi Rust çalışma zamanında panik yapardı:
$ cargo run
Compiling koleksiyonlar v0.1.0 ($PROJE/listings/ch08-common-koleksiyonlar/output-only-01-not-char-boundary)
thread 'main' (34670) panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Aralıklar kullanarak string dilimleri oluştururken dikkatli olmalısınız çünkü bunu yapmak programınızı çökertebilir.
Stringlerin Üzerinde Yineleme (Iterating) Yapmak
Stringlerin parçaları üzerinde çalışmanın en iyi yolu, karakter mi yoksa bayt mı istediğinizi açıkça belirtmektir. Bireysel Unicode skaler değerleri için chars (karakterler) metodunu kullanın. “Зд” üzerinde chars çağrıldığında char türünde iki değeri ayırır ve döndürür; her bir elemana erişmek için sonucun üzerinde yineleme yapabilirsiniz:
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}Bu kod aşağıdakileri yazdıracaktır:
З
д
Alternatif olarak bytes (baytlar) metodu her bir ham baytı döndürür, ki bu sizin kullanım alanınız için uygun olabilir:
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}Bu kod, bu string’i oluşturan 4 baytı yazdıracaktır:
208
151
208
180
Ancak geçerli Unicode skaler değerlerinin 1 bayttan fazlasından oluşabileceğini unutmayın.
Devanagari alfabesinde olduğu gibi stringlerden grafem kümeleri elde etmek karmaşıktır, bu nedenle bu işlev standart kütüphane tarafından sağlanmaz. İhtiyacınız olan işlevsellik buysa crates.io adresinde crateler mevcuttur.
Stringlerin Karmaşıklıklarıyla Başa Çıkmak
Özetlemek gerekirse, stringler karmaşıktır. Farklı programlama dilleri, bu karmaşıklığı programcıya nasıl sunacakları konusunda farklı seçimler yaparlar. Rust, String verilerinin doğru işlenmesini tüm Rust programları için varsayılan davranış haline getirmeyi seçti; bu da programcıların UTF-8 verilerini en başından ele almak için daha fazla kafa yormaları gerektiği anlamına gelir. Bu takas, stringlerin karmaşıklığının diğer programlama dillerinde görünenden daha fazlasını açığa çıkarır, ancak geliştirme yaşam döngünüzün ilerleyen aşamalarında ASCII olmayan karakterlerle ilgili hataları ele almak zorunda kalmanızı önler.
İyi haber şu ki, standart kütüphane bu karmaşık durumları doğru bir şekilde ele almaya yardımcı olmak için String ve &str türleri üzerine inşa edilmiş birçok işlev sunuyor. Bir string’de arama yapmak için contains (içerir) ve bir string’in parçalarını başka bir string ile değiştirmek için replace (değiştir) gibi faydalı metotlar için belgelere göz atmayı unutmayın.
Biraz daha az karmaşık bir şeye geçelim: hash mapler (karma haritalar)!
Hash Map'lerde Anahtarları ve İlişkili Değerleri Saklama
İlişkili Değerlerle Anahtarları Hash Maplerde Saklamak
Yaygın koleksiyonlarımızın sonuncusu hash map’tir (karma harita). HashMap<K, V> türü, K türündeki anahtarları V türündeki değerlerle eşleştirmeyi depolamak için bir karma fonksiyonu kullanır ve bu fonksiyon, bu anahtar ve değerleri belleğe nasıl yerleştireceğini belirler. Birçok programlama dili bu tür bir veri yapısını destekler, ancak genellikle hash, map (harita), object (nesne), hash table (karma tablosu), dictionary (sözlük) veya associative array (ilişkisel dizi) gibi birkaç farklı isim kullanırlar.
Hash mapler, verileri vektörlerde olduğu gibi bir indeks kullanarak değil de herhangi bir türde olabilen bir anahtar kullanarak aramak istediğinizde kullanışlıdır. Örneğin bir oyunda, her takımın skorunu bir hash mapte tutabilirsiniz; burada her anahtar bir takımın adıdır ve değerler her takımın skorudur. Bir takımın adı verildiğinde, skorunu alabilirsiniz.
Bu bölümde hash maplerin temel API’sini inceleyeceğiz, ancak standart kütüphane tarafından HashMap<K, V> üzerinde tanımlanan fonksiyonlarda daha birçok güzel şey saklıdır. Her zaman olduğu gibi, daha fazla bilgi için standart kütüphane belgelerini kontrol edin.
Yeni Bir Hash Map Oluşturmak
Boş bir hash map oluşturmanın bir yolu new kullanmak ve insert (ekle) ile eleman eklemektir. Liste 8-20’de isimleri Mavi ve Sarı olan iki takımın skorlarını takip ediyoruz. Mavi takım 10 puanla, Sarı takım ise 50 puanla başlar.
fn main() {
use std::collections::HashMap;
let mut skorlar = HashMap::new();
skorlar.insert(String::from("Mavi"), 10);
skorlar.insert(String::from("Sarı"), 50);
}Önce standart kütüphanenin koleksiyonlar kısmından HashMap’i use ile kullanıma dahil etmemiz gerektiğine dikkat edin. Üç yaygın koleksiyonumuzdan bu, en az sıklıkla kullanılanıdır, bu nedenle otomatik olarak kapsama dahil edilen özellikler arasında yer almaz. Hash mapler ayrıca standart kütüphaneden daha az destek alır; örneğin, bunları oluşturmak için yerleşik bir makro yoktur.
Tıpkı vektörler gibi, hash mapler de verilerini yığında depolar. Bu HashMap, String türünde anahtarlara ve i32 türünde değerlere sahiptir. Vektörler gibi, hash mapler de homojendir: Tüm anahtarlar aynı türde olmalı ve tüm değerler aynı türde olmalıdır.
Bir Hash Mapteki Değerlere Erişmek
Liste 8-21’de gösterildiği gibi anahtarını get (al) metoduna sağlayarak hash map’ten bir değer alabiliriz.
fn main() {
use std::collections::HashMap;
let mut skorlar = HashMap::new();
skorlar.insert(String::from("Mavi"), 10);
skorlar.insert(String::from("Sarı"), 50);
let takim_adi = String::from("Mavi");
let skor = skorlar.get(&takim_adi).copied().unwrap_or(0);
}Burada skor, Mavi takımla ilişkili değere sahip olacak ve sonuç 10 olacaktır. get metodu bir Option<&V> döndürür; hash mapte o anahtar için bir değer yoksa get, None döndürecektir. Bu program Option’ı, Option<&i32> yerine Option<i32> almak için copied (kopyalanmış) çağrısı yaparak ve ardından eğer skorlar bu anahtar için bir girdiye sahip değilse skor’u sıfıra ayarlamak için unwrap_or çağrısı yaparak ele alır.
Bir for döngüsü kullanarak, vektörlerde yaptığımıza benzer bir şekilde bir hash map’teki her anahtar-değer çifti üzerinde yineleme yapabiliriz:
fn main() {
use std::collections::HashMap;
let mut skorlar = HashMap::new();
skorlar.insert(String::from("Mavi"), 10);
skorlar.insert(String::from("Sarı"), 50);
for (anahtar, deger) in &skorlar {
println!("{anahtar}: {deger}");
}
}Bu kod her bir çifti rastgele bir sırada yazdıracaktır:
Sarı: 50
Mavi: 10
Hash Maplerde Sahipliği Yönetmek
i32 gibi Copy (kopyalama) trait’ini uygulayan türler için değerler hash map’e kopyalanır. String gibi sahiplenilmiş değerler için değerler taşınacak ve Liste 8-22’de gösterildiği gibi hash map bu değerlerin sahibi olacaktır.
fn main() {
use std::collections::HashMap;
let alan_adi = String::from("Favori renk");
let alan_degeri = String::from("Mavi");
let mut map = HashMap::new();
map.insert(alan_adi, alan_degeri);
// alan_adi ve alan_degeri bu noktada geçersizdir, bunları kullanmayı deneyin ve
// hangi derleyici hatasını aldığınızı görün!
}alan_adi ve alan_degeri değişkenlerini, insert çağrısıyla hash map’e taşındıktan sonra artık kullanamayız.
Eğer hash map’e değerlere ait referansları eklersek, değerler hash map’e taşınmaz. Referansların işaret ettiği değerler, en az hash map geçerli olduğu sürece geçerli olmalıdır. Bu konular hakkında Bölüm 10’da “Referansları Ömürlerle Doğrulamak (Validating References with Lifetimes)” kısmında daha fazla konuşacağız.
Bir Hash Mapi Güncellemek
Anahtar ve değer çiftlerinin sayısı artabilir olsa da her benzersiz anahtarın aynı anda yalnızca bir değerle ilişkisi olabilir (ancak tersi geçerli değildir: Örneğin hem Mavi takım hem de Sarı takım, skorlar hash map’inde 10 değerini depolayabilir).
Bir hash mapteki veriyi değiştirmek istediğinizde, bir anahtara halihazırda bir değer atanmışsa bu durumu nasıl ele alacağınıza karar vermelisiniz. Eski değeri tamamen göz ardı edip yerine yeni değeri koyabilirsiniz. Eski değeri koruyup yeni değeri yok sayabilir ve yalnızca anahtarın zaten bir değeri yoksa yeni değeri ekleyebilirsiniz. Veya eski değer ile yeni değeri birleştirebilirsiniz. Her birini nasıl yapacağımıza bakalım!
Bir Değerin Üzerine Yazmak (Overwriting)
Eğer bir hash map’e bir anahtar ve bir değer ekler ve daha sonra aynı anahtarı farklı bir değerle eklerseniz, o anahtarla ilişkili değer değiştirilir. Liste 8-23’teki kod insert fonksiyonunu iki kez çağırsa bile, hash map yalnızca bir anahtar-değer çifti barındıracaktır çünkü her ikisinde de Mavi takımın anahtarı için değer ekliyoruz.
fn main() {
use std::collections::HashMap;
let mut skorlar = HashMap::new();
skorlar.insert(String::from("Mavi"), 10);
skorlar.insert(String::from("Mavi"), 25);
println!("{skorlar:?}");
}Bu kod {"Mavi": 25} yazdıracaktır. 10 olan orijinal değerin üzerine yazılmıştır.
Yalnızca Bir Anahtarın Değeri Yoksa Bir Anahtar ve Değer Eklemek
Belirli bir anahtarın bir değer ile hash mapte halihazırda var olup olmadığını kontrol etmek ve ardından şu eylemleri gerçekleştirmek yaygındır: Eğer anahtar hash mapte varsa mevcut değer olduğu gibi kalmalıdır; eğer anahtar yoksa onu ve onun için bir değer ekleyin.
Hash maplerin bunun için kontrol etmek istediğiniz anahtarı parametre olarak alan entry (giriş) adında özel bir API’si vardır. entry metodunun dönüş değeri, var olabilecek veya olmayabilecek bir değeri temsil eden Entry adlı bir enum’dır. Diyelim ki Sarı takımın anahtarının onunla ilişkili bir değeri olup olmadığını kontrol etmek istiyoruz. Eğer yoksa 50 değerini eklemek istiyoruz ve aynısını Mavi takım için de yapmak istiyoruz. entry API’si kullanılarak kod, Liste 8-24’teki gibi görünür.
fn main() {
use std::collections::HashMap;
let mut skorlar = HashMap::new();
skorlar.insert(String::from("Mavi"), 10);
skorlar.entry(String::from("Sarı")).or_insert(50);
skorlar.entry(String::from("Mavi")).or_insert(50);
println!("{skorlar:?}");
}entry metodu kullanarak değer eklemekEntry üzerindeki or_insert metodu, karşılık gelen Entry anahtarı varsa o değere değiştirilebilir bir referans (mutable reference) döndürmek üzere tanımlanmıştır ve eğer yoksa, parametreyi bu anahtar için yeni bir değer olarak ekler ve yeni değere değiştirilebilir bir referans döndürür. Bu teknik, mantığı kendi başımıza yazmaktan çok daha temizdir ve ek olarak ödünç alma denetleyicisi ile daha uyumlu çalışır.
Liste 8-24’teki kodun çalıştırılması {"Sarı": 50, "Mavi": 10} yazdıracaktır. İlk entry çağrısı, Sarı takım için 50 değeri ile birlikte anahtarı ekleyecektir çünkü Sarı takımın halihazırda bir değeri yoktur. İkinci entry çağrısı hash map’i değiştirmeyecektir çünkü Mavi takım halihazırda 10 değerine sahiptir.
Eski Değere Dayalı Olarak Bir Değeri Güncellemek
Hash mapler için başka bir yaygın kullanım durumu, bir anahtarın değerini aramak ve sonra eski değere dayanarak onu güncellemektir. Örneğin Liste 8-25, bazı metinlerdeki her bir kelimenin kaç kez geçtiğini sayan bir kod gösterir. Anahtarlar olarak kelimeleri içeren bir hash map kullanıyoruz ve o kelimeyi kaç kez gördüğümüzü takip etmek için değeri artırıyoruz. Eğer bir kelimeyi ilk kez görüyorsak ilk olarak 0 değerini ekleyeceğiz.
fn main() {
use std::collections::HashMap;
let metin = "merhaba dünya harika dünya";
let mut map = HashMap::new();
for kelime in metin.split_whitespace() {
let sayac = map.entry(kelime).or_insert(0);
*sayac += 1;
}
println!("{map:?}");
}Bu kod {"dünya": 2, "merhaba": 1, "harika": 1} yazdıracaktır. Aynı anahtar-değer çiftlerinin farklı bir sırada yazdırıldığını görebilirsiniz: “Bir Hash Mapteki Değerlere Erişmek” bölümünden bir hash map üzerinde yineleme yapmanın rastgele bir düzende gerçekleştiğini hatırlayın.
split_whitespace (boşluklardan_ayır) metodu, metin içindeki değerin boşluklarla ayrılmış alt dilimleri üzerinde bir yineleyici döndürür. or_insert metodu belirtilen anahtar için değere değiştirilebilir bir referans (&mut V) döndürür. Burada, bu değiştirilebilir referansı sayac değişkeninde depoluyoruz, bu nedenle bu değere atama yapmak için öncelikle yıldız imi (*) kullanarak sayac’ı referanstan kaldırmalıyız. Değiştirilebilir referans for döngüsünün sonunda kapsamın dışına çıkar, bu nedenle tüm bu değişiklikler güvenlidir ve ödünç alma kuralları tarafından izin verilir.
Karma (Hashing) Fonksiyonları
Varsayılan olarak HashMap, karma tablolarını barındıran hizmet reddi (denial-of-service, DoS) saldırılarına karşı direnç sağlayabilen SipHash adlı bir karma fonksiyonu kullanır1. Bu mevcut en hızlı karma algoritması değildir, ancak performanstaki düşüşle birlikte gelen daha iyi güvenlik için yapılan takasa değer. Eğer kodunuzun profilini çıkarır ve varsayılan karma fonksiyonunun amaçlarınız için çok yavaş olduğunu fark ederseniz, farklı bir karma oluşturucu belirterek başka bir fonksiyona geçiş yapabilirsiniz. Bir hasher (karma oluşturucu), BuildHasher trait’ini uygulayan bir türdür. Trait’ler ve bunların nasıl uygulanacağı hakkında Bölüm 10’da konuşacağız. Kendi karma oluşturucunuzu baştan uygulamak zorunda değilsiniz; crates.io, diğer Rust kullanıcıları tarafından paylaşılan, birçok yaygın karma algoritmasını uygulayan karma oluşturucular sağlayan kütüphanelere sahiptir.
Özet
Vektörler, stringler ve hash mapler verileri depolamanız, bunlara erişmeniz ve bunları değiştirmeniz gerektiğinde programlarda gereken büyük miktarda işlevselliği sağlayacaktır. İşte artık çözmek için donanımlı olmanız gereken bazı egzersizler:
- Bir tam sayı listesi verildiğinde bir vektör kullanın ve listenin medyanını (sıralandığında, orta konumdaki değer) ve modunu (en sık oluşan değer; burada bir hash map yardımcı olacaktır) döndürün.
- Stringleri Pig Latin’e (Domuz Latincesi) dönüştürün. Her kelimenin ilk sessiz harfi kelimenin sonuna taşınır ve ay eklenir, böylece ilk ilkay-f (irst-fay) olur. Sesli harfle başlayan kelimelerin sonuna bunun yerine hay eklenir (elma (apple), elma-hay (apple-hay) olur). UTF-8 kodlamasıyla ilgili detayları aklınızda bulundurun!
- Bir hash map ve vektörler kullanarak bir kullanıcının bir şirketteki bir departmana çalışan isimleri eklemesini sağlamak için bir metin arayüzü oluşturun; örneğin, “Sally’yi Mühendisliğe Ekle (Add Sally to Engineering)” veya “Amir’i Satışa Ekle (Add Amir to Sales)”. Ardından kullanıcının bir departmandaki tüm kişilerin veya şirketteki tüm kişilerin departmana göre alfabetik olarak sıralanmış bir listesini almasına izin verin.
Standart kütüphane API belgeleri, bu egzersizler için yararlı olacak vektörlerin, stringlerin ve hash maplerin sahip olduğu metotları açıklar!
İşlemlerin başarısız olabileceği daha karmaşık programlara giriyoruz, bu yüzden hata yönetimi hakkında tartışmak için mükemmel bir zaman. Sırada bunu yapacağız!
Hata Yönetimi
Hatalar, yazılımda hayatın bir gerçeğidir; bu nedenle Rust’ın, bir şeylerin yanlış gittiği durumları ele almak için bir dizi özelliği vardır. Çoğu durumda Rust, kodunuzun derlenmesinden önce bir hata olasılığını kabul etmenizi ve bazı eylemlerde bulunmanızı gerektirir. Bu gereklilik, kodunuzu üretime (production) dağıtmadan önce hataları keşfetmenizi ve uygun şekilde ele almanızı sağlayarak programınızı daha sağlam hale getirir!
Rust, hataları iki ana kategoriye ayırır: kurtarılabilir (recoverable) ve kurtarılamaz hatalar. Örneğin bir dosya bulunamadı hatası gibi kurtarılabilir bir hata için büyük olasılıkla sadece sorunu kullanıcıya bildirmek ve işlemi yeniden denemek isteriz. Kurtarılamaz hatalar ise her zaman bir dizinin sonunun ötesindeki bir konuma erişmeye çalışmak gibi hataların belirtileridir ve bu yüzden programı derhal durdurmak isteriz.
Çoğu dil bu iki tür hata arasında ayrım yapmaz ve istisnalar (exceptions) gibi mekanizmalar kullanarak her ikisini de aynı şekilde ele alır. Rust’ta istisnalar (exceptions) yoktur. Bunun yerine, kurtarılabilir hatalar için Result<T, E> türüne ve program kurtarılamaz bir hatayla karşılaştığında yürütmeyi durduran panic! makrosuna sahiptir. Bu bölüm önce panic! çağırmayı ele alıyor ve ardından Result<T, E> değerleri döndürmek hakkında konuşuyor. Ek olarak, bir hatadan kurtulmaya çalışıp çalışmamaya veya yürütmeyi durdurup durdurmamaya karar verirken dikkat edilmesi gerekenleri inceleyeceğiz.
panic! ile Kurtarılamayan Hatalar
panic! ile Kurtarılamayan Hatalar
Bazen kodunuzda kötü şeyler olur ve bu konuda yapabileceğiniz hiçbir şey yoktur. Bu durumlar için Rust’ın panic! makrosu vardır. Uygulamada paniğe neden olmanın iki yolu vardır: kodumuzun panik yapmasına neden olacak bir eylemde bulunmak (bir dizinin sonunu geçerek erişmek gibi) veya açıkça panic! makrosunu çağırmak. Her iki durumda da programımızda bir paniğe neden oluruz. Varsayılan olarak bu panikler bir hata mesajı yazdıracak, yığını geri saracak (unwind), temizleyecek ve çıkacaktır. Bir çevre değişkeni aracılığıyla, bir panik meydana geldiğinde paniğin kaynağının izini sürmeyi kolaylaştırmak için Rust’ın çağrı yığınını (call stack) görüntülemesini de sağlayabilirsiniz.
Bir Paniğe Yanıt Olarak Yığını Geri Sarmak veya İptal Etmek
Varsayılan olarak, bir panik oluştuğunda program geri sarmaya (unwinding) başlar, bu da Rust’ın yığında geriye doğru yürüdüğü ve karşılaştığı her fonksiyondan verileri temizlediği anlamına gelir. Ancak, geriye doğru yürümek ve temizlemek çok iş gerektirir. Bu nedenle Rust, alternatif olarak verileri temizlemeden programı sonlandıran hemen iptal etme (aborting) seçeneğini de sunar.
Programın kullanmakta olduğu belleğin daha sonra işletim sistemi tarafından temizlenmesi gerekecektir. Projenizde ortaya çıkan ikili dosyayı olabildiğince küçük yapmanız gerekiyorsa, Cargo.toml dosyanızdaki uygun [profile] bölümlerine panic = 'abort' ekleyerek panik anında geri sarmadan iptal etmeye geçebilirsiniz. Örneğin, yayın (release) modunda panik anında iptal etmek istiyorsanız şunu ekleyin:
[profile.release]
panic = 'abort'
Basit bir programda panic! çağırmayı deneyelim:
fn main() {
panic!("çök ve yan");
}Programı çalıştırdığınızda şuna benzer bir şey göreceksiniz:
$ cargo run
Compiling panik v0.1.0 ($PROJE/listings/ch09-error-handling/no-listing-01-panik)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.09s
Running `target/debug/panik`
thread 'main' (44082) panikked at src/main.rs:2:5:
çök ve yan
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
panic! çağrısı, son iki satırda bulunan hata mesajına neden olur. İlk satır, panik mesajımızı ve kaynak kodumuzda paniğin oluştuğu yeri gösterir: src/main.rs:2:5 bunun, src/main.rs dosyamızın ikinci satırı, beşinci karakteri olduğunu belirtir.
Bu durumda, belirtilen satır bizim kodumuzun bir parçasıdır ve o satıra gidersek panic! makro çağrısını görürüz. Diğer durumlarda, panic! çağrısı kodumuzun çağırdığı bir kodda olabilir ve hata mesajı tarafından bildirilen dosya adı ve satır numarası, nihayetinde panic! çağrısına yol açan bizim kodumuzun satırı değil, panic! makrosunun çağrıldığı başka birinin kodundaki satır olacaktır.
Probleme neden olan kodumuzun bölümünü bulmak için, panic! çağrısının geldiği fonksiyonların geri izlemesini (backtrace) kullanabiliriz. Bir panic! geri izlemesini nasıl kullanacağımızı anlamak için başka bir örneğe bakalım ve bir panic! çağrısı makroyu doğrudan çağıran bizim kodumuzdan ziyade, kodumuzdaki bir hata nedeniyle bir kütüphaneden geldiğinde neye benzediğini görelim. Liste 9-1, bir vektörde geçerli indeks aralığının ötesindeki bir indekse erişmeye çalışan bir koda sahiptir.
fn main() {
let v = vec![1, 2, 3];
v[99];
}panic! çağrısına neden olacaktırBurada vektörümüzün 100. elemanına (indeksleme sıfırdan başladığı için 99. indekstedir) erişmeye çalışıyoruz ancak vektörün sadece üç elemanı var. Bu durumda Rust panik yapacaktır. [] kullanımının bir eleman döndürmesi varsayılır, ancak geçersiz bir indeks geçerseniz Rust’ın burada döndürebileceği doğru olan bir eleman yoktur.
C’de bir veri yapısının sonunun ötesinde okuma yapmaya çalışmak tanımsız davranıştır (undefined behavior). Bellek o yapıya ait olmasa bile, veri yapısındaki o elemana karşılık gelecek olan bellekteki konumda ne varsa onu alabilirsiniz. Buna arabellek aşımı (buffer overread) denir ve eğer bir saldırgan indeksi veri yapısından sonra depolanan ve izin verilmemesi gereken verileri okuyacak şekilde manipüle edebiliyorsa güvenlik açıklarına (security vulnerabilities) yol açabilir.
Programınızı bu tür güvenlik açıklarından korumak için, eğer var olmayan bir indeksteki bir elemanı okumaya çalışırsanız, Rust yürütmeyi durduracak ve devam etmeyi reddedecektir. Deneyelim ve görelim:
$ cargo run
Compiling panik v0.1.0 ($PROJE/listings/ch09-hata-yonetimi/listing-09-01)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.11s
Running `target/debug/panik`
thread 'main' (42022) panikked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Bu hata, main.rs dosyamızın 4. satırına işaret ediyor; burada v vektörünün 99. indeksine erişmeye çalışıyoruz.
note: satırı, hataya neden olan şeyin tam olarak ne olduğunun bir geri izlemesini (backtrace) almak için RUST_BACKTRACE çevre değişkenini ayarlayabileceğimizi söyler. Bir geri izleme (backtrace), bu noktaya gelmek için çağrılan tüm fonksiyonların bir listesidir. Rust’taki geri izlemeler diğer dillerdeki gibi çalışır: Geri izlemeyi okumanın anahtarı, en üstten başlayıp kendi yazdığınız dosyaları görene kadar okumaktır. Sorunun ortaya çıktığı nokta orasıdır. O noktanın üstündeki satırlar sizin kodunuzun çağırdığı koddur; altındaki satırlar ise sizin kodunuzu çağıran koddur. Bu önceki ve sonraki satırlar, çekirdek Rust kodunu, standart kütüphane kodunu veya kullanmakta olduğunuz crateleri içerebilir. RUST_BACKTRACE çevre değişkenini 0 hariç herhangi bir değere ayarlayarak bir geri izleme almayı deneyelim. Liste 9-2, göreceğinize benzer bir çıktı gösterir.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
RUST_BACKTRACE çevre değişkeni ayarlandığında görüntülenen bir panic! çağrısı tarafından oluşturulan geri izlemeBu epey bir çıktı! Göreceğiniz kesin çıktı, işletim sisteminize ve Rust sürümünüze bağlı olarak farklı olabilir. Bu bilgileri içeren geri izlemeleri almak için hata ayıklama sembollerinin etkinleştirilmiş olması gerekir. Hata ayıklama sembolleri, burada yaptığımız gibi, --release bayrağı olmadan cargo build veya cargo run kullanıldığında varsayılan olarak etkinleştirilir.
Liste 9-2’deki çıktıda, geri izlemenin 6. satırı projemizde soruna neden olan satıra işaret eder: src/main.rs dosyasının 4. satırı. Eğer programımızın panik yapmasını istemiyorsak, incelememize kendi yazdığımız bir dosyadan bahseden ilk satırın işaret ettiği konumdan başlamalıyız. Bilerek panik yapacak kod yazdığımız Liste 9-1’de, paniği düzeltmenin yolu vektör indeks aralığının ötesinde bir eleman istememektir. Kodunuz gelecekte paniklediğinde, kodun paniğe neden olmak için hangi değerlerle nasıl bir eylemde bulunduğunu ve bunun yerine kodun ne yapması gerektiğini bulmanız gerekecektir.
Daha sonra bu bölümdeki “panic! Yapmalı mı Yapmamalı mı?” kısmında panic!’e ve hata durumlarını ele almak için panic!’i ne zaman kullanıp ne zaman kullanmamamız gerektiğine geri döneceğiz. Sırada, Result kullanarak bir hatadan nasıl kurtulacağımıza bakacağız.
Result ile Kurtarılabilir Hatalar
Result ile Kurtarılabilir Hatalar
Çoğu hata, programın tamamen durmasını gerektirecek kadar ciddi değildir. Bazen bir fonksiyon başarısız olduğunda, bunun nedeni kolayca yorumlayıp yanıt verebileceğiniz bir nedendir. Örneğin, bir dosyayı açmaya çalışırsanız ve bu işlem dosya mevcut olmadığı için başarısız olursa, süreci sonlandırmak yerine dosyayı oluşturmak isteyebilirsiniz.
Bölüm 2’deki “Potansiyel Başarısızlığı Result ile Ele Almak” kısmından hatırlayın, Result enum’ı Ok ve Err olmak üzere iki varyanta (seçeneğe) sahip olarak aşağıdaki gibi tanımlanır:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}T ve E jenerik tür parametreleridir: Jenerikleri Bölüm 10’da daha ayrıntılı olarak tartışacağız. Şu anda bilmeniz gereken şey, T’nin Ok varyantı içindeki bir başarı durumunda döndürülecek değerin türünü, E’nin ise Err varyantı içindeki bir başarısızlık durumunda döndürülecek hatanın türünü temsil ettiğidir. Result bu jenerik tür parametrelerine sahip olduğu için, döndürmek istediğimiz başarı değeri ve hata değerinin farklı olabileceği birçok farklı durumda Result türünü ve üzerinde tanımlanan fonksiyonları kullanabiliriz.
Başarısız olabileceği için Result değeri döndüren bir fonksiyon çağıralım. Liste 9-3’te bir dosya açmaya çalışıyoruz.
use std::fs::File;
fn main() {
let karsilama_dosyasi_sonucu = File::open("merhaba.txt");
}File::open’ın dönüş türü bir Result<T, E>’dir. Jenerik T parametresi File::open uygulaması tarafından, bir dosya tutucusu (file handle) olan std::fs::File başarı değeri türü ile doldurulmuştur. Hata değerinde kullanılan E’nin türü std::io::Error’dır. Bu dönüş türü, File::open çağrısının başarılı olabileceği ve okuyabileceğimiz veya yazabileceğimiz bir dosya tutucusu döndürebileceği anlamına gelir. Fonksiyon çağrısı başarısız da olabilir: Örneğin dosya mevcut olmayabilir veya dosyaya erişim iznimiz olmayabilir. File::open fonksiyonunun, başarılı mı yoksa başarısız mı olduğunu bize bildirmenin ve aynı zamanda bize dosya tutucusunu veya hata bilgisini vermenin bir yoluna sahip olması gerekir. Bu bilgi tam olarak Result enum’ının ilettiği şeydir.
File::open’ın başarılı olması durumunda, karsilama_dosyasi_sonucu değişkenindeki değer, bir dosya tutucusu barındıran bir Ok örneği olacaktır. Başarısız olması durumunda ise karsilama_dosyasi_sonucu içindeki değer, meydana gelen hatanın türü hakkında daha fazla bilgi barındıran bir Err örneği olacaktır.
File::open’ın döndürdüğü değere bağlı olarak farklı eylemler gerçekleştirmek için Liste 9-3’teki koda ekleme yapmamız gerekir. Liste 9-4, temel bir araç olan ve Bölüm 6’da tartıştığımız match ifadesini kullanarak Result’ı ele almanın bir yolunu gösterir.
use std::fs::File;
fn main() {
let karsilama_dosyasi_sonucu = File::open("merhaba.txt");
let karsilama_dosyasi = match karsilama_dosyasi_sonucu {
Ok(dosya) => dosya,
Err(hata) => panic!("Dosyayı açarken problem oluştu: {hata:?}"),
};
}Result varyantlarını ele almak için bir match ifadesi kullanmakOption enum’ı gibi, Result enum’ının ve varyantlarının (seçeneklerinin) prelude (önsöz/başlangıç) tarafından kapsama dahil edildiğini (brought into scope), bu nedenle match kollarındaki (arms) Ok ve Err varyantlarından önce Result:: belirtmemize gerek olmadığını unutmayın.
Sonuç Ok olduğunda, bu kod iç dosya değerini Ok varyantından döndürecek ve biz de o dosya tutucusu değerini karsilama_dosyasi değişkenine atayacağız. match sonrasında, okuma veya yazma işlemleri için dosya tutucusunu kullanabiliriz.
match’in diğer kolu (arm), File::open’dan bir Err değeri aldığımız durumu ele alır. Bu örnekte panic! makrosunu çağırmayı seçtik. Geçerli dizinimizde (directory) merhaba.txt adında bir dosya yoksa ve bu kodu çalıştırırsak, panic! makrosundan aşağıdaki çıktıyı görürüz:
$ cargo run
Compiling hata-yonetimi v0.1.0 (file:///projects/hata-yonetimi)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/hata-yonetimi`
thread 'main' panicked at src/main.rs:8:23:
Dosyayı açarken problem oluştu: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Her zamanki gibi, bu çıktı bize tam olarak neyin yanlış gittiğini söylüyor.
Farklı Hatalar Üzerinde Eşleştirme (Matching) Yapmak
Liste 9-4’teki kod, File::open neden başarısız olursa olsun panic! yapacaktır. Ancak biz farklı başarısızlık nedenleri için farklı eylemler yapmak istiyoruz. Eğer File::open dosya mevcut olmadığı için başarısız olursa, dosyayı oluşturmak ve yeni dosyanın tutucusunu döndürmek istiyoruz. Eğer File::open başka bir nedenden dolayı (örneğin dosyayı açma iznimiz olmadığı için) başarısız olursa, kodun yine Liste 9-4’te olduğu gibi panic! yapmasını istiyoruz. Bunun için, Liste 9-5’te gösterilen bir iç match ifadesi ekliyoruz.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let karsilama_dosyasi_sonucu = File::open("merhaba.txt");
let karsilama_dosyasi = match karsilama_dosyasi_sonucu {
Ok(dosya) => dosya,
Err(hata) => match hata.kind() {
ErrorKind::NotFound => match File::create("merhaba.txt") {
Ok(olusturulan_dosya) => olusturulan_dosya,
Err(e) => panic!("Dosyayı oluştururken problem oluştu: {e:?}"),
},
_ => {
panic!("Dosyayı açarken problem oluştu: {hata:?}");
}
},
};
}File::open’ın Err varyantı içinde döndürdüğü değerin türü, standart kütüphane tarafından sağlanan bir yapı (struct) olan io::Error’dır. Bu yapının, bir io::ErrorKind değeri almak için çağırabileceğimiz kind (tür) adında bir metodu vardır. io::ErrorKind enum’ı standart kütüphane tarafından sağlanır ve bir io işleminden kaynaklanabilecek farklı hata türlerini temsil eden varyantlara sahiptir. Kullanmak istediğimiz varyant, açmaya çalıştığımız dosyanın henüz mevcut olmadığını belirten ErrorKind::NotFound (Bulunamadı) varyantıdır. Bu yüzden karsilama_dosyasi_sonucu üzerinde bir eşleştirme yapıyoruz, ancak ayrıca hata.kind() üzerinde de bir iç eşleştirme yapıyoruz.
İç eşleştirmede kontrol etmek istediğimiz koşul, hata.kind() tarafından döndürülen değerin ErrorKind enum’ının NotFound varyantı olup olmadığıdır. Eğer öyleyse, File::create ile dosyayı oluşturmaya çalışıyoruz. Ancak File::create de başarısız olabileceği için iç match ifadesinde ikinci bir kola ihtiyacımız var. Dosya oluşturulamadığında farklı bir hata mesajı yazdırılır. Dış match’in ikinci kolu aynı kalır, böylece program eksik dosya hatası dışındaki tüm hatalarda panik yapar.
Result<T, E> ile match Kullanmanın Alternatifleri
Bu çok fazla match demek! match ifadesi çok kullanışlıdır ama aynı zamanda çok ilkeldir (primitive). Bölüm 13’te, Result<T, E> üzerinde tanımlanan metodların çoğuyla birlikte kullanılan kapanışları öğreneceksiniz. Kodunuzda Result<T, E> değerlerini ele alırken bu metodlar match kullanmaktan daha özlü olabilir.
Örneğin, Liste 9-5’te gösterilen mantığı bu kez kapanışları ve unwrap_or_else metodunu kullanarak yazmanın başka bir yolu:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let karsilama_dosyasi = File::open("merhaba.txt").unwrap_or_else(|hata| {
if hata.kind() == ErrorKind::NotFound {
File::create("merhaba.txt").unwrap_or_else(|hata| {
panic!("Dosyayı oluştururken problem oluştu: {hata:?}");
})
} else {
panic!("Dosyayı açarken problem oluştu: {hata:?}");
}
});
}Bu kod Liste 9-5 ile aynı davranışa sahip olmasına rağmen hiçbir match ifadesi içermez ve okunması daha temizdir. Bölüm 13’ü okuduktan sonra bu örneğe geri dönün ve standart kütüphane belgelerinde unwrap_or_else metodunu araştırın. Hatalarla uğraşırken bu metodların çok daha fazlası devasa, iç içe geçmiş match ifadelerini temizleyebilir.
Hata Durumunda Panik İçin Kısayollar: unwrap ve expect
match kullanmak yeterince iyi çalışır, ancak biraz ayrıntılı/uzun olabilir ve niyeti her zaman iyi aktarmayabilir. Result<T, E> türü üzerinde çeşitli ve daha spesifik görevleri yerine getirmek için tanımlanmış birçok yardımcı (helper) metod vardır. unwrap metodu, tıpkı Liste 9-4’te yazdığımız match ifadesi gibi uygulanan bir kısayol metodudur. Eğer Result değeri Ok varyantıysa, unwrap Ok içindeki değeri döndürecektir. Eğer Result Err varyantıysa, unwrap bizim için panic! makrosunu çağıracaktır. İşte unwrap kullanımına bir örnek:
use std::fs::File;
fn main() {
let karsilama_dosyasi = File::open("merhaba.txt").unwrap();
}Eğer bu kodu merhaba.txt dosyası olmadan çalıştırırsak, unwrap metodunun yaptığı panic! çağrısından bir hata mesajı görürüz:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Benzer şekilde, expect metodu panic! hata mesajını seçmemize de izin verir. unwrap yerine expect kullanmak ve iyi hata mesajları sağlamak, niyetinizi iletebilir ve paniğin kaynağının izini sürmeyi kolaylaştırabilir. expect sözdizimi şuna benzer:
use std::fs::File;
fn main() {
let karsilama_dosyasi = File::open("merhaba.txt")
.expect("merhaba.txt bu projeye dahil edilmelidir");
}expect’i de unwrap ile aynı şekilde kullanırız: dosya tutucusunu döndürmek veya panic! makrosunu çağırmak için. expect tarafından panic! çağrısında kullanılan hata mesajı, unwrap’in kullandığı varsayılan panic! mesajı yerine bizim expect’e ilettiğimiz parametre olacaktır. İşte şuna benzer:
thread 'main' panicked at src/main.rs:5:10:
merhaba.txt bu projeye dahil edilmelidir: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Üretime hazır (production-quality) kodlarda çoğu Rustacean unwrap yerine expect’i seçer ve işlemin neden her zaman başarılı olmasının beklendiği hakkında daha fazla bağlam (context) verir. Bu şekilde, varsayımlarınızın yanlış olduğu kanıtlanırsa (hata alırsanız), hata ayıklamada kullanabileceğiniz daha fazla bilginiz olur.
Hataları Yaymak (Propagating Errors)
Bir fonksiyonun uygulaması başarısız olabilecek bir şey çağırdığında, hatayı fonksiyonun içinde ele almak yerine ne yapılacağına karar verebilmesi için hatayı çağıran koda döndürebilirsiniz. Bu hatayı yaymak/iletmek (propagating) olarak bilinir ve kodunuzun bağlamında elinizde olandan ziyade hatanın nasıl ele alınacağını belirleyen daha fazla bilginin veya mantığın olabileceği çağıran koda daha fazla kontrol verir.
Örneğin Liste 9-6, bir dosyadan bir kullanıcı adını okuyan bir fonksiyonu gösterir. Dosya mevcut değilse veya okunamıyorsa, bu fonksiyon o hataları, kendisini çağıran koda geri döndürecektir.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn dosyadan_kullanici_adini_oku() -> Result<String, io::Error> {
let kullanici_adi_dosyasi_sonucu = File::open("merhaba.txt");
let mut kullanici_adi_dosyasi = match kullanici_adi_dosyasi_sonucu {
Ok(dosya) => dosya,
Err(e) => return Err(e),
};
let mut kullanici_adi = String::new();
match kullanici_adi_dosyasi.read_to_string(&mut kullanici_adi) {
Ok(_) => Ok(kullanici_adi),
Err(e) => Err(e),
}
}
}match kullanarak çağıran koda hataları döndüren bir fonksiyonBu fonksiyon çok daha kısa bir şekilde yazılabilir, ancak hata yönetimini keşfetmek için ilk başta çoğunu manuel olarak yaparak başlayacağız; sonunda daha kısa olan yolu göstereceğiz. Önce fonksiyonun dönüş türüne bakalım: Result<String, io::Error>. Bu, fonksiyonun Result<T, E> türünde bir değer döndürdüğü, burada jenerik T parametresinin somut String türüyle doldurulduğu ve jenerik E türünün somut io::Error türüyle doldurulduğu anlamına gelir.
Eğer bu fonksiyon hiçbir problem yaşamadan başarılı olursa, bu fonksiyonu çağıran kod, bu fonksiyonun dosyadan okuduğu kullanici_adi String’ini barındıran bir Ok değeri alacaktır. Eğer bu fonksiyon herhangi bir problemle karşılaşırsa, çağıran kod problemlerin ne olduğuna dair daha fazla bilgi barındıran bir io::Error örneği içeren bir Err değeri alacaktır. Bu fonksiyonun dönüş türü olarak io::Error’ı seçtik çünkü bu, bu fonksiyonun gövdesinde çağırdığımız ve başarısız olabilecek işlemlerin her ikisinden ( File::open fonksiyonu ve read_to_string metodu) dönen hata değerinin türüdür.
Fonksiyonun gövdesi File::open fonksiyonunu çağırarak başlar. Ardından Result değerini Liste 9-4’teki match’e benzeyen bir match ile ele alırız. Eğer File::open başarılı olursa, desen (pattern) değişkeni olan dosya içindeki dosya tutucusu kullanici_adi_dosyasi adlı değiştirilebilir değişkendeki değer olur ve fonksiyon devam eder. Err durumunda, panic! çağırmak yerine fonksiyondan tamamen ve erkenden (early) çıkmak ve File::open’dan gelen, artık desen değişkeni e’de bulunan hata değerini bu fonksiyonun hata değeri olarak çağıran koda geri iletmek için return anahtar kelimesini kullanırız.
Yani, eğer kullanici_adi_dosyasi’nda bir dosya tutucumuz varsa, fonksiyon daha sonra kullanici_adi değişkeninde yeni bir String oluşturur ve dosyanın içeriğini kullanici_adi’na okumak için kullanici_adi_dosyasi’ndaki dosya tutucusu üzerinde read_to_string metodunu çağırır. File::open başarılı olmuş olsa bile read_to_string metodu da başarısız olabileceği için bir Result döndürür. Bu yüzden o Result’ı ele almak için başka bir match’e ihtiyacımız var: Eğer read_to_string başarılı olursa fonksiyonumuz da başarılı olmuş olur ve dosyadan alınan, şu an kullanici_adi değişkeninde bulunan kullanıcı adını bir Ok içine sararak döndürürüz. Eğer read_to_string başarısız olursa, File::open’ın dönüş değerini işleyen match’te hata değerini döndürdüğümüz gibi hata değerini döndürürüz. Ancak açıkça return dememize gerek yoktur, çünkü bu fonksiyondaki son ifadedir.
Bu kodu çağıran kod daha sonra bir kullanıcı adı içeren bir Ok değeri ya da bir io::Error içeren bir Err değeri almayı yönetecek hale gelecektir. Bu değerlerle ne yapılacağına karar vermek çağıran koda bağlıdır. Çağıran kod bir Err değeri alırsa, panic! çağırıp programı çökertebilir, varsayılan (default) bir kullanıcı adı kullanabilir veya kullanıcı adını dosya dışındaki başka bir yerden (örneğin) bulabilir. Çağıran kodun gerçekte ne yapmaya çalıştığı hakkında yeterli bilgiye sahip değiliz, bu yüzden tüm başarı veya hata bilgilerini uygun bir şekilde ele alınması için yukarı doğru iletiriz (propagate).
Hataları yayma (propagating errors) deseni Rust’ta o kadar yaygındır ki Rust bunu kolaylaştırmak için soru işareti (?) operatörünü sağlar.
? Operatörü Kısayolu
Liste 9-7, Liste 9-6’daki ile aynı işlevselliğe sahip olan ancak ? operatörünü kullanan bir dosyadan_kullanici_adini_oku uygulamasını gösterir.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn dosyadan_kullanici_adini_oku() -> Result<String, io::Error> {
let mut kullanici_adi_dosyasi = File::open("merhaba.txt")?;
let mut kullanici_adi = String::new();
kullanici_adi_dosyasi.read_to_string(&mut kullanici_adi)?;
Ok(kullanici_adi)
}
}? operatörünü kullanarak çağıran koda hataları döndüren bir fonksiyonBir Result değerinin sonuna konan ?, Liste 9-6’daki Result değerlerini ele almak için tanımladığımız match ifadeleriyle neredeyse aynı şekilde çalışmak üzere tanımlanmıştır. Eğer Result değeri Ok ise, Ok içindeki değer bu ifadeden geri dönecek (get returned) ve program devam edecektir. Eğer değer bir Err ise, hata değerinin çağıran koda iletilmesi için return anahtar kelimesini kullanmışız gibi tüm fonksiyondan Err döndürülecektir.
Liste 9-6’daki match ifadesinin yaptığı ile ? operatörünün yaptığı arasında bir fark vardır: Üzerinde ? operatörü çağrılan hata değerleri, değerleri bir türden diğerine dönüştürmek için kullanılan ve standart kütüphanedeki From trait’inde tanımlı olan from fonksiyonundan geçer. ? operatörü from fonksiyonunu çağırdığında, alınan hata türü geçerli fonksiyonun dönüş türünde tanımlanan hata türüne dönüştürülür. Bu, kısımlar birçok farklı nedenle başarısız olabilse bile, bir fonksiyonun başarısız olabileceği tüm yolları temsil etmek üzere tek bir hata türü döndürdüğünde kullanışlıdır.
Örneğin, Liste 9-7’deki dosyadan_kullanici_adini_oku fonksiyonunu değiştirebilir ve kendi tanımladığımız OurError (BizimHatamiz) adında özel bir hata türünü döndürebiliriz. Eğer io::Error’dan bir OurError örneği oluşturmak için impl From<io::Error> for OurError tanımlarsak, o zaman dosyadan_kullanici_adini_oku fonksiyonunun gövdesindeki ? operatörü çağrıları, fonksiyona başka bir kod eklemeye gerek kalmadan from çağırıp hata türlerini dönüştürecektir.
Liste 9-7 bağlamında, File::open çağrısının sonundaki ?, Ok içindeki değeri kullanici_adi_dosyasi değişkenine döndürecektir. Eğer bir hata meydana gelirse, ? operatörü tüm fonksiyondan erken dönecek ve herhangi bir Err değerini çağıran koda verecektir. Aynı şey read_to_string çağrısının sonundaki ? için de geçerlidir.
? operatörü pek çok tekrarlayan (boilerplate) kodu ortadan kaldırır ve bu fonksiyonun uygulamasını daha basit hale getirir. Liste 9-8’de gösterildiği gibi metod çağrılarını hemen ? sonrasına zincirleyerek (chaining) bu kodu daha da kısaltabiliriz.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn dosyadan_kullanici_adini_oku() -> Result<String, io::Error> {
let mut kullanici_adi = String::new();
File::open("merhaba.txt")?.read_to_string(&mut kullanici_adi)?;
Ok(kullanici_adi)
}
}? operatöründen sonra metod çağrılarını zincirleme (chaining)kullanici_adi değişkenindeki yeni String’in oluşturulmasını fonksiyonun başına taşıdık; o kısım değişmedi. Bir kullanici_adi_dosyasi değişkeni oluşturmak yerine read_to_string çağrısını doğrudan File::open("merhaba.txt")? sonucuna zincirledik. read_to_string çağrısının sonunda hala bir ? var ve hem File::open hem de read_to_string başarılı olduğunda hataları döndürmek yerine hala kullanici_adi içeren bir Ok değeri döndürüyoruz. İşlevsellik Liste 9-6 ve Liste 9-7’deki ile yine aynıdır; bu sadece onu yazmanın farklı, daha ergonomik (ergonomic) bir yoludur.
Liste 9-9, fs::read_to_string kullanarak bunu daha da kısa yapmanın bir yolunu gösterir.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn dosyadan_kullanici_adini_oku() -> Result<String, io::Error> {
fs::read_to_string("merhaba.txt")
}
}fs::read_to_string kullanmakBir dosyayı bir string’in içine okumak oldukça yaygın bir işlem olduğundan, standart kütüphane dosyayı açan, yeni bir String oluşturan, dosyanın içeriğini okuyan, içerikleri o String içine koyan ve onu döndüren kullanışlı fs::read_to_string fonksiyonunu sağlar. Elbette fs::read_to_string kullanmak bize tüm hata yönetimini açıklama fırsatı vermez, bu yüzden ilk olarak uzun yolu tercih ettik.
? Operatörünün Nerelerde Kullanılabileceği
? operatörü yalnızca, dönüş türü ?’nin üzerinde kullanıldığı değer ile uyumlu (compatible) olan fonksiyonlarda kullanılabilir. Bunun nedeni, ? operatörünün Liste 9-6’da tanımladığımız match ifadesi ile aynı şekilde fonksiyondan değerin erken bir dönüşünü (early return) gerçekleştirecek şekilde tanımlanmış olmasıdır. Liste 9-6’da, match bir Result değeri kullanıyordu ve erken dönen kol bir Err(e) değeri döndürüyordu. Bu return ile uyumlu olması için fonksiyonun dönüş türünün bir Result olması gerekir.
Liste 9-10’da, ? operatörünü, ? kullandığımız değerin türüyle uyumsuz bir dönüş türüne sahip olan bir main fonksiyonunda kullandığımızda alacağımız hataya bakalım.
use std::fs::File;
fn main() {
let karsilama_dosyasi = File::open("merhaba.txt")?;
}() döndüren bir main fonksiyonunda ? kullanmaya çalışmak derlenmeyecektir.Bu kod bir dosyayı açar ki bu da başarısız olabilir. ? operatörü, File::open tarafından döndürülen Result değerini takip eder, ancak bu main fonksiyonu Result değil () dönüş türüne sahiptir. Bu kodu derlediğimizde şu hata mesajını alırız:
$ cargo run
Compiling hata-yonetimi v0.1.0 ($PROJE/listings/ch09-error-handling/listing-09-10)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:54
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let karsilama_dosyasi = File::open("merhaba.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let karsilama_dosyasi = File::open("merhaba.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `hata-yonetimi` (bin "hata-yonetimi") due to 1 previous error
Bu hata bize ? operatörünü yalnızca Result, Option veya FromResidual’ı uygulayan başka bir tür döndüren bir fonksiyonda kullanmaya iznimiz olduğuna işaret etmektedir.
Hatayı düzeltmek için iki seçeneğiniz var. Birincisi, sizi engelleyen bir kısıtlamanız olmadığı sürece, fonksiyonunuzun dönüş türünü ? operatörünü üzerinde kullandığınız değerle uyumlu olacak şekilde değiştirmektir. Diğer bir seçenek de, Result<T, E>’yi uygun olan herhangi bir şekilde ele almak için bir match veya Result<T, E> metodlarından birini kullanmaktır.
Hata mesajı ayrıca ?’nin Option<T> değerleri ile de kullanılabileceğinden bahsetmiştir. Tıpkı ?’yi Result’ta kullanırken olduğu gibi, ?’yi Option üzerinde yalnızca bir Option döndüren bir fonksiyonda kullanabilirsiniz. Bir Option<T> üzerinde çağrıldığında ? operatörünün davranışı, bir Result<T, E> üzerinde çağrıldığındaki davranışına benzerdir: Eğer değer None ise, None o noktada fonksiyondan erken döndürülecektir. Değer Some ise, Some içindeki değer ifadenin sonuç değeri olur ve fonksiyon devam eder. Liste 9-11’de verilen metindeki ilk satırın son karakterini bulan bir fonksiyona ait örnek bulunmaktadır.
fn ilk_satirin_son_karakteri(metin: &str) -> Option<char> {
metin.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
ilk_satirin_son_karakteri("Merhaba, dünya\nBugün nasılsın?"),
Some('a')
);
assert_eq!(ilk_satirin_son_karakteri(""), None);
assert_eq!(ilk_satirin_son_karakteri("\nmerhaba"), None);
}Option<T> değeri üzerinde ? operatörünü kullanmakBu fonksiyon Option<char> döndürür, çünkü orada bir karakter olması da olmaması da mümkündür. Bu kod metin string dilimi argümanını alır ve üzerinde lines (satırlar) metodunu çağırır; bu da string içindeki satırlar üzerinde bir yineleyici döndürür. Bu fonksiyon ilk satırı incelemek istediği için yineleyiciden ilk değeri almak amacıyla yineleyici üzerinde next (sonraki) metodunu çağırır. metin boş bir string ise, bu next çağrısı None döndürecek ve bu durumda durdurup ilk_satirin_son_karakteri fonksiyonundan None dönmek için ? kullanırız. Eğer metin boş string değilse, next, metin içindeki ilk satırın bir string dilimini barındıran bir Some değeri döndürecektir.
? string dilimini dışarı çıkarır (extracts) ve o string diliminin karakterlerinin yineleyicisini almak için üzerinde chars (karakterler) çağırabiliriz. Bu ilk satırdaki son karakterle ilgileniyoruz, bu nedenle yineleyicideki son öğeyi döndürmesi için last (son) çağırıyoruz. Bu bir Option’dır, çünkü ilk satırın boş bir string olması mümkündür; örneğin "\nmerhaba" örneğinde olduğu gibi metin boş bir satırla başlayıp diğer satırlarda karakterlere sahipse. Ancak, eğer ilk satırda bir son karakter varsa bu Some varyantında döndürülecektir. Ortadaki ? operatörü, bu mantığı ifade etmenin özlü bir yolunu vererek fonksiyonu tek bir satırda uygulamamızı sağlar. Eğer ? operatörünü Option üzerinde kullanamasaydık, bu mantığı daha fazla metod çağrısı veya bir match ifadesi kullanarak uygulamak zorunda kalırdık.
? operatörünü Result döndüren bir fonksiyonda Result üzerinde, Option döndüren bir fonksiyonda ise Option üzerinde kullanabileceğinizi, ancak ikisini birbirine karıştırıp eşleştiremeyeceğinizi unutmayın. ? operatörü bir Result’ı otomatik olarak bir Option’a ya da tam tersine dönüştürmez; bu durumlarda, dönüştürme işlemini açıkça yapmak için Result üzerindeki ok metodu ya da Option üzerindeki ok_or metodu gibi metodları kullanabilirsiniz.
Şimdiye kadar kullandığımız tüm main fonksiyonları () döndürdü. main fonksiyonu, yürütülebilir (executable) bir programın giriş (entry) ve çıkış noktası olması nedeniyle özeldir ve programın beklendiği gibi davranabilmesi için dönüş türünün ne olabileceğine dair kısıtlamalar vardır.
Neyse ki, main aynı zamanda bir Result<(), E> de döndürebilir. Liste 9-12, Liste 9-10’daki kodu barındırır, ancak main fonksiyonunun dönüş türünü Result<(), Box<dyn Error>> olarak değiştirdik ve sonuna Ok(()) dönüş değeri ekledik. Bu kod artık derlenecektir.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let karsilama_dosyasi = File::open("merhaba.txt")?;
Ok(())
}main’i Result<(), E> döndürecek şekilde değiştirmek, Result değerleri üzerinde ? operatörünün kullanılmasına olanak tanır.Box<dyn Error> türü bir trait nesnesidir, bu konudan Bölüm 18’deki “Paylaşılan Davranış Üzerinden Soyutlama Yapmak İçin Trait Nesneleri Kullanmak” kısmında bahsedeceğiz. Şimdilik, Box<dyn Error> türünü “herhangi bir hata türü” anlamında okuyabilirsiniz. Box<dyn Error> hata türüne sahip bir main fonksiyonunda Result değeri üzerinde ? kullanımına izin verilir, çünkü herhangi bir Err değerinin erken döndürülmesini mümkün kılar. Bu main fonksiyonunun gövdesi sadece std::io::Error türünde hatalar döndürecek olsa da, Box<dyn Error> belirtmek suretiyle bu imza main gövdesine diğer hataları döndüren başka kodlar eklense dahi doğru kalmaya devam edecektir.
Bir main fonksiyonu Result<(), E> döndürdüğünde yürütülebilir dosya (executable), main Ok(()) döndürürse 0 değeriyle çıkış yapar, main bir Err değeri döndürürse sıfır olmayan bir değerle çıkış yapar. C ile yazılmış yürütülebilir dosyalar çıkarken tamsayılar döndürürler: Başarıyla çıkan programlar 0 tamsayısını, hatalı olanlar ise 0’dan farklı bir tamsayıyı döndürür. Rust da bu kuralla uyumlu olması adına yürütülebilir dosyalardan tamsayılar döndürür.
main fonksiyonu bir ExitCode döndüren report (rapor) fonksiyonunu içeren std::process::Termination trait’ini uygulayan tüm türleri döndürebilir. Kendi türleriniz için Termination trait’ini uygulamak hakkında daha fazla bilgi edinmek için standart kütüphane dokümanlarına başvurun.
Artık panic! çağırmanın veya Result döndürmenin detaylarını tartışmış olduğumuza göre, hangi durumlarda hangisinin uygun olduğuna nasıl karar vereceğimiz konusuna geri dönelim.
panic! Yapmalı mı Yapmamalı mı?
panic! Yapmalı mı Yapmamalı mı?
Peki ne zaman panic! çağırmanız ve ne zaman Result döndürmeniz gerektiğine nasıl karar verirsiniz? Kod panik yaptığında kurtarmanın bir yolu yoktur. Kurtarmanın mümkün bir yolu olsun ya da olmasın, herhangi bir hata durumu için panic! çağırabilirsiniz, ancak bu durumda çağıran kod adına bir durumun kurtarılamaz olduğuna karar vermiş olursunuz. Bir Result değeri döndürmeyi seçtiğinizde, çağıran koda seçenekler sunarsınız. Çağıran kod kendi durumuna uygun bir şekilde kurtarmaya çalışmayı seçebilir veya bu durumda bir Err değerinin kurtarılamaz olduğuna karar verebilir, böylece o da panic! çağırarak kurtarılabilir hatanızı kurtarılamaz bir hataya dönüştürebilir. Bu nedenle, başarısız olabilecek bir fonksiyon tanımlarken varsayılan olarak Result döndürmek iyi bir seçimdir.
Örnekler, prototip kodları ve testler gibi durumlarda, Result döndürmek yerine panik yapan kodlar yazmak daha uygundur. Gelin bunun nedenini inceleyelim ve daha sonra derleyicinin başarısızlığın imkansız olduğunu anlayamadığı ama bir insan olarak sizin anlayabildiğiniz durumları tartışalım. Bu bölüm, kütüphane kodlarında (library code) panik yapıp yapmamaya nasıl karar verileceğine dair bazı genel yönergeler ile sona erecektir.
Örnekler, Prototip Kodu ve Testler
Bazı kavramları açıklamak için bir örnek yazarken sağlam bir hata yönetimi kodunu (hata-yonetimi code) da dahil etmek örneği daha az anlaşılır hale getirebilir. Örneklerde, unwrap gibi panikleyebilen bir metoda yapılan çağrının, kodunuzun geri kalanının ne yaptığına bağlı olarak değişebilecek şekilde uygulamanızın hataları ele alma biçimi için bir yer tutucu olduğu anlaşılır.
Benzer şekilde, prototip oluştururken ve hataları nasıl ele alacağınıza karar vermeye henüz hazır olmadığınızda unwrap ve expect metodları çok kullanışlıdır. Programınızı daha sağlam hale getirmeye hazır olduğunuz zamanlar için kodunuzda net işaretler bırakırlar.
Eğer bir testte bir metot çağrısı başarısız olursa, test edilen işlevsellik o metod olmasa bile tüm testin başarısız olmasını istersiniz. Bir testin başarısızlık olarak işaretlenmesinin yolu panic! olduğundan, unwrap veya expect çağırmak tam olarak gerçekleşmesi gereken şeydir.
Derleyiciden Daha Fazla Bilgiye Sahip Olduğunuz Durumlar
Result’ın bir Ok değerine sahip olmasını sağlayan başka bir mantığınız olduğunda, ancak bu mantık derleyicinin anlayabileceği bir şey olmadığında da expect çağırmak uygun olacaktır. Yine de ele almanız gereken bir Result değerine sahip olursunuz: Çağırdığınız işlem, sizin özel durumunuzda mantıksal olarak imkansız olsa bile genel olarak başarısız olma olasılığını hala taşır. Kodu manuel olarak inceleyerek hiçbir zaman bir Err varyantına sahip olmayacağınızdan emin olabiliyorsanız, expect çağırmak ve argüman metninde hiçbir zaman bir Err varyantına sahip olmayacağınızı düşünme nedeninizi belgelemek son derece kabul edilebilirdir. İşte bir örnek:
fn main() {
use std::net::IpAddr;
let ev: IpAddr = "127.0.0.1"
.parse()
.expect("Sabit kodlanmış IP adresi geçerli olmalıdır");
}Sabit kodlanmış bir string’i ayrıştırarak bir IpAddr örneği oluşturuyoruz. 127.0.0.1’in geçerli bir IP adresi olduğunu görebiliriz, bu yüzden burada expect kullanmak kabul edilebilirdir. Ancak, sabit kodlanmış, geçerli bir string’e sahip olmak parse metodunun dönüş türünü değiştirmez: Yine de bir Result değeri alırız ve derleyici bu string’in her zaman geçerli bir IP adresi olduğunu görecek kadar akıllı olmadığı için, Err varyantı bir olasılıkmış gibi derleyici bizi yine de Result’ı ele almaya zorlayacaktır. Eğer IP adresi string’i programa sabit kodlanmış olmak yerine bir kullanıcıdan gelseydi ve dolayısıyla başarısız olma ihtimali olsaydı, Result’ı kesinlikle daha sağlam bir şekilde ele almak isterdik. Bu IP adresinin sabit kodlanmış olduğu varsayımından bahsetmek, gelecekte IP adresini başka bir kaynaktan almamız gerekirse expect’i daha iyi bir hata yönetimi (hata-yonetimi) koduyla değiştirmemizi sağlayacaktır.
Hata Yönetimi Yönergeleri
Kodunuzun kötü bir duruma düşmesi muhtemelse kodunuzun panik yapması tavsiye edilir. Bu bağlamda kötü durum, kodunuza geçersiz değerler, çelişkili değerler veya eksik değerler geçildiğinde olduğu gibi bazı varsayımların, garantilerin, sözleşmelerin veya değişmezlerin ihlal edilmesidir; ayrıca bunlara ek olarak aşağıdakilerden biri veya daha fazlasıdır:
- Kötü durum, bir kullanıcının verileri yanlış formatta girmesi gibi zaman zaman gerçekleşmesi muhtemel olan bir şeyin aksine beklenmeyen bir şeydir.
- Bu noktadan sonraki kodunuz, sorunu her adımda kontrol etmek yerine bu kötü durumda olmamaya güvenmek zorundadır.
- Bu bilgiyi kullandığınız türlerde kodlamanın iyi bir yolu yoktur. Ne demek istediğimize dair bir örneği Bölüm 18’deki “Durumları ve Davranışları Türler Olarak Kodlamak” kısmında işleyeceğiz.
Eğer biri kodunuzu çağırır ve mantıklı olmayan değerler verirse, yapabiliyorsanız bir hata döndürmek en iyisidir, böylece kütüphane kullanıcısı bu durumda ne yapmak istediğine karar verebilir. Ancak, devam etmenin güvensiz veya zararlı olabileceği durumlarda, en iyi seçenek panic! çağırmak ve kütüphanenizi kullanan kişiyi kodundaki hata konusunda uyararak geliştirme sırasında düzeltmelerini sağlamak olabilir. Benzer şekilde, kontrolünüz dışında olan ve düzeltmenin hiçbir yolu olmayan geçersiz bir durum döndüren dış bir kodu çağırıyorsanız genellikle panic! uygundur.
Bununla birlikte, başarısızlık bekleniyorsa, Result döndürmek bir panic! çağrısı yapmaktan daha uygundur. Örnekler arasında bir ayrıştırıcıya hatalı biçimlendirilmiş veriler verilmesi veya bir HTTP isteğinin hız sınırına ulaştığınızı belirten bir durum döndürmesi yer alır. Bu durumlarda Result döndürmek, başarısızlığın, çağıran kodun nasıl ele alacağına karar vermesi gereken beklenen bir olasılık olduğunu gösterir.
Kodunuz, geçersiz değerler kullanılarak çağrıldığında kullanıcıyı riske atabilecek bir işlem gerçekleştirdiğinde, kodunuz önce değerlerin geçerli olduğunu doğrulamalı ve değerler geçerli değilse panik yapmalıdır. Bu çoğunlukla güvenlik nedeniyledir: Geçersiz veriler üzerinde çalışmaya kalkışmak, kodunuzu güvenlik açıklarına maruz bırakabilir. Bir sınırların dışında bellek erişimi girişiminde bulunursanız standart kütüphanenin panic! çağırmasının ana nedeni budur: Mevcut veri yapısına ait olmayan bir belleğe erişmeye çalışmak yaygın bir güvenlik problemidir. Fonksiyonların genellikle sözleşmeleri vardır: Davranışları yalnızca girdiler belirli gereksinimleri karşıladığında garanti edilir. Sözleşme ihlal edildiğinde panik yapmak mantıklıdır, çünkü bir sözleşme ihlali her zaman çağıran taraftaki bir hatayı gösterir ve bu çağıran kodun açıkça ele almasını isteyeceğiniz bir hata türü değildir. Aslında, çağıran kodun kurtulması için mantıklı bir yol yoktur; çağıran programcıların kodu düzeltmesi gerekir. Bir fonksiyona ait sözleşmeler, özellikle de bir ihlalin paniğe neden olacağı durumlarda, fonksiyonun API dokümantasyonunda açıklanmalıdır.
Ancak, tüm fonksiyonlarınızda çok sayıda hata kontrolüne sahip olmak uzun, ayrıntılı ve can sıkıcı olacaktır. Neyse ki kontrollerin birçoğunu sizin yerinize yapması için Rust’ın tür sistemini ve dolayısıyla derleyici tarafından yapılan tür denetimini kullanabilirsiniz. Eğer fonksiyonunuz parametre olarak belirli bir türe sahipse, derleyicinin zaten geçerli bir değere sahip olduğunuzdan emin olduğunu bilerek kodunuzun mantığıyla ilerleyebilirsiniz. Örneğin, Option yerine bir türünüz varsa, programınız hiçbir şey yerine bir şeye sahip olmayı bekler. Bu durumda kodunuzun Some ve None varyantları için iki durumu ele alması gerekmez: Sadece kesinlikle bir değere sahip olmak için tek bir durumu olacaktır. Fonksiyonunuza hiçbir şey iletmeye çalışan kod derlenmeyecektir bile, bu nedenle fonksiyonunuzun çalışma zamanında bu durumu kontrol etmesi gerekmez. Başka bir örnek, parametrenin asla negatif olmadığından emin olmak için u32 gibi işaretsiz bir tamsayı türü kullanmaktır.
Doğrulama (Validation) İçin Özel Türler (Custom Types)
Geçerli bir değere sahip olduğumuzdan emin olmak için Rust’ın tür sistemini kullanma fikrini bir adım öteye taşıyalım ve doğrulama için özel bir tür oluşturmaya bakalım. Bölüm 2’deki, kodumuzun kullanıcıdan 1 ile 100 arasında bir sayıyı tahmin etmesini istediği tahmin oyununu hatırlayın. Kullanıcının tahminini gizli sayımızla karşılaştırmadan önce bu sayılar arasında olduğunu hiçbir zaman doğrulamadık; sadece tahminin pozitif olduğunu doğruladık. Bu durumda sonuçlar çok vahim değildi: “Çok büyük” veya “Çok küçük” şeklindeki çıktılarımız hala doğru olurdu. Ancak kullanıcıyı geçerli tahminlere yönlendirmek ve kullanıcının aralık dışında bir sayı tahmin etmesi ile (örneğin) harf yazması durumlarında farklı davranışlara sahip olmak kullanışlı bir geliştirme olurdu.
Bunu yapmanın bir yolu, potansiyel olarak negatif sayılara izin vermek için tahmini sadece u32 yerine i32 olarak ayrıştırmak ve ardından sayının aralıkta olması için şöyle bir kontrol eklemek olabilir:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
io::stdin().read_line(&mut tahmin).expect("Satır okunamadı");
let tahmin: i32 = match tahmin.trim().parse() {
Ok(sayi) => sayi,
Err(_) => continue,
};
if tahmin < 1 || tahmin > 100 {
println!("Gizli sayı 1 ile 100 arasında olacak.");
continue;
}
match tahmin.cmp(&gizli_sayi) {
// --snip--
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => {
println!("Kazandınız!");
break;
}
}
}
}if ifadesi değerimizin aralığın dışında olup olmadığını kontrol eder, kullanıcıya sorunu bildirir ve döngünün bir sonraki yinelemesini başlatmak ve başka bir tahmin istemek için continue çağırır. if ifadesinden sonra, tahmin’in 1 ile 100 arasında olduğunu bilerek tahmin ve gizli sayı arasındaki karşılaştırmalara devam edebiliriz.
Ancak bu ideal bir çözüm değildir: Eğer programın sadece 1 ile 100 arasındaki değerler üzerinde çalışması kesinlikle kritikse ve bu gerekliliğe sahip birçok fonksiyonu varsa, her fonksiyonda böyle bir kontrole sahip olmak sıkıcı olur (ve performansı etkileyebilir).
Bunun yerine, doğrulamaları her yerde tekrarlamak yerine tahsis edilmiş bir modülde yeni bir tür yapabilir ve türün bir örneğini oluşturmak için doğrulamaları bir fonksiyona koyabiliriz. Bu sayede, fonksiyonların imzalarında yeni türü kullanmaları ve aldıkları değerleri güvenle kullanmaları güvenli olur. Liste 9-13, yalnızca new (yeni) fonksiyonu 1 ile 100 arasında bir değer alırsa bir Tahmin (Guess) örneği oluşturacak bir Tahmin türünü tanımlamanın bir yolunu gösterir.
#![allow(unused)]
fn main() {
pub struct Tahmin {
deger: i32,
}
impl Tahmin {
pub fn new(deger: i32) -> Tahmin {
if deger < 1 || deger > 100 {
panic!(
"Tahmin değeri 1 ile 100 arasında olmalıdır, {deger} alındı."
);
}
Tahmin { deger }
}
pub fn deger(&self) -> i32 {
self.deger
}
}
}Tahmin (Guess) türüsrc/tahmin_oyunu.rs dosyasındaki bu kodun, src/lib.rs dosyasına (burada göstermediğimiz) mod tahmin_oyunu; modül beyanının eklenmesine bağlı olduğunu unutmayın. Bu yeni modülün dosyası içinde, i32 tutan deger (value) adında bir alana sahip Tahmin adında bir struct (yapı) tanımlıyoruz. Sayının depolanacağı yer burasıdır.
Daha sonra, Tahmin üzerinde Tahmin değerlerinin örneklerini oluşturan new (yeni) adında ilişkili bir fonksiyon (associated function) uygularız. new fonksiyonu, i32 türünde deger (value) adında bir parametreye sahip olacak ve bir Tahmin döndürecek şekilde tanımlanmıştır. new fonksiyonunun gövdesindeki kod, deger’in 1 ile 100 arasında olduğundan emin olmak için onu test eder. Eğer deger bu testten geçemezse, bir panic! çağrısı yaparız ki bu da çağıran kodu yazan programcıyı düzeltmesi gereken bir hata olduğu konusunda uyarır, çünkü bu aralığın dışında bir deger ile bir Tahmin oluşturmak, Tahmin::new’in güvendiği sözleşmeyi ihlal edecektir. Tahmin::new’in panikleyebileceği koşullar herkese açık (public-facing) API dokümantasyonunda tartışılmalıdır; oluşturduğunuz API dokümantasyonunda panic! olasılığını belirten belgeleme kurallarını (documentation conventions) Bölüm 14’te ele alacağız. Eğer deger testi geçerse, deger alanı deger parametresine ayarlanmış yeni bir Tahmin yaratırız ve Tahmin’i döndürürüz.
Ardından, self’i ödünç alan, başka parametresi olmayan ve bir i32 döndüren deger (value) adında bir metot uygularız. Bu tür metotlara bazen alıcı denir çünkü amacı alanlarından (fields) bazı verileri almak ve onu döndürmektir. Bu açık metod gereklidir çünkü Tahmin yapısının (struct) deger alanı gizlidir. Tahmin yapısını kullanan kodun doğrudan deger’i ayarlamasına izin verilmemesi için deger alanının gizli olması önemlidir: tahmin_oyunu modülü dışındaki kod, bir Tahmin örneği oluşturmak için Tahmin::new fonksiyonunu kullanmak zorundadır, böylece bir Tahmin’in, Tahmin::new fonksiyonundaki koşullar tarafından kontrol edilmemiş bir deger’e sahip olmasının hiçbir yolu olmadığından emin olunur.
Böylece yalnızca 1 ile 100 arasındaki sayıları parametre alan veya döndüren bir fonksiyon, imzasında bir i32 yerine bir Tahmin aldığını veya döndürdüğünü bildirebilir ve gövdesinde herhangi bir ek doğrulama yapmasına gerek kalmaz.
Özet
Rust’ın hata yönetimi (hata-yonetimi) özellikleri daha sağlam kodlar yazmanıza yardımcı olmak için tasarlanmıştır. panic! makrosu, programınızın başa çıkamayacağı bir durumda olduğunu belirtir ve geçersiz veya yanlış değerlerle ilerlemeye çalışmak yerine sürece durmasını söylemenize olanak tanır. Result enum’ı, işlemlerin kodunuzun kurtarabileceği bir şekilde başarısız olabileceğini belirtmek için Rust’ın tür sistemini kullanır. Sizin kodunuzu çağıran koda, potansiyel başarıyı ya da başarısızlığı ele alması gerektiğini bildirmek için Result’ı kullanabilirsiniz. panic! ve Result’ı uygun durumlarda kullanmak kodunuzu kaçınılmaz problemler karşısında daha güvenilir hale getirecektir.
Artık standart kütüphanenin jenerikleri Option ve Result enum’larıyla kullanmasının kullanışlı yollarını gördüğünüze göre, jeneriklerin nasıl çalıştığı ve onları kodunuzda nasıl kullanabileceğiniz hakkında konuşacağız.
Jenerik Türler, Traitler ve Ömürler
Her programlama dili, kavramların tekrarını etkin bir şekilde ele almak için araçlara sahiptir. Rust’ta bu araçlardan biri jeneriklerdir: somut türler veya diğer özellikler için soyut yedeklerdir. Kod derlenip çalıştırılırken yerlerinde ne olacağını bilmeden jeneriklerin davranışını veya diğer jeneriklerle nasıl ilişki kurduklarını ifade edebiliriz.
Fonksiyonlar, i32 veya String gibi somut bir tür yerine bir tür jenerik türe ait parametreler alabilir; tıpkı aynı kodu birden fazla somut değer üzerinde çalıştırmak için bilinmeyen değerlere sahip parametreler aldıkları gibi. Aslında, Bölüm 6’da Option<T> ile, Bölüm 8’de Vec<T> ve HashMap<K, V> ile ve Bölüm 9’da Result<T, E> ile jenerikleri zaten kullandık. Bu bölümde, kendi türlerinizi, fonksiyonlarınızı ve metotlarınızı jeneriklerle nasıl tanımlayacağınızı keşfedeceksiniz!
Önce kod tekrarını azaltmak için bir fonksiyonun nasıl çıkarılacağını gözden geçireceğiz. Ardından, yalnızca parametrelerinin türleri bakımından farklılık gösteren iki fonksiyondan jenerik bir fonksiyon oluşturmak için aynı tekniği kullanacağız. Ayrıca struct ve enum tanımlarında jenerik türlerin nasıl kullanılacağını açıklayacağız.
Daha sonra, davranışı jenerik bir şekilde tanımlamak için traitleri nasıl kullanacağınızı öğreneceksiniz. Herhangi bir tür yerine, yalnızca belirli bir davranışa sahip türleri kabul etmesi adına bir jenerik türü kısıtlamak için traitleri jenerik türlerle birleştirebilirsiniz.
Son olarak, derleyiciye referansların birbiriyle nasıl ilişki kurduğu hakkında bilgi veren bir çeşit jenerik olan ömürleri tartışacağız. Ömürler, ödünç alınan değerler hakkında derleyiciye yeterli bilgi vermemizi sağlar, böylece referansların bizim yardımımız olmadan olabileceğinden daha fazla durumda geçerli kalacağından emin olabilir.
Bir Fonksiyonu Çıkararak Tekrarlamayı Kaldırmak
Jenerikler, kod tekrarını kaldırmak için belirli türleri birden fazla türü temsil eden bir yer tutucuyla değiştirmemizi sağlar. Jenerik sözdizimine dalmadan önce, belirli değerleri birden fazla değeri temsil eden bir yer tutucuyla değiştiren bir fonksiyon çıkararak jenerik türleri içermeyen bir şekilde tekrarı nasıl kaldıracağımıza bakalım. Sonra, jenerik bir fonksiyonu çıkarmak için aynı tekniği uygulayacağız! Bir fonksiyona çıkarabileceğiniz tekrarlayan kodu nasıl tanıyacağınızı görerek, jenerikleri kullanabilecek tekrarlayan kodları tanımaya başlayacaksınız.
Bir listedeki en büyük sayıyı bulan, Liste 10-1’deki kısa programla başlayacağız.
fn main() {
let sayi_listesi = vec![34, 50, 25, 100, 65];
let mut en_buyuk = &sayi_listesi[0];
for sayi in &sayi_listesi {
if sayi > en_buyuk {
en_buyuk = sayi;
}
}
println!("En büyük sayı: {en_buyuk}");
assert_eq!(*en_buyuk, 100);
}sayi_listesi değişkeninde bir tamsayı listesi saklıyoruz ve listedeki ilk sayının referansını en_buyuk adlı bir değişkene yerleştiriyoruz. Ardından listedeki tüm sayılar üzerinde yineleme yapıyoruz ve eğer o anki sayı en_buyuk içinde depolanan sayıdan daha büyükse o değişkendeki referansı değiştiriyoruz. Ancak, o anki sayı şimdiye kadar görülen en büyük sayıdan küçük veya ona eşitse değişken değişmez ve kod listedeki bir sonraki sayıya geçer. Listedeki tüm sayıları değerlendirdikten sonra, en_buyuk en büyük sayıya referans vermelidir, bu örnekte o da 100’dür.
Şimdi iki farklı sayı listesindeki en büyük sayıyı bulmakla görevlendirildik. Bunu yapmak için, Liste 10-2’de gösterildiği gibi Liste 10-1’deki kodu kopyalamayı ve aynı mantığı programın iki farklı yerinde kullanmayı seçebiliriz.
fn main() {
let sayi_listesi = vec![34, 50, 25, 100, 65];
let mut en_buyuk = &sayi_listesi[0];
for sayi in &sayi_listesi {
if sayi > en_buyuk {
en_buyuk = sayi;
}
}
println!("En büyük sayı: {en_buyuk}");
let sayi_listesi = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut en_buyuk = &sayi_listesi[0];
for sayi in &sayi_listesi {
if sayi > en_buyuk {
en_buyuk = sayi;
}
}
println!("En büyük sayı: {en_buyuk}");
}Bu kod çalışmasına rağmen, kodu kopyalamak yorucu ve hataya açıktır. Ayrıca, kodu değiştirmek istediğimizde birden fazla yerde güncellemeyi de unutmamalıyız.
Bu tekrarı ortadan kaldırmak için, parametre olarak aktarılan herhangi bir tamsayı listesi üzerinde çalışan bir fonksiyon tanımlayarak bir soyutlama oluşturacağız. Bu çözüm kodumuzu daha açık hale getirir ve bir listedeki en büyük sayıyı bulma kavramını soyut bir şekilde ifade etmemizi sağlar.
Liste 10-3’te, en büyük sayıyı bulan kodu en_buyuk_bul adlı bir fonksiyona çıkarıyoruz. Ardından Liste 10-2’deki iki listedeki en büyük sayıyı bulmak için fonksiyonu çağırıyoruz. Bu fonksiyonu gelecekte sahip olabileceğimiz diğer herhangi bir i32 değer listesinde de kullanabiliriz.
fn en_buyuk_bul(liste: &[i32]) -> &i32 {
let mut en_buyuk = &liste[0];
for oge in liste {
if oge > en_buyuk {
en_buyuk = oge;
}
}
en_buyuk
}
fn main() {
let sayi_listesi = vec![34, 50, 25, 100, 65];
let sonuc = en_buyuk_bul(&sayi_listesi);
println!("En büyük sayı: {sonuc}");
assert_eq!(*sonuc, 100);
let sayi_listesi = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let sonuc = en_buyuk_bul(&sayi_listesi);
println!("En büyük sayı: {sonuc}");
assert_eq!(*sonuc, 6000);
}en_buyuk_bul fonksiyonu, fonksiyona aktarabileceğimiz herhangi bir somut i32 değer dilimini temsil eden liste adında bir parametreye sahiptir. Sonuç olarak, fonksiyonu çağırdığımızda, kod aktardığımız belirli değerler üzerinde çalışır.
Özetle, Liste 10-2’deki kodu Liste 10-3’e dönüştürmek için attığımız adımlar şunlardır:
- Tekrarlanan kodu belirleyin.
- Tekrarlanan kodu fonksiyonun gövdesine çıkarın ve o kodun girdilerini ve dönüş değerlerini fonksiyon imzasında belirtin.
- Bunun yerine fonksiyonu çağırmak için tekrarlanan kodun iki örneğini güncelleyin.
Sırada, kod tekrarını azaltmak için aynı adımları jeneriklerle kullanacağız. Fonksiyon gövdesinin belirli değerler yerine soyut bir liste üzerinde çalışabilmesi gibi, jenerikler de kodun soyut türler üzerinde çalışmasına izin verir.
Örneğin, iki fonksiyonumuz olduğunu varsayalım: biri i32 değerlerinden oluşan bir dilimdeki en büyük öğeyi, diğeri ise char değerlerinden oluşan bir dilimdeki en büyük öğeyi bulan bir fonksiyon. Bu tekrarı nasıl ortadan kaldırırdık? Hadi öğrenelim!
Jenerik Veri Türleri
Jenerik Veri Türleri
Fonksiyon imzaları veya struct’lar (yapılar) gibi öğeler için tanımlamalar oluşturmak amacıyla jenerikleri kullanırız, bunları daha sonra birçok farklı somut veri türüyle kullanabiliriz. İlk olarak jenerikleri kullanarak fonksiyonları, struct’ları, enum’ları ve metotları nasıl tanımlayacağımıza bakalım. Sonra jeneriklerin kod performansını nasıl etkilediğini tartışacağız.
Fonksiyon Tanımlarında
Jenerik kullanan bir fonksiyon tanımlarken, jenerikleri genellikle parametrelerin ve dönüş değerinin veri türlerini belirteceğimiz yere, yani fonksiyonun imzasına yerleştiririz. Bunu yapmak kodumuzu daha esnek hale getirir ve kod tekrarını engellerken fonksiyonumuzu çağıranlara daha fazla işlevsellik sağlar.
en_buyuk fonksiyonumuza devam edersek, Liste 10-4 her ikisi de bir dilimdeki en büyük değeri bulan iki fonksiyon göstermektedir. Daha sonra bunları jenerik kullanan tek bir fonksiyonda birleştireceğiz.
fn en_buyuk_i32(liste: &[i32]) -> &i32 {
let mut en_buyuk = &liste[0];
for oge in liste {
if oge > en_buyuk {
en_buyuk = oge;
}
}
en_buyuk
}
fn en_buyuk_char(liste: &[char]) -> &char {
let mut en_buyuk = &liste[0];
for oge in liste {
if oge > en_buyuk {
en_buyuk = oge;
}
}
en_buyuk
}
fn main() {
let sayi_listesi = vec![34, 50, 25, 100, 65];
let sonuc = en_buyuk_i32(&sayi_listesi);
println!("En büyük sayı: {sonuc}");
assert_eq!(*sonuc, 100);
let karakter_listesi = vec!['y', 'm', 'a', 'q'];
let sonuc = en_buyuk_char(&karakter_listesi);
println!("En büyük karakter: {sonuc}");
assert_eq!(*sonuc, 'y');
}en_buyuk_i32 fonksiyonu Liste 10-3’te çıkardığımız ve bir dilimdeki en büyük i32’yi bulan fonksiyondur. en_buyuk_char fonksiyonu ise bir dilimdeki en büyük char değerini bulur. Fonksiyon gövdeleri aynı koda sahiptir, bu yüzden tek bir fonksiyona jenerik bir tür parametresi dahil ederek bu tekrarı ortadan kaldıralım.
Yeni, tek bir fonksiyondaki türleri parametre haline getirmek için tıpkı bir fonksiyona geçirilen değer parametrelerinde yaptığımız gibi tür parametresini isimlendirmemiz gerekir. Bir tür parametresi adı olarak herhangi bir tanımlayıcı kullanabilirsiniz. Ancak biz T kullanacağız çünkü kural olarak, Rust’taki tür parametresi adları kısadır (genellikle tek bir harf) ve Rust’ın tür adlandırma kuralı UpperCamelCase (BüyükDeveHali) şeklindedir. Türün (Type) kısaltması olan T, çoğu Rust programcısının varsayılan seçimidir.
Fonksiyonun gövdesinde bir parametre kullandığımızda, derleyicinin bu adın ne anlama geldiğini bilmesi için imzaya parametre adını bildirmemiz gerekir. Benzer şekilde, bir fonksiyon imzasında bir tür parametresi adı kullandığımızda, kullanmadan önce tür parametresi adını bildirmemiz gerekir. Jenerik en_buyuk fonksiyonunu tanımlamak için tür adı tanımlarını fonksiyon adı ve parametre listesi arasına açılı ayraçlar (angle brackets, <>) içine yerleştiririz, tıpkı bunun gibi:
fn en_buyuk_bul<T>(liste: &[T]) -> &T {Bu tanımı “en_buyuk_bul fonksiyonu T türü üzerinde jeneriktir” olarak okuruz. Bu fonksiyonun, T türündeki değerlerden oluşan bir dilim olan liste adında bir parametresi vardır. en_buyuk_bul fonksiyonu aynı T türünde bir değere referans döndürecektir.
Liste 10-5, imzasında jenerik veri türünü kullanan birleştirilmiş en_buyuk_bul fonksiyon tanımını gösterir. Liste ayrıca fonksiyonu bir i32 değer dilimiyle veya char değer dilimiyle nasıl çağırabileceğimizi de gösterir. Bu kodun henüz derlenmeyeceğini unutmayın.
fn en_buyuk_bul<T>(liste: &[T]) -> &T {
let mut en_buyuk = &liste[0];
for oge in liste {
if oge > en_buyuk {
en_buyuk = oge;
}
}
en_buyuk
}
fn main() {
let sayi_listesi = vec![34, 50, 25, 100, 65];
let sonuc = en_buyuk_bul(&sayi_listesi);
println!("En büyük sayı: {sonuc}");
let karakter_listesi = vec!['y', 'm', 'a', 'q'];
let sonuc = en_buyuk_bul(&karakter_listesi);
println!("En büyük karakter: {sonuc}");
}en_buyuk_bul fonksiyonu; bu henüz derlenmiyorBu kodu şu anda derlersek şu hatayı alırız:
$ cargo run
Compiling bolum10 v0.1.0 ($PROJE/listings/ch10-generic-types-traits-and-lifetimes/listing-10-05)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:16
|
5 | if oge > en_buyuk {
| --- ^ -------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn en_buyuk_bul<T: std::cmp::PartialOrd>(liste: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `bolum10` (bin "bolum10") due to 1 previous error
Yardım metni bir trait olan std::cmp::PartialOrd’dan bahsediyor ve bir sonraki bölümde traitler hakkında konuşacağız. Şimdilik bu hatanın, en_buyuk_bul gövdesinin T’nin olabileceği olası tüm türler için çalışmayacağını ifade ettiğini bilin. Gövdede T türündeki değerleri karşılaştırmak istediğimizden, yalnızca değerleri sıralanabilen türleri kullanabiliriz. Karşılaştırmaları mümkün kılmak için standart kütüphane, türler üzerine uygulayabileceğiniz std::cmp::PartialOrd trait’ine sahiptir (bu trait hakkında daha fazla bilgi için Ek C’ye bakın). Liste 10-5’i düzeltmek için yardım metninin önerisini izleyebilir ve T için geçerli olan türleri yalnızca PartialOrd uygulayanlarla kısıtlayabiliriz. Standart kütüphane hem i32 hem de char üzerinde PartialOrd uyguladığı için liste o zaman derlenecektir.
Struct (Yapı) Tanımlarında
Ayrıca bir veya daha fazla alanda <> sözdizimini kullanarak jenerik tür parametresi kullanmak için struct’lar tanımlayabiliriz. Liste 10-6 herhangi bir türden x ve y koordinat değerlerini tutmak için bir Nokta<T> struct’ı tanımlar.
struct Nokta<T> {
x: T,
y: T,
}
fn main() {
let tamsayi = Nokta { x: 5, y: 10 };
let ondalikli = Nokta { x: 1.0, y: 4.0 };
}T türünde x ve y değerlerini tutan bir Nokta<T> yapısıStruct tanımlarında jenerik kullanma sözdizimi, fonksiyon tanımlarında kullanılana benzer. İlk olarak struct isminin hemen arkasında açılı ayraçlar içinde tür parametresinin ismini tanımlıyoruz. Daha sonra struct tanımında normalde somut veri türlerini belirteceğimiz yerlerde jenerik türü kullanıyoruz.
Nokta<T>’yi tanımlamak için sadece bir jenerik tür kullandığımızdan, bu tanımın Nokta<T> yapısının bir T türü üzerinde jenerik olduğunu ve x ve y alanlarının ikisinin de aynı türden olduğunu söylediğine dikkat edin (bu tür ne olursa olsun). Liste 10-7’deki gibi farklı türlerde değerleri olan bir Nokta<T> örneği oluşturursak kodumuz derlenmeyecektir.
struct Nokta<T> {
x: T,
y: T,
}
fn main() {
let calismayacak = Nokta { x: 5, y: 4.0 };
}x ve y alanları aynı türden olmalıdır çünkü ikisi de aynı jenerik veri türü T’ye sahiptir.Bu örnekte x’e tamsayı olan 5 değerini atadığımızda derleyiciye Nokta<T>’nin bu örneği için T jenerik türünün bir tamsayı olacağını bildiririz. Daha sonra, x ile aynı türde olmasını tanımladığımız y için 4.0 belirttiğimizde, bunun gibi bir tür uyuşmazlığı hatası alırız:
$ cargo run
Compiling bolum10 v0.1.0 ($PROJE/listings/ch10-generic-types-traits-and-lifetimes/listing-10-07)
error[E0308]: mismatched types
--> src/main.rs:7:41
|
7 | let calismayacak = Nokta { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `bolum10` (bin "bolum10") due to 1 previous error
x ve y’nin her ikisinin de jenerik olduğu ancak farklı türlere sahip olabildiği bir Nokta struct’ı tanımlamak için birden fazla jenerik tür parametresi kullanabiliriz. Örneğin, Liste 10-8’de x’in T türünde ve y’nin U türünde olduğu, T ve U türleri üzerinde jenerik olması için Nokta’nın tanımını değiştiriyoruz.
struct Nokta<T, U> {
x: T,
y: U,
}
fn main() {
let ikisi_de_tamsayi = Nokta { x: 5, y: 10 };
let ikisi_de_ondalikli = Nokta { x: 1.0, y: 4.0 };
let tamsayi_ve_ondalikli = Nokta { x: 5, y: 4.0 };
}x ve y’nin farklı türlerde değerlere sahip olabileceği bir Nokta<T, U>Artık gösterilen tüm Nokta örneklerine izin veriliyor! Bir tanımda istediğiniz kadar çok jenerik tür parametresi kullanabilirsiniz ancak birkaça taneden fazlasını kullanmak kodunuzun okunmasını zorlaştırır. Kodunuzda çok sayıda jenerik türe ihtiyaç duyduğunuzu fark ederseniz, bu durum kodunuzun daha küçük parçalara bölünerek yeniden yapılandırılması gerektiğine işaret edebilir.
Enum Tanımlarında
Struct’larda yaptığımız gibi enum’ları da varyantlarında (seçeneklerinde) jenerik veri türlerini barındıracak şekilde tanımlayabiliriz. Standart kütüphanenin sağladığı ve Bölüm 6’da kullandığımız Option<T> enum’ına bir kez daha bakalım:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Bu tanım artık size daha mantıklı gelmelidir. Gördüğünüz gibi Option<T> enum’ı T türü üzerinde jeneriktir ve iki varyantı vardır: T türünden bir değer tutan Some ve hiçbir değer tutmayan bir None varyantı. Option<T> enum’ını kullanarak isteğe bağlı bir değerin soyut kavramını ifade edebiliriz ve Option<T> jenerik olduğu için bu isteğe bağlı değerin türü ne olursa olsun bu soyutlamayı kullanabiliriz.
Enum’lar birden fazla jenerik türü de kullanabilir. Bölüm 9’da kullandığımız Result enum’ının tanımı buna bir örnektir:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}Result enum’ı T ve E olmak üzere iki tür üzerinde jeneriktir ve iki varyantı vardır: T türünden bir değer tutan Ok ve E türünden bir değer tutan Err. Bu tanım, başarılı olabilecek (bir tür T değeri döndüren) veya başarısız olabilecek (bir tür E hatası döndüren) bir operasyonumuzun olduğu her yerde Result enum’ını kullanmayı elverişli hale getirir. Aslında, Liste 9-3’te dosya başarıyla açıldığında T’nin std::fs::File türüyle doldurulduğu ve dosya açılırken sorunlar olduğunda E’nin std::io::Error türüyle doldurulduğu bir dosyayı açmak için kullandığımız şey budur.
Kodunuzda sadece tuttukları değerlerin türleri açısından farklılık gösteren çoklu struct veya enum tanımlarına sahip olduğunuz durumları fark ettiğinizde, bunun yerine jenerik türler kullanarak tekrarlardan kaçınabilirsiniz.
Metot Tanımlarında
Struct ve enum’lar üzerinde metotlar uygulayabilir (Bölüm 5’te yaptığımız gibi) ve jenerik türleri bunların tanımlarında da kullanabiliriz. Liste 10-9, Liste 10-6’da tanımladığımız Nokta<T> struct’ı üzerinde uygulanan x adlı metodu gösterir.
struct Nokta<T> {
x: T,
y: T,
}
impl<T> Nokta<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Nokta { x: 5, y: 10 };
println!("p.x = {}", p.x());
}Nokta<T> struct’ı üzerinde, T türündeki x alanına referans döndürecek olan x isimli bir metodu uygulamakBurada Nokta<T> üzerinde x alanındaki veriye bir referans döndüren x adında bir metot tanımladık.
Metotları Nokta<T> türü üzerinde uyguladığımızı belirtmek için T’yi kullanabilmek adına impl’den hemen sonra T bildirmemiz gerektiğine dikkat edin. T’yi impl’den sonra jenerik bir tür olarak bildirerek Rust, Nokta içindeki açılı parantezlerdeki türün somut bir türden ziyade jenerik bir tür olduğunu belirleyebilir. Bu jenerik parametre için struct tanımında bildirilen jenerik parametreden farklı bir ad seçebilirdik ancak aynı adı kullanmak kuraldır. Jenerik bir tür bildiren bir impl içerisinde bir metot yazarsanız, jenerik türün yerine hangi somut tür (concrete type) gelirse gelsin, o metot türün herhangi bir örneğinde tanımlanacaktır.
Bir tür üzerinde metotları tanımlarken jenerik türler üzerindeki kısıtlamaları da belirtebiliriz. Örneğin herhangi bir jenerik türdeki Nokta<T> örnekleri yerine yalnızca Nokta<f32> örnekleri üzerinde metotlar uygulayabilirdik. Liste 10-10’da somut tür f32’yi kullanıyoruz, bu da impl’den sonra herhangi bir tür bildirmediğimiz anlamına geliyor.
struct Nokta<T> {
x: T,
y: T,
}
impl<T> Nokta<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Nokta<f32> {
fn orijinden_uzaklik(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Nokta { x: 5, y: 10 };
println!("p.x = {}", p.x());
}T jenerik tür parametresi için belirli bir somut türe sahip bir struct’a (yapıya) uygulanan bir impl bloğuBu kod Nokta<f32> türünün orijinden_uzaklik adlı bir metoda sahip olacağı anlamına gelir; T’nin f32 türünde olmadığı diğer Nokta<T> örneklerinde bu metot tanımlı olmayacaktır. Bu metot, noktamızın (0.0, 0.0) koordinatlarındaki noktadan ne kadar uzakta olduğunu ölçer ve yalnızca ondalıklı türler için mevcut olan matematiksel işlemleri kullanır.
Bir struct tanımındaki jenerik tür parametreleri, aynı struct’ın metot imzalarında kullandıklarınızla her zaman aynı değildir. Liste 10-11, örneği daha açık hale getirmek için Nokta struct’ı için X1 ve Y1 jenerik türlerini ve karistir metodunun imzası için X2 ve Y2 jenerik türlerini kullanır. Bu metot, ( X1 türünde olan) self’teki (kendisindeki) Nokta değerinin x değerinden ve ( Y2 türünde olan) parametre olarak geçilen Nokta değerinin y değerinden yeni bir Nokta örneği yaratır.
struct Nokta<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Nokta<X1, Y1> {
fn karistir<X2, Y2>(self, diger: Nokta<X2, Y2>) -> Nokta<X1, Y2> {
Nokta {
x: self.x,
y: diger.y,
}
}
}
fn main() {
let p1 = Nokta { x: 5, y: 10.4 };
let p2 = Nokta {
x: "Merhaba",
y: 'c',
};
let p3 = p1.karistir(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}main fonksiyonunda, x için i32 (değeri 5) ve y için f64 (değeri 10.4) olan bir Nokta tanımladık. p2 değişkeni x için string dilimine (değeri "Merhaba") ve y için bir char türüne (değeri 'c') sahip bir Nokta yapısıdır. p2 argümanıyla p1 üzerinde karistir çağrısı yapmak bize p3’ü verir, ki bu da x için bir i32’ye sahip olacaktır çünkü x p1’den gelmiştir. p3 değişkeninin y değeri char olacaktır çünkü y p2’den gelmiştir. println! makrosunun çağrılması p3.x = 5, p3.y = c yazdıracaktır.
Bu örneğin amacı, bazı jenerik parametrelerin impl ile bazı jenerik parametrelerin ise metot tanımıyla bildirildiği bir durumu göstermektir. Burada X1 ve Y1 jenerik parametreleri impl sonrasında bildirilir çünkü onlar struct tanımıyla birlikte giderler. X2 ve Y2 jenerik parametreleri fn karistir’dan (fn mixup) sonra bildirilir çünkü sadece metotla ilgilidirler.
Jenerikleri Kullanan Kodların Performansı
Jenerik tür parametrelerini kullanırken bir çalışma zamanı maliyeti olup olmadığını merak ediyor olabilirsiniz. İyi haber şu ki, jenerik türler kullanmak programınızı somut türler kullandığınızdan daha yavaş çalıştırmayacaktır.
Rust derleme zamanında jenerikleri kullanarak kodun monomorfizasyonunu (monomorphization - tektipleştirme) gerçekleştirerek bunu başarır. Monomorfizasyon, derlendiğinde kullanılan somut türleri doldurarak jenerik kodu özel/spesifik koda dönüştürme işlemidir. Bu süreçte derleyici, Liste 10-5’te jenerik fonksiyonu yaratmak için kullandığımız adımların tersini yapar: Derleyici jenerik kodun çağrıldığı tüm yerlere bakar ve jenerik kodun birlikte çağrıldığı somut türler için kod üretir.
Standart kütüphanenin jenerik Option<T> enum’ını kullanarak bunun nasıl çalıştığına bakalım:
#![allow(unused)]
fn main() {
let tamsayi = Some(5);
let ondalikli = Some(5.0);
}Rust bu kodu derlediğinde monomorfizasyon uygular. Bu süreç sırasında derleyici Option<T> örneklerinde kullanılmış olan değerleri okur ve iki tür Option<T> tespit eder: Biri i32 diğeri ise f64. Bu şekilde, Option<T>’nin jenerik tanımını i32 ve f64’e özel iki tanıma genişletir ve böylece jenerik tanımı belirli olanlarla değiştirir.
Kodun monomorfize edilmiş (tektipleştirilmiş) hali aşağıdakine benzer (derleyici burada örnek olarak kullandıklarımızdan farklı isimler kullanır):
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let tamsayi = Option_i32::Some(5);
let ondalikli = Option_f64::Some(5.0);
}Jenerik Option<T>, derleyici tarafından oluşturulan belirli tanımlarla değiştirilir. Rust jenerik kodu her bir örnekte türü belirten bir koda derlediğinden, jenerikleri kullanmak için hiçbir çalışma zamanı maliyeti ödemeyiz. Kod çalıştığında, tıpkı her tanımı elle kopyalamışız gibi performans gösterir. Monomorfizasyon süreci, Rust’ın jeneriklerini çalışma zamanında son derece verimli hale getirir.
Trait'lerle Ortak Davranış Tanımlama
Traitler ile Paylaşılan Davranışı Tanımlamak
Bir trait, belirli bir türün sahip olduğu ve diğer türlerle paylaşabileceği işlevselliği tanımlar. Paylaşılan davranışı soyut bir şekilde tanımlamak için traitleri kullanabiliriz. Jenerik bir türün belirli bir davranışa sahip herhangi bir tür olabileceğini belirtmek için trait sınırlarını kullanabiliriz.
Not: Traitler, bazı farklılıkları olsa da, diğer dillerde genellikle arayüzler olarak adlandırılan bir özelliğe benzerdir.
Bir Trait Tanımlamak
Bir türün davranışı, o tür üzerinde çağırabileceğimiz metotlardan oluşur. Tüm bu türlerde aynı metotları çağırabiliyorsak farklı türler aynı davranışı paylaşır. Trait tanımları, bazı amaçları gerçekleştirmek için gerekli bir dizi davranışı tanımlamak amacıyla metot imzalarını gruplamanın bir yoludur.
Örneğin, çeşitli türlerde ve miktarlarda metin tutan birden fazla struct’ımız (yapımız) olduğunu varsayalım: Belirli bir konumda dosyalanmış bir haber hikayesini tutan HaberMakalesi struct’ı ve yeni bir gönderi mi, yeniden paylaşım mı yoksa başka bir gönderiye yanıt mı olduğunu belirten meta verilerle birlikte en fazla 280 karaktere sahip olabilen SosyalGonderi struct’ı.
Bir HaberMakalesi veya SosyalGonderi örneğinde depolanabilecek verilerin özetlerini görüntüleyebilen aggregator (toplayıcı) adında bir medya toplayıcı kütüphane crate’i yapmak istiyoruz. Bunu yapmak için, her bir türden bir özete ihtiyacımız var ve bir örnek üzerinde ozetle metodu çağırarak bu özeti isteyeceğiz. Liste 10-12 bu davranışı ifade eden açık bir Ozet trait’inin tanımını gösterir.
pub trait Ozet {
fn ozetle(&self) -> String;
}ozetle metodunun sağladığı davranıştan oluşan bir Ozet trait’iBurada, trait anahtar kelimesini ve ardından bu durumda Ozet olan trait adını kullanarak bir trait bildiriyoruz. Ayrıca, birkaç örnekte göreceğimiz gibi, bu crate’e bağlı olan cratelerin de bu trait’ten yararlanabilmesi için trait’i pub olarak bildiriyoruz. Süslü parantezlerin (curly brackets) içinde, bu trait’i uygulayan türlerin davranışlarını tanımlayan metot imzalarını bildiririz, bu durumda fn ozetle(&self) -> String’dir.
Metot imzasından sonra süslü parantezler içinde bir uygulama sağlamak yerine noktalı virgül kullanırız. Bu trait’i uygulayan her tür, metodun gövdesi için kendi özel davranışını sağlamalıdır. Derleyici, Ozet trait’ine sahip olan her türün tam olarak bu imzayla tanımlanmış ozetle metoduna sahip olmasını zorunlu kılacaktır.
Bir trait gövdesinde birden fazla metoda sahip olabilir: Metot imzaları her satıra bir tane olacak şekilde listelenir ve her satır noktalı virgülle biter.
Bir Tür Üzerinde Trait Uygulamak (Implementing)
Ozet trait’inin metotlarının istenen imzalarını tanımladığımıza göre, artık onu medya toplayıcımızdaki türler üzerinde uygulayabiliriz. Liste 10-13, ozetle metodunun dönüş değerini oluşturmak için manşeti, yazarı ve konumu kullanan HaberMakalesi struct’ı üzerinde Ozet trait’inin bir uygulamasını gösterir. SosyalGonderi struct’ı için, gönderi içeriğinin halihazırda 280 karakterle sınırlı olduğunu varsayarak ozetle metodunu kullanıcı adı ve ardından gönderinin tüm metni olarak tanımlıyoruz.
pub trait Ozet {
fn ozetle(&self) -> String;
}
pub struct HaberMakalesi {
pub manset: String,
pub konum: String,
pub yazar: String,
pub icerik: String,
}
impl Ozet for HaberMakalesi {
fn ozetle(&self) -> String {
format!("{}, {} ({})", self.manset, self.yazar, self.konum)
}
}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn ozetle(&self) -> String {
format!("{}: {}", self.kullanici_adi, self.icerik)
}
}HaberMakalesi ve SosyalGonderi türleri üzerinde Ozet trait’inin uygulanmasıBir tür üzerinde bir trait uygulamak, normal metotları uygulamaya benzer. Aradaki fark, impl kelimesinden sonra uygulamak istediğimiz trait adını koymamız, ardından for anahtar kelimesini kullanmamız ve sonra trait’i uygulamak istediğimiz türün adını belirtmemizdir. impl bloğunun içine, trait tanımında belirtilen metot imzalarını koyarız. Her imzanın sonuna noktalı virgül eklemek yerine süslü parantezler kullanırız ve trait’in metotlarının o belirli tür için sahip olmasını istediğimiz belirli davranışla metot gövdesini doldururuz.
Kütüphane HaberMakalesi ve SosyalGonderi üzerinde Ozet trait’ini uyguladığına göre, crate kullanıcıları normal metotları çağırdığımız şekilde HaberMakalesi ve SosyalGonderi örneklerinde trait metotlarını çağırabilir. Tek fark, kullanıcının türlerin yanı sıra trait’i de kapsama dahil etmesi gerektiğidir. İşte bir ikili crate’in aggregator kütüphane crate’imizi nasıl kullanabileceğine dair bir örnek:
use aggregator::{Ozet, SosyalGonderi};
fn main() {
let gonderi = SosyalGonderi {
kullanici_adi: String::from("horse_ebooks"),
icerik: String::from(
"elbette, muhtemelen zaten bildiğiniz gibi, insanlar",
),
yanit: false,
yeniden_paylasim: false,
};
println!("1 yeni gönderi: {}", gonderi.ozetle());
}Bu kod 1 yeni gönderi: horse_ebooks: elbette, muhtemelen zaten bildiğiniz gibi, insanlar yazdırır.
aggregator crate’ine bağlı olan diğer crateler de Ozet trait’ini kendi türleri üzerinde uygulamak için Ozet trait’ini kapsama dahil edebilirler. Dikkat edilmesi gereken bir kısıtlama, bir tür üzerinde bir trait’i ancak trait veya türden biri ya da her ikisi bizim crate’imiz için yerel ise uygulayabilmemizdir. Örneğin, SosyalGonderi türü bizim aggregator crate’imiz için yerel olduğundan, aggregator crate işlevselliğimizin bir parçası olarak SosyalGonderi gibi özel bir tür üzerinde Display (Göster) gibi standart kütüphane traitlerini uygulayabiliriz. Ayrıca, Ozet trait’i aggregator crate’imiz için yerel olduğundan, aggregator crate’imizde Vec<T> üzerinde Ozet uygulayabiliriz.
Ancak harici traitleri harici türler üzerinde uygulayamayız. Örneğin, aggregator crate’imiz içerisinde Vec<T> üzerinde Display trait’ini uygulayamayız, çünkü hem Display hem de Vec<T> standart kütüphanede tanımlanmıştır ve aggregator crate’imiz için yerel değildir. Bu kısıtlama, tutarlılık adı verilen bir özelliğin ve daha spesifik olarak ebeveyn türün mevcut olmaması nedeniyle bu adı alan yetim kuralının bir parçasıdır. Bu kural, başkalarının kodunun sizin kodunuzu, sizin kodunuzun da başkalarının kodunu bozamamasını sağlar. Kural olmasaydı, iki crate aynı tür için aynı trait’i uygulayabilirdi ve Rust hangi uygulamayı kullanacağını bilemezdi.
Varsayılan Uygulamaları (Default Implementations) Kullanmak
Bazen her türdeki tüm metotlar için uygulama gerektirmek yerine bir trait’teki metotların bazılarında veya tümünde varsayılan bir davranışa sahip olmak yararlıdır. Böylece, trait’i belirli bir tür üzerinde uygularken, her metodun varsayılan davranışını koruyabilir veya geçersiz kılabiliriz.
Liste 10-14’te, Liste 10-12’de yaptığımız gibi yalnızca metot imzasını tanımlamak yerine Ozet trait’inin ozetle metodu için varsayılan bir string (dizgi) belirliyoruz.
pub trait Ozet {
fn ozetle(&self) -> String {
String::from("(Devamını oku...)")
}
}
pub struct HaberMakalesi {
pub manset: String,
pub konum: String,
pub yazar: String,
pub icerik: String,
}
impl Ozet for HaberMakalesi {}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn ozetle(&self) -> String {
format!("{}: {}", self.kullanici_adi, self.icerik)
}
}ozetle metodunun varsayılan bir uygulamasıyla birlikte Ozet trait’ini tanımlamakHaberMakalesi örneklerini özetlerken varsayılan bir uygulama kullanmak için impl Ozet for HaberMakalesi {} şeklinde boş bir impl bloğu belirtiriz.
Artık doğrudan HaberMakalesi üzerinde ozetle metodunu tanımlamıyor olsak da, varsayılan bir uygulama sağladık ve HaberMakalesi’nin Ozet trait’ini uyguladığını belirttik. Sonuç olarak, HaberMakalesi örneğinde ozetle metodunu hala şu şekilde çağırabiliriz:
use aggregator::{self, HaberMakalesi, Ozet};
fn main() {
let makale = HaberMakalesi {
manset: String::from("Penguenler Stanley Cup Şampiyonluğunu kazandı!"),
konum: String::from("Pittsburgh, PA, ABD"),
yazar: String::from("Iceburgh"),
icerik: String::from(
"Pittsburgh Penguenleri bir kez daha NHL'deki en iyi \
hokey takımı.",
),
};
println!("Yeni makale mevcut! {}", makale.ozetle());
}Bu kod Yeni makale mevcut! (Devamını oku...) yazdırır.
Varsayılan bir uygulama oluşturmak, Liste 10-13’teki SosyalGonderi üzerindeki Ozet uygulamasında herhangi bir şeyi değiştirmemizi gerektirmez. Bunun nedeni, varsayılan bir uygulamayı geçersiz kılma sözdiziminin, varsayılan bir uygulaması olmayan bir trait metodunu uygulama sözdizimiyle aynı olmasıdır.
Varsayılan uygulamalar, diğer metotların varsayılan bir uygulaması olmasa bile aynı trait’teki diğer metotları çağırabilir. Bu şekilde, bir trait çok fazla faydalı işlevsellik sağlayabilir ve uygulayıcılardan sadece küçük bir kısmını belirtmelerini isteyebilir. Örneğin, uygulamasının gerekli olduğu yazari_ozetle metodu olan bir Ozet trait’i tanımlayabiliriz ve ardından yazari_ozetle metodunu çağıran varsayılan bir uygulamaya sahip ozetle metodu tanımlayabiliriz:
pub trait Ozet {
fn yazari_ozetle(&self) -> String;
fn ozetle(&self) -> String {
format!(
"({} yazarından daha fazlasını okuyun...)",
self.yazari_ozetle()
)
}
}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn yazari_ozetle(&self) -> String {
format!("@{}", self.kullanici_adi)
}
}Bu Ozet sürümünü kullanmak için, trait’i bir tür üzerinde uygularken sadece yazari_ozetle metodunu tanımlamamız gerekir:
pub trait Ozet {
fn yazari_ozetle(&self) -> String;
fn ozetle(&self) -> String {
format!(
"({} yazarından daha fazlasını okuyun...)",
self.yazari_ozetle()
)
}
}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn yazari_ozetle(&self) -> String {
format!("@{}", self.kullanici_adi)
}
}yazari_ozetle’yi tanımladıktan sonra, SosyalGonderi struct’ının örnekleri üzerinde ozetle’yi çağırabiliriz ve ozetle’nin varsayılan uygulaması, sağladığımız yazari_ozetle tanımını çağıracaktır. yazari_ozetle uygulamasını gerçekleştirdiğimiz için Ozet trait’i bize daha fazla kod yazmamıza gerek kalmadan ozetle metodunun davranışını verdi. İşte şöyle görünür:
use aggregator::{self, SosyalGonderi, Ozet};
fn main() {
let gonderi = SosyalGonderi {
kullanici_adi: String::from("horse_ebooks"),
icerik: String::from(
"elbette, muhtemelen zaten bildiğiniz gibi, insanlar",
),
yanit: false,
yeniden_paylasim: false,
};
println!("1 yeni gönderi: {}", gonderi.ozetle());
}Bu kod 1 yeni gönderi: (@horse_ebooks yazarından daha fazlasını okuyun...) yazdırır.
Aynı metodun geçersiz kılınan bir uygulamasından varsayılan uygulamayı çağırmanın mümkün olmadığını unutmayın.
Traitleri Parametre Olarak Kullanmak
Artık traitlerin nasıl tanımlanacağını ve uygulanacağını bildiğinize göre, birçok farklı türü kabul eden fonksiyonları tanımlamak için traitleri nasıl kullanacağınızı keşfedebiliriz. Ozet trait’ini uygulayan bir türde olan oge parametresi üzerinde ozetle metodunu çağıran bildir fonksiyonunu tanımlamak için Liste 10-13’te HaberMakalesi ve SosyalGonderi türleri üzerinde uyguladığımız Ozet trait’ini kullanacağız. Bunu yapmak için, impl Trait sözdizimini şu şekilde kullanırız:
pub trait Ozet {
fn ozetle(&self) -> String;
}
pub struct HaberMakalesi {
pub manset: String,
pub konum: String,
pub yazar: String,
pub icerik: String,
}
impl Ozet for HaberMakalesi {
fn ozetle(&self) -> String {
format!("{}, {} ({})", self.manset, self.yazar, self.konum)
}
}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn ozetle(&self) -> String {
format!("{}: {}", self.kullanici_adi, self.icerik)
}
}
pub fn bildir(oge: &impl Ozet) {
println!("Son dakika haberi! {}", oge.ozetle());
}oge parametresi için somut bir tür (concrete type) yerine impl anahtar kelimesini ve trait adını belirtiyoruz. Bu parametre, belirtilen trait’i uygulayan herhangi bir türü kabul eder. bildir’in gövdesinde, oge üzerinde Ozet trait’inden gelen ozetle gibi metotları çağırabiliriz. bildir çağırabiliriz ve herhangi bir HaberMakalesi veya SosyalGonderi örneği geçebiliriz. Fonksiyonu String veya i32 gibi herhangi bir türle çağıran kod derlenmeyecektir çünkü bu türler Ozet trait’ini uygulamazlar.
Trait Sınırı (Trait Bound) Sözdizimi
impl Trait sözdizimi basit durumlar için işe yarar ancak aslında trait sınırı (trait bound) olarak bilinen daha uzun bir formun sözdizimsel şekeri gibidir; şu şekilde görünür:
pub fn bildir<T: Ozet>(oge: &T) {
println!("Son dakika haberi! {}", oge.ozetle());
}Bu uzun form, önceki bölümdeki örneğe eşdeğerdir ancak daha uzundur. Jenerik tür parametresinin bildirimi ile birlikte iki nokta üst üsteden sonra ve açılı parantezlerin içine trait sınırlarını yerleştiririz.
impl Trait sözdizimi kullanışlıdır ve basit durumlarda kodu daha özlü hale getirirken, daha tam olan (fuller) trait sınırı sözdizimi diğer durumlarda daha fazla karmaşıklığı ifade edebilir. Örneğin, Ozet uygulayan iki parametremiz olabilir. Bunu impl Trait sözdizimi ile yapmak şuna benzer:
pub fn bildir(oge1: &impl Ozet, oge2: &impl Ozet) {Eğer bu fonksiyonun oge1 ve oge2’nin farklı türlere sahip olmasına izin vermesini istiyorsak (her iki tür de Ozet uyguladığı sürece) impl Trait kullanmak uygundur. Ancak her iki parametreyi de aynı türe sahip olmaya zorlamak istersek, şu şekilde bir trait sınırı kullanmalıyız:
pub fn bildir<T: Ozet>(oge1: &T, oge2: &T) {oge1 ve oge2 parametrelerinin türü olarak belirtilen jenerik tür T, fonksiyonu öyle bir kısıtlar ki, oge1 ve oge2 için argüman olarak iletilen değerin somut türü (concrete type) aynı olmalıdır.
+ Sözdizimi ile Birden Fazla Trait Sınırı
Birden fazla trait sınırı da belirtebiliriz. Diyelim ki bildir’in oge üzerinde ozetle ile birlikte ekran biçimlendirmesini de kullanmasını istiyoruz: bildir tanımında oge’nin hem Display hem de Ozet trait’lerini uygulaması gerektiğini belirtiyoruz. Bunu + sözdizimini kullanarak yapabiliriz:
pub fn bildir(oge: &(impl Ozet + Display)) {+ sözdizimi jenerik türler üzerindeki trait sınırlarıyla da geçerlidir:
pub fn bildir<T: Ozet + Display>(oge: &T) {Belirtilen iki trait sınırı ile bildir’in gövdesi ozetle’yi çağırabilir ve oge’yi formatlamak için {} kullanabilir.
where Cümlecikleriyle Daha Açık Trait Sınırları
Çok fazla trait sınırı kullanmanın dezavantajları vardır. Her jeneriğin kendi trait sınırları vardır, bu nedenle birden fazla jenerik tür parametresine sahip fonksiyonlar, fonksiyonun adı ve parametre listesi arasında çok fazla trait sınırı bilgisi içerebilir, bu da fonksiyon imzasının okunmasını zorlaştırır. Bu nedenle, Rust fonksiyon imzasından sonra bir where (nerede/şartıyla) cümleciği içinde trait sınırlarını belirtmek için alternatif bir sözdizimine sahiptir. Yani bunu yazmak yerine:
fn bazi_fonksiyonlar<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {Şu şekilde bir where cümleciği kullanabiliriz:
fn bazi_fonksiyonlar<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Bu fonksiyonun imzası daha az karmaşıktır: Fonksiyon adı, parametre listesi ve dönüş türü birbirine yakındır, tıpkı çok fazla trait sınırı olmayan bir fonksiyona benzer şekilde.
Traitleri Uygulayan (Implement) Türler Döndürmek
impl Trait sözdizimini, burada gösterildiği gibi bir trait uygulayan bazı türlerden bir değer döndürmek için dönüş pozisyonunda da kullanabiliriz:
pub trait Ozet {
fn ozetle(&self) -> String;
}
pub struct HaberMakalesi {
pub manset: String,
pub konum: String,
pub yazar: String,
pub icerik: String,
}
impl Ozet for HaberMakalesi {
fn ozetle(&self) -> String {
format!("{}, {} ({})", self.manset, self.yazar, self.konum)
}
}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn ozetle(&self) -> String {
format!("{}: {}", self.kullanici_adi, self.icerik)
}
}
fn ozetlenebilir_dondur() -> impl Ozet {
SosyalGonderi {
kullanici_adi: String::from("horse_ebooks"),
icerik: String::from(
"elbette, muhtemelen zaten bildiğiniz gibi, insanlar",
),
yanit: false,
yeniden_paylasim: false,
}
}Dönüş türü olarak impl Ozet kullanarak, ozetlenebilir_dondur fonksiyonunun somut türün adını vermeden Ozet trait’ini uygulayan bir tür döndürdüğünü belirtiyoruz. Bu durumda, ozetlenebilir_dondur bir SosyalGonderi döndürür ancak bu fonksiyonu çağıran kodun bunu bilmesi gerekmez.
Dönüş türünü sadece uyguladığı trait ile belirtebilme yeteneği, özellikle Bölüm 13’te ele aldığımız kapanışlar ve yineleyiciler bağlamında faydalıdır. Kapanışlar ve yineleyiciler, yalnızca derleyicinin bildiği türler veya belirtilmesi çok uzun olan türler yaratır. impl Trait sözdizimi, bir fonksiyonun çok uzun bir tür yazmaya gerek kalmadan Iterator trait’ini uygulayan bir tür döndürdüğünü özlü bir şekilde belirtmenizi sağlar.
Ancak, impl Trait’i yalnızca tek bir tür döndürüyorsanız kullanabilirsiniz. Örneğin, dönüş türü impl Ozet olarak belirtilen ve bir HaberMakalesi ya da bir SosyalGonderi döndüren bu kod işe yaramayacaktır:
pub trait Ozet {
fn ozetle(&self) -> String;
}
pub struct HaberMakalesi {
pub manset: String,
pub konum: String,
pub yazar: String,
pub icerik: String,
}
impl Ozet for HaberMakalesi {
fn ozetle(&self) -> String {
format!("{}, {} ({})", self.manset, self.yazar, self.konum)
}
}
pub struct SosyalGonderi {
pub kullanici_adi: String,
pub icerik: String,
pub yanit: bool,
pub yeniden_paylasim: bool,
}
impl Ozet for SosyalGonderi {
fn ozetle(&self) -> String {
format!("{}: {}", self.kullanici_adi, self.icerik)
}
}
fn ozetlenebilir_dondur(degistir: bool) -> impl Ozet {
if degistir {
HaberMakalesi {
manset: String::from(
"Penguenler Stanley Cup Şampiyonluğunu kazandı!",
),
konum: String::from("Pittsburgh, PA, ABD"),
yazar: String::from("Iceburgh"),
icerik: String::from(
"Pittsburgh Penguenleri bir kez daha NHL'deki en iyi \
hokey takımı.",
),
}
} else {
SosyalGonderi {
kullanici_adi: String::from("horse_ebooks"),
icerik: String::from(
"elbette, muhtemelen zaten bildiğiniz gibi, insanlar",
),
yanit: false,
yeniden_paylasim: false,
}
}
}Derleyicide impl Trait sözdiziminin nasıl uygulandığına ilişkin kısıtlamalar nedeniyle HaberMakalesi veya SosyalGonderi döndürülmesine izin verilmez. Bu davranışa sahip bir fonksiyonun nasıl yazılacağını Bölüm 18’in “Paylaşılan Davranış Üzerinden Soyutlama Yapmak İçin Trait Nesneleri Kullanmak” bölümünde ele alacağız.
Metotları Koşullu (Conditionally) Uygulamak İçin Trait Sınırlarını Kullanmak
Jenerik tür parametreleri kullanan bir impl bloğu ile birlikte bir trait sınırı kullanarak, belirtilen traitleri uygulayan türler için koşullu olarak metotlar uygulayabiliriz. Örneğin, Liste 10-15’teki Cift<T> türü her zaman yeni bir Cift<T> örneği döndüren new fonksiyonunu uygular (Bölüm 5’in “Metot Sözdizimi” kısmından hatırlayın, Self, bu durumda Cift<T> olan impl bloğunun türü için bir tür takma adıdır). Fakat bir sonraki impl bloğunda, Cift<T> yalnızca kendi içindeki T türü karşılaştırmayı sağlayan PartialOrd trait’ini ve yazdırmayı sağlayan Display trait’ini uyguluyorsa karsilastir_goster metodunu uygular.
use std::fmt::Display;
struct Cift<T> {
x: T,
y: T,
}
impl<T> Cift<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Cift<T> {
fn karsilastir_goster(&self) {
if self.x >= self.y {
println!("En büyük üye x = {}", self.x);
} else {
println!("En büyük üye y = {}", self.y);
}
}
}Ayrıca, başka bir trait’i uygulayan herhangi bir tür için koşullu olarak bir trait de uygulayabiliriz. Trait sınırlarını karşılayan herhangi bir tür üzerindeki trait uygulamalarına kapsayıcı uygulamalar denir ve Rust standart kütüphanesinde yaygın olarak kullanılırlar. Örneğin, standart kütüphane Display trait’ini uygulayan her tür için ToString trait’ini uygular. Standart kütüphanedeki impl bloğu bu koda benzemektedir:
impl<T: Display> ToString for T {
// --snip--
}Standart kütüphanede bu kapsayıcı uygulama (blanket implementation) bulunduğundan dolayı, Display trait’ini uygulayan herhangi bir tür üzerinde ToString trait’i tarafından tanımlanan to_string metodunu çağırabiliriz. Örneğin tamsayılar Display uyguladığından tamsayıları bu şekilde karşılık gelen String değerlerine dönüştürebiliriz:
#![allow(unused)]
fn main() {
let s = 3.to_string();
}Kapsayıcı uygulamalar, trait’in dokümantasyonunda “Uygulayıcılar” (Implementors) bölümünde yer alır.
Traitler ve trait sınırları, kod tekrarını azaltmak için jenerik tür parametrelerini kullanan kod yazmamızı sağlarken aynı zamanda derleyiciye jenerik türün belirli bir davranışa sahip olmasını istediğimizi belirtmemize de olanak tanır. Derleyici daha sonra trait sınırı bilgisini, kodumuzla birlikte kullanılan tüm somut türlerin doğru davranışı sağladığını kontrol etmek için kullanabilir. Dinamik olarak yazılmış dillerde, bir metodu tanımlamayan bir tür üzerinde metodu çağırsaydık çalışma zamanında bir hata alırdık. Ancak Rust bu hataları derleme zamanına taşır, böylece kodumuz çalışmadan önce sorunları düzeltmeye zorlanırız. Ek olarak, çalışma zamanında davranış için kontrol yapan bir kod yazmamıza gerek kalmaz, çünkü zaten derleme zamanında kontrol etmişizdir. Bunu yapmak jeneriklerin esnekliğinden vazgeçmek zorunda kalmadan performansı artırır.
Ömürlerle Referansları Doğrulama
Referansları Ömürlerle (Lifetimes) Doğrulamak
Ömürler, daha önce kullandığımız başka bir jenerik türüdür. Ömürler, bir türün istediğimiz davranışa sahip olduğundan emin olmak yerine, referansların onlara ihtiyacımız olduğu sürece geçerli kalmasını sağlar.
Bölüm 4’teki “Referanslar ve Ödünç Alma (Borrowing)” kısmında bahsetmediğimiz bir detay, Rust’taki her referansın bir ömrü (lifetime) olduğudur; bu, o referansın geçerli olduğu kapsamdır. Tıpkı çoğu zaman türlerin çıkarsanması gibi, çoğu zaman ömürler de örtüktür ve çıkarsanırlar. Yalnızca birden fazla türün mümkün olduğu durumlarda türleri açıklamamız gerekir. Benzer bir şekilde, referansların ömürlerinin birkaç farklı şekilde ilişkili olabileceği durumlarda da ömürleri açıklamamız gerekir. Rust, çalışma zamanında kullanılan gerçek referansların kesinlikle geçerli olacağından emin olmak için jenerik ömür parametrelerini kullanarak bu ilişkileri açıklamayı zorunlu tutar.
Ömürleri açıklamak, diğer çoğu programlama dilinde var olan bir kavram bile değildir, bu yüzden bu size yabancı gelecektir. Bu bölümde ömürleri bütünüyle ele almayacak olsak da, bu kavrama alışabilmeniz için ömür sözdizimiyle karşılaşabileceğiniz yaygın durumları tartışacağız.
Sarkan Referanslar (Dangling References)
Ömürlerin temel amacı, sarkan referansları önlemektir. Eğer bunların var olmasına izin verilseydi, bir programın başvurmayı amaçladığı veriler dışındaki verilere referans vermesine neden olurdu. Bir dış kapsama ve bir iç kapsama sahip olan Liste 10-16’daki programı düşünün.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Not: Liste 10-16, 10-17 ve 10-23’teki örnekler, değişkenlere ilk değer vermeden onları bildirir, bu nedenle değişken adı dış kapsamda mevcuttur. İlk bakışta bu, Rust’ın null (boş) değerlere sahip olmamasıyla çelişiyor gibi görünebilir. Ancak, bir değişkene değer vermeden onu kullanmaya çalışırsak, derleme zamanı hatası alırız; bu da Rust’ın gerçekten null değerlere izin vermediğini gösterir.
Dış kapsam, ilk değeri olmayan r adında bir değişken tanımlar ve iç kapsam, ilk değeri 5 olan x adında bir değişken tanımlar. İç kapsamın içinde, r’nin değerini x’e bir referans olarak ayarlamaya çalışırız. Sonra iç kapsam sona erer ve r’deki değeri yazdırmaya çalışırız. Bu kod derlenmeyecektir, çünkü biz onu kullanmaya çalışmadan önce r’nin atıfta bulunduğu değer kapsam dışına çıkmıştır. İşte hata mesajı:
$ cargo run
Compiling bolum10 v0.1.0 (file:///projects/bolum10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `bolum10` (bin "bolum10") due to 1 previous error
Hata mesajı, x değişkeninin “yeterince uzun yaşamadığını (does not live long enough)” söyler. Bunun nedeni, iç kapsam 7. satırda sona erdiğinde x’in kapsam dışına çıkacak olmasıdır. Ancak r dış kapsam için hala geçerlidir; kapsamı daha geniş olduğu için onun “daha uzun yaşadığını” söylüyoruz. Rust bu kodun çalışmasına izin verseydi, r x kapsam dışına çıktığında ayrılması iptal edilen belleğe atıfta bulunuyor olurdu ve r ile yapmaya çalıştığımız hiçbir şey doğru çalışmazdı. Peki, Rust bu kodun geçersiz olduğunu nasıl belirliyor? Bir ödünç alma denetleyicisi kullanır.
Ödünç Alma Denetleyicisi (Borrow Checker)
Rust derleyicisi, tüm ödünç almaların geçerli olup olmadığını belirlemek için kapsamları karşılaştıran bir ödünç alma denetleyicisine sahiptir. Liste 10-17, Liste 10-16 ile aynı kodu gösterir, ancak değişkenlerin ömürlerini gösteren açıklamalarla birlikte.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+r ve x’in ömürlerinin sırasıyla 'a ve 'b olarak adlandırılan açıklamalarıBurada r’nin ömrünü 'a ile ve x’in ömrünü 'b ile açıkladık. Gördüğünüz gibi içteki 'b bloğu dıştaki 'a ömür bloğundan çok daha küçüktür. Derleme zamanında Rust iki ömrün boyutunu karşılaştırır ve r’nin 'a ömrüne sahip olduğunu ancak 'b ömrüne sahip bir belleğe atıfta bulunduğunu görür. 'b, 'a’dan daha kısa olduğu için program reddedilir: Referansın konusu referans kadar uzun yaşamaz.
Liste 10-18 kodu düzeltir, böylece kod bir sarkan referansa (dangling reference) sahip olmaz ve hiçbir hata vermeden derlenir.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+Burada x, bu durumda 'a’dan daha büyük olan 'b ömrüne sahiptir. Bu, r’nin x’e atıfta bulunabileceği anlamına gelir; çünkü Rust, r’deki referansın x geçerli olduğu sürece her zaman geçerli olacağını bilir.
Artık referansların ömürlerinin nerede olduğunu ve Rust’ın referansların her zaman geçerli olacağından emin olmak için ömürleri nasıl analiz ettiğini bildiğinize göre, fonksiyon parametrelerindeki ve dönüş değerlerindeki jenerik ömürleri inceleyelim.
Fonksiyonlarda Jenerik Ömürler
İki string (dizgi) diliminden daha uzun olanını döndüren bir fonksiyon yazacağız. Bu fonksiyon iki string dilimi alacak ve tek bir string dilimi döndürecek. en_uzun fonksiyonunu uyguladıktan sonra, Liste 10-19’daki kod En uzun dizgi: abcd yazdırmalıdır.
fn main() {
let dizgi1 = String::from("abcd");
let dizgi2 = "xyz";
let sonuc = en_uzun(dizgi1.as_str(), dizgi2);
println!("En uzun dizgi: {sonuc}");
}en_uzun fonksiyonunu çağıran bir main fonksiyonuFonksiyonun, stringler (String) yerine birer referans olan string dilimlerini almasını istediğimize dikkat edin; çünkü en_uzun fonksiyonunun kendi parametrelerinin sahipliğini almasını istemiyoruz. Liste 10-19’da kullandığımız parametrelerin neden istediğimiz parametreler olduğu hakkında daha fazla tartışma için Bölüm 4’teki “Parametre Olarak String Dilimleri” kısmına bakın.
en_uzun fonksiyonunu Liste 10-20’de gösterildiği gibi uygulamaya çalışırsak derlenmeyecektir.
fn main() {
let dizgi1 = String::from("abcd");
let dizgi2 = "xyz";
let sonuc = en_uzun(dizgi1.as_str(), dizgi2);
println!("En uzun dizgi: {sonuc}");
}
fn en_uzun(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}en_uzun fonksiyonunun bir uygulamasıBunun yerine, ömürler hakkında konuşan şu hatayı alırız:
$ cargo run
Compiling bolum10 v0.1.0 ($PROJE/listings/ch10-generic-types-traits-and-lifetimes/listing-10-20)
error[E0106]: missing lifetime specifier
--> src/main.rs:10:33
|
10 | fn en_uzun(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
10 | fn en_uzun<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `bolum10` (bin "bolum10") due to 1 previous error
Yardım metni, dönüş türünün üzerinde jenerik bir ömür parametresine ihtiyacı olduğunu ortaya koymaktadır, çünkü Rust döndürülen referansın x’i mi yoksa y’yi mi ifade ettiğini söyleyemez. Aslında, biz de bilmiyoruz, çünkü bu fonksiyonun gövdesindeki if bloğu x’e bir referans döndürürken else bloğu y’ye bir referans döndürüyor!
Bu fonksiyonu tanımlarken, bu fonksiyona geçirilecek somut değerleri bilmediğimizden if durumunun (case) mu yoksa else durumunun mu yürütüleceğini (execute) bilemeyiz. Aynı zamanda geçirilecek referansların somut ömürlerini de bilmiyoruz, bu yüzden döndürdüğümüz referansın her zaman geçerli olup olmayacağını belirlemek için Liste 10-17 ve 10-18’de yaptığımız gibi kapsamlara bakamayız. Ödünç alma denetleyicisi de bunu belirleyemez, çünkü x ve y’nin ömürlerinin dönüş değerinin ömrüyle nasıl bir ilişkisi olduğunu bilmez. Bu hatayı düzeltmek için, referanslar arasındaki ilişkiyi tanımlayan jenerik ömür parametreleri ekleyeceğiz, böylece ödünç alma denetleyicisi analizini gerçekleştirebilir.
Ömür Açıklaması Sözdizimi (Lifetime Annotation Syntax)
Ömür açıklamaları, referanslardan hiçbirinin ne kadar yaşayacağını değiştirmez. Aksine, ömürleri etkilemeden birden fazla referansın ömürlerinin birbirleriyle olan ilişkilerini tanımlarlar. Tıpkı imza bir jenerik tür parametresi belirttiğinde fonksiyonların herhangi bir türü kabul edebilmesi gibi, jenerik bir ömür parametresi belirterek fonksiyonlar herhangi bir ömre sahip referansları kabul edebilirler.
Ömür açıklamalarının biraz alışılmadık bir sözdizimi vardır: Ömür parametrelerinin adları bir kesme işaretiyle (') başlamalıdır ve genellikle tıpkı jenerik türler gibi tamamen küçük harflidir ve çok kısadır. Çoğu insan ilk ömür açıklaması için 'a ismini kullanır. Ömür parametresi açıklamalarını, bir referansın & işaretinden sonra, açıklama ile referansın türünü ayırmak için bir boşluk kullanarak yerleştiririz.
İşte bazı örnekler; ömür parametresi olmayan bir i32’ye referans, 'a adlı bir ömür parametresi olan bir i32’ye referans ve ayrıca 'a ömrüne sahip bir i32’ye değiştirilebilir bir referans:
&i32 // a reference (bir referans)
&'a i32 // a reference with an explicit lifetime (açık bir ömre sahip bir referans)
&'a mut i32 // a mutable reference with an explicit lifetime (açık bir ömre sahip değiştirilebilir bir referans)Tek başına bir ömür açıklaması çok fazla bir anlama sahip değildir, çünkü açıklamalar Rust’a birden fazla referansın jenerik ömür parametrelerinin birbiriyle nasıl ilişkili olduğunu söylemek içindir. en_uzun fonksiyonu bağlamında ömür açıklamalarının birbirleriyle nasıl ilişkilendiğini inceleyelim.
Fonksiyon İmzalarında (Function Signatures)
Fonksiyon imzalarında ömür açıklamalarını kullanmak için, tıpkı jenerik tür parametrelerinde yaptığımız gibi, fonksiyon adı ile parametre listesi arasındaki açılı ayraçlar içinde jenerik ömür parametrelerini bildirmemiz gerekir.
İmzanın şu kısıtlamayı ifade etmesini istiyoruz: Döndürülen referans, her iki parametre geçerli olduğu sürece geçerli olacaktır. Bu, parametrelerin ömürleri ve dönüş değeri arasındaki ilişkidir. Liste 10-21’de gösterildiği gibi ömre 'a adını vereceğiz ve sonra onu her referansa ekleyeceğiz.
fn main() {
let dizgi1 = String::from("abcd");
let dizgi2 = "xyz";
let sonuc = en_uzun(dizgi1.as_str(), dizgi2);
println!("En uzun dizgi: {sonuc}");
}
fn en_uzun<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}'a) sahip olması gerektiğini belirten en_uzun fonksiyonu tanımıBu kodu Liste 10-19’daki main fonksiyonu ile birlikte kullandığımızda kod derlenmeli ve istediğimiz sonucu üretmelidir.
Fonksiyon imzası şimdi Rust’a, bazı 'a ömürleri için fonksiyonun her ikisi de en az 'a ömrü kadar yaşayan string dilimleri olan iki parametre aldığını söyler. Fonksiyon imzası ayrıca Rust’a, fonksiyondan döndürülen string diliminin en az 'a ömrü kadar yaşayacağını söyler. Pratikte bu, en_uzun fonksiyonu tarafından döndürülen referansın ömrünün, fonksiyon argümanları tarafından atıfta bulunulan değerlerin ömürlerinden küçük olanıyla aynı olduğu anlamına gelir. Bu ilişkiler, Rust’ın bu kodu analiz ederken kullanmasını istediğimiz şeylerdir.
Unutmayın, bu fonksiyon imzasında ömür parametrelerini belirttiğimizde, aktarılan veya döndürülen hiçbir değerin ömrünü değiştirmiyoruz. Bunun yerine, ödünç alma denetleyicisinin bu kısıtlamalara uymayan değerleri reddetmesini gerektiğini belirtiyoruz. Unutmayın ki, en_uzun fonksiyonunun x ve y’nin tam olarak ne kadar yaşayacağını bilmesi gerekmez, sadece bu imzayı sağlayacak 'a için bir kapsamın yerine geçebileceğini bilmesi yeterlidir.
Fonksiyonlardaki ömürleri açıklarken, açıklamalar fonksiyonun gövdesine değil, fonksiyon imzasının içine girer. Ömür açıklamaları, imzadaki türlere çok benzer şekilde fonksiyonun sözleşmesinin bir parçası haline gelir. Fonksiyon imzalarının ömür sözleşmesini içermesi, Rust derleyicisinin yaptığı analizin daha basit olabileceği anlamına gelir. Bir fonksiyonun açıklanma şekli veya çağrılma şekli ile ilgili bir sorun varsa derleyici hataları, kodumuzun ilgili kısmına ve kısıtlamalara daha kesin bir şekilde işaret edebilir. Eğer Rust derleyicisi bunun yerine ömürlerin ilişkilerinin nasıl olmasını amaçladığımıza dair daha fazla çıkarsama yapsaydı, derleyici yalnızca kodumuzun kullanımına sorunun nedeninden çok uzakta olan bir noktada işaret edebilirdi.
Somut referansları en_uzun fonksiyonuna ilettiğimizde, 'a’nın yerine geçecek olan somut ömür, x’in kapsamının y’nin kapsamıyla örtüşen kısmıdır. Başka bir deyişle, jenerik ömür 'a, x ve y’nin ömürlerinin daha küçük olanına eşit somut ömrü alacaktır. Döndürülen referansı da aynı 'a ömür parametresiyle açıkladığımız için, döndürülen referans da x ve y ömürlerinden küçük olanın uzunluğu boyunca geçerli olacaktır.
Farklı somut ömürlere sahip referanslar ileterek ömür açıklamalarının en_uzun fonksiyonunu nasıl kısıtladığına bakalım. Liste 10-22 basit bir örnektir.
fn main() {
let dizgi1 = String::from("uzun dizgi uzundur");
{
let dizgi2 = String::from("xyz");
let sonuc = en_uzun(dizgi1.as_str(), dizgi2.as_str());
println!("En uzun dizgi: {sonuc}");
}
}
fn en_uzun<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}String değerlerine referanslarla en_uzun fonksiyonunu kullanmakBu örnekte, dizgi1 dış kapsamın sonuna kadar geçerlidir, dizgi2 iç kapsamın sonuna kadar geçerlidir ve sonuc iç kapsamın sonuna kadar geçerli olan bir şeye atıfta bulunur. Bu kodu çalıştırdığınızda, ödünç alma denetleyicisinin bunu onayladığını göreceksiniz; derlenecek ve En uzun dizgi: uzun dizgi uzundur yazdıracaktır.
Sırada, sonuc değişkenindeki referansın ömrünün iki argümanın daha küçük olanı olması gerektiğini gösteren bir örnek deneyelim. sonuc değişkeninin bildirimini iç kapsamın dışına taşıyacağız ancak sonuc değişkenine değer atamasını dizgi2 ile aynı kapsamın içinde bırakacağız. Ardından, sonuc kullanan println! makrosunu iç kapsam bittikten sonra iç kapsamın dışına taşıyacağız. Liste 10-23’teki kod derlenmeyecektir.
fn main() {
let dizgi1 = String::from("uzun dizgi uzundur");
let sonuc;
{
let dizgi2 = String::from("xyz");
sonuc = en_uzun(dizgi1.as_str(), dizgi2.as_str());
}
println!("En uzun dizgi: {sonuc}");
}
fn en_uzun<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}dizgi2 kapsam dışına çıktıktan sonra sonuc kullanmaya çalışmakBu kodu derlemeye çalıştığımızda şu hatayı alırız:
$ cargo run
Compiling bolum10 v0.1.0 ($PROJE/listings/ch10-generic-types-traits-and-lifetimes/listing-10-23)
error[E0597]: `dizgi2` does not live long enough
--> src/main.rs:7:42
|
6 | let dizgi2 = String::from("xyz");
| ------ binding `dizgi2` declared here
7 | sonuc = en_uzun(dizgi1.as_str(), dizgi2.as_str());
| ^^^^^^ borrowed value does not live long enough
8 | }
| - `dizgi2` dropped here while still borrowed
9 | println!("En uzun dizgi: {sonuc}");
| ----- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `bolum10` (bin "bolum10") due to 1 previous error
Hata sonuc değişkeninin println! ifadesi için geçerli olması için dizgi2’nin dış kapsamın sonuna kadar geçerli olması gerektiğini gösteriyor. Rust bunu biliyor çünkü fonksiyon parametrelerinin ve dönüş değerlerinin ömürlerini aynı 'a ömür parametresini kullanarak açıkladık.
İnsanlar olarak bizler bu koda bakıp dizgi1’in dizgi2’den daha uzun olduğunu ve dolayısıyla sonuc’un dizgi1’e bir referans içereceğini görebiliriz. dizgi1 henüz kapsam dışına çıkmadığı için, dizgi1’e yapılan bir referans println! ifadesi (statement) için hala geçerli olacaktır. Ancak derleyici bu durumda referansın geçerli olduğunu göremiyor. Biz Rust’a en_uzun fonksiyonu tarafından döndürülen referansın ömrünün, aktarılan referansların ömürlerinden daha küçük olanıyla aynı olduğunu söyledik. Bu nedenle, ödünç alma denetleyicisi, potansiyel olarak geçersiz bir referansa sahip olduğu gerekçesiyle Liste 10-23’teki koda izin vermez.
en_uzun fonksiyonuna iletilen referansların değerlerini ve ömürlerini ve döndürülen referansın nasıl kullanıldığını değiştiren daha fazla deney tasarlamayı deneyin. Derlemeden önce deneylerinizin ödünç alma denetleyicisini geçip geçmeyeceği hakkında hipotezler kurun; sonra haklı olup olmadığınızı görmek için kontrol edin!
İlişkiler (Relationships)
Ömür parametrelerini (lifetime parameters) belirtmeniz gereken yol, fonksiyonunuzun ne yaptığına bağlıdır. Örneğin, en_uzun fonksiyonunun uygulamasını her zaman en uzun string dilimi yerine ilk parametreyi döndürecek şekilde değiştirseydik, y parametresi üzerinde bir ömür belirtmemize gerek kalmazdı. Aşağıdaki kod derlenecektir:
fn main() {
let dizgi1 = String::from("abcd");
let dizgi2 = "efghijklmnopqrstuvwxyz";
let sonuc = en_uzun(dizgi1.as_str(), dizgi2);
println!("En uzun dizgi: {sonuc}");
}
fn en_uzun<'a>(x: &'a str, y: &str) -> &'a str {
x
}x parametresi ve dönüş türü için bir 'a ömür parametresi belirttik, ancak y parametresi için belirtmedik, çünkü y’nin ömrünün x’in ömrüyle veya dönüş değeriyle hiçbir ilişkisi yoktur.
Bir fonksiyondan bir referans döndürürken, dönüş türünün ömür parametresi parametrelerden birinin ömür parametresiyle eşleşmelidir. Döndürülen referans parametrelerden birine atıfta bulunmuyorsa, bu fonksiyon içinde oluşturulmuş bir değere atıfta bulunması gerekir. Ancak, değer fonksiyonun sonunda kapsam dışına çıkacağı için bu sarkan bir referans (dangling reference) olacaktır. en_uzun fonksiyonunun derlenmeyecek olan bu uygulama denemesini inceleyelim:
fn main() {
let dizgi1 = String::from("abcd");
let dizgi2 = "xyz";
let sonuc = en_uzun(dizgi1.as_str(), dizgi2);
println!("En uzun dizgi: {sonuc}");
}
fn en_uzun<'a>(x: &str, y: &str) -> &'a str {
let sonuc = String::from("gerçekten uzun dizgi");
sonuc.as_str()
}Burada, dönüş türü için bir 'a ömür parametresi belirtmiş olsak bile bu uygulama derlenemeyecektir, çünkü dönüş değerinin ömrünün parametrelerin ömrüyle hiçbir ilgisi yoktur. İşte aldığımız hata mesajı:
$ cargo run
Compiling bolum10 v0.1.0 ($PROJE/listings/ch10-generic-types-traits-and-lifetimes/no-listing-09-unrelated-lifetime)
error[E0515]: cannot return value referencing local variable `sonuc`
--> src/main.rs:12:5
|
12 | sonuc.as_str()
| -----^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `sonuc` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `bolum10` (bin "bolum10") due to 1 previous error; 2 warnings emitted
Sorun şu ki sonuc, en_uzun fonksiyonunun sonunda kapsam dışına çıkar ve temizlenir. Biz aynı zamanda fonksiyondan sonuc’a bir referans döndürmeye çalışıyoruz. Sarkan referansı (dangling reference) değiştirecek ömür parametrelerini belirtebilmemizin hiçbir yolu yoktur ve Rust sarkan bir referans oluşturmamıza izin vermeyecektir. Bu durumda en iyi düzeltme, çağıran fonksiyonun değeri temizlemekten sorumlu olabilmesi için bir referans yerine sahip olunan bir veri türü döndürmek olacaktır.
Nihayetinde, ömür sözdizimi fonksiyonların çeşitli parametrelerinin ve dönüş değerlerinin ömürlerini birbirine bağlamakla ilgilidir. Bunlar bağlandıktan sonra Rust, bellek açısından güvenli operasyonlara izin vermek ve sarkan işaretçiler oluşturacak veya bellek güvenliğini ihlal edecek operasyonları reddetmek için yeterli bilgiye sahip olur.
Struct (Yapı) Tanımlarında
Şimdiye kadar tanımladığımız struct’ların (yapıların) tümü sahip olunan türleri barındırıyordu. Struct’ları referansları barındıracak şekilde tanımlayabiliriz ancak bu durumda, struct’ın tanımındaki her referansa bir ömür açıklaması eklememiz gerekir. Liste 10-24’te, string dilimi tutan OnemliAlinti adlı bir struct bulunmaktadır.
struct OnemliAlinti<'a> {
bolum: &'a str,
}
fn main() {
let roman = String::from("Bana İsmail deyin. Birkaç yıl önce...");
let ilk_cumle = roman.split('.').next().unwrap();
let i = OnemliAlinti { bolum: ilk_cumle };
}Bu struct, referans olan bir string dilimi barındıran bolum adlı tek bir alana sahiptir. Jenerik veri türlerinde olduğu gibi, jenerik ömür parametresinin adını struct adından sonra açılı ayraçlar içinde bildiriyoruz, böylece struct tanımının gövdesinde ömür parametresini kullanabiliyoruz. Bu açıklama, bir OnemliAlinti örneğinin, bolum alanında tuttuğu referanstan daha uzun yaşayamayacağı anlamına gelir.
Buradaki main fonksiyonu, roman değişkenine ait olan String’in ilk cümlesine referans tutan bir OnemliAlinti struct’ı örneği yaratır. roman’daki veri, OnemliAlinti örneği yaratılmadan önce de mevcuttur. Dahası, roman ancak OnemliAlinti kapsam dışına çıktıktan sonra kapsam dışına çıkar, bu nedenle OnemliAlinti örneğindeki referans geçerlidir.
Ömür Düşürülmesi (Lifetime Elision)
Her referansın bir ömrü olduğunu ve referansları kullanan fonksiyonlar veya struct’lar için ömür parametrelerini belirtmeniz gerektiğini öğrendiniz. Ancak Liste 4-9’da sahip olduğumuz ve Liste 10-25’te yeniden gösterilen bir fonksiyon, parametre ve dönüş türü referans olmasına rağmen ömür açıklamaları olmadan derlendi.
fn ilk_kelime(s: &str) -> &str {
let baytlar = s.as_bytes();
for (i, &oge) in baytlar.iter().enumerate() {
if oge == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let benim_dizgim = String::from("merhaba dünya");
// ilk_kelime `String`lerin dilimleri üzerinde çalışır
let kelime = ilk_kelime(&benim_dizgim[..]);
let benim_dizgi_sabitim = "merhaba dünya";
// ilk_kelime string sabitlerinin dilimleri üzerinde çalışır
let kelime = ilk_kelime(&benim_dizgi_sabitim[..]);
// String sabitleri *zaten* string dilimi olduğundan,
// bu dilim sözdizimi olmadan da çalışır!
let kelime = ilk_kelime(benim_dizgi_sabitim);
}Bu fonksiyonun ömür açıklamaları olmadan derlenmesinin nedeni tarihseldir: Rust’ın ilk sürümlerinde (1.0 öncesi) bu kod derlenemezdi, çünkü her referansın açık bir ömre ihtiyacı vardı. O zamanlar, fonksiyon imzası şöyle yazılırdı:
fn ilk_kelime<'a>(s: &'a str) -> &'a str {Pek çok Rust kodu yazdıktan sonra Rust ekibi, Rust programcılarının belirli durumlarda aynı ömür açıklamalarını defalarca girdiğini fark etti. Bu durumlar öngörülebilirdi ve birkaç deterministik (belirlenimci) deseni (pattern) izliyordu. Geliştiriciler bu desenleri derleyicinin koduna programladılar, böylece ödünç alma denetleyicisi bu durumlardaki ömürleri çıkarabilirdi ve açık açıklamalara ihtiyaç duymazdı.
Rust tarihinin bu parçası önemlidir çünkü daha deterministik desenlerin ortaya çıkması ve derleyiciye eklenmesi mümkündür. Gelecekte, daha da az ömür açıklaması gerekebilir.
Rust’ın referansları analizine programlanan desenlere ömür düşürülmesi kuralları denir. Bunlar programcıların izlemesi gereken kurallar değildir; derleyicinin dikkate alacağı bir dizi özel durumdur ve eğer kodunuz bu durumlara uyuyorsa ömürleri açıkça yazmanız gerekmez.
Elizyon (düşürülme / elision) kuralları tam bir çıkarım sağlamaz. Rust kuralları uyguladıktan sonra referansların sahip olduğu ömürler hakkında hala bir belirsizlik varsa, derleyici kalan referansların ömrünün ne olması gerektiğini tahmin etmeyecektir. Tahmin etmek yerine derleyici size bir hata verir ve siz de ömür açıklamalarını ekleyerek bu hatayı çözebilirsiniz.
Fonksiyon veya metot parametrelerindeki ömürlere girdi ömürleri ve dönüş değerlerindeki ömürlere çıktı ömürleri denir.
Derleyici, açık açıklamaların olmadığı durumlarda referansların ömürlerini bulmak için üç kural kullanır. İlk kural girdi ömürleri için, ikinci ve üçüncü kurallar ise çıktı ömürleri için geçerlidir. Derleyici üç kuralın sonuna gelir ve hala ömürlerini çözemediği referanslar kalırsa, derleyici bir hata vererek durur. Bu kurallar fn (fonksiyon) tanımlarının yanı sıra impl blokları için de geçerlidir.
İlk kural, derleyicinin referans olan her parametreye bir ömür parametresi atamasıdır. Başka bir deyişle, bir parametreye sahip olan bir fonksiyon bir ömür parametresi alır: fn foo<'a>(x: &'a i32); iki parametresi olan bir fonksiyon iki ayrı ömür parametresi alır: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); ve bu böyle devam eder.
İkinci kural, eğer sadece bir girdi ömrü parametresi varsa, o ömrün tüm çıktı ömür parametrelerine atanmasıdır: fn foo<'a>(x: &'a i32) -> &'a i32.
Üçüncü kural ise şudur: Birden fazla girdi ömür parametresi varsa, ancak bu bir metot olduğu için içlerinden biri &self veya &mut self ise, tüm çıktı ömür parametrelerine self’in ömrü atanır. Bu üçüncü kural, daha az sembol gerektirdiği için metotları okumayı ve yazmayı çok daha güzel hale getirir.
Hadi kendimizi derleyici yerine koyalım. Liste 10-25’teki ilk_kelime fonksiyonunun imzasındaki referansların ömürlerini bulmak için bu kuralları uygulayacağız. İmza, referanslarla ilişkilendirilmiş herhangi bir ömür olmadan başlar:
fn ilk_kelime(s: &str) -> &str {Ardından, derleyici her parametrenin kendi ömrünü almasını belirten ilk kuralı uygular. Her zamanki gibi buna 'a diyeceğiz, bu yüzden imza artık şu şekildedir:
fn ilk_kelime<'a>(s: &'a str) -> &str {İkinci kural uygulanır çünkü tam olarak bir tane girdi ömrü (input lifetime) vardır. İkinci kural, bir girdi parametresinin ömrünün çıktı ömrüne atandığını belirtir, bu yüzden imza artık şu şekildedir:
fn ilk_kelime<'a>(s: &'a str) -> &'a str {Artık bu fonksiyon imzasındaki tüm referansların ömürleri var ve derleyici, programcının bu fonksiyon imzasındaki ömürleri açıklamasına ihtiyaç duymadan analizine devam edebilir.
Başka bir örneğe bakalım, bu kez Liste 10-20’de çalışmaya başladığımızda hiçbir ömür parametresi olmayan en_uzun fonksiyonunu kullanalım:
fn en_uzun(x: &str, y: &str) -> &str {İlk kuralı uygulayalım: Her parametre kendi ömrüne sahip olur. Bu sefer bir yerine iki parametremiz var, yani iki ömrümüz var:
fn en_uzun<'a, 'b>(x: &'a str, y: &'b str) -> &str {Birden fazla girdi ömrü olduğu için ikinci kuralın geçerli olmadığını görebilirsiniz. en_uzun bir metot yerine bir fonksiyon olduğu için üçüncü kural da geçerli değildir, dolayısıyla parametrelerden hiçbiri self değildir. Üç kuralın hepsini denedikten sonra, hala dönüş türünün ömrünün ne olduğunu çözemedik. Liste 10-20’deki kodu derlemeye çalışırken hata almamızın nedeni budur: Derleyici ömür elizyonu kurallarını işletmiş ancak yine de imzadaki referansların tüm ömürlerini çözememiştir.
Üçüncü kural gerçekten sadece metot imzalarında geçerli olduğu için, üçüncü kuralın neden metot imzalarında ömürleri çok sık açıklamak zorunda olmadığımız anlamına geldiğini görmek için sonraki adımda bu bağlamdaki ömürlere bakacağız.
Metot Tanımlarında (Method Definitions)
Ömürlere sahip bir struct (yapı) üzerinde metotlar uyguladığımızda, Liste 10-11’de gösterildiği gibi jenerik tür parametreleriyle aynı sözdizimini kullanırız. Ömür parametrelerini nerede beyan edip kullanacağımız, bunların struct’ın (yapının) alanlarıyla (fields) mı yoksa metot parametreleri ve dönüş değerleriyle mi ilgili olduğuna bağlıdır.
Struct alanları (fields) için ömür isimlerinin her zaman impl anahtar kelimesinden sonra beyan edilmesi ve daha sonra struct isminden sonra kullanılması gerekir çünkü bu ömürler struct türünün bir parçasıdır.
impl bloğunun içindeki metot imzalarında, referanslar struct’ın alanlarındaki referansların ömrüne bağlı olabilir veya bağımsız olabilirler. Ek olarak, ömür elizyonu kuralları genellikle metot imzalarında ömür açıklamalarının gerekli olmamasını sağlar. Liste 10-24’te tanımladığımız OnemliAlinti adlı struct’ı kullanarak bazı örneklere bakalım.
İlk olarak, tek parametresi self’e olan bir referans olan ve hiçbir şeye referans olmayan bir i32 döndüren seviye adında bir metot kullanacağız:
struct OnemliAlinti<'a> {
bolum: &'a str,
}
impl<'a> OnemliAlinti<'a> {
fn seviye(&self) -> i32 {
3
}
}
impl<'a> OnemliAlinti<'a> {
fn duyur_ve_bolumu_dondur(&self, duyuru: &str) -> &str {
println!("Lütfen dikkat: {duyuru}");
self.bolum
}
}
fn main() {
let roman = String::from("Bana İsmail deyin. Birkaç yıl önce...");
let ilk_cumle = roman.split('.').next().unwrap();
let i = OnemliAlinti { bolum: ilk_cumle };
}Ömür parametresinin impl sonrasında beyan edilmesi ve tür adından sonra kullanılması gereklidir, ancak birinci elizyon kuralı nedeniyle, self’e olan referansın ömrünü açıklamak zorunda değiliz.
İşte üçüncü ömür elizyon kuralının geçerli olduğu bir örnek:
struct OnemliAlinti<'a> {
bolum: &'a str,
}
impl<'a> OnemliAlinti<'a> {
fn seviye(&self) -> i32 {
3
}
}
impl<'a> OnemliAlinti<'a> {
fn duyur_ve_bolumu_dondur(&self, duyuru: &str) -> &str {
println!("Lütfen dikkat: {duyuru}");
self.bolum
}
}
fn main() {
let roman = String::from("Bana İsmail deyin. Birkaç yıl önce...");
let ilk_cumle = roman.split('.').next().unwrap();
let i = OnemliAlinti { bolum: ilk_cumle };
}İki girdi ömrü vardır, bu yüzden Rust birinci ömür elizyon kuralını uygular ve hem &self hem de duyuru’ya kendi ömürlerini verir. Ardından, parametrelerden biri &self olduğundan, dönüş türü &self’in ömrünü alır ve tüm ömürler hesaba katılmış olur.
Statik Ömür (The Static Lifetime)
Tartışmamız gereken özel ömürlerden biri de, etkilenen referansın programın tüm süresi boyunca yaşayabileceğini ifade eden 'static’tir. Tüm string (dizgi) sabitleri 'static ömre sahiptir ve bunu aşağıdaki gibi açıklayabiliriz:
#![allow(unused)]
fn main() {
let s: &'static str = "Statik bir ömrüm var.";
}Bu string’in metni doğrudan her zaman erişilebilir olan programın ikili dosyasına depolanır. Bu nedenle, tüm string sabitlerinin ömrü 'static’tir.
Hata mesajlarında 'static ömrünü kullanmanız yönünde öneriler görebilirsiniz. Ancak bir referans için ömür olarak 'static belirtmeden önce, sahip olduğunuz referansın gerçekten programınızın tüm ömrü boyunca yaşayıp yaşamadığını ve yaşamasını isteyip istemediğinizi düşünün. Çoğu zaman, 'static ömrünü öneren bir hata mesajı, sarkan bir referans (dangling reference) oluşturmaya teşebbüs etmekten veya mevcut ömürlerin uyumsuzluğundan kaynaklanır. Bu gibi durumlarda çözüm, 'static ömrünü belirtmek değil, o sorunları çözmektir.
Jenerik Tür Parametreleri, Trait Sınırları ve Ömürler Bir Arada
Jenerik tür parametrelerini, trait sınırlarını ve ömürleri tek bir fonksiyonda belirleme sözdizimine kısaca göz atalım!
fn main() {
let dizgi1 = String::from("abcd");
let dizgi2 = "xyz";
let sonuc =
duyuruyla_en_uzun(dizgi1.as_str(), dizgi2, "Bugün birinin doğum günü!");
println!("En uzun dizgi: {sonuc}");
}
use std::fmt::Display;
fn duyuruyla_en_uzun<'a, T>(x: &'a str, y: &'a str, dyr: T) -> &'a str
where
T: Display,
{
println!("Duyuru! {dyr}");
if x.len() > y.len() {
x
} else {
y
}
}Bu, Liste 10-21’deki iki string (dizgi) diliminden daha uzun olanını döndüren en_uzun fonksiyonudur. Ancak şimdi, where cümleciğinde belirtildiği gibi Display trait’ini uygulayan herhangi bir türle doldurulabilen T jenerik türünde dyr adında fazladan bir parametreye sahip. Bu ekstra parametre {} kullanılarak yazdırılacaktır, bu nedenle Display trait sınırı (trait bound) gereklidir. Ömürler bir jenerik türü olduğundan, 'a ömür parametresi ve T jenerik tür parametresinin bildirimleri fonksiyon adından sonraki açılı ayraçlar içinde aynı listede yer alır.
Özet
Bu bölümde birçok konuyu ele aldık! Artık jenerik tür parametreleri (generic type parameters), traitler ve trait sınırları ve jenerik ömür parametreleri hakkında bilgi sahibi olduğunuza göre, pek çok farklı durumda çalışan kodları tekrar etmeden yazmaya hazırsınız. Jenerik tür parametreleri kodu farklı türlere uygulamanızı sağlar. Traitler ve trait sınırları, türler jenerik olsa bile, kodun ihtiyaç duyduğu davranışa sahip olacaklarını garanti eder. Bu esnek kodun sarkan (dangling) herhangi bir referansa sahip olmamasını sağlamak için ömür açıklamalarını nasıl kullanacağınızı öğrendiniz. Ve tüm bu analizler derleme zamanında gerçekleşir, yani çalışma zamanı performansını etkilemez!
İnanın ya da inanmayın, bu bölümde tartıştığımız konularda öğrenilecek daha çok şey var: Bölüm 18, traitleri kullanmanın başka bir yolu olan trait nesnelerini (trait objects) tartışıyor. Ayrıca, yalnızca çok gelişmiş senaryolarda ihtiyaç duyacağınız ömür açıklamalarını içeren daha karmaşık senaryolar da vardır; bunlar için Rust Referansını (Rust Reference) okumalısınız. Ancak sırada, kodunuzun olması gerektiği gibi çalıştığından emin olabilmek için Rust’ta nasıl test yazacağınızı öğreneceksiniz.
Otomatik Testler Yazmak
1972 tarihli “Mütevazı Programcı (The Humble Programmer)” adlı makalesinde Edsger W. Dijkstra, “program test etmenin hataların varlığını göstermenin çok etkili bir yolu olabileceğini, ancak bunların yokluğunu göstermek konusunda umutsuzca yetersiz olduğunu” söylemiştir. Bu, elimizden geldiğince çok test yapmaya çalışmamamız gerektiği anlamına gelmez!
Programlarımızdaki doğruluk, kodumuzun amaçladığımız şeyi yapma ölçüsüdür. Rust, programların doğruluğu hakkında yüksek derecede endişe duyularak tasarlanmıştır, ancak doğruluğun kanıtlanması karmaşıktır ve kolay değildir. Rust’ın tür sistemi bu yükün büyük bir kısmını üstlenir, ancak tür sistemi her şeyi yakalayamaz. Bu nedenle Rust, otomatik yazılım testleri yazmak için destek içerir.
Kendisine iletilen sayıya 2 ekleyen bir iki_ekle fonksiyonu yazdığımızı varsayalım. Bu fonksiyonun imzası, parametre olarak bir tamsayı kabul eder ve sonuç olarak bir tamsayı döndürür. Bu fonksiyonu uygulayıp derlediğimizde Rust, örneğin bu fonksiyona bir String değeri veya geçersiz bir referans iletmediğimizden emin olmak için şimdiye kadar öğrendiğiniz tüm tür denetimini ve ödünç alma denetimini yapar. Ancak Rust bu fonksiyonun tam olarak bizim amaçladığımız şeyi yapıp yapmadığını, yani örneğin parametreye 10 eklemek veya parametreden 50 çıkarmak yerine parametreye 2 ekleyip eklemediğini kontrol edemez! İşte testler burada devreye girer.
Örneğin iki_ekle fonksiyonuna 3 ilettiğimizde dönen değerin 5 olduğunu doğrulayan testler yazabiliriz. Kodumuzda değişiklik yaptığımızda, mevcut doğru davranışın değişmediğinden emin olmak için bu testleri çalıştırabiliriz.
Test yazmak karmaşık bir beceridir: Bir bölümde iyi testlerin nasıl yazılacağına dair her ayrıntıyı ele alamayacak olsak da, bu bölümde Rust’ın test araçlarının mekaniklerini tartışacağız. Testlerinizi yazarken kullanabileceğiniz açıklamalar ve makrolar, testlerinizi çalıştırmak için sağlanan varsayılan davranışlar ve seçenekler ile testlerin birim testleri ve entegrasyon testleri olarak nasıl organize edileceği hakkında konuşacağız.
Nasıl Test Yazılır
Testler Nasıl Yazılır
Testler, test olmayan kodun beklenen şekilde çalışıp çalışmadığını doğrulayan Rust fonksiyonlarıdır. Test fonksiyonlarının gövdeleri tipik olarak şu üç eylemi gerçekleştirir:
- İhtiyaç duyulan verileri veya durumu ayarlamak.
- Test etmek istediğiniz kodu çalıştırmak.
- Sonuçların beklediğiniz gibi olduğunu doğrulamak.
Rust’ın bu eylemleri gerçekleştiren testler yazmak için özel olarak sağladığı ve test özniteliği (attribute), birkaç makro ve should_panic (paniklemeli) özniteliği gibi özellikleri inceleyelim.
Test Fonksiyonlarını Yapılandırmak
En basit haliyle, Rust’ta bir test, test özniteliğiyle açıklanmış (annotated) bir fonksiyondur. Öznitelikler (attributes) Rust kodunun parçaları hakkındaki meta verilerdir; Bölüm 5’te struct’larla kullandığımız derive özniteliği buna bir örnektir. Bir fonksiyonu test fonksiyonuna dönüştürmek için, fn’den önceki satıra #[test] ekleyin. Testlerinizi cargo test komutuyla çalıştırdığınızda Rust, açıklanmış (annotated) fonksiyonları çalıştıran ve her bir test fonksiyonunun geçip geçmediğini veya başarısız olup olmadığını bildiren bir test çalıştırıcı ikili dosyası oluşturur.
Cargo ile yeni bir kütüphane projesi oluşturduğumuzda, içinde bir test fonksiyonu bulunan bir test modülü bizim için otomatik olarak üretilir. Bu modül size testlerinizi yazmanız için bir şablon sunar, böylece her yeni projeye başladığınızda tam yapıyı ve sözdizimini araştırmak zorunda kalmazsınız. İstediğiniz kadar ek test fonksiyonu ve test modülü ekleyebilirsiniz!
Testlerin nasıl çalıştığına dair bazı yönleri, aslında herhangi bir kodu test etmeden önce şablon testiyle deneyler yaparak keşfedeceğiz. Ardından, yazdığımız bazı kodları çağıran ve davranışının doğru olduğunu doğrulayan gerçek dünya testleri yazacağız.
İki sayıyı toplayacak adder (toplayıcı) adında yeni bir kütüphane projesi oluşturalım:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
adder kütüphanenizdeki src/lib.rs dosyasının içeriği Liste 11-1’deki gibi görünmelidir.
pub fn topla(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn calisiyor() {
let sonuc = topla(2, 2);
assert_eq!(sonuc, 4);
}
}cargo new tarafından otomatik olarak üretilen kodDosya örnek bir add (topla) fonksiyonuyla başlar, böylece test edecek bir şeyimiz olur.
Şimdilik yalnızca calisiyor fonksiyonuna odaklanalım. #[test] açıklamasına dikkat edin: Bu öznitelik bunun bir test fonksiyonu olduğunu belirtir, böylece test çalıştırıcısı bu fonksiyonu bir test olarak ele alacağını bilir. Ortak senaryolar kurmaya veya ortak işlemleri gerçekleştirmeye yardımcı olması için tests modülünde test olmayan fonksiyonlarımız da olabilir, bu nedenle her zaman hangi fonksiyonların test olduğunu belirtmemiz gerekir.
Örnek fonksiyon gövdesi, 2 ile 2’yi toplama fonksiyonunun çağrılmasının sonucunu içeren sonuc’un 4’e eşit olduğunu doğrulamak için assert_eq! makrosunu kullanır. Bu doğrulama (assertion), tipik bir testin formatı için bir örnek görevi görür. Bu testin geçtiğini görmek için çalıştıralım.
cargo test komutu Liste 11-2’de gösterildiği gibi projemizdeki tüm testleri çalıştırır.
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/listing-11-07)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::iki_ekliyor ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo testi derledi ve çalıştırdı. running 1 test (1 test çalıştırılıyor) satırını görüyoruz. Sonraki satırda tests::calisiyor adlı oluşturulan test fonksiyonunun adı ve o testi çalıştırmanın sonucunun ok (tamam) olduğu gösterilir. test result: ok. (test sonucu: tamam.) genel özeti tüm testlerin geçtiği anlamına gelir ve 1 passed; 0 failed (1 geçti; 0 başarısız oldu) yazan kısım geçen veya başarısız olan testlerin toplam sayısını verir.
Bir testi yok sayıldı olarak işaretlemek mümkündür, böylece belirli bir örnekte çalışmaz; bunu bu bölümün ilerleyen kısımlarında “Açıkça İstenmedikçe Testleri Yok Saymak” kısmında ele alacağız. Bunu burada yapmadığımız için özet 0 ignored (0 yoksayıldı) şeklinde gösterilir. Ayrıca cargo test komutuna yalnızca adı bir string (dizgi) ile eşleşen testleri çalıştırmak için bir argüman da iletebiliriz; buna filtreleme denir ve bunu “Testlerin Bir Alt Kümesini İsme Göre Çalıştırmak” bölümünde ele alacağız. Burada, çalıştırılan testleri filtrelemedik, bu nedenle özetin sonunda 0 filtered out (0 filtrelendi) yazar.
0 measured (0 ölçüldü) istatistiği performansı ölçen kıyaslama testleri içindir. Kıyaslama testleri, bu yazının yazıldığı sırada yalnızca Rust’ın gecelik (nightly) sürümünde kullanılabilir. Daha fazlasını öğrenmek için kıyaslama testleri hakkındaki belgelere bakın.
Test çıktısının Doc-tests adder ile başlayan bir sonraki bölümü dokümantasyon testlerinin sonuçları içindir. Henüz hiçbir dokümantasyon testimiz yok, ancak Rust, API dokümantasyonumuzda görünen herhangi bir kod örneğini derleyebilir. Bu özellik, dokümanlarınızı ve kodunuzu senkronize tutmanıza yardımcı olur! Dokümantasyon testlerinin nasıl yazılacağını Bölüm 14’teki “Test Olarak Dokümantasyon Yorumları” kısmında tartışacağız. Şimdilik Doc-tests çıktısını görmezden geleceğiz.
Testi kendi ihtiyaçlarımıza göre özelleştirmeye başlayalım. İlk olarak, calisiyor fonksiyonunun adını farklı bir adla, örneğin şu şekilde kesif olarak değiştirin:
Dosya adı: src/lib.rs
pub fn topla(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn kesif() {
let sonuc = topla(2, 2);
assert_eq!(sonuc, 4);
}
}Ardından, cargo test’i tekrar çalıştırın. Çıktı artık calisiyor yerine kesif’i gösteriyor:
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/no-listing-01-changing-test-name)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::kesif ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Şimdi başka bir test daha ekleyeceğiz, ama bu sefer başarısız olan bir test yapacağız! Test fonksiyonundaki bir şey paniklediğinde testler başarısız olur. Her test yeni bir iş parçacığında çalıştırılır ve ana iş parçacığı bir test iş parçacığının öldüğünü gördüğünde test başarısız olarak işaretlenir. Bölüm 9’da, panik yapmanın en basit yolunun panic! makrosunu çağırmak olduğundan bahsetmiştik. Yeni testi baska_bir_test adında bir fonksiyon olarak girin, böylece src/lib.rs dosyanız Liste 11-3’teki gibi görünür.
pub fn topla(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn kesif() {
let sonuc = topla(2, 2);
assert_eq!(sonuc, 4);
}
#[test]
fn baska_bir_test() {
panic!("Bu testi başarısız yap");
}
}panic! makrosunu çağırdığımız için başarısız olacak ikinci bir test eklemekcargo test komutunu kullanarak testleri tekrar çalıştırın. Çıktı Liste 11-4’teki gibi görünmeli ve kesif testimizin geçtiğini, baska_bir_test’in ise başarısız olduğunu göstermelidir.
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/listing-11-03)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.08s
Running unittests src/lib.rs ($PROJE/listings/ch11-writing-automated-tests/listing-11-03/target/debug/deps/toplayici-ac13090f6eeacc92)
running 2 tests
test tests::kesif ... ok
test tests::baska_bir_test ... FAILED
failures:
---- tests::baska_bir_test stdout ----
thread 'tests::baska_bir_test' (84265) panicked at src/lib.rs:17:9:
Bu testi başarısız yap
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::baska_bir_test
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bireysel sonuçlar (individual results) ile özet arasında iki yeni bölüm görünür: test tests::baska_bir_test satırı ok yerine FAILED (BAŞARISIZ) gösterir. İlk yeni bölüm, her bir test başarısızlığının ayrıntılı nedenini görüntüler. Bu durumda, tests::baska_bir_test’in src/lib.rs dosyasındaki 17. satırda Bu testi başarısız yap (Make this test fail) mesajıyla paniklediği için başarısız olduğu detaylarını alıyoruz. Sonraki bölümde sadece başarısız olan tüm testlerin adları listelenir ki bu da çok sayıda test ve çok sayıda ayrıntılı başarısız test çıktısı olduğunda kullanışlıdır. Daha kolay hata ayıklamak amacıyla yalnızca o testi çalıştırmak için başarısız olan bir testin adını kullanabiliriz; testleri çalıştırmanın yolları hakkında “Testlerin Nasıl Çalıştırılacağını Kontrol Etme” bölümünde daha fazla konuşacağız.
Özet satırı en sonda görüntülenir: Genel olarak, test sonucumuz FAILED (BAŞARISIZ)’dır. Bir testimiz geçti ve bir testimiz başarısız oldu.
Farklı senaryolarda test sonuçlarının neye benzediğini gördüğünüze göre, testlerde yararlı olan panic! dışındaki bazı makrolara bakalım.
assert! ile Sonuçları Kontrol Etmek
Standart kütüphane tarafından sağlanan assert! makrosu, bir testteki bazı koşulların true (doğru) olarak değerlendirilmesini sağlamak istediğinizde yararlıdır. assert! makrosuna bir Boolean (mantıksal değer) olarak değerlendirilen bir argüman veririz. Eğer değer true ise hiçbir şey olmaz ve test geçer. Değer false (yanlış) ise, assert! makrosu testin başarısız olmasına neden olmak için panic! çağırır. assert! makrosunu kullanmak, kodumuzun amaçladığımız şekilde çalışıp çalışmadığını kontrol etmemize yardımcı olur.
Bölüm 5, Liste 5-15’te, burada Liste 11-5’te tekrarlanan bir Dikdortgen yapısı (struct) ve bir tutabilir_mi metodu kullandık. Gelin bu kodu src/lib.rs dosyasına koyalım ve ardından assert! makrosunu kullanarak bunun için bazı testler yazalım.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn tutabilir_mi(&self, diger: &Dikdortgen) -> bool {
self.genislik > diger.genislik && self.yukseklik > diger.yukseklik
}
}Dikdortgen struct’ı ve tutabilir_mi metodututabilir_mi metodu bir Boolean döndürür, bu da assert! makrosu için mükemmel bir kullanım durumu olduğu anlamına gelir. Liste 11-6’da, genişliği 8 ve yüksekliği 7 olan bir Dikdortgen örneği oluşturarak ve onun genişliği 5 ve yüksekliği 1 olan başka bir Dikdortgen örneğini tutabildiğini (hold) doğrulayarak (asserting) tutabilir_mi metodunu uygulayan (exercises) bir test yazıyoruz.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn tutabilir_mi(&self, diger: &Dikdortgen) -> bool {
self.genislik > diger.genislik && self.yukseklik > diger.yukseklik
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn buyuk_kucugu_tutabilir_mi() {
let buyuk = Dikdortgen {
genislik: 8,
yukseklik: 7,
};
let kucuk = Dikdortgen {
genislik: 5,
yukseklik: 1,
};
assert!(buyuk.tutabilir_mi(&kucuk));
}
}tutabilir_mi için bir testtests modülünün içindeki use super::*; satırına dikkat edin. tests modülü, Bölüm 7’de “Modül Ağacındaki Bir Öğeye Atıfta Bulunmak İçin Yollar” kısmında ele aldığımız olağan görünürlük (visibility) kurallarını izleyen normal bir modüldür. tests modülü bir iç modül (inner module) olduğu için, dış modülde (outer module) test edilen kodu iç modülün kapsamına getirmemiz gerekir. Burada bir glob kullanıyoruz, böylece dış modülde tanımladığımız her şey bu tests modülü tarafından kullanılabilir (available) olur.
Testimizi buyuk_kucugu_tutabilir_mi olarak adlandırdık ve ihtiyacımız olan iki Dikdortgen örneğini oluşturduk. Ardından, assert! makrosunu çağırdık ve ona buyuk.tutabilir_mi(&kucuk) (larger.can_hold(&smaller)) çağrısının sonucunu geçtik (passed). Bu ifadenin true döndürmesi varsayılır, bu yüzden testimiz geçmelidir. Hadi öğrenelim!
$ cargo test
Compiling rectangle v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/listing-11-06)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.12s
Running unittests src/lib.rs (target/debug/deps/rectangle-6014e2d502513b6d)
running 1 test
test tests::buyuk_kucugu_tutabilir_mi ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Geçiyor! Haydi başka bir test ekleyelim, bu sefer daha küçük bir dikdörtgenin daha büyük bir dikdörtgeni tutamayacağını doğrulayalım:
Dosya adı: src/lib.rs
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
impl Dikdortgen {
fn tutabilir_mi(&self, diger: &Dikdortgen) -> bool {
self.genislik > diger.genislik && self.yukseklik > diger.yukseklik
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn buyuk_kucugu_tutabilir_mi() {
// --snip--
let buyuk = Dikdortgen {
genislik: 8,
yukseklik: 7,
};
let kucuk = Dikdortgen {
genislik: 5,
yukseklik: 1,
};
assert!(buyuk.tutabilir_mi(&kucuk));
}
#[test]
fn kucuk_buyugu_tutamaz() {
let buyuk = Dikdortgen {
genislik: 8,
yukseklik: 7,
};
let kucuk = Dikdortgen {
genislik: 5,
yukseklik: 1,
};
assert!(!kucuk.tutabilir_mi(&buyuk));
}
}Bu durumda tutabilir_mi fonksiyonunun doğru sonucu false (yanlış) olduğundan, assert! makrosuna iletmeden önce bu sonucu değillememiz (negate) gerekir. Sonuç olarak, tutabilir_mi false döndürürse testimiz geçecektir:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::buyuk_kucugu_tutabilir_mi ... ok
test tests::kucuk_buyugu_tutamaz ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Geçen iki test! Şimdi kodumuza bir hata (bug) eklediğimizde test sonuçlarımıza ne olacağını görelim. Genişlikleri (widths) karşılaştırırken büyüktür işaretini (>) küçüktür işaretiyle (<) değiştirerek tutabilir_mi metodunun uygulamasını değiştireceğiz:
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
// --snip--
impl Dikdortgen {
fn tutabilir_mi(&self, diger: &Dikdortgen) -> bool {
self.genislik < diger.genislik && self.yukseklik > diger.yukseklik
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn buyuk_kucugu_tutabilir_mi() {
let buyuk = Dikdortgen {
genislik: 8,
yukseklik: 7,
};
let kucuk = Dikdortgen {
genislik: 5,
yukseklik: 1,
};
assert!(buyuk.tutabilir_mi(&kucuk));
}
#[test]
fn kucuk_buyugu_tutamaz() {
let buyuk = Dikdortgen {
genislik: 8,
yukseklik: 7,
};
let kucuk = Dikdortgen {
genislik: 5,
yukseklik: 1,
};
assert!(!kucuk.tutabilir_mi(&buyuk));
}
}Testleri şimdi çalıştırmak şunları üretir:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::buyuk_kucugu_tutabilir_mi ... FAILED
test tests::kucuk_buyugu_tutamaz ... ok
failures:
---- tests::buyuk_kucugu_tutabilir_mi stdout ----
thread 'tests::buyuk_kucugu_tutabilir_mi' panicked at src/lib.rs:28:9:
assertion failed: buyuk.tutabilir_mi(&kucuk)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::buyuk_kucugu_tutabilir_mi
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Testlerimiz hatayı yakaladı! buyuk.genislik (larger.width) 8 ve kucuk.genislik (smaller.width) 5 olduğu için, tutabilir_mi içindeki genişliklerin (widths) karşılaştırması artık false döndürür: 8, 5’ten küçük değildir.
assert_eq! ve assert_ne! Makroları ile Eşitliği Test Etmek
İşlevselliği doğrulamanın yaygın bir yolu, test edilen kodun sonucu ile kodun döndürmesini beklediğiniz değer arasında eşitlik testi yapmaktır. Bunu assert! makrosunu kullanarak ve ona == operatörü ile bir ifade ileterek yapabilirsiniz. Ancak bu o kadar yaygın bir testtir ki, standart kütüphane bu testi daha rahat gerçekleştirmek için bir çift makro (assert_eq! ve assert_ne!) sağlar. Bu makrolar sırasıyla iki argümanı eşitlik veya eşitsizlik açısından karşılaştırır. Doğrulama başarısız olursa iki değeri de yazdırırlar ki bu da testin neden başarısız olduğunu görmeyi kolaylaştırır; buna karşılık assert! makrosu false değerine yol açan değerleri yazdırmadan yalnızca == ifadesi için false değerini aldığını belirtir.
Liste 11-7’de parametresine 2 ekleyen iki_ekle adında bir fonksiyon yazıyoruz ve ardından bu fonksiyonu assert_eq! makrosunu kullanarak test ediyoruz.
pub fn iki_ekle(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn iki_ekliyor() {
let sonuc = iki_ekle(2);
assert_eq!(sonuc, 4);
}
}assert_eq! makrosunu kullanarak iki_ekle fonksiyonunu test etmekGeçip geçmediğini kontrol edelim!
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/listing-11-07)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::iki_ekliyor ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
iki_ekle(2) çağrısının sonucunu tutan sonuc adında bir değişken oluşturuyoruz. Ardından assert_eq! makrosuna argüman olarak sonuc ve 4’ü geçiriyoruz. Bu test için çıktı satırı test tests::iki_ekliyor ... ok şeklindedir ve ok (tamam) metni testimizin geçtiğini gösterir!
assert_eq!’in başarısız olduğunda nasıl göründüğünü görmek için kodumuza bir hata (bug) ekleyelim. iki_ekle fonksiyonunun uygulamasını 3 ekleyecek şekilde değiştirin:
pub fn iki_ekle(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn iki_ekliyor() {
let sonuc = iki_ekle(2);
assert_eq!(sonuc, 4);
}
}Testleri tekrar çalıştırın:
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/no-listing-04-bug-in-add-two)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::iki_ekliyor ... FAILED
failures:
---- tests::iki_ekliyor stdout ----
thread 'tests::iki_ekliyor' (86516) panicked at src/lib.rs:14:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::iki_ekliyor
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Testimiz hatayı yakaladı! tests::iki_ekliyor testi başarısız oldu ve mesaj bize başarısız olan doğrulamanın (assertion) left == right (sol == sağ) olduğunu ve left ile right değerlerinin ne olduğunu söylüyor. Bu mesaj hata ayıklamaya başlamamıza yardımcı olur: iki_ekle(2) çağırmanın sonucunu koyduğumuz left argümanı 5’ti ama right argümanı 4’tü. Çok fazla testimiz olduğunda bunun özellikle yararlı olacağını hayal edebilirsiniz.
Bazı dillerde ve test framework’lerinde (çatı/altyapı) eşitlik doğrulama fonksiyonlarının parametrelerine expected (beklenen) ve actual (gerçek) adının verildiğini ve argümanları belirttiğimiz sıranın önemli olduğunu unutmayın. Ancak Rust’ta bunlar left (sol) ve right (sağ) olarak adlandırılır ve beklediğimiz değeri ve kodun ürettiği değeri belirttiğimiz sıra (order) önemli değildir. Bu testteki doğrulamayı assert_eq!(4, sonuc) olarak yazabilirdik ve bu da yine assertion `left == right` failed şeklinde aynı başarısızlık mesajını verirdi.
assert_ne! makrosu, verdiğimiz iki değer eşit değilse geçecek ve eşitse başarısız olacaktır. Bu makro, bir değerin ne olacağından emin olmadığımız ama ne olmaması gerektiğini kesin olarak bildiğimiz durumlarda en kullanışlıdır. Örneğin, girdisini bir şekilde değiştirmesi garanti edilen bir fonksiyonu test ediyorsak, ancak girdinin değiştirilme şekli testlerimizi çalıştırdığımız haftanın gününe bağlıysa, doğrulanacak en iyi şey fonksiyonun çıktısının girdiye eşit olmaması (not equal) olabilir.
Yüzeyin altında, assert_eq! ve assert_ne! makroları sırasıyla == ve != operatörlerini kullanır. Doğrulamalar başarısız olduğunda, bu makrolar argümanlarını debug (hata ayıklama) formatlamasını kullanarak yazdırır, bu da karşılaştırılan değerlerin PartialEq ve Debug trait’lerini (özelliklerini) uygulaması gerektiği anlamına gelir. Tüm ilkel türler ve standart kütüphane türlerinin çoğu bu traitleri uygular. Kendi tanımladığınız struct’lar ve enum’lar için, bu türlerin eşitliğini doğrulamak adına PartialEq uygulamanız gerekecektir. Doğrulama başarısız olduğunda değerleri yazdırmak için Debug trait’ini de uygulamanız gerekecektir. Her iki trait de Bölüm 5’teki Liste 5-12’de belirtildiği gibi türetilebilir traitler olduğundan, bu genellikle struct veya enum tanımınıza #[derive(PartialEq, Debug)] açıklamasını eklemek kadar kolaydır. Bu ve diğer türetilebilir traitler hakkında daha fazla detay için Ek C, “Türetilebilir Traitler (Derivable Traits)” bölümüne bakınız.
Özel Başarısızlık Mesajları Eklemek
Başarısızlık mesajıyla birlikte yazdırılacak özel bir mesajı assert!, assert_eq! ve assert_ne! makrolarına isteğe bağlı argümanlar olarak da ekleyebilirsiniz. Gerekli argümanlardan sonra belirtilen tüm argümanlar format! makrosuna iletilir (Bölüm 8’de “+ veya format! Makrosu ile Birleştirmek (Concatenating)” kısmında tartışılmıştır), böylece {} yer tutucularını ve bu yer tutuculara gidecek değerleri içeren bir format string’i (dizgisi) iletebilirsiniz. Özel mesajlar, bir doğrulamanın ne anlama geldiğini belgelemek için faydalıdır; bir test başarısız olduğunda koddaki sorunun ne olduğu hakkında daha iyi bir fikre sahip olursunuz.
Örneğin, insanları ismen selamlayan bir fonksiyonumuz olduğunu ve fonksiyona geçtiğimiz adın çıktıda göründüğünü test etmek istediğimizi varsayalım:
Dosya adı: src/lib.rs
pub fn selamlama(isim: &str) -> String {
format!("Merhaba {isim}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn selamlama_isim_iceriyor() {
let sonuc = selamlama("Carol");
assert!(sonuc.contains("Carol"));
}
}Bu programa yönelik gereksinimler henüz tam olarak kararlaştırılmadı (agreed upon) ve selamlamanın başındaki Merhaba (Hello) metninin değişeceğinden oldukça eminiz. Gereksinimler değiştiğinde testi güncellemek zorunda kalmamaya karar verdik, bu nedenle selamlama fonksiyonundan döndürülen değere tam eşitlik kontrolü yapmak yerine çıktının girdi parametresinin metnini içerdiğini doğrulayacağız.
Şimdi selamlama fonksiyonunu isim değişkenini dışarıda bırakacak şekilde değiştirerek bu koda bir hata ekleyelim ve varsayılan test başarısızlığının nasıl göründüğüne bakalım:
pub fn selamlama(isim: &str) -> String {
String::from("Merhaba!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn selamlama_isim_iceriyor() {
let sonuc = selamlama("Carol");
assert!(sonuc.contains("Carol"));
}
}Bu testin çalıştırılması aşağıdakini üretir:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::selamlama_isim_iceriyor ... FAILED
failures:
---- tests::selamlama_isim_iceriyor stdout ----
thread 'tests::selamlama_isim_iceriyor' panicked at src/lib.rs:12:9:
assertion failed: sonuc.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::selamlama_isim_iceriyor
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bu sonuç sadece doğrulamanın başarısız olduğunu ve doğrulamanın hangi satırda olduğunu gösterir. Daha kullanışlı bir başarısızlık mesajı, selamlama fonksiyonundan gelen değeri yazdıracaktır. selamlama fonksiyonundan aldığımız gerçek değerle doldurulmuş bir yer tutucusu (placeholder) olan format string’inden oluşan özel bir başarısızlık mesajı ekleyelim:
pub fn selamlama(isim: &str) -> String {
String::from("Merhaba!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn selamlama_isim_iceriyor() {
let sonuc = selamlama("Carol");
assert!(
sonuc.contains("Carol"),
"Selamlama isim içermiyordu, değer `{sonuc}` idi"
);
}
}Şimdi testi çalıştırdığımızda daha bilgilendirici bir hata mesajı alacağız:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::selamlama_isim_iceriyor ... FAILED
failures:
---- tests::selamlama_isim_iceriyor stdout ----
thread 'tests::selamlama_isim_iceriyor' panicked at src/lib.rs:12:9:
Selamlama isim içermiyordu, değer `Merhaba!` idi
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::selamlama_isim_iceriyor
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Test çıktısında gerçekten aldığımız değeri görebiliyoruz, bu da olmasını beklediğimiz şey yerine ne olduğunun hatasını ayıklamamıza yardımcı olacaktır.
should_panic ile Panikleri (Panics) Kontrol Etmek
Dönüş değerlerini kontrol etmeye ek olarak kodumuzun hata durumlarını (error conditions) beklediğimiz gibi yönetip yönetmediğini kontrol etmek de önemlidir. Örneğin, Bölüm 9 Liste 9-13’te oluşturduğumuz Tahmin türünü düşünün. Tahmin’i kullanan diğer kodlar, Tahmin örneklerinin sadece 1 ile 100 arasındaki değerleri içereceğinin garantisine bağlıdır. Bu aralığın dışında bir değerle Tahmin örneği oluşturma denemesinin panik yarattığından emin olan bir test yazabiliriz.
Bunu test fonksiyonumuza should_panic (paniklemeli) özniteliğini ekleyerek yapıyoruz. Fonksiyonun içindeki kod paniklerse test geçer; fonksiyonun içindeki kod paniklemezse test başarısız olur.
Liste 11-8, Tahmin::new (Guess::new) hata durumlarının beklediğimiz zaman gerçekleştiğini kontrol eden bir testi gösterir.
pub struct Tahmin {
deger: i32,
}
impl Tahmin {
pub fn new(deger: i32) -> Tahmin {
if deger < 1 || deger > 100 {
panic!(
"Tahmin değeri 1 ile 100 arasında olmalıdır, {deger} alındı."
);
}
Tahmin { deger }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn yuzden_buyuk() {
Tahmin::new(200);
}
}panic!’e neden olacağını test etme#[should_panic] özniteliğini (attribute) #[test] özniteliğinden sonra ve uygulandığı test fonksiyonundan önce yerleştiririz. Bu test geçtiğindeki sonuca bakalım:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::yuzden_buyuk - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Güzel görünüyor! Şimdi new (yeni) fonksiyonunun değer 100’den büyükse paniğe kapılacağı koşulunu kaldırarak kodumuza bir hata (bug) sokalım:
pub struct Tahmin {
deger: i32,
}
// --snip--
impl Tahmin {
pub fn new(deger: i32) -> Tahmin {
if deger < 1 {
panic!(
"Tahmin değeri 1 ile 100 arasında olmalıdır, {deger} alındı."
);
}
Tahmin { deger }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn yuzden_buyuk() {
Tahmin::new(200);
}
}Liste 11-8’deki testi çalıştırdığımızda, başarısız olacaktır:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::yuzden_buyuk - should panic ... FAILED
failures:
---- tests::yuzden_buyuk stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::yuzden_buyuk
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bu durumda pek yardımcı bir mesaj alamıyoruz, ancak test fonksiyonuna baktığımızda onun #[should_panic] ile açıklandığını (annotated) görüyoruz. Aldığımız hata (failure), test fonksiyonundaki kodun paniğe neden olmadığı anlamına gelir.
should_panic kullanan testler kesin (imprecise) olmayabilir. Bir should_panic testi, test beklediğimizden farklı bir nedenle paniklese bile geçer. should_panic testlerini daha kesin hale getirmek için, should_panic özniteliğine isteğe bağlı (optional) bir expected (beklenen) parametresi ekleyebiliriz. Test altyapısı başarısızlık mesajının sağlanan metni içerdiğinden emin olacaktır. Örneğin Liste 11-9’da, new fonksiyonunun değerin çok küçük ya da çok büyük olmasına bağlı olarak farklı mesajlarla paniklediği Tahmin için değiştirilmiş koda bakın.
pub struct Tahmin {
deger: i32,
}
// --snip--
impl Tahmin {
pub fn new(deger: i32) -> Tahmin {
if deger < 1 {
panic!(
"Tahmin değeri 1'den büyük veya 1'e eşit olmalıdır, {deger} alındı."
);
} else if deger > 100 {
panic!(
"Tahmin değeri 100'den küçük veya 100'e eşit olmalıdır, {deger} alındı."
);
}
Tahmin { deger }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "100'den küçük veya 100'e eşit")]
fn yuzden_buyuk() {
Tahmin::new(200);
}
}panic! için test yapmakBu test geçecektir çünkü should_panic özniteliğinin expected (beklenen) parametresine koyduğumuz değer, Tahmin::new fonksiyonunun paniklediği mesajın bir alt dizgisidir. Beklediğimiz panik mesajının tamamını da belirtebilirdik ki bu durumda Tahmin değeri 100'den küçük veya 100'e eşit olmalıdır, 200 alındı. (Guess value must be less than or equal to 100, got 200.) olurdu. Neyi belirteceğiniz, panik mesajının ne kadarının benzersiz veya dinamik olduğuna ve testinizin ne kadar kesin olmasını istediğinize bağlıdır. Bu durumda panik mesajının bir alt dizgisi, test fonksiyonundaki kodun else if deger > 100 (else if value > 100) durumunu çalıştırdığından emin olmak için yeterlidir.
expected (beklenen) mesaja sahip bir should_panic testi başarısız olduğunda ne olacağını görmek için, if deger < 1 ve else if deger > 100 bloklarının gövdelerini değiştirerek kodumuza tekrar bir hata ekleyelim:
pub struct Tahmin {
deger: i32,
}
impl Tahmin {
pub fn new(deger: i32) -> Tahmin {
if deger < 1 {
panic!(
"Tahmin değeri 100'den küçük veya 100'e eşit olmalıdır, {deger} alındı."
);
} else if deger > 100 {
panic!(
"Tahmin değeri 1'den büyük veya 1'e eşit olmalıdır, {deger} alındı."
);
}
Tahmin { deger }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "100'den küçük veya 100'e eşit")]
fn yuzden_buyuk() {
Tahmin::new(200);
}
}Bu kez should_panic testini çalıştırdığımızda başarısız olacaktır:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::yuzden_buyuk - should panic ... FAILED
failures:
---- tests::yuzden_buyuk stdout ----
thread 'tests::yuzden_buyuk' panicked at src/lib.rs:12:13:
Tahmin değeri 1'den büyük veya 1'e eşit olmalıdır, 200 alındı.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "Tahmin değeri 1'den büyük veya 1'e eşit olmalıdır, 200 alındı."
expected substring: "100'den küçük veya 100'e eşit"
failures:
tests::yuzden_buyuk
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Hata mesajı, bu testin beklediğimiz gibi gerçekten de paniklediğini, ancak panik mesajının beklenen 100'den küçük veya 100'e eşit (less than or equal to 100) dizgisini (string) içermediğini gösteriyor. Bu durumda aldığımız panik mesajı Tahmin değeri 1'den büyük veya 1'e eşit olmalıdır, 200 alındı. (Guess value must be greater than or equal to 1, got 200) şeklindeydi. Artık hatamızın (bug) nerede olduğunu bulmaya başlayabiliriz!
Testlerde Result<T, E> Kullanmak
Şimdiye kadar tüm testlerimiz başarısız olduklarında panikliyorlardı. Ayrıca Result<T, E> kullanan testler de yazabiliriz! İşte Liste 11-1’deki testin, paniklemek yerine Result<T, E> kullanacak ve bir Err (hata) döndürecek şekilde yeniden yazılmış hali:
pub fn topla(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn calisiyor() -> Result<(), String> {
let sonuc = topla(2, 2);
if sonuc == 4 {
Ok(())
} else {
Err(String::from("iki artı iki dört etmez"))
}
}
}calisiyor fonksiyonu artık Result<(), String> dönüş türüne sahip. Fonksiyonun gövdesinde assert_eq! makrosunu çağırmak yerine, test başarılı olduğunda Ok(()) ve test başarısız olduğunda içinde bir String barındıran bir Err döndürüyoruz.
Testleri Result<T, E> döndürecek şekilde yazmak, testlerin gövdesinde soru işareti operatörünü (?) kullanmanızı sağlar; bu da içlerindeki herhangi bir işlem Err varyantı döndürdüğünde başarısız olması gereken testleri yazmanın kullanışlı bir yolu olabilir.
Result<T, E> kullanan testlerde #[should_panic] açıklamasını (annotation) kullanamazsınız. Bir işlemin bir Err varyantı döndürdüğünü doğrulamak için Result<T, E> değeri üzerinde soru işareti operatörünü kullanmayın. Bunun yerine assert!(deger.is_err()) kullanın.
Test yazmanın birkaç yolunu bildiğinize göre, testlerimizi çalıştırdığımızda neler olduğuna bakalım ve cargo test ile kullanabileceğimiz farklı seçenekleri inceleyelim.
Testlerin Nasıl Çalıştırılacağını Kontrol Etme
Testlerin Nasıl Çalıştırılacağını Kontrol Etme
Tıpkı cargo run’ın kodunuzu derlemesi ve ardından ortaya çıkan ikili dosyayı çalıştırması gibi, cargo test de kodunuzu test modunda derler ve ortaya çıkan test ikili dosyasını çalıştırır. cargo test tarafından üretilen ikili dosyanın varsayılan davranışı, tüm testleri paralel olarak çalıştırmak ve test çalışmaları (test runs) sırasında üretilen çıktıyı yakalayarak çıktının görüntülenmesini engellemek ve test sonuçlarıyla ilgili çıktının okunmasını kolaylaştırmaktır. Ancak bu varsayılan davranışı değiştirmek için komut satırı seçeneklerini (command line options) belirtebilirsiniz.
Bazı komut satırı seçenekleri cargo test’e, bazıları ise ortaya çıkan test ikili dosyasına gider. Bu iki tür argümanı ayırmak için cargo test’e giden argümanları, ardından -- ayırıcısını (separator) ve ardından test ikili dosyasına gidenleri listelersiniz. cargo test --help komutunu çalıştırmak cargo test ile kullanabileceğiniz seçenekleri gösterirken, cargo test -- --help komutunu çalıştırmak ayırıcıdan sonra kullanabileceğiniz seçenekleri gösterir. Bu seçenekler aynı zamanda rustc Kitabının “Testler” (Tests) bölümünde de belgelenmiştir.
Testleri Paralel veya Ardışık Olarak Çalıştırmak
Birden fazla test çalıştırdığınızda, varsayılan olarak bunlar iş parçacıklarını kullanarak paralel olarak çalışır, yani daha çabuk bitirirler ve daha çabuk geri bildirim alırsınız. Testler aynı anda çalıştığı için testlerinizin birbirine ya da geçerli çalışma dizini veya çevre değişkenleri (environment variables) gibi paylaşılan bir çevre de dahil olmak üzere paylaşılan herhangi bir duruma (shared state) bağlı olmadığından emin olmalısınız.
Örneğin, testlerinizin her birinin diskte test-ciktisi.txt (test-output.txt) adında bir dosya oluşturan ve bu dosyaya bir miktar veri yazan bir kod çalıştırdığını varsayalım. Ardından her test bu dosyadaki verileri okur ve dosyanın belirli bir değer içerdiğini (her testte farklı olan) doğrular. Testler aynı anda çalıştığı için bir test dosyayı yazıp okuduğu sırada başka bir test dosyanın üzerine yazabilir (overwrite). İkinci test daha sonra kod yanlış olduğu için değil, paralel çalışırken testler birbirine karıştığı (interfered) için başarısız olacaktır. Çözümlerden biri her testin farklı bir dosyaya yazdığından emin olmaktır; başka bir çözüm de testleri teker teker (one at a time) çalıştırmaktır.
Eğer testleri paralel çalıştırmak istemiyorsanız ya da kullanılan iş parçacığı sayısı üzerinde daha ince taneli bir kontrole (fine-grained control) sahip olmak istiyorsanız --test-threads bayrağını (flag) ve kullanmak istediğiniz iş parçacığı sayısını test ikili dosyasına gönderebilirsiniz. Aşağıdaki örneğe bir göz atın:
$ cargo test -- --test-threads=1
Test iş parçacığı sayısını 1 olarak ayarlayarak programa herhangi bir paralellik kullanmamasını söylüyoruz. Testleri tek bir iş parçacığı kullanarak çalıştırmak, paralel olarak çalıştırmaktan daha uzun sürecektir ancak durumu (state) paylaşmaları halinde testler birbirine karışmayacaktır.
Fonksiyon Çıktısını Göstermek
Varsayılan olarak, bir test geçerse Rust’ın test kütüphanesi standart çıktıya (standard output) yazdırılan her şeyi yakalar. Örneğin bir testte println! çağırırsak ve test geçerse, println! çıktısını terminalde görmeyiz; sadece testin geçtiğini gösteren satırı görürüz. Bir test başarısız olursa, standart çıktıya yazdırılan her şeyi başarısızlık mesajının geri kalanıyla birlikte göreceğiz.
Buna bir örnek olarak Liste 11-10’da, parametresinin değerini yazdıran ve 10 döndüren anlamsız (silly) bir fonksiyonun yanı sıra geçen bir test ve başarısız olan bir test bulunmaktadır.
fn yazdir_ve_10_dondur(a: i32) -> i32 {
println!("{} değerini aldım", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn bu_test_gececek() {
let deger = yazdir_ve_10_dondur(4);
assert_eq!(deger, 10);
}
#[test]
fn bu_test_basarisiz_olacak() {
let deger = yazdir_ve_10_dondur(8);
assert_eq!(deger, 5);
}
}println! çağıran bir fonksiyon için testlerBu testleri cargo test ile çalıştırdığımızda şu çıktıyı göreceğiz:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::bu_test_basarisiz_olacak ... FAILED
test tests::bu_test_gececek ... ok
failures:
---- tests::bu_test_basarisiz_olacak stdout ----
8 değerini aldım
thread 'tests::bu_test_basarisiz_olacak' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::bu_test_basarisiz_olacak
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Unutmayın ki geçen test çalıştığında ekrana yazdırılan 4 değerini aldım (I got the value 4) ifadesini bu çıktının hiçbir yerinde göremiyoruz. Bu çıktı yakalanmıştır. Başarısız olan testten gelen 8 değerini aldım (I got the value 8) çıktısı, test başarısızlığının nedenini de gösteren test özeti çıktısının bölümünde yer alıyor.
Eğer geçen testlerin yazdırılan değerlerini de görmek istiyorsak Rust’a --show-output ile başarılı testlerin çıktısını da göstermesini söyleyebiliriz:
$ cargo test -- --show-output
Liste 11-10’daki testleri --show-output bayrağı ile tekrar çalıştırdığımızda aşağıdaki çıktıyı görürüz:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::bu_test_basarisiz_olacak ... FAILED
test tests::bu_test_gececek ... ok
successes:
---- tests::bu_test_gececek stdout ----
4 değerini aldım
successes:
tests::bu_test_gececek
failures:
---- tests::bu_test_basarisiz_olacak stdout ----
8 değerini aldım
thread 'tests::bu_test_basarisiz_olacak' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::bu_test_basarisiz_olacak
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Testlerin Bir Alt Kümesini İsme Göre Çalıştırmak
Tam bir test paketini (test suite) çalıştırmak bazen uzun sürebilir. Eğer belirli bir alandaki kod üzerinde çalışıyorsanız sadece o kodla ilgili testleri çalıştırmak isteyebilirsiniz. Çalıştırmak istediğiniz test(ler)in adını veya adlarını argüman olarak cargo test’e ileterek hangi testlerin çalıştırılacağını seçebilirsiniz.
Testlerin bir alt kümesinin (subset) nasıl çalıştırılacağını göstermek için öncelikle Liste 11-11’de gösterildiği gibi iki_ekle fonksiyonumuz için üç test oluşturacak ve hangilerinin çalıştırılacağını seçeceğiz.
pub fn iki_ekle(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn iki_ve_iki_ekle() {
let sonuc = iki_ekle(2);
assert_eq!(sonuc, 4);
}
#[test]
fn uc_ve_iki_ekle() {
let sonuc = iki_ekle(3);
assert_eq!(sonuc, 5);
}
#[test]
fn yuz() {
let sonuc = iki_ekle(100);
assert_eq!(sonuc, 102);
}
}Daha önce gördüğümüz gibi testleri hiçbir argüman aktarmadan çalıştırırsak tüm testler paralel olarak çalışacaktır:
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/listing-11-11)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 3 tests
test tests::uc_ve_iki_ekle ... ok
test tests::yuz ... ok
test tests::iki_ve_iki_ekle ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Tek Bir Testi Çalıştırmak
Sadece o testi çalıştırmak için herhangi bir test fonksiyonunun adını cargo test’e geçebiliriz:
$ cargo test yuz
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/output-only-02-single-test)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::yuz ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Sadece yuz (one_hundred) isimli test çalıştırıldı; diğer iki test bu isme uymadı. Test çıktısı, sonunda 2 filtered out (2 filtrelendi) görüntüleyerek, çalışmayan daha fazla testimiz olduğunu bize bildirir.
Bu şekilde birden fazla testin adını belirleyemeyiz; yalnızca cargo test’e verilen ilk değer kullanılacaktır. Ancak birden fazla test çalıştırmanın bir yolu var.
Birden Fazla Testi Çalıştırmak İçin Filtreleme
Bir test adının bir bölümünü belirtebiliriz ve adı bu değerle eşleşen tüm testler çalıştırılır. Örneğin testlerimizden ikisinin adı ekle içerdiğinden cargo test ekle komutunu kullanarak bu ikisini çalıştırabiliriz:
$ cargo test ekle
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/output-only-03-multiple-tests)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 2 tests
test tests::uc_ve_iki_ekle ... ok
test tests::iki_ve_iki_ekle ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Bu komut adında ekle olan tüm testleri çalıştırdı ve yuz (one_hundred) adlı testi filtreledi. Ayrıca bir testin içinde göründüğü modülün testin adının bir parçası haline geldiğini, dolayısıyla modülün adına göre filtreleme yaparak bir modüldeki tüm testleri çalıştırabileceğimizi unutmayın.
Açıkça İstenmedikçe Testleri Yok Saymak
Bazen birkaç spesifik testin çalıştırılması çok zaman alıcı (time-consuming) olabilir, bu nedenle cargo test’in çoğu çalıştırması sırasında bunları hariç tutmak isteyebilirsiniz. Çalıştırmak istediğiniz tüm testleri argüman olarak listelemek yerine zaman alan testleri dışarıda bırakmak için Liste 11-12’de gösterildiği gibi ignore (yoksay) özniteliğini (attribute) kullanarak onlara açıklama ekleyebilirsiniz:
Dosya adı: src/lib.rs
pub fn topla(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn calisiyor() {
let sonuc = topla(2, 2);
assert_eq!(sonuc, 4);
}
#[test]
#[ignore]
fn pahali_test() {
// çalışması bir saat süren kod
}
}#[test]’ten sonra, hariç tutmak istediğimiz teste #[ignore] satırını ekleriz. Artık testlerimizi çalıştırdığımızda calisiyor çalışıyor ancak pahali_test (expensive_test) çalışmıyor:
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/no-listing-11-ignore-a-test)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 2 tests
test tests::pahali_test ... ignored
test tests::calisiyor ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
pahali_test fonksiyonu ignored (yoksayıldı) olarak listelenir. Sadece yoksayılan testleri çalıştırmak istiyorsak cargo test -- --ignored komutunu kullanabiliriz:
$ cargo test -- --ignored
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/output-only-04-running-ignored)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.11s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::pahali_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Hangi testlerin çalıştırılacağını kontrol ederek cargo test sonuçlarınızın hızlı bir şekilde dönmesini sağlayabilirsiniz. ignored (yoksayılan) testlerin sonuçlarını kontrol etmenin mantıklı olduğu bir noktaya geldiğinizde ve sonuçları beklemek için zamanınız olduğunda bunun yerine cargo test -- --ignored çalıştırabilirsiniz. İster yoksayılsın ister yoksayılmasın tüm testleri çalıştırmak istiyorsanız cargo test -- --include-ignored komutunu çalıştırabilirsiniz.
Test Organizasyonu
Test Organizasyonu
Bölümün başında bahsedildiği gibi test etmek karmaşık bir disiplindir ve farklı insanlar farklı terminoloji ile organizasyonlar kullanır. Rust topluluğu testleri iki ana kategoride düşünür: birim testleri ve entegrasyon testleri. Birim testleri daha küçük ve daha odaklıdır; bir defada bir modülü yalıtılmış olarak test eder ve gizli arayüzleri test edebilir. Entegrasyon testleri tamamen kütüphanenizin dışındadır ve kodunuzu tıpkı diğer harici kodların kullanacağı şekilde kullanarak yalnızca açık arayüzü çağırır ve test başına potansiyel olarak birden çok modülü uygulayabilir.
Kütüphanenizin parçalarının ayrı ayrı ve birlikte beklediğiniz şeyi yaptığından emin olmak için her iki tür testi de yazmak önemlidir.
Birim Testleri (Unit Tests)
Birim testlerinin amacı, kodun nerede beklendiği gibi çalışıp çalışmadığını hızlı bir şekilde belirlemek için her bir kod birimini kodun geri kalanından yalıtılmış olarak test etmektir. Birim testlerini test ettikleri kodla birlikte her dosyada src dizinine koyacaksınız. Gelenek, her dosyada test fonksiyonlarını içerecek tests adlı bir modül oluşturmak ve modüle cfg(test) açıklamasını eklemektir.
tests Modülü ve #[cfg(test)]
tests modülündeki #[cfg(test)] açıklaması Rust’a test kodunu cargo build çalıştırdığınızda değil, yalnızca cargo test çalıştırdığınızda derlemesini ve çalıştırmasını söyler. Bu, sadece kütüphaneyi oluşturmak (build) istediğinizde derleme süresinden kazandırır ve testler dahil edilmediği için ortaya çıkan derlenmiş yapıtta (artifact) alan tasarrufu sağlar. Entegrasyon testlerinin farklı bir dizinde yer aldıkları için #[cfg(test)] açıklamasına ihtiyaç duymadıklarını göreceksiniz. Ancak birim testleri kodla aynı dosyalara girdiğinden, derlenmiş sonuca dahil edilmemeleri gerektiğini belirtmek için #[cfg(test)] kullanacaksınız.
Bu bölümün ilk kısmında yeni adder projesini oluşturduğumuzda Cargo’nun bizim için bu kodu ürettiğini (generated) hatırlayın:
Dosya adı: src/lib.rs
pub fn topla(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn calisiyor() {
let sonuc = topla(2, 2);
assert_eq!(sonuc, 4);
}
}Otomatik olarak üretilen tests modülü üzerindeki cfg özniteliği yapılandırma anlamına gelir ve Rust’a aşağıdaki öğenin yalnızca belirli bir yapılandırma seçeneği sağlandığında dahil edilmesi gerektiğini söyler. Bu durumda yapılandırma seçeneği, testleri derlemek ve çalıştırmak için Rust tarafından sağlanan test seçeneğidir. cfg özniteliğini kullanarak Cargo, test kodumuzu yalnızca testleri aktif olarak cargo test ile çalıştırırsak derler. Bu, #[test] ile açıklanmış fonksiyonlara ek olarak bu modülün içinde olabilecek herhangi bir yardımcı (helper) fonksiyonu da içerir.
Gizli (Private) Fonksiyon Testleri
Test topluluğunda gizli fonksiyonların doğrudan test edilip edilmemesi gerektiği konusunda bir tartışma vardır ve diğer diller gizli fonksiyonları test etmeyi zorlaştırır veya imkansız hale getirir. Hangi test ideolojisine bağlı olursanız olun Rust’ın gizlilik (privacy) kuralları, gizli fonksiyonları test etmenize izin verir. ic_toplayici adında gizli bir fonksiyona sahip olan Liste 11-12’deki koda bakın.
pub fn iki_ekle(a: u64) -> u64 {
ic_toplayici(a, 2)
}
fn ic_toplayici(sol: u64, sag: u64) -> u64 {
sol + sag
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ic() {
let sonuc = ic_toplayici(2, 2);
assert_eq!(sonuc, 4);
}
}ic_toplayici fonksiyonunun pub olarak işaretlenmediğini unutmayın. Testler sadece bir Rust kodudur ve tests modülü de sadece başka bir modüldür. “Modül Ağacındaki Bir Öğeye Atıfta Bulunmak İçin Yollar” bölümünde tartıştığımız gibi alt modüllerdeki (child modules) öğeler ata (ancestor) modüllerindeki öğeleri kullanabilirler. Bu testte tests modülünün üst modülüne ait olan tüm öğeleri use super::* ile kapsama getiriyoruz ve ardından test ic_toplayici’yi çağırabiliyor. Eğer gizli fonksiyonların test edilmemesi gerektiğini düşünüyorsanız Rust’ta sizi bunu yapmaya zorlayacak hiçbir şey yoktur.
Entegrasyon Testleri
Rust’ta entegrasyon testleri kütüphanenizin tamamen dışındadır. Kütüphanenizi diğer kodların kullanacağı şekilde kullanırlar, bu da kütüphanenizin yalnızca açık API’sinin parçası olan fonksiyonları çağırabilecekleri anlamına gelir. Amaçları, kütüphanenizin birçok parçasının birlikte doğru çalışıp çalışmadığını test etmektir. Kendi başlarına doğru çalışan kod birimleri entegre edildiklerinde sorun yaşayabilirler, bu nedenle entegre edilmiş kodun test kapsamı da önemlidir. Entegrasyon testleri oluşturmak için öncelikle bir tests dizinine ihtiyacınız vardır.
tests Dizini
Proje dizinimizin en üst seviyesinde, src’nin yanında bir tests dizini oluşturuyoruz. Cargo entegrasyon test dosyalarını bu dizinde araması gerektiğini bilir. Daha sonra istediğimiz kadar test dosyası oluşturabiliriz ve Cargo dosyaların her birini ayrı bir crate (sandık) olarak derler.
Bir entegrasyon testi oluşturalım. Liste 11-12’deki kod hala src/lib.rs dosyasındayken bir tests dizini yapın ve tests/entegrasyon_testi.rs adında yeni bir dosya oluşturun. Dizin yapınız şu şekilde görünmelidir:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── entegrasyon_testi.rs
tests/entegrasyon_testi.rs dosyasına Liste 11-13’teki kodu girin.
use toplayici::iki_ekle;
#[test]
fn iki_ekliyor() {
let sonuc = iki_ekle(2);
assert_eq!(sonuc, 4);
}adder crate’indeki bir fonksiyonun entegrasyon testitests dizinindeki her dosya ayrı bir crate’dir, bu nedenle kütüphanemizi her bir test crate’inin kapsamına getirmemiz gerekir. Bu nedenle kodun en üstüne use adder::iki_ekle; ekliyoruz, buna birim testlerinde ihtiyacımız yoktu.
tests/entegrasyon_testi.rs dosyasındaki herhangi bir koda #[cfg(test)] açıklamasını eklememize gerek yoktur. Cargo, tests dizinini özel olarak ele alır ve bu dizindeki dosyaları yalnızca cargo test çalıştırdığımızda derler. Şimdi cargo test’i çalıştırın:
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/listing-11-13)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.13s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::ic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/entegrasyon_testi.rs (target/debug/deps/entegrasyon_testi-5737c6970c195272)
running 1 test
test iki_ekliyor ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Üç bölümden oluşan çıktı birim testlerini, entegrasyon testini ve dokümantasyon (doc) testlerini içerir. Bir bölümdeki herhangi bir test başarısız olursa sonraki bölümlerin çalıştırılmayacağını unutmayın. Örneğin, bir birim testi başarısız olursa, entegrasyon ve dokümantasyon testleri için herhangi bir çıktı olmayacaktır, çünkü bu testler yalnızca tüm birim testleri geçiyorsa çalıştırılacaktır.
Birim testleri için olan ilk bölüm gördüğümüzle aynıdır: her birim testi için bir satır (Liste 11-12’de eklediğimiz ic (internal) adlı test) ve ardından birim testleri için bir özet satırı.
Entegrasyon testleri bölümü Running tests/entegrasyon_testi.rs (tests/entegrasyon_testi.rs çalıştırılıyor) satırıyla başlar. Ardından, Doc-tests adder bölümü başlamadan hemen önce o entegrasyon testindeki her test fonksiyonu için bir satır ve entegrasyon testinin sonuçları için bir özet satırı bulunur.
Her entegrasyon test dosyasının kendi bölümü vardır, bu nedenle tests dizinine daha fazla dosya eklersek daha fazla entegrasyon testi bölümü olacaktır.
Belirli bir entegrasyon test fonksiyonunu, test fonksiyonunun adını cargo test’e argüman olarak belirterek hala çalıştırabiliriz. Belirli bir entegrasyon test dosyasındaki tüm testleri çalıştırmak için cargo test’in --test argümanını ve ardından dosyanın adını kullanın:
$ cargo test --test entegrasyon_testi
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/output-only-05-single-integration)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.12s
Running tests/entegrasyon_testi.rs (target/debug/deps/entegrasyon_testi-5737c6970c195272)
running 1 test
test iki_ekliyor ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bu komut sadece tests/entegrasyon_testi.rs dosyasındaki testleri çalıştırır.
Entegrasyon Testlerindeki Alt Modüller (Submodules)
Daha fazla entegrasyon testi ekledikçe testleri organize etmeye yardımcı olması için tests dizininde daha fazla dosya yapmak isteyebilirsiniz; örneğin test fonksiyonlarını test ettikleri işlevselliğe göre gruplandırabilirsiniz. Daha önce de belirtildiği gibi, tests dizinindeki her bir dosya kendi başına ayrı bir crate olarak derlenir ki bu da son kullanıcıların crate’inizi kullanım şeklini daha yakından taklit edecek ayrı kapsamlar oluşturmak için kullanışlıdır. Ancak bu durum tests dizinindeki dosyaların src dizinindeki dosyalarla aynı davranışı (behavior) paylaşmadığı anlamına gelir; bunu Bölüm 7’de kodu modüllere ve dosyalara nasıl ayıracağınızla ilgili olarak öğrenmiştiniz.
Birden fazla entegrasyon test dosyasında kullanılacak bir dizi yardımcı fonksiyona sahip olduğunuzda ve bunları ortak (common) bir modüle çıkarmak için Bölüm 7’nin “Modülleri Farklı Dosyalara Ayırma” kısmındaki adımları izlemeye çalıştığınızda tests dizini dosyalarının bu farklı davranışı en çok göze çarpan şeydir. Örneğin, tests/ortak.rs dosyasını oluşturur ve içine kurulum (setup) adında bir fonksiyon yerleştirirsek, birden fazla test dosyasındaki birden fazla test fonksiyonundan çağırmak istediğimiz bazı kodları kurulum’a ekleyebiliriz:
Dosya adı: tests/ortak.rs
pub fn kurulum() {
// kütüphanenizin testlerine özgü kurulum kodu buraya gelecek
}Testleri tekrar çalıştırdığımızda, ortak.rs dosyası herhangi bir test fonksiyonu içermemesine ya da kurulum fonksiyonunu hiçbir yerden çağırmamamıza rağmen test çıktısında bu dosya için yeni bir bölüm göreceğiz:
$ cargo test
Compiling toplayici v0.1.0 ($PROJE/listings/ch11-writing-automated-tests/no-listing-12-shared-test-code-problem)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.14s
Running unittests src/lib.rs (target/debug/deps/toplayici-ac13090f6eeacc92)
running 1 test
test tests::ic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/ortak.rs (target/debug/deps/ortak-65e36ecf6e3af4a8)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/entegrasyon_testi.rs (target/debug/deps/entegrasyon_testi-5737c6970c195272)
running 1 test
test iki_ekliyor ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests toplayici
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Test sonuçlarında ortak’ın yanında running 0 tests (0 test çalıştırılıyor) yazması istediğimiz bir şey değildi. Biz sadece diğer entegrasyon test dosyalarıyla bazı kodları paylaşmak istedik. Test çıktısında ortak ifadesinin görünmesini önlemek için, tests/ortak.rs oluşturmak yerine tests/ortak/mod.rs oluşturacağız. Proje dizini (project directory) artık şu şekilde görünecektir:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── ortak
│ └── mod.rs
└── entegrasyon_testi.rs
Bu, Bölüm 7’de “Alternatif Dosya Yolları” kısmında bahsettiğimiz ve Rust’ın da anladığı eski adlandırma kuralıdır. Dosyayı bu şekilde adlandırmak Rust’a ortak modülünü bir entegrasyon test dosyası olarak kabul etmemesini söyler. kurulum fonksiyon kodunu tests/ortak/mod.rs dosyasına taşıyıp tests/ortak.rs dosyasını sildiğimizde test çıktısındaki bu bölüm artık görünmeyecektir. tests dizininin alt dizinlerindeki dosyalar ayrı crateler olarak derlenmezler veya test çıktısında bölümleri olmaz.
tests/ortak/mod.rs dosyasını oluşturduktan sonra, onu herhangi bir entegrasyon test dosyasından bir modül olarak kullanabiliriz. İşte tests/entegrasyon_testi.rs dosyasındaki iki_ekliyor testinden kurulum fonksiyonunu çağırmaya bir örnek:
Dosya adı: tests/entegrasyon_testi.rs
use toplayici::iki_ekle;
mod ortak;
#[test]
fn iki_ekliyor() {
ortak::kurulum();
let sonuc = iki_ekle(2);
assert_eq!(sonuc, 4);
}mod ortak; beyanının (declaration), Liste 7-21’de gösterdiğimiz modül beyanıyla aynı olduğuna dikkat edin. Daha sonra test fonksiyonunda ortak::kurulum() fonksiyonunu çağırabiliriz.
İkili (Binary) Crateler İçin Entegrasyon Testleri
Projemiz sadece src/main.rs dosyası içeren ve src/lib.rs dosyası olmayan bir ikili crate ise, tests dizininde entegrasyon testleri oluşturamayız ve src/main.rs dosyasında tanımlanan fonksiyonları use (kullan) ifadesiyle (statement) kapsama alamayız. Sadece kütüphane crateleri diğer cratelerin kullanabileceği fonksiyonları açığa çıkarır; ikili cratelerin kendi başlarına çalıştırılması amaçlanmıştır.
İkili dosya sağlayan Rust projelerinin, src/lib.rs dosyasında yaşayan mantığı çağıran basit bir src/main.rs dosyasına sahip olmasının nedenlerinden biri budur. Bu yapıyı kullanarak, entegrasyon testleri önemli işlevselliği kullanılabilir (available) kılmak için use ile kütüphane crate’ini test edebilir. Önemli işlevsellik çalışıyorsa, src/main.rs dosyasındaki küçük miktardaki kod da çalışacaktır ve o küçük koddaki miktarın test edilmesine gerek yoktur.
Özet
Rust’ın test etme özellikleri, kodunuzun nasıl çalışması gerektiğini belirtmeniz için bir yol sağlayarak, siz değişiklik yapsanız bile kodun beklediğiniz gibi çalışmaya devam etmesini sağlar. Birim testleri, bir kütüphanenin farklı bölümlerini ayrı ayrı test eder ve gizli uygulama ayrıntılarını test edebilir. Entegrasyon testleri, kütüphanenin pek çok parçasının birlikte doğru çalışıp çalışmadığını kontrol eder ve kodu test etmek için, harici kodun kütüphaneyi kullanacağı aynı yolla kütüphanenin açık API’sini kullanır. Rust’ın tür sistemi ve sahiplik kuralları bazı tür hataları önlemeye yardımcı olsa bile, kodunuzun nasıl davranması beklendiğiyle ilgili mantık hatalarını azaltmak için testler yine de önemlidir.
Bir proje üzerinde çalışmak için bu bölümde ve önceki bölümlerde öğrendiklerinizi birleştirelim!
Bir G/Ç (I/O) Projesi: Bir Komut Satırı Programı Oluşturmak
Bu bölüm, şimdiye kadar öğrendiğiniz pek çok becerinin bir özeti ve standart kütüphanenin birkaç özelliğinin daha keşfidir. Şu an sahip olduğunuz bazı Rust kavramlarını pratik yapmak için, dosya ve komut satırı girdisi/çıktısı (input/output) ile etkileşime giren bir komut satırı aracı oluşturacağız.
Rust’ın hızı, güvenliği, tek ikili dosya çıktısı (single binary output) ve çapraz platform (cross-platform) desteği, onu komut satırı araçları oluşturmak için ideal bir dil haline getirir; bu nedenle projemiz için klasik komut satırı arama aracı grep’in (dünya çapında bir düzenli ifade arama ve yazdırma - globally search a regular expression and print) kendi sürümünü yapacağız. En basit kullanım senaryosunda, grep belirtilen bir dosyada belirtilen bir string’i (dizgiyi) arar. Bunu yapmak için grep bir dosya yolunu ve bir string’i argüman olarak alır. Ardından dosyayı okur, o dosyada string argümanını içeren satırları bulur ve o satırları yazdırır.
Yol boyunca, komut satırı aracımızın diğer birçok komut satırı aracının kullandığı terminal özelliklerini kullanmasını nasıl sağlayacağımızı göstereceğiz. Kullanıcının aracımızın davranışını yapılandırmasına izin vermek için bir çevre değişkeninin değerini okuyacağız. Ayrıca, kullanıcının başarılı çıktıyı bir dosyaya yönlendirirken hata mesajlarını ekranda görebilmesi için hata mesajlarını standart çıktı (stdout) yerine standart hata konsolu akışına (stderr) yazdıracağız.
Rust topluluğunun bir üyesi olan Andrew Gallant, zaten ripgrep adında tam özellikli, çok hızlı bir grep sürümü yarattı. Karşılaştırıldığında, bizim versiyonumuz oldukça basit olacak, ancak bu bölüm size ripgrep gibi gerçek dünya projelerini anlamanız için gereken bazı arka plan bilgilerini verecektir.
Bizim grep projemiz şu ana kadar öğrendiğiniz bazı kavramları birleştirecek:
- Kodu organize etmek (Bölüm 7)
- Vektörleri ve stringleri kullanmak (Bölüm 8)
- Hata yönetimi (Error handling) (Bölüm 9)
- Uygun yerlerde traitleri ve ömürleri kullanmak (Bölüm 10)
- Test yazmak (Bölüm 11)
Ayrıca Bölüm 13 ve Bölüm 18’in ayrıntılı olarak ele alacağı kapanışları, yineleyicileri ve trait nesnelerini kısaca tanıtacağız.
Komut Satırı Argümanlarını Kabul Etme
Komut Satırı Argümanlarını Kabul Etmek
Her zaman olduğu gibi cargo new ile yeni bir proje oluşturalım. Sisteminizde zaten var olabilecek grep aracından ayırt etmek için projemize minigrep adını vereceğiz:
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
İlk görev minigrep’in iki komut satırı argümanını kabul etmesini sağlamaktır: dosya yolu ve aranacak string (dizgi). Yani, programımızı cargo run ile, sonraki argümanların cargo için değil programımız için olduğunu belirtmek için iki tire (--), aranacak string ve içinde aranacak dosyanın yolu ile şu şekilde çalıştırabilmek istiyoruz:
$ cargo run -- aranacakstring ornek-dosyaadi.txt
Şu anda cargo new tarafından üretilen program verdiğimiz argümanları işleyemez. crates.io’daki mevcut bazı kütüphaneler komut satırı argümanlarını kabul eden bir program yazmaya yardımcı olabilir, ancak bu kavramı yeni öğrendiğiniz için bu yeteneği kendimiz uygulayalım.
Argüman Değerlerini Okumak
minigrep’in ona ilettiğimiz komut satırı argümanlarının değerlerini okumasını sağlamak için, Rust’ın standart kütüphanesinde sağlanan std::env::args fonksiyonuna ihtiyacımız olacak. Bu fonksiyon, minigrep’e iletilen komut satırı argümanlarının bir yineleyicisini döndürür. Yineleyicileri (iteratörleri) Bölüm 13’te tam olarak ele alacağız. Şimdilik yineleyiciler hakkında yalnızca iki ayrıntı bilmeniz gerekir: Yineleyiciler bir dizi değer üretir ve yineleyicinin ürettiği tüm öğeleri barındıran vektör gibi bir koleksiyona dönüştürmek için yineleyici üzerinde collect (topla) metodunu çağırabiliriz.
Liste 12-1’deki kod, minigrep programınızın kendisine aktarılan tüm komut satırı argümanlarını okumasını ve ardından değerleri bir vektörde toplamasını sağlar.
use std::env;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
dbg!(argumanlar);
}İlk olarak, args (argümanlar) fonksiyonunu kullanabilmek için use ifadesiyle std::env modülünü kapsama dahil ediyoruz. std::env::args fonksiyonunun iki seviyeli modüllerin içine yerleştirildiğine dikkat edin. Bölüm 7’de tartıştığımız gibi, istenen fonksiyonun birden fazla modül içine yerleştirildiği durumlarda fonksiyon yerine ebeveyn modülü kapsama almayı seçtik. Bunu yaparak, std::env’deki diğer fonksiyonları kolayca kullanabiliriz. Ayrıca, use std::env::args eklemekten ve ardından fonksiyonu yalnızca args ile çağırmaktan daha az belirsizdir, çünkü args kolayca mevcut modülde tanımlanmış bir fonksiyon sanılabilir.
args Fonksiyonu ve Geçersiz Unicode
Herhangi bir argüman geçersiz Unicode içeriyorsa std::env::args’ın panikleyeceğini unutmayın. Programınızın geçersiz Unicode barındıran argümanları kabul etmesi gerekiyorsa, bunun yerine std::env::args_os kullanın. Bu fonksiyon, String değerleri yerine OsString değerleri üreten bir yineleyici döndürür. Basitlik adına burada std::env::args kullanmayı seçtik, çünkü OsString değerleri platforma göre farklılık gösterir ve üzerinde çalışılması String değerlerinden daha karmaşıktır.
main fonksiyonunun ilk satırında env::args çağırıyoruz ve yineleyiciyi, yineleyicinin ürettiği tüm değerleri barındıran bir vektöre dönüştürmek için hemen collect kullanıyoruz. Birçok türde koleksiyon oluşturmak için collect fonksiyonunu kullanabiliriz, bu nedenle stringlerden oluşan bir vektör istediğimizi belirtmek için argumanlar değişkeninin türünü açıkça açıklıyoruz. Rust’ta türleri açıklamanız çok nadiren gerekse de, Rust istediğiniz koleksiyon türünü çıkaramadığı için collect genellikle açıklamanız gereken bir fonksiyondur.
Son olarak, dbg! (hata ayıklama) makrosunu kullanarak vektörü yazdırıyoruz. Önce argüman olmadan sonra iki argümanla kodu çalıştırmayı deneyelim:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] argumanlar = [
"target/debug/minigrep",
]
$ cargo run -- aranan samanlik
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep aranan samanlik`
[src/main.rs:5:5] argumanlar = [
"target/debug/minigrep",
"aranan",
"samanlik",
]
Vektördeki ilk değerin "target/debug/minigrep" olduğuna dikkat edin; bu, bizim ikili dosyamızın adıdır. Bu, C’deki argüman listesinin davranışıyla eşleşerek, programların çalıştırılmalarında çağrıldıkları adı kullanmalarına izin verir. Mesajlarda program adını yazdırmak isterseniz veya programı çağırmak için hangi komut satırı takma adının kullanıldığına bağlı olarak programın davranışını değiştirmek isterseniz program ismine erişebilmek genellikle kullanışlıdır. Ancak bu bölümün amaçları doğrultusunda bunu görmezden geleceğiz ve yalnızca ihtiyacımız olan iki argümanı kaydedeceğiz.
Argüman Değerlerini Değişkenlere Kaydetmek (Saving)
Program şu anda komut satırı argümanları olarak belirtilen değerlere erişebiliyor. Şimdi iki argümanın değerini, değerleri programın geri kalanı boyunca kullanabilmemiz için değişkenlere kaydetmemiz gerekiyor. Bunu Liste 12-2’de yapıyoruz.
use std::env;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let sorgu = &argumanlar[1];
let dosya_yolu = &argumanlar[2];
println!("Aranan: {sorgu}");
println!("Dosya: {dosya_yolu}");
}Vektörü yazdırdığımızda gördüğümüz gibi programın adı vektördeki ilk değeri argumanlar[0]’da alıyor, bu yüzden argümanlara 1. indeksten başlıyoruz. minigrep’in aldığı ilk argüman aradığımız string’dir (dizgidir), bu nedenle ilk argümana bir referansı sorgu değişkenine koyuyoruz. İkinci argüman dosya yolu olacaktır, bu yüzden ikinci argümana bir referansı dosya_yolu değişkenine yerleştiriyoruz.
Kodun amaçladığımız gibi çalıştığını kanıtlamak için bu değişkenlerin değerlerini geçici olarak yazdırıyoruz. Hadi bu programı tekrar test ve ornek.txt (sample.txt) argümanlarıyla çalıştıralım:
$ cargo run -- test ornek.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test ornek.txt`
Aranan: test
Dosya: ornek.txt
Harika, program çalışıyor! İhtiyacımız olan argümanların değerleri doğru değişkenlere kaydediliyor. Daha sonra kullanıcının argüman sağlamaması gibi bazı olası hatalı durumlarla başa çıkmak için bazı hata yönetimi ekleyeceğiz; şimdilik bu durumu göz ardı edeceğiz ve bunun yerine dosya okuma özellikleri eklemeye çalışacağız.
Bir Dosyayı Okuma
Dosya Okuma
Şimdi, dosya_yolu argümanında belirtilen dosyayı okuma işlevselliği ekleyeceğiz. İlk olarak, test etmek için örnek bir dosyaya ihtiyacımız var: Birkaç tekrarlanan kelime içeren, çok satırlı az miktarda metne sahip bir dosya kullanacağız. Liste 12-3’te işe yarayacak kısa bir şiir var! Projenizin kök dizininde siir.txt adında bir dosya oluşturun ve aşağıdaki dizeleri girin.
Ne hasta bekler sabahı,
Ne taze ölüyü mezar.
Ne de şeytan, bir günahı,
Seni beklediğim kadar.
Geçti istemem gelmeni,
Yokluğunda buldum seni;
Bırak vehmimde gölgeni
Gelme, artık neye yarar?
Metni yerine yerleştirdikten sonra, src/main.rs dosyasını düzenleyin ve Liste 12-4’te gösterildiği gibi dosyayı okuyacak kodu ekleyin.
use std::env;
use std::fs;
fn main() {
// --snip--
let argumanlar: Vec<String> = env::args().collect();
let sorgu = &argumanlar[1];
let dosya_yolu = &argumanlar[2];
println!("Aranan: {sorgu}");
println!("Dosya: {dosya_yolu}");
let icerik = fs::read_to_string(dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
}İlk olarak, use ifadesiyle standart kütüphanenin ilgili bir bölümünü dahil ediyoruz: Dosyaları işlemek için std::fs’ye ihtiyacımız var.
main fonksiyonunda, yeni fs::read_to_string ifadesi dosya_yolunu alır, o dosyayı açar ve dosyanın içeriklerini barındıran std::io::Result<String> türünde bir değer döndürür.
Bundan sonra, programın şu ana kadar çalıştığını kontrol edebilmemiz için dosya okunduktan sonra icerik değerini yazdıran geçici bir println! ifadesi daha ekliyoruz.
İlk komut satırı argümanı olarak herhangi bir string (henüz arama kısmını uygulamadığımız için) ve ikinci argüman olarak siir.txt dosyasını kullanarak bu kodu çalıştıralım:
$ cargo run -- mezar siir.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep mezar siir.txt`
Aranan: mezar
Dosya: siir.txt
Metin içeriği:
Ne hasta bekler sabahı,
Ne taze ölüyü mezar.
Ne de şeytan, bir günahı,
Seni beklediğim kadar.
Geçti istemem gelmeni,
Yokluğunda buldum seni;
Bırak vehmimde gölgeni
Gelme, artık neye yarar?
Harika! Kod dosyanın içeriğini okudu ve sonra yazdırdı. Fakat kodun birkaç kusuru var. Şu anda main fonksiyonunun birden çok sorumluluğu var: Genel olarak, her fonksiyon yalnızca bir fikirden sorumluysa fonksiyonlar daha net ve bakımı daha kolaydır. Diğer bir sorun ise hataları (errors) elimizden geldiğince iyi yönetmiyor olmamız. Program henüz küçük olduğu için bu kusurlar büyük bir problem değil, ancak program büyüdükçe bunları temiz bir şekilde düzeltmek daha da zorlaşacaktır. Az miktarda kodu yeniden düzenlemek çok daha kolay olduğundan, program geliştirirken yeniden düzenlemeye erken başlamak iyi bir pratiktir. Bunu bir sonraki adımda yapacağız.
Modülerliği ve Hata Yönetimini İyileştirmek İçin Yeniden Düzenleme
Modülerliği ve Hata Yönetimini (Error Handling) İyileştirmek İçin Yeniden Düzenleme (Refactoring)
Programımızı iyileştirmek için, programın yapısıyla ve olası hataları nasıl ele aldığıyla ilgili dört sorunu çözeceğiz. Birincisi, main fonksiyonumuz şu anda iki görevi yerine getiriyor: Argümanları ayrıştırıyor (parses) ve dosyaları okuyor. Programımız büyüdükçe, main fonksiyonunun ele aldığı ayrı görevlerin sayısı artacaktır. Bir fonksiyon sorumluluk kazandıkça, hakkında akıl yürütmesi, test etmesi ve parçalarından birini bozmadan (breaking) değiştirmesi daha zor hale gelir. İşlevselliği ayırmak en iyisidir, böylece her fonksiyon tek bir görevden sorumlu olur.
Bu sorun aynı zamanda ikinci soruna da bağlıdır: sorgu ve dosya_yolu programımız için yapılandırma değişkenleri olmalarına rağmen, programın mantığını yerine getirmek için icerik gibi değişkenler de kullanılır. main ne kadar uzarsa, kapsama dahil etmemiz gereken değişkenler o kadar artar; kapsamda ne kadar çok değişkenimiz olursa, her birinin amacını takip etmek o kadar zor olur. Yapılandırma değişkenlerini amaçlarını netleştirmek için tek bir yapıda gruplamak en iyisidir.
Üçüncü sorun, dosya okunurken hata oluştuğunda expect ile bir hata mesajı yazdırmış olmamızdır, ancak hata mesajı yalnızca Dosya okunamadı yazar. Bir dosyayı okumak çeşitli şekillerde başarısız olabilir: Örneğin, dosya eksik olabilir veya dosyayı açma iznimiz olmayabilir. Şu anda duruma bakılmaksızın her şey için aynı hata mesajını yazdırıyoruz, bu da kullanıcıya herhangi bir bilgi vermez!
Dördüncüsü, bir hatayı ele almak için expect kullanıyoruz ve eğer kullanıcı programımızı yeterli argüman belirtmeden çalıştırırsa, Rust’tan sorunu açıkça açıklamayan bir index out of bounds (indeks sınırların dışında) hatası alır. Eğer hata yönetimi (error-handling) kodunun tamamı tek bir yerde olsaydı, hata yönetimi mantığının değişmesi gerektiğinde gelecekteki bakımcıların koda bakmak için tek bir yeri olurdu. Tüm hata yönetimi kodunun tek bir yerde olması, son kullanıcılarımız için anlamlı mesajlar yazdırdığımızdan da emin olmamızı sağlar.
Projemizi yeniden düzenleyerek bu dört sorunu ele alalım.
İkili (Binary) Projelerde İlgi Alanlarını Ayırmak (Separating Concerns)
main fonksiyonuna birden fazla görevin sorumluluğunu atamaya dair bu organizasyonel sorun, pek çok ikili proje için ortaktır. Sonuç olarak pek çok Rust programcısı, main fonksiyonu büyümeye başladığında ikili bir programın ayrı ayrı ilgi alanlarını ayırmayı kullanışlı bulur. Bu sürecin aşağıdaki adımları vardır:
- Programınızı bir main.rs dosyasına ve bir lib.rs dosyasına bölün ve programınızın mantığını lib.rs dosyasına taşıyın.
- Komut satırı ayrıştırma mantığınız küçük olduğu sürece
mainfonksiyonunda kalabilir. - Komut satırı ayrıştırma mantığı karmaşıklaşmaya başladığında, onu
mainfonksiyonundan çıkarıp başka fonksiyonlara veya türlere taşıyın.
Bu süreçten sonra main fonksiyonunda kalan sorumluluklar aşağıdakilerle sınırlı olmalıdır:
- Komut satırı ayrıştırma mantığını argüman değerleriyle çağırmak
- Diğer yapılandırmaları ayarlamak
- lib.rs içindeki bir
calistirfonksiyonunu çağırmak calistirbir hata döndürürse hatayı ele almak
Bu desen (pattern) ilgi alanlarını ayırmak ile ilgilidir: main.rs programı çalıştırmayı, lib.rs ise eldeki görevin tüm mantığını halleder. main fonksiyonunu doğrudan test edemediğiniz için bu yapı, programınızın tüm mantığını main fonksiyonunun dışına taşıyarak test etmenize olanak tanır. main fonksiyonunda kalan kod, okuyarak doğruluğunu kanıtlayacak kadar küçük olacaktır. Bu süreci izleyerek programımızı yeniden işleyelim.
Argüman Ayrıştırıcısını (Argument Parser) Çıkarmak
Argümanları ayrıştırma işlevselliğini main’in çağıracağı bir fonksiyona çıkaracağız. Liste 12-5, src/main.rs dosyasında tanımlayacağımız yeni bir fonksiyon olan yapilandirma_ayristir’ı (parse_config) çağıran main fonksiyonunun yeni başlangıcını göstermektedir.
use std::env;
use std::fs;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let (sorgu, dosya_yolu) = yapilandirma_ayristir(&argumanlar);
// --snip--
println!("Aranan: {sorgu}");
println!("Dosya: {dosya_yolu}");
let icerik = fs::read_to_string(dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
}
fn yapilandirma_ayristir(argumanlar: &[String]) -> (&str, &str) {
let sorgu = &argumanlar[1];
let dosya_yolu = &argumanlar[2];
(sorgu, dosya_yolu)
}main’den bir yapilandirma_ayristir fonksiyonu çıkarmakKomut satırı argümanlarını hala bir vektörde topluyoruz, ancak 1. indeksteki argüman değerini main fonksiyonu içinde sorgu değişkenine ve 2. indeksteki argüman değerini dosya_yolu değişkenine atamak yerine tüm vektörü yapilandirma_ayristir fonksiyonuna geçiriyoruz. yapilandirma_ayristir fonksiyonu daha sonra hangi argümanın hangi değişkene gideceğini belirleyen mantığı tutar ve değerleri main’e geri geçirir. sorgu ve dosya_yolu değişkenlerini hala main’de oluşturuyoruz, ancak main artık komut satırı argümanları ile değişkenlerin nasıl eşleştiğini belirleme sorumluluğuna sahip değildir.
Bu yeniden çalışma, küçük programımız için aşırı görünebilir, ancak küçük, artımlı adımlarla yeniden düzenleme yapıyoruz. Bu değişikliği yaptıktan sonra argüman ayrıştırmanın hâlâ çalıştığını doğrulamak için programı tekrar çalıştırın. Hata oluştuğunda nedenini belirlemeye yardımcı olması açısından ilerlemenizi sık sık kontrol etmek iyidir.
Yapılandırma (Configuration) Değerlerini Gruplamak
yapilandirma_ayristir fonksiyonunu daha da geliştirmek için küçük bir adım daha atabiliriz. Şu anda bir demet döndürüyoruz, ancak daha sonra bu demeti derhal yeniden ayrı parçalara bölüyoruz. Bu, belki de henüz doğru soyutlamaya sahip olmadığımızın bir işaretidir.
Geliştirme için yer olduğunu gösteren bir diğer gösterge de yapilandirma_ayristir’ın (parse_config) yapilandirma (config) kısmıdır; bu da döndürdüğümüz iki değerin ilişkili olduğunu ve her ikisinin de tek bir yapılandırma değerinin parçası olduğunu ima eder. Şu anda iki değeri bir demet içinde gruplamak haricinde bu anlamı verinin yapısında aktarmıyoruz; bunun yerine iki değeri tek bir struct içine koyacağız ve struct alanlarının her birine anlamlı bir ad vereceğiz. Bunu yapmak, bu kodun gelecekteki bakımcılarının farklı değerlerin birbiriyle nasıl ilişki kurduğunu ve amaçlarının ne olduğunu anlamasını kolaylaştıracaktır.
Liste 12-6, yapilandirma_ayristir fonksiyonundaki geliştirmeleri göstermektedir.
use std::env;
use std::fs;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma = yapilandirma_ayristir(&argumanlar);
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
let icerik =
fs::read_to_string(yapilandirma.dosya_yolu).expect("Dosya okunamadı");
// --snip--
println!("Metin içeriği:\n{icerik}");
}
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
fn yapilandirma_ayristir(argumanlar: &[String]) -> Yapilandirma {
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Yapilandirma { sorgu, dosya_yolu }
}Yapilandirma struct’ının bir örneğini döndürmek için yapilandirma_ayristir fonksiyonunu yeniden düzenlemeksorgu ve dosya_yolu adında alanlara (fields) sahip olacak şekilde tanımlanmış Yapilandirma adında bir struct ekledik. yapilandirma_ayristir fonksiyonunun imzası artık bir Yapilandirma değeri döndürdüğünü gösteriyor. yapilandirma_ayristir’ın gövdesinde eskiden argumanlar’daki String değerlerine referans veren string dilimleri döndürdüğümüz yerde, artık Yapilandirma’yı sahiplenilmiş String değerleri içerecek şekilde tanımlıyoruz. main’deki argumanlar değişkeni argüman değerlerinin sahibidir ve yapilandirma_ayristir fonksiyonunun onları sadece ödünç almasına izin verir; yani Yapilandirma, argumanlar’daki değerlerin sahipliğini almaya kalksaydı Rust’ın ödünç alma kurallarını ihlal etmiş olurduk.
String verilerini yönetebileceğimizin pek çok yolu vardır; en kolayı (biraz verimsiz olsa da) değerler üzerinde clone (klonla) metodunu çağırmaktır. Bu, Yapilandirma örneğinin sahip olması için verinin tam bir kopyasını çıkaracaktır, ki bu da string verisine bir referans depolamaktan daha fazla zaman ve bellek gerektirir. Ancak verileri klonlamak, referansların ömürlerini yönetmek zorunda kalmayacağımız için kodumuzu çok daha basit hale getirir; bu durumda basitlik elde etmek için biraz performanstan vazgeçmek değerli bir takastır.
clone Kullanımının Takasları (Trade-Offs)
Birçok Rustacean arasında, çalışma zamanı maliyeti nedeniyle sahiplik sorunlarını düzeltmek için clone kullanmaktan kaçınma eğilimi vardır. Bölüm 13’te, bu tür durumlarda daha verimli metotların nasıl kullanılacağını öğreneceksiniz. Ancak şimdilik ilerlemeye devam etmek için birkaç string’i kopyalamak uygundur çünkü bu kopyaları yalnızca bir kez yapacaksınız ve dosya yolunuz ile sorgu string’iniz çok küçüktür. İlk denemenizde kodunuzu aşırı optimize etmeye çalışmaktansa biraz verimsiz de olsa çalışan bir programa sahip olmak daha iyidir. Rust’ta daha deneyimli hale geldikçe, en verimli çözümle başlamak daha kolay olacaktır ancak şimdilik clone çağırmak kesinlikle kabul edilebilirdir.
yapilandirma_ayristir tarafından döndürülen Yapilandirma örneğini yapilandirma adında bir değişkene yerleştirmesi için main fonksiyonunu güncelledik ve daha önce ayrı sorgu ve dosya_yolu değişkenlerini kullanan kodu, artık bunun yerine Yapilandirma struct’ı üzerindeki alanları kullanacak şekilde güncelledik.
Artık kodumuz, sorgu ve dosya_yolu’nun birbiriyle ilişkili olduğunu ve amaçlarının programın çalışma şeklini yapılandırmak olduğunu daha net bir şekilde yansıtıyor. Bu değerleri kullanan herhangi bir kod, onları yapilandirma örneğinde, amaçlarına göre isimlendirilmiş alanlarda (fields) bulacağını bilir.
Yapilandirma İçin Bir Yapıcı (Constructor) Oluşturmak
Şimdiye kadar, komut satırı argümanlarını ayrıştırmaktan sorumlu mantığı main’den çıkarıp yapilandirma_ayristir fonksiyonuna yerleştirdik. Bunu yapmak sorgu ve dosya_yolu değerlerinin ilişkili olduğunu ve bu ilişkinin kodumuzda aktarılması gerektiğini görmemize yardımcı oldu. Ardından sorgu ve dosya_yolu’nun ilgili amacını isimlendirmek ve değerlerin isimlerini yapilandirma_ayristir fonksiyonundan struct alanı isimleri olarak döndürebilmek için bir Yapilandirma struct’ı ekledik.
Yani artık yapilandirma_ayristir fonksiyonunun amacı bir Yapilandirma örneği oluşturmak olduğuna göre, yapilandirma_ayristir’ı sıradan bir fonksiyondan Yapilandirma struct’ı ile ilişkili new adında bir fonksiyona değiştirebiliriz. Bu değişikliği yapmak kodu daha idiyomatik hale getirecektir. String gibi standart kütüphanedeki türlerin örneklerini String::new fonksiyonunu çağırarak oluşturabiliriz. Benzer şekilde, yapilandirma_ayristir’ı Yapilandirma ile ilişkili bir new fonksiyonuna dönüştürerek Yapilandirma::new fonksiyonunu çağırıp Yapilandirma örnekleri yaratabileceğiz. Liste 12-7 yapmamız gereken değişiklikleri gösteriyor.
use std::env;
use std::fs;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma = Yapilandirma::new(&argumanlar);
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
let icerik =
fs::read_to_string(yapilandirma.dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
// --snip--
}
// --snip--
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn new(argumanlar: &[String]) -> Yapilandirma {
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Yapilandirma { sorgu, dosya_yolu }
}
}yapilandirma_ayristir’ı Yapilandirma::new olarak değiştirmekmain fonksiyonunda daha önce yapilandirma_ayristir çağırdığımız yeri, onun yerine Yapilandirma::new çağıracak şekilde güncelledik. yapilandirma_ayristir adını new (yeni) olarak değiştirdik ve bunu, new fonksiyonunu Yapilandirma ile ilişkilendiren bir impl bloğunun içine taşıdık. Çalıştığından emin olmak için bu kodu tekrar derlemeyi deneyin.
Hata Yönetimini (Error Handling) Düzeltmek
Şimdi hata yönetimimizi düzeltmeye çalışacağız. Vektör üçten daha az öge barındırıyorsa argumanlar vektöründeki değerlere 1. indeks veya 2. indeksten erişme denemesinin programın paniklemesine neden olacağını hatırlayın. Programı herhangi bir argüman olmadan çalıştırmayı deneyin; şu şekilde görünecektir:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: calistir with `RUST_BACKTRACE=1` environment variable to display a backtrace
index out of bounds: the len is 1 but the index is 1 (indeks sınırların dışında: uzunluk 1 ancak indeks 1) satırı, programcılara yönelik bir hata mesajıdır. Bu son kullanıcılarımızın bunun yerine ne yapmaları gerektiğini anlamalarına yardımcı olmayacaktır. Haydi bunu şimdi düzeltelim.
Hata Mesajını İyileştirmek
Liste 12-8’de, new fonksiyonuna 1. indeks ve 2. indekse erişmeden önce dilimin (slice) yeterince uzun olduğunu doğrulayacak bir kontrol ekliyoruz. Eğer dilim yeterince uzun değilse program panikler ve daha iyi bir hata mesajı görüntüler.
use std::env;
use std::fs;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma = Yapilandirma::new(&argumanlar);
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
let icerik =
fs::read_to_string(yapilandirma.dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
}
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
// --snip--
fn new(argumanlar: &[String]) -> Yapilandirma {
if argumanlar.len() < 3 {
panic!("yeterli argüman yok");
}
// --snip--
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Yapilandirma { sorgu, dosya_yolu }
}
}Bu kod Liste 9-13’te yazdığımız Tahmin::new fonksiyonuna benzerdir, burada deger argümanı geçerli değerler aralığı dışındaysa panic! (panik) çağırıyorduk. Burada değerlerin bir aralığını kontrol etmek yerine argumanlar’ın uzunluğunun en az 3 olduğunu kontrol ediyoruz ve fonksiyonun geri kalanı bu koşulun karşılandığı varsayımı altında çalışabiliyor. Eğer argumanlar üçten az ögeye sahipse, bu koşul true olacak ve programı anında sonlandırmak için panic! makrosunu çağıracağız.
new içindeki bu ekstra birkaç satır kodla birlikte hatanın şimdi nasıl göründüğünü görmek için programı herhangi bir argüman olmadan tekrar çalıştıralım:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
yeterli argüman yok
note: calistir with `RUST_BACKTRACE=1` environment variable to display a backtrace
Bu çıktı daha iyi: Artık makul bir hata mesajımız var. Ancak, kullanıcılarımıza vermek istemediğimiz yabancı bilgilerimiz de var. Belki de Liste 9-13’te kullandığımız teknik burada kullanmak için en iyisi değildir: panic! çağrısı, Bölüm 9’da da tartışıldığı üzere, bir kullanım probleminden ziyade bir programlama problemi için daha uygundur. Bunun yerine, Bölüm 9’da öğrendiğiniz diğer tekniği—başarıyı veya hatayı belirten bir Result döndürmeyi kullanacağız.
panic! Çağırmak Yerine Bir Result Döndürmek
Bunun yerine, başarılı durumda bir Yapilandirma örneğini barındıran ve hata durumunda problemi açıklayan bir Result (sonuç) değeri döndürebiliriz. Aynı zamanda fonksiyon adını new’den olustur’a (build) değiştireceğiz, çünkü pek çok programcı new fonksiyonlarının asla başarısız olmamasını bekler. Yapilandirma::olustur main’e bilgi ilettiğinde, bir sorun olduğunu sinyallemek için Result türünü kullanabiliriz. Daha sonra bir panic! çağrısının sebep olduğu thread 'main' ve RUST_BACKTRACE ile ilgili kısımlar olmadan main’i, Err varyantını (seçeneğini) kullanıcılarımız için daha pratik bir hataya dönüştürecek şekilde değiştirebiliriz.
Liste 12-9, şimdi Yapilandirma::olustur olarak adlandırdığımız fonksiyonun dönüş değerinde yapmamız gereken değişiklikleri ve fonksiyon gövdesinde bir Result döndürmek için gerekenleri göstermektedir. Bu kodun, bir sonraki listede (listing) yapacağımız gibi main’i de güncelleyene kadar derlenmeyeceğini unutmayın.
use std::env;
use std::fs;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma = Yapilandirma::new(&argumanlar);
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
let icerik =
fs::read_to_string(yapilandirma.dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
}
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}Yapilandirma::olustur’dan bir Result döndürmekBizim olustur (build) fonksiyonumuz, başarılı (success) durumda bir Yapilandirma örneğiyle ve hatalı durumda bir string sabitiyle bir Result döndürür. Hata değerlerimiz her zaman 'static ömre (lifetime) sahip string sabitleri olacaktır.
Fonksiyonun gövdesinde iki değişiklik yaptık: Artık kullanıcı yeterince argüman aktarmadığında panic! çağırmak yerine bir Err (hata) değeri döndürüyoruz ve Yapilandirma dönüş değerini bir Ok (tamam) içine sarmalıyoruz. Bu değişiklikler fonksiyonun yeni tür imzasına uymasını sağlar.
Yapilandirma::olustur’dan bir Err değeri döndürmek, main fonksiyonunun olustur (build) fonksiyonundan döndürülen Result değerini yönetmesine ve hata durumunda işlemden daha temiz bir şekilde çıkmasına olanak tanır.
Yapilandirma::olustur’u Çağırmak ve Hataları Ele Almak (Handling Errors)
Hata durumunu ele almak ve kullanıcı dostu bir mesaj yazdırmak için Liste 12-10’da gösterildiği gibi Yapilandirma::olustur tarafından döndürülen Result’ı yönetecek şekilde main’i güncellememiz gerekir. Ayrıca, komut satırı aracından sıfır olmayan bir hata koduyla çıkma sorumluluğunu panic!’ten alacak ve bunun yerine elimizle uygulayacağız. Sıfır olmayan bir çıkış durumu, programımızı çağıran prosese (işleme), programın bir hata durumuyla çıktığını bildiren bir kuraldır.
use std::env;
use std::fs;
use std::process;
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
// --snip--
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
let icerik =
fs::read_to_string(yapilandirma.dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
}
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}Yapilandirma oluşturmak başarısız olursa bir hata kodu ile çıkış (exiting) yapmakBu listede henüz detaylı olarak işlemediğimiz bir metodu kullandık: unwrap_or_else, standart kütüphane tarafından Result<T, E> üzerinde tanımlanmıştır. unwrap_or_else kullanmak panic! tabanlı (non-panic!) olmayan bazı özel hata yönetimlerini tanımlamamızı sağlar. Result bir Ok değeri ise, bu metodun davranışı unwrap’e (paketi açmaya) benzer: Ok’un sarmaladığı iç değeri döndürür. Ancak değer bir Err değeri ise bu metot, tanımladığımız ve unwrap_or_else’e argüman olarak geçirdiğimiz anonim bir fonksiyon olan kapanıştaki kodu çağırır. Kapanışları Bölüm 13’te daha detaylı olarak işleyeceğiz. Şimdilik sadece unwrap_or_else’in dikey çubuklar arasında görünen hata (err) argümanındaki kapanışımıza Liste 12-9’da eklediğimiz statik "yeterli argüman yok" string’i olan Err’nin iç değerini ileteceğini bilmeniz gerekir. Daha sonra kapanışın içindeki kod çalıştığında hata değerini kullanabilir.
Standart kütüphaneden process’i (işlem) kapsama almak için yeni bir use satırı ekledik. Hata durumunda çalıştırılacak kapanışın içindeki kod sadece iki satırdan oluşuyor: hata değerini yazdırıyoruz ve ardından process::exit çağırıyoruz. process::exit fonksiyonu programı anında durduracak ve çıkış durum kodu olarak iletilen (passed) numarayı döndürecektir. Bu Liste 12-8’de kullandığımız panic! temelli yönetime benziyor, ancak artık fazladan çıktının hiçbirini almıyoruz. Deneyelim:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Argümanları ayrıştırırken problem oluştu: yeterli argüman yok
Mükemmel! Bu çıktı kullanıcılarımız için çok daha dostane.
Mantığı (Logic) main’den Çıkarmak
Artık yapılandırma ayrıştırmasını yeniden düzenlemeyi bitirdiğimize göre, programın mantığına dönelim. “İkili Projelerde İlgi Alanlarını Ayırmak (Separating Concerns)” kısmında belirttiğimiz gibi, yapılandırmayı ayarlamak veya hataları (errors) ele almak ile ilgili olmayan, şu anda main fonksiyonunda bulunan tüm mantığı tutacak calistir adında bir fonksiyon çıkaracağız. İşimizi bitirdiğimizde main fonksiyonu kısa olacak ve incelemeyle doğrulanması kolaylaşacak, ve tüm diğer mantık için testler yazabileceğiz.
Liste 12-11, calistir fonksiyonunu ayırmanın ufak ve artımlı bir gelişimini gösteriyor.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
calistir(yapilandirma);
}
fn calistir(yapilandirma: Yapilandirma) {
let icerik =
fs::read_to_string(yapilandirma.dosya_yolu).expect("Dosya okunamadı");
println!("Metin içeriği:\n{icerik}");
}
// --snip--
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}calistir fonksiyonunu ayırmakArtık calistir fonksiyonu dosyayı okuma kısmından başlayarak main’in geri kalan mantığının tümünü kapsıyor. calistir fonksiyonu parametre (argument) olarak Yapilandirma örneğini alır.
calistir Fonksiyonundan Hata (Error) Döndürmek
Artık kalan program mantığı calistir fonksiyonuna ayrıldığına göre Liste 12-9’da Yapilandirma::olustur fonksiyonuyla yaptığımız gibi hata yönetimini iyileştirebiliriz. expect fonksiyonunu çağırıp programın panik yapmasına müsaade etmek yerine bir şeyler ters gittiğinde calistir fonksiyonu bir Result<T, E> değeri döndürecek. Bu, hataları yönetmeyle ilgili mantığı kullanıcı dostu bir yolla main’de pekiştirmemize izin verecek. Liste 12-12’de calistir’ın gövdesinde ve imzasında yapmamız gereken değişiklikler yer almaktadır.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
calistir(yapilandirma);
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
println!("Metin içeriği:\n{icerik}");
Ok(())
}
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}Result değeri döndürebilmek için calistir fonksiyonunu değiştirmekBurada üç önemli değişiklik yaptık. Birincisi, calistir fonksiyonunun dönüş türünü Result<(), Box<dyn Error>> olarak değiştirdik. Bu fonksiyon daha önce birim türü olan () döndürüyordu, ve onu Ok (Tamam) durumu için dönen değer olarak tutuyoruz.
Hata türü için, trait (özellik) objesi olan Box<dyn Error>’ı kullandık (ve üstte bir use satırıyla std::error::Error’ı çalışma alanımıza dâhil ettik). Bölüm 18’de trait objelerini detaylı işleyeceğiz. Şimdilik yalnızca Box<dyn Error>’ın fonksiyonun Error (Hata) trait’ini uygulayan bir tür döndüreceği anlamına geldiğini bilmeniz yeterlidir, fakat dönen değerin tam olarak hangi tür olacağını belirlemek zorunda değiliz. Bu da bize farklı hata durumları için farklı türde hatalar döndürebilme esnekliğini kazandırır. dyn anahtar kelimesi dinamik kelimesinin kısaltmasıdır.
İkincisi, Bölüm 9’da bahsettiğimiz gibi ? (soru işareti) operatörü lehine expect çağrısını kaldırdık. Hata durumunda panic! çağırmak yerine, ? mevcut fonksiyondan gelen hatayı fonksiyonu çağıran kısma ele alması için döndürecek.
Üçüncüsü, calistir fonksiyonu artık başarılı durumlarda bir Ok (Tamam) değeri döndürüyor. İmzada calistir fonksiyonunun başarılı dönüş türünün () olacağını belirttik, bu nedenle birim türü değerini Ok değeri ile sarmalamamız gerekir. Başlangıçta bu Ok(()) (Tamam) sözdizimi kulağa biraz garip gelebilir. Fakat () ifadesini bu şekilde kullanmak, calistir fonksiyonunu yalnızca fonksiyonun yapacağı yan etkileri için çağırdığımızın; dolayısıyla da geri döndürdüğü değere ihtiyaç duymadığımızın idiyomatik karşılığıdır.
Bu kodu çalıştırdığınızda derlenecektir fakat ekranda bir uyarıyla karşılaşacaksınız:
$ cargo run -- mezar siir.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:23:5
|
23 | calistir(yapilandirma);
| ^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` (part of `#[warn(unused)]`) on by default
help: use `let _ = ...` to ignore the resulting value
|
23 | let _ = calistir(yapilandirma);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep mezar siir.txt`
Aranan: mezar
Dosya: siir.txt
Metin içeriği:
Ne hasta bekler sabahı,
Ne taze ölüyü mezar.
Ne de şeytan, bir günahı,
Seni beklediğim kadar.
Geçti istemem gelmeni,
Yokluğunda buldum seni;
Bırak vehmimde gölgeni
Gelme, artık neye yarar?
Rust bize yazdığımız kodun bir Result değerini yok saydığını, oysaki bu değerin potansiyel bir hataya işaret edebileceğini söylüyor. Ortada bir hata olup olmadığını kontrol etmiyoruz ve derleyici bize büyük olasılıkla burada bir hata yönetimi (error-handling) yazmayı kastettiğimizi hatırlatıyor! Haydi şimdi o sorunu da halledelim.
main Fonksiyonunda, calistir Fonksiyonundan Dönen Hataların Yönetimi (Handling Errors)
Hataları Liste 12-10’da Yapilandirma::olustur fonksiyonunda kullandığımız tekniğe benzer ufak farklılıkları bulunan bir teknikle kontrol edip ele alacağız:
Dosya adı: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
println!("Aranan: {}", yapilandirma.sorgu);
println!("Dosya: {}", yapilandirma.dosya_yolu);
if let Err(e) = calistir(yapilandirma) {
println!("Uygulama hatası: {e}");
process::exit(1);
}
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
println!("Metin içeriği:\n{icerik}");
Ok(())
}
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}Eğer calistir fonksiyonu bir Err (hata) değeri döndürdüyse bunu tespit edip, programı process::exit(1) komutuyla durdurmak için unwrap_or_else yerine if let komutunu kullandık. calistir fonksiyonu bizim için Yapilandirma::olustur fonksiyonu gibi unwrap ile paketten çıkartıp alabileceğimiz (return) bir değer sunmuyor. Başarılı senaryolarda calistir yalnızca () döndürdüğü için sadece hatayı tespit etmekle ilgileniyoruz; bu sebeple kullanıldığında sadece () döndürecek bir metoda yani unwrap_or_else’e ihtiyacımız yok.
if let ile unwrap_or_else fonksiyonlarının gövdeleri her iki örnekte de tamamen aynıdır: Hatayı yazdırıyoruz ve programdan çıkıyoruz.
Kodu Bir Kütüphane (Library) Crate’ine Ayırmak
Şu ana kadar minigrep projemiz hiç fena durmuyor! Artık src/main.rs dosyasını bölecek ve kodun ufak bir kısmını src/lib.rs dosyasına aktaracağız. Bu sayede kodlarımızı çok daha kolayca test edebilir (test) ve çok daha az sorumluluğa sahip olan bir src/main.rs dosyası yaratabiliriz.
Hadi src/main.rs yerine metni aramaktan sorumlu kodu src/lib.rs’de tanımlayalım, bu bizim (veya minigrep kütüphanemizi kullanan herhangi birinin) arama fonksiyonunu kendi minigrep ikili dosyamızdan daha farklı bağlamlardan çağırmamıza olanak tanır.
İlk olarak, src/lib.rs içerisindeki ara fonksiyonu imzasını Liste 12-13’te gösterildiği üzere bir unimplemented! makrosu ile tanımlayalım. Bir sonraki adımda içini kodlarla doldurduğumuzda imza hakkında daha ayrıntılı açıklama yapıyor olacağız.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
unimplemented!();
}ara fonksiyonunu tanımlamakKütüphane crate’imizin açık bir API’sinin bir parçası olduğunu atamak için fonksiyon tanımlamasında pub anahtar sözcüğünü kullandık. Artık ikili crate’imizden de kolaylıkla kullanılabilecek, test edilebilir bir kütüphane crate’imiz var!
Artık Liste 12-14’te gösterildiği gibi src/lib.rs’de tanımlanan kodu src/main.rs içerisindeki ikili crate’in kapsamına sokmamız ve çağırmamız gerekiyor.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::ara;
fn main() {
// --snip--
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
if let Err(e) = calistir(yapilandirma) {
println!("Uygulama hatası: {e}");
process::exit(1);
}
}
// --snip--
struct Yapilandirma {
sorgu: String,
dosya_yolu: String,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
for satir in ara(&yapilandirma.sorgu, &icerik) {
println!("{satir}");
}
Ok(())
}minigrep kütüphanesinden ara fonksiyonunu çağırmakKütüphane crate’inin içerisindeki ara fonksiyonunu ikili crate’imizin kapsamına alabilmek için kodumuza use minigrep::ara satırını ekledik. Daha sonra, calistir fonksiyonunun içerisinden metni okuyup yazdırmak yerine, ara fonksiyonunu çağırıp içerisine argüman olarak yapilandirma.sorgu (config.query) değeri ile icerik değerini iletiyoruz. Böylelikle calistir, bir for döngüsü vasıtasıyla ara fonksiyonundan dönen ve aranan metne uygun her bir satırı kolaylıkla yazdırabilecektir. Bu aynı zamanda arama sonucunun ekrana başarıyla yansıtıldığı takdirde sadece aranan kelimeye dair bulguları yazdırabilmesi için main fonksiyonunun içerisinde çalıştırdığımız sorgu ile dosya_yolunu yazdıran println! kodlarını da kaldırmak için en uygun zamandır.
Arama fonksiyonunun, herhangi bir yazdırma gerçekleşmeden önce tüm sonuçları döndürdüğü bir vektöre toplayacağını unutmayın. Bu tür bir yaklaşımda, büyük dosyalar üzerinde arama gerçekleştirilirken, bulunan her sonuç bulunduğu an basılamayacağı için çıktı oldukça yavaş verilebilir. Bunu çözmek adına kullanılabilecek olası çözüm olan yineleyicileri Bölüm 13’te işliyor olacağız.
Vay canına! Epey iş başardık, ama gelecekte kodlarımızın başarısı için kendi ayarlamalarımızı şimdiden yapmış olduk. Artık olası hata durumlarını yönetmek (handle errors) ve koda modüler bir görünüm kazandırmak daha kolay. İşimizin neredeyse tamamı bundan sonra src/lib.rs üzerinden gerçekleşecek.
Eski kodlarla yapılamayıp yeni edindiğimiz modüler özelliklerle kazandığımız yeni avantajların tadını, biraz test yazarak kutlayalım!
Test Güdümlü Geliştirme ile İşlevsellik Ekleme
Test Güdümlü Geliştirme (Test-Driven Development) ile İşlevsellik Eklemek
Artık src/lib.rs içerisindeki arama mantığını main fonksiyonundan ayırdığımıza göre, kodumuzun çekirdek işlevselliği için test yazmak çok daha kolaydır. İkili dosyamızı komut satırından çağırmak zorunda kalmadan fonksiyonları çeşitli argümanlarla doğrudan çağırabilir ve dönüş değerlerini kontrol edebiliriz.
Bu bölümde, aşağıdaki adımları içeren test güdümlü geliştirme (test-driven development - TDD) sürecini kullanarak minigrep programına arama mantığını ekleyeceğiz:
- Başarısız olan bir test yazın ve beklediğiniz nedenden dolayı başarısız olduğundan emin olmak için çalıştırın.
- Yeni testin geçmesini sağlayacak kadar kod yazın veya mevcut kodu değiştirin.
- Yeni eklediğiniz veya değiştirdiğiniz kodu yeniden düzenleyin ve testlerin geçmeye devam ettiğinden emin olun.
-
- adımdan itibaren tekrarlayın!
Yazılım geliştirmenin pek çok yolundan yalnızca biri olsa da, TDD kod tasarımını yönlendirmeye yardımcı olabilir. Testin geçmesini sağlayan kodu yazmadan önce testi yazmak, süreç boyunca yüksek test kapsamını sürdürmeye yardımcı olur.
Dosya içeriklerinde aranan string’i gerçekten arayacak ve sorguyla eşleşen (match) satırların bir listesini üretecek işlevselliğin uygulamasını test güdümlü olarak yapacağız. Bu işlevselliği ara adında bir fonksiyona ekleyeceğiz.
Başarısız Olan Bir Test Yazmak
Bölüm 11’de yaptığımız gibi src/lib.rs dosyasına test fonksiyonu içeren bir tests modülü ekleyeceğiz. Test fonksiyonu, ara fonksiyonunun sahip olmasını istediğimiz davranışı belirtir: Bir sorgu ve aranacak metni alacak ve metinden yalnızca sorguyu barındıran satırları döndürecektir. Liste 12-15 bu testi göstermektedir.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn tek_sonuc() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
}ara fonksiyonu için sahip olmak istediğimiz işlevselliğe dair başarısız bir test oluşturmakBu test "güven" string’ini (dizgisini) arar. Aradığımız metin üç satırdan oluşuyor ve bunlardan sadece biri "güven" içeriyor (açılış çift tırnağından sonraki ters eğik çizginin Rust’a bu string sabitinin içeriklerinin başına yeni satır karakteri koymamasını söylediğine dikkat edin). ara fonksiyonundan dönen değerin yalnızca beklediğimiz satırı barındırdığını doğruluyoruz.
Bu testi çalıştırırsak, unimplemented! (uygulanmadı) makrosu “not implemented” (uygulanmadı) mesajıyla paniklediği için şu an başarısız olacaktır. TDD ilkelerine uygun olarak, Liste 12-16’da gösterildiği gibi ara fonksiyonunu her zaman boş bir vektör döndürecek şekilde tanımlayarak fonksiyon çağrıldığında testin paniklememesini sağlayacak kadar kod ekleme yönünde küçük bir adım atacağız. Böylece test derlenmeli (compile) ve başarısız olmalıdır, çünkü boş bir vektör "güvenli, hızlı, üretken." satırını barındıran bir vektörle eşleşmez.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn tek_sonuc() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
}ara fonksiyonunu tanımlamakŞimdi ara fonksiyonunun imzasında açık bir 'a ömrü (lifetime) tanımlamaya ve bu ömrü icerik argümanı ve dönüş değeriyle birlikte kullanmaya neden ihtiyacımız olduğunu tartışalım. Bölüm 10’dan hatırlayın ki, ömür parametreleri hangi argümanın ömrünün dönüş değerinin ömrüne bağlandığını belirtir. Bu durumda, döndürülen vektörün (sorgu argümanı yerine) icerik argümanının dilimlerine referans veren string dilimleri içermesi gerektiğini belirtiyoruz.
Başka bir deyişle, Rust’a ara fonksiyonu tarafından döndürülen verinin, ara fonksiyonuna icerik argümanıyla aktarılan veri kadar uzun yaşayacağını (live as long as) söylüyoruz. Bu önemlidir! Bir dilim (slice) tarafından atıfta bulunulan (referenced) verinin, referansın geçerli olması için geçerli olması (valid) gerekir; eğer derleyici icerik yerine sorgu’nun string dilimlerini oluşturduğumuzu varsayarsa, güvenlik denetimini yanlış yapacaktır.
Ömür açıklamalarını unutup bu fonksiyonu derlemeye çalışırsak şu hatayı alırız:
$ cargo olustur
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn ara(sorgu: &str, icerik: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `sorgu` or `icerik`
help: consider introducing a named lifetime parameter
|
1 | pub fn ara<'a>(sorgu: &'a str, icerik: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust çıktı için iki parametreden hangisine ihtiyacımız olduğunu bilemez, bu nedenle bunu açıkça söylememiz gerekir. Yardım metninin tüm parametreler ve çıktı türü için aynı ömür parametresinin belirtilmesini önerdiğine dikkat edin, ki bu yanlıştır! Tüm metnimizi barındıran parametre icerik olduğundan ve metnin eşleşen parçalarını döndürmek istediğimizden, ömür sözdizimini kullanarak dönüş değerine bağlanması gereken tek parametrenin icerik olduğunu biliyoruz.
Diğer programlama dilleri, imzadaki argümanları dönüş değerlerine bağlamanızı gerektirmez ancak bu pratik zamanla kolaylaşacaktır. Bu örneği Bölüm 10’daki “Ömürlerle Referansları Doğrulamak” bölümündeki örneklerle karşılaştırmak isteyebilirsiniz.
Testi Geçecek Kodu Yazmak
Şu anda testimiz başarısız oluyor çünkü her zaman boş bir vektör döndürüyoruz. Bunu düzeltmek ve ara’yı uygulamak için programımızın şu adımları izlemesi gerekir:
- İçeriğin her satırı üzerinde yineleme yapın.
- Satırın sorgu string’imizi içerip içermediğini kontrol edin.
- İçeriyorsa, döndürdüğümüz değerler listesine ekleyin.
- İçermiyorsa, hiçbir şey yapmayın.
- Eşleşen sonuçların listesini döndürün.
Satırlar üzerinde yineleme yapmakla başlayarak her bir adım üzerinde çalışalım.
lines Metodu ile Satırlar Üzerinde Yineleme (Iterating) Yapmak
Rust, stringlerin satır satır yinelemesini işlemek için Liste 12-17’de gösterildiği gibi çalışan ve uygun bir şekilde lines (satırlar) olarak adlandırılan yararlı bir metoda sahiptir. Bunun henüz derlenmeyeceğini unutmayın.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
for satir in icerik.lines() {
// satir ile bir şeyler yapın
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn tek_sonuc() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
}icerik’teki her bir satır üzerinde yineleme yapmaklines metodu bir yineleyici döndürür. Yineleyicileri Bölüm 13’te derinlemesine tartışacağız. Ancak yineleyicinin bu kullanım şeklini Liste 3-5’te gördüğünüzü hatırlayın; burada bir koleksiyondaki her bir öğe üzerinde bir miktar kod çalıştırmak için bir yineleyici ile birlikte bir for döngüsü kullanmıştık.
Her Satırda Sorguyu (Query) Aramak
Sırada o anki satırın sorgu string’imizi barındırıp barındırmadığını kontrol edeceğiz. Neyse ki stringlerin bunu bizim için yapan contains (içerir) adlı yararlı bir metodu var! Liste 12-18’de gösterildiği gibi ara fonksiyonuna contains metodu çağrısı ekleyin. Bunun hala derlenmeyeceğini unutmayın.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
for satir in icerik.lines() {
if satir.contains(sorgu) {
// satir ile bir şeyler yapın
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn tek_sonuc() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
}sorgu’daki string’i barındırıp barındırmadığını görmek için işlevsellik eklemekŞu anda işlevselliği oluşturuyoruz. Kodun derlenmesini sağlamak için fonksiyon imzasında yapacağımızı belirttiğimiz gibi gövdeden bir değer döndürmemiz (return) gerekiyor.
Eşleşen Satırları Depolamak
Bu fonksiyonu bitirmek için, döndürmek istediğimiz eşleşen satırları saklayacak bir yola ihtiyacımız var. Bunun için for döngüsünden önce değiştirilebilir bir vektör oluşturabilir ve satir’ı vektörde depolamak için push (it) metodunu çağırabiliriz. for döngüsünden sonra, Liste 12-19’da gösterildiği gibi vektörü döndürürüz.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
let mut sonuclar = Vec::new();
for satir in icerik.lines() {
if satir.contains(sorgu) {
sonuclar.push(satir);
}
}
sonuclar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn tek_sonuc() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
}Artık ara fonksiyonu sadece sorgu içeren satırları döndürmelidir ve testimiz geçmelidir. Testi çalıştıralım:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::tek_sonuc ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Testimiz geçti, yani çalıştığını biliyoruz!
Bu noktada, aynı işlevselliği sürdürmek adına testleri geçer durumda tutarken arama fonksiyonunun uygulamasını yeniden düzenleme fırsatlarını değerlendirebiliriz. Arama fonksiyonundaki kod çok kötü değil, ancak yineleyicilerin bazı yararlı özelliklerinden yararlanmıyor. Bölüm 13’te yineleyicileri ayrıntılı olarak inceleyeceğimiz bu örneğe geri döneceğiz ve nasıl iyileştireceğimize bakacağız.
Artık programın tamamı çalışmalı! Önce şiirden tam olarak bir satır döndürmesi gereken bir kelimeyle deneyelim: mezar.
$ cargo run -- mezar siir.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep mezar siir.txt`
Ne taze ölüyü mezar.
Harika! Şimdi bek gibi birden fazla satırla eşleşecek bir kelime deneyelim:
$ cargo run -- bek siir.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep bek siir.txt`
Ne hasta bekler sabahı,
Seni beklediğim kadar.
Ve son olarak, şiirde hiçbir yerde olmayan bir kelimeyi (örneğin monomorphization) aradığımızda hiçbir satır almadığımızdan emin olalım:
$ cargo run -- monomorphization siir.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization siir.txt`
Mükemmel! Klasik bir aracın kendi mini versiyonunu oluşturduk ve uygulamaların nasıl yapılandırılacağı hakkında çok şey öğrendik. Ayrıca dosya giriş ve çıkışları, ömürler, testler ve komut satırı ayrıştırma hakkında biraz bilgi edindik.
Bu projeyi tamamlamak için çevre değişkenleriyle (environment variables) nasıl çalışılacağını ve standart hataya (standard error) nasıl yazdırılacağını kısaca göstereceğiz; her ikisi de komut satırı programları yazarken yararlıdır.
Çevre Değişkenleri ile Çalışma
Çevre Değişkenleriyle (Environment Variables) Çalışmak
minigrep ikili dosyasına ek bir özellik (feature) ekleyerek onu iyileştireceğiz: kullanıcının bir çevre değişkeni aracılığıyla açabileceği büyük/küçük harf duyarsız arama seçeneği. Bu özelliği bir komut satırı seçeneği (command line option) haline getirebilir ve kullanıcıların bunu her uygulamak istediklerinde girmelerini gerektirebilirdik, ancak bunun yerine onu bir çevre değişkeni haline getirerek, kullanıcılarımızın çevre değişkenini bir kez ayarlamasına ve o terminal oturumundaki tüm aramalarının büyük/küçük harfe duyarsız olmasına izin veriyoruz.
Büyük/Küçük Harf Duyarsız Arama Fonksiyonu İçin Başarısız Olan Bir Test Yazmak
İlk olarak minigrep kütüphanesine, çevre değişkeninin bir değeri olduğunda çağrılacak olan buyuk_kucuk_harf_duyarsiz_ara adlı yeni bir fonksiyon ekliyoruz. TDD (test güdümlü geliştirme) sürecini takip etmeye devam edeceğiz, bu nedenle ilk adım yine başarısız olan bir test yazmaktır. Yeni buyuk_kucuk_harf_duyarsiz_ara fonksiyonu için yeni bir test ekleyeceğiz ve iki test arasındaki farkları netleştirmek için Liste 12-20’de gösterildiği gibi eski testimizi tek_sonuc (one_result) yerine buyuk_kucuk_harf_duyarli (case_sensitive) olarak yeniden adlandıracağız.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
let mut sonuclar = Vec::new();
for satir in icerik.lines() {
if satir.contains(sorgu) {
sonuclar.push(satir);
}
}
sonuclar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn buyuk_kucuk_harf_duyarli() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.
Güven kolay kazanılmaz.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
#[test]
fn buyuk_kucuk_harf_duyarsiz() {
let sorgu = "güven";
let icerik = "\
Güven:
önce sağlamlık gelir.
Planlı çalış, sakin ol.
güven kazanılır.";
assert_eq!(
vec!["Güven:", "güven kazanılır."],
buyuk_kucuk_harf_duyarsiz_ara(sorgu, icerik)
);
}
}Eski testin icerik kısmını da düzenlediğimize dikkat edin. Büyük/küçük harf duyarlı bir şekilde arama yaptığımızda "güven" sorgusuyla eşleşmemesi gereken, büyük G kullanan "Güven kolay kazanılmaz." metnine sahip yeni bir satır ekledik. Eski testi bu şekilde değiştirmek, daha önce uyguladığımız büyük/küçük harf duyarlı arama işlevselliğini yanlışlıkla bozmadığımızdan emin olmamıza yardımcı olur. Bu test şimdi geçmeli ve biz büyük/küçük harf duyarsız arama üzerinde çalışırken de geçmeye devam etmelidir.
Büyük/küçük harf duyarsız arama için yeni test sorgu olarak "gÜvEn" kullanıyor. Eklemek üzere olduğumuz buyuk_kucuk_harf_duyarsiz_ara fonksiyonunda "gÜvEn" sorgusu, büyük G harfi içeren "Güven:" satırıyla eşleşmeli ve her ikisi de sorgudan farklı büyük/küçük harf kullanımına sahip olsa bile "güven kazanılır." satırıyla da eşleşmelidir. Bu bizim başarısız (failing) testimizdir ve derlenemeyecektir çünkü henüz buyuk_kucuk_harf_duyarsiz_ara fonksiyonunu tanımlamadık. Testin derlendiğini ve başarısız olduğunu görmek için Liste 12-16’da ara fonksiyonu için yaptığımıza benzer şekilde her zaman boş bir vektör döndüren iskelet bir uygulama eklemekten çekinmeyin.
buyuk_kucuk_harf_duyarsiz_ara Fonksiyonunu Uygulamak (Implementing)
Liste 12-21’de gösterilen buyuk_kucuk_harf_duyarsiz_ara fonksiyonu, ara fonksiyonu ile neredeyse aynı olacaktır. Tek fark, girdi argümanlarının durumu ne olursa olsun, satırın sorguyu barındırıp barındırmadığını (contains) kontrol ettiğimizde aynı durumda olmaları için sorguyu ve her bir satirı küçük harfe dönüştürecek olmamızdır.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
let mut sonuclar = Vec::new();
for satir in icerik.lines() {
if satir.contains(sorgu) {
sonuclar.push(satir);
}
}
sonuclar
}
pub fn buyuk_kucuk_harf_duyarsiz_ara<'a>(
sorgu: &str,
icerik: &'a str,
) -> Vec<&'a str> {
let sorgu = sorgu.to_lowercase();
let mut sonuclar = Vec::new();
for satir in icerik.lines() {
if satir.to_lowercase().contains(&sorgu) {
sonuclar.push(satir);
}
}
sonuclar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn buyuk_kucuk_harf_duyarli() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.
Güven kolay kazanılmaz.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
#[test]
fn buyuk_kucuk_harf_duyarsiz() {
let sorgu = "güven";
let icerik = "\
Güven:
önce sağlamlık gelir.
Planlı çalış, sakin ol.
güven kazanılır.";
assert_eq!(
vec!["Güven:", "güven kazanılır."],
buyuk_kucuk_harf_duyarsiz_ara(sorgu, icerik)
);
}
}buyuk_kucuk_harf_duyarsiz_ara fonksiyonunu tanımlamakÖnce, orijinal sorguyu gölgeleyerek, sorgu string’ini (dizgisini) küçük harfe dönüştürüyoruz ve aynı isimli yeni bir değişkende saklıyoruz. Sorgu üzerinde to_lowercase (küçük harfe dönüştür) çağırmak gereklidir, böylece kullanıcının sorgusu "güven", "GÜVEN", "Güven" veya "gÜvEn" olursa olsun sorguyu sanki "güven" imiş gibi ele alırız ve büyük/küçük harfe duyarsız oluruz. to_lowercase temel Unicode’u işleyebilecek olsa da yüzde 100 doğru olmayacaktır. Gerçek bir uygulama yazıyor olsaydık burada biraz daha fazla iş yapmak isterdik, ancak bu bölüm Unicode değil çevre değişkenleri (environment variables) ile ilgili olduğu için şimdilik bunu bu şekilde bırakacağız.
sorgu’nun artık bir string dilimi olmaktan ziyade (rather than) bir String olduğuna dikkat edin, çünkü to_lowercase çağırmak mevcut verilere referans vermek yerine yeni veriler oluşturur. Örnek olarak sorgunun "gÜvEn" olduğunu varsayalım: Bu string dilimi kullanabileceğimiz küçük harfli bir u veya e barındırmaz, bu nedenle "güven" içeren yeni bir String tahsis etmemiz gerekir. Şimdi contains metoduna argüman olarak sorgu’yu aktardığımızda, bir ampersand (ve işareti - &) eklememiz gerekir çünkü contains’in imzası bir string dilimi alacak şekilde tanımlanmıştır.
Sonra, tüm karakterleri küçük harfe dönüştürmek için her satir üzerinde bir to_lowercase çağrısı ekliyoruz. Artık satir ve sorguyu küçük harfe dönüştürdüğümüze göre sorgunun büyük/küçük harf durumu ne olursa olsun eşleşmeleri bulacağız.
Bakalım bu uygulama testleri geçecek mi:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::buyuk_kucuk_harf_duyarsiz ... ok
test tests::buyuk_kucuk_harf_duyarli ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Harika! Geçtiler. Şimdi calistir fonksiyonundan yeni buyuk_kucuk_harf_duyarsiz_ara fonksiyonunu çağıralım. İlk olarak Yapilandirma struct’ına, büyük/küçük harfe duyarlı ve duyarsız arama arasında geçiş yapmak için bir yapılandırma seçeneği ekleyeceğiz. Bu alanı eklemek derleyici hatalarına neden olacaktır çünkü henüz hiçbir yerde bu alanı ilklendirmiyoruz:
Dosya adı: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
// --snip--
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
if let Err(e) = calistir(yapilandirma) {
println!("Uygulama hatası: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
let sonuclar = if yapilandirma.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&yapilandirma.sorgu, &icerik)
} else {
ara(&yapilandirma.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}Bir Boolean (mantıksal değer) barındıran buyuk_kucuk_harf_yoksay alanını ekledik. Ardından Liste 12-22’de gösterildiği gibi calistir fonksiyonunun buyuk_kucuk_harf_yoksay alanının değerini kontrol etmesine ve bunu ara fonksiyonunu mu yoksa buyuk_kucuk_harf_duyarsiz_ara fonksiyonunu mu çağıracağına karar vermek için kullanmasına ihtiyacımız var. Bu henüz derlenmeyecektir.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
// --snip--
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
if let Err(e) = calistir(yapilandirma) {
println!("Uygulama hatası: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
Ok(Yapilandirma { sorgu, dosya_yolu })
}
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
let sonuclar = if yapilandirma.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&yapilandirma.sorgu, &icerik)
} else {
ara(&yapilandirma.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}yapilandirma.buyuk_kucuk_harf_yoksay içerisindeki değere bağlı olarak ara ya da buyuk_kucuk_harf_duyarsiz_ara fonksiyonunu çağırmakSon olarak çevre değişkenini kontrol etmemiz gerekiyor. Çevre değişkenleriyle çalışmak için gerekli fonksiyonlar, halihazırda src/main.rs dosyasının en üstünde kapsama dahil edilmiş olan (in scope) standart kütüphanedeki env modülündedir. Liste 12-23’te gösterildiği gibi IGNORE_CASE (BÜYÜK KÜÇÜK HARF YOKSAY) adlı bir çevre değişkeni için herhangi bir değer ayarlanıp ayarlanmadığını görmek üzere env modülündeki var fonksiyonunu kullanacağız.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
println!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
if let Err(e) = calistir(yapilandirma) {
println!("Uygulama hatası: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
let sonuclar = if yapilandirma.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&yapilandirma.sorgu, &icerik)
} else {
ara(&yapilandirma.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}IGNORE_CASE isimli bir çevre değişkeninde herhangi bir değer olup olmadığını kontrol etmekBurada buyuk_kucuk_harf_yoksay adında yeni bir değişken oluşturuyoruz. Değerini ayarlamak için env::var fonksiyonunu çağırıyor ve ona IGNORE_CASE çevre değişkeninin adını aktarıyoruz. env::var fonksiyonu, çevre değişkeni herhangi bir değere ayarlanmışsa, çevre değişkeninin değerini içeren başarılı Ok varyantını (seçeneğini) döndürecek bir Result (Sonuç) döndürür. Eğer çevre değişkeni ayarlanmamışsa Err (Hata) varyantını döndürecektir.
Çevre değişkeninin ayarlanıp ayarlanmadığını kontrol etmek için Result üzerindeki is_ok metodunu kullanıyoruz, bu da programın büyük/küçük harf duyarsız arama yapması gerektiği anlamına gelir. Eğer IGNORE_CASE çevre değişkeni herhangi bir değere ayarlanmamışsa, is_ok false (yanlış) değerini döndürecektir ve program büyük/küçük harf duyarlı arama gerçekleştirecektir. Çevre değişkeninin değeri umurumuzda değil, sadece ayarlanmış veya ayarlanmamış olması önemli, bu nedenle unwrap, expect veya Result üzerinde gördüğümüz diğer metotları kullanmak yerine is_ok komutunu kontrol ediyoruz.
buyuk_kucuk_harf_yoksay değişkenindeki değeri Yapilandirma örneğine geçiriyoruz, böylece Liste 12-22’de uyguladığımız (implemented) gibi calistir fonksiyonu o değeri okuyabilir ve buyuk_kucuk_harf_duyarsiz_ara mı yoksa ara mı çağıracağına karar verebilir.
Haydi bir deneyelim! İlk olarak programımızı, çevre değişkeni ayarlanmadan ve tamamı küçük harflerden oluşan ne sorgusuyla çalıştıracağız. Büyük/küçük harfe duyarlı aramada yalnızca gerçekten küçük harfli ne geçen satırın dönmesini bekleriz:
$ cargo run -- ne siir.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep ne siir.txt`
Gelme, artık neye yarar?
Görünüşe göre hala çalışıyor! Şimdi programı IGNORE_CASE (BÜYÜK KÜÇÜK HARF YOKSAY) 1’e ayarlanmış olarak fakat aynı ne sorgusuyla çalıştıralım:
$ IGNORE_CASE=1 cargo run -- ne siir.txt
PowerShell kullanıyorsanız, çevre değişkenini ayarlamanız ve programı ayrı komutlar olarak çalıştırmanız gerekir:
PS> $Env:IGNORE_CASE=1; cargo run -- ne siir.txt
Bu IGNORE_CASE’in shell (kabuk) oturumunuzun geri kalanı boyunca kalıcı olmasını sağlayacaktır. Remove-Item cmdlet’i ile kaldırılabilir:
PS> Remove-Item Env:IGNORE_CASE
Büyük/küçük harf duyarsız arama sayesinde Ne ile başlayan satırları da elde etmeliyiz:
Ne hasta bekler sabahı,
Ne taze ölüyü mezar.
Ne de şeytan, bir günahı,
Gelme, artık neye yarar?
Mükemmel, artık hem Ne ile başlayan satırları hem de küçük harfli ne geçen satırı aldık! Bizim minigrep programımız artık bir çevre değişkeni tarafından kontrol edilen büyük/küçük harf duyarsız arama yapabiliyor. Artık komut satırı argümanları (command line arguments) veya çevre değişkenleri kullanarak belirlenen seçenekleri nasıl yöneteceğinizi biliyorsunuz.
Bazı programlar aynı yapılandırma için hem argümanlara hem de çevre değişkenlerine izin verir. Böyle durumlarda, programlar birinin veya diğerinin öncelikli olduğuna karar verir. Kendi başınıza yapacağınız bir başka alıştırma olarak büyük/küçük harf duyarlılığını bir komut satırı argümanı veya bir çevre değişkeni aracılığıyla kontrol etmeyi deneyin. Programın biri büyük/küçük harf duyarlı, diğeri büyük/küçük harf yoksay olarak ayarlanmış şekilde çalıştırılması durumunda komut satırı argümanının mı yoksa çevre değişkeninin mi öncelikli olması gerektiğine karar verin.
std::env modülü çevre değişkenleriyle ilgilenmek için çok daha yararlı özellikler barındırır: Nelerin mevcut olduğunu görmek için belgesine göz atın.
Hataları Standart Hata Çıktısına Yönlendirme
Hataları Standart Hataya (Standard Error) Yönlendirmek
Şu anda println! makrosunu kullanarak tüm çıktılarımızı terminale yazıyoruz. Çoğu terminalde iki tür çıktı vardır: Genel bilgiler için standart çıktı (stdout) ve hata mesajları için standart hata (stderr). Bu ayrım, kullanıcıların bir programın başarılı çıktısını bir dosyaya yönlendirmeyi, ancak hata mesajlarını yine de ekrana yazdırmayı seçmesini sağlar.
println! makrosu yalnızca standart çıktıya yazdırma yeteneğine sahiptir, bu yüzden standart hataya yazdırmak için başka bir şey kullanmalıyız.
Hataların Nereye Yazıldığını Kontrol Etmek
İlk olarak, standart hataya yazdırmak istediğimiz hata mesajları da dahil olmak üzere, minigrep tarafından yazdırılan içeriğin şu anda standart çıktıya nasıl yazıldığını gözlemleyelim. Bunu standart çıktı akışını bilerek bir hataya neden olurken bir dosyaya yönlendirerek yapacağız. Standart hata akışını yönlendirmeyeceğiz, bu nedenle standart hataya gönderilen herhangi bir içerik ekranda görüntülenmeye devam edecektir.
Komut satırı programlarının hata mesajlarını standart hata akışına göndermesi beklenir, böylece standart çıktı akışını bir dosyaya yönlendirsek bile hata mesajlarını ekranda görebiliriz. Programımız şu anda iyi davranmıyor: Bunun yerine hata mesajı çıktısını bir dosyaya kaydettiğini görmek üzereyiz!
Bu davranışı göstermek için, programı > ve standart çıktı akışını yönlendirmek istediğimiz ciktilar.txt (output.txt) dosya yolu ile çalıştıracağız. Bir hataya neden olması gereken herhangi bir argümanı iletmeyeceğiz:
$ cargo run > ciktilar.txt
> sözdizimi, kabuğa standart çıktının içeriğini ekran yerine ciktilar.txt dosyasına yazmasını söyler. Ekrana yazdırılmasını beklediğimiz hata mesajını görmedik, bu da mesajın dosyaya gittiği anlamına gelir. ciktilar.txt dosyasının içerdiği şey budur:
Argümanları ayrıştırırken problem oluştu: yeterli argüman yok
Evet, hata mesajımız standart çıktıya yazdırılıyor. Bu gibi hata mesajlarının standart hataya yazdırılması çok daha yararlıdır, böylece dosyaya yalnızca başarılı bir çalıştırmadan elde edilen veriler gider. Bunu değiştireceğiz.
Hataları Standart Hataya (Standard Error) Yazdırmak
Hata mesajlarının yazdırılma şeklini değiştirmek için Liste 12-24’teki kodu kullanacağız. Bu bölümün başlarında yaptığımız yeniden düzenleme nedeniyle, hata mesajlarını yazdıran tüm kodlar tek bir fonksiyonda, yani main içindedir. Standart kütüphane, standart hata akışına yazdıran eprintln! makrosunu sağlar, bu nedenle println! çağırdığımız iki yeri, hata yazdırmak için bunun yerine eprintln! kullanacak şekilde değiştirelim.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let argumanlar: Vec<String> = env::args().collect();
let yapilandirma =
Yapilandirma::olustur(&argumanlar).unwrap_or_else(|hata| {
eprintln!("Argümanları ayrıştırırken problem oluştu: {hata}");
process::exit(1);
});
if let Err(e) = calistir(yapilandirma) {
eprintln!("Uygulama hatası: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(yapilandirma: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(yapilandirma.dosya_yolu)?;
let sonuclar = if yapilandirma.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&yapilandirma.sorgu, &icerik)
} else {
ara(&yapilandirma.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}eprintln! kullanarak hata mesajlarını standart çıktı yerine standart hataya yazmakŞimdi programı hiçbir argüman olmadan ve standart çıktıyı > ile yönlendirerek aynı şekilde tekrar çalıştıralım:
$ cargo run > ciktilar.txt
Argümanları ayrıştırırken problem oluştu: yeterli argüman yok
Artık hatayı ekranda görüyoruz ve ciktilar.txt hiçbir şey içermiyor ki bu da komut satırı programlarından beklediğimiz davranıştır.
Hata vermeyen ancak standart çıktıyı yine de aşağıdaki gibi bir dosyaya yönlendiren argümanlarla programı tekrar çalıştıralım:
$ cargo run -- ne siir.txt > ciktilar.txt
Terminalde herhangi bir çıktı görmeyeceğiz ve ciktilar.txt sonuçlarımızı barındıracak:
Dosya adı: ciktilar.txt
Gelme, artık neye yarar?
Bu, uygun olduğu şekilde başarılı çıktılar için standart çıktıyı ve hata çıktıları için standart hatayı kullandığımızı gösterir.
Özet
Bu bölüm, şimdiye kadar öğrendiğiniz bazı önemli kavramları özetledi ve Rust’ta yaygın G/Ç (I/O) işlemlerinin nasıl gerçekleştirileceğini ele aldı. Komut satırı argümanlarını (command line arguments), dosyaları, çevre değişkenlerini (environment variables) ve hataları yazdırmak için eprintln! makrosunu kullanarak, artık komut satırı uygulamaları yazmaya hazırsınız. Önceki bölümlerdeki kavramlarla birleştirildiğinde, kodunuz iyi organize edilmiş olacak, verileri uygun veri yapılarında etkili bir şekilde depolayacak, hataları güzel bir şekilde yönetecek ve iyi test edilmiş olacaktır.
Sırada fonksiyonel dillerden etkilenen bazı Rust özelliklerini inceleyeceğiz: kapanışlar ve yineleyiciler.
Fonksiyonel Dil Özellikleri: Yineleyiciler (Iterators) ve Kapanışlar (Closures)
Rust’ın tasarımı mevcut birçok dilden ve teknikten ilham almıştır ve önemli etkilerden biri de fonksiyonel programlamadır (functional programming). Fonksiyonel tarzda programlama genellikle fonksiyonları argüman olarak ileterek, diğer fonksiyonlardan döndürerek, daha sonra çalıştırılmak üzere değişkenlere atayarak (ve benzeri şekillerde) değer olarak kullanmayı içerir.
Bu bölümde, fonksiyonel programlamanın ne olup olmadığı tartışmasına girmeyeceğiz; bunun yerine Rust’ın, genellikle “fonksiyonel” olarak adlandırılan birçok dildeki özelliklere benzeyen bazı özelliklerini tartışacağız.
Daha spesifik olarak şunları ele alacağız:
- Bir değişkende saklayabileceğiniz, fonksiyona benzeyen bir yapı olan Kapanışlar (Closures)
- Bir dizi ögeyi (element) işlemenin (processing) bir yolu olan Yineleyiciler (Iterators)
- Bölüm 12’deki G/Ç (I/O) projesini geliştirmek için kapanışların ve yineleyicilerin nasıl kullanılacağı
- Kapanışların ve yineleyicilerin performansı (sürprizbozan: Düşündüğünüzden daha hızlıdırlar!)
Bölüm 6’da işlediğimiz desen eşleştirme ve enum’lar gibi, fonksiyonel tarzdan etkilenen bazı diğer Rust özelliklerini zaten ele almıştık. Kapanışlarda ve yineleyicilerde uzmanlaşmak (mastering), hızlı ve idiyomatik Rust kodu yazmanın önemli bir parçası olduğundan, bu bölümün tamamını onlara ayıracağız.
Kapanışlar (Closures)
Kapanışlar (Closures)
Rust’taki kapanışlar, bir değişkende saklayabileceğiniz veya diğer fonksiyonlara argüman olarak aktarabileceğiniz anonim fonksiyonlardır (anonymous functions). Kapanışı tek bir yerde oluşturabilir ve daha sonra kapanışı farklı bir bağlamda (context) değerlendirmek üzere başka bir yerde çağırabilirsiniz. Fonksiyonların aksine, kapanışlar tanımlandıkları kapsamdaki değerleri yakalayabilirler (capture). Bu kapanış özelliklerinin kodun yeniden kullanımına (code reuse) ve davranışların özelleştirilmesine (behavior customization) nasıl olanak tanıdığını göstereceğiz.
Çevreyi Yakalamak (Capturing the Environment)
İlk olarak, daha sonra kullanmak üzere tanımlandıkları çevredeki değerleri yakalamak için kapanışları nasıl kullanabileceğimizi inceleyeceğiz. Senaryomuz şu: Tişört şirketimiz arada bir, promosyon olarak e-posta listemizdeki (mailing list) birine özel, sınırlı sayıda üretilmiş bir gömlek (shirt) hediye ediyor. E-posta listesindeki kişiler isteğe bağlı olarak profillerine favori renklerini ekleyebilirler. Ücretsiz gömlek için seçilen kişinin favori rengi ayarlanmışsa o renk gömleği alır. Kişi favori bir renk belirtmemişse şirkette şu anda en çok hangi renk varsa onu alır.
Bunu uygulamanın pek çok yolu vardır. Bu örnek için, Kirmizi ve Mavi varyantlarına (seçeneklerine) sahip GomlekRengi adlı bir enum kullanacağız (basitlik adına mevcut renk sayısını sınırlıyoruz). Şirketin envanterini, şu anda stokta bulunan gömlek renklerini temsil eden bir Vec<GomlekRengi> barındıran gomlekler adlı bir alana (field) sahip Envanter struct’ı ile temsil ediyoruz. Envanter üzerinde tanımlanan hediye_et metodu, ücretsiz gömlek kazananın isteğe bağlı (optional) gömlek rengi tercihini alır ve kişinin alacağı gömlek rengini döndürür. Bu kurulum Liste 13-1’de gösterilmiştir.
#[derive(Debug, PartialEq, Copy, Clone)]
enum GomlekRengi {
Kirmizi,
Mavi,
}
struct Envanter {
gomlekler: Vec<GomlekRengi>,
}
impl Envanter {
fn hediye_et(&self, kullanici_tercihi: Option<GomlekRengi>) -> GomlekRengi {
kullanici_tercihi.unwrap_or_else(|| self.en_cok_stoklanan())
}
fn en_cok_stoklanan(&self) -> GomlekRengi {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.gomlekler {
match color {
GomlekRengi::Kirmizi => num_red += 1,
GomlekRengi::Mavi => num_blue += 1,
}
}
if num_red > num_blue {
GomlekRengi::Kirmizi
} else {
GomlekRengi::Mavi
}
}
}
fn main() {
let magaza = Envanter {
gomlekler: vec![GomlekRengi::Mavi, GomlekRengi::Kirmizi, GomlekRengi::Mavi],
};
let kullanici_tercihi1 = Some(GomlekRengi::Kirmizi);
let giveaway1 = magaza.hediye_et(kullanici_tercihi1);
println!(
"{:?} tercihine sahip kullanıcı {:?} alıyor",
kullanici_tercihi1, giveaway1
);
let kullanici_tercihi2 = None;
let giveaway2 = magaza.hediye_et(kullanici_tercihi2);
println!(
"{:?} tercihine sahip kullanıcı {:?} alıyor",
kullanici_tercihi2, giveaway2
);
}main fonksiyonunda tanımlanan magaza, bu sınırlı üretim promosyonu için dağıtılmak üzere kalan iki mavi gömleğe ve bir kırmızı gömleğe sahiptir. Kırmızı gömlek tercih eden bir kullanıcı için ve tercihi olmayan bir kullanıcı için hediye_et metodunu çağırıyoruz.
Yine, bu kod birçok şekilde uygulanabilirdi ve burada kapanışlara odaklanmak için, kapanış kullanan hediye_et metodunun gövdesi hariç olmak üzere daha önce öğrendiğiniz kavramlara bağlı kaldık. hediye_et metodunda, kullanıcı tercihini Option<GomlekRengi> türünde bir parametre olarak alıyoruz ve kullanici_tercihi üzerinde unwrap_or_else metodunu çağırıyoruz. Option<T> üzerindeki unwrap_or_else metodu standart kütüphane tarafından tanımlanır. Bir argüman alır: herhangi bir argümanı olmayan ve T değerini (bu durumda GomlekRengi olmak üzere Option<T>’nin Some varyantında saklanan aynı tür) döndüren bir kapanış. Option<T> Some varyantı ise unwrap_or_else Some içinden değeri döndürür. Option<T> None varyantı ise unwrap_or_else kapanışı çağırır ve kapanış tarafından döndürülen değeri döndürür.
unwrap_or_else’e argüman olarak || self.en_cok_stoklanan() (|| self.most_stocked()) kapanış ifadesini belirtiyoruz. Bu, kendi başına hiçbir parametre almayan bir kapanıştır (kapanışın parametreleri olsaydı, iki dikey çubuk arasında görünüverirdi). Kapanışın gövdesi self.en_cok_stoklanan()’ı çağırır. Kapanışı burada tanımlıyoruz ve unwrap_or_else’in uygulaması sonuca ihtiyaç duyulursa kapanışı daha sonra değerlendirecektir.
Bu kodu çalıştırmak aşağıdakini yazdırır:
$ cargo run
Compiling gomlek-sirketi v0.1.0 (file:///projects/gomlek-sirketi)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/gomlek-sirketi`
The user with preference Some(Kirmizi) gets Kirmizi
The user with preference None gets Mavi
Buradaki ilginç bir özellik, mevcut Envanter örneği üzerinde self.en_cok_stoklanan() öğesini çağıran bir kapanış aktarmış olmamızdır. Standart kütüphanenin, tanımladığımız Envanter veya GomlekRengi türleri ya da bu senaryoda kullanmak istediğimiz mantık hakkında hiçbir şey bilmesine gerek yoktu. Kapanış, self Envanter örneğine yönelik değiştirilemez bir referans (immutable reference) yakalar (captures) ve bunu unwrap_or_else metoduna belirlediğimiz kod ile iletir. Fonksiyonlar ise çevrelerini bu şekilde yakalayamazlar.
Kapanış Türlerini Çıkarsamak ve Açıklamak (Inferring and Annotating)
Fonksiyonlar ve kapanışlar arasında daha fazla fark vardır. Kapanışlar genellikle, fn fonksiyonlarının yaptığı gibi parametrelerin veya dönüş değerinin türlerini açıklamanızı gerektirmez. Türler, kullanıcılarınıza sunulan açık bir arayüzün (interface) parçası olduğu için fonksiyonlarda tür açıklamaları (type annotations) gereklidir. Bu arayüzü katı bir şekilde (rigidly) tanımlamak, bir fonksiyonun hangi tür değerleri kullandığı ve döndürdüğü konusunda herkesin hemfikir olmasını sağlamak açısından önemlidir. Kapanışlar ise bunun gibi açık bir arayüzde kullanılmazlar: Değişkenlerde saklanırlar ve onlara isim vermeden ve onları kütüphanemizin kullanıcılarına açmadan (exposing) kullanılırlar.
Kapanışlar tipik olarak kısadır ve rastgele bir senaryodan ziyade yalnızca dar bir bağlamda geçerlidir. Bu sınırlı bağlamlar (limited contexts) içinde derleyici (compiler), çoğu değişkenin türünü çıkarsayabildiği gibi, parametrelerin türlerini ve dönüş türünü de çıkarsayabilir (derleyicinin kapanış türü açıklamalarına da ihtiyaç duyduğu nadir durumlar vardır).
Değişkenlerde olduğu gibi, eğer kesinlikle gerekenden (strictly necessary) daha uzun, ayrıntılı (verbose) olma pahasına açıklığı (explicitness) ve netliği (clarity) artırmak istersek tür açıklamaları ekleyebiliriz. Bir kapanış için türleri açıklamak, Liste 13-2’de gösterilen tanıma benzeyecektir. Bu örnekte, Liste 13-1’de yaptığımız gibi onu argüman olarak ilettiğimiz yerde tanımlamak yerine bir kapanış tanımlıyor ve onu bir değişkende saklıyoruz.
use std::thread;
use std::time::Duration;
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure(intensity));
println!("Next, do {} situps!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure(intensity)
);
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}Tür açıklamaları eklendiğinde, kapanışların sözdizimi fonksiyonların sözdizimine daha çok benzer görünür. Karşılaştırma için burada, parametresine 1 ekleyen bir fonksiyon ve aynı davranışa sahip bir kapanış tanımlıyoruz. İlgili kısımları hizalamak için bazı boşluklar ekledik. Bu, dikey çubukların (pipes) kullanımı ve isteğe bağlı olan sözdizimi miktarı haricinde kapanış sözdiziminin fonksiyon sözdizimine ne kadar benzediğini göstermektedir:
fn bir_ekle_v1 (x: u32) -> u32 { x + 1 }
let bir_ekle_v2 = |x: u32| -> u32 { x + 1 };
let bir_ekle_v3 = |x| { x + 1 };
let bir_ekle_v4 = |x| x + 1 ;İlk satır bir fonksiyon tanımını ve ikinci satır tamamen açıklanmış (annotated) bir kapanış tanımını gösterir. Üçüncü satırda, kapanış tanımından tür açıklamalarını kaldırıyoruz. Dördüncü satırda, kapanış gövdesinde sadece bir ifade olduğu için isteğe bağlı (optional) olan süslü parantezleri (brackets) kaldırıyoruz. Bunların tümü, çağrıldıklarında aynı davranışı üretecek geçerli (valid) tanımlamalardır. bir_ekle_v3 ve bir_ekle_v4 satırları derlenebilmek için kapanışların değerlendirilmesini gerektirir, çünkü türler kullanımlarından çıkarılacaktır (inferred). Bu, Rust’ın türü çıkarabilmesi için tür açıklamalarına veya Vec’e eklenecek bir türden değerlere ihtiyaç duyan let v = Vec::new(); komutuna benzer.
Kapanış tanımlarında derleyici her bir parametre ve dönüş değeri için somut (concrete) bir tür çıkaracaktır. Örneğin, Liste 13-3 sadece parametre olarak aldığı değeri döndüren kısa bir kapanışın tanımını göstermektedir. Bu kapanış, bu örneğin amacı dışında pek kullanışlı değildir. Tanıma herhangi bir tür açıklaması (type annotations) eklemediğimize dikkat edin. Herhangi bir tür açıklaması olmadığı için kapanışı herhangi bir türle çağırabiliriz ki bunu ilk defa burada String ile yaptık. Daha sonra ornek_kapanis’ı bir tamsayı ile çağırmaya çalışırsak hata alırız.
fn main() {
let ornek_kapanis = |x| x;
let s = ornek_kapanis(String::from("merhaba"));
let n = ornek_kapanis(5);
}Derleyici bize şu hatayı verir:
$ cargo run
Compiling kapanis-ornek v0.1.0 (file:///projects/kapanis-ornek)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = ornek_kapanis(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = ornek_kapanis(String::from("merhaba"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let ornek_kapanis = |x| x;
| ^
help: try using a conversion method
|
5 | let n = ornek_kapanis(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `kapanis-ornek` (bin "kapanis-ornek") due to 1 previous error
ornek_kapanis’ı String değeri ile ilk kez çağırdığımızda derleyici x’in türünü ve kapanışın dönüş türünü String olarak çıkarsar (infers). Bu türler daha sonra ornek_kapanis içindeki kapanışa kilitlenir (locked into) ve aynı kapanışla başka bir tür kullanmaya çalıştığımızda tür hatası alırız.
Referansları Yakalamak (Capturing) veya Sahipliği (Ownership) Taşımak
Kapanışlar, bir fonksiyonun bir parametreyi alabildiği üç yolla doğrudan eşleşen üç yolla değerleri ortamlarından yakalayabilirler: değiştirilemez şekilde ödünç alma (borrowing immutably), değiştirilebilir şekilde ödünç alma (borrowing mutably) ve sahipliği alma (taking ownership). Kapanışın, fonksiyonun gövdesinin yakalanan değerlerle ne yaptığına dayanarak bunlardan hangisini kullanacağına kendisi karar verecektir.
Liste 13-4’te, sadece değeri yazdırmak için değiştirilemez bir referansa ihtiyaç duyduğundan dolayı liste adlı vektöre değiştirilemez bir referans yakalayan bir kapanış tanımlıyoruz.
fn main() {
let liste = vec![1, 2, 3];
println!("Before defining closure: {liste:?}");
let sadece_odunc_alir = || println!("From closure: {liste:?}");
println!("Before calling closure: {liste:?}");
sadece_odunc_alir();
println!("After calling closure: {liste:?}");
}Bu örnek ayrıca bir değişkenin bir kapanış tanımına bağlanabileceğini ve daha sonra tıpkı değişken adı bir fonksiyon adıymış gibi değişken adını ve parantezleri kullanarak kapanışı çağırabileceğimizi gösterir.
Aynı anda liste’ye birden çok değiştirilemez referans alabileceğimiz için, liste’ye kapanış tanımından önceki, kapanış tanımından sonraki ama kapanış çağrılmadan önceki ve kapanış çağrıldıktan sonraki kodlardan hâlâ erişilebilir. Bu kod derlenir, çalışır ve şunu yazdırır:
$ cargo run
Compiling kapanis-ornek v0.1.0 (file:///projects/kapanis-ornek)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/kapanis-ornek`
Kapanışı tanımlamadan önce: [1, 2, 3]
Kapanışı çağırmadan önce: [1, 2, 3]
From closure: [1, 2, 3]
Kapanışı çağırdıktan sonra: [1, 2, 3]
Sonraki adımda, Liste 13-5’te, liste vektörüne bir öğe eklemesi için kapanış gövdesini (closure body) değiştiriyoruz. Kapanış artık değiştirilebilir bir referans yakalar (captures).
fn main() {
let mut liste = vec![1, 2, 3];
println!("Before defining closure: {liste:?}");
let mut degistirilebilir_odunc_alir = || liste.push(7);
degistirilebilir_odunc_alir();
println!("After calling closure: {liste:?}");
}Bu kod derlenir, çalışır ve şunu yazdırır:
$ cargo run
Compiling kapanis-ornek v0.1.0 (file:///projects/kapanis-ornek)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/kapanis-ornek`
Kapanışı tanımlamadan önce: [1, 2, 3]
Kapanışı çağırdıktan sonra: [1, 2, 3, 7]
degistirilebilir_odunc_alir kapanışının tanımlanması ile çağrılması arasında artık bir println! bulunmadığına dikkat edin: degistirilebilir_odunc_alir tanımlandığında, liste’ye değiştirilebilir bir referans yakalar. Kapanış çağrıldıktan sonra kapanışı bir daha kullanmayız, bu nedenle değiştirilebilir ödünç alma (mutable borrow) sona erer. Kapanış tanımı ile kapanış çağrısı arasında yazdırmak (print) için değiştirilemez bir ödünç almaya (immutable borrow) izin verilmez, çünkü değiştirilebilir bir ödünç alma varken başka hiçbir ödünç almaya izin verilmez. Hangi hata mesajını aldığınızı görmek için oraya bir println! eklemeyi deneyin!
Kapanışın gövdesi sahipliğe kesin olarak (strictly) ihtiyaç duymasa bile kapanışın kullandığı değerlerin sahipliğini çevreden almasını zorlamak (force) istiyorsanız parametre listesinden önce move (taşı) anahtar kelimesini kullanabilirsiniz.
Bu teknik çoğunlukla verileri taşımak (move) için yeni bir iş parçacığına bir kapanış aktarılırken, verilerin yeni iş parçacığı tarafından sahiplenilmesi için kullanışlıdır. Eşzamanlılıktan (concurrency) bahsederken 16. Bölümde iş parçacıklarını ve bunları neden kullanmak isteyeceğinizi ayrıntılı olarak tartışacağız, ancak şimdilik move anahtar kelimesine ihtiyaç duyan bir kapanış kullanarak yeni bir iş parçacığı oluşturmayı (spawning) kısaca inceleyelim. Liste 13-6, vektörü main (ana) iş parçacığı yerine yeni bir iş parçacığında yazdırmak için Liste 13-4’ün değiştirilmiş halini göstermektedir.
use std::thread;
fn main() {
let liste = vec![1, 2, 3];
println!("Before defining closure: {liste:?}");
thread::spawn(move || println!("From thread: {liste:?}"))
.join()
.unwrap();
}liste’nin sahipliğini almaya zorlamak için move kullanmakYeni bir iş parçacığı yaratıyoruz (spawn) ve bu iş parçacığına argüman olarak çalıştırması için bir kapanış veriyoruz. Kapanış gövdesi (closure body) listeyi yazdırır. Liste 13-4’te kapanış, yazdırabilmek için gerek duyduğu en az (least amount of access) erişim hakkı olduğundan dolayı liste’yi sadece değiştirilemez bir referans kullanarak yakalamıştı. Bu örnekte, kapanış gövdesinin hala yalnızca değiştirilemez bir referansa ihtiyacı olsa da kapanış tanımının başına move anahtar kelimesini koyarak liste’nin kapanışa taşınması (moved) gerektiğini belirtmeliyiz. Eğer ana (main) iş parçacığı yeni iş parçacığı üzerinde join (katıl) çağrısı yapmadan önce daha fazla işlem gerçekleştirirse, yeni iş parçacığı ana iş parçacığının geri kalanı bitmeden önce bitebilir ya da ana iş parçacığı önce bitebilir. Ana iş parçacığı liste’nin sahipliğini sürdürürse ancak yeni iş parçacığından önce bitip liste’yi düşürürse, iş parçacığındaki değiştirilemez referans (immutable reference) geçersiz olur. Bu nedenle derleyici, referansın geçerli (valid) olması için yeni iş parçacığına verilen kapanışa liste’nin taşınmasını gerektirir. Hangi derleyici hatalarını (compiler errors) aldığınızı görmek için move anahtar kelimesini kaldırmayı veya kapanış tanımlandıktan sonra ana iş parçacığında liste’yi kullanmayı deneyin!
Yakalanan Değerleri Kapanışların Dışına Taşımak (Moving)
Bir kapanış tanımlandığı çevreden bir değerin referansını veya sahipliğini yakaladığında (böylece, eğer varsa, nelerin kapanışın içine taşındığını etkiler), kapanışın gövdesindeki kod, kapanış daha sonra değerlendirildiğinde referanslara veya değerlere ne olacağını tanımlar (böylece, eğer varsa, nelerin kapanışın dışına taşındığını etkiler).
Bir kapanış gövdesi aşağıdakilerden herhangi birini yapabilir: Yakalanan (captured) değeri kapanıştan dışarı taşıyabilir, yakalanan değeri değiştirebilir (mutate), değeri ne taşıyabilir ne de değiştirebilir veya başından itibaren ortamdan hiçbir şey yakalamayabilir.
Bir kapanışın ortamdaki değerleri yakalama ve ele alma şekli (handles values), kapanışın hangi trait’leri uyguladığını etkiler ve trait’ler, fonksiyonların ve struct’ların ne tür kapanışları kullanabileceklerini nasıl belirttiklerini gösterir. Kapanışlar, kapanış gövdesinin değerleri nasıl ele aldığına bağlı olarak bu üç Fn trait’inden birini, ikisini veya üçünü birden eklemeli bir biçimde otomatik olarak uygular:
FnOncebir kez çağrılabilen kapanışlar için geçerlidir. Tüm kapanışlar en azından bu trait’i uygular çünkü tüm kapanışlar çağrılabilir. Yakaladığı değerleri kendi gövdesinin dışına çıkaran bir kapanış sadeceFnOnce’ı uygulayacak ve diğerFntrait’lerini uygulamayacaktır çünkü sadece bir kez çağrılabilir.FnMutyakaladıkları değerleri kendi gövdelerinin dışına çıkarmayan ancak yakalanan değerleri değiştirebilen (mutate) kapanışlar için geçerlidir. Bu kapanışlar birden fazla kez çağrılabilir.Fnçevrelerinden hiçbir şey yakalamayan kapanışların yanı sıra, yakaladıkları değerleri kendi gövdelerinden dışarı çıkarmayan ve yakalanan değerleri değiştirmeyen kapanışlar için geçerlidir. Bu kapanışlar ortamlarını değiştirmeden birden fazla kez çağrılabilir ki bu, bir kapanışın aynı anda birden fazla kez çağrılması gibi durumlarda önemlidir.
Liste 13-1’de kullandığımız Option<T> üzerindeki unwrap_or_else metodunun tanımına bakalım:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Hatırlayacağınız gibi T, bir Option’ın Some varyantındaki değerin türünü temsil eden jenerik türdür. Bu T türü aynı zamanda unwrap_or_else fonksiyonunun dönüş türüdür: Örneğin Option<String> üzerinde unwrap_or_else çağıran kod bir String alacaktır.
Daha sonra, unwrap_or_else fonksiyonunun ek jenerik F tür parametresine sahip olduğuna dikkat edin. F türü, unwrap_or_else çağrılırken sağladığımız kapanış olan f adlı parametrenin türüdür.
Jenerik F türü üzerinde belirtilen trait sınırı (trait bound) FnOnce() -> T’dir; bu da F’nin bir kez çağrılabilmesi, hiç argüman almaması ve bir T döndürmesi gerektiği anlamına gelir. Trait sınırında FnOnce kullanmak, unwrap_or_else’in f’yi bir kereden fazla çağırmayacağı kısıtlamasını (constraint) ifade eder. unwrap_or_else’in gövdesinde Option’ın Some olması halinde f’nin çağrılmayacağını görebiliriz. Eğer Option None ise f bir kez çağrılacaktır. Tüm kapanışlar FnOnce’ı uyguladığı için, unwrap_or_else her üç tür kapanışı da kabul eder ve olabildiğince esnektir.
Not: Yapmak istediğimiz şey ortamdan bir değer yakalamayı gerektirmiyorsa
Fntraitlerinden birini uygulayan bir şeye ihtiyaç duyduğumuz yerde bir kapanış yerine bir fonksiyonun adını kullanabiliriz. Örneğin,Option<Vec<T>>değeri üzerinde değerinNoneolması durumunda yeni ve boş bir vektör elde etmek içinunwrap_or_else(Vec::new)çağırabiliriz. Derleyici (compiler), bir fonksiyon tanımı içinFntraitlerinden hangisi geçerliyse onu otomatik olarak uygular.
Şimdi bunun unwrap_or_else’den nasıl farklı olduğunu ve sort_by_key’in neden trait sınırı için FnOnce yerine FnMut kullandığını görmek üzere dilimler üzerinde tanımlanan standart kütüphane metodu sort_by_key’e (anahtara_göre_sırala) bakalım. Kapanış, değerlendirilen dilimdeki mevcut ögeye bir referans formunda tek bir argüman alır ve sıralanabilen (ordered) K türünde bir değer döndürür. Bu fonksiyon, bir dilimi her bir ögenin belirli bir özniteliğine (attribute) göre sıralamak istediğinizde kullanışlıdır. Liste 13-7’de Dikdortgen örneklerinden oluşan bir listemiz var ve bunları genislik özniteliklerine göre düşükten yükseğe sıralamak için sort_by_key kullanıyoruz.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let mut liste = [
Dikdortgen { genislik: 10, yukseklik: 1 },
Dikdortgen { genislik: 3, yukseklik: 5 },
Dikdortgen { genislik: 7, yukseklik: 12 },
];
liste.sort_by_key(|r| r.genislik);
println!("{liste:#?}");
}sort_by_key kullanmakBu kod şunu yazdırır:
$ cargo run
Compiling dikdortgenler v0.1.0 (file:///projects/dikdortgenler)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/dikdortgenler`
[
Dikdortgen {
genislik: 3,
yukseklik: 5,
},
Dikdortgen {
genislik: 7,
yukseklik: 12,
},
Dikdortgen {
genislik: 10,
yukseklik: 1,
},
]
sort_by_key fonksiyonunun FnMut kapanışı alacak şekilde tanımlanmasının nedeni, kapanışı birden çok kez çağırmasıdır: dilimdeki her öğe için bir kez. |r| r.genislik (|r| r.width) kapanışı ortamından herhangi bir şey yakalamaz (capture), değiştirmez (mutate) veya dışarı taşımaz (move out), dolayısıyla trait sınırı gereksinimlerini karşılar.
Buna karşılık, Liste 13-8 ortamdan dışarıya bir değer taşıdığı için yalnızca FnOnce trait’ini uygulayan bir kapanış örneğini göstermektedir. Derleyici (compiler) bu kapanışı sort_by_key ile kullanmamıza izin vermeyecektir.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let mut liste = [
Dikdortgen { genislik: 10, yukseklik: 1 },
Dikdortgen { genislik: 3, yukseklik: 5 },
Dikdortgen { genislik: 7, yukseklik: 12 },
];
let mut siralama_islemleri = vec![];
let deger = String::from("closure called");
liste.sort_by_key(|r| {
siralama_islemleri.push(deger);
r.genislik
});
println!("{liste:#?}");
}sort_by_key ile bir FnOnce kapanışı kullanmaya çalışmakBu, liste sıralanırken sort_by_key fonksiyonunun kapanışı kaç kez çağırdığını saymaya çalışmak için kurgulanmış ve dolambaçlı bir yoldur (işe yaramaz). Bu kod, bu sayma işlemini, kapanışın ortamından alınan bir String olan deger’i siralama_islemleri vektörüne iterek (pushing) yapmaya çalışır. Kapanış deger’i yakalar (captures) ve ardından deger’in sahipliğini siralama_islemleri vektörüne aktararak deger’i kapanışın dışına çıkarır. Bu kapanış bir kez çağrılabilir; ikinci kez çağırmaya çalışmak işe yaramaz, çünkü deger artık ortama yeniden siralama_islemleri’ne itilmek üzere bulunamaz! Bu nedenle, bu kapanış sadece FnOnce’ı uygular. Biz bu kodu derlemeye çalıştığımızda, kapanışın FnMut’u uygulaması gerektiğinden (must implement) dolayı deger’in kapanıştan dışarı çıkarılamayacağına (moved out) dair şu hatayı alırız:
$ cargo run
Compiling dikdortgenler v0.1.0 (file:///projects/dikdortgenler)
error[E0507]: cannot move out of `deger`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let deger = String::from("closure called");
| ----- ------------------------------ move occurs because `deger` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | liste.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | siralama_islemleri.push(deger);
| ^^^^^ `deger` is moved here
|
help: consider cloning the deger if the performance cost is acceptable
|
18 | siralama_islemleri.push(deger.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `dikdortgenler` (bin "dikdortgenler") due to 1 previous error
Hata mesajı, kapanışın gövdesinde deger’i ortam dışına taşıyan satırı gösterir. Bunu düzeltmek için, değerleri ortam dışına taşımayacak şekilde kapanış gövdesini değiştirmeliyiz. Ortamda bir sayaç tutmak ve kapanış gövdesinde bu sayacın değerini artırmak, kapanışın kaç kez çağrıldığını saymak için çok daha anlaşılır bir yoldur. Liste 13-9’daki kapanış sort_by_key ile çalışır, çünkü siralama_islemi_sayisi sayacına sadece değiştirilebilir bir referans yakalar ve dolayısıyla birden fazla kez çağrılabilir.
#[derive(Debug)]
struct Dikdortgen {
genislik: u32,
yukseklik: u32,
}
fn main() {
let mut liste = [
Dikdortgen { genislik: 10, yukseklik: 1 },
Dikdortgen { genislik: 3, yukseklik: 5 },
Dikdortgen { genislik: 7, yukseklik: 12 },
];
let mut siralama_islemi_sayisi = 0;
liste.sort_by_key(|r| {
siralama_islemi_sayisi += 1;
r.genislik
});
println!("{liste:#?}, sorted in {siralama_islemi_sayisi} operations");
}sort_by_key ile bir FnMut kapanışı kullanılmasına izin verilir.Kapanışları kullanan fonksiyonlar veya türler tanımlarken veya kullanırken Fn traitleri (özellikleri) önemlidir. Bir sonraki bölümde yineleyicileri tartışacağız. Birçok yineleyici metodu (iterator methods) kapanış argümanlarını alır, bu yüzden devam ederken bu kapanış detaylarını aklınızda bulundurun!
İteratörlerle Bir Dizi Öğeyi İşleme
Yineleyiciler (Iterators) ile Bir Dizi Ögeyi (Item) İşlemek
Yineleyici deseni (iterator pattern), bir dizi öge üzerinde sırayla bazı görevleri (task) yerine getirmenize olanak tanır. Bir yineleyici, her bir öge üzerinde yineleme yapma ve dizinin (sequence) ne zaman bittiğini belirleme mantığından sorumludur. Yineleyicileri kullandığınızda bu mantığı kendiniz yeniden uygulamak (reimplement) zorunda kalmazsınız.
Rust’ta yineleyiciler tembeldir (lazy), yani siz yineleyiciyi tüketmek (consume) ve kullanmak (use it up) için metotlar çağırana kadar hiçbir etkileri yoktur. Örneğin, Liste 13-10’daki kod Vec<T> üzerinde tanımlı olan iter metodunu çağırarak v1 vektöründeki ögeler üzerinde bir yineleyici yaratır. Bu kod tek başına yararlı hiçbir şey yapmaz.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}Yineleyici v1_iter değişkeninde saklanır. Bir yineleyici oluşturduğumuzda, onu çeşitli şekillerde kullanabiliriz. Liste 3-5’te, bir dizideki (array) her bir öge üzerinde kod çalıştırmak için bir for döngüsü kullanarak dizi üzerinde yineleme yapmıştık. Arka planda bu, örtük olarak bir yineleyici yarattı ve sonra onu tüketti, ancak bunun tam olarak nasıl çalıştığının üstünkörü geçmiştik.
Liste 13-11’deki örnekte, yineleyicinin oluşturulmasını, yineleyicinin for döngüsünde kullanımından ayırıyoruz. for döngüsü v1_iter içindeki yineleyici kullanılarak çağrıldığında, yineleyicideki her bir eleman, döngünün her bir iterasyonunda (iteration) kullanılır ve bu da her bir değeri ekrana yazdırır.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for deger in v1_iter {
println!("Got: {deger}");
}
}for döngüsünde bir yineleyici kullanmakStandart kütüphanelerinde (standard libraries) yineleyici bulunmayan dillerde, aynı işlevselliği muhtemelen 0 indeksinden (index) başlayan bir değişken oluşturarak, bir değeri almak üzere vektöre indeksleme yapmak için bu değişkeni kullanarak ve değişkendeki değeri, vektördeki ögelerin toplam sayısına ulaşana kadar bir döngü içerisinde artırarak yazardınız.
Yineleyiciler, hata yapma ihtimaliniz olan tekrarlayan kodları ortadan kaldırarak tüm bu mantığı sizin için halleder. Yineleyiciler, yalnızca vektörler gibi indeksleyebileceğiniz (index into) veri yapılarıyla (data structures) değil, pek çok farklı türdeki diziyle (sequence) aynı mantığı kullanmanız için size daha fazla esneklik sağlar. Yineleyicilerin bunu nasıl yaptığına bakalım.
Iterator Trait’i (Özelliği) ve next (Sonraki) Metodu
Tüm yineleyiciler standart kütüphanede tanımlanan Iterator adlı bir trait’i uygular. Trait’in tanımı şuna benzer:
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// varsayılan (default) uygulamalara sahip metotlar atlanmıştır
}
}Bu tanımın bazı yeni sözdizimleri kullandığına dikkat edin: type Item ve Self::Item (Bölüm 20’de ilişkili türler hakkında derinlemesine konuşacağız). Şimdilik bilmeniz gereken tek şey, bu kodun, Iterator trait’ini uygulamanın bir Item (Öge) türü de tanımlamanızı gerektirdiğini ve bu Item türünün next (sonraki) metodunun dönüş türünde kullanıldığını söylediğidir. Başka bir deyişle, Item türü, yineleyiciden döndürülecek tür olacaktır.
Iterator trait’i, uygulayıcıların (implementors) yalnızca bir metodu tanımlamasını gerektirir: her seferinde yineleyicinin bir ögesini Some içine sarılmış olarak döndüren ve yineleme bittiğinde None döndüren next metodu.
Yineleyiciler üzerinde doğrudan next metodunu çağırabiliriz; Liste 13-12, vektörden oluşturulan yineleyici üzerinde yapılan tekrarlı next çağrılarından hangi değerlerin döndürüldüğünü gösterir.
#[cfg(test)]
mod tests {
#[test]
fn yineleyici_gosterimi() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}next metodu çağırmakv1_iter’i değiştirilebilir yapmamız gerektiğine dikkat edin: Bir yineleyici üzerinde next metodunu çağırmak, yineleyicinin dizide (sequence) nerede olduğunu takip etmek (keep track) için kullandığı iç durumu (internal state) değiştirir. Diğer bir deyişle bu kod yineleyiciyi tüketir veya kullanır. next’e yapılan her çağrı yineleyiciden bir öge tüketir. Bir for döngüsü kullandığımızda v1_iter’i mut (değiştirilebilir) yapmamıza gerek kalmamıştı, çünkü döngü v1_iter’in sahipliğini almış ve arka planda onu değiştirilebilir hale getirmişti.
Ayrıca next çağrılarından aldığımız değerlerin vektördeki değerlere değiştirilemez referanslar (immutable references) olduğuna dikkat edin. iter metodu, değiştirilemez referanslar üzerinde bir yineleyici üretir. Eğer v1’in sahipliğini alan ve sahip olunan değerler (owned values) döndüren bir yineleyici oluşturmak istiyorsak, iter yerine into_iter çağırabiliriz. Benzer şekilde, eğer değiştirilebilir referanslar (mutable references) üzerinde yineleme yapmak istiyorsak iter yerine iter_mut çağırabiliriz.
Yineleyiciyi Tüketen (Consume) Metotlar
Iterator trait’i, standart kütüphane tarafından sağlanan varsayılan uygulamalara (default implementations) sahip bir dizi farklı metoda sahiptir; bu metotlar hakkında standart kütüphane API belgelerinde Iterator trait’i altına bakarak bilgi edinebilirsiniz. Bu metotlardan bazıları tanımlarında next metodunu çağırırlar ki bu da Iterator trait’ini uygularken next metodunu uygulamanız gerekmesinin nedenidir.
next’i çağıran metotlara tüketici adaptörler (consuming adapters) adı verilir çünkü onları çağırmak yineleyiciyi tüketir. Buna bir örnek, yineleyicinin sahipliğini alan ve art arda next çağırarak ögeler üzerinde yineleme yapan ve böylece yineleyiciyi tüketen sum (toplam) metodudur. Yineleme yaptıkça her bir ögeyi çalışan bir toplama ekler ve yineleme tamamlandığında toplamı döndürür. Liste 13-13, sum metodunun kullanımını gösteren bir teste sahiptir.
#[cfg(test)]
mod tests {
#[test]
fn yineleyici_toplami() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let toplam: i32 = v1_iter.sum();
assert_eq!(toplam, 6);
}
}sum metodunu çağırmaksum çağrısından sonra v1_iter’i kullanmamıza izin verilmez, çünkü sum üzerinde çağırdığımız yineleyicinin sahipliğini alır.
Başka Yineleyiciler (Iterators) Üreten Metotlar
Yineleyici adaptörleri (Iterator adapters), Iterator trait’inde tanımlanan ve yineleyiciyi tüketmeyen metotlardır. Bunun yerine, orijinal yineleyicinin bazı özelliklerini değiştirerek farklı yineleyiciler üretirler.
Liste 13-14, ögeler yinelendikçe her bir öge için çağrılacak bir kapanış alan map (haritalandır) yineleyici adaptörü metodunun çağrılmasına bir örnek gösterir. map metodu, değiştirilen ögeleri üreten yeni bir yineleyici döndürür. Buradaki kapanış, vektördeki her bir ögenin 1 artırılacağı yeni bir yineleyici oluşturur.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}map yineleyici adaptörünü çağırmakAncak bu kod bir uyarı üretir:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Liste 13-14’teki kod hiçbir şey yapmaz; belirttiğimiz kapanış asla çağrılmaz. Uyarı bize bunun nedenini hatırlatıyor: Yineleyici adaptörleri tembeldir (lazy) ve bizim yineleyiciyi burada tüketmemiz gerekir.
Bu uyarıyı düzeltmek ve yineleyiciyi tüketmek için, Liste 12-1’de env::args ile kullandığımız collect (topla) metodunu kullanacağız. Bu metot yineleyiciyi tüketir ve ortaya çıkan değerleri bir koleksiyon veri tipine toplar.
Liste 13-15’te, map (haritalandır) çağrısından dönen yineleyici üzerinde yineleme yapmanın sonuçlarını bir vektörde topluyoruz. Bu vektör sonuç olarak orijinal vektördeki her bir ögenin 1 artırılmış halini barındıracaktır.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}map metodunu ve ardından yeni yineleyiciyi tüketip bir vektör oluşturmak için collect metodunu çağırmakmap bir kapanış aldığından, her bir öge üzerinde gerçekleştirmek istediğimiz herhangi bir işlemi belirtebiliriz. Bu, kapanışların Iterator trait’inin sağladığı yineleme davranışını yeniden kullanırken bazı davranışları özelleştirmenize (customize) nasıl olanak tanıdığının harika bir örneğidir.
Karmaşık eylemleri okunabilir bir şekilde gerçekleştirmek için birden fazla yineleyici adaptörü (iterator adapters) çağrısını birbirine zincirleyebilirsiniz. Ancak tüm yineleyiciler tembel olduğundan, yineleyici adaptörlerine yapılan çağrılardan sonuç almak için tüketen adaptör (consuming adapter) metotlarından birini çağırmalısınız.
Ortamlarını Yakalayan Kapanışlar (Closures That Capture Their Environment)
Birçok yineleyici adaptörü kapanışları argüman olarak alır ve yineleyici adaptörlerine argüman olarak belirteceğimiz kapanışlar genellikle ortamlarını yakalayan kapanışlar olacaktır.
Bu örnek için, bir kapanış alan filter (filtrele) metodunu kullanacağız. Kapanış, yineleyiciden bir öge alır ve bir bool (mantıksal değer) döndürür. Kapanış true (doğru) döndürürse, değer filter tarafından üretilen yinelemeye (iteration) dahil edilecektir. Kapanış false döndürürse değer dahil edilmeyecektir.
Liste 13-16’da, bir Ayakkabi struct örneği koleksiyonu üzerinde yineleme yapmak için ayakkabi_numarasi değişkenini ortamından yakalayan bir kapanış ile birlikte filter’ı (filtrele) kullanıyoruz. Yalnızca belirtilen numaradaki ayakkabıları döndürecektir.
#[derive(PartialEq, Debug)]
struct Ayakkabi {
numara: u32,
stil: String,
}
fn numaradaki_ayakkabilar(ayakkabilar: Vec<Ayakkabi>, ayakkabi_numarasi: u32) -> Vec<Ayakkabi> {
ayakkabilar.into_iter().filter(|s| s.numara == ayakkabi_numarasi).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn numaraya_gore_filtreler() {
let ayakkabilar = vec![
Ayakkabi {
numara: 10,
stil: String::from("spor_ayakkabi"),
},
Ayakkabi {
numara: 13,
stil: String::from("sandalet"),
},
Ayakkabi {
numara: 10,
stil: String::from("bot"),
},
];
let in_my_size = numaradaki_ayakkabilar(ayakkabilar, 10);
assert_eq!(
in_my_size,
vec![
Ayakkabi {
numara: 10,
stil: String::from("spor_ayakkabi")
},
Ayakkabi {
numara: 10,
stil: String::from("bot")
},
]
);
}
}ayakkabi_numarasinı yakalayan bir kapanış ile filter metodunu kullanmaknumaradaki_ayakkabilar fonksiyonu, parametre olarak bir ayakkabı vektörünün (vector of shoes) ve bir ayakkabı numarasının sahipliğini alır. Yalnızca belirtilen numaranın olduğu ayakkabıları içeren bir vektör döndürür.
numaradaki_ayakkabilar’ın gövdesinde, vektörün sahipliğini alan bir yineleyici oluşturmak için into_iter çağırıyoruz. Ardından, bu yineleyiciyi yalnızca kapanışın true (doğru) değerini döndürdüğü ögeleri barındıran yeni bir yineleyiciye uyarlamak (adapt) için filter çağırıyoruz.
Kapanış, ortamdan ayakkabi_numarasi parametresini yakalar (captures) ve bu değeri her ayakkabının numarasıyla karşılaştırarak yalnızca belirtilen numara olan ayakkabıları tutar. Son olarak collect komutunu çağırmak, uyarlanmış yineleyicinin döndürdüğü değerleri fonksiyonun döndürdüğü bir vektörde toplar.
Test, numaradaki_ayakkabilar metodunu çağırdığımızda sadece belirlediğimiz değerle aynı numaraya sahip olan ayakkabıların geri döndüğünü gösterir.
G/Ç (I/O) Projemizi İyileştirme
G/Ç (I/O) Projemizi İyileştirmek
Yineleyiciler hakkındaki bu yeni bilgiyle, koddaki yerleri daha net ve özlü hale getirmek için yineleyiciler kullanarak Bölüm 12’deki G/Ç projesini geliştirebiliriz. Yineleyicilerin Yapilandirma::olustur fonksiyonu ve ara fonksiyonu uygulamamızı nasıl geliştirebileceğine bakalım.
Bir Yineleyici Kullanarak clone’u (Klonlamayı) Kaldırmak
Liste 12-6’da, String değerlerinden oluşan bir dilim alan ve dilimin içine indeksleyip değerleri klonlayarak (cloning) Yapilandirma struct’ının bir örneğini oluşturan ve Yapilandirma struct’ının bu değerlere sahip olmasını sağlayan bir kod ekledik. Liste 13-17’de Yapilandirma::olustur fonksiyonunun Liste 12-23’teki uygulamasını yeniden ürettik.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let argumanlar: Vec<String> = env::argumanlar().collect();
let config = Yapilandirma::olustur(&argumanlar).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = calistir(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(config: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(config.dosya_yolu)?;
let sonuclar = if config.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&config.sorgu, &icerik)
} else {
ara(&config.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}Yapilandirma::olustur fonksiyonunun yeniden üretimiO zamanlar, verimsiz clone çağrıları için endişelenmememiz gerektiğini, çünkü bunları gelecekte kaldıracağımızı söylemiştik. İşte o zaman geldi!
Burada clone’a ihtiyacımız vardı çünkü argumanlar parametresinde String elemanlarına sahip bir dilimimiz (slice) var ancak olustur fonksiyonu argumanlar’ın sahibi değil. Bir Yapilandirma örneğinin sahipliğini döndürmek için, Yapilandirma örneğinin kendi değerlerine sahip olabilmesi amacıyla Yapilandirma’nın sorgu ve dosya_yolu alanlarındaki değerleri klonlamamız gerekiyordu.
Yineleyiciler hakkındaki yeni bilgimiz sayesinde, olustur fonksiyonunu bir dilimi ödünç almak yerine argüman olarak bir yineleyicinin sahipliğini alacak şekilde değiştirebiliriz. Dilimin uzunluğunu kontrol eden ve belirli konumlara indeksleyen kod yerine yineleyici işlevselliğini kullanacağız. Yineleyici değerlere erişeceği için bu, Yapilandirma::olustur fonksiyonunun ne yaptığını netleştirecektir.
Yapilandirma::olustur yineleyicinin sahipliğini aldığında ve ödünç alan indeksleme işlemlerini kullanmayı bıraktığında, clone çağrısı yapmak ve yeni bir tahsis yapmak yerine String değerlerini yineleyiciden Yapilandirma içine taşıyabiliriz.
Döndürülen Yineleyiciyi (Returned Iterator) Doğrudan Kullanmak
G/Ç projenizin src/main.rs dosyasını açın, şu şekilde görünmelidir:
Dosya adı: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let argumanlar: Vec<String> = env::argumanlar().collect();
let config = Yapilandirma::olustur(&argumanlar).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = calistir(config) {
eprintln!("Uygulama hatası: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(config: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(config.dosya_yolu)?;
let sonuclar = if config.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&config.sorgu, &icerik)
} else {
ara(&config.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}Önce Liste 12-24’te sahip olduğumuz main fonksiyonunun başlangıcını, bu kez bir yineleyici kullanan Liste 13-18’deki kodla değiştireceğiz. Bu kod, Yapilandirma::olustur’u da güncelleyene kadar derlenmeyecektir.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let config = Yapilandirma::olustur(env::argumanlar()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = calistir(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(argumanlar: &[String]) -> Result<Yapilandirma, &'static str> {
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(config: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(config.dosya_yolu)?;
let sonuclar = if config.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&config.sorgu, &icerik)
} else {
ara(&config.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}env::args’ın dönüş değerini Yapilandirma::olustur’a geçirmek (passing)env::args fonksiyonu bir yineleyici döndürür! Yineleyici değerlerini bir vektörde toplayıp ardından Yapilandirma::olustur’a bir dilim (slice) geçirmek (passing) yerine, artık env::args’tan döndürülen yineleyicinin sahipliğini doğrudan Yapilandirma::olustur’a iletiyoruz.
Sonra Yapilandirma::olustur’un tanımını (definition) güncellemeliyiz. Yapilandirma::olustur’un imzasını Liste 13-19’a benzeyecek şekilde değiştirelim. Bu yine de derlenmeyecektir çünkü fonksiyon gövdesini (function body) de güncellememiz gerekiyor.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let config = Yapilandirma::olustur(env::argumanlar()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = calistir(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(
mut argumanlar: impl Iterator<Item = String>,
) -> Result<Yapilandirma, &'static str> {
// --snip--
if argumanlar.len() < 3 {
return Err("yeterli argüman yok");
}
let sorgu = argumanlar[1].clone();
let dosya_yolu = argumanlar[2].clone();
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(config: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(config.dosya_yolu)?;
let sonuclar = if config.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&config.sorgu, &icerik)
} else {
ara(&config.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}Yapilandirma::olustur’un imzasını bir yineleyici bekleyecek şekilde güncellemekenv::args fonksiyonu için standart kütüphane dokümantasyonu, döndürdüğü yineleyicinin türünün std::env::Args olduğunu ve bu türün Iterator trait’ini uyguladığını ve String değerleri döndürdüğünü gösterir.
Yapilandirma::olustur fonksiyonunun imzasını, argumanlar parametresinin &[String] yerine impl Iterator<Item = String> trait sınırlarına sahip jenerik bir tür olacak şekilde güncelledik. Bölüm 10’un “Traitleri Parametre Olarak Kullanmak” kısmında tartışılan impl Trait sözdiziminin bu kullanımı, argumanlar’ın Iterator trait’ini uygulayan ve String ögeleri döndüren herhangi bir tür olabileceği anlamına gelir.
argumanlar’ın sahipliğini aldığımız ve üzerinde yineleme yaparak argumanlar’ı değiştireceğimiz (mutating) için, onu değiştirilebilir hale getirmek üzere argumanlar parametresinin spesifikasyonuna mut anahtar kelimesini ekleyebiliriz.
Iterator Trait Metotlarını Kullanmak
Sonraki adımda, Yapilandirma::olustur’un gövdesini düzelteceğiz. argumanlar Iterator trait’ini uyguladığı için onun üzerinde next (sonraki) metodunu çağırabileceğimizi biliyoruz! Liste 13-20, Liste 12-23’teki kodu next metodunu kullanacak şekilde günceller.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{ara, buyuk_kucuk_harf_duyarsiz_ara};
fn main() {
let config = Yapilandirma::olustur(env::argumanlar()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = calistir(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Yapilandirma {
pub sorgu: String,
pub dosya_yolu: String,
pub buyuk_kucuk_harf_yoksay: bool,
}
impl Yapilandirma {
fn olustur(
mut argumanlar: impl Iterator<Item = String>,
) -> Result<Yapilandirma, &'static str> {
argumanlar.next();
let sorgu = match argumanlar.next() {
Some(arg) => arg,
None => return Err("Didn't get a sorgu string"),
};
let dosya_yolu = match argumanlar.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let buyuk_kucuk_harf_yoksay = env::var("IGNORE_CASE").is_ok();
Ok(Yapilandirma {
sorgu,
dosya_yolu,
buyuk_kucuk_harf_yoksay,
})
}
}
fn calistir(config: Yapilandirma) -> Result<(), Box<dyn Error>> {
let icerik = fs::read_to_string(config.dosya_yolu)?;
let sonuclar = if config.buyuk_kucuk_harf_yoksay {
buyuk_kucuk_harf_duyarsiz_ara(&config.sorgu, &icerik)
} else {
ara(&config.sorgu, &icerik)
};
for satir in sonuclar {
println!("{satir}");
}
Ok(())
}Yapilandirma::olustur’un gövdesini değiştirmekenv::args dönüş değerindeki ilk değerin programın adı olduğunu unutmayın. Bunu göz ardı etmek ve bir sonraki değere geçmek istiyoruz, bu yüzden önce next’i çağırıyoruz ve dönüş değeriyle hiçbir şey yapmıyoruz. Sonra, Yapilandirma’nın sorgu alanına (field) koymak istediğimiz değeri elde etmek için next’i çağırıyoruz. Eğer next Some döndürürse, değeri dışarı çıkarmak için bir match kullanıyoruz. Eğer None döndürürse bu, yeterli argüman (arguments) verilmediği anlamına gelir ve bir Err (hata) değeri ile erkenden döneriz (return early). Aynı şeyi dosya_yolu değeri için de yapıyoruz.
Yineleyici Adaptörleriyle (Iterator Adapters) Kodu Netleştirmek
Burada Liste 12-19’da olduğu gibi Liste 13-21’de de çoğaltılan G/Ç projemizdeki ara fonksiyonunda yineleyicilerden faydalanabiliriz.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
let mut sonuclar = Vec::new();
for satir in icerik.lines() {
if satir.contains(sorgu) {
sonuclar.push(satir);
}
}
sonuclar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn tek_sonuc() {
let sorgu = "güven";
let icerik = "\
Güven:
güvenli, hızlı, üretken.
Üçünü de seç.";
assert_eq!(vec!["güvenli, hızlı, üretken."], ara(sorgu, icerik));
}
}ara fonksiyonunun uygulamasıYineleyici adaptörü metotlarını kullanarak bu kodu daha özlü bir şekilde yazabiliriz. Bunu yapmak aynı zamanda değiştirilebilir bir ara sonuclar vektörüne sahip olmaktan kaçınmamızı sağlar. Fonksiyonel programlama stili, kodu daha net hale getirmek için değiştirilebilir durum (mutable state) miktarını en aza indirmeyi tercih eder. Değiştirilebilir durumu kaldırmak, aramanın paralel olarak gerçekleşmesini sağlayacak gelecekteki bir geliştirmeyi mümkün kılabilir, çünkü sonuclar vektörüne eşzamanlı erişimi yönetmek zorunda kalmayız. Liste 13-22 bu değişikliği göstermektedir.
pub fn ara<'a>(sorgu: &str, icerik: &'a str) -> Vec<&'a str> {
icerik
.lines()
.filter(|satir| satir.contains(sorgu))
.collect()
}
pub fn buyuk_kucuk_harf_duyarsiz_ara<'a>(
sorgu: &str,
icerik: &'a str,
) -> Vec<&'a str> {
let sorgu = sorgu.to_lowercase();
let mut sonuclar = Vec::new();
for satir in icerik.lines() {
if satir.to_lowercase().contains(&sorgu) {
sonuclar.push(satir);
}
}
sonuclar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let sorgu = "duct";
let icerik = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], ara(sorgu, icerik));
}
#[test]
fn case_insensitive() {
let sorgu = "rUsT";
let icerik = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
buyuk_kucuk_harf_duyarsiz_ara(sorgu, icerik)
);
}
}ara fonksiyonunun uygulamasında yineleyici adaptörü metotlarını kullanmakara fonksiyonunun amacının icerik içindeki sorguyu barındıran tüm satırları döndürmek (return) olduğunu unutmayın. Liste 13-16’daki filter (filtrele) örneğine benzer şekilde bu kod, yalnızca satir.contains(sorgu)’nun (line.contains(query)) true (doğru) döndürdüğü satırları tutmak için filter adaptörünü kullanır. Daha sonra eşleşen satırları collect (topla) ile başka bir vektörde toplarız. Çok daha basit! Aynı değişikliği buyuk_kucuk_harf_duyarsiz_ara fonksiyonunda da yineleyici metotlarını kullanmak için yapmaktan çekinmeyin.
Daha ileri bir iyileştirme olarak collect çağrısını kaldırıp fonksiyonun bir yineleyici adaptörü haline gelmesi için dönüş türünü impl Iterator<Item = &'a str> olarak değiştirerek ara fonksiyonundan bir yineleyici döndürün. Testleri de güncellemeniz gerekeceğini unutmayın! Davranıştaki farkı gözlemlemek için bu değişikliği yapmadan önce ve yaptıktan sonra minigrep aracınızı kullanarak büyük bir dosyada arama yapın. Bu değişiklikten önce program, tüm sonuçları toplayana kadar hiçbir sonucu yazdırmaz ancak değişiklikten sonra, eşleşen her satır bulundukça sonuçlar yazdırılacaktır, çünkü calistir fonksiyonundaki for döngüsü yineleyicinin tembelliğinden faydalanabilir.
Döngüler (Loops) ve Yineleyiciler (Iterators) Arasında Seçim Yapmak
Bir sonraki mantıksal soru, kendi kodunuzda hangi stili seçeceğiniz ve nedenidir: Liste 13-21’deki orijinal uygulama mı yoksa Liste 13-22’deki yineleyicileri kullanan versiyon mu (tüm sonuçları döndürmeden önce yineleyici döndürmek yerine biriktirdiğimizi varsayarak). Çoğu Rust programcısı yineleyici stilini kullanmayı tercih eder. Başlangıçta alışması biraz zordur ancak çeşitli yineleyici adaptörlerini (iterator adapters) ve ne yaptıklarını hissetmeye başladığınızda yineleyicilerin anlaşılması daha kolay olabilir. Döngülerin çeşitli kısımlarıyla uğraşmak ve yeni vektörler oluşturmak yerine, kod döngünün üst düzey hedefine odaklanır. Bu, sıradan kodun bir kısmını soyutlayarak, yineleyicideki her ögenin geçmesi gereken filtreleme koşulu gibi bu koda özgü kavramların daha kolay görülmesini sağlar.
Peki bu iki uygulama (implementations) gerçekten eşdeğer midir? Sezgisel varsayım (assumption), daha düşük seviyeli döngünün daha hızlı olacağı yönünde olabilir. Hadi performans hakkında konuşalım.
Döngüler ve İteratörlerde Performans
Döngülerde (Loops) ve Yineleyicilerde (Iterators) Performans
Döngü mü yoksa yineleyici mi kullanacağınızı belirlemek için hangi uygulamanın daha hızlı olduğunu bilmeniz gerekir: ara fonksiyonunun açık bir for döngüsüne sahip olan versiyonu mu yoksa yineleyicilerle olan versiyonu mu.
Sör Arthur Conan Doyle’un The Adventures of Sherlock Holmes (Sherlock Holmes’un Maceraları) kitabının tüm içeriğini bir String’e yükleyerek ve içeriğin içinde the kelimesini arayarak bir kıyaslama çalıştırdık. İşte ara fonksiyonunun for döngüsünü kullanan sürümü ile yineleyicileri kullanan sürümündeki kıyaslama sonuçları:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
İki uygulamanın da benzer performansları var! Buradaki amacımız iki versiyonun eşdeğer olduğunu kanıtlamak değil; bu iki uygulamanın performans açısından nasıl karşılaştırılacağına dair genel bir fikir edinmek olduğu için kıyaslama kodunu burada açıklamayacağız.
Daha kapsamlı bir kıyaslama için, icerik olarak çeşitli boyutlardaki çeşitli metinleri, sorgu olarak farklı uzunluklardaki farklı sözcükleri ve diğer her tür varyasyonu kullanarak kontrol etmelisiniz. Mesele şu: Yineleyiciler üst düzey bir soyutlama olmalarına rağmen, alt düzey kodu kendiniz yazsaydınız olacak kodla yaklaşık olarak aynı şekilde derlenir. Yineleyiciler Rust’ın sıfır maliyetli soyutlamalarından biridir; bununla, soyutlamayı kullanmanın (using the abstraction) hiçbir ek çalışma zamanı yükü getirmediğini kastediyoruz. Bu, C++’ın orijinal tasarımcısı ve uygulayıcısı Bjarne Stroustrup’un 2012 ETAPS “Foundations of C++” (C++’ın Temelleri) açılış sunumunda sıfır yükü tanımlamasına benzerdir:
Genel olarak, C++ uygulamaları sıfır yük ilkesine uyar: Kullanmadığınız şeylerin parasını ödemezsiniz. Ve dahası: Kullandığınız şeyi elle kodlayarak daha iyisini yapamazsınız.
Pek çok durumda, yineleyicileri kullanan Rust kodu, elle yazacağınız aynı assembly (çevirici) koduna derlenir. Döngü açma ve dizi erişimindeki sınır denetimini ortadan kaldırma gibi optimizasyonlar uygulanır ve ortaya çıkan kodu son derece verimli hale getirir. Artık bunu bildiğinize göre, yineleyicileri ve kapanışları korkusuzca kullanabilirsiniz! Kodu daha üst düzeymiş gibi gösterirler ancak bunu yaptığınız için bir çalışma zamanı performans cezası uygulamazlar.
Özet
Kapanışlar ve yineleyiciler, fonksiyonel programlama dili fikirlerinden esinlenilen Rust özellikleridir. Üst düzey fikirleri alt düzey performansta (low-level performance) açıkça ifade etme konusundaki Rust’ın kapasitesine katkıda bulunurlar. Kapanışların ve yineleyicilerin uygulamaları, çalışma zamanı performansının etkilenmeyeceği şekildedir. Bu, Rust’ın sıfır maliyetli soyutlamalar sağlamaya çabalama hedefinin bir parçasıdır.
G/Ç projemizin ifade gücünü artırdığımıza göre, şimdi projeyi dünyayla paylaşmamıza yardımcı olacak bazı cargo özelliklerine daha bakalım.
Cargo ve Crates.io Hakkında Daha Fazlası
Buraya kadar Cargo’nun yalnızca kodumuzu derlemek, çalıştırmak ve test etmek için gereken en temel özelliklerini kullandık; ama Cargo bundan çok daha fazlasını yapabilir. Bu bölümde, şu işleri nasıl yapacağınızı göstermek için daha gelişmiş bazı özelliklerine bakacağız:
- Derleme sürecinizi sürüm profilleriyle özelleştirmek.
- Kütüphaneleri crates.io üzerinde yayımlamak.
- Büyük projeleri çalışma alanlarıyla düzenlemek.
- crates.io üzerinden ikili dosyalar kurmak.
- Özel komutlarla Cargo’yu genişletmek.
Cargo, bu bölümde anlattıklarımızdan da fazlasını yapabilir. Tüm özelliklerinin ayrıntılı açıklaması için Cargo belgelerine bakın.
Sürüm Profilleriyle Derlemeleri Özelleştirme
Sürüm Profilleriyle Derlemeleri Özelleştirmek
Rust’ta sürüm profilleri (release profiles), bir programcının kod derlemeyle ilgili çeşitli seçenekler üzerinde daha fazla denetim sahibi olmasını sağlayan, önceden tanımlanmış ve özelleştirilebilir profil ayarlarıdır. Her profil diğerlerinden bağımsız olarak yapılandırılır.
Cargo’nun iki ana profili vardır: cargo build çalıştırdığınızda kullanılan
dev profili ve cargo build --release çalıştırdığınızda kullanılan release
profili. dev profili geliştirme için iyi varsayılanlarla gelir; release
profiliyse yayıma uygun derlemeler için iyi varsayılanlara sahiptir.
Bu profil adlarını, derleme çıktılarında daha önce görmüş olabilirsiniz:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
Buradaki dev ve release, derleyicinin kullandığı farklı profillerdir.
Projede Cargo.toml dosyasına açıkça herhangi bir [profile.*] bölümü
eklemediğiniz sürece Cargo, her profil için varsayılan ayarlar uygular.
Özelleştirmek istediğiniz profile uygun bir [profile.*] bölümü eklediğinizde,
varsayılan ayarların istediğiniz kısmını geçersiz kılmış olursunuz. Örneğin,
dev ve release profilleri için opt-level ayarının varsayılan değerleri
şöyledir:
Dosya Adı: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
opt-level ayarı, Rust’ın kodunuza uygulayacağı iyileştirme miktarını
belirler; aralık 0 ile 3 arasındadır. Daha fazla iyileştirme derleme süresini
uzatır. Bu yüzden geliştirme aşamasında kodunuzu sık sık derliyorsanız, ortaya
çıkan kod biraz daha yavaş çalışsa bile daha hızlı derleme için daha az
iyileştirme tercih edersiniz. Bu nedenle dev için varsayılan opt-level
değeri 0’dır. Kodunuzu yayımlamaya hazır olduğunuzdaysa derlemeye biraz daha
fazla zaman ayırmak en iyisidir. Sürüm kipinde genellikle bir kez derlersiniz,
ama derlenmiş programı çok kez çalıştırırsınız; bu yüzden sürüm kipi, daha uzun
derleme süresini daha hızlı çalışan kodla takas eder. release profili için
varsayılan opt-level değerinin 3 olmasının sebebi budur.
Varsayılan bir ayarı, Cargo.toml içine farklı bir değer yazarak geçersiz kılabilirsiniz. Örneğin geliştirme profilinde 1. düzey iyileştirme kullanmak istersek, projemizin Cargo.toml dosyasına şu iki satırı ekleyebiliriz:
Dosya Adı: Cargo.toml
[profile.dev]
opt-level = 1
Bu kod, varsayılan 0 ayarını geçersiz kılar. Artık cargo build
çalıştırdığımızda Cargo, dev profiline ait varsayılanlarla birlikte bizim
opt-level özelleştirmemizi de kullanır. opt-level değerini 1 yaptığımız
için Cargo varsayılandan daha fazla iyileştirme uygular, ama bir sürüm
derlemesindeki kadar fazla değil.
Her profil için tüm yapılandırma seçeneklerinin ve varsayılan değerlerin tam listesi için Cargo belgelerine bakın.
Crates.io'da Bir Crate Yayınlama
Bir Crate’i Crates.io’da Yayımlamak
Projelerimizde bağımlılık olarak crates.io üzerindeki paketleri kullandık; ama kendi paketlerinizi yayımlayarak kodunuzu başka insanlarla da paylaşabilirsiniz. crates.io üzerindeki crate kayıt sistemi, paketlerinizin kaynak kodunu dağıtır; yani ağırlıklı olarak açık kaynak kod barındırır.
Rust ve Cargo, yayımladığınız paketin başkaları tarafından daha kolay bulunmasını ve kullanılmasını sağlayan özellikler sunar. Önce bu özelliklerden bazılarına bakacağız, ardından bir paketin nasıl yayımlanacağını anlatacağız.
Yararlı Belgelendirme Yorumları Yazmak
Paketlerinizi doğru biçimde belgelendirmek, başka kullanıcıların onları ne zaman
ve nasıl kullanacağını anlamasını kolaylaştırır; bu yüzden iyi belgelere zaman
ayırmaya değer. 3. bölümde Rust koduna iki eğik çizgiyle, yani // ile yorum
eklemeyi görmüştük. Rust’ta ayrıca, HTML belgesi üreten özel bir yorum türü
olan belgelendirme yorumu (documentation comment) da vardır. Bu HTML,
crate’inizin nasıl kullanıldığını öğrenmek isteyen programcılar için tasarlanmış
açık API öğelerine ait belgelendirme yorumlarının içeriğini gösterir; crate’in
nasıl gerçeklendiğini değil.
Belgelendirme yorumları iki değil üç eğik çizgi, yani /// kullanır ve metni
biçimlendirmek için Markdown sözdizimini destekler. Belgelendirme yorumlarını,
belgelendirdikleri öğenin hemen üstüne yazın. Liste 14-1, benim_crate
adındaki bir crate içinde yer alan bir_ekle fonksiyonu için yazılmış bir
belgelendirme yorumunu gösteriyor.
/// Verilen sayıya bir ekler.
///
/// # Ornekler
///
/// ```
/// let girdi = 5;
/// let yanit = benim_crate::bir_ekle(girdi);
///
/// assert_eq!(6, yanit);
/// ```
pub fn bir_ekle(x: i32) -> i32 {
x + 1
}Burada bir_ekle fonksiyonunun ne yaptığını açıklıyoruz, ardından # Ornekler
başlığıyla bir bölüm açıyor ve fonksiyonun nasıl kullanılacağını gösteren bir
kod örneği veriyoruz. Bu belgelendirme yorumundan HTML belge üretmek için
cargo doc çalıştırabiliriz. Bu komut, Rust ile birlikte gelen rustdoc
aracını çalıştırır ve üretilen HTML belgeleri target/doc dizinine koyar.
Kolaylık olsun diye cargo doc --open, mevcut crate’inizin belgeleri için HTML
çıktısını derler; ayrıca tüm bağımlılıkların belgelerini de üretir ve sonucu
tarayıcıda açar. bir_ekle fonksiyonuna giderseniz, belgelendirme yorumundaki
metnin Şekil 14-1’deki gibi işlendiğini görürsünüz.
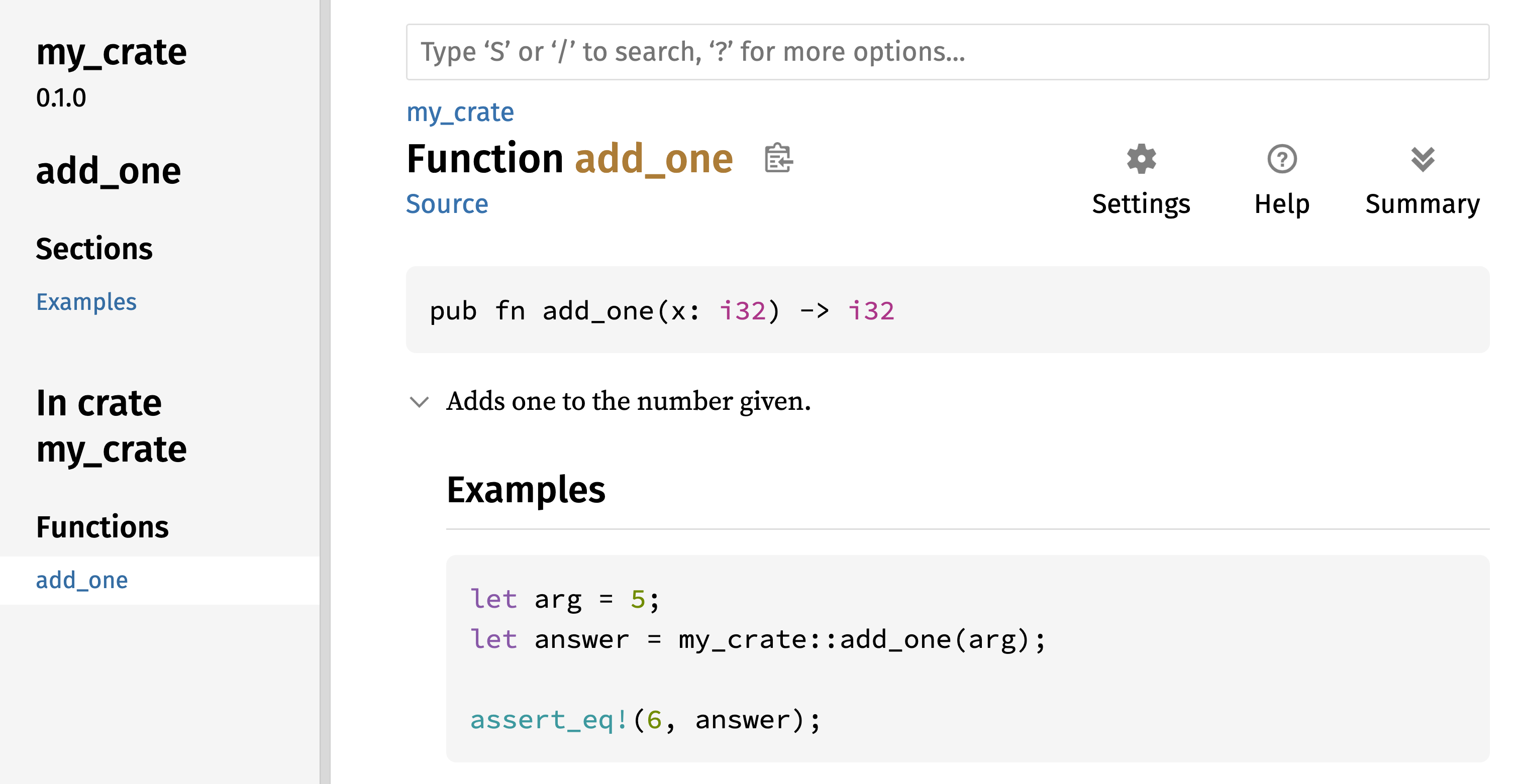
Şekil 14-1: bir_ekle fonksiyonu için HTML belgesi
Sık Kullanılan Bölümler
Liste 14-1’de HTML içinde “Ornekler” başlıklı bir bölüm oluşturmak için Markdown
başlığı olan # Ornekleri kullandık. Crate yazarlarının belgelerde sık kullandığı
başka bölümler de vardır:
- Panics: Belgelenen fonksiyonun hangi durumlarda panikleyebileceğini açıklar. Programlarının paniklemesini istemeyen çağıranlar, bu durumlarda fonksiyonu çağırmadığından emin olabilir.
- Errors: Fonksiyon bir
Resultdöndürüyorsa, hangi tür hataların oluşabileceğini ve bunların hangi koşullarda dönebileceğini anlatmak, çağıranların farklı hataları farklı biçimlerde ele alan kodlar yazmasını kolaylaştırır. - Safety: Fonksiyonu çağırmak
unsafeise, 20. bölümde ayrıntılandıracağımız gibi, nedenunsafeolduğunu ve çağıranların koruması gereken değişmezleri açıklayan bir bölüm bulunmalıdır.
Belgelendirme yorumlarının çoğunda bu bölümlerin hepsi gerekmez. Yine de bu liste, kullanıcıların kodunuz hakkında bilmek isteyeceği noktaları hatırlatan iyi bir denetim listesidir.
Belgelendirme Yorumlarını Test Olarak Kullanmak
Belgelendirme yorumlarının içine örnek kod blokları eklemek, kütüphanenizin
nasıl kullanılacağını göstermeye yardımcı olur ve güzel bir yan kazanç da sağlar:
cargo test çalıştırıldığında, belgelerdeki kod örnekleri de test olarak
çalıştırılır! Örnekli belge kadar iyi bir şey yoktur. Ama belge yazıldıktan
sonra kod değiştiği için artık çalışmayan örnekler kadar kötü bir şey de yok.
Liste 14-1’deki bir_ekle fonksiyonu belgesiyle cargo test çalıştırırsak,
test sonuçlarında şu bölümü görürüz:
Doc-tests benim_crate
running 1 test
test src/lib.rs - bir_ekle (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Şimdi fonksiyonu ya da örneği değiştirip örnekteki assert_eq! panikletecek
hale getirirsek ve cargo testi yeniden çalıştırırsak, belge testleri örneğin
ve kodun birbirinden koptuğunu hemen yakalar.
Kapsayıcı Öğeye Yazılan Yorumlar
//! biçimindeki doc yorumları, yorumların ardından gelen öğeyi değil,
yorumları içeren öğeyi belgelendirir. Bu yorumları genellikle crate kök
dosyasında (geleneksel olarak src/lib.rs) ya da bir modülün içinde, crate’i
veya modülü bütün olarak belgelendirmek için kullanırız.
Örneğin bir_ekle fonksiyonunu içeren benim_crate crate’inin amacını
açıklamak için, src/lib.rs dosyasının başına //! ile başlayan belge
yorumları ekleriz. Liste 14-2 bunu gösterir.
//! # Benim Crate'im
//!
//! `benim_crate`, belirli hesaplamalari yapmayi daha kullanisli hale getiren
//! yardimci araclarin bir koleksiyonudur.
/// Verilen sayiya bir ekler.
// --snip--
///
/// # Ornekler
///
/// ```
/// let girdi = 5;
/// let yanit = benim_crate::bir_ekle(girdi);
///
/// assert_eq!(6, yanit);
/// ```
pub fn bir_ekle(x: i32) -> i32 {
x + 1
}benim_crate crate’inin tamami icin yazilan belge//! ile başlayan son satırdan sonra hiç kod olmadığına dikkat edin. Yorumları
/// yerine //! ile başlattığımız için, bu yorumların ardından gelen öğeyi
değil, yorumu içeren öğeyi belgelendiriyoruz. Bu örnekte o öğe, crate kökü
olan src/lib.rs dosyasıdır. Yani bu yorumlar tüm crate’i anlatır.
cargo doc --open çalıştırdığımızda bu yorumlar, benim_crate için üretilen
belgenin ilk sayfasında, crate içindeki açık öğelerin listesinin üstünde
görünür. Şekil 14-2’de bunu görebilirsiniz.
Öğelerin içinde yazılan belgelendirme yorumları özellikle crate’leri ve modülleri anlatmak için kullanışlıdır. Bunları, kapsayıcının genel amacını açıklamak ve kullanıcıların crate’in düzenini anlamasına yardımcı olmak için kullanın.
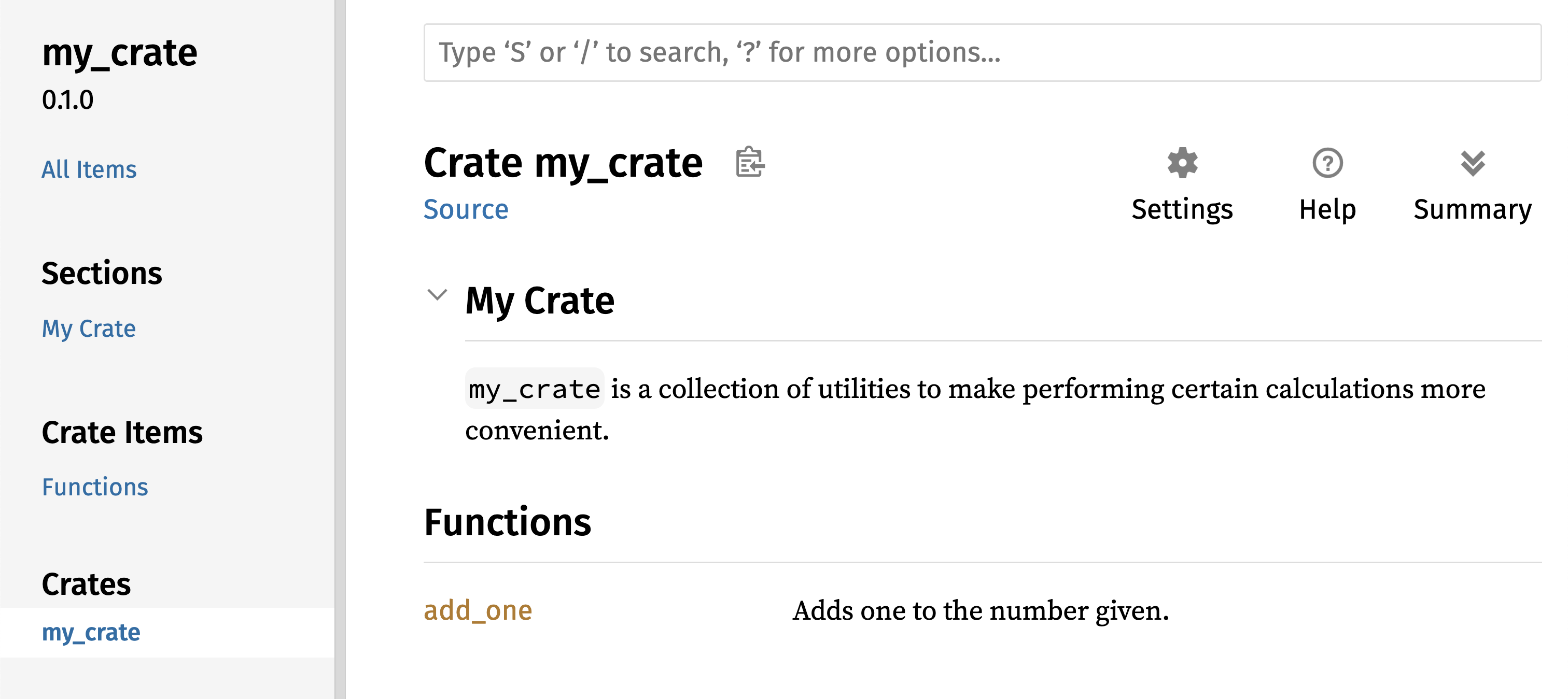
Şekil 14-2: benim_crate için işlenmiş belge; crate’i bir bütün olarak açıklayan yorum da buna dahil
Kullanışlı Bir Açık API Dışa Aktarmak
Bir crate yayımlarken açık API’nizin yapısı önemli bir tasarım kararıdır. Crate’inizi kullanan insanlar, yapıya sizin kadar hakim olmaz. Modül ağacı büyükse, ihtiyaç duydukları parçaları bulmakta zorlanabilirler.
- bölümde
pubanahtar sözcüğüyle öğeleri nasıl açık hale getirdiğimizi veuseanahtar sözcüğüyle öğeleri nasıl kapsama aldığımızı görmüştük. Ancak bir crate geliştirirken size mantıklı gelen yapı, kullanıcılarınız için o kadar pratik olmayabilir. Struct’ları veya türleri birkaç katmanlı bir hiyerarşide düzenlemek isteyebilirsiniz; ama hiyerarşinin derininde duran bir türü kullanmak isteyenler, önce o türün var olduğunu fark etmekte zorlanabilir. Ayrıcause benim_crate::bir_modul::baska_modul::FaydaliTur;yazmak yerine yalnızcause benim_crate::FaydaliTur;yazabilmek isterler.
Güzel haber şu: Yapı başka bir kütüphaneden kullanacak kişiler için pratik
değilse, iç düzeninizi baştan kurmak zorunda değilsiniz. Bunun yerine pub use
kullanarak, gizli yapınızdan farklı bir açık yapı oluşturacak şekilde öğeleri
yeniden dışa aktarabilirsiniz. Yeniden dışa aktarma (re-exporting), bir yerde
bulunan açık bir öğeyi başka bir yerde de açık hale getirir; sanki öğe doğrudan
orada tanımlanmış gibi davranır.
Örneğin sanatsal kavramları modellemek için sanat adında bir kütüphane
yazdığımızı düşünelim. Bu kütüphanede iki modül olsun: turler modülü
BirincilRenk ve IkincilRenk adlı iki enum içeriyor, yardimcilar modülü de
karistir adlı bir fonksiyon içeriyor. Liste 14-3 bunu gösterir.
//! # Sanat
//!
//! Sanatsal kavramlari modellemek icin bir kutuphane.
pub mod turler {
/// RYB renk modeline gore birincil renkler.
pub enum BirincilRenk {
Kirmizi,
Sari,
Mavi,
}
/// RYB renk modeline gore ikincil renkler.
pub enum IkincilRenk {
Turuncu,
Yesil,
Mor,
}
}
pub mod yardimcilar {
use crate::turler::*;
/// Iki birincil rengi esit miktarda birlestirerek
/// bir ikincil renk olusturur.
pub fn karistir(renk1: BirincilRenk, renk2: BirincilRenk) -> IkincilRenk {
// --snip--
let _ = (renk1, renk2);
unimplemented!();
}
}turler ve yardimcilar modullerine ayrilmis bir sanat kutuphanesiŞekil 14-3, bu crate için cargo doc ile üretilen belgenin ön sayfasının nasıl
görüneceğini gösterir.
Şekil 14-3: turler ve yardimcilar modüllerini listeleyen sanat belgesinin ön sayfası
Burada BirincilRenk ve IkincilRenk türlerinin ön sayfada listelenmediğine,
aynı şekilde karistir fonksiyonunun da görünmediğine dikkat edin. Bunları
görmek için turler ve yardimcilar bağlantılarına tıklamamız gerekir.
Bu kütüphaneye bağımlı başka bir crate, sanat içindeki öğeleri kullanmak için
şu an tanımlanmış modül yapısını belirten use ifadeleri yazmak zorunda kalır.
Liste 14-4, sanat crate’indeki BirincilRenk ve karistir öğelerini kullanan
bir crate örneğini gösterir.
use sanat::turler::BirincilRenk;
use sanat::yardimcilar::karistir;
fn main() {
let kirmizi = BirincilRenk::Kirmizi;
let sari = BirincilRenk::Sari;
karistir(kirmizi, sari);
}sanat crate’indeki ogeleri ic yapi disa aktarilmis halde kullanan bir crateListe 14-4’teki kodun yazarı, BirincilRenkin turler modülünde ve
karistirın yardimcilar modülünde olduğunu önce keşfetmek zorundadır.
sanat crate’inin modül yapısı, onu geliştirenler için onu kullananlardan daha
anlamlıdır. İç yapı, sanat crate’ini nasıl kullanacağını anlamaya çalışan biri
için yararlı bilgi sunmaz; tam tersine, nereye bakacağını çözmeye çalışan
geliştiricilerin kafasını karıştırır ve use ifadelerinde modül adlarını
yazmalarını gerektirir.
İç düzeni açık API’den kaldırmak için, Liste 14-3’teki sanat crate’i kodunu
değiştirip öğeleri üst düzeyde yeniden dışa aktaracak pub use ifadeleri
ekleyebiliriz. Liste 14-5 bunu gösterir.
//! # Sanat
//!
//! Sanatsal kavramlari modellemek icin bir kutuphane.
pub use self::turler::BirincilRenk;
pub use self::turler::IkincilRenk;
pub use self::yardimcilar::karistir;
pub mod turler {
// --snip--
/// RYB renk modeline gore birincil renkler.
pub enum BirincilRenk {
Kirmizi,
Sari,
Mavi,
}
/// RYB renk modeline gore ikincil renkler.
pub enum IkincilRenk {
Turuncu,
Yesil,
Mor,
}
}
pub mod yardimcilar {
// --snip--
use crate::turler::*;
/// Iki birincil rengi esit miktarda birlestirerek
/// bir ikincil renk olusturur.
pub fn karistir(renk1: BirincilRenk, renk2: BirincilRenk) -> IkincilRenk {
let _ = (renk1, renk2);
IkincilRenk::Turuncu
}
}pub use ifadeleri eklemekBu crate için cargo doc tarafından üretilen API belgesi artık yeniden dışa
aktarımları da ön sayfada listeler ve bağlantılar. Böylece BirincilRenk,
IkincilRenk ve karistir çok daha kolay bulunur. Şekil 14-4 bunu gösterir.
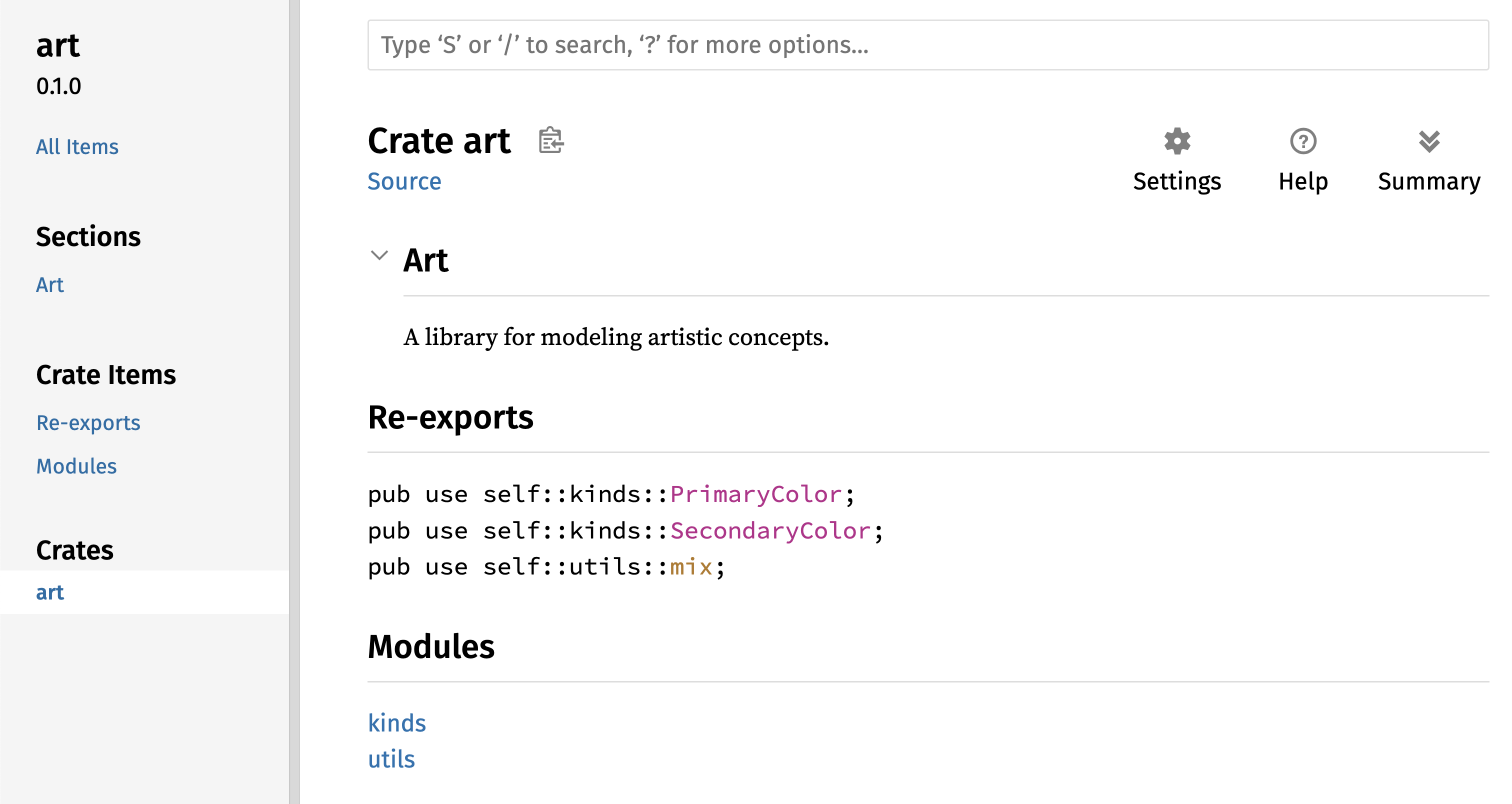
Şekil 14-4: Yeniden dışa aktarımları listeleyen sanat belgesinin ön sayfası
sanat crate’ini kullananlar isterlerse Liste 14-4’teki gibi iç yapıyı hâlâ
görüp kullanabilir, isterlerse Liste 14-5’teki daha kullanışlı yapıyı seçebilir.
Liste 14-6 ikinci yaklaşımı gösterir.
use sanat::karistir;
use sanat::BirincilRenk;
fn main() {
// --snip--
let kirmizi = BirincilRenk::Kirmizi;
let sari = BirincilRenk::Sari;
karistir(kirmizi, sari);
}sanat crate’inden yeniden disa aktarilan ogeleri kullanan bir programİç içe çok sayıda modül olduğunda, türleri üst düzeye pub use ile yeniden dışa
aktarmak, crate’i kullanan kişilerin deneyiminde ciddi fark yaratabilir.
pub use’ün bir başka yaygın kullanım alanı da bir bağımlılıktaki tanımları,
mevcut crate üzerinden yeniden dışa aktarıp onları sizin açık API’nizin bir
parçası haline getirmektir.
Kullanışlı bir açık API tasarlamak, tam anlamıyla bilimden çok biraz sanata
benzer; kullanıcılarınız için en iyi çalışan API’yi bulana kadar yineleme
yapabilirsiniz. pub use seçimi, iç yapınızı nasıl kuracağınız konusunda size
esneklik sağlar ve iç yapıyla kullanıcılara sunduğunuz yüzeyi birbirinden
ayırır. Kurduğunuz bazı crate’lerin koduna bakın; çoğunda iç yapının açık API’den
farklı olduğunu görürsünüz.
Crates.io Hesabı Açmak
Herhangi bir crate yayımlayabilmek için önce crates.io üzerinde bir hesap açmalı ve bir API belirteci almalısınız. Bunun
için crates.io ana sayfasına gidip GitHub
hesabınızla oturum açın. Şu anda GitHub hesabı zorunlu, ama ileride site başka
yöntemleri de destekleyebilir. Giriş yaptıktan sonra
https://crates.io/me/ adresindeki hesap
ayarlarınıza gidip API anahtarınızı alın. Sonra cargo login komutunu
çalıştırıp istendiğinde API anahtarınızı yapıştırın:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Bu komut Cargo’ya API belirtecinizi bildirir ve onu yerel olarak ~/.cargo/credentials.toml içine kaydeder. Bu belirtecin gizli olduğunu unutmayın: Kimseyle paylaşmayın. Herhangi bir nedenle paylaşırsanız derhal iptal edip yenisini üretin.
Yeni Bir Crate’e Meta Veri Eklemek
Yayımlamak istediğiniz bir crate’iniz olduğunu düşünelim. Yayımlamadan önce,
crate’in Cargo.toml dosyasındaki [package] bölümüne bazı meta veriler
eklemeniz gerekir.
Crate’inizin benzersiz bir adı olmalıdır. Yerelde çalışırken crate’e istediğiniz
adı verebilirsiniz. Ama crates.io üzerindeki
crate adları “ilk gelen alır” mantığıyla ayrılır. Bir ad alındığında, artık
başka hiç kimse o adla crate yayımlayamaz. Yayımlamayı denemeden önce
kullanmak istediğiniz adı arayın. Ad alınmışsa başka bir ad bulmalı ve
Cargo.toml içindeki [package] bölümündeki name alanını buna göre
güncellemelisiniz:
Dosya Adı: Cargo.toml
[package]
name = "tahmin_oyunu"
Benzersiz bir ad seçmiş olsanız bile, bu noktada cargo publish
çalıştırırsanız önce bir uyarı, ardından bir hata alırsınız:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Bu hatanın nedeni, bazı kritik bilgilerin eksik olmasıdır: bir açıklama ve bir
lisans zorunludur. Böylece insanlar crate’inizin ne yaptığını ve hangi
koşullarda kullanabileceklerini bilir. Cargo.toml içine, arama sonuçlarında da
görüneceği için bir iki cümlelik kısa bir açıklama ekleyin. license alanı
içinse bir lisans tanımlayıcısı değeri yazmanız gerekir. Linux Foundation’ın
Software Package Data Exchange (SPDX) listesi, bu alanda
kullanabileceğiniz tanımlayıcıları içerir. Örneğin crate’inizi MIT lisansıyla
lisansladığınızı belirtmek için MIT tanımlayıcısını ekleyebilirsiniz:
Dosya Adı: Cargo.toml
[package]
name = "tahmin_oyunu"
license = "MIT"
Kullanmak istediğiniz lisans SPDX listesinde yer almıyorsa, lisans metnini bir
dosyaya koymalı, o dosyayı projenize eklemeli ve license yerine license-file
anahtarını kullanarak dosya adını belirtmelisiniz.
Hangi lisansın projeniz için uygun olduğuna karar vermek bu kitabın kapsamı
dışında. Rust topluluğunda pek çok kişi projelerini, Rust’ın yaptığı gibi
MIT OR Apache-2.0 çift lisansıyla lisanslar. Bu kullanım, projeniz için
birden fazla lisansı OR ile ayırarak yazabileceğinizi de gösterir.
Benzersiz bir ad, sürüm, açıklama ve lisans eklendiğinde, yayımlanmaya hazır bir projenin Cargo.toml dosyası şöyle görünebilir:
Dosya Adı: Cargo.toml
[package]
name = "tahmin_oyunu"
version = "0.1.0"
edition = "2024"
description = "Bilgisayarin sectigi sayiyi tahmin ettiginiz eglenceli bir oyun."
license = "MIT OR Apache-2.0"
[dependencies]
Cargo belgeleri başka hangi meta verileri ekleyebileceğinizi de anlatır; böylece başkalarının crate’inizi daha kolay keşfetmesini ve kullanmasını sağlayabilirsiniz.
Crates.io’ya Yayımlamak
Hesabınızı oluşturduğunuza, API belirtecinizi kaydettiğinize, crate’inize ad verdiğinize ve gerekli meta verileri eklediğinize göre artık yayıma hazırsınız. Bir crate yayımlamak, belirli bir sürümü başkalarının kullanabilmesi için crates.io üzerine yükler.
Dikkatli olun; yayımlama kalıcıdır. Bir sürümün üstüne asla yazılamaz ve kod yalnızca bazı özel durumlarda silinebilir. Crates.io’nun temel amaçlarından biri, crates.io üzerindeki crate’lere bağlı tüm projelerin derlemelerinin gelecekte de çalışmasını sağlayan kalıcı bir arşiv olmasıdır. Sürümleri silmeye izin vermek bu amacı imkânsız hale getirirdi. Öte yandan yayımlayabileceğiniz sürüm sayısında herhangi bir sınır yoktur.
cargo publish komutunu yeniden çalıştırın. Bu kez başarılı olmalıdır:
$ cargo publish
Updating crates.io index
Packaging tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Compiling tahmin_oyunu v0.1.0
(file:///projects/tahmin_oyunu/target/package/tahmin_oyunu-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading tahmin_oyunu v0.1.0 (file:///projects/tahmin_oyunu)
Uploaded tahmin_oyunu v0.1.0 to registry `crates-io`
note: waiting for `tahmin_oyunu v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published tahmin_oyunu v0.1.0 at registry `crates-io`
Tebrikler! Kodunuzu artık Rust topluluğuyla paylaştınız; isteyen herkes sizin crate’inizi projesine bağımlılık olarak kolayca ekleyebilir.
Var Olan Bir Crate’in Yeni Sürümünü Yayımlamak
Crate’inizde değişiklik yapıp yeni bir sürüm yayımlamaya hazır olduğunuzda,
Cargo.toml dosyasındaki version değerini değiştirir ve yeniden yayımlarsınız.
Yaptığınız değişikliğin türüne göre uygun sonraki sürüm numarasını seçmek için
Semantik Sürümleme kurallarını kullanın. Sonra cargo publish
çalıştırarak yeni sürümü yükleyin.
Crates.io’da Sürümleri Kullanımdan Kaldırmak
Bir crate’in önceki sürümlerini silemezsiniz; ama yeni projelerin onları yeni bir bağımlılık olarak eklemesini engelleyebilirsiniz. Bu, bir crate sürümü bir sebeple bozuk çıktığında işe yarar. Böyle durumlar için Cargo, bir sürümü yank etmeyi destekler.
Bir sürümü yank etmek, mevcut projelerin çalışmasını bozmadan yeni projelerin o sürüme bağımlı olmasını engeller. Pratikte bu, elinde Cargo.lock bulunan projelerin bozulmaması, ama gelecekte üretilecek yeni Cargo.lock dosyalarının yank edilen sürümü seçmemesi demektir.
Daha önce yayımladığınız bir crate’in belirli bir sürümünü yank etmek için,
crate dizininde cargo yank çalıştırır ve istediğiniz sürümü belirtirsiniz.
Örneğin tahmin_oyunu adlı crate’in 1.0.1 sürümünü yayımladıysak ve şimdi
yank etmek istiyorsak, proje dizininde şu komutu çalıştırırız:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank tahmin_oyunu@1.0.1
Komuta --undo ekleyerek yapılan yank işlemini geri de alabilirsiniz:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank tahmin_oyunu@1.0.1
Bir yank işlemi hiçbir kodu silmez. Örneğin yanlışlıkla yüklenmiş gizli bilgileri ortadan kaldırmaz. Böyle bir şey olduysa o gizli bilgileri hemen sıfırlamanız gerekir.
Cargo Çalışma Alanları (Workspaces)
Cargo Çalışma Alanları
- bölümde hem ikili crate hem de kütüphane crate içeren bir paket oluşturmuştuk. Projeniz büyüdükçe kütüphane crate’in de büyümeye devam ettiğini ve paketi birden fazla kütüphane crate’e bölmek istediğinizi fark edebilirsiniz. Cargo’nun çalışma alanı (workspace) adı verilen özelliği, birlikte geliştirilen ilişkili birden çok paketi yönetmeyi kolaylaştırır.
Bir Çalışma Alanı Oluşturmak
Çalışma alanı, aynı Cargo.lock dosyasını ve aynı çıktı dizinini paylaşan
paketler kümesidir. Yapıya odaklanabilmek için basit kod kullanan bir çalışma
alanı örneği oluşturalım. Çalışma alanını düzenlemenin farklı yolları vardır;
biz yalnızca yaygın bir yaklaşımı göstereceğiz. Bir ikili crate ve iki kütüphane
crate içeren bir çalışma alanımız olacak. Ana işlevi sunacak ikili crate,
iki kütüphaneye bağımlı olacak. Kütüphanelerden biri bir_ekle fonksiyonunu,
diğeri ise iki_ekle fonksiyonunu sağlayacak. Bu üç crate aynı çalışma alanının
parçası olacak. Önce çalışma alanı için yeni bir dizin oluşturalım:
$ mkdir add
$ cd add
Ardından add dizininde, tüm çalışma alanını yapılandıracak Cargo.toml
dosyasını oluşturalım. Bu dosyada [package] bölümü olmayacak. Onun yerine
üyeleri eklememizi sağlayacak bir [workspace] bölümüyle başlayacak. Ayrıca
çözümleyicinin en güncel sürümünü kullanmak için resolver değerini "3"
yapacağız:
Dosya Adı: Cargo.toml
[workspace]
resolver = "3"
Şimdi topla dizini içinde cargo new çalıştırarak toplayici ikili crate’ini
oluşturalım:
$ cargo new toplayici
Created binary (application) `toplayici` package
Adding `toplayici` as member of workspace at `file:///projects/topla`
Bir çalışma alanı içinde cargo new çalıştırıldığında, Cargo yeni oluşturulan
paketi çalışma alanı Cargo.toml dosyasındaki [workspace] tanımının members
anahtarına da otomatik olarak ekler:
[workspace]
resolver = "3"
members = ["toplayici"]
Bu noktada cargo build çalıştırarak çalışma alanını derleyebiliriz. topla
dizininizin dosya yapısı şu hale gelir:
├── Cargo.lock
├── Cargo.toml
├── toplayici
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Çalışma alanının en üst düzeyde tek bir target dizini vardır ve derlenmiş
yapıtlar bu dizine yazılır; toplayici paketinin kendine ait bir target dizini
yoktur. Hatta cargo buildi toplayici dizininden çalıştırsak bile çıktılar yine
topla/target altına gider; topla/toplayici/target altına değil. Cargo çalışma
alanlarında target dizinini böyle düzenler çünkü bu crate’lerin birbirine
bağımlı olması beklenir. Her crate’in kendi target dizini olsaydı, her crate
diğer crate’leri de kendi dizinine çıktı koymak için yeniden derlemek zorunda
kalırdı. Ortak bir target dizini paylaşmak gereksiz yeniden derlemeleri önler.
Çalışma Alanına İkinci Paketi Eklemek
Şimdi çalışma alanına bir üye paket daha ekleyelim ve buna bir_ekle diyelim.
bir_ekle adlı yeni bir kütüphane crate’i üretin:
$ cargo new bir_ekle --lib
Created library `bir_ekle` package
Adding `bir_ekle` as member of workspace at `file:///projects/topla`
Üst düzey Cargo.toml artık members listesinde bir_ekle yolunu da içerir:
Dosya Adı: Cargo.toml
[workspace]
resolver = "3"
members = ["toplayici", "bir_ekle"]
topla dizininizin dosya yapısı artık şöyle olur:
├── Cargo.lock
├── Cargo.toml
├── bir_ekle
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── toplayici
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Şimdi bir_ekle/src/lib.rs dosyasına bir_ekle fonksiyonunu ekleyelim:
Dosya Adı: bir_ekle/src/lib.rs
pub fn bir_ekle(x: i32) -> i32 {
x + 1
}Artık ikili crate’imizi barındıran toplayici paketinin, bu kütüphaneyi içeren
pakete bağımlı olmasını sağlayabiliriz. Önce toplayici/Cargo.toml dosyasına bu
crate için yol bağımlılığı eklememiz gerekir.
Dosya Adı: toplayici/Cargo.toml
[dependencies]
bir_ekle = { path = "../bir_ekle", package = "bir_ekle" }
Cargo, çalışma alanındaki crate’lerin birbirine bağımlı olacağını kendiliğinden varsaymaz; bu ilişkileri açıkça yazmamız gerekir.
Şimdi toplayici crate’inde bir_ekle fonksiyonunu kullanalım. toplayici/src/main.rs
dosyasını açıp main fonksiyonunu, Liste 14-7’deki gibi bir_ekle
fonksiyonunu çağıracak şekilde değiştirin.
fn main() {
let sayi = 10;
println!(
"Merhaba, dünya! {sayi} artı bir {} eder!",
bir_ekle::bir_ekle(sayi)
);
}toplayici crate’inden bir_ekle kutuphane fonksiyonunu kullanmakŞimdi çalışma alanının en üst düzeyindeki topla dizininde cargo build
çalıştırarak her şeyi derleyelim!
$ cargo build
Compiling bir_ekle v0.1.0 (file:///projects/topla/bir_ekle)
Compiling toplayici v0.1.0 (file:///projects/topla/toplayici)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
İkili crate’i topla dizininden çalıştırmak için, çalışma alanındaki hangi paketi
çalıştırmak istediğimizi -p bayrağı ve paket adıyla belirtiriz:
$ cargo run -p toplayici
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/toplayici`
Merhaba, dünya! 10 artı bir 11 eder!
Bu komut, toplayici/src/main.rs içindeki ve bir_ekle crate’ine bağımlı olan kodu
çalıştırır.
Harici Bir Pakete Bağımlı Olmak
Çalışma alanında her crate dizininde ayrı bir Cargo.lock yerine, üst düzeyde
tek bir Cargo.lock dosyası bulunduğuna dikkat edin. Bu, tüm crate’lerin tüm
bağımlılıkların aynı sürümünü kullanmasını sağlar. toplayici/Cargo.toml ve
bir_ekle/Cargo.toml dosyalarına rand paketini eklersek, Cargo bunları tek
bir rand sürümüne çözer ve bunu tek Cargo.lock dosyasına yazar. Böylece
çalışma alanındaki tüm crate’ler birbirleriyle uyumlu kalır. Şimdi rand
crate’ini bir_ekle/Cargo.toml içindeki [dependencies] bölümüne ekleyelim ki
onu bir_ekle crate’inde kullanabilelim:
Dosya Adı: bir_ekle/Cargo.toml
[dependencies]
rand = "0.8.5"
Şimdi bir_ekle/src/lib.rs dosyasına use rand; ekleyebiliriz. Ardından topla
dizininde cargo build çalıştırınca, tüm çalışma alanıyla birlikte rand
crate’i de indirilip derlenir. randı kapsama aldığımız halde kullanmadığımız
için bir uyarı görürüz:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling bir_ekle v0.1.0 (file:///projects/topla/bir_ekle)
warning: unused import: `rand`
--> bir_ekle/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `bir_ekle` (lib) generated 1 warning (run `cargo fix --lib -p bir_ekle` to apply 1 suggestion)
Compiling toplayici v0.1.0 (file:///projects/topla/toplayici)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Artık üst düzey Cargo.lock dosyası, bir_ekle crate’inin rand bağımlılığına
ilişkin bilgiyi içerir. Ama rand çalışma alanında bir yerde kullanılıyor diye,
onu diğer crate’lerde de otomatik kullanamayız; bunun için onların Cargo.toml
dosyalarına da rand eklememiz gerekir. Örneğin toplayici paketine ait
toplayici/src/main.rs dosyasına use rand; yazarsak hata alırız:
$ cargo build
--snip--
Compiling toplayici v0.1.0 (file:///projects/topla/toplayici)
error[E0432]: unresolved import `rand`
--> toplayici/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Bunu düzeltmek için toplayici paketinin Cargo.toml dosyasını düzenleyip randın
ona da bağımlılık olduğunu belirtmemiz gerekir. toplayici paketini derlemek,
Cargo.lock içinde toplayici için bağımlılık listesine randı ekler; ama randın
ek bir kopyası indirilmez. Cargo, çalışma alanındaki her pakette rand
kullanan crate’lerin, uyumlu sürüm belirttikleri sürece aynı rand sürümünü
kullanmasını sağlar. Bu da hem yer kazandırır hem de crate’lerin birbiriyle
uyumlu kalmasını sağlar.
Çalışma alanındaki crate’ler aynı bağımlılığın birbiriyle uyumsuz sürümlerini isterse, Cargo hepsini ayrı ayrı çözer; ama yine de olabildiğince az sayıda sürüm kullanmaya çalışır.
Çalışma Alanına Test Eklemek
Bir geliştirme daha yapalım ve bir_ekle crate’i içinde bir_ekle::bir_ekle
fonksiyonu için bir test ekleyelim:
Dosya Adı: bir_ekle/src/lib.rs
pub fn bir_ekle(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn calisir() {
assert_eq!(3, bir_ekle(2));
}
}Şimdi üst düzey topla dizininde cargo test çalıştırın. Böyle yapılandırılmış
bir çalışma alanında cargo test, çalışma alanındaki tüm crate’lerin testlerini
çalıştırır:
$ cargo test
Compiling bir_ekle v0.1.0 (file:///projects/topla/bir_ekle)
Compiling toplayici v0.1.0 (file:///projects/topla/toplayici)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/bir_ekle-93c49ee75dc46543)
running 1 test
test tests::calisir ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/toplayici-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests bir_ekle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Çıktının ilk bölümü, bir_ekle crate’i içindeki calisir testinin geçtiğini
gösterir. Sonraki bölümde toplayici crate’inde hiç test bulunmadığını, son bölümde
de bir_ekle crate’inde hiç belge testi olmadığını görürüz.
Üst düzey dizinden, çalışma alanındaki tek bir crate için de test
çalıştırabiliriz. Bunun için -p bayrağını kullanıp test etmek istediğimiz
crate adını belirtiriz:
$ cargo test -p bir_ekle
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/bir_ekle-93c49ee75dc46543)
running 1 test
test tests::calisir ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests bir_ekle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bu çıktı, cargo testin yalnızca bir_ekle crate’inin testlerini
çalıştırdığını ve toplayici crate’inin testlerini çalıştırmadığını gösterir.
Çalışma alanındaki crate’leri crates.io
üzerinde yayımlarsanız, her crate’i ayrı ayrı yayımlamanız gerekir. cargo test
örneğinde olduğu gibi, -p bayrağını kullanarak çalışma alanındaki belirli bir
crate’i yayımlayabilirsiniz.
Ek pratik olarak, bu çalışma alanına iki_ekle adında bir crate’i de bir_ekle
crate’iyle benzer biçimde ekleyin!
Projeniz büyüdükçe çalışma alanı kullanmayı düşünün: Tek parça büyük bir kod yığını yerine daha küçük ve daha kolay anlaşılır bileşenlerle çalışmanıza olanak tanır. Üstelik çalışma alanındaki crate’ler aynı anda sık değişiyorsa, aralarındaki eşgüdümü de kolaylaştırır.
cargo install ile İkili Dosyaları Kurma
cargo install ile İkili Dosyalar Kurmak
cargo install komutu, ikili crate’leri yerel olarak kurup kullanmanıza
olanak tanır. Bu komut sistem paketlerinin yerini almak için değil, Rust
geliştiricilerinin başkalarının crates.io
üzerinde paylaştığı araçları pratik biçimde kurabilmesi için tasarlanmıştır.
Yalnızca ikili hedefi (binary target) olan paketleri kurabileceğinizi
unutmayın. İkili hedef (binary target), crate içinde src/main.rs dosyası ya
da ikili olarak belirtilmiş başka bir dosya varsa oluşturulan çalıştırılabilir
programdır. Buna karşılık kütüphane hedefi tek başına çalıştırılamaz; ama başka
programların içine eklenmek için uygundur. Genellikle crate’lerin README
dosyasında, ilgili crate’in bir kütüphane mi, ikili hedef mi, yoksa her ikisini
de mi içerdiği bilgisi yer alır.
cargo install ile kurulan tüm ikili dosyalar, kurulum kök dizininin bin
klasöründe tutulur. Rust’ı rustup.rs ile kurduysanız ve özel bir ayar
yapmadıysanız bu dizin $HOME/.cargo/bin olur. cargo install ile kurduğunuz
programları çalıştırabilmek için bu dizinin $PATH içinde olduğundan emin olun.
Örneğin, 12. bölümde dosya aramak için kullanılan grep aracının Rust ile
yazılmış bir sürümü olan ripgrepten söz etmiştik. ripgrep kurmak için şu
komutu çalıştırabiliriz:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
Çıktının sondan bir önceki satırı, kurulan ikili dosyanın konumunu ve adını
gösterir; ripgrep örneğinde bu ad rg’dir. Daha önce de söylediğimiz gibi,
kurulum dizini $PATH içinde olduğu sürece rg --help çalıştırabilir ve dosya
aramak için daha hızlı, daha “Rust usulü” bir araç kullanmaya başlayabilirsiniz.
Özel Komutlarla Cargo'yu Genişletme
Özel Komutlarla Cargo’yu Genişletmek
Cargo, kendisini değiştirmeden yeni alt komutlarla genişletebileceğiniz şekilde
tasarlanmıştır. $PATH içinde adı cargo-birsey olan bir ikili dosya varsa,
onu cargo birsey yazarak sanki Cargo’nun kendi alt komutlarından biriymiş
gibi çalıştırabilirsiniz. Böyle özel komutlar, cargo --list çıktısında da
listelenir. Eklentileri cargo install ile kurup ardından yerleşik Cargo
araçlarıyla aynı şekilde çalıştırabilmek, Cargo tasarımının çok kullanışlı bir
yanıdır.
Özet
Cargo ve crates.io ile kod paylaşmak, Rust ekosistemini pek çok farklı iş için kullanışlı kılan şeylerden biridir. Rust’ın standart kütüphanesi küçük ve kararlıdır; ama crate’leri paylaşmak, kullanmak ve dilden bağımsız bir hızda geliştirmek kolaydır. İşinize yarayan kodu crates.io üzerinde paylaşmaktan çekinmeyin; büyük olasılıkla başka birinin de işine yarayacaktır.
Akıllı İşaretçiler
İşaretçi, bellekteki bir adresi tutan değişkenler için kullanılan genel bir
kavramdır. Bu adres başka bir veriye karşılık gelir; yani o veriyi “işaret
eder”. Rust’taki en yaygın işaretçi türü, 4. bölümde öğrendiğiniz
referanslardır. Referanslar & simgesiyle gösterilir ve işaret ettikleri
değeri ödünç alırlar. Veri göstermenin dışında özel bir yetenekleri yoktur;
ek maliyet de getirmezler.
Akıllı işaretçiler (smart pointers) ise işaretçi gibi davranan ama buna ek olarak meta veri ve ek yetenekler de taşıyan veri yapılarıdır. Akıllı işaretçiler yalnızca Rust’a özgü değildir: Kökenleri C++’a uzanır ve başka dillerde de bulunurlar. Rust’ın standart kütüphanesinde, referansların sunduğu olanakların ötesine geçen farklı akıllı işaretçi türleri vardır. Genel fikri incelemek için birkaç örneğe bakacağız; bunların arasında, referans sayımı (reference counting) kullanan bir akıllı işaretçi türü de olacak. Bu işaretçi, sahip sayısını takip ederek ve ortada sahip kalmadığında veriyi temizleyerek, aynı verinin birden fazla sahibi olmasına izin verir.
Rust’ta sahiplik ve ödünç alma kavramları bulunduğu için referanslarla akıllı işaretçiler arasında ek bir fark daha vardır: Referanslar yalnızca veri ödünç alırken, akıllı işaretçiler çoğu durumda işaret ettikleri verinin sahibi olur.
Akıllı işaretçiler genellikle struct’larla gerçeklenir. Sıradan bir struct’tan
farklı olarak Deref ve Drop trait’lerini uygularlar. Deref trait’i,
akıllı işaretçi struct’ının örneğinin referans gibi davranmasını sağlar; böylece
kodunuzu hem referanslarla hem akıllı işaretçilerle çalışacak biçimde
yazabilirsiniz. Drop trait’i ise bir akıllı işaretçi örneği kapsam dışına
çıktığında çalışacak kodu özelleştirmenize izin verir. Bu bölümde her iki
trait’i de ele alacak ve akıllı işaretçiler için neden önemli olduklarını
göstereceğiz.
Akıllı işaretçi deseni, Rust’ta sık kullanılan genel bir tasarım deseni olduğu için bu bölüm mevcut tüm akıllı işaretçileri kapsamayacak. Birçok kütüphanenin kendi akıllı işaretçileri vardır; isterseniz siz de kendinizinkini yazabilirsiniz. Biz standart kütüphanedeki en yaygın akıllı işaretçilere odaklanacağız:
Box<T>, değerleri yığında (heap) saklamak içinRc<T>, birden çok sahipliğe izin veren referans sayımlı türRef<T>veRefMut<T>; bunlaraRefCell<T>üzerinden erişilir ve ödünç alma kurallarını derleme zamanında değil çalışma zamanında denetler
Bunlara ek olarak, değiştirilemez bir türün içindeki değeri değiştirmeye izin veren bir API sunduğu içsel değiştirilebilirlik (interior mutability) desenini de işleyeceğiz. Ayrıca referans döngülerini, bunların nasıl bellek sızıntısına yol açabileceğini ve nasıl önlenebileceğini de konuşacağız.
Hadi başlayalım!
Heap Üzerindeki Veriyi İşaret Etmek İçin Box<T> Kullanımı
Yığındaki Veriyi İşaret Etmek İçin Box<T> Kullanmak
En sade akıllı işaretçi kutudur; türü Box<T> diye yazılır. Kutular
(boxes), veriyi yığın yerine öbekte (heap) saklamanızı sağlar. Yığında kalan
şey, öbekteki veriyi gösteren işaretçinin kendisidir. Yığın ile öbek arasındaki
farkı tazelemek için 4. bölüme bakabilirsiniz.
Kutuların, veriyi yığın yerine öbekte tutmak dışında belirgin bir ek maliyeti yoktur. Ama ek yetenekleri de çok fazla değildir. Genellikle şu durumlarda kullanırsınız:
- Boyutu derleme zamanında bilinemeyen bir türünüz vardır ve bu türün değerini, tam boyut gerektiren bir bağlamda kullanmak istersiniz.
- Büyük miktarda veriniz vardır; sahipliği taşımak istersiniz ama bunu yaparken verinin kopyalanmamasını istersiniz.
- Belirli bir somut türü değil, belli bir trait’i uygulayan herhangi bir türü sahiplenmek istersiniz.
İlk durumu “Kutularla Özyineli Türleri Mümkün Kılmak” bölümünde göstereceğiz. İkinci durumda, büyük verinin sahipliğini taşımak uzun sürebilir; çünkü veri yığın üzerinde kopyalanır. Bu performansı iyileştirmek için veriyi kutu içinde öbekte tutabiliriz. Böylece yığında yalnızca küçük işaretçi verisi kopyalanır, asıl veri ise öbekte aynı yerde kalır. Üçüncü durumaysa trait nesnesi (trait object) denir; 18. bölümdeki [“Trait Nesneleriyle Ortak Davranışı Soyutlamak”][trait-objects] başlığı tamamen buna ayrılmıştır. Burada öğrenecekleriniz orada da işinize yarayacak!
Veriyi Öbekte Saklamak
Box<T> için öbekte saklama kullanım senaryosuna geçmeden önce sözdizimine ve
Box<T> içindeki değerlerle nasıl etkileşim kurulduğuna bakalım.
Liste 15-1, bir kutunun i32 değerini öbekte saklamak için nasıl
kullanıldığını gösteriyor.
fn main() {
let k = Box::new(5);
println!("k = {k}");
}i32 degerini kutu kullanarak obekte saklamakk değişkenine, öbekte ayrılmış 5 değerini işaret eden bir Box atıyoruz.
Program k = 5 yazdırır; bu durumda kutudaki veriye, veri yığındaymış gibi
erişebiliriz. Her sahip olunan değer gibi, kutu kapsam dışına çıktığında
serbest bırakılır. Bu serbest bırakma hem yığındaki kutunun kendisi hem de
öbekte işaret ettiği veri için gerçekleşir.
Tek bir değeri öbeğe koymak çok heyecan verici değildir; bu yüzden kutuları çoğu
zaman tek başlarına bu şekilde kullanmazsınız. Tek bir i32 gibi varsayılan
olarak yığında duran değerler çoğu durumda zaten daha uygundur. Şimdi kutuların
olmasaydı tanımlayamayacağımız türleri nasıl mümkün kıldığına bakalım.
Kutularla Özyineli Türleri Mümkün Kılmak
Özyineli tür (recursive type) değerleri, kendi içinde aynı türden başka bir
değeri barındırabilir. Bu türler sorun yaratır çünkü Rust’ın bir türün ne kadar
yer kapladığını derleme zamanında bilmesi gerekir. Oysa özyineli türlerde iç içe
geçme teorik olarak sonsuza dek sürebilir; dolayısıyla Rust değer için gereken
alanı bilemez. Box<T> bilinen bir boyuta sahip olduğu için, özyineli tür
tanımına kutu ekleyerek bu sorunu çözeriz.
Örnek olarak cons list türüne bakalım. Bu veri türü fonksiyonel programlama dillerinde yaygındır. Tanımlayacağımız cons list, özyineleme dışında oldukça basittir; bu yüzden burada gördüğümüz fikirler, ileride daha karmaşık özyineli durumlarda da işinize yarar.
Cons Listeyi Anlamak
Cons liste, Lisp programlama dili ve türevlerinden gelen, iç içe çiftlerden
oluşan ve bağlı listenin Lisp dünyasındaki karşılığı olan bir veri yapısıdır.
Adını, Lisp’teki cons fonksiyonundan alır; bu ad aslında construct
function’ın kısaltmasıdır. İki argümandan yeni bir çift oluşturur. Bir değerle
başka bir çiftten oluşan yapılar üzerinde cons çağrıları yaparak özyineli
çiftlerden oluşan cons listeler kurabiliriz.
Örneğin 1, 2, 3 listesini içeren bir cons listenin sözde kod gösterimi şöyledir:
(1, (2, (3, Nil)))
Cons listedeki her öğe iki parçadan oluşur: mevcut öğenin değeri ve bir sonraki
öğenin değeri. Listenin son öğesi, sonraki öğe olmadan yalnızca Nil denilen
değeri taşır. Cons liste, cons fonksiyonunun özyineli biçimde çağrılmasıyla
üretilir. Özyinelemenin taban durumu için geleneksel ad Nildir. Bunun, 6.
bölümde gördüğümüz geçersiz ya da eksik değer anlamındaki “null” veya “nil”
fikriyle aynı şey olmadığını unutmayın.
Cons liste Rust’ta pek yaygın değildir. Rust’ta çoğu durumda öğe listesi
gerekiyorsa Vec<T> daha iyi seçimdir. Ama daha karmaşık özyineli veri türleri
çeşitli durumlarda kullanışlıdır; bu bölümde cons listeyle başlamak, dikkat
dağıtıcı ayrıntılara boğulmadan kutuların özyineli veri türünü nasıl mümkün
kıldığını görmemizi sağlar.
Liste 15-2, cons listeyi temsil edecek bir enum tanımı içeriyor. Bu kod henüz
derlenmeyecek; çünkü birazdan göstereceğimiz gibi Liste türünün bilinen bir
boyutu yoktur.
enum Liste {
Dugum(i32, Liste),
Bos,
}
fn main() {}i32 degerlerinden olusan bir kons liste veri yapisini temsil etmek icin enum tanimlamaya ilk denemeNot: Bu örnekte yalnızca
i32değerleri tutan bir cons liste gerçekliyoruz. 10. bölümde gördüğümüz gibi bunu jeneriklerle de yapabilir ve her türden değeri saklayabilen bir cons liste tanımlayabilirdik.
1, 2, 3 listesini Liste türüyle saklamak, Liste 15-3’teki gibi görünür.
enum Liste {
Dugum(i32, Liste),
Bos,
}
// --snip--
use crate::Liste::{Bos, Dugum};
fn main() {
let liste = Dugum(1, Dugum(2, Dugum(3, Bos)));
}1, 2, 3 listesini saklamak icin Liste enumunu kullanmakİlk Dugum değeri 1 ve başka bir Liste değeri taşır. Bu Liste, 2 ve
başka bir Liste taşıyan başka bir Dugumdur. Sonraki Liste de 3 ve
sonunda listenin bittiğini bildiren özyineli olmayan Bos varyantını tutar.
Liste 15-3’teki kodu derlemeye çalışırsak, Liste 15-4’teki hatayı alırız.
$ cargo run
Compiling kons-liste v0.1.0 (file:///projects/kons-liste)
error[E0072]: recursive type `Liste` has infinite size
--> src/main.rs:1:1
|
1 | enum Liste {
| ^^^^^^^^^
2 | Dugum(i32, Liste),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Dugum(i32, Box<Liste>),
| ++++ +
error[E0391]: cycle detected when computing when `Liste` needs drop
--> src/main.rs:1:1
|
1 | enum Liste {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `Liste` needs drop again
= note: cycle used when computing whether `Liste` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `kons-liste` (bin "kons-liste") due to 2 previous errors
Hata bu türün “sonsuz boyuta” sahip olduğunu söyler. Bunun sebebi, Listeyi
kendi türünden başka bir değeri doğrudan içinde taşıyan özyineli bir varyantla
tanımlamış olmamızdır. Sonuç olarak Rust, bir Liste değerini saklamak için ne
kadar yer gerektiğini hesaplayamaz. Şimdi bunun neden böyle olduğunu açalım.
Önce Rust’ın özyineli olmayan bir türün boyutunu nasıl hesapladığını görelim.
Özyineli Olmayan Türün Boyutunu Hesaplamak
- bölümde enum tanımlarını anlatırken Liste 6-2’de tanımladığımız
Messageenumunu hatırlayın:
enum Mesaj {
Cik,
Tasi { x: i32, y: i32 },
Yaz(String),
RenkDegistir(i32, i32, i32),
}
fn main() {}Rust, Message için ne kadar alan ayıracağını belirlemek adına her varyanta
bakar ve en fazla alan gerektiren varyantı bulur. Message::Quit hiç alana
ihtiyaç duymaz, Message::Move iki i32 saklayacak kadar alana ihtiyaç duyar,
vb. Aynı anda yalnızca tek bir varyant kullanılacağı için, Message değerinin
gerektirdiği en büyük alan, en büyük varyantın kapladığı alandır.
Bunu, Liste 15-2’deki Liste enumu gibi özyineli bir türde Rust ne yapmaya
çalıştığıyla karşılaştırın. Derleyici önce Dugum varyantına bakar; içinde bir
i32 ve bir Liste vardır. Demek ki Dugum, i32 boyutu artı Liste
boyutuna ihtiyaç duyar. Listenin boyutunu bulmak için yine varyantlara bakar
ve yine Dugume gelir. Bu süreç sonsuza kadar sürer; Şekil 15-1 bunu gösterir.

Şekil 15-1: Sonsuz Dugum varyantlarından oluşan sonsuz bir Liste
Boyutu Bilinen Özyineli Tür Elde Etmek
Rust özyineli tanımlanmış türler için ne kadar yer ayıracağını hesaplayamadığı için, derleyici şu yardımcı öneriyi içeren bir hata verir:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Dugum(i32, Box<Liste>),
| ++++ +
Buradaki indirection, değeri doğrudan saklamak yerine ona işaret eden bir işaretçi saklamak demektir.
Box<T> bir işaretçi olduğu için Rust onun ne kadar yer kapladığını her zaman
bilir: işaretçinin boyutu, işaret ettiği verinin miktarına göre değişmez.
Demek ki Dugum varyantına başka bir Listeyi doğrudan koymak yerine
Box<T> koyabiliriz. Box<T>, bir sonraki Liste değerini Dugumün içinde
değil öbekte tutar. Kavramsal olarak yine aynı listeye sahibiz; ama bu kez
öğeler birbirinin içine değil yanına yerleştirilmiş gibidir.
Liste 15-2’deki Liste tanımını ve Liste 15-3’teki kullanımı Liste 15-5’teki
koda çevirirsek, artık kod derlenir.
enum Liste {
Dugum(i32, Box<Liste>),
Bos,
}
use crate::Liste::{Bos, Dugum};
fn main() {
let liste = Dugum(1, Box::new(Dugum(2, Box::new(Dugum(3, Box::new(Bos))))));
}Box<T> kullanan Liste tanimiDugum varyantı şimdi bir i32 boyutu ve kutu işaretçisinin boyutunu ister.
Bos varyantıysa hiç değer taşımaz; dolayısıyla yığında Dugumden daha az yer
kaplar. Artık herhangi bir Listenin boyutunun, i32 boyutu artı bir kutu
işaretçisi boyutu kadar olacağını biliyoruz. Kutu kullanarak sonsuz özyineli
zinciri kırdık; böylece derleyici Listeyi saklamak için gereken boyutu
hesaplayabilir. Şekil 15-2 bunu gösteriyor.

Şekil 15-2: Sonsuz boyutlu olmayan bir Liste; çünkü Dugum bir Box tutuyor
Kutular yalnızca dolaylı erişim ve öbek tahsisi sağlar; ileride göreceğimiz diğer akıllı işaretçi türlerindeki gibi ek yetenekleri yoktur. Bu ek yeteneklerin getirdiği maliyetleri de taşımazlar; bu yüzden cons liste gibi, ihtiyacımız olan tek şey dolaylı erişim olduğunda çok kullanışlıdırlar. Kutular için başka kullanım alanlarını 18. bölümde yeniden göreceğiz.
Box<T> akıllı işaretçi sayılır; çünkü Deref trait’ini uygular. Bu sayede
Box<T> değerlerine referansmış gibi davranılabilir. Box<T> kapsam dışına
çıktığında, kutunun işaret ettiği öbek verisi de Drop trait’i sayesinde
temizlenir. Bu iki trait, bu bölümün geri kalanında göreceğimiz diğer akıllı
işaretçi türleri için daha da önemli olacak. Şimdi onlara bakalım.
Akıllı İşaretçilere Normal Referanslar Gibi Davranma
Akıllı İşaretçilere Normal Referanslar Gibi Davranmak
Deref trait’ini uygulamak, * başvuru çözme operatörünün (dereference
operator) davranışını özelleştirmenizi sağlar. Bu trait’i, akıllı işaretçi
normal referans gibi davranacak şekilde uygularsanız, referanslarla çalışan
kodu akıllı işaretçilerle de kullanabilirsiniz.
Önce başvuru çözme operatörünün normal referanslarla nasıl çalıştığına bakalım.
Ardından Box<T> gibi davranan özel bir tür tanımlamayı deneyeceğiz ve neden
başvuru çözmenin referanslardaki gibi çalışmadığını göreceğiz. Sonra Deref
trait’ini uygulamanın akıllı işaretçileri referanslara benzer biçimde
çalıştırmayı nasıl mümkün kıldığına bakacağız. En sonda da Rust’ın deref
zorlama (deref coercion) özelliğini ve bunun referanslarla akıllı işaretçileri
birlikte nasıl kullanmamızı kolaylaştırdığını göreceğiz.
Referansın Göstediği Değere Gitmek
Normal referans bir işaretçi türüdür. İşaretçiyi düşünmenin kolay yollarından
biri, başka yerde tutulan bir değere uzanan ok gibi görmektir. Liste 15-6’da
bir i32 değerine referans oluşturuyor ve başvuru çözme operatörüyle bu
referansın gösterdiği değere gidiyoruz.
fn main() {
let sayi = 5;
let referans = &sayi;
assert_eq!(5, sayi);
assert_eq!(5, *referans);
}i32 degerine giden referansi, basvuru cozme operatoruyle izlemeksayi değişkeni 5 değerini tutar. referansı sayiya referans olacak
şekilde ayarlarız. sayinın 5 olduğuna dair doğrulama yapabiliriz. Ama
referans içindeki değeri doğrulamak istersek, *referans yazarak referansın
işaret ettiği değere gitmemiz gerekir; böylece derleyici gerçek değerleri
karşılaştırabilir.
assert_eq!(5, referans); yazsaydık derleme hatası alırdık:
$ cargo run
Compiling deref-ornegi v0.1.0 (file:///projects/deref-ornegi)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, referans);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-ornegi` (bin "deref-ornegi") due to 1 previous error
Sayı ile sayıya referans farklı türler olduğu için doğrudan karşılaştırılamaz. Referansın işaret ettiği değere gitmek için başvuru çözme operatörünü kullanmalıyız.
Box<T>yi Referans Gibi Kullanmak
Liste 15-6’daki kodu, referans yerine Box<T> kullanacak biçimde
yeniden yazabiliriz. Liste 15-7’de kutu üzerinde kullanılan başvuru çözme
operatörü, Liste 15-6’daki referans üzerinde kullanılanla aynı şekilde çalışır.
fn main() {
let sayi = 5;
let kutu = Box::new(sayi);
assert_eq!(5, sayi);
assert_eq!(5, *kutu);
}Box<i32> uzerinde basvuru cozme operatorunu kullanmakFark şu: bu kez kutu, sayinın kopyalanmış değerini işaret eden bir kutudur.
Son doğrulamada *kutu ile kutunun gösterdiği değere, referansta yaptığımızın
aynı şekilde gidebiliyoruz. Şimdi bunun neden mümkün olduğunu görmek için kendi
kutu türümüzü tanımlayalım.
Kendi Akıllı İşaretçimizi Tanımlamak
Standart kütüphanenin sunduğu Box<T>ye benzer sarmalayıcı bir tür oluşturalım.
Amaç, akıllı işaretçilerin varsayılan olarak referanslardan nasıl farklı
davrandığını deneyimlemek. Ardından başvuru çözmeyi nasıl ekleyebileceğimizi
göreceğiz.
Not: Birazdan oluşturacağımız
BenimKutu<T>ile gerçekBox<T>arasında önemli bir fark var: bizim sürümümüz veriyi öbekte tutmayacak. Burada odakDerefolduğu için verinin nerede saklandığı değil, işaretçi gibi davranışı önemli.
Box<T> aslında tek öğeli bir demet struct’ıdır; Liste 15-8 de aynı mantıkla
BenimKutu<T> türünü tanımlar. Box<T>deki new fonksiyonuna benzeyen bir
yeni fonksiyonu da tanımlıyoruz.
struct BenimKutu<T>(T);
impl<T> BenimKutu<T> {
fn yeni(x: T) -> BenimKutu<T> {
BenimKutu(x)
}
}
fn main() {}BenimKutu<T> turunu tanimlamakBenimKutu adında bir struct tanımlayıp jenerik T parametresi ekliyoruz;
çünkü her türden değeri tutabilsin istiyoruz. BenimKutu::yeni, T türünden
bir parametre alır ve bu değeri saklayan BenimKutu döndürür.
Şimdi Liste 15-7’deki main fonksiyonunu Liste 15-8’e ekleyip Box<T>
yerine BenimKutu<T> kullanalım. Liste 15-9 derlenmez; çünkü Rust BenimKutu
üzerinde başvuru çözmenin nasıl yapılacağını bilmiyor.
struct BenimKutu<T>(T);
impl<T> BenimKutu<T> {
fn yeni(x: T) -> BenimKutu<T> {
BenimKutu(x)
}
}
fn main() {
let sayi = 5;
let kutu = BenimKutu::yeni(sayi);
assert_eq!(5, sayi);
assert_eq!(5, *kutu);
}BenimKutu<T>yi referans ve Box<T> gibi kullanmaya calismakHata şöyle olur:
$ cargo run
Compiling deref-ornegi v0.1.0 (file:///projects/deref-ornegi)
error[E0614]: type `BenimKutu<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *kutu);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-ornegi` (bin "deref-ornegi") due to 1 previous error
BenimKutu<T> üzerinde bu yeteneği tanımlamadığımız için başvuru çözülemez.
Bunu sağlamak için Deref trait’ini uygulamalıyız.
Deref Trait’ini Uygulamak
- bölümdeki [“Bir Tür Üzerinde Trait Uygulamak”][impl-trait]
başlığında gördüğümüz gibi, trait uygulamak için gerekli yöntemleri yazmamız
gerekir. Standart kütüphanedeki
Dereftrait’i,selfi ödünç alan ve içteki veriye referans döndürenderefadlı tek bir yöntem ister. Liste 15-10 bu uygulamayı gösterir.
use std::ops::Deref;
impl<T> Deref for BenimKutu<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct BenimKutu<T>(T);
impl<T> BenimKutu<T> {
fn yeni(x: T) -> BenimKutu<T> {
BenimKutu(x)
}
}
fn main() {
let sayi = 5;
let kutu = BenimKutu::yeni(sayi);
assert_eq!(5, sayi);
assert_eq!(5, *kutu);
}BenimKutu<T> uzerinde Deref uygulamaktype Target = T; sözdizimi, Deref trait’inin kullanacağı ilişkili türü
tanımlar. İlişkili türler jenerik parametre bildirmeye benzer ama biraz farklı
bir mekanizmadır; ayrıntısını 20. bölümde göreceğiz.
deref yönteminin gövdesine &self.0 yazıyoruz; böylece * ile erişmek
istediğimiz değere referans dönüyor. 5. bölümdeki demet struct’larında olduğu
gibi .0, ilk alanı seçer. Artık Liste 15-9’daki *kutu kullanan main
derlenir ve doğrulamalar geçer.
Deref olmadan derleyici yalnızca & referanslarını çözebilir. deref
yöntemi, Deref uygulayan herhangi bir türü alıp referansa çevirebilme
yeteneği kazandırır.
Liste 15-9’da *kutu yazdığımızda, arka planda Rust şu kodu çalıştırır:
*(kutu.deref())Rust, * operatörünü deref çağrısıyla ve ardından normal başvuru çözmeyle
değiştirir; böylece bunu her seferinde elle düşünmemiz gerekmez.
derefin doğrudan değeri değil de referans döndürmesinin sebebi sahiplik
sistemidir. Değeri doğrudan döndürseydi, değer selfin içinden taşınmış olurdu.
Biz çoğu durumda akıllı işaretçinin içindeki değerin sahipliğini almak istemeyiz.
Fonksiyon ve Metotlarda Deref Zorlaması Kullanmak
Deref zorlama, Deref trait’ini uygulayan bir türe ait referansı başka bir
türe ait referansa dönüştürür. Örneğin String, Deref uygulayıp &str
döndürdüğü için &String, &stre dönüştürülebilir. Bu özellik fonksiyon ve
metot çağrılarında, verdiğiniz argüman türü parametre türüyle tam eşleşmediğinde
otomatik çalışır.
Bu özellik, fonksiyon ve metot çağrısı yazarken & ve * ile açıkça referans
alma ve çözme ihtiyacını azaltır. Ayrıca hem referanslarla hem akıllı
işaretçilerle çalışabilen daha esnek kod yazmanızı sağlar.
Bunu görmek için, Liste 15-8’de tanımladığımız BenimKutu<T> ve Liste 15-10’da
eklediğimiz Deref uygulamasını kullanalım. Liste 15-11, parametresi &str
olan merhaba fonksiyonunu gösterir.
fn merhaba(isim: &str) {
println!("Merhaba, {isim}!");
}
fn main() {}&str olan merhaba fonksiyonumerhaba("Rust"); gibi bir çağrı zaten çalışır. Ama deref zorlama sayesinde
BenimKutu<String> referansı da geçebiliriz; Liste 15-12 bunu gösterir.
use std::ops::Deref;
impl<T> Deref for BenimKutu<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct BenimKutu<T>(T);
impl<T> BenimKutu<T> {
fn yeni(x: T) -> BenimKutu<T> {
BenimKutu(x)
}
}
fn merhaba(isim: &str) {
println!("Merhaba, {isim}!");
}
fn main() {
let kutu = BenimKutu::yeni(String::from("Rust"));
merhaba(&kutu);
}merhabayi BenimKutu<String> referansiyla cagirmakBurada merhabaya &kutu geçiriyoruz; bu bir BenimKutu<String> referansıdır.
BenimKutu<T> üzerinde Deref uyguladığımız için Rust bunu önce &Stringe
çevirir. Standart kütüphane de String için Deref uygulayıp &str
döndürdüğünden, ikinci kez deref çağrısı yapılarak &str elde edilir.
Sonuçta merhabanın beklediği türle eşleşmiş oluruz.
Rust’ta deref zorlama olmasaydı, Liste 15-12 yerine Liste 15-13’teki gibi açık kod yazmamız gerekirdi:
use std::ops::Deref;
impl<T> Deref for BenimKutu<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct BenimKutu<T>(T);
impl<T> BenimKutu<T> {
fn yeni(x: T) -> BenimKutu<T> {
BenimKutu(x)
}
}
fn merhaba(isim: &str) {
println!("Merhaba, {isim}!");
}
fn main() {
let kutu = BenimKutu::yeni(String::from("Rust"));
merhaba(&(*kutu)[..]);
}(*kutu)[..] ifadesi hem BenimKutu<String>yi Stringe çözer hem de tam
dizgiyi kapsayan bir dizgi dilimi üretir. Deref zorlama bu işi bizim yerimize
otomatik yaptığı için kod daha kısa ve okunur olur.
Rust üç durumda deref zorlama yapar:
T: Deref<Target=U>ise&T,&Uye çevrilir.T: DerefMut<Target=U>ise&mut T,&mut Uye çevrilir.T: Deref<Target=U>ise&mut T,&Uye de çevrilebilir.
Üçüncü durum, değiştirilebilir referansın değiştirilemez referans da olabilmesi nedeniyle mümkündür. Tersi doğru değildir: değiştirilemez referansla değiştirilebilir referans elde edilemez.
Drop Trait'i ile Temizlik Sırasında Kod Çalıştırma
Drop Trait’i ile Temizlik Sırasında Kod Çalıştırmak
Akıllı işaretçi deseni için önemli ikinci trait Droptur. Bir değer kapsam
dışına çıkmak üzereyken ne olacağını özelleştirmenizi sağlar. Drop
uygulamasını herhangi bir tür için yazabilir ve böylece dosya, ağ bağlantısı
gibi kaynakları bırakmak için çalışacak kodu belirleyebilirsiniz.
Dropu akıllı işaretçiler bağlamında ele alıyoruz; çünkü Drop çoğunlukla
akıllı işaretçi yazarken kullanılır. Örneğin Box<T> bırakıldığında, kutunun
işaret ettiği öbek alanı serbest bırakılır.
Bazı dillerde, bazı türlerin örnekleriyle işiniz bittiğinde belleği ya da kaynağı serbest bırakacak kodu programcının elle çağırması gerekir. Dosya tanıtıcıları, soketler ve kilitler buna örnektir. Programcı unutursa sistem zorlanabilir hatta çökebilir. Rust’ta ise bir değer kapsam dışına çıktığında hangi kodun çalışacağını belirtirsiniz; derleyici bu kodu uygun yerlere otomatik ekler.
Bir değer kapsam dışına çıktığında çalışacak kodu Drop trait’ini
uygulayarak belirlersiniz. Bu trait, selfi değiştirilebilir referans olarak
alan drop adlı bir yöntem ister. Rust’ın dropu ne zaman çağırdığını görmek
için şimdilik bu yönteme println! ekleyelim.
Liste 15-14, kapsam dışına çıkınca mesaj basan OzelAkilliIsaretci yapısını
gösterir.
struct OzelAkilliIsaretci {
veri: String,
}
impl Drop for OzelAkilliIsaretci {
fn drop(&mut self) {
println!(
"`{}` verisine sahip OzelAkilliIsaretci bırakılıyor!",
self.veri
);
}
}
fn main() {
let c = OzelAkilliIsaretci {
veri: String::from("benim şeylerim"),
};
let d = OzelAkilliIsaretci {
veri: String::from("diğer şeyler"),
};
println!("OzelAkilliIsaretciler oluşturuldu");
}Drop uygulamali OzelAkilliIsaretci yapisiDrop trait’i prelude içinde olduğu için ayrıca kapsamaya almamız gerekmez.
OzelAkilliIsaretci için Drop uyguluyor ve drop içinde bir mesaj
yazdırıyoruz. Gerçek hayatta bu gövdeye kaynak temizleme mantığı konurdu.
main içinde iki OzelAkilliIsaretci oluşturup ardından
OzelAkilliIsaretciler oluşturuldu yazdırıyoruz. main sonunda bu değerler
kapsam dışına çıkar ve Rust dropu otomatik çağırır. Yani dropu bizim
elle çağırmamıza gerek yoktur.
Programı çalıştırınca şunu görürüz:
$ cargo run
Compiling birak-ornegi v0.1.0 (file:///projects/birak-ornegi)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/birak-ornegi`
OzelAkilliIsaretciler oluşturuldu
`diğer şeyler` verisine sahip OzelAkilliIsaretci bırakılıyor!
`benim şeylerim` verisine sahip OzelAkilliIsaretci bırakılıyor!
Rust değerler kapsam dışına çıktığında dropu otomatik çağırır. Değişkenler
oluşturulma sırasının tersine bırakılır; bu yüzden d, cden önce bırakılır.
Bazen bir değeri kapsam sonunu beklemeden daha erken temizlemek isteyebilirsiniz.
Örneğin kilit yöneten akıllı işaretçilerde, kilidi erkenden bırakıp aynı kapsam
içindeki başka kodun kilidi almasına izin vermek isteyebilirsiniz. Rust,
Drop trait’inin drop yöntemini elle çağırmanıza izin vermez; bunun yerine
standart kütüphanedeki std::mem::drop fonksiyonunu kullanırsınız.
Liste 15-14’teki maini değiştirip drop yöntemini elle çağırmak istersek,
Liste 15-15’teki kod çalışmaz.
struct OzelAkilliIsaretci {
veri: String,
}
impl Drop for OzelAkilliIsaretci {
fn drop(&mut self) {
println!(
"`{}` verisine sahip OzelAkilliIsaretci bırakılıyor!",
self.veri
);
}
}
fn main() {
let c = OzelAkilliIsaretci {
veri: String::from("bir miktar veri"),
};
println!("OzelAkilliIsaretci oluşturuldu");
c.drop();
println!("OzelAkilliIsaretci, main bitmeden önce bırakıldı");
}Drop trait’indeki dropu elle cagirmaya calismakDerlersek şu hatayı alırız:
$ cargo run
Compiling birak-ornegi v0.1.0 (file:///projects/birak-ornegi)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `birak-ornegi` (bin "birak-ornegi") due to 1 previous error
Hata açıkça drop çağrısının yasak olduğunu söyler. Buradaki destructor,
örneği temizleyen fonksiyon için kullanılan genel terimdir. Yapıcı
(constructor) nasıl örnek oluşturuyorsa, destructor da örneği temizler.
Rust buna izin vermez; çünkü kapsam sonunda yine otomatik drop çağrılırdı.
Böylece aynı değer iki kez temizlenmeye çalışılırdı.
Bu yüzden bir değeri erkenden bırakmak istiyorsak, std::mem::drop
fonksiyonunu çağırırız. Değeri fonksiyona argüman olarak veririz; prelude içinde
olduğu için ayrıca use yazmamız gerekmez. Liste 15-16 bunu gösterir.
struct OzelAkilliIsaretci {
veri: String,
}
impl Drop for OzelAkilliIsaretci {
fn drop(&mut self) {
println!(
"`{}` verisine sahip OzelAkilliIsaretci bırakılıyor!",
self.veri
);
}
}
fn main() {
let c = OzelAkilliIsaretci {
veri: String::from("bir miktar veri"),
};
println!("OzelAkilliIsaretci oluşturuldu");
drop(c);
println!("OzelAkilliIsaretci, main bitmeden önce bırakıldı");
}std::mem::drop cagirmakBu kodun çıktısı şöyledir:
$ cargo run
Compiling birak-ornegi v0.1.0 (file:///projects/birak-ornegi)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/birak-ornegi`
OzelAkilliIsaretci oluşturuldu
`bir miktar veri` verisine sahip OzelAkilliIsaretci bırakılıyor!
OzelAkilliIsaretci, main bitmeden önce bırakıldı
OzelAkilliIsaretci oluşturuldu ile main bitmeden önce bırakıldı satırları
arasında, bırakma mesajının yazdırılması c değerinin o noktada temizlendiğini
gösterir.
Drop uygulamasıyla verdiğiniz kodu birçok yaratıcı şekilde kullanabilirsiniz;
örneğin kendi bellek ayırıcınızı yazabilirsiniz. Drop ve Rust’ın sahiplik
sistemi sayesinde temizlik kodunu hatırlamak zorunda kalmazsınız; Rust bunu
sizin için yapar.
Ayrıca hâlâ kullanılan bir değeri yanlışlıkla temizlemekten de korkmanız
gerekmez. Referansların geçerliliğini koruyan sahiplik sistemi, dropun yalnızca
değer artık kullanılmıyorken bir kez çağrılmasını da sağlar.
Rc<T>, Referans Sayılı Akıllı İşaretçi
Referans Sayımlı Akıllı İşaretçi Rc<T>
Çoğu durumda sahiplik açıktır: hangi değişkenin hangi değere sahip olduğunu bilirsiniz. Ama bazen tek bir değerin birden çok sahibi olabilir. Örneğin graf veri yapılarında birden fazla kenar aynı düğümü gösterebilir; bu durumda o düğüm kavramsal olarak tüm bu kenarlar tarafından sahiplenilir. Düğüm, ona işaret eden sahip kalmayana kadar temizlenmemelidir.
Birden çok sahipliği açıkça etkinleştirmek için Rust’taki Rc<T> türünü
kullanırız. Bu ad reference counting’in kısaltmasıdır. Rc<T>, bir değere
kaç referans olduğunu takip eder; referans sayısı sıfıra indiğinde, geçersiz
referans üretmeden veri temizlenebilir.
Rc<T>yi aile oturma odasındaki televizyon gibi düşünebilirsiniz: Odaya gelen
ilk kişi televizyonu açar. Başkaları da gelip izleyebilir. Son kişi çıkınca
televizyon kapatılır. İçeride biri hâlâ televizyon izlerken kapatılırsa kavga
çıkar.
Rc<T>yi, programın birden çok kısmının okuyacağı veriyi öbekte ayırmak
istediğimiz ama veriyi en son kimin kullanmayı bırakacağını derleme zamanında
bilmediğimiz durumlarda kullanırız. Bilseydik, verinin sahibini o yapar ve normal
sahiplik kurallarına uyardık.
Rc<T> yalnızca tek iş parçacıklı senaryolar içindir. 16. bölümde çok iş
parçacıklı programlarda referans sayımının nasıl yapılacağını göreceğiz.
Veri Paylaşmak
Liste 15-5’teki cons liste örneğine geri dönelim. Orada Box<T> kullanmıştık.
Bu kez üçüncü bir listeyi birlikte sahiplenen iki liste kuracağız.

Şekil 15-3: b ve c listeleri, a listesinin sahipliğini paylaşıyor
Önce 5 ve 10u içeren a listesini, sonra 3 ile başlayan b ve 4 ile
başlayan c listelerini kuracağız. Hem b hem c, ardından anın devamını
kullanacak.
Bunu Box<T>li Liste tanımımızla yapmak işe yaramaz; Liste 15-17 bunu
gösterir.
enum Liste {
Dugum(i32, Box<Liste>),
Bos,
}
use crate::Liste::{Bos, Dugum};
fn main() {
let a = Dugum(5, Box::new(Dugum(10, Box::new(Bos))));
let b = Dugum(3, Box::new(a));
let c = Dugum(4, Box::new(a));
}Box<T>li listeye izin verilmedigini gostermekDerleyince şu hatayı alırız:
$ cargo run
Compiling kons-liste v0.1.0 (file:///projects/kons-liste)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Dugum(5, Box::new(Dugum(10, Box::new(Bos))));
| - move occurs because `a` has type `Liste`, which does not implement the `Copy` trait
10 | let b = Dugum(3, Box::new(a));
| - value moved here
11 | let c = Dugum(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum Liste {
| ^^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Dugum(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `kons-liste` (bin "kons-liste") due to 1 previous error
Dugum varyantları tuttukları verinin sahibidir. byi oluşturduğumuz anda a
bye taşınır. Ardından cyi oluştururken ayı yeniden kullanamayız.
Dugumü referans tutacak şekilde değiştirsek bu kez ömür parametreleri
tanımlamamız gerekirdi. Bu da listedeki her öğenin tüm listenin ömrü kadar
yaşamasını gerektirirdi. Liste 15-17’deki örnek için geçerli olsa da her zaman
böyle değildir.
Bu yüzden Liste tanımında Box<T> yerine Rc<T> kullanacağız; Liste 15-18
bunu gösterir. Her Dugum artık bir değer ve Listeyi gösteren Rc<T> taşır.
byi oluştururken ayı sahiplenmek yerine anın tuttuğu Rc<Liste>yi
klonlarız; böylece referans sayısı artar ve veri paylaşılır. c için de aynısı
yapılır.
enum Liste {
Dugum(i32, Rc<Liste>),
Bos,
}
use crate::Liste::{Bos, Dugum};
use std::rc::Rc;
fn main() {
let a = Rc::new(Dugum(5, Rc::new(Dugum(10, Rc::new(Bos)))));
let b = Dugum(3, Rc::clone(&a));
let c = Dugum(4, Rc::clone(&a));
}Rc<T> kullanan Liste tanimiRc<T> prelude içinde olmadığı için önce kapsamaya almamız gerekir. main
içinde 5 ve 10u barındıran listeyi a adlı Rc<Liste>ye koyuyoruz.
Ardından b ve c oluşturulurken Rc::clone(&a) çağırıyoruz.
İstersek a.clone() da yazabilirdik; ama Rust geleneği burada Rc::clone
kullanmaktır. Çünkü Rc::clone, çoğu clone uygulaması gibi tüm veriyi derin
kopyalamaz; yalnızca referans sayısını artırır. Görsel olarak da bu iki klon
türünü birbirinden ayırmak performans analizi yaparken işimizi kolaylaştırır.
Klonlayarak Referans Sayısını Artırmak
Liste 15-18’deki çalışan örneği biraz değiştirip adaki Rc<Liste>nin referans
sayısının nasıl değiştiğini görelim.
Liste 15-19’da c listesini iç kapsam içine alıyoruz; böylece c kapsam dışına
çıkınca sayının nasıl düştüğünü görebiliriz.
enum Liste {
Dugum(i32, Rc<Liste>),
Bos,
}
use crate::Liste::{Bos, Dugum};
use std::rc::Rc;
// --snip--
fn main() {
let a = Rc::new(Dugum(5, Rc::new(Dugum(10, Rc::new(Bos)))));
println!("a oluşturulduktan sonraki sayı = {}", Rc::strong_count(&a));
let b = Dugum(3, Rc::clone(&a));
println!("b oluşturulduktan sonraki sayı = {}", Rc::strong_count(&a));
{
let c = Dugum(4, Rc::clone(&a));
println!("c oluşturulduktan sonraki sayı = {}", Rc::strong_count(&a));
}
println!("c kapsamdan çıkınca sayı = {}", Rc::strong_count(&a));
}Referans sayısı her değiştiğinde Rc::strong_count çağırıp sonucu yazdırıyoruz.
Bu fonksiyona yalnızca count değil strong_count denmesinin nedeni, Rc<T>nin
weak_count adlı başka bir sayaç daha tutmasıdır; onu “Weak<T> Kullanarak
Referans Döngülerini Önlemek” bölümünde
göreceğiz.
Çıktı şöyledir:
$ cargo run
Compiling kons-liste v0.1.0 (file:///projects/kons-liste)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/kons-liste`
a oluşturulduktan sonraki sayı = 1
b oluşturulduktan sonraki sayı = 2
c oluşturulduktan sonraki sayı = 3
c kapsamdan çıkınca sayı = 2
anın başlangıçta referans sayısı 1dir. Her clone çağrısı sayıyı bir
artırır. c kapsam dışına çıktığında sayı bir azalır. Azaltmak için ayrıca
fonksiyon çağırmamız gerekmez; Rc<T> kapsam dışına çıktığında Drop
uygulaması sayacı otomatik düşürür.
Bu örnekte görmediğimiz şey, main sonunda b ve sonra a kapsam dışına
çıkınca sayının 0 olması ve Rc<Liste>nin tamamen temizlenmesidir. Rc<T>
tek bir değerin birden çok sahibi olmasını sağlar; sayaç da herhangi bir sahip
yaşadığı sürece değerin geçerli kalmasını güvence altına alır.
Rc<T>, değiştirilemez referanslar üzerinden veriyi birden çok yerde yalnızca
okuma amaçlı paylaşmanızı sağlar. Değiştirilebilir erişim de verseydi, 4.
bölümde gördüğümüz ödünç alma kurallarını ihlal etmek kolaylaşırdı. Yine de
veriyi değiştirebilmek çok faydalı. Sonraki bölümde, bu kısıtı esnetmek için
RefCell<T> ile içsel değiştirilebilirlik desenini göreceğiz.
RefCell<T> ve İçsel Değiştirilebilirlik Deseni
RefCell<T> ve İçsel Değiştirilebilirlik Deseni
İçsel değiştirilebilirlik (interior mutability), elde yalnızca değiştirilemez
referanslar olsa bile veriyi değiştirmeye izin veren bir Rust tasarım desenidir.
Normalde ödünç alma kuralları buna izin vermez. Bu desen, değişiklik ve ödünç
alma kurallarını yöneten normal Rust davranışını esnetmek için veri yapısının
içinde unsafe kod kullanır. Unsafe, kuralları derleyiciye değil bizim
manuel denetlediğimizi söyler; ayrıntısını 20. bölümde göreceğiz.
Bu deseni kullanan türleri ancak ödünç alma kurallarının çalışma zamanında da
izleneceğinden eminseniz kullanmalısınız. İçteki unsafe kod güvenli bir API
arkasına saklanır; dışarıdan bakınca tür yine değiştirilemez görünür.
Bu fikri, içsel değiştirilebilirliği kullanan RefCell<T> türü üzerinden
inceleyelim.
Ödünç Alma Kurallarını Çalışma Zamanında Uygulamak
Rc<T>den farklı olarak RefCell<T>, tuttuğu veri üzerinde tek sahipliği
temsil eder. Peki onu Box<T>den ayıran nedir? 4. bölümdeki ödünç alma
kurallarını hatırlayın:
- Aynı anda ya tek bir değiştirilebilir referansınız olabilir ya da istediğiniz kadar değiştirilemez referansınız olabilir; ikisi bir arada olamaz.
- Referanslar her zaman geçerli olmalıdır.
Referanslar ve Box<T> ile bu kuralların değişmezleri derleme zamanında
uygulanır. RefCell<T> ileyse çalışma zamanında uygulanır. Referanslarla
kuralları bozarsanız derleyici hata verir. RefCell<T> ile bozarsanız program
panic! ile kapanır.
Derleme zamanında denetlemenin avantajı, hataların daha erken yakalanması ve çalışma zamanı maliyeti olmamasıdır. Bu yüzden Rust’ta varsayılan yaklaşım budur.
Çalışma zamanında denetlemenin avantajıysa, derleme zamanında fazla katı kalan denetimlerin reddedeceği bazı bellek-güvenli senaryoları mümkün kılmasıdır. Rust derleyicisi gibi durağan analiz araçları doğaları gereği temkinlidir. Bazı özellikleri yalnızca kodu analiz ederek belirlemek imkânsızdır; en bilinen örnek Duruş Problemi’dir.
Bu yüzden derleyici kurallara uyulduğundan emin değilse, doğru bir programı
bile reddedebilir. Bu rahatsız edicidir ama felaket değildir. Buna karşılık
yanlış programı kabul etseydi, Rust’ın verdiği güvencelere güvenemezdik.
RefCell<T>, kurallara uyduğunuzdan emin olduğunuz ama derleyicinin bunu
kanıtlayamadığı durumlarda işe yarar.
RefCell<T> de Rc<T> gibi yalnızca tek iş parçacıklı kullanım içindir.
Çok iş parçacıklı bağlamda kullanırsanız derleme hatası alırsınız. 16. bölümde,
aynı işlevselliğin çok iş parçacıklı sürümünü göreceğiz.
Box<T>, Rc<T> ve RefCell<T> arasında seçim yaparken akılda tutulacak kısa
özet şöyledir:
Rc<T>aynı verinin birden çok sahibi olmasına izin verir;Box<T>veRefCell<T>tek sahiplidir.Box<T>, derleme zamanında denetlenen değiştirilemez ya da değiştirilebilir ödünçler sunar;Rc<T>yalnızca derleme zamanında denetlenen değiştirilemez ödünçler sunar;RefCell<T>ise çalışma zamanında denetlenen her iki türü de sunar.RefCell<T>çalışma zamanında denetlenen değiştirilebilir ödünçlere izin verdiği için, kendisi değiştirilemez olsa bile içindeki değeri değiştirebilirsiniz.
Değiştirilemez bir değerin içindeki veriyi değiştirmek, işte bu içsel değiştirilebilirlik desenidir.
İçsel Değiştirilebilirlik Kullanmak
Ödünç alma kurallarının sonucu olarak, elinizde değiştirilemez bir değer varken onu değiştirilebilir olarak ödünç alamazsınız. Örneğin şu kod derlenmez:
fn main() {
let sayi = 5;
let degistirilebilir_referans = &mut sayi;
}Derlerseniz şu hatayı alırsınız:
$ cargo run
Compiling odunc-alma v0.1.0 (file:///projects/odunc-alma)
error[E0596]: cannot borrow `sayi` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let degistirilebilir_referans = &mut sayi;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut sayi = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `odunc-alma` (bin "odunc-alma") due to 1 previous error
Bununla birlikte, bazı durumlarda bir değerin kendi metotları içinde kendini
değiştirmesi ama dış dünyaya değiştirilemez görünmesi faydalıdır. RefCell<T>
bunu yapmanın yollarından biridir. Tam anlamıyla kurallardan kaçmaz; yalnızca
kontrolü derleme zamanından çalışma zamanına taşır. Kuralı ihlal ederseniz
derleme hatası değil panic! alırsınız.
Şimdi RefCell<T>yi gerçekten işimize yarayan bir örnek üzerinde görelim.
Sahte Nesnelerle Test Yazmak
Test sırasında programcı bazen bir türün yerine başka bir tür kullanır; amaç belirli davranışı gözlemek ve doğru uygulanıp uygulanmadığını denetlemektir. Bu geçici türe test double denir. Bunun özel bir biçimi olan mock object, test boyunca neler olduğunu kaydeder; böylece doğru eylemlerin gerçekleşip gerçekleşmediğini doğrulayabilirsiniz.
Rust’ta bazı dillerdeki anlamıyla nesne yoktur ve standart kütüphanede hazır mock altyapısı gelmez. Ama aynı işi görecek struct’ları rahatlıkla tanımlayabilirsiniz.
Şu senaryoyu test edelim: bir değerin üst sınıra ne kadar yaklaştığını izleyen ve mevcut değerin sınıra yaklaşmasına göre mesaj gönderen bir kütüphane yazacağız. Örneğin bir kullanıcının yapabileceği API çağrısı kotasını izlemek için kullanılabilir.
Bu kütüphane yalnızca sınıra yakınlığı ve hangi eşiklerde hangi mesajın
gönderileceğini bilir. Mesajların nasıl gönderileceğini ise kütüphaneyi kullanan
uygulama sağlayacaktır. Bunun için Iletici adlı bir trait tanımlıyoruz.
Liste 15-20 kütüphane kodunu gösterir.
pub trait Iletici {
fn gonder(&self, ileti: &str);
}
pub struct SinirIzleyici<'a, T: Iletici> {
iletici: &'a T,
deger: usize,
en_buyuk: usize,
}
impl<'a, T> SinirIzleyici<'a, T>
where
T: Iletici,
{
pub fn yeni(iletici: &'a T, en_buyuk: usize) -> SinirIzleyici<'a, T> {
SinirIzleyici {
iletici,
deger: 0,
en_buyuk,
}
}
pub fn deger_ata(&mut self, deger: usize) {
self.deger = deger;
let en_buyugun_yuzdesi = self.deger as f64 / self.en_buyuk as f64;
if en_buyugun_yuzdesi >= 1.0 {
self.iletici.gonder("Hata: Kotanizi astiniz!");
} else if en_buyugun_yuzdesi >= 0.9 {
self.iletici
.gonder("Acil uyari: Kotanizin %90'ini gectiniz!");
} else if en_buyugun_yuzdesi >= 0.75 {
self.iletici.gonder("Uyari: Kotanizin %75'ini gectiniz!");
}
}
}Buradaki önemli noktalardan biri, Iletici trait’inin selfi değiştirilemez
referans alan gonder metodunu tanımlamasıdır. Sahte nesnemiz, gerçek nesneyle
aynı şekilde kullanılabilmek için bu arayüzü uygulamalıdır. İkinci önemli nokta
ise SinirIzleyici üzerindeki deger_ata davranışını test etmek istememizdir.
deger parametresine verdiğimiz şeyi değiştirebiliriz ama deger_ata bize
doğrulama yapacağımız bir sonuç döndürmez. Biz de “belirli bir en_buyuk
değeriyle oluşturulmuş SinirIzleyici, farklı sayılar verildiğinde doğru
iletileri gönderiyor mu?” sorusunu sınamak isteriz.
Gerçekten e-posta ya da mesaj göndermek yerine, yalnızca gönderilmesi istenen
mesajları kaydeden bir sahte nesneye ihtiyacımız var. Sahte nesnenin örneğini
oluşturup SinirIzleyiciye verecek, sonra deger_ata çağıracak ve sonrasında
beklediğimiz mesajların kaydedilip kaydedilmediğine bakacağız. Liste 15-21 bu
yönde bir girişimi gösteriyor; ama ödünç alma denetleyicisi buna izin vermiyor.
pub trait Iletici {
fn gonder(&self, ileti: &str);
}
pub struct SinirIzleyici<'a, T: Iletici> {
iletici: &'a T,
deger: usize,
en_buyuk: usize,
}
impl<'a, T> SinirIzleyici<'a, T>
where
T: Iletici,
{
pub fn yeni(iletici: &'a T, en_buyuk: usize) -> SinirIzleyici<'a, T> {
SinirIzleyici {
iletici,
deger: 0,
en_buyuk,
}
}
pub fn deger_ata(&mut self, deger: usize) {
self.deger = deger;
let en_buyugun_yuzdesi = self.deger as f64 / self.en_buyuk as f64;
if en_buyugun_yuzdesi >= 1.0 {
self.iletici.gonder("Hata: Kotanizi astiniz!");
} else if en_buyugun_yuzdesi >= 0.9 {
self.iletici
.gonder("Acil uyari: Kotanizin %90'ini gectiniz!");
} else if en_buyugun_yuzdesi >= 0.75 {
self.iletici.gonder("Uyari: Kotanizin %75'ini gectiniz!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct SahteIletici {
gonderilen_iletiler: Vec<String>,
}
impl SahteIletici {
fn yeni() -> SahteIletici {
SahteIletici {
gonderilen_iletiler: vec![],
}
}
}
impl Iletici for SahteIletici {
fn gonder(&self, ileti: &str) {
self.gonderilen_iletiler.push(String::from(ileti));
}
}
#[test]
fn yuzde_75_ustu_uyari_iletisi_gonderir() {
let sahte_iletici = SahteIletici::yeni();
let mut sinir_izleyici = SinirIzleyici::yeni(&sahte_iletici, 100);
sinir_izleyici.deger_ata(80);
assert_eq!(sahte_iletici.gonderilen_iletiler.len(), 1);
}
}SahteIletici gerceklemesi denemesiBu test kodu, gönderilen iletileri tutmak için Vec<String> kullanan
SahteIletici yapısını tanımlar. Boş ileti listesiyle başlayan örnekler
oluşturmayı kolaylaştırmak için yeni ilişkili fonksiyonunu da ekleriz.
Ardından Iletici trait’ini uygularız.
Testte, SinirIzleyiciye deger olarak 80 verdiğimizde, yani 100lük
sınırın yüzde 75’ini geçtiğimizde ne olduğunu sınarız. Önce yeni bir
SahteIletici, sonra ona referans verilen bir SinirIzleyici oluştururuz.
deger_ata(80) çağırdıktan sonra, sahte ileticinin bir mesaj kaydetmiş olmasını
bekleriz.
Ama burada bir sorun var:
$ cargo test
Compiling sinir-izleyici v0.1.0 (file:///projects/sinir-izleyici)
error[E0596]: cannot borrow `self.gonderilen_iletiler` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.gonderilen_iletiler.push(String::from(ileti));
| ^^^^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn gonder(&mut self, ileti: &str);
3 | }
...
56 | impl Iletici for SahteIletici {
57 ~ fn gonder(&mut self, ileti: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `sinir-izleyici` (lib test) due to 1 previous error
gonder, selfi değiştirilemez referans aldığı için SahteIletici içindeki
ileti listesini değiştiremiyoruz. Hata mesajının önerdiği gibi trait’i ve
uygulamayı &mut self yapamayız; çünkü sırf test kolaylığı için Iletici
trait’ini değiştirmek istemiyoruz.
İşte burada içsel değiştirilebilirlik devreye girer. gonderilen_iletiler
alanını RefCell<T> içine alırız; böylece gonder metodu self
değiştirilemez referans alsa bile, içerideki veriyi değiştirebilir. Liste 15-22
bunu gösterir.
pub trait Iletici {
fn gonder(&self, ileti: &str);
}
pub struct SinirIzleyici<'a, T: Iletici> {
iletici: &'a T,
deger: usize,
en_buyuk: usize,
}
impl<'a, T> SinirIzleyici<'a, T>
where
T: Iletici,
{
pub fn yeni(iletici: &'a T, en_buyuk: usize) -> SinirIzleyici<'a, T> {
SinirIzleyici {
iletici,
deger: 0,
en_buyuk,
}
}
pub fn deger_ata(&mut self, deger: usize) {
self.deger = deger;
let en_buyugun_yuzdesi = self.deger as f64 / self.en_buyuk as f64;
if en_buyugun_yuzdesi >= 1.0 {
self.iletici.gonder("Hata: Kotanizi astiniz!");
} else if en_buyugun_yuzdesi >= 0.9 {
self.iletici
.gonder("Acil uyari: Kotanizin %90'ini gectiniz!");
} else if en_buyugun_yuzdesi >= 0.75 {
self.iletici.gonder("Uyari: Kotanizin %75'ini gectiniz!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct SahteIletici {
gonderilen_iletiler: RefCell<Vec<String>>,
}
impl SahteIletici {
fn yeni() -> SahteIletici {
SahteIletici {
gonderilen_iletiler: RefCell::new(vec![]),
}
}
}
impl Iletici for SahteIletici {
fn gonder(&self, ileti: &str) {
self.gonderilen_iletiler
.borrow_mut()
.push(String::from(ileti));
}
}
#[test]
fn yuzde_75_ustu_uyari_iletisi_gonderir() {
// --snip--
let sahte_iletici = SahteIletici::yeni();
let mut sinir_izleyici = SinirIzleyici::yeni(&sahte_iletici, 100);
sinir_izleyici.deger_ata(80);
assert_eq!(sahte_iletici.gonderilen_iletiler.borrow().len(), 1);
}
}RefCell<T> kullanmakgonderilen_iletiler alanı artık Vec<String> değil
RefCell<Vec<String>>dir. yeni içinde boş vektörün etrafına yeni bir
RefCell örneği sararız.
gonder uygulamasında ilk parametre hâlâ selfin değiştirilemez ödüncüdür;
trait tanımıyla uyumludur. self.gonderilen_iletiler üzerinde borrow_mut
çağırarak içteki vektöre değiştirilebilir erişim alır, ardından push
kullanarak iletiyi kaydederiz.
Doğrulamada da vektörün boyuna bakmak için borrow çağırıp değiştirilemez
referans alırız.
Ödünçleri Çalışma Zamanında İzlemek
Normal referanslarda & ve &mut kullanırız. RefCell<T> ileyse borrow ve
borrow_mut kullanırız. borrow, Ref<T>; borrow_mut ise RefMut<T>
döndürür. Her iki tür de Deref uyguladığı için normal referanslar gibi
davranabilir.
RefCell<T>, o anda etkin olan Ref<T> ve RefMut<T> akıllı işaretçilerinin
sayısını izler. borrow her çağrıldığında değiştirilemez ödünç sayısını
artırır. Ref<T> kapsam dışına çıkınca sayı bir azalır. Tıpkı derleme zamanı
kuralları gibi, RefCell<T> de aynı anda çok sayıda değiştirilemez ödünç ya da
yalnızca tek değiştirilebilir ödünç olmasına izin verir.
Kural ihlali yaparsak, referanslarda olduğu gibi derleme hatası değil çalışma
zamanında panic! alırız. Liste 15-23, Liste 15-22’deki gonder
uygulamasının bilerek bozulmuş sürümüdür: aynı kapsam içinde iki
değiştirilebilir ödünç oluşturmaya çalışıyoruz.
pub trait Iletici {
fn gonder(&self, ileti: &str);
}
pub struct SinirIzleyici<'a, T: Iletici> {
iletici: &'a T,
deger: usize,
en_buyuk: usize,
}
impl<'a, T> SinirIzleyici<'a, T>
where
T: Iletici,
{
pub fn yeni(iletici: &'a T, en_buyuk: usize) -> SinirIzleyici<'a, T> {
SinirIzleyici {
iletici,
deger: 0,
en_buyuk,
}
}
pub fn deger_ata(&mut self, deger: usize) {
self.deger = deger;
let en_buyugun_yuzdesi = self.deger as f64 / self.en_buyuk as f64;
if en_buyugun_yuzdesi >= 1.0 {
self.iletici.gonder("Hata: Kotanizi astiniz!");
} else if en_buyugun_yuzdesi >= 0.9 {
self.iletici
.gonder("Acil uyari: Kotanizin %90'ini gectiniz!");
} else if en_buyugun_yuzdesi >= 0.75 {
self.iletici.gonder("Uyari: Kotanizin %75'ini gectiniz!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct SahteIletici {
gonderilen_iletiler: RefCell<Vec<String>>,
}
impl SahteIletici {
fn yeni() -> SahteIletici {
SahteIletici {
gonderilen_iletiler: RefCell::new(vec![]),
}
}
}
impl Iletici for SahteIletici {
fn gonder(&self, ileti: &str) {
let mut ilk_odunc = self.gonderilen_iletiler.borrow_mut();
let mut ikinci_odunc = self.gonderilen_iletiler.borrow_mut();
ilk_odunc.push(String::from(ileti));
ikinci_odunc.push(String::from(ileti));
}
}
#[test]
fn yuzde_75_ustu_uyari_iletisi_gonderir() {
let sahte_iletici = SahteIletici::yeni();
let mut sinir_izleyici = SinirIzleyici::yeni(&sahte_iletici, 100);
sinir_izleyici.deger_ata(80);
assert_eq!(sahte_iletici.gonderilen_iletiler.borrow().len(), 1);
}
}RefCell<T>nin panic vermesini gormekÖnce borrow_mutten dönen RefMut<T> için ilk_odunc değişkenini, ardından
aynı kapsamda ikinci bir RefMut<T> için ikinci_oduncu oluşturuyoruz. Bu,
aynı kapsamda iki değiştirilebilir referans demektir ve yasaktır. Kod derlenir
ama test başarısız olur:
$ cargo test
Compiling sinir-izleyici v0.1.0 (file:///projects/sinir-izleyici)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/sinir_izleyici-e599811fa246dbde)
running 1 test
test tests::yuzde_75_ustu_uyari_iletisi_gonderir ... FAILED
failures:
---- tests::yuzde_75_ustu_uyari_iletisi_gonderir stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::yuzde_75_ustu_uyari_iletisi_gonderir
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Kodun already borrowed: BorrowMutError mesajıyla paniklediğine dikkat edin.
RefCell<T>, kuralları çalışma zamanında işte böyle uygular.
Bu yaklaşımın bedeli vardır: hataları geliştirme sürecinde daha geç fark
edebilirsiniz ve çalışma zamanında küçük de olsa ek maliyet oluşur. Buna
rağmen, yalnızca değiştirilemez değerlerin izin verildiği bağlamda kendini
değiştirebilen sahte nesneler yazmak gibi durumlarda RefCell<T> çok işe yarar.
Değiştirilebilir Verinin Birden Fazla Sahibi Olmasına İzin Vermek
RefCell<T> çok sık Rc<T> ile birlikte kullanılır. Rc<T>, verinin birden
çok sahibi olmasına izin verir ama yalnızca değiştirilemez erişim sunar. Eğer
Rc<T> içinde RefCell<T> taşırsanız, hem birden çok sahipliğe hem de
değiştirilebilirliğe sahip olursunuz.
Liste 15-18’de Rc<T> kullanarak bir listenin birden çok yerde
paylaşılabildiğini görmüştük. Ama Rc<T> yalnızca değiştirilemez değerleri
tuttuğu için, liste oluştuktan sonra içindeki değerleri değiştiremiyorduk.
Şimdi RefCell<T> ekleyerek bunu mümkün kılacağız. Liste 15-24 bunu gösterir.
#[derive(Debug)]
enum List {
Dugum(Rc<RefCell<i32>>, Rc<List>),
Bos,
}
use crate::List::{Bos, Dugum};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let deger = Rc::new(RefCell::new(5));
let a = Rc::new(Dugum(Rc::clone(°er), Rc::new(Bos)));
let b = Dugum(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Dugum(Rc::new(RefCell::new(4)), Rc::clone(&a));
*deger.borrow_mut() += 10;
println!("a sonrası = {a:?}");
println!("b sonrası = {b:?}");
println!("c sonrası = {c:?}");
}Liste olusturmak icin Rc<RefCell<i32>> kullanmakÖnce Rc<RefCell<i32>> türünden deger oluşturuyoruz ki sonra doğrudan
erişebilelim. Ardından a listesini, degeri taşıyan Dugum varyantıyla
kuruyoruz. Burada degeri klonlamamız gerekir; böylece içteki 5in sahipliği
hem degerde hem ada olur.
a listesini Rc<T> içine sarıyoruz ki b ve c oluşturulurken ikisi de
ayı işaret edebilsin.
Listeler kurulduktan sonra degere 10 eklemek istiyoruz. Bunun için
borrow_mut çağırıyoruz. Rust’ın otomatik başvuru çözmesi, Rc<T>yi içteki
RefCell<T>ye indirger. borrow_mut, RefMut<T> döndürür; biz de bunu
çözerek iç değeri değiştiririz.
a, b ve cyi yazdırdığımızda hepsinin artık 15 içerdiğini görürüz:
$ cargo run
Compiling kons-liste v0.1.0 (file:///projects/kons-liste)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/kons-liste`
a sonrasi = Dugum(RefCell { value: 15 }, Bos)
b sonrasi = Dugum(RefCell { value: 3 }, Dugum(RefCell { value: 15 }, Bos))
c sonrasi = Dugum(RefCell { value: 4 }, Dugum(RefCell { value: 15 }, Bos))
Bu teknik oldukça kullanışlıdır. Dışarıdan bakınca değiştirilemez bir Liste
gibi görünür; ama RefCell<T>nin sunduğu API ile gerektiğinde iç veriyi
değiştirebiliriz. Çalışma zamanındaki ödünç denetimi veri yarışlarını önler;
bazı veri yapılarında biraz performans kaybına karşılık bu esneklik gayet
değerlidir. Elbette RefCell<T> çok iş parçacıklı kodda çalışmaz; onun güvenli
karşılığı olan Mutex<T>yi 16. bölümde göreceğiz.
Referans Döngüleri Bellek Sızıntısına Neden Olabilir
Referans Döngüleri Bellek Sızıntısına Yol Açabilir
Rust’ın bellek güvenliği garantileri, yanlışlıkla hiç temizlenmeyecek bellek
oluşturmayı zorlaştırır; ama imkânsız yapmaz. Buna bellek sızıntısı denir.
Bellek sızıntılarını tamamen önlemek Rust’ın garantileri arasında değildir; yani
Rust’ta bellek sızıntısı bellek açısından güvenlidir. Rc<T> ve RefCell<T>
kullanarak bunu görebiliriz: öğelerin birbirine döngü oluşturacak şekilde
referans verdiği yapılar kurmak mümkündür. Böyle durumda döngüdeki her öğenin
referans sayısı sıfıra düşmez ve değerler asla bırakılmaz.
Referans Döngüsü Oluşturmak
Bunun nasıl olabileceğine, Liste 15-25’teki Liste tanımı ve kuyruk metodu
ile bakalım.
use crate::Liste::{Bos, Dugum};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum Liste {
Dugum(i32, RefCell<Rc<Liste>>),
Bos,
}
impl Liste {
fn kuyruk(&self) -> Option<&RefCell<Rc<Liste>>> {
match self {
Dugum(_, oge) => Some(oge),
Bos => None,
}
}
}
fn main() {}Dugum varyantinin gosterdigi seyi degistirebilmek icin RefCell<T> tutan kons liste tanimiBu, Liste 15-5’teki Liste tanımının başka bir varyasyonudur. Dugum
varyantının ikinci alanı artık RefCell<Rc<Liste>>; yani Liste 15-24’teki gibi
i32yi değil, Dugumün işaret ettiği Listeyi değiştirmek istiyoruz.
kuyruk metodu da ikinci öğeye erişmeyi kolaylaştırıyor.
Liste 15-26’da, bu tanımı kullanan maini ekliyoruz. Kod, a adlı bir liste ve
ona işaret eden b adlı başka bir liste oluşturuyor. Sonra ayı, Bos yerine
byi gösterecek biçimde değiştirerek referans döngüsü yaratıyor.
println! satırları süreç boyunca referans sayılarını gösteriyor.
use crate::Liste::{Bos, Dugum};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum Liste {
Dugum(i32, RefCell<Rc<Liste>>),
Bos,
}
impl Liste {
fn kuyruk(&self) -> Option<&RefCell<Rc<Liste>>> {
match self {
Dugum(_, oge) => Some(oge),
Bos => None,
}
}
}
fn main() {
let a = Rc::new(Dugum(5, RefCell::new(Rc::new(Bos))));
println!("a icin ilk rc sayisi = {}", Rc::strong_count(&a));
println!("a sonraki oge = {:?}", a.kuyruk());
let b = Rc::new(Dugum(10, RefCell::new(Rc::clone(&a))));
println!("b olustuktan sonra a rc sayisi = {}", Rc::strong_count(&a));
println!("b icin ilk rc sayisi = {}", Rc::strong_count(&b));
println!("b sonraki oge = {:?}", b.kuyruk());
if let Some(baglanti) = a.kuyruk() {
*baglanti.borrow_mut() = Rc::clone(&b);
}
println!("a degistikten sonra b rc sayisi = {}", Rc::strong_count(&b));
println!("a degistikten sonra a rc sayisi = {}", Rc::strong_count(&a));
// Bir dongu olustugunu gormek icin sonraki satirin yorumunu kaldirin;
// bu, yigin tasmasina yol acar.
// println!("a sonraki oge = {:?}", a.kuyruk());
}Liste degeriyle referans dongusu olusturmaka değişkeninde başlangıçta 5, Bos listesini tutan bir Rc<Liste> kuruyoruz.
Sonra 10 değerini taşıyan ve ayı işaret eden bir başka Rc<Liste>yi b
değişkenine koyuyoruz.
Ardından ayı Bos yerine byi gösterecek şekilde değiştiriyoruz. Bunun için
a.kuyruk() ile RefCell<Rc<Liste>>ye referans alıp baglantiya koyuyor,
sonra borrow_mut ile içteki Rc<Liste>yi bye çeviriyoruz.
Son println!i şimdilik yorumlu bırakarak kodu çalıştırırsak şu çıktıyı alırız:
$ cargo run
Compiling kons-liste v0.1.0 (file:///projects/kons-liste)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/kons-liste`
a icin ilk rc sayisi = 1
a sonraki oge = Some(RefCell { value: Bos })
b olustuktan sonra a rc sayisi = 2
b icin ilk rc sayisi = 1
b sonraki oge = Some(RefCell { value: Dugum(5, RefCell { value: Bos }) })
a degistikten sonra b rc sayisi = 2
a degistikten sonra a rc sayisi = 2
ayı bye bağladıktan sonra hem a hem b için referans sayısı 2 olur.
main sonunda Rust önce byi bırakır; ama sayısı 1e düştüğü için belleği
silinmez. Sonra ayı bırakır; onun sayısı da 1e düşer. Böylece iki liste de
öbekte sonsuza kadar kalır.

Şekil 15-4: Birbirini işaret eden a ve b listelerinin oluşturduğu referans döngüsü
Son println!in yorumunu kaldırırsanız Rust bu döngüyü yazdırmaya çalışır;
adan bye, bden aya giderek sonsuza kadar ilerler ve sonunda yığın taşar.
Gerçek programlarda bunun sonucu daha ciddi olabilir. Büyük miktarda bellek ayıran döngüler uzun süre tutulursa program gereğinden fazla bellek tüketir ve sistemi zorlayabilir.
Referans döngüsü oluşturmak kolay değildir ama imkânsız da değildir. İçsel değiştirilebilirlik ve referans sayımı kullanan iç içe türlerle çalışırken döngü kurmadığınızdan siz emin olmalısınız; Rust bunu otomatik yakalayamaz. Bu tür hatalar mantık hatasıdır; otomatik test, kod incelemesi ve iyi geliştirme alışkanlıklarıyla azaltılmalıdır.
Bir başka çözüm de veri yapısını, bazı referanslar sahipliği ifade ederken bazıları etmeyecek şekilde yeniden düzenlemektir. Böylece döngü içinde sahiplik ifade etmeyen referanslar kullanabilir ve gerçek bırakma kararını yalnızca sahiplik ilişkileriyle sınırlayabilirsiniz.
Weak<T> Kullanarak Referans Döngülerini Önlemek
Rc::clone çağrısının strong_countu artırdığını ve bir Rc<T> örneğinin
yalnızca strong_count sıfıra düştüğünde temizlendiğini gördük. Aynı değere
zayıf referans oluşturmak için Rc::downgrade kullanabilirsiniz. Bu, Weak<T>
adlı akıllı işaretçiyi üretir.
Güçlü referanslar (Rc<T>), sahipliği paylaşır. Zayıf referanslar
(Weak<T>) ise sahiplik ilişkisi ifade etmez; sayıları, değerin ne zaman
temizleneceğini etkilemez. Bu yüzden zayıf referans içeren döngüler, güçlü
referans sayısı sıfıra indiğinde kırılmış olur.
Rc::downgrade çağrısı strong_countu değil weak_countu artırır. weak_count
değerin kaç Weak<T> tarafından izlendiğini tutar. Fark şudur: Rc<T>nin
temizlenmesi için weak_countun sıfır olması gerekmez.
Weak<T>nin gösterdiği değer zaten düşürülmüş olabilir. Bu yüzden Weak<T>yi
gerçekten kullanmadan önce hâlâ geçerli olup olmadığını kontrol etmelisiniz.
Bunun için upgrade çağrılır; sonuç Option<Rc<T>> olur. Değer yaşıyorsa
Some, düşürülmüşse None alırsınız.
Bunu görmek için, yalnızca sonraki öğeyi bilen liste yerine çocuklarını ve ebeveynlerini bilen ağaç düğümleri kuracağız.
Ağaç Veri Yapısı Oluşturmak
İlk olarak çocuk düğümlerini bilen bir ağaç oluşturalım. Kendi i32 değerini ve
çocuk düğümlere referansları tutan Node yapısını tanımlıyoruz:
Dosya Adı: src/main.rs
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
deger: i32,
cocuklar: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let yaprak = Rc::new(Node {
deger: 3,
cocuklar: RefCell::new(vec![]),
});
let dal = Rc::new(Node {
deger: 5,
cocuklar: RefCell::new(vec![Rc::clone(&yaprak)]),
});
}Bir Node çocuklarının sahibi olsun, ama değişkenler de tek tek düğümlere
erişebilsin istiyoruz. Bunun için Vec<T> öğelerini Rc<Node> yapıyoruz.
Çocuk listesini değiştirmek isteyebileceğimiz için Vec<Rc<Node>>yi
RefCell<T> içine alıyoruz.
Sonra, çocuksuz ve değeri 3 olan yaprak düğümünü ve değeri 5 olan, çocuk
olarak yaprakı içeren dal düğümünü oluşturuyoruz.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
deger: i32,
cocuklar: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let yaprak = Rc::new(Node {
deger: 3,
cocuklar: RefCell::new(vec![]),
});
let dal = Rc::new(Node {
deger: 5,
cocuklar: RefCell::new(vec![Rc::clone(&yaprak)]),
});
}yaprak dugumu ve cocuk olarak yapraki iceren dal dugumu olusturmakyapraktaki Rc<Node>yi klonlayıp dal içine koyuyoruz; yani yaprak
artık iki sahipli. daldan yapraka dal.cocuklar yoluyla gidebiliriz; ama
yapraktan dala dönemeyiz. Çünkü yaprak, dalı tanımaz. Şimdi bunu
düzelteceğiz.
Çocuktan Ebeveyne Referans Eklemek
Çocuk düğümün ebeveynini bilebilmesi için Node tanımına ebeveyn alanı
eklemeliyiz. Ama bunun türü Rc<T> olamaz; aksi halde yaprak.ebeveyn,
dalı; dal.cocuklar da yaprakı güçlü biçimde tutar ve döngü oluşur.
İlişkiye başka açıdan bakınca çözüm netleşir: ebeveyn çocuğunun sahibi olmalı, ama çocuk ebeveyninin sahibi olmamalıdır. İşte bu zayıf referans senaryosudur.
Bu nedenle ebeveyn alanını Rc<T> değil, Weak<T> yapacağız; daha doğrusu
RefCell<Weak<Node>>. Liste 15-28 bunu gösterir.
Dosya Adı: src/main.rs
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
deger: i32,
ebeveyn: RefCell<Weak<Node>>,
cocuklar: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let yaprak = Rc::new(Node {
deger: 3,
ebeveyn: RefCell::new(Weak::new()),
cocuklar: RefCell::new(vec![]),
});
println!("yaprak ebeveyni = {:?}", yaprak.ebeveyn.borrow().upgrade());
let dal = Rc::new(Node {
deger: 5,
ebeveyn: RefCell::new(Weak::new()),
cocuklar: RefCell::new(vec![Rc::clone(&yaprak)]),
});
*yaprak.ebeveyn.borrow_mut() = Rc::downgrade(&dal);
println!("yaprak ebeveyni = {:?}", yaprak.ebeveyn.borrow().upgrade());
}Bir düğüm ebeveynini işaret edebilir ama ona sahip olmaz. Liste 15-28’de
yaprak, dalı ebeveyni olarak görecek şekilde maini güncelliyoruz.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
deger: i32,
ebeveyn: RefCell<Weak<Node>>,
cocuklar: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let yaprak = Rc::new(Node {
deger: 3,
ebeveyn: RefCell::new(Weak::new()),
cocuklar: RefCell::new(vec![]),
});
println!("yaprak ebeveyni = {:?}", yaprak.ebeveyn.borrow().upgrade());
let dal = Rc::new(Node {
deger: 5,
ebeveyn: RefCell::new(Weak::new()),
cocuklar: RefCell::new(vec![Rc::clone(&yaprak)]),
});
*yaprak.ebeveyn.borrow_mut() = Rc::downgrade(&dal);
println!("yaprak ebeveyni = {:?}", yaprak.ebeveyn.borrow().upgrade());
}yaprak dugumuyaprak oluşturulurken ebeveyn alanı için boş bir Weak<Node> koyuyoruz.
Bu yüzden ilk println! çağrısında upgrade sonucu None olur:
yaprak ebeveyni = None
dalı oluşturduktan sonra yaprak.ebeveyn alanına Rc::downgrade(&dal)
sonucunu yazarız. Böylece yaprak, ebeveynini bilebilir ama ona sahip olmaz.
İkinci yazdırmada Some(...) görürüz. Üstelik yazdırılan yapıda Weak
etiketleri göründüğü için döngü olmadığını da anlarız.
strong_count ve weak_count Değişimini Görselleştirmek
Şimdi strong_count ve weak_count değerlerinin nasıl değiştiğine bakalım.
Bunun için dal oluşturmayı iç kapsama alacağız; böylece kapsam bitince ne
olduğunu net görürüz. Liste 15-29 değişiklikleri gösterir.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
deger: i32,
ebeveyn: RefCell<Weak<Node>>,
cocuklar: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let yaprak = Rc::new(Node {
deger: 3,
ebeveyn: RefCell::new(Weak::new()),
cocuklar: RefCell::new(vec![]),
});
println!(
"yaprak guclu = {}, zayif = {}",
Rc::strong_count(&yaprak),
Rc::weak_count(&yaprak),
);
{
let dal = Rc::new(Node {
deger: 5,
ebeveyn: RefCell::new(Weak::new()),
cocuklar: RefCell::new(vec![Rc::clone(&yaprak)]),
});
*yaprak.ebeveyn.borrow_mut() = Rc::downgrade(&dal);
println!(
"dal guclu = {}, zayif = {}",
Rc::strong_count(&dal),
Rc::weak_count(&dal),
);
println!(
"yaprak guclu = {}, zayif = {}",
Rc::strong_count(&yaprak),
Rc::weak_count(&yaprak),
);
}
println!("yaprak ebeveyni = {:?}", yaprak.ebeveyn.borrow().upgrade());
println!(
"yaprak guclu = {}, zayif = {}",
Rc::strong_count(&yaprak),
Rc::weak_count(&yaprak),
);
}dali ic kapsamda olusturup guclu ve zayif referans sayilarini incelemekyaprak ilk oluşturulduğunda güçlü sayı 1, zayıf sayı 0dır. İç kapsamda
dal oluşturulup yaprakla ilişkilendirilince, dalın güçlü sayısı 1, zayıf
sayısı 1 olur; çünkü yaprak.ebeveyn, dala zayıf referans verir. Bu sırada
yaprakın güçlü sayısı 2 olur; çünkü dal.cocuklar, yaprakı da güçlü
şekilde tutar.
İç kapsam bittiğinde dal kapsam dışına çıkar; güçlü sayı 0 olduğu için
Node düşürülür. yaprak.ebeveyndeki zayıf referans buna engel olmaz; bu
yüzden bellek sızıntısı oluşmaz.
Kapsamdan sonra yaprakın ebeveynine yeniden erişmeyi denersek yine None
alırız. Program sonunda yaprak yalnız kaldığı için güçlü sayı 1, zayıf sayı
0dır.
Sayaçları yönetme ve değerleri bırakma mantığının tamamı Rc<T> ve Weak<T>
içinde, Drop uygulamalarıyla birlikte gelir. Çocuktan ebeveyne giden ilişkinin
Weak<T> olacağını Node tanımında belirleyerek, ebeveyn ve çocukların
birbirini gösterebildiği ama referans döngüsü üretmeyen bir yapı kurabilirsiniz.
Özet
Bu bölüm, akıllı işaretçileri kullanarak Rust’ın normal referanslarla varsayılan
olarak sunduğundan farklı güvenceler ve takaslar elde etmeyi anlattı. Box<T>
bilinen boyuta sahip olup öbekteki veriyi işaret eder. Rc<T>, aynı verinin
birden çok sahibi olabilmesi için referans sayısını tutar. RefCell<T> ise
değiştirilemez bir dış türü korurken içteki değeri değiştirmemize izin verir ve
ödünç alma kurallarını derleme zamanında değil çalışma zamanında uygular.
Ayrıca akıllı işaretçilerin sunduğu pek çok davranışı mümkün kılan Deref ve
Drop trait’lerini de gördük. Referans döngülerinin bellek sızıntısına nasıl
yol açabileceğini ve Weak<T> kullanarak nasıl önlenebileceğini de inceledik.
Bu bölüm ilginizi çektiyse ve kendi akıllı işaretçilerinizi yazmak istiyorsanız, “The Rustonomicon” size daha fazla ayrıntı sunar.
Sırada Rust’ta eşzamanlılık var. Orada da birkaç yeni akıllı işaretçi göreceğiz.
Korkusuz Eşzamanlılık
Rust’ın büyük hedeflerinden biri de eşzamanlı programlamayı güvenli ve verimli bir şekilde ele almaktır. Eşzamanlı programlama (concurrent programming), programın farklı bölümlerinin birbirinden bağımsız ilerlemesidir. Paralel programlama (parallel programming) ise farklı bölümlerin gerçekten aynı anda çalışmasıdır. Bilgisayarlar çok çekirdekli işlemcilerden daha fazla yararlandıkça bu iki yaklaşım da giderek daha önemli hale geliyor. Tarihsel olarak bu tür programlar yazmak zordu ve hataya açıktı. Rust bunu değiştirmeyi amaçlıyor.
İlk başta Rust ekibi, bellek güvenliğini sağlamakla eşzamanlılık sorunlarını önlemenin farklı yöntemlerle çözülecek iki ayrı problem olduğunu düşünüyordu. Zamanla sahiplik ve tür sisteminin, hem bellek güvenliğini hem de eşzamanlılıktaki sorunları yönetmek için çok güçlü araçlar sunduğunu fark ettiler. Sahiplik ve tür denetiminden yararlanıldığı için, eşzamanlılığa dair pek çok hata Rust’ta çalışma zamanı hatası değil derleme zamanı hatası olur. Böylece çalışma zamanında ortaya çıkan bir hatayı tekrar üretmeye uzun zaman harcamak yerine, yanlış kod doğrudan derlenmez ve size sorunu açıklayan bir hata verir. Sonuç olarak kodunuzu üretime çıktıktan sonra değil, daha yazarken düzeltebilirsiniz. Rust’ın bu yönüne korkusuz eşzamanlılık adı veriliyor. Korkusuz eşzamanlılık, ince ve sinsi hatalardan uzak; aynı zamanda yeniden düzenlemesi kolay kod yazmanızı sağlar.
Not: Sade tutmak için bu bölümde birçok sorundan söz ederken daha kesin bir ayrım yapıp “eşzamanlı ve/veya paralel” demek yerine yalnızca “eşzamanlı” diyeceğiz. Bu bölüm boyunca “eşzamanlı” gördüğünüz yerlerde zihninizde “eşzamanlı ve/veya paralel” diye okuyun. Bir sonraki bölümde bu ayrım daha önemli hale geldiğinde daha net konuşacağız.
Birçok dil, eşzamanlılık sorunlarına sunduğu çözümler konusunda oldukça katı davranır. Örneğin Erlang, mesaj iletimine dayalı eşzamanlılık için zarif olanaklar sunar; ama iş parçacıkları arasında durum paylaşmak için pek açık yollar vermez. Olası çözümlerin yalnızca bir kısmını desteklemek, üst seviye diller için makul bir yaklaşımdır; çünkü bu diller belli soyutlamaları kazanmak için biraz denetimden vazgeçmeyi zaten vaat eder. Buna karşılık daha alt seviyeli dillerden, eldeki duruma göre en iyi performansı verecek çözümü sunması ve donanım üstünde daha az soyutlama kurması beklenir. Bu yüzden Rust, sorununuzu ve gereksinimlerinizi hangi model daha iyi karşılıyorsa onu kullanabilmeniz için çeşitli araçlar sunar.
Bu bölümde şu konuları işleyeceğiz:
- Aynı anda birden fazla kod parçası çalıştırmak için iş parçacıkları nasıl oluşturulur?
- Kanalların iş parçacıkları arasında mesaj taşıdığı mesaj iletimli eşzamanlılık
- Birden çok iş parçacığının aynı veriye eriştiği paylaşımlı durum eşzamanlılığı
- Rust’ın eşzamanlılık güvencelerini, standart kütüphanedeki türlerin yanında
kullanıcı tanımlı türlere de taşıyan
SyncveSendtrait’leri
Kodu Aynı Anda Çalıştırmak İçin Thread'leri Kullanma
Kodu Aynı Anda Çalıştırmak İçin İş Parçacıkları Kullanmak
Günümüzde çoğu işletim sisteminde çalışan program kodu bir süreç (process) içinde yürütülür ve işletim sistemi aynı anda birden fazla süreci yönetir. Bir programın içinde de aynı anda ilerleyen bağımsız parçalar olabilir. Bu bağımsız parçaları çalıştıran yapılara iş parçacığı (thread) denir. Örneğin bir web sunucusu, aynı anda birden fazla isteğe yanıt verebilmek için birden çok iş parçacığı kullanabilir.
Programınızdaki hesabı birden fazla iş parçacığına bölüp görevleri aynı anda çalıştırmak performansı artırabilir; ama bunun karşılığında karmaşıklık da artar. İş parçacıkları aynı anda çalışabildiği için, farklı iş parçacıklarında yer alan kodunuzun hangi sırayla işleyeceğine dair doğal bir garanti yoktur. Bu da şu tür sorunlara yol açabilir:
- İş parçacıklarının veri ya da kaynaklara tutarsız bir sırayla eriştiği yarış durumları
- İki iş parçacığının birbirini beklediği ve ikisinin de devam edemediği kilitlenmeler
- Yalnızca bazı durumlarda ortaya çıkan, tekrar üretmesi ve güvenle düzeltmesi zor hatalar
Rust, iş parçacığı kullanmanın olumsuz yanlarını azaltmaya çalışır; ama çok iş parçacıklı programlama yine de dikkatli düşünmeyi ve tek iş parçacıklı programlardan farklı bir kod yapısını gerektirir.
Programlama dilleri iş parçacıklarını çeşitli şekillerde uygular; birçok
işletim sistemi de yeni iş parçacığı oluşturmak için çağrılabilen bir API
sunar. Rust standart kütüphanesi iş parçacıkları için 1:1 modelini kullanır:
Programdaki her dil düzeyi iş parçacığı için bir işletim sistemi iş parçacığı
vardır. Farklı ödünleşimler sunan başka iş parçacığı modellerini uygulayan
crate’ler de vardır. Bir sonraki bölümde göreceğimiz Rust’ın async sistemi de
eşzamanlılığa farklı bir yaklaşım sunar.
spawn ile Yeni Bir İş Parçacığı Oluşturmak
Yeni bir iş parçacığı oluşturmak için thread::spawn fonksiyonunu çağırır ve
ona, yeni iş parçacığında çalıştırmak istediğimiz kodu içeren bir kapanış
veririz. 16-1 numaralı liste, ana iş parçacığından biraz metin; yeni oluşturulan
iş parçacığından da başka metinler yazdırır.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for sira in 1..10 {
println!("oluşturulan iş parçacığından merhaba sayı {sira}!");
thread::sleep(Duration::from_millis(1));
}
});
for sira in 1..5 {
println!("ana iş parçacığından merhaba sayı {sira}!");
thread::sleep(Duration::from_millis(1));
}
}Rust programında ana iş parçacığı tamamlandığında, oluşturulmuş bütün iş parçacıkları işleri bitmiş olsun ya da olmasın kapatılır. Bu programın çıktısı her çalıştırmada biraz farklı olabilir; ama aşağıdakine benzer görünür:
ana iş parçacığından merhaba sayı 1!
oluşturulan iş parçacığından merhaba sayı 1!
ana iş parçacığından merhaba sayı 2!
oluşturulan iş parçacığından merhaba sayı 2!
ana iş parçacığından merhaba sayı 3!
oluşturulan iş parçacığından merhaba sayı 3!
ana iş parçacığından merhaba sayı 4!
oluşturulan iş parçacığından merhaba sayı 4!
oluşturulan iş parçacığından merhaba sayı 5!
thread::sleep çağrıları bir iş parçacığını kısa süreliğine durdurur ve başka
bir iş parçacığının çalışmasına fırsat verir. Çoğu zaman iş parçacıkları sıra
ile ilerler; ama bu garanti değildir. Her şey işletim sisteminizin iş
parçacıklarını nasıl zamanladığına bağlıdır. Bu çalıştırmada, kodda önce
oluşturulan iş parçacığındaki println! görünse de ilk yazdıran ana iş
parçacığı oldu. Ayrıca oluşturulan iş parçacığına i değeri 9 olana kadar
yazdırmasını söylemiş olsak da, ana iş parçacığı kapanmadan önce ancak 5
sayısına kadar gelebildi.
Bu kodu çalıştırıp yalnızca ana iş parçacığının çıktısını görürseniz ya da hiç örtüşme görmezseniz, aralıkları büyütmeyi deneyin. Böylece işletim sisteminin iki iş parçacığı arasında geçiş yapması için daha fazla fırsat oluşur.
Tüm İş Parçacıklarının Bitmesini Beklemek
16-1 numaralı listedeki kodun sorunu şu: Ana iş parçacığı çoğu zaman daha erken bittiği için oluşturulan iş parçacığı yarıda kesiliyor. Üstelik iş parçacıkları hangi sırayla çalışacak belli olmadığından, oluşturulan iş parçacığının hiç çalışacağı da garanti değil.
Bu sorunu çözmek için thread::spawn dönüş değerini bir değişkende
saklayabiliriz. thread::spawn fonksiyonu JoinHandle<T> döndürür.
JoinHandle<T>, sahip olunan bir değerdir; bunun üstünde join metodunu
çağırdığımızda ilgili iş parçacığının tamamlanmasını bekleriz. 16-2 numaralı
liste, 16-1’de oluşturduğumuz iş parçacığı için dönen JoinHandle<T> değerini
nasıl kullandığımızı ve main sonlanmadan önce bu iş parçacığının bitmesini
garanti etmek için join metodunu nasıl çağırdığımızı gösteriyor.
use std::thread;
use std::time::Duration;
fn main() {
let tutamac = thread::spawn(|| {
for sira in 1..10 {
println!("oluşturulan iş parçacığından merhaba sayı {sira}!");
thread::sleep(Duration::from_millis(1));
}
});
for sira in 1..5 {
println!("ana iş parçacığından merhaba sayı {sira}!");
thread::sleep(Duration::from_millis(1));
}
tutamac.join().unwrap();
}thread::spawn dönüşündeki JoinHandle<T> değerini saklamaktutamac üzerinde join çağırmak, şu anda çalışan iş parçacığını, tutamacın
temsil ettiği iş parçacığı bitene kadar bloklar (blocking). Bir iş parçacığının
bloklanması, onun iş yapmasının ya da sonlanmasının geçici olarak engellenmesi
demektir. join çağrısını ana iş parçacığındaki for döngüsünden sonraya
koyduğumuz için, 16-2 numaralı listenin çıktısı şuna benzer:
ana iş parçacığından merhaba sayı 1!
ana iş parçacığından merhaba sayı 2!
oluşturulan iş parçacığından merhaba sayı 1!
ana iş parçacığından merhaba sayı 3!
oluşturulan iş parçacığından merhaba sayı 2!
ana iş parçacığından merhaba sayı 4!
oluşturulan iş parçacığından merhaba sayı 3!
oluşturulan iş parçacığından merhaba sayı 4!
oluşturulan iş parçacığından merhaba sayı 5!
oluşturulan iş parçacığından merhaba sayı 6!
oluşturulan iş parçacığından merhaba sayı 7!
oluşturulan iş parçacığından merhaba sayı 8!
oluşturulan iş parçacığından merhaba sayı 9!
İki iş parçacığı dönüşümlü ilerlemeyi sürdürür; ama tutamac.join() çağrısı
nedeniyle ana iş parçacığı sona ermez ve oluşturulan iş parçacığının
tamamlanmasını bekler.
Şimdi de tutamac.join() çağrısını main içindeki for döngüsünden önceye
taşırsak ne olur, ona bakalım:
use std::thread;
use std::time::Duration;
fn main() {
let tutamac = thread::spawn(|| {
for sira in 1..10 {
println!("oluşturulan iş parçacığından merhaba sayı {sira}!");
thread::sleep(Duration::from_millis(1));
}
});
tutamac.join().unwrap();
for sira in 1..5 {
println!("ana iş parçacığından merhaba sayı {sira}!");
thread::sleep(Duration::from_millis(1));
}
}Bu durumda ana iş parçacığı önce oluşturulan iş parçacığının bitmesini bekler,
sonra kendi for döngüsünü çalıştırır. Yani çıktılar artık iç içe geçmez:
oluşturulan iş parçacığından merhaba sayı 1!
oluşturulan iş parçacığından merhaba sayı 2!
oluşturulan iş parçacığından merhaba sayı 3!
oluşturulan iş parçacığından merhaba sayı 4!
oluşturulan iş parçacığından merhaba sayı 5!
oluşturulan iş parçacığından merhaba sayı 6!
oluşturulan iş parçacığından merhaba sayı 7!
oluşturulan iş parçacığından merhaba sayı 8!
oluşturulan iş parçacığından merhaba sayı 9!
ana iş parçacığından merhaba sayı 1!
ana iş parçacığından merhaba sayı 2!
ana iş parçacığından merhaba sayı 3!
ana iş parçacığından merhaba sayı 4!
join çağrısının nereye yazıldığı gibi küçük ayrıntılar bile iş
parçacıklarının gerçekten aynı anda çalışıp çalışmayacağını etkileyebilir.
İş Parçacıklarıyla move Kapanışları Kullanmak
thread::spawn içine verdiğimiz kapanışlarla birlikte çoğu zaman move
anahtar sözcüğünü de kullanırız. Çünkü bu durumda kapanış, kullandığı
değerlerin sahipliğini çevresinden alır; böylece o değerlerin sahipliği bir iş
parçacığından diğerine aktarılmış olur. 13. bölümde “Referansları Yakalamak
ya da Sahipliği Taşımak” kısmında move anahtar
sözcüğünü kapanışlar bağlamında görmüştük. Şimdi move ile thread::spawn
arasındaki ilişkiye odaklanacağız.
16-1 numaralı listedeki kapanışın hiç parametre almadığına dikkat edin: Ana iş parçacığındaki hiçbir veriyi, oluşturulan iş parçacığındaki kodda kullanmıyoruz. Oluşturulan iş parçacığında ana iş parçacığından veri kullanabilmek için, kapanış ihtiyaç duyduğu değerleri yakalamalıdır. 16-3 numaralı liste, ana iş parçacığında bir vektör oluşturup onu oluşturulan iş parçacığında kullanma girişimini gösteriyor. Ama birazdan göreceğiniz gibi bu halde çalışmaz.
use std::thread;
fn main() {
let vektor = vec![1, 2, 3];
let tutamac = thread::spawn(|| {
println!("İşte bir vektör: {vektor:?}");
});
tutamac.join().unwrap();
}Kapanış vektor değişkenini kullandığı için onu yakalar ve kendi çevresinin
bir parçası haline getirir. thread::spawn bu kapanışı yeni bir iş
parçacığında çalıştırdığına göre, sanki bu yeni iş parçacığında vektor
değerine erişebilmemiz gerekiyormuş gibi görünür. Fakat bu örneği derlediğimizde
şu hatayı alırız:
$ cargo run
Compiling is-parcaciklari v0.1.0 (file:///projects/is-parcaciklari)
error[E0373]: closure may outlive the current function, but it borrows `vektor`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let tutamac = thread::spawn(|| {
| ^^ may outlive borrowed value `vektor`
7 | println!("İşte bir vektör: {vektor:?}");
| ------ `vektor` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let tutamac = thread::spawn(|| {
| __________________^
7 | | println!("İşte bir vektör: {vektor:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `vektor` (and any other referenced variables), use the `move` keyword
|
6 | let tutamac = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `is-parcaciklari` (bin "is-parcaciklari") due to 1 previous error
Rust, vektor değişkeninin nasıl yakalanacağını çıkarsar (infer). Burada
println! yalnızca vektor için bir referansa ihtiyaç duyduğu için kapanış
onu ödünç almaya çalışır. Sorun şu ki Rust, oluşturulan iş parçacığının ne
kadar yaşayacağını bilemez; bu yüzden vektor için alınan referansın her zaman
geçerli kalıp kalmayacağını da bilemez.
16-4 numaralı liste, vektor referansının geçersiz hale gelmesinin çok daha
olası olduğu bir senaryo gösterir.
use std::thread;
fn main() {
let vektor = vec![1, 2, 3];
let tutamac = thread::spawn(|| {
println!("İşte bir vektör: {vektor:?}");
});
drop(vektor); // eyvah!
tutamac.join().unwrap();
}vektor değerini düşürürken, kapanış içinde ona referans yakalamaya çalışan bir iş parçacığıRust bu kodu çalıştırmamıza izin verseydi, oluşturulan iş parçacığı hiç
çalışmadan hemen arka plana alınabilirdi. O iş parçacığının içinde vektore
ait bir referans var; ama ana iş parçacığı 15. bölümde gördüğümüz drop
fonksiyonunu kullanarak vektorü anında serbest bırakıyor. Sonra oluşturulan
iş parçacığı çalışmaya başladığında vektor artık geçerli olmuyor; dolayısıyla
ona ait referans da geçersiz hale geliyor. Kötü haber!
16-3 numaralı listedeki derleyici hatasını düzeltmek için hata mesajındaki öneriyi uygulayabiliriz:
help: to force the closure to take ownership of `vektor` (and any other referenced variables), use the `move` keyword
|
6 | let tutamac = thread::spawn(move || {
| ++++
Kapanışın önüne move eklediğimizde, Rust’ın ödünç alma çıkarımı yapmasına
izin vermek yerine kullanılan değerlerin sahipliğini kapanışın almasını
zorlamış oluruz. 16-3 numaralı listedeki örneğin 16-5’te gösterilen bu
değiştirilmiş hali, istediğimiz gibi derlenir ve çalışır.
use std::thread;
fn main() {
let vektor = vec![1, 2, 3];
let tutamac = thread::spawn(move || {
println!("İşte bir vektör: {vektor:?}");
});
tutamac.join().unwrap();
}move kullanmak16-4 numaralı listedeki kodu da aynı yolla düzeltmeyi düşünebiliriz. Orada ana
iş parçacığı drop çağrısıyla vektorü düşürüyordu. Fakat 16-5’teki gibi
move kullandığımız anda, vektorün sahipliği kapanışa aktarılır. Bu yüzden
ana iş parçacığında artık drop(vektor) çağırmak mümkün olmaz. Bunu
denediğimizde, bu kez aşağıdaki gibi farklı bir derleyici hatası alırız:
$ cargo run
Compiling is-parcaciklari v0.1.0 (file:///projects/is-parcaciklari)
error[E0382]: use of moved value: `vektor`
--> src/main.rs:10:10
|
4 | let vektor = vec![1, 2, 3];
| ------ move occurs because `vektor` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let tutamac = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("İşte bir vektör: {vektor:?}");
| ------ variable moved due to use in closure
...
10 | drop(vektor); // eyvah!
| ^^^^^^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = vektor.clone();
7 ~ let tutamac = thread::spawn(move || {
8 ~ println!("İşte bir vektör: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `is-parcaciklari` (bin "is-parcaciklari") due to 1 previous error
Rust’ın sahiplik kuralları bizi yine korumuş oldu.
Mesaj İletimiyle Thread'ler Arası Veri Transferi
Mesaj İletimiyle İş Parçacıkları Arasında Veri Taşımak
Güvenli eşzamanlılık sağlamak için giderek daha popüler hale gelen yaklaşımlardan biri mesaj iletimi (message passing) modelidir. Bu modelde iş parçacıkları ya da aktörler, veri içeren mesajları birbirlerine göndererek iletişim kurar. Go dilinin belgelerinde geçen şu ünlü söz bunu güzel özetler: “Belleği paylaşarak iletişim kurmayın; iletişim kurarak belleği paylaşın.”
Mesaj göndermeye dayalı eşzamanlılık için Rust standart kütüphanesi kanal uygulaması sunar. Kanal (channel), verinin bir iş parçacığından diğerine gönderilmesini sağlayan genel bir programlama kavramıdır.
Programlamadaki bir kanalı, yönü belli bir su yolu gibi düşünebilirsiniz. Örneğin bir dereye lastik ördek bırakırsanız, ördek akış yönünde ilerleyip su yolunun sonuna kadar gider.
Bir kanalın iki yarısı vardır: gönderici ve alıcı. Gönderici, ördeği suya bıraktığınız yukarı kısımdır; alıcı ise ördeğin aşağı akışta ulaştığı yerdir. Kodunuzun bir bölümü göndermek istediği veriyle gönderici tarafın metodlarını çağırır; başka bir bölümü de alıcı ucunda yeni mesaj gelip gelmediğini kontrol eder. Gönderici ya da alıcı taraflardan biri düşürüldüğünde kanalın kapandığı söylenir.
Burada, değer üreten ve bunları kanal üzerinden gönderen bir iş parçacığı ile bu değerleri alıp ekrana yazdıran başka bir iş parçacığı olan küçük bir program kuracağız. Özelliği göstermek için kanaldan basit değerler göndereceğiz. Bu yönteme alıştıktan sonra, örneğin bir sohbet sistemi ya da hesabın farklı parçalarını yapan birçok iş parçacığının sonuçları tek bir iş parçacığında topladığı sistemler gibi, iletişim kurması gereken her durumda kanalları kullanabilirsiniz.
Önce 16-6 numaralı listede bir kanal oluşturacağız; ama henüz onunla hiçbir şey yapmayacağız. Bunun şimdilik derlenmediğine dikkat edin; çünkü Rust, kanal üzerinden hangi tür değerler göndermek istediğimizi henüz bilemez.
use std::sync::mpsc;
fn main() {
let (gonderici, alici) = mpsc::channel();
}gonderici ve alici değişkenlerine atamakYeni bir kanal oluşturmak için mpsc::channel fonksiyonunu çağırırız. Buradaki
mpsc, multiple producer, single consumer ifadesinin kısaltmasıdır. Kısaca
Rust standart kütüphanesindeki kanal uygulaması, bir kanalın değer üreten
birden fazla gönderici ucu olmasına izin verir; ama o değerleri tüketen tek
bir alıcı ucu vardır. Bunu birçok küçük akarsuyun birleşip tek bir nehre
dönüşmesine benzetebilirsiniz: Farklı akışlardan gelen her şey sonunda aynı
nehirde toplanır. Şimdilik tek bir göndericiyle başlayacağız; örnek çalışır
hale gelince birden fazla gönderici ekleyeceğiz.
mpsc::channel fonksiyonu bir demet döndürür. İlk eleman gönderme ucu, yani
göndericidir; ikinci eleman ise alma ucu, yani alıcıdır. Birçok alanda
transmitter ve receiver için geleneksel olarak tx ve rx kısaltmaları
kullanılır; biz burada değişkenleri doğrudan gonderici ve alici olarak
adlandırdık. Bu demeti parçalayan bir desenle birlikte let ifadesi
kullanıyoruz. let ifadelerindeki desenler ile parçalayıcı atamayı 19. bölümde
inceleyeceğiz. Şimdilik bilinmesi gereken şu: mpsc::channel dönüşündeki
demetin parçalarını çıkarmak için bu kullanım çok elverişlidir.
Şimdi gönderici tarafı oluşturulan bir iş parçacığına taşıyalım ve oradan tek bir dizgi gönderelim. Böylece oluşturulan iş parçacığı ana iş parçacığıyla iletişim kurmuş olacak. Bu, nehrin yukarı kısmına lastik ördek bırakmaya ya da bir iş parçacığından diğerine sohbet mesajı göndermeye benzer.
use std::sync::mpsc;
use std::thread;
fn main() {
let (gonderici, alici) = mpsc::channel();
thread::spawn(move || {
let deger = String::from("merhaba");
gonderici.send(deger).unwrap();
});
}gonderici değerini oluşturulan iş parçacığına taşıyıp "merhaba" göndermekYine thread::spawn ile yeni bir iş parçacığı oluşturuyor, ardından move
yardımıyla gonderici değerini kapanışa taşıyoruz. Böylece göndericinin
sahipliği oluşturulan iş parçacığında oluyor. Kanal üzerinden mesaj
gönderebilmek için o iş parçacığının göndericiye sahip olması gerekir.
Gönderici tarafında, göndermek istediğimiz değeri alan bir send metodu vardır.
send metodu Result<T, E> döndürür. Yani alıcı daha önce düşürülmüşse ve
değeri gönderecek yer kalmamışsa, gönderme işlemi hata döndürür. Bu örnekte
hata olursa paniklemek için unwrap çağırıyoruz. Gerçek bir uygulamada ise
bunu uygun şekilde ele almak isteriz; doğru hata yönetimi stratejileri için 9.
bölüme dönebilirsiniz.
16-8 numaralı listede, ana iş parçacığında alıcıdan gelen değeri alacağız. Bu da nehrin sonundan lastik ördeği almak ya da gelen bir sohbet mesajını okumak gibidir.
use std::sync::mpsc;
use std::thread;
fn main() {
let (gonderici, alici) = mpsc::channel();
thread::spawn(move || {
let deger = String::from("merhaba");
gonderici.send(deger).unwrap();
});
let alinan = alici.recv().unwrap();
println!("Alındı: {alinan}");
}"merhaba" değerini alıp ekrana yazdırmakAlıcı tarafın kullanışlı iki metodu vardır: recv ve try_recv. Burada
receive kelimesinin kısaltması olan recv metodunu kullanıyoruz. Bu metod,
ana iş parçacığını bloklayarak kanal üzerinden bir değer gönderilmesini
bekler. Bir değer geldiğinde onu Result<T, E> içinde döndürür. Gönderici uç
kapandığında ise artık yeni değer gelmeyeceğini belirtmek için hata döndürür.
try_recv metodu ise bloklamaz; hemen Result<T, E> döndürür. O anda mesaj
varsa Ok, yoksa Err gelir. Bu, mesaj beklerken aynı iş parçacığının başka
işleri de varsa kullanışlıdır: Arada bir try_recv çağırabilir, mesaj geldiyse
onu işleyebilir, gelmediyse kısa süre başka işler yapıp sonra yeniden
kontrol edebilirsiniz.
Bu örnekte sadelik için recv kullandık; çünkü ana iş parçacığının yapacak
başka bir işi yok, yalnızca mesaj gelmesini bekliyor.
16-8 numaralı listedeki kodu çalıştırdığımızda, ana iş parçacığından şu değerin yazdırıldığını görürüz:
Alındı: merhaba
Tam istediğimiz gibi!
Kanallar Üzerinden Sahiplik Aktarmak
Mesaj gönderirken sahiplik kuralları çok kritik bir rol oynar; çünkü güvenli
eşzamanlı kod yazmanızı sağlar. Rust programlarınız boyunca sahipliği düşünmek,
eşzamanlı programlamadaki hataları önlemenin büyük bir parçasıdır. Kanallar ile
sahipliğin birlikte nasıl çalıştığını görmek için küçük bir deney yapalım:
Oluşturulan iş parçacığında deger adlı bir değeri kanaldan gönderdikten
sonra yeniden kullanmaya çalışacağız. 16-9 numaralı listedeki kodu
derlemeyi deneyin; neden buna izin verilmediğini göreceksiniz.
use std::sync::mpsc;
use std::thread;
fn main() {
let (gonderici, alici) = mpsc::channel();
thread::spawn(move || {
let deger = String::from("merhaba");
gonderici.send(deger).unwrap();
println!("değer şu: {deger}");
});
let alinan = alici.recv().unwrap();
println!("Alındı: {alinan}");
}deger kanal üzerinden gönderildikten sonra onu yeniden kullanmaya çalışmakBurada deger değişkenini gonderici.send ile kanala yolladıktan sonra
ekrana yazdırmaya çalışıyoruz. Buna izin verilmesi kötü olurdu; çünkü değer
başka bir iş parçacığına gönderildiği anda, o iş parçacığı bizim yeniden
kullanmaya çalışmamızdan önce değeri değiştirebilir ya da düşürebilirdi.
Böyle bir durumda tutarsız ya da hiç var olmayan veri yüzünden beklenmedik
sonuçlar ve hatalar ortaya çıkabilirdi. Neyse ki Rust, 16-9 numaralı listedeki
kodu derlemeye çalıştığımızda bize hata verir:
$ cargo run
Compiling mesaj-iletimi v0.1.0 (file:///projects/mesaj-iletimi)
error[E0382]: borrow of moved value: `deger`
--> src/main.rs:10:27
|
8 | let deger = String::from("merhaba");
| ----- move occurs because `deger` has type `String`, which does not implement the `Copy` trait
9 | gonderici.send(deger).unwrap();
| ----- value moved here
10 | println!("değer şu: {deger}");
| ^^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `mesaj-iletimi` (bin "mesaj-iletimi") due to 1 previous error
Eşzamanlılıkla ilgili hatamız bu sayede derleme zamanında yakalandı. send
fonksiyonu parametresinin sahipliğini alır ve değer taşındığında alıcı onun
yeni sahibi olur. Böylece gönderdikten sonra aynı değeri yanlışlıkla yeniden
kullanmamız engellenir; sahiplik sistemi her şeyin doğru olduğundan emin olur.
Birden Fazla Değer Göndermek
16-8 numaralı listedeki kod derlenip çalıştı; ama aslında iki ayrı iş parçacığının kanal üzerinden konuştuğunu çok net göstermiyordu.
16-10 numaralı listede, 16-8’deki örneği daha görünür hale getirmek için bazı değişiklikler yaptık: Oluşturulan iş parçacığı artık birden fazla mesaj gönderecek ve her mesaj arasında bir saniye bekleyecek.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (gonderici, alici) = mpsc::channel();
thread::spawn(move || {
let degerler = vec![
String::from("merhaba"),
String::from("olusturulan"),
String::from("is"),
String::from("parcacigindan"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for alinan in alici {
println!("Alındı: {alinan}");
}
}Bu kez oluşturulan iş parçacığında, ana iş parçacığına göndermek istediğimiz
dizgilerden oluşan bir vektör var. Vektör üzerinde dönüyor, her değeri tek tek
gönderiyor ve her gönderim arasında thread::sleep ile bir saniye bekliyoruz.
Ana iş parçacığında artık recv fonksiyonunu açıkça çağırmıyoruz. Bunun
yerine alici değerini bir yineleyici (iterator) gibi kullanıyoruz. Gelen her
değeri ekrana yazdırıyoruz. Kanal kapandığında yineleme de sona eriyor.
16-10 numaralı listedeki kodu çalıştırdığınızda, her satır arasında yaklaşık bir saniye olacak şekilde aşağıdakine benzer bir çıktı görmeniz gerekir:
Alındı: merhaba
Alındı: olusturulan
Alındı: is
Alındı: parcacigindan
Ana iş parçacığındaki for döngüsünde ayrıca bir bekleme ya da gecikme kodu
olmadığı için, ana iş parçacığının oluşturulan iş parçacığından değer gelmesini
beklediğini buradan anlayabiliyoruz.
Birden Fazla Gönderici Oluşturmak
Daha önce mpsc kısaltmasının multiple producer, single consumer anlamına
geldiğini söylemiştik. Şimdi bunu gerçekten kullanalım ve 16-10 numaralı
listedeki kodu genişleterek, aynı alıcıya değer gönderen birden çok iş
parçacığı oluşturalım. Bunu yapmak için göndericiyi klonlayacağız; 16-11
numaralı liste tam olarak bunu gösteriyor.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (gonderici, alici) = mpsc::channel();
let gonderici1 = gonderici.clone();
thread::spawn(move || {
let degerler = vec![
String::from("merhaba"),
String::from("olusturulan"),
String::from("is"),
String::from("parcacigindan"),
];
for deger in degerler {
gonderici1.send(deger).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let degerler = vec![
String::from("daha"),
String::from("fazla"),
String::from("mesaj"),
String::from("sana"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for alinan in alici {
println!("Alındı: {alinan}");
}
// --snip--
}Bu kez ilk iş parçacığını oluşturmadan önce göndericinin clone metodunu
çağırıyoruz. Böylece ilk oluşturulan iş parçacığına verebileceğimiz yeni bir
gönderici elde ediyoruz. Orijinal göndericiyi ise ikinci oluşturulan iş
parçacığına veriyoruz. Böylece elimizde, tek bir alıcıya farklı mesajlar
yollayan iki ayrı iş parçacığı oluyor.
Bu kodu çalıştırdığınızda çıktı aşağıdakine benzer görünür:
Alındı: merhaba
Alındı: daha
Alındı: olusturulan
Alındı: fazla
Alındı: mesaj
Alındı: is
Alındı: sana
Alındı: parcacigindan
Sisteminizin zamanlamasına göre değerleri farklı bir sırada da görebilirsiniz.
İşte eşzamanlılığı hem ilginç hem de zor yapan şeylerden biri bu. thread::sleep
çağrılarındaki sürelerle oynarsanız her çalıştırmada biraz daha farklı ve
öngörülmesi daha zor çıktılar elde edersiniz.
Kanalların nasıl çalıştığını gördüğümüze göre, şimdi eşzamanlılığın başka bir yoluna bakalım.
Paylaşımlı Durum (Shared-State) Eşzamanlılığı
Paylaşımlı Durum Eşzamanlılığı
Mesaj iletimi, eşzamanlılığı yönetmenin iyi yollarından biridir; ama tek yol bu değildir. Başka bir yöntem de birden fazla iş parçacığının aynı paylaşılan veriye erişmesidir. Go belgelerindeki şu sözün bu bölümünü yeniden düşünün: “Belleği paylaşarak iletişim kurmayın.”
Peki belleği paylaşarak iletişim kurmak nasıl bir şeye benzerdi? Ayrıca mesaj iletimini savunanlar neden bellek paylaşımından özellikle kaçınmayı öneriyor?
Bir bakıma, herhangi bir programlama dilindeki kanallar tek sahipliğe benzer; çünkü bir değeri kanaldan gönderdiğinizde artık onu kullanmamanız gerekir. Paylaşımlı bellekle eşzamanlılık ise çoklu sahipliğe benzer: Birden çok iş parçacığı aynı anda aynı bellek konumuna erişebilir. 15. bölümde akıllı işaretçilerin çoklu sahipliği nasıl mümkün kıldığını görmüştünüz. Çoklu sahiplik, farklı sahiplerin yönetilmesini gerektirdiği için doğal olarak karmaşıklık da getirir. Rust’ın tür sistemi ve sahiplik kuralları bu yönetimi doğru yapma konusunda çok yardımcı olur. Bir örnek olarak, paylaşımlı bellek eşzamanlılığında sık kullanılan temel yapılardan biri olan mutex’e bakalım.
Mutex<T> ile Erişimi Denetlemek
Mutex, mutual exclusion ifadesinin kısaltmasıdır; yani bir mutex, belli bir anda yalnızca tek bir iş parçacığının bazı verilere erişmesine izin verir. Mutex içindeki veriye erişmek için, iş parçacığı önce erişim istediğini bildirmeli ve mutex’in kilidini (lock) almalıdır. Kilit, mutex’in bir parçası olan ve o anda veriye kimin özel erişimi olduğunu takip eden veri yapısıdır. Bu yüzden mutex’in tuttuğu veriyi kilitleme sistemiyle koruduğu söylenir.
Mutex’lerin kullanımı zor olmakla ünlüdür; çünkü iki kuralı sürekli akılda tutmanız gerekir:
- Veriyi kullanmadan önce kilidi almaya çalışmalısınız.
- Mutex’in koruduğu veriyle işiniz bittiğinde, diğer iş parçacıkları da kilidi alabilsin diye kilidi bırakmalısınız.
Bunu gündelik bir benzetmeyle düşünelim: Tek mikrofonu olan bir panel oturumunu hayal edin. Konuşmacılardan biri konuşmadan önce mikrofonu istediğini belirtmelidir. Mikrofonu alınca istediği kadar konuşur; sonra da sıradaki kişiye verir. Bir konuşmacı işini bitirince mikrofonu devretmeyi unutursa, başka kimse konuşamaz. Paylaşılan mikrofonun yönetimi bozulursa panel planlandığı gibi ilerlemez.
Mutex yönetimini doğru yapmak gerçekten zordur; işte bu yüzden birçok kişi kanalları daha heyecan verici bulur. Ama Rust’ın tür sistemi ve sahiplik kuralları sayesinde, kilitleme ile kilidi bırakma işlerini yanlış yapmanız çok daha zordur.
Mutex<T> API’si
Mutex’in nasıl kullanıldığını görmek için önce tek iş parçacıklı çok basit bir örnekle başlayalım; 16-12 numaralı liste bunu gösteriyor.
use std::sync::Mutex;
fn main() {
let kilit = Mutex::new(5);
{
let mut sayi = kilit.lock().unwrap();
*sayi = 6;
}
println!("kilit = {kilit:?}");
}Mutex<T> API’sini tek iş parçacıklı bağlamda incelemekBirçok türde olduğu gibi Mutex<T> değerini de new ilişkili fonksiyonuyla
oluştururuz. İçindeki veriye erişmek için lock metoduyla kilidi alırız. Bu
çağrı, kilidi alma sırası bize gelene kadar mevcut iş parçacığını bloklar.
Kilidi elinde tutan başka bir iş parçacığı paniklerse lock çağrısı hata
verebilir. Böyle bir durumda artık hiç kimse kilidi alamayacağı için, burada
unwrap kullanıp bu iş parçacığının da paniklemesini seçtik.
Kilidi aldıktan sonra, burada sayi adını verdiğimiz dönüş değerini içerideki
veriye ait değiştirilebilir referans gibi kullanabiliriz. Tür sistemi, kilit
değerinin içindeki veriyi kullanmadan önce gerçekten kilit aldığımızdan emin
olur. kilit değişkeninin türü i32 değil Mutex<i32> olduğu için, içerideki
i32 değeri kullanabilmek adına zorunlu olarak lock çağırırız. Bunu
unutamayız; tür sistemi başka türlü izin vermez.
lock çağrısı, bizim unwrap ile ele aldığımız LockResult içine sarılmış
bir MutexGuard döndürür. MutexGuard, Deref uygular; böylece içerideki
veriyi işaret eder. Ayrıca Drop uygulaması sayesinde bir MutexGuard kapsam
dışına çıktığında kilit otomatik olarak bırakılır. Bu da içteki kapsamın sonunda
olur. Sonuç olarak kilidi bırakmayı unutup mutex’i başka iş parçacıklarının
kullanmasına engel olma riski yaşamayız; kilit bırakma işi kendiliğinden olur.
Kilidi bıraktıktan sonra mutex değerini ekrana yazdırabilir ve içerideki i32
değerini 6 yaptığımızı görebiliriz.
Mutex<T> İçin Paylaşımlı Erişim
Şimdi Mutex<T> kullanarak bir değeri birden fazla iş parçacığı arasında
paylaştırmayı deneyelim. 10 iş parçacığı oluşturup her birinin sayacı 1
artırmasını isteyeceğiz; böylece sayaç 0’dan 10’a çıkacak. 16-13 numaralı
listedeki örnek derleyici hatası verecek ve bu hata üzerinden Mutex<T> ile
çalışırken Rust’ın bize nasıl yardım ettiğini daha iyi anlayacağız.
use std::sync::Mutex;
use std::thread;
fn main() {
let sayac = Mutex::new(0);
let mut tutamaclar = vec![];
for _ in 0..10 {
let tutamac = thread::spawn(move || {
let mut sayi = sayac.lock().unwrap();
*sayi += 1;
});
tutamaclar.push(tutamac);
}
for tutamac in tutamaclar {
tutamac.join().unwrap();
}
println!("Sonuç: {}", *sayac.lock().unwrap());
}Mutex<T> ile korunan sayacı artıran on iş parçacığı16-12 numaralı listedekine benzer şekilde, Mutex<T> içindeki bir i32
değerini tutmak için sayac değişkeni oluşturuyoruz. Ardından bir sayı aralığı
üzerinde dönerek 10 iş parçacığı başlatıyoruz. thread::spawn çağrısına,
sayacı iş parçacığına taşıyan, lock metoduyla Mutex<T> kilidini alan ve
sonra içerdeki değere 1 ekleyen aynı kapanışı veriyoruz. Bir iş parçacığı
kapanışı bitirdiğinde sayi kapsam dışına çıkar ve kilit bırakılır; böylece
başka bir iş parçacığı kilidi alabilir.
Ana iş parçacığında bütün tutamaçları bir vektörde topluyoruz. Sonra 16-2
numaralı listedeki gibi her tutamaç üzerinde join çağırarak tüm iş
parçacıklarının bitmesini bekliyoruz. En sonunda ana iş parçacığı kilidi alıp
programın sonucunu yazdırıyor.
Bu örneğin derlenmeyeceğini söylemiştik. Şimdi nedenine bakalım:
$ cargo run
Compiling paylasimli-durum v0.1.0 (file:///projects/paylasimli-durum)
error[E0382]: borrow of moved value: `sayac`
--> src/main.rs:21:29
|
5 | let sayac = Mutex::new(0);
| ----- move occurs because `sayac` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let tutamac = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Sonuç: {}", *sayac.lock().unwrap());
| ^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = sayac.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `paylasimli-durum` (bin "paylasimli-durum") due to 1 previous error
Hata mesajı sayac değerinin döngünün önceki yinelemesinde taşındığını
söylüyor. Yani Rust bize, kilitli sayac değerinin sahipliğini birden fazla iş
parçacığına taşıyamayacağımızı anlatıyor. Bunu, 15. bölümde gördüğümüz çoklu
sahiplik yaklaşımıyla düzeltmeye çalışalım.
Birden Fazla İş Parçacığıyla Çoklu Sahiplik
- bölümde bir değere birden fazla sahip vermek için
Rc<T>akıllı işaretçisini kullanmıştık. Aynı şeyi burada da yapıp ne olacağına bakalım. 16-14 numaralı listedeMutex<T>değeriniRc<T>içine sarıyor ve iş parçacığına taşımadan önceRc<T>değerini klonluyoruz.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let sayac = Rc::new(Mutex::new(0));
let mut tutamaclar = vec![];
for _ in 0..10 {
let sayac = Rc::clone(&sayac);
let tutamac = thread::spawn(move || {
let mut sayi = sayac.lock().unwrap();
*sayi += 1;
});
tutamaclar.push(tutamac);
}
for tutamac in tutamaclar {
tutamac.join().unwrap();
}
println!("Sonuç: {}", *sayac.lock().unwrap());
}Mutex<T> değerine sahip olabilmesi için Rc<T> kullanmaya çalışmakYine derliyoruz ve… bu kez farklı hatalar alıyoruz. Derleyici bize çok şey öğretiyor:
$ cargo run
Compiling paylasimli-durum v0.1.0 (file:///projects/paylasimli-durum)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `paylasimli-durum` (bin "paylasimli-durum") due to 1 previous error
Bu mesajın en önemli kısmı şudur:
`Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely.
Derleyici bunun nedenini de söylüyor:
the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`.
Bir sonraki bölümde Send trait’ini ayrıntılı konuşacağız. Şimdilik şunu
bilin: Send, iş parçacıklarıyla kullanılacak türlerin eşzamanlı bağlamlara
uygun olduğunu garanti eden trait’lerden biridir.
Ne yazık ki Rc<T> iş parçacıkları arasında paylaşmak için güvenli değildir.
Rc<T> referans sayısını yönettiğinde, her clone çağrısında sayıyı artırır,
her klon düşürüldüğünde de azaltır. Fakat bu sayacın güncellenmesi sırasında
başka bir iş parçacığının araya girmesini önleyecek bir eşzamanlılık ilkelini
kullanmaz. Bu da yanlış sayımlara, dolayısıyla çok sinsi hatalara, bellek
sızıntılarına ya da işimiz bitmeden bir değerin düşürülmesine yol açabilir.
Burada bize gereken şey, Rc<T>ye çok benzeyen ama referans sayısını iş
parçacığı güvenli biçimde güncelleyen bir türdür.
Arc<T> ile Atomik Referans Sayımı
Neyse ki Arc<T>, Rc<T> gibi davranan ama eşzamanlı ortamlarda güvenle
kullanılabilen bir türdür. Buradaki a, atomic sözcüğünden gelir; yani bu
tür atomik referans sayımlıdır (atomically reference-counted). Atomikler,
burada ayrıntısına girmeyeceğimiz ayrı bir eşzamanlılık ilkelidir. Daha fazla
bilgi için standart kütüphanedeki std::sync::atomic
belgelerine bakabilirsiniz. Şimdilik bilmeniz gereken, atomik türlerin ilkel
türler gibi çalıştığı ama iş parçacıkları arasında güvenle paylaşılabildiğidir.
Şu soru akla gelebilir: Madem öyle, neden bütün ilkel türler atomik değil ya da
standart kütüphane türleri varsayılan olarak neden Arc<T> kullanmıyor?
Cevap şu: İş parçacığı güvenliği bir performans bedeli getirir ve bu bedeli
yalnızca gerçekten gerektiğinde ödemek istersiniz. Tek bir iş parçacığında
çalışıyorsanız, atomik güvenceleri zorunlu kılmak zorunda kalmayan kod daha
hızlı çalışabilir.
Örneğimize geri dönelim: Arc<T> ile Rc<T> aynı API’yi sunar. Bu nedenle
programı düzeltmek için yalnızca use satırını, new çağrısını ve clone
çağrısını değiştirmemiz yeterlidir. 16-15 numaralı listedeki kod sonunda
derlenir ve çalışır.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let sayac = Arc::new(Mutex::new(0));
let mut tutamaclar = vec![];
for _ in 0..10 {
let sayac = Arc::clone(&sayac);
let tutamac = thread::spawn(move || {
let mut sayi = sayac.lock().unwrap();
*sayi += 1;
});
tutamaclar.push(tutamac);
}
for tutamac in tutamaclar {
tutamac.join().unwrap();
}
println!("Sonuç: {}", *sayac.lock().unwrap());
}Mutex<T> değerini Arc<T> ile sarmalamakBu kod aşağıdaki çıktıyı üretir:
Sonuç: 10
Başardık! 0’dan 10’a kadar saydık. Bu çok etkileyici görünmeyebilir; ama
Mutex<T> ve iş parçacığı güvenliği hakkında pek çok şey öğrenmiş olduk.
Aslında aynı yapı, yalnızca sayaç artırmak değil çok daha karmaşık hesaplar
için de kullanılabilir. Bu stratejiyle bir hesabı bağımsız parçalara bölebilir,
parçaları iş parçacıklarına dağıtabilir ve sonunda her parçanın sonucunu
Mutex<T> aracılığıyla ortak sonuca yansıtabilirsiniz.
Şunu da unutmayın: Basit sayısal işlemler yapıyorsanız, standart
kütüphanedeki std::sync::atomic modülü altında
Mutex<T>den daha sade türler bulunur. Bu türler ilkel verilere güvenli,
eşzamanlı ve atomik erişim sağlar. Biz burada Mutex<T>yi ilkel bir türle
kullanmayı özellikle seçtik; çünkü amacımız öncelikle Mutex<T>nin nasıl
çalıştığını göstermekti.
RefCell<T>/Rc<T> ile Mutex<T>/Arc<T> Karşılaştırması
sayac değişkeninin değiştirilemez tanımlandığını ama içindeki değere
değiştirilebilir referans alabildiğimizi fark etmiş olabilirsiniz. Bu da
Mutex<T>nin, Cell ailesindeki türler gibi içsel değiştirilebilirlik
sağladığını gösterir. 15. bölümde Rc<T> içindeki değeri değiştirebilmek için
RefCell<T> kullanmıştık; burada da aynı işi Arc<T> içindeki değer için
Mutex<T> ile yapıyoruz.
Dikkat edilmesi gereken başka bir nokta daha var: Mutex<T> kullanırken Rust
sizi her türlü mantık hatasından koruyamaz. 15. bölümde, Rc<T> kullanırken
iki değerin birbirini işaret etmesiyle referans döngüsü kurulabileceğini ve
bunun bellek sızıntısına yol açabileceğini görmüştünüz. Benzer biçimde
Mutex<T> de kilitlenme (deadlock) riskini taşır. Bu durum, bir işlemin iki
kaynak için kilit alması gerektiğinde ve iki iş parçacığının bu kilitlerden
birer tanesini alıp birbirini sonsuza kadar beklemesiyle ortaya çıkar.
Kilitlenmeler ilginizi çekiyorsa, bir kilitlenme içeren küçük bir Rust programı
yazmayı deneyin. Ardından başka dillerde mutex kullanan sistemlerde uygulanan
kilitlenme azaltma stratejilerini araştırın ve benzerini Rust’ta kurmayı
deneyin. Standart kütüphanedeki Mutex<T> ve MutexGuard API belgeleri bu
konuda yararlı bilgiler içerir.
Bölümü Send ve Sync trait’lerinden ve bunları özel türlerle nasıl
kullanabileceğimizden söz ederek tamamlayacağız.
Send ve Sync ile Genişletilebilir Eşzamanlılık
Send ve Sync ile Genişletilebilir Eşzamanlılık
İlginç bir nokta şu: Bu bölümde şimdiye kadar gördüğümüz eşzamanlılık özelliklerinin neredeyse tamamı dilin kendisinden değil, standart kütüphaneden geliyor. Yani eşzamanlılığı ele alırken seçenekleriniz yalnızca dilin veya standart kütüphanenin sunduklarıyla sınırlı değil; kendi eşzamanlılık araçlarınızı yazabilir ya da başkalarının yazdığı çözümleri kullanabilirsiniz.
Buna rağmen, dilin içine gömülü temel eşzamanlılık kavramları arasında
standart kütüphanedeki std::marker trait’leri olan Send ve Sync özel bir
yer tutar.
İş Parçacıkları Arasında Sahiplik Aktarmak
Send işaretleyici trait’i, bu trait’i uygulayan bir türün değerlerinin
iş parçacıkları arasında taşınabildiğini söyler. Rust’taki türlerin neredeyse
tamamı Send uygular; ama Rc<T> gibi bazı istisnalar vardır. Rc<T>,
Send olamaz; çünkü bir Rc<T> değerini clone edip kopyanın sahipliğini
başka bir iş parçacığına aktarsaydınız, iki iş parçacığı da referans sayısını
aynı anda güncelleyebilirdi. Bu nedenle Rc<T>, iş parçacığı güvenliğinin
performans maliyetini ödemek istemediğiniz tek iş parçacıklı senaryolar için
tasarlanmıştır.
Dolayısıyla Rust’ın tür sistemi ve trait sınırları, bir Rc<T> değerini
yanlışlıkla iş parçacıkları arasında güvensiz şekilde göndermenizi engeller.
Bunu 16-14 numaralı listede denediğimizde the trait `Send` is not implemented for `Rc<Mutex<i32>>` hatasını aldık. Send uygulayan Arc<T>
kullandığımız anda kod derlendi.
Tamamı Send türlerinden oluşan bir tür de otomatik olarak Send kabul edilir.
Ham işaretçiler hariç, ilkel türlerin neredeyse tamamı Send’dir; ham
işaretçilere 20. bölümde döneceğiz.
Birden Fazla İş Parçacığından Erişim
Sync işaretleyici trait’i, bu trait’i uygulayan türlere birden fazla
iş parçacığından referans vermenin güvenli olduğunu belirtir. Başka bir deyişle
bir T türü için &T (T’ye değiştirilemez referans) güvenle başka bir
iş parçacığına gönderilebiliyorsa, o T türü Sync uygular. Send’e benzer
biçimde ilkel türlerin tamamı Sync uygular; tamamen Sync türlerden oluşan
türler de yine Sync olur.
Akıllı işaretçi Rc<T>, Send uygulamamasının sebebiyle aynı nedenle Sync
de uygulamaz. 15. bölümde gördüğümüz RefCell<T> ile onun akrabası olan
Cell<T> ailesi de Sync değildir. Çünkü RefCell<T>’nin çalışma zamanında
yaptığı ödünç denetimi iş parçacığı güvenli değildir. Buna karşılık akıllı
işaretçi Mutex<T>, Sync uygular ve [“Mutex<T> için Paylaşımlı Erişim”]
shared-access bölümünde gördüğünüz gibi birden fazla iş
parçacığı arasında erişim paylaşmak için kullanılabilir.
Send ve Sync’i Elle Uygulamak Güvensizdir
Tamamı Send ve Sync uygulayan parçalardan oluşan türler bu trait’leri
zaten otomatik olarak aldığı için, çoğu zaman bunları elle uygulamamız gerekmez.
Üstelik bunlar işaretleyici trait olduğu için uygulanacak bir metod da yoktur;
esas amaçları eşzamanlılığa ilişkin bazı değişmezleri zorunlu kılmaktır.
Bu trait’leri elle uygulamak, unsafe Rust kodu yazmayı gerektirir.
unsafe Rust’ı 20. bölümde ele alacağız. Şimdilik bilinmesi gereken nokta şu:
Send ve Sync parçalardan oluşmayan yeni eşzamanlı türler tasarlamak,
güvenlik güvencelerini koruyabilmek için çok dikkatli düşünmeyi gerektirir.
“The Rustonomicon”, bu güvenceler ve onları nasıl koruyacağınız
hakkında daha ayrıntılı bilgi içerir.
Özet
Bu kitapta eşzamanlılık konusunu son kez görmüyorsunuz: Bir sonraki bölüm eşzamansız programlamaya odaklanacak ve 21. bölümdeki proje bu bölümdeki kavramları, burada gördüğümüz küçük örneklerden daha gerçekçi bir senaryoda kullanacak.
Daha önce de değindiğimiz gibi, Rust’ın eşzamanlılığı ele alış biçiminin çok az bir kısmı dilin parçasıdır; birçok çözüm crate’ler halinde sunulur. Bu crate’ler standart kütüphaneden daha hızlı gelişir. Bu yüzden çok iş parçacıklı senaryolarda kullanılacak güncel ve güçlü crate’leri çevrim içi araştırmayı ihmal etmeyin.
Rust standart kütüphanesi, mesaj iletimi için kanallar ve Mutex<T> ile
Arc<T> gibi eşzamanlı bağlamlarda güvenle kullanılabilen akıllı işaretçiler
sağlar. Tür sistemi ile ödünç alma denetleyicisi, bu çözümleri kullanan
kodunuzun veri yarışına ya da geçersiz referanslara sürüklenmemesini sağlar.
Kodunuz bir kez derlendikten sonra, başka dillerde peşine düşmesi zor olan
hatalara kapılmadan birden fazla iş parçacığında güvenle çalışacağına
inanabilirsiniz. Eşzamanlı programlama artık korkulacak bir şey değil:
Programlarınızı korkusuzca eşzamanlı hale getirin!
Eşzamansız Programlamanın Temelleri: Async, Await, Future ve Akışlar
Bilgisayardan yapmasını istediğimiz birçok işlem biraz zaman alabilir. Bu uzun süren işler tamamlanmayı beklerken başka bir şeyler de yapabilsek güzel olurdu. Modern bilgisayarlar aynı anda birden fazla iş üzerinde çalışmak için iki temel yaklaşım sunar: paralellik ve eşzamanlılık. Buna karşılık programlarımızın mantığı çoğu zaman daha doğrusal yazılır. Programın hangi işlemleri yapacağını ve bir fonksiyonun hangi noktalarda duraklayıp başka bir bölümün devreye girebileceğini, her kod parçasının tam olarak hangi sırayla ve nasıl çalışacağını en baştan tek tek tarif etmek zorunda kalmadan ifade edebilmek isteriz. Eşzamansız programlama (asynchronous programming), tam da bunu sağlayan bir soyutlamadır: kodu, olası duraklama noktaları ve sonunda üretilecek sonuçlar üzerinden ifade etmemize izin verir; geri kalan koordinasyon ayrıntılarını da bizim yerimize üstlenir.
Bu bölüm, 16. bölümde iş parçacıklarıyla gördüğümüz paralellik ve eşzamanlılık
yaklaşımını temel alıp alternatif bir yol tanıtıyor: Rust’ın future’ları,
akışları, async ve await sözdizimi ve eşzamansız işlemlerin yürütülmesini
yöneten üçüncü taraf çalışma zamanı crate’leri.
Bir örnek düşünelim. Diyelim ki aile kutlamasından hazırladığınız bir videoyu dışa aktarıyorsunuz. Bu işlem dakikalar, hatta saatler sürebilir. Video dışa aktarma, kullanabildiği kadar CPU ve GPU gücü tüketir. Eğer tek CPU çekirdeğiniz olsaydı ve işletim sistemi bu dışa aktarmayı bitene kadar durdurmasaydı, yani işlem senkron çalışsaydı, bu görev sürerken bilgisayarda başka hiçbir şey yapamazdınız. Bu oldukça can sıkıcı olurdu. Neyse ki işletim sistemleri bu tür işleri görünmez biçimde yeterince sık bölerek aynı anda başka işlerin de yürümesine olanak tanır.
Şimdi de başkasının paylaştığı bir videoyu indirdiğinizi düşünün. Bu da zaman alabilir; ama CPU’yu video dışa aktarma kadar meşgul etmez. Burada CPU, ağdan veri gelmesini beklemek zorundadır. Veri gelmeye başlar başlamaz okumaya başlayabilirsiniz; ama tamamının ulaşması zaman alabilir. Veri geldikten sonra bile, video büyükse hepsini belleğe almak bir iki saniye sürebilir. Bu kısa gibi görünse de, saniyede milyarlarca işlem yapabilen modern işlemciler için uzun bir süredir. Yine işletim sistemi, ağ çağrısı tamamlanana kadar beklerken CPU’nun başka işler yapmasına olanak tanımak için programı görünmez biçimde keser.
Video dışa aktarma, CPU-bağımlı ya da hesaplama-bağımlı bir işe örnektir. Sınırını, CPU veya GPU’nun işleme hızı ve bu hızın ne kadarını bu işe ayırabildiği belirler. Video indirme ise G/Ç-bağımlı (I/O-bound) bir işlemdir; burada sınır, bilgisayarın girdi/çıktı hızıdır. Ağ üzerinden veri ne kadar hızlı gelirse işlem de ancak o kadar hızlı ilerleyebilir.
Her iki örnekte de işletim sisteminin görünmez kesmeleri bir tür eşzamanlılık sağlar. Ancak bu eşzamanlılık tüm program düzeyindedir: işletim sistemi bir programı durdurup başka programlara çalışma fırsatı verir. Çoğu durumda ise, programlarımızı işletim sisteminden daha ayrıntılı bildiğimiz için, onun göremediği eşzamanlılık fırsatlarını biz fark edebiliriz.
Örneğin dosya indirmelerini yöneten bir araç yazıyorsak, tek bir indirme başlatmanın arayüzü kilitlememesi gerekir; kullanıcılar aynı anda birden fazla indirme de başlatabilmelidir. Oysa ağla etkileşen birçok işletim sistemi API’si bloklayıcıdır (blocking); yani işlediği veri tamamen hazır olana kadar programın ilerleyişini durdurur.
Not: Aslında düşünürseniz çoğu fonksiyon çağrısı da böyledir. Ama bloklayıcı terimi genellikle dosyalar, ağ ya da bilgisayardaki başka kaynaklarla etkileşen çağrılar için kullanılır; çünkü özellikle bu tür durumlarda işlemin bloklamayan olması program açısından önemli fayda sağlar.
Ana iş parçacığımızı bloklamaktan kaçınmak için her dosya indirmesine ayrı bir iş parçacığı ayırabilirdik. Ancak bu iş parçacıklarının kullandığı sistem kaynaklarının ek maliyeti bir noktadan sonra sorun olur. İdeal olan, çağrının baştan bloklamaması ve bizim yalnızca programın tamamlamasını istediğimiz bir iş kümesini tanımlayıp, bunların en iyi sırayla ve biçimde nasıl çalıştırılacağı kararını çalışma zamanına bırakmamızdır.
Rust’ın async (yani asynchronous) soyutlaması tam olarak bunu sağlar. Bu bölümde şu başlıkları ele alacağız:
- Rust’ın
asyncveawaitsözdizimi nasıl kullanılır, eşzamansız fonksiyonlar bir çalışma zamanı ile nasıl yürütülür? asyncmodeli, 16. bölümde gördüğümüz bazı eşzamanlılık problemlerini çözmek için nasıl kullanılır?- Çok iş parçacıklı yapı ile
async, birbirini tamamlayan çözümler olarak hangi durumlarda birlikte kullanılabilir?
Ama önce, async’in pratikte nasıl çalıştığını görmeden önce, paralellik ile
eşzamanlılık arasındaki farkı biraz daha netleştirelim.
Paralellik ve Eşzamanlılık
Şimdiye kadar paralellik ile eşzamanlılığı çoğu yerde neredeyse eş anlamlı gibi kullandık. Artık bunları biraz daha dikkatli ayırmamız gerekiyor; çünkü çalışmaya başladıkça aradaki farklar görünür hale gelecek.
Bir yazılım projesindeki işi bir ekibin nasıl paylaştırabileceğini düşünün. Tek bir kişiye birden fazla görev verebilir, her kişiye tek bir görev atayabilir ya da bu iki yaklaşımı karıştırabilirsiniz.
Bir kişi, görevlerin hiçbiri bitmeden önce birkaç farklı iş üzerinde sırayla çalışıyorsa bu _eşzamanlılık_tır. Bunu uygulamanın bir yolu, bilgisayarınızda iki farklı proje açık tutmaya benzer: birinden sıkıldığınızda ya da bir yerde takıldığınızda ötekine geçersiniz. Tek kişisinizdir; iki işte tam anlamıyla aynı anda ilerleyemezsiniz. Ama aralarında gidip gelerek ikisini de yavaş yavaş ilerletebilirsiniz (bkz. Şekil 17-1).

Ekipteki herkes bir görev alıp onun üzerinde tek başına çalışıyorsa bu _paralellik_tir. Ekipteki her kişi tam anlamıyla aynı anda ilerleme kaydedebilir (bkz. Şekil 17-2).

Bu iki iş akışında da görevler arasında koordinasyon gerekebilir. Diyelim ki bir kişiye verilen görevin ötekilerden tamamen bağımsız olduğunu sandınız ama aslında önce başka birinin işini bitirmesi gerekiyordu. Bu durumda işin bir kısmı paralel yapılabilirken, bir kısmı da aslında seri olarak, yani birbiri ardına ilerlemek zorundadır (bkz. Şekil 17-3).

Aynı şekilde, kendi işlerinizden birinin başka bir işinize bağlı olduğunu fark edebilirsiniz. Bu durumda eşzamanlı çalışmanız da kısmen seri hale gelir.
Paralellik ile eşzamanlılık bazen birbirinin içine de geçer. Bir iş arkadaşınız siz bir görevi bitirene kadar beklemek zorundaysa, büyük olasılıkla tüm enerjinizi o göreve verip onun önünü açarsınız. Böylece artık ne onunla paralel çalışıyorsunuzdur ne de kendi diğer işleriniz arasında eşzamanlı geçiş yapıyorsunuzdur.
Aynı temel dinamik yazılım ve donanım için de geçerlidir. Tek CPU çekirdekli
bir makinede işlemci aynı anda yalnızca tek bir iş yapabilir; ama yine de
eşzamanlı çalışabilir. İş parçacıkları, süreçler ve async gibi araçlarla
bilgisayar bir işi durdurup diğerlerine geçebilir, sonra yeniden ilkine döner.
Birden fazla CPU çekirdeği olan makinede ise gerçekten paralel çalışma da
mümkündür. Bir çekirdek bir işi yaparken diğeri tamamen farklı bir işi aynı
anda yürütebilir.
Rust’ta async kod genellikle eşzamanlı yürür. Donanıma, işletim sistemine ve
kullandığımız eşzamanlı çalışma zamanına bağlı olarak, bu eşzamanlılık arka
planda paralellik de kullanabilir.
Şimdi Rust’ta eşzamansız programlamanın gerçekten nasıl çalıştığına bakalım.
Futures ve Async Sözdizimi
Future’lar ve Async Sözdizimi
Rust’ta eşzamansız programlamanın temel taşları future yapısı ile async ve
await anahtar sözcükleridir.
Bir future, şu anda hazır olmayabilen ama ileride bir noktada hazır olacak
değerdir. Aynı kavram başka dillerde bazen task ya da promise gibi
isimlerle de karşınıza çıkar. Rust, farklı eşzamansız işlemlerin farklı veri
yapılarıyla gerçekleştirilebilmesini ama yine de ortak bir arayüzle
çalışabilmesini sağlamak için Future trait’ini sunar. Rust’ta future’lar,
Future trait’ini uygulayan türlerdir. Her future, ne kadar ilerlediğine ve
“hazır” olmanın ne anlama geldiğine dair kendi durum bilgisini taşır.
async anahtar sözcüğünü bloklara ve fonksiyonlara uygulayarak bunların
duraklatılıp yeniden sürdürülebileceğini belirtirsiniz. Bir async blok ya da
async fonksiyon içinde ise await kullanarak bir future’ı bekleyebilirsiniz.
Bir async blok ya da fonksiyon içinde future beklediğiniz her nokta, o bloğun
veya fonksiyonun duraklayıp yeniden devam edebileceği potansiyel yerdir.
Bir future’ın değerinin hazır olup olmadığını yoklama sürecine polling denir.
C# ve JavaScript gibi başka diller de async ile await anahtar sözcüklerini
kullanır. Bu dillere aşinaysanız Rust’ın sözdizimi ve davranışında dikkate değer
farklar olduğunu görebilirsiniz. Birazdan bunun nedenini de anlayacağız.
Pratikte async Rust yazarken çoğu zaman async ile await kullanırız. Rust
bunları, tıpkı for döngülerini Iterator trait’i üzerinden eşdeğer koda
çevirdiği gibi, Future trait’ini kullanan eşdeğer koda derler. Ama Rust bize
Future trait’ini sunduğu için, gerektiğinde bu trait’i kendi veri türleriniz
için de uygulayabilirsiniz.
Bu anlatım biraz soyut kalmış olabilir. O yüzden ilk async programımızı yazalım: küçük bir web kazıyıcı. Komut satırından iki URL alacak, ikisini de eşzamanlı olarak isteyecek ve hangisi önce biterse onun sonucunu döndürecek.
İlk Async Programımız
Bu bölümde odağı ekosistemin ayrıntılarına değil, async öğrenmeye vermek için
trpl crate’ini kullandık. trpl, başta futures ve tokio olmak üzere ihtiyaç duyacağınız türleri,
trait’leri ve fonksiyonları yeniden dışa aktarır. futures crate’i Rust’ın
async denemeleri için resmî yuvalardan biridir ve Future trait’i de ilk kez
orada tasarlandı. Tokio ise bugün Rust dünyasında özellikle web uygulamaları
için en yaygın async çalışma zamanıdır.
Bazen trpl, bölümde önemli olmayan ayrıntılarla dikkatimizin dağılmaması için
orijinal API’leri yeniden adlandırır ya da sarmalar. Nasıl çalıştığını görmek
isterseniz kaynak koduna bakabilirsiniz.
hello-async adında yeni bir ikili proje oluşturup trpl bağımlılığını
ekleyin:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Şimdi trpl’nin sunduğu parçalarla ilk async programımızı yazabiliriz.
İki web sayfasını alacak, her birinin <title> etiketini çıkaracak ve hangisi
önce biterse onun başlığını yazdıran küçük bir komut satırı aracı kuracağız.
sayfa_basligi Fonksiyonunu Tanımlamak
İlk olarak, bir sayfanın URL’sini parametre olarak alan, sayfaya istek yapan ve
<title> etiketindeki metni döndüren bir fonksiyon yazalım.
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn sayfa_basligi(url: &str) -> Option<String> {
let yanit = trpl::get(url).await;
let yanit_metni = yanit.text().await;
Html::parse(&yanit_metni)
.select_first("title")
.map(|title| title.inner_html())
}Önce sayfa_basligi adında bir fonksiyon tanımlıyor ve onu async ile
işaretliyoruz. Sonra kendisine verilen URL’yi almak için trpl::get
fonksiyonunu çağırıyor, yanıtı beklemek için await kullanıyoruz. Ardından
yanıtın gövdesini metne çevirmek için text metodunu çağırıyor ve onu da
bekliyoruz. Bu iki adımın ikisi de eşzamansızdır.
Bu future’ların ikisini de açıkça beklemek zorundayız; çünkü Rust’ta future’lar
tembeldir. Yani siz await etmeden hiçbir şey yapmazlar. Bu size 13.
bölümdeki yineleyicileri hatırlatabilir: yineleyiciler de next çağrısı
olmadan ilerlemez.
Not: Bu davranış, 16. bölümde
thread::spawnile gördüğümüzden farklıdır. Orada yeni iş parçacığına verdiğimiz kapanış hemen çalışmaya başlamıştı. Rust’ın performans güvencelerini koruyabilmesi için future’ların tembel olması önemlidir.
yanit_metni elimizde olduğunda, onu Html::parse ile Html türüne çevirip
ham dizgi yerine daha zengin bir veri yapısı üzerinde çalışıyoruz. Özellikle
select_first("title") ile ilk <title> öğesini buluyoruz. Böyle bir öğe
olmayabileceği için sonuç Option<ElementRef> olur. Son olarak map
kullanarak varsa başlık içeriğini String olarak çıkarıyoruz. Sonuçta elimizde
Option<String> olur.
Rust’ta await anahtar sözcüğünün, beklenen ifadenin önüne değil sonuna
geldiğine dikkat edin. Yani sonek biçimindedir. Bu, metot zincirlerini daha
rahat yazabilmemizi sağlar. Nitekim 17-2 numaralı listedeki gibi trpl::get
ve text çağrılarını tek zincirde de kullanabiliriz.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn sayfa_basligi(url: &str) -> Option<String> {
let yanit_metni = trpl::get(url).await.text().await;
Html::parse(&yanit_metni)
.select_first("title")
.map(|title| title.inner_html())
}await anahtar sözcüğüyle zincirleme çağrı yapmakBöylece ilk async fonksiyonumuzu yazmış olduk. Şimdi main içinde bunu
çağırmadan önce, derleyicinin bu kodu nasıl gördüğüne kısaca bakalım.
Rust, async ile işaretlenmiş bir blok gördüğünde, onu Future trait’ini
uygulayan benzersiz ve adsız bir veri türüne dönüştürür. async ile işaretli
bir fonksiyon gördüğünde ise, gövdesi bir async blok olan normal bir
fonksiyona çevirir. Async fonksiyonun dönüş türü de derleyicinin o async blok
için oluşturduğu adsız veri türüdür.
Bu yüzden async fn yazmak, aslında “dönüş türü future olan bir fonksiyon”
yazmakla eşdeğerdir. Derleyici açısından 17-1’deki async fn sayfa_basligi
aşağı yukarı şuna denk gelir:
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn sayfa_basligi(url: &str) -> impl Future<Output = Option<String>> {
async move {
let metin = trpl::get(url).await.text().await;
Html::parse(&metin)
.select_first("title")
.map(|title| title.inner_html())
}
}Burada birkaç kritik nokta var:
- Dönüşte, 10. bölümde gördüğümüz
impl Traitsözdizimi kullanılıyor. - Dönen değer
Futureuygular veOutputtürüOption<String>olur. - Orijinal fonksiyon gövdesindeki bütün kod, bir
async moveblok içine sarılmıştır. - Blok ifadesi fonksiyonun gerçek dönüş değeridir.
Bir Async Fonksiyonu Çalışma Zamanıyla Yürütmek
İlk adım olarak tek bir sayfanın başlığını alalım. 17-3 numaralı liste bunu gösteriyor; ama bu hali henüz derlenmez.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match sayfa_basligi(url).await {
Some(title) => println!("{url} için başlık {title} idi"),
None => println!("{url} için başlık yoktu"),
}
}
async fn sayfa_basligi(url: &str) -> Option<String> {
let yanit_metni = trpl::get(url).await.text().await;
Html::parse(&yanit_metni)
.select_first("title")
.map(|title| title.inner_html())
}sayfa_basligi fonksiyonunu main içinden çağırmak- bölümde komut satırı argümanlarını alırken kullandığımız aynı deseni
izliyoruz. Sonra URL’yi
sayfa_basligifonksiyonuna verip sonucu bekliyoruz. SonuçOption<String>olduğu için, sayfanın başlığı olup olmamasına göre farklı mesajlar yazdırmak adınamatchkullanıyoruz.
Sorun şu: await anahtar sözcüğünü yalnızca async fonksiyonlarda ya da async
bloklarda kullanabilirsiniz. Rust, özel main fonksiyonunu doğrudan async
yapmanıza izin vermez.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
mainin async olamamasının sebebi, async kodun bir çalışma zamanına
(runtime) ihtiyaç duymasıdır. Çalışma zamanı, eşzamansız kodun yürütülme
ayrıntılarını yöneten crate’tir. Bir programın main fonksiyonu çalışma
zamanını başlatabilir; ama onun kendisi çalışma zamanı değildir. Async kod
çalıştıran her Rust programı, future’ları yürütecek bir çalışma zamanı kurulan
en az bir noktaya sahiptir.
Async destekleyen birçok dil çalışma zamanını dilin içine gömer; Rust bunu yapmaz. Bunun yerine, hedef kullanım durumuna göre farklı ödünleşimler yapan çeşitli async çalışma zamanları vardır. Yüksek trafikli, çok çekirdekli bir sunucunun ihtiyaçlarıyla tek çekirdekli küçük bir mikrokontrolcünün ihtiyaçları aynı değildir.
Bu bölümde trpl crate’inden block_on fonksiyonunu kullanacağız. Bu
fonksiyon, bir future alır ve o future tamamlanana kadar mevcut iş parçacığını
bekletir. Arka planda tokio kullanarak bir çalışma zamanı kurar ve verdiğiniz
future’ı çalıştırır. Future bitince de onun ürettiği değeri geri döndürür.
İsterseniz sayfa_basligi’ndan dönen future’ı doğrudan block_ona verip sonuç
üzerinde match yapabilirsiniz. Ama çoğu gerçek async kodda tek bir async
çağrıdan fazlası olduğu için, biz 17-4 numaralı listedeki gibi bir async blok
geçip sayfa_basligi çağrısını onun içinde await edeceğiz.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match sayfa_basligi(url).await {
Some(title) => println!("{url} için başlık {title} idi"),
None => println!("{url} için başlık yoktu"),
}
})
}
async fn sayfa_basligi(url: &str) -> Option<String> {
let yanit_metni = trpl::get(url).await.text().await;
Html::parse(&yanit_metni)
.select_first("title")
.map(|title| title.inner_html())
}trpl::block_on ile bir async bloğu beklemekBu kodu çalıştırdığımızda başta beklediğimiz davranışı alırız:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/asenkron_bekleme 'https://www.rust-lang.org'`
https://www.rust-lang.org için başlık Rust Programming Language idi
Her await noktası, denetimin çalışma zamanına geri verildiği yerdir.
Çalışma zamanının daha sonra dönüp devam edebilmesi için, derleyici async blok
içindeki durumu görünmez bir durum makinesi olarak saklar. Sanki aşağıdaki gibi
bir enum yazmışsınız gibi düşünebilirsiniz:
extern crate trpl; // required for mdbook test
enum SayfaBasligiFuture<'a> {
Baslangic { url: &'a str },
GetBeklemeNoktasi { url: &'a str },
MetinBeklemeNoktasi { yanit: trpl::Response },
}Bu durum makinesini elle yazmak yorucu ve hataya açık olurdu. Neyse ki Rust derleyicisi async kod için gereken veri yapılarını otomatik olarak üretip yönetir. Ödünç alma ve sahiplik kuralları da aynı şekilde geçerli olmaya devam eder.
Nihayetinde bu durum makinesini bir şeyin yürütmesi gerekir; işte o şey çalışma zamanıdır. Bu nedenle async dünyasında sık sık executor terimini de görürsünüz: executor, çalışma zamanının async kodu fiilen yürüten parçasıdır.
Artık 17-3’te neden doğrudan async fn main yazamadığımızı daha net görebiliriz.
main async olsaydı, ondan dönen future’ın durum makinesini de başka bir şeyin
yönetmesi gerekirdi. Oysa programın başlangıç noktası zaten maindir. Bu
yüzden main içinde trpl::block_on çağırıp çalışma zamanını elle kurduk.
Not: Bazı çalışma zamanları, doğrudan async
mainyazmanızı sağlayan makrolar sunar. Bu makrolar perde arkasında bizim 17-4’te elle yaptığımızı yapar: normal birmainoluşturur, içinde çalışma zamanını başlatır ve future’ı tamamlanana kadar yürütür.
İki URL’yi Eşzamanlı Olarak Yarıştırmak
Şimdi sayfa_basligi fonksiyonunu komut satırından aldığımız iki farklı URL ile
çağırıp hangisinin önce döndüğünü görelim. 17-5 numaralı liste bunu yapar.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let baslik_gelecegi_1 = sayfa_basligi(&args[1]);
let baslik_gelecegi_2 = sayfa_basligi(&args[2]);
let (url, olasi_baslik) =
match trpl::select(baslik_gelecegi_1, baslik_gelecegi_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} ilk döndü");
match olasi_baslik {
Some(title) => println!("Sayfa başlığı şuydu: '{title}'"),
None => println!("Başlığı yoktu."),
}
})
}
async fn sayfa_basligi(url: &str) -> (&str, Option<String>) {
let yanit_metni = trpl::get(url).await.text().await;
let title = Html::parse(&yanit_metni)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}sayfa_basligi çağırıp hangisinin önce döndüğünü görmekÖnce iki URL için ayrı ayrı sayfa_basligi çağırıyor ve dönen future’ları
baslik_gelecegi_1 ile baslik_gelecegi_2 içinde saklıyoruz. Bunlar henüz
hiçbir şey yapmaz; çünkü future’lar tembeldir ve onları daha beklemedik.
Sonra bunları trpl::select fonksiyonuna veriyoruz. select, kendisine verilen
future’lardan hangisi önce tamamlansa ona göre bir değer döndürür.
trpl::select sonucunda Either::Left ya da Either::Right gelir. Hangi taraf
döndüyse, ona karşılık gelen URL ve başlık bilgisini alırız. Böylece “ilk önce
hangi URL döndü?” sorusuna cevap verip, eğer başlık varsa onu da yazdırabiliriz.
Bu örnek bize iki önemli şeyi gösterir:
- Future’lar ancak beklendiklerinde gerçekten yürür.
- Birden fazla future’ı aynı anda başlatmak için onları teker teker
awaitetmek yerine,selectveyajoingibi yardımcılarla birlikte yürütmek gerekir.
Böylece ilk gerçek async programımızı da tamamlamış olduk. Sonraki bölümde, aynı yaklaşımı daha genel eşzamanlılık problemlerine uygulayacağız.
Async ile Eşzamanlılık Uygulama
async ile Eşzamanlılığı Uygulamak
Bu bölümde async yaklaşımını, 16. bölümde iş parçacıklarıyla ele aldığımız
eşzamanlılık problemlerinin bazılarına uygulayacağız. Orada temel fikirlerin
çoğunu zaten konuştuğumuz için, burada daha çok iş parçacıkları ile future’lar
arasındaki farklara odaklanacağız.
Birçok durumda async ile eşzamanlılık kurmaya yarayan API’ler, iş
parçacıklarıyla çalışırken kullandıklarımıza oldukça benzer. Bazı durumlarda ise
tam tersine belirgin biçimde farklılaşırlar. Ayrıca API’ler dışarıdan benzer
göründüğünde bile, çoğu zaman davranışları ve neredeyse her zaman performans
özellikleri farklıdır.
spawn_task ile Yeni Bir Görev Oluşturmak
- bölümde “
spawnile Yeni Bir İş Parçacığı Oluşturmak” kısmında yaptığımız ilk örnek, iki ayrı iş parçacığında sayaç arttırmaktı. Aynı şeyi bu kezasyncile yapalım.trplcrate’i,thread::spawnAPI’sine çok benzeyenspawn_taskfonksiyonunu vethread::sleep’in eşzamansız karşılığı olansleepfonksiyonunu sunar. Bunları birlikte kullanınca 17-6 numaralı listedeki örneği elde ederiz.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("birinci görevden merhaba sayı {i}!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("ikinci görevden merhaba sayı {i}!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}Başlangıç olarak main fonksiyonunu trpl::block_on ile sarıyoruz; böylece en
üst düzey akışımız eşzamansız çalışabiliyor.
Not: Bu noktadan sonra bölümdeki her örnek
mainiçinde aynıtrpl::block_onsarmalamasını kullanacak. Tıpkımainfonksiyonunu çoğu örnekte açıkça göstermediğimiz gibi, burada da zaman zaman bunu atlayacağız. Kendi kodunuza eklemeyi unutmayın.
Ardından blok içinde iki döngü yazıyoruz. Her ikisinde de yarım saniye bekleyen
bir trpl::sleep çağrısı var. Döngülerden birini trpl::spawn_task içine,
ötekini de üst düzey for döngüsü olarak bırakıyoruz. sleep çağrılarından
sonra da await ekliyoruz.
Bu kod, iş parçacıklı sürüme çok benzer davranır. Kendi terminalinizde çalıştırdığınızda mesajların sırası yine farklı olabilir:
ikinci görevden merhaba sayı 1!
birinci görevden merhaba sayı 1!
birinci görevden merhaba sayı 2!
ikinci görevden merhaba sayı 2!
birinci görevden merhaba sayı 3!
ikinci görevden merhaba sayı 3!
birinci görevden merhaba sayı 4!
ikinci görevden merhaba sayı 4!
birinci görevden merhaba sayı 5!
Ama bu sürüm, ana async blok içindeki for döngüsü biter bitmez sonlanır.
Çünkü spawn_task ile başlattığımız görev, main sona erdiğinde kapatılır.
İlk görevin gerçekten sonuna kadar çalışmasını istiyorsak, onun bitmesini
beklemek için bir join tutamacı kullanmamız gerekir. İş parçacıklarında bunu
join ile yapmıştık. 17-7 numaralı listede aynı işi await ile yapıyoruz;
çünkü görev tutamacının kendisi zaten bir future’dır. Output türü Result
olduğu için await sonrasında unwrap da çağırıyoruz.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let tutamac = trpl::spawn_task(async {
for i in 1..10 {
println!("birinci görevden merhaba sayı {i}!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("ikinci görevden merhaba sayı {i}!");
trpl::sleep(Duration::from_millis(500)).await;
}
tutamac.await.unwrap();
});
}await kullanmakBu güncellenmiş sürüm her iki döngü de tamamlanana kadar çalışır:
ikinci görevden merhaba sayı 1!
birinci görevden merhaba sayı 1!
birinci görevden merhaba sayı 2!
ikinci görevden merhaba sayı 2!
birinci görevden merhaba sayı 3!
ikinci görevden merhaba sayı 3!
birinci görevden merhaba sayı 4!
ikinci görevden merhaba sayı 4!
birinci görevden merhaba sayı 5!
birinci görevden merhaba sayı 6!
birinci görevden merhaba sayı 7!
birinci görevden merhaba sayı 8!
birinci görevden merhaba sayı 9!
Şimdilik async ile iş parçacıkları benzer sonuçlar veriyor gibi görünüyor;
sadece sözdizimi farklı. Burada join tutamacında join çağırmak yerine
await kullanıyoruz ve sleep çağrılarını da bekliyoruz.
Asıl büyük fark, bunun için ayrı bir işletim sistemi iş parçacığı açmak zorunda
olmamamız. Hatta burada görev başlatmak bile şart değil. Çünkü async bloklar,
derleme sonrasında adsız future’lara dönüşür. Dolayısıyla her döngüyü bir async
blok içine koyup, ikisini de trpl::join ile birlikte sonuna kadar
çalıştırabiliriz.
- bölümde “Tüm İş Parçacıklarının Bitmesini Beklemek” kısmında
std::thread::spawndönüşü olanJoinHandleüstündejoinmetodunu kullanmıştık.trpl::joinbunun future’lar için olan karşılığı gibidir. İki future verirseniz, size bu ikisi birlikte tamamlandığında her ikisinin çıktısını taşıyan bir demet döndüren yeni bir future üretir. Bu yüzden 17-8 numaralı listedefut1ilefut2yi ayrı ayrı beklemek yerine,trpl::jointarafından üretilen yeni future’ı bekliyoruz.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("birinci görevden merhaba sayı {i}!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("ikinci görevden merhaba sayı {i}!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}trpl::join kullanmakBu kodu çalıştırdığımızda iki future’ın da sonuna kadar yürüdüğünü görürüz:
birinci görevden merhaba sayı 1!
ikinci görevden merhaba sayı 1!
birinci görevden merhaba sayı 2!
ikinci görevden merhaba sayı 2!
birinci görevden merhaba sayı 3!
ikinci görevden merhaba sayı 3!
birinci görevden merhaba sayı 4!
ikinci görevden merhaba sayı 4!
birinci görevden merhaba sayı 5!
birinci görevden merhaba sayı 6!
birinci görevden merhaba sayı 7!
birinci görevden merhaba sayı 8!
birinci görevden merhaba sayı 9!
Bu kez sıra her çalıştırmada aynı kalır. Bu, iş parçacıklarıyla ve 17-7’deki
trpl::spawn_task kullanımıyla gördüğümüzden farklıdır. Nedeni, trpl::join
fonksiyonunun adil (fair) davranmasıdır: her future’ı sırayla yoklar, biri
hazır diye ötekinin önüne geçmesine izin vermez. İş parçacıklarında hangi
iş parçacığının ne kadar süre koşacağını işletim sistemi belirler. Async
Rust’ta ise bu kararı çalışma zamanı verir.
Şu varyasyonları deneyip ne yaptıklarını gözlemleyin:
- Döngülerden birinin ya da ikisinin etrafındaki async bloğu kaldırın.
- Her async bloğu tanımladıktan hemen sonra
awaitedin. - Yalnızca ilk döngüyü async blok içine koyun; sonra oluşan future’ı ikinci döngü tamamlandıktan sonra bekleyin.
Dilerseniz önce çıktının ne olacağını tahmin edip sonra kodu çalıştırarak kontrol edin.
İki Görev Arasında Mesaj İletimiyle Veri Göndermek
Future’lar arasında veri paylaşmak da tanıdık gelecek: yine mesaj iletimi kullanacağız, ama bu kez türlerin ve fonksiyonların eşzamansız sürümleriyle. Temel farkları daha iyi görmek için 16. bölümdeki “İş Parçacıkları Arasında Mesaj İletimiyle Veri Taşımak” kısmına göre biraz farklı bir rota izleyeceğiz. 17-9 numaralı listede yalnızca tek bir async blokla başlıyoruz; henüz ayrı bir görev başlatmıyoruz.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let deger = String::from("merhaba");
gonderici.send(deger).unwrap();
let alinan = alici.recv().await.unwrap();
println!("alındı '{alinan}'");
});
}gonderici ve alici değişkenlerine atamakBurada 16. bölümde iş parçacıklarıyla kullandığımız çoklu üretici, tekli
tüketici kanalının eşzamansız sürümü olan trpl::channel kullanılıyor. API’de
yalnızca küçük farklar var: alıcı taraf değiştirilemez değil değiştirilebilir
oluyor ve recv metodu değeri doğrudan vermek yerine, beklememiz gereken bir
future üretiyor. Mesaj göndermek için ayrı bir iş parçacığına ya da ayrı bir
göreve bile ihtiyacımız yok; yalnızca alici.recv çağrısını beklememiz yeterli.
std::mpsc::channel içindeki senkron Receiver::recv, mesaj gelene kadar
bloklar. Buna karşılık trpl::Receiver::recv bloklamaz; çünkü kendisi zaten
eşzamansızdır. Hazır olmadığında denetimi çalışma zamanına geri verir. Biz de
send çağrısını beklemeyiz; çünkü burada kullandığımız kanal sınırsızdır ve
gönderim bloklayıcı değildir.
Not: Bu eşzamansız kodun tamamı
trpl::block_oniçine verdiğimiz async blokta çalıştığı için, blok içindeki her şey bloklamadan ilerleyebilir. Buna karşılık blok dışındaki kod,block_ondönene kadar bekler.block_onun amacı zaten budur: hangi noktada bloklayıp senkron ile async kod arasında geçiş yapacağını sizin seçmenizi sağlar.
Bu örnekte iki önemli şey var. Birincisi, mesaj hemen gelir. İkincisi, burada future kullansak da henüz gerçek anlamda eşzamanlılık yoktur. Listedeki her şey tıpkı future yokmuş gibi sırayla gerçekleşir.
Şimdi mesajları tek tek ve aralarında bekleyerek gönderelim. 17-10 numaralı liste bunu gösteriyor.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let degerler = vec![
String::from("merhaba"),
String::from("-den"),
String::from("gelecek"),
String::from("icinden"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = alici.recv().await {
println!("alındı '{value}'");
}
});
}await ile beklemekMesajları göndermenin yanı sıra onları almak da gerekiyor. Kaç mesaj geleceğini
bildiğimiz için teoride alici.recv().await çağrısını dört kez elle
yazabilirdik. Ama gerçek hayatta çoğu zaman bilinmeyen sayıda mesaj bekleriz.
Bu yüzden artık mesaj kalmadığını anlayana kadar beklemeyi sürdürmemiz gerekir.
16-10 numaralı listede senkron kanal için for döngüsü kullanmıştık. Rust şu
anda eşzamansız üretilen öğeler için doğrudan for döngüsü sunmadığından,
burada while let koşullu döngüsünü kullanıyoruz. Bu yapı, 6. bölümde
gördüğünüz if let biçiminin döngü karşılığıdır. Desen eşleştiği sürece döngü
devam eder.
alici.recv() çağrısı bir future üretir; biz de onu await ederiz. Mesaj
geldiğinde future Some(message) olarak çözülür. Kanal kapandığında ise artık
değer kalmadığını göstermek için None döner. while let döngüsü bütün bunları
bir araya getirir: sonuç Some(message) ise mesajı alıp gövde içinde
kullanırız; None ise döngü biter.
Bu kod artık bütün mesajları başarıyla gönderip alır; ama iki problem kalır. Birincisi, mesajlar yarım saniye arayla değil, program başladıktan yaklaşık iki saniye sonra topluca gelir. İkincisi, program hiç sonlanmaz; yeni mesaj beklemeye devam eder.
Tek Async Blok İçindeki Kod Doğrusal Çalışır
Mesajların neden tek tek değil de topluca geldiğini anlayarak başlayalım. Bir
async blok içinde await noktaları hangi sıradaysa, kod çalışırken de akış o
sırayla ilerler.
17-10 numaralı listede yalnızca tek bir async blok var; bu yüzden her şey
doğrusaldır. Hâlâ eşzamanlılık yoktur. Bütün gonderici.send çağrıları ve
onların arasındaki trpl::sleep çağrıları tamamlanır; ancak ondan sonra
while let döngüsü recv tarafındaki await noktalarına gelmeye başlar.
İstediğimiz davranış, yani her mesaj arasında gerçekten beklenmesi ise
gönderme ve alma işlemlerini kendi async bloklarına ayırmamızı gerektirir.
Bunu 17-11 numaralı listede yapıyoruz ve iki future’ı trpl::join ile birlikte
çalıştırıyoruz.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let gonderici_gelecegi = async {
let degerler = vec![
String::from("merhaba"),
String::from("-den"),
String::from("gelecek"),
String::from("icinden"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let alici_gelecegi = async {
while let Some(value) = alici.recv().await {
println!("alındı '{value}'");
}
};
trpl::join(gonderici_gelecegi, alici_gelecegi).await;
});
}send ile recv işlemlerini ayrı async bloklara bölüp bunların future’larını birlikte beklemekBu güncel sürümle mesajlar iki saniye sonra toplu halde gelmek yerine, yaklaşık 500 milisaniye aralıklarla yazdırılır.
Sahipliği Async Blok İçine Taşımak
Buna rağmen program yine hiç bitmez. Sebep, while let döngüsü ile
trpl::join arasındaki ilişkidir:
trpl::jointarafından dönen future ancak kendisine verilen iki future da bittiğinde tamamlanır.- Gönderen future, son mesajı yolladıktan sonra son uykusunu da tamamlayınca biter.
- Alan future,
while letdöngüsü bitmeden tamamlanmaz. while letdöngüsü,alici.recv().awaitNonedöndürmeden bitmez.recvancak kanalın öbür ucu kapandığındaNonedöndürür.- Kanal, ya
alici.closeçağrılırsa ya da gönderici taraf düşerse kapanır.
Şu anda mesaj gönderen async blok gondericiyi yalnızca ödünç alıyor. Ama onu
blok içine taşıyabilseydik, blok sona erdiğinde gonderici de düşerdi.
13. bölümde move anahtar sözcüğünü kapanışlarla nasıl kullandığımızı, 16.
bölümde de iş parçacıklarıyla çalışırken neden sık sık buna ihtiyaç duyduğumuzu
görmüştünüz. Aynı mantık async bloklar için de geçerlidir. Bu yüzden 17-12
numaralı listede async bloğunu async move yapıyoruz.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let gonderici_gelecegi = async move {
// --snip--
let degerler = vec![
String::from("merhaba"),
String::from("-den"),
String::from("gelecek"),
String::from("icinden"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let alici_gelecegi = async {
while let Some(value) = alici.recv().await {
println!("alındı '{value}'");
}
};
trpl::join(gonderici_gelecegi, alici_gelecegi).await;
});
}Bu sürümü çalıştırdığımızda, son mesaj alındıktan sonra program düzgün biçimde sona erer. Şimdi birden fazla future’dan veri göndermek için nelerin değişmesi gerektiğine bakalım.
join! Makrosuyla Birden Fazla Future’ı Birleştirmek
Bu eşzamansız kanal aynı zamanda çoklu üreticili olduğu için, birden fazla
future içinden mesaj göndermek istersek gonderici üstünde clone
çağırabiliriz. 17-13 numaralı liste bunu gösteriyor.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let gonderici1 = gonderici.clone();
let gonderici1_gelecegi = async move {
let degerler = vec![
String::from("merhaba"),
String::from("-den"),
String::from("gelecek"),
String::from("icinden"),
];
for deger in degerler {
gonderici1.send(deger).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let alici_gelecegi = async {
while let Some(value) = alici.recv().await {
println!("alındı '{value}'");
}
};
let gonderici_gelecegi = async move {
let degerler = vec![
String::from("daha"),
String::from("fazla"),
String::from("mesaj"),
String::from("sana"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(gonderici1_gelecegi, gonderici_gelecegi, alici_gelecegi);
});
}Önce ilk async bloktan önce gondericiyi klonlayıp gonderici1 oluşturuyoruz.
Sonra 17-12’de yaptığımız gibi gonderici1i ilk bloğun içine taşıyoruz. Daha
sonra da orijinal gondericiyi yeni bir async blok içine taşıyıp biraz daha
yavaş aralıklarla başka mesajlar gönderiyoruz.
Mesaj gönderen iki async blok da async move olmak zorunda. Aksi halde
gonderici ile gonderici1 bloklar tamamlandığında düşmez ve yine sonsuz döngü
sorununa geri döneriz.
Son olarak trpl::join yerine trpl::join! kullanıyoruz. Çünkü bu makro,
derleme zamanında kaç tane future olacağını bildiğimiz durumlarda istediğimiz
sayıda future’ı birlikte beklememize izin verir.
Böylece iki gönderen future’dan gelen bütün mesajları görürüz. Ayrıca iki future farklı gecikmeler kullandığı için, mesajlar da farklı zaman aralıklarında ulaşır:
alındı 'merhaba'
alındı 'daha'
alındı '-den'
alındı 'gelecek'
alındı 'fazla'
alındı 'icinden'
alındı 'mesaj'
alındı 'sana'
Bu bölümde future’lar arasında mesaj iletimini, bir async blok içindeki kodun neden sıralı çalıştığını, sahipliğin async blok içine nasıl taşındığını ve birden fazla future’ın nasıl birleştirildiğini gördük. Şimdi de çalışma zamanına başka bir göreve geçebileceğini ne zaman ve neden söylememiz gerektiğine bakalım.
Herhangi Bir Sayıda Future ile Çalışma
Denetimi Çalışma Zamanına Geri Vermek
“İlk Async Programımız” kısmından hatırlayın:
Her await noktasında Rust, beklenen future hazır değilse çalışma zamanına
görevi durdurup başka bir işe geçme fırsatı verir. Tersi de doğrudur: Rust,
async blokları yalnızca await noktalarında durdurur ve denetimi çalışma
zamanına geri verir. await noktaları arasındaki her şey senkrondur.
Bu şu anlama gelir: Bir async blok içinde await olmadan uzun süre iş
yaparsanız, o future başka future’ların ilerlemesini engeller. Bazen buna bir
future’ın ötekileri aç bırakması denir. Bazı durumlarda bu büyük sorun
olmayabilir. Ama pahalı bir hazırlık işi yapıyorsanız, uzun süren bir hesap
koşturuyorsanız ya da bir future belirli bir işi sonsuza kadar sürdürecekse,
denetimi çalışma zamanına ne zaman geri vereceğinizi dikkatle düşünmeniz
gerekir.
Bunu göstermek için uzun süren bir işlemi taklit edelim. 17-14 numaralı liste,
slow fonksiyonunu tanıtıyor.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' {ms}ms çalıştı");
}thread::sleep kullanmakBu kodda trpl::sleep yerine std::thread::sleep kullanıyoruz; böylece
slow çağrısı mevcut iş parçacığını gerçekten bloke ediyor. Böylece slow
gerçek dünyadaki hem uzun süren hem bloklayıcı işlemleri temsil edebiliyor.
17-15 numaralı listede bu slow fonksiyonunu, iki future içinde CPU-bağımlı iş
yürütmeyi taklit etmek için kullanıyoruz.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' başladı.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' bitti.");
};
let b = async {
println!("'b' başladı.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' bitti.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' {ms}ms çalıştı");
}slow fonksiyonunu çağırmakHer future, bir sürü yavaş işi yaptıktan sonra çalışma zamanına denetim veriyor. Bu kodu çalıştırdığınızda aşağıdaki çıktıyı görürsünüz:
'a' başladı.
'a' 30ms çalıştı
'a' 10ms çalıştı
'a' 20ms çalıştı
'b' başladı.
'b' 75ms çalıştı
'b' 10ms çalıştı
'b' 15ms çalıştı
'b' 350ms çalıştı
'a' bitti.
17-5 numaralı listede iki URL’yi yarıştırmak için trpl::select kullanmıştık.
Burada da select, a biter bitmez tamamlanıyor. Ama iki future içindeki
slow çağrıları birbirine karışmıyor. a future’ı, trpl::sleep noktasına
gelene kadar bütün işini yapıyor; sonra b kendi trpl::sleep noktasına kadar
çalışıyor; ardından a tamamen bitiyor. Her iki future’ın da ağır işleri
arasında ilerleme kaydedebilmesi için await noktalarına ihtiyacımız var.
Yani await edebileceğimiz bir şeye ihtiyacımız var!
17-15’te bunu kısmen zaten görüyoruz: a future’ının sonundaki trpl::sleep
çağrısını kaldırırsanız, b hiç çalışmadan a tamamlanır. O halde ilerlemeyi
parçalara bölmek için şimdilik trpl::sleep kullanmayı deneyelim; 17-16
numaralı liste bunu gösteriyor.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let bir_ms = Duration::from_millis(1);
let a = async {
println!("'a' başladı.");
slow("a", 30);
trpl::sleep(bir_ms).await;
slow("a", 10);
trpl::sleep(bir_ms).await;
slow("a", 20);
trpl::sleep(bir_ms).await;
println!("'a' bitti.");
};
let b = async {
println!("'b' başladı.");
slow("b", 75);
trpl::sleep(bir_ms).await;
slow("b", 10);
trpl::sleep(bir_ms).await;
slow("b", 15);
trpl::sleep(bir_ms).await;
slow("b", 350);
trpl::sleep(bir_ms).await;
println!("'b' bitti.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' {ms}ms çalıştı");
}trpl::sleep kullanmakHer slow çağrısının arasına trpl::sleep ve bir await noktası ekledik.
Böylece iki future’ın işi iç içe geçiyor:
'a' başladı.
'a' 30ms çalıştı
'b' başladı.
'b' 75ms çalıştı
'a' 10ms çalıştı
'b' 10ms çalıştı
'a' 20ms çalıştı
'b' 15ms çalıştı
'a' bitti.
a hâlâ ilk trpl::sleep çağrısına kadar biraz önden gidiyor; çünkü ilk
slow çalışmadan önce hiç await etmiyor. Ama ondan sonra iki future, her
await noktasında sırayla denetim değiştiriyor. İşi istediğimiz anlamlı
parçalara bölmek tamamen bize kalmış.
Aslında burada uyumak istemiyoruz; olabildiğince hızlı ilerlemek istiyoruz.
Tek ihtiyacımız çalışma zamanına denetimi geri vermek. Bunun için doğrudan
trpl::yield_now kullanabiliriz. 17-17 numaralı listede bütün trpl::sleep
çağrılarını bununla değiştiriyoruz.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' başladı.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' bitti.");
};
let b = async {
println!("'b' başladı.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' bitti.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' {ms}ms çalıştı");
}yield_now kullanmakBu sürüm hem niyetimizi daha açık anlatır hem de çoğu zaman sleep
kullanmaktan daha hızlıdır. Çünkü sleep’in dayandığı zamanlayıcıların çözünürlüğü
çoğu zaman sınırlıdır. Kullandığımız sleep sürümü örneğin bir nanosaniye
verseniz bile en az bir milisaniye uyur. Modern bilgisayarlar için bir
milisaniye çok uzundur.
Bu da async’in, programın başka neler yaptığına bağlı olarak, CPU-bağımlı
işlerde bile yararlı olabileceğini gösterir. Çünkü kodun farklı parçaları
arasındaki ilişkiyi kurmak için kullanışlı bir yapı sağlar. Bunun bedeli,
async durum makinesinin ek maliyetidir. Bu yaklaşım, işbirlikli çoklu görev
biçimidir: her future, await noktaları sayesinde denetimi ne zaman teslim
edeceğine kendi karar verir. Dolayısıyla çok uzun süre bloklamamak da onun
sorumluluğudur.
Gerçek dünyada elbette her fonksiyon çağrısının arasına bir await koymazsınız.
Bu biçimde denetim devretmek ucuzdur ama bedelsiz değildir. Bazı durumlarda
CPU-bağımlı işi küçük parçalara bölmek genel performansı düşürebilir. Yine de
beklediğiniz eşzamanlılığın neden seri çalıştığını anlamak için bu dinamiği
akılda tutmak önemlidir.
Kendi Async Soyutlamalarımızı Kurmak
Future’ları birleştirerek yeni desenler de oluşturabiliriz. Örneğin elimizdeki
async yapı taşlarıyla bir timeout fonksiyonu kurabiliriz. Bu bittiğinde, o da
başka async soyutlamalar oluşturmakta kullanabileceğimiz yeni bir yapı taşı
haline gelir.
17-18 numaralı liste, bu hayali timeout fonksiyonunun yavaş bir future ile
nasıl davranmasını beklediğimizi gösteriyor.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let yavas = async {
trpl::sleep(Duration::from_secs(5)).await;
"Sonunda bitti"
};
match timeout(yavas, Duration::from_secs(2)).await {
Ok(message) => println!("'{message}' ile başarılı oldu"),
Err(duration) => {
println!("{} saniye sonra başarısız oldu", duration.as_secs())
}
}
});
}timeout kullanımıŞimdi bunu gerçekten yazalım. Önce API’yi düşünelim:
- Kendisi de async fonksiyon olmalı ki onu
awaitedebilelim. - İlk parametresi çalıştırılacak bir future olmalı.
- İkinci parametre beklenecek azami süre olmalı. Bunun için
Durationkullanmak en elverişli yol. - Dönüş türü
Resultolmalı. Future zamanında tamamlanırsaOk, süre dolarsaErrdönmeli.
17-19 numaralı liste bu imzayı gösteriyor.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let yavas = async {
trpl::sleep(Duration::from_secs(5)).await;
"Sonunda bitti"
};
match timeout(yavas, Duration::from_secs(2)).await {
Ok(message) => println!("'{message}' ile başarılı oldu"),
Err(duration) => {
println!("{} saniye sonra başarısız oldu", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
denecek_gelecek: F,
azami_sure: Duration,
) -> Result<F::Output, Duration> {
// Uygulamamiz buraya gelecek!
}timeout imzasını tanımlamakTürler tamam. Şimdi davranışı düşünelim: Parametre olarak gelen future ile
süreyi yarıştırmak istiyoruz. Süreden bir zamanlayıcı future üretmek için
trpl::sleep, ikisini yarıştırmak için de trpl::select kullanabiliriz.
17-20 numaralı listede timeout, trpl::select sonucunu eşleştirerek
gerçekleniyor.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// --snip--
fn main() {
trpl::block_on(async {
let yavas = async {
trpl::sleep(Duration::from_secs(5)).await;
"Sonunda bitti"
};
match timeout(yavas, Duration::from_secs(2)).await {
Ok(message) => println!("'{message}' ile başarılı oldu"),
Err(duration) => {
println!("{} saniye sonra başarısız oldu", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
denecek_gelecek: F,
azami_sure: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(denecek_gelecek, trpl::sleep(azami_sure)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(azami_sure),
}
}select ve sleep ile timeout tanımlamaktrpl::select uygulaması adil değildir; argümanları geçtiğiniz sırayla yoklar.
Bu yüzden denecek_gelecek değerini ilk argüman olarak veriyoruz; böylece
azami_sure çok kısa olsa bile ana future’ın önce bir şansı olur. Eğer
denecek_gelecek önce biterse select, Left ile onun çıktısını döndürür.
Zamanlayıcı önce biterse Right ile () döner.
Eğer ana future başarıyla tamamlandıysa Ok(output) döndürürüz. Süre önce
dolduysa Right(()) içindeki () değerini yok sayıp Err(azami_sure)
döndürürüz.
Böylece başka iki async yardımcıdan yararlanarak çalışan bir timeout elde
ettik. Kodu çalıştırdığımızda zaman aşımı nedeniyle başarısız çıktıyı görürüz:
2 saniye sonra başarısız oldu
Future’lar başka future’larla birleştirilebildiği için, küçük async yapı taşlarından çok güçlü araçlar kurabilirsiniz. Örneğin aynı yaklaşımı zaman aşımı ile yeniden denemeyi birleştirmek için kullanabilir, sonra bunu ağ çağrıları gibi işlemlere uygulayabilirsiniz.
Pratikte çoğu zaman doğrudan async ile await kullanır, ikinci adımda da
select gibi fonksiyonlar veya join! gibi makrolarla en dıştaki future’ların
nasıl yürütüleceğini kontrol edersiniz.
Şimdiye kadar aynı anda birden fazla future ile çalışmanın farklı yollarını gördük. Sırada, zaman içinde art arda gelen çok sayıda future-benzeri öğeyi akışlar ile ele almak var.
Akışlar (Streams): Sıralı Future'lar
Akışlar: Sırayla Gelen Future’lar
Bu bölümün başlarında, “Mesaj İletimi”
kısmında eşzamansız kanalın alıcı tarafını nasıl kullandığımızı hatırlayın.
recv metodu zaman içinde öğeler üreten eşzamansız bir dizi sağlar. Bu, daha
genel bir desen olan akış (stream) kavramının özel bir örneğidir. Kuyrukta
öğe belirmesi, çok büyük verilerin dosya sisteminden parça parça çekilmesi ya
da ağdan zaman içinde veri gelmesi gibi birçok şey doğal olarak akış olarak
ifade edilir. Akışlar future benzeri yapılar olduğu için, onları başka
future’larla birlikte kullanabilir ve ilginç biçimlerde birleştirebiliriz.
Örneğin çok fazla ağ çağrısı yapmamak için olayları gruplayabilir, uzun süren
iş dizilerine zaman aşımı ekleyebilir ya da kullanıcı arayüzü olaylarını gereksiz
iş yapmamak için seyreltebiliriz.
- bölümde
Iteratortrait’ini incelerken de bir öğe dizisi görmüştük; ama yineleyiciler ile eşzamansız kanal alıcısı arasında iki temel fark vardır. Birincisi zamandır: yineleyiciler senkron, kanal alıcısı ise eşzamansızdır. İkincisi API’dir.Iteratorile doğrudan çalışırken senkronnextmetodunu çağırırız. Özellikletrpl::Receiverakışında ise eşzamansızrecvmetodunu kullandık. Bunun dışında his olarak oldukça benzerler ve bu benzerlik tesadüf değildir. Akış, yinelemenin eşzamansız biçimi gibidir.trpl::Receiverözellikle mesaj bekler; ama genel amaçlı akış API’si daha geniştir:Iteratorgibi sıradaki öğeyi verir, yalnız bunu eşzamansız yapar.
Rust’ta yineleyiciler ile akışlar arasındaki bu yakınlık sayesinde, aslında her
hangi bir yineleyiciden akış üretebiliriz. Yineleyicide olduğu gibi akışla da
next metodunu çağırıp sonucu await ederek çalışırız. 17-21 numaralı liste
bunu gösteriyor; fakat bu hali henüz derlenmez.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let degerler = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let yineleyici = degerler.iter().map(|n| n * 2);
let mut akis = trpl::stream_from_iter(yineleyici);
while let Some(value) = akis.next().await {
println!("Değer şuydu: {value}");
}
});
}Önce sayı dizisinden bir array oluşturuyor, bunu yineleyiciye çeviriyor ve
map ile değerleri iki katına çıkarıyoruz. Ardından trpl::stream_from_iter
fonksiyonuyla yineleyiciyi bir akışa dönüştürüyoruz. Son olarak while let
döngüsüyle, akıştan gelen öğeleri geldikçe işliyoruz.
Ne yazık ki bu kodu çalıştırmayı denediğimizde derlenmiyor ve next metodunun
bulunamadığını söylüyor:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Çıktının anlattığı gibi, derleyici hatasının sebebi next metodunu
kullanabilmek için doğru trait’in kapsamda olmamasıdır. İlk bakışta bunun
Stream trait’i olmasını bekleyebilirsiniz; ama gereken trait aslında
StreamExt’tir. Buradaki Ext, extension yani genişletme anlamına gelir.
Rust topluluğunda, bir trait’i başka bir trait ile genişletmek için sık
kullanılan bir adlandırma biçimidir.
Stream trait’i, Iterator ile Future fikirlerini birleştiren düşük seviyeli
bir arayüz tanımlar. StreamExt ise bunun üstüne, next dahil olmak üzere
Iterator trait’indeki yardımcı metodlara benzeyen daha yüksek seviyeli API’ler
ekler. Bu yazı hazırlanırken Stream ve StreamExt henüz standart
kütüphanenin parçası değil; ama ekosistemdeki çoğu crate benzer tanımlar
kullanır.
Derleyici hatasını düzeltmek için trpl::StreamExt için bir use satırı
eklememiz yeterlidir; 17-22 numaralı liste bunu gösteriyor.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let degerler = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// --snip--
let yineleyici = degerler.iter().map(|n| n * 2);
let mut akis = trpl::stream_from_iter(yineleyici);
while let Some(value) = akis.next().await {
println!("Değer şuydu: {value}");
}
});
}Bu parçalar birleştiğinde kod tam istediğimiz gibi çalışır. Üstelik artık
StreamExt kapsamda olduğu için, akışlarla çalışırken onun sunduğu diğer
yardımcı metodları da yineleyicilerde olduğu gibi kullanabiliriz.
Async Trait'lerine Daha Yakından Bakış
Async İçin Trait’lere Daha Yakından Bakmak
Bölüm boyunca Future, Stream ve StreamExt trait’lerini farklı biçimlerde
kullandık. Çoğu günlük Rust kodu için bunların ayrıntılarına derinlemesine
girmeniz gerekmez. Ama bazen Pin türü ve Unpin trait’i ile birlikte bu
trait’lerin bazı ayrıntılarını anlamanız gerekir. Bu bölümde, tam da o tür
senaryolarda işinize yarayacak kadar derine ineceğiz.
Future Trait’i
Önce Future trait’ine yakından bakalım. Rust onu kabaca şöyle tanımlar:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Bu tanımda birkaç yeni tür ve yeni sözdizimi var. Önce parçaları ayıralım.
İlk olarak Output, future tamamlandığında hangi değerin üretileceğini söyler.
Bu, Iterator trait’indeki Item ile benzer rol oynar. İkinci olarak Future,
özel imzalı bir poll metoduna sahiptir. Bu metod self için Pin<&mut Self>
alır, ayrıca Context türüne değiştirilebilir referans bekler ve
Poll<Self::Output> döndürür.
Şimdilik Pin ve Context ayrıntılarını bir kenara bırakalım; dönüş türü olan
Poll ile başlayalım:
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}Poll, Option’a biraz benzer: değer taşıyan bir varyantı vardır (Ready(T))
ve değer taşımayan bir varyantı vardır (Pending). Ama anlamı başkadır.
Pending, future’ın hâlâ işi olduğunu ve daha sonra yeniden yoklanması
gerektiğini söyler. Ready ise future’ın işini bitirdiğini ve sonucun hazır
olduğunu belirtir.
await kullanan kod gördüğünüzde, Rust bunu perde arkasında poll
çağrılarına çevirir. Örneğin 17-4 numaralı listedeki “sayfa başlığını al”
örneği, kaba bir fikir vermesi açısından aşağıdakine benzer bir koda dönüşür:
match sayfa_basligi(url).poll() {
Ready(baslik) => match baslik {
Some(title) => println!("{url} için başlık {title} idi"),
None => println!("{url} için başlık yoktu"),
},
Pending => {
// Burada daha sonra yeniden denemek gerekir
}
}Eğer future hâlâ Pending ise onu yeniden yoklamamız gerekir. Ama bunu
sonsuz döngüyle körlemesine yapmak istemeyiz; aksi halde await bloklayıcı
hale gelir. Bunun yerine Rust, future hazır değilse denetimi çalışma zamanına
geri verecek şekilde kod üretir. Çalışma zamanı da daha sonra uygun olduğunda
future’ı yeniden poll eder.
17-2 numaralı bölümde alici.recv() çağrısını beklediğimizi görmüştük. recv
bir future döndürür. Çalışma zamanı, poll sonucu Pending ise future’ın
hazır olmadığını anlar; Ready(Some(message)) ya da Ready(None) döndüğünde
ise ilerleyebileceğini bilir.
Pin Türü ve Unpin Trait’i
17-13 numaralı listede trpl::join! ile üç future’ı beklemiştik. Ama bazen
çalışma zamanında sayısı belli olacak bir future koleksiyonuyla uğraşırız.
17-23 numaralı listedeki kod, üç future’ı bir vektöre koyup trpl::join_all
çağırmayı deniyor; ama bu haliyle derlenmiyor.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let gonderici1 = gonderici.clone();
let gonderici1_gelecegi = async move {
let degerler = vec![
String::from("merhaba"),
String::from("-den"),
String::from("gelecek"),
String::from("icinden"),
];
for deger in degerler {
gonderici1.send(deger).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let alici_gelecegi = async {
while let Some(value) = alici.recv().await {
println!("alındı '{value}'");
}
};
let gonderici_gelecegi = async move {
// --snip--
let degerler = vec![
String::from("daha"),
String::from("fazla"),
String::from("mesaj"),
String::from("sana"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let gelecekler: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(gonderici1_gelecegi), Box::new(alici_gelecegi), Box::new(gonderici_gelecegi)];
trpl::join_all(gelecekler).await;
});
}Her future’ı Box içine koyuyoruz; böylece onları trait nesnesi haline
getiriyoruz. Bunun faydası şu: async blokların her biri farklı adsız türler
üretse de, hepsi Future<Output = ()> uyguladığı için hepsini aynı koleksiyona
koyabiliyoruz.
Yine de kod derlenmiyor. Hata mesajının özeti şu:
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
...
= note: consider using the `pin!` macro
Mesaj bize pin! makrosunu kullanmamızı söylüyor. Yani değerleri Pin içine
alarak bellekte taşınamayacaklarını garanti etmemiz gerekiyor. Çünkü burada
dyn Future<Output = ()> türü Unpin uygulamıyor.
Bu ilk bakışta garip görünebilir. Doğrudan await ederken böyle bir şey
gerekmemişti. Sebebi şu: await, future’ı örtük biçimde pin’ler. Ama burada
future’ı doğrudan beklemiyoruz; önce onları başka bir future oluşturan
join_all içine veriyoruz. join_all ise koleksiyon içindeki her öğenin
uygun future olmasını bekliyor ve Box<T> ancak T, gerektiğinde pinlenip
güvenle taşınabiliyorsa bu şartı sağlayabiliyor.
Future trait’indeki poll metoduna yeniden bakarsanız sebebi görünür:
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;Future’ı poll etmek için self üzerinde Pin<&mut Self> gerekiyor. Yani
future’ın bellekteki yerinin sabit olduğuna dair garanti verilmesi lazım.
Bu neden gerekli? Çünkü bölüm boyunca söylediğimiz gibi, await noktaları
derleme sırasında bir durum makinesine dönüşür. Derleyici, bir await
noktasından ötekine kadar hangi verilerin yaşaması gerektiğine bakar ve buna
göre varyantlar üretir. Bazı async bloklarda oluşan bu durum makinesi, kendi
içinde kendisine referanslar taşıyabilir. Böyle türler kendine referanslı
yapılar olur.
Kendine referanslı bir yapıyı bellek içinde taşımak tehlikelidir. Çünkü içindeki
referanslar eski adrese bakmaya devam eder. Bu da geçersiz referanslara ve çok
zor hatalara yol açabilir. Pin, tam burada devreye girer: bir değeri Pin
ile sardığınızda, o değerin artık bellekte taşınmayacağını garanti edersiniz.
Önemli nokta şu: Pin<Box<SomeType>> yazdığınızda aslında sabitlenen şey
Box işaretçisinin kendisi değil, işaret ettiği SomeType değeridir. Box
yine taşınabilir; ama içindeki veri taşınmaz. Bize gereken güvence de tam
olarak budur.
Peki her tür için böyle bir sabitleme gerekli midir? Hayır. Sayılar, bool
değerleri, çoğu Vec ve günlük Rust türü kendi içine referans taşımaz; bunları
taşımak güvenlidir. İşte Unpin trait’i tam burada devreye girer.
Unpin, 16. bölümde gördüğümüz Send ve Sync gibi bir işaretleyici
trait’tir. Kendi başına davranış taşımaz. Yalnızca, “Bu tür için pinleme
güvencesi özel olarak korunmak zorunda değil; gerektiğinde taşınabilir” bilgisini
derleyiciye iletir.
Derleyici, güvenli olduğunu kanıtlayabildiği türler için Unpin’i otomatik
olarak uygular. Yani Unpin normal durumdur; !Unpin ise özel durumdur.
Örneğin String, Pin içine alınabilir; ama zaten Unpin olduğu için
taşınması güvenlidir. Buna karşılık async blokların ürettiği bazı future’lar
Unpin olmayabilir.
Bu yüzden 17-23 numaralı listedeki future’ları açıkça pinlememiz gerekir.
17-24 numaralı liste, her future tanımlandığı yerde pin! kullanarak sorunu
çözer.
extern crate trpl; // required for mdbook test
use std::pin::{Pin, pin};
// --snip--
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (gonderici, mut alici) = trpl::channel();
let gonderici1 = gonderici.clone();
let gonderici1_gelecegi = pin!(async move {
// --snip--
let degerler = vec![
String::from("merhaba"),
String::from("-den"),
String::from("gelecek"),
String::from("icinden"),
];
for deger in degerler {
gonderici1.send(deger).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let alici_gelecegi = pin!(async {
// --snip--
while let Some(value) = alici.recv().await {
println!("alındı '{value}'");
}
});
let gonderici_gelecegi = pin!(async move {
// --snip--
let degerler = vec![
String::from("daha"),
String::from("fazla"),
String::from("mesaj"),
String::from("sana"),
];
for deger in degerler {
gonderici.send(deger).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let gelecekler: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![gonderici1_gelecegi, alici_gelecegi, gonderici_gelecegi];
trpl::join_all(gelecekler).await;
});
}Bu sürüm artık derlenir ve çalışır. Future’ları çalışma zamanında vektöre ekleyip çıkarabilir, sonra da hepsini birlikte bekleyebiliriz.
Pin ve Unpin, günlük uygulama kodundan çok daha alt seviyeli kütüphaneler
veya çalışma zamanı yazarken önemlidir. Ama hata mesajlarında karşınıza
çıktıklarında, artık neye işaret ettiklerini daha iyi biliyorsunuz.
Stream Trait’i
Artık Future, Pin ve Unpin hakkında biraz daha derin fikir sahibi
olduğumuza göre, şimdi Stream trait’ine dönelim. Bölümün önceki kısımlarında
gördüğünüz gibi akışlar, eşzamansız yineleyicilere benzer. Ama Iterator ile
Futureun aksine, bu yazı yazılırken Stream standart kütüphanede yer
almıyor; ekosistemde en yaygın kullanılan tanım futures crate’inden geliyor.
Iterator ile Future tanımlarını bir araya getirerek akışı şöyle düşünebiliriz:
Iterator::next,Option<Self::Item>üretir.Future::poll,Poll<Self::Output>üretir.
Zaman içinde hazır hale gelen bir öğe dizisini ifade etmek için bunları
birleştiren bir Stream trait’i tanımlarız:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
}Stream trait’indeki Item, akışın ürettiği öğelerin türünü belirtir. Bu yönü
ile Iteratora benzer; çünkü sıfır ya da daha fazla öğe üretebilir. Futuredan
ayrıldığı nokta da budur; Future her zaman tek bir Output üretir.
poll_next metodunun dönüş türü olarak Poll<Option<_>> kullanması da çok
anlamlıdır. Dıştaki Poll, öğenin henüz hazır olup olmadığını; içteki Option
ise daha fazla öğe kalıp kalmadığını gösterir.
Bölümde akışlarla çalışırken doğrudan poll_next çağırmadık. Onun yerine
next metodunu ve StreamExt trait’ini kullandık. Çünkü StreamExt, Stream
üstüne daha rahat API’ler ekler. İstersek poll_next çağrılarıyla elle durum
makinesi de yazabilirdik; ama await ile çalışmak çok daha rahattır.
StreamExt içindeki next metodunun bir örneği şöyledir:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
trait StreamExt: Stream {
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// diger metotlar...
}
}StreamExt, akışlarla kullanılabilecek ilginç yardımcı metodların yuvasıdır.
Ekosistemdeki çoğu tür için, bir tür Stream uygularsa StreamExt de otomatik
olarak onun için erişilebilir olur. Bu sayede temel trait sabit kalırken
kullanışlı yardımcı API’ler topluluk tarafından daha hızlı geliştirilebilir.
Kullandığımız trpl sürümünde StreamExt, yalnızca next metodunu tanımlamakla
kalmaz; aynı zamanda Stream::poll_next ayrıntılarını doğru biçimde ele alan
bir varsayılan uygulama da sunar. Bu da şu anlama gelir: kendi akış türünüzü
yazmanız gerekirse yalnızca Stream trait’ini uygulamanız yeterlidir. Sonra o
türü kullanan herkes, StreamExt metodlarını otomatik olarak kullanabilir.
Bu trait’lerin alt seviye ayrıntıları için şimdilik bu kadar yeterli. Bölümü kapatmadan önce future’ların, görevlerin ve iş parçacıklarının nasıl birlikte oturduğunu son kez bir araya getirelim.
Future'lar, Görevler (Tasks) ve Thread'ler
Her Şeyi Birleştirmek: Future, Görev ve İş Parçacığı
- bölümde gördüğümüz gibi, iş parçacıkları eşzamanlılığa yaklaşmanın bir
yolunu sunar. Bu bölümde ise başka bir yol gördük:
async, future ve akışlar. Hangisini ne zaman seçeceğinizi merak ediyorsanız kısa cevap şu: duruma göre. Üstelik çoğu zaman seçim iş parçacıkları veyaasyncdeğil, iş parçacıkları veasyncolur.
Birçok işletim sistemi onlarca yıldır iş parçacığı temelli eşzamanlılık modelleri sunuyor; bu yüzden birçok programlama dili de onları destekliyor. Ama bunun bedelleri var. Pek çok işletim sisteminde her iş parçacığı kayda değer miktarda bellek kullanır. Ayrıca iş parçacıkları yalnızca işletim sistemi ve donanım destekliyorsa mümkündür. Masaüstü ve mobil sistemlerin aksine bazı gömülü sistemlerde işletim sistemi bile yoktur; dolayısıyla iş parçacıkları da yoktur.
async modeli farklı ve sonuçta tamamlayıcı bir ödünleşim seti sunar. async
yaklaşımında eşzamanlı işlemler için ayrı ayrı iş parçacıkları gerekmez.
Bunun yerine işlemler, akışlar bölümünde trpl::spawn_task ile yaptığımız gibi
görevler üstünde çalışabilir. Görev, iş parçacığına benzer; ama onu işletim
sistemi değil, kütüphane düzeyindeki kod, yani çalışma zamanı yönetir.
İş parçacığı başlatma API’leri ile görev başlatma API’lerinin birbirine benzemesinin iyi bir nedeni var. İş parçacıkları, senkron işlem kümeleri için bir sınır görevi görür; eşzamanlılık iş parçacıkları arasında mümkündür. Görevler ise eşzamansız işlem kümeleri için bir sınırdır; eşzamanlılık hem görevler arasında hem de görevlerin içinde mümkündür, çünkü bir görev gövdesindeki future’lar arasında geçiş yapabilir. Son olarak future’lar, Rust’ın en ince taneli eşzamanlılık birimidir ve her future başka future’lardan oluşan bir ağacı temsil edebilir. Çalışma zamanı, daha doğrusu onun yürütücüsü (executor), görevleri yönetir; görevler de future’ları yönetir. Bu yönüyle görevler, işletim sistemi yerine çalışma zamanı tarafından yönetilen hafif iş parçacıkları gibidir.
Bu, async görevlerin her zaman iş parçacıklarından daha iyi olduğu anlamına
gelmez; tersi de doğru değil. İş parçacıklarıyla eşzamanlılık, bazı bakımlardan
async ile eşzamanlılıktan daha basit bir programlama modelidir. Bu hem güçlü
yanı hem de zayıf yanı olabilir. İş parçacıkları çoğu zaman “başlat ve bırak”
gibidir; yerleşik bir future karşılıkları yoktur. İşletim sistemi müdahale
etmedikçe başladıkları işi sonuna kadar götürürler.
Öte yandan iş parçacıkları ile görevler çoğu zaman birlikte çok iyi çalışır;
çünkü bazı çalışma zamanlarında görevler iş parçacıkları arasında taşınabilir.
Hatta bu bölümde kullandığımız çalışma zamanı, spawn_blocking ve spawn_task
işlevleri dahil, varsayılan olarak çok iş parçacıklıdır. Birçok çalışma zamanı,
iş parçacıklarının o anki kullanımına göre görevleri şeffaf biçimde aralarında
taşıyan iş çalma (work stealing) yaklaşımını kullanır. Böylece sistemin genel
performansı iyileşir. Bu yaklaşım, hem iş parçacıklarını hem görevleri hem de
dolayısıyla future’ları birlikte gerektirir.
Hangi yöntemi nerede kullanacağınıza karar verirken şu pratik kuralları akılda tutabilirsiniz:
- İş çok iyi paralelleştirilebiliyorsa yani CPU-bağımlıysa, örneğin büyük bir veri kümesini bağımsız parçalara ayırıp işleyebiliyorsanız, iş parçacıkları daha iyi seçimdir.
- İş çok iyi eşzamanlıysa yani G/Ç-bağımlıysa, örneğin farklı kaynaklardan
farklı hızlarda gelen iletileri ele alıyorsanız,
asyncdaha iyi seçimdir.
Hem paralellik hem eşzamanlılık gerekiyorsa, iş parçacıkları ile async
arasında seçim yapmak zorunda değilsiniz. İkisini rahatça birlikte
kullanabilirsiniz. Böylece her biri en iyi olduğu rolü üstlenir. 17-25 numaralı
liste, gerçek Rust kodunda sık rastlanan böyle bir birleşime örnek gösteriyor.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (gonderici, mut alici) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
gonderici.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = alici.recv().await {
println!("{message}");
}
});
}Önce bir eşzamansız kanal oluşturuyoruz. Sonra kanalın gönderici tarafının
sahipliğini move ile alan bir iş parçacığı başlatıyoruz. İş parçacığının
içinde 1’den 10’a kadar sayıları gönderiyor ve her birinin arasında bir saniye
bekliyoruz. Son olarak, bölüm boyunca yaptığımız gibi trpl::block_on içine
verilen bir async bloktan üretilen future’ı çalıştırıyoruz. Bu future içinde de
diğer mesaj iletimi örneklerinde olduğu gibi iletileri bekliyoruz.
Bölümün başındaki video örneğine geri dönersek, video kodlama görevlerini ayrı bir iş parçacığında çalıştırdığınızı düşünün; çünkü video kodlama CPU-bağımlı bir iştir. Ama bu işlemler bittiğinde kullanıcı arayüzünü bir eşzamansız kanal üzerinden bilgilendirebilirsiniz. Gerçek dünyada bu tür birleşimlerin sayısız örneği vardır.
Özet
Bu kitapta eşzamanlılık konusunu son kez görmüyorsunuz. 21. bölümdeki proje, buradaki küçük örneklerden daha gerçekçi bir senaryoda bu kavramları uygulayacak; ayrıca iş parçacıklarıyla çözüm üretmeyi görevler ve future’larla çözüm üretmeyle daha doğrudan karşılaştıracak.
Hangi yaklaşımı seçerseniz seçin, Rust size güvenli, hızlı ve eşzamanlı kod yazmak için gerekli araçları verir; ister yüksek trafiğe sahip bir web sunucusu yazın, ister gömülü bir işletim sistemi.
Sıradaki bölümde, Rust programları büyüdükçe problemleri modellemenin ve çözümleri düzenlemenin deyimsel yollarını konuşacağız. Ayrıca Rust’ın deyişlerinin nesne yönelimli programlamadan aşina olabileceğiniz kalıplarla nasıl ilişki kurduğunu da ele alacağız.
Nesne Yönelimli Programlama Özellikleri
Nesne yönelimli programlama (object-oriented programming, OOP), programları modellemenin yollarından biridir. Nesne kavramı 1960’larda Simula dilinde ortaya çıktı. Bu nesneler, Alan Kay’in nesnelerin birbirine mesaj gönderdiği programlama mimarisini etkiledi. Kay, 1967’de bu yaklaşımı anlatmak için object-oriented programming terimini ortaya attı. OOP’nin ne olduğu konusunda pek çok farklı tanım vardır. Bu tanımlardan bazılarına göre Rust nesne yönelimlidir, bazılarına göreyse değildir.
Bu bölümde, yaygın biçimde nesne yönelimli kabul edilen bazı özellikleri ele alacağız ve bunların Rust’taki deyimsel karşılıklarına bakacağız. Ardından nesne yönelimli bir tasarım deseninin Rust’ta nasıl uygulanabileceğini gösterecek, sonra da bunu Rust’ın kendi güçlü yanlarını kullanarak kurulmuş alternatif bir çözümle karşılaştıracağız.
Nesne Yönelimli Dillerin Karakteristikleri
Nesne Yönelimli Dillerin Özellikleri
Programlama dünyasında, bir dilin nesne yönelimli sayılması için hangi özelliklere sahip olması gerektiği konusunda tam bir uzlaşma yoktur. Rust, OOP dahil olmak üzere birçok programlama yaklaşımından etkilenmiştir; örneğin 13. bölümde fonksiyonel programlamadan gelen özellikleri görmüştük. Kabaca bakarsak, nesne yönelimli dillerin ortak sayılan bazı özellikleri vardır: nesneler, kapsülleme ve kalıtım. Şimdi bunların ne anlama geldiğine ve Rust’ın bunları destekleyip desteklemediğine bakalım.
Nesneler Veri ve Davranışı Birlikte Taşır
Erich Gamma, Richard Helm, Ralph Johnson ve John Vlissides’in yazdığı, Gang of Four kitabı olarak da anılan Design Patterns: Elements of Reusable Object-Oriented Software, OOP tasarım desenlerini kataloglayan klasik bir kaynak sayılır. Kitap OOP’yi şöyle tanımlar:
Nesne yönelimli programlar nesnelerden oluşur. Bir nesne, hem veriyi hem de o veri üzerinde çalışan yordamları bir araya getirir. Bu yordamlar genellikle metot ya da işlem olarak adlandırılır.
Bu tanıma göre Rust nesne yönelimlidir: struct ve enum’lar veri taşır; impl
blokları da onlara metotlar kazandırır. Rust’ta bunlara doğrudan “nesne”
demesek de, Gang of Four tanımına göre aynı işlevi görürler.
Uygulama Ayrıntılarını Gizleyen Kapsülleme
OOP ile sık ilişkilendirilen başka bir özellik de kapsülleme (encapsulation) fikridir. Bunun anlamı, bir nesnenin uygulama ayrıntılarının o nesneyi kullanan kod tarafından doğrudan erişilebilir olmamasıdır. Yani nesneyle etkileşmenin tek yolu onun açık API’si olur; dışarıdaki kod nesnenin içini eşeleyip veriyi veya davranışı doğrudan değiştiremez. Bunun avantajı, nesneyi kullanan kodu bozmadan iç yapıyı değiştirebilmenizdir.
- bölümde kapsüllemeyi nasıl denetlediğimizi görmüştük:
pubanahtar sözcüğüyle hangi modül, tür, fonksiyon ve metodun açık olacağına karar veririz; geri kalan her şey varsayılan olarak gizlidir. Örneğini32değerlerden oluşan bir vektörü ve bu vektörün ortalamasını tutanOrtalamaliKoleksiyonadlı bir struct tanımlayabiliriz. Böylece her ihtiyaç duyulduğunda ortalamayı yeniden hesaplamak zorunda kalmayız; hesaplanmış değeri önbellekte tutarız.
pub struct OrtalamaliKoleksiyon {
liste: Vec<i32>,
ortalama: f64,
}OrtalamaliKoleksiyon struct’ıStruct pub olarak işaretlenmiştir; böylece başka kodlar onu kullanabilir.
Ama struct içindeki alanlar gizli kalır. Bu burada önemlidir; çünkü listeye
değer eklendiğinde ya da listeden değer çıkarıldığında ortalamanın da güncel
kalmasını istiyoruz. Bunun için struct üstünde ekle, cikar ve ortalama
metotlarını uygularız.
pub struct OrtalamaliKoleksiyon {
liste: Vec<i32>,
ortalama: f64,
}
impl OrtalamaliKoleksiyon {
pub fn ekle(&mut self, deger: i32) {
self.liste.push(deger);
self.ortalamayi_guncelle();
}
pub fn cikar(&mut self) -> Option<i32> {
let sonuc = self.liste.pop();
match sonuc {
Some(deger) => {
self.ortalamayi_guncelle();
Some(deger)
}
None => None,
}
}
pub fn ortalama(&self) -> f64 {
self.ortalama
}
fn ortalamayi_guncelle(&mut self) {
let toplam: i32 = self.liste.iter().sum();
self.ortalama = toplam as f64 / self.liste.len() as f64;
}
}OrtalamaliKoleksiyon üzerindeki açık ekle, cikar ve ortalama metotlarıekle, cikar ve ortalama, OrtalamaliKoleksiyon içindeki veriye erişmenin
veya onu değiştirmenin tek yoludur. ekle ile listeye öğe eklenince ya da
cikar ile çıkarılınca, her iki metot da gizli ortalamayi_guncelle metodunu
çağırarak ortalama alanını günceller.
liste ile ortalama alanlarını gizli bırakarak dışarıdaki kodun liste
alanına doğrudan müdahale etmesini engelleriz. Yoksa liste değişir ama
ortalama senkron kalmayabilir. ortalama metodu ise dışarıdaki kodun
ortalama değerini okuyabilmesini sağlar; ama onu doğrudan değiştirmesine izin
vermez.
Bu kapsülleme sayesinde, gelecekte OrtalamaliKoleksiyon’ın iç yapısını
kolayca değiştirebiliriz. Örneğin liste alanı için Vec<i32> yerine
HashSet<i32> kullanabiliriz. Dış dünyaya açık ekle, cikar ve ortalama
metotlarının imzaları değişmediği sürece, bu türü kullanan kodun değişmesine
gerek kalmazdı.
Eğer bir dilin nesne yönelimli sayılabilmesi için kapsüllemeyi desteklemesi
şartsa, Rust bu koşulu karşılar. Çünkü kodun farklı parçalarında pub
kullanıp kullanmamak, uygulama ayrıntılarını kapsüllemenizi sağlar.
Tür Sistemi ve Kod Paylaşımı Olarak Kalıtım
Kalıtım (inheritance), bir nesnenin başka bir nesnenin tanımından öğeler devralmasıdır. Böylece üst nesnenin verisini ve davranışını tekrar yazmadan kazanır.
Eğer bir dilin nesne yönelimli sayılması için kalıtım şartsa, Rust bu anlamda nesne yönelimli değildir. Bir struct’ın başka bir struct’ın alanlarını ve metotlarını doğrudan miras almasını sağlayan yerleşik bir mekanizma yoktur.
Yine de kalıtımı genelde iki nedenle kullanırsınız. Birincisi kod tekrarını azaltmaktır. Bir tür için tanımladığınız davranışı başka bir türde de yeniden kullanmak istersiniz. Rust’ta bunu sınırlı ölçüde, trait’lerdeki varsayılan metot uygulamalarıyla yapabilirsiniz.
İkinci neden tür sistemidir: bir alt türün, üst türün kullanılabildiği yerlerde kullanılabilmesini istemek. Buna çok biçimlilik (polymorphism) denir.
Çok Biçimlilik
Birçok kişi çok biçimliliği kalıtımla eş anlamlı sanır; ama aslında daha geniş bir kavramdır. Kodun birden fazla türde veriyle çalışabilmesini ifade eder. Kalıtımlı dillerde bu genellikle alt sınıflar üzerinden sağlanır.
Rust bunun yerine jenerikler ve trait sınırları kullanır. Buna bazen sınırlı parametrik çok biçimlilik denir.
Rust, kalıtımı doğrudan sunmayarak farklı bir ödünleşim seçmiştir. Kalıtım çoğu zaman gerekenden fazla kod paylaşımına yol açabilir. Alt türler, üst türün her özelliğini her zaman paylaşmamalıdır; ama kalıtım onları paylaşmaya zorlayabilir. Bu da tasarımı daha az esnek hale getirir.
Bu yüzden Rust, çalışma zamanında çok biçimlilik elde etmek için kalıtım yerine trait nesnelerini kullanır. Şimdi trait nesnelerinin nasıl çalıştığına bakalım.
Ortak Davranışı Soyutlamak İçin Trait Nesnelerini Kullanma
Ortak Davranış Üzerinden Soyutlamak İçin Trait Nesnelerini Kullanmak
- bölümde vektörlerin bir sınırlamasından söz etmiştik: yalnızca tek bir türün öğelerini tutabilirler. Bunu aşmak için, tamsayı, ondalıklı sayı ve metin tutabilen varyantlara sahip bir enum tanımlamıştık. Bu çözüm, değiş tokuş edilebilir türlerin kümesi derleme zamanında sabitse gayet iyidir.
Ama bazen kütüphanemizi kullanan kişinin bu tür kümesini genişletebilmesini
isteriz. Bunu göstermek için, ekrandaki öğelerin listesini dolaşıp her biri
için ciz metodunu çağıran küçük bir grafik arayüz aracı hayal edelim. Bunun
için arayuz adında bir kütüphane crate’i yazacağız. Bu crate Dugme gibi
bazı türler sunabilir. Fakat kullanıcılar kendi türlerini de tanımlamak
isteyecektir; örneğin biri SecimKutusu, bir başkası farklı bir bileşen ekler.
Kütüphaneyi yazarken, ileride herkesin hangi türleri tanımlayacağını bilemeyiz.
Ama şunu biliyoruz: arayuz, farklı türlerden pek çok değeri izleyebilmeli ve
her biri üzerinde ciz metodunu çağırabilmeli. Bize önemli olan, somut türün
ne olduğu değil; bu metodun var olup olmadığıdır.
Kalıtımlı bir dilde bunu yapmak için Component gibi bir üst sınıf tanımlayıp
ona draw metodu verebilir, Dugme, Resim ve SecimKutusu gibi türleri bu
sınıftan türetebilirdik. Rust’ta kalıtım olmadığından, bunu başka bir yolla
kurmamız gerekir.
Ortak Davranış İçin Bir Trait Tanımlamak
Önce Ciz adında, tek metodu ciz olan bir trait tanımlayacağız. Sonra trait
nesnesi alan bir vektör tanımlayacağız. Trait nesnesi, belirli bir trait’i
uygulayan bir türün örneğine ve o tür için trait metodlarını çalışma zamanında
bulmaya yarayan tabloya birlikte işaret eder. Trait nesnesi oluşturmak için
referans veya Box<T> gibi bir işaretçi, ardından dyn anahtar sözcüğü ve
ilgili trait yazılır.
Trait nesnelerini jenerik veya somut tür yerine kullanabiliriz. Nerede trait nesnesi kullanıyorsak, Rust tür sistemi o bağlamda kullanılacak her değerin bu trait’i uyguladığını derleme zamanında garanti eder. Böylece bütün olası türleri önceden bilmemiz gerekmez.
18-3 numaralı liste Ciz trait’ini tanımlar.
pub trait Ciz {
fn ciz(&self);
}Ciz trait’inin tanımıŞimdi Ekran adında, içinde bilesenler vektörü tutan bir struct
tanımlayalım. Bu vektörün türü Vec<Box<dyn Ciz>> olur.
pub trait Ciz {
fn ciz(&self);
}
pub struct Ekran {
pub bilesenler: Vec<Box<dyn Ciz>>,
}bilesenler alanı Ciz trait’ini uygulayan trait nesneleri tutan Ekran struct’ıEkran üzerinde de her bileşen için ciz metodunu çağıran calistir metodunu
tanımlarız.
pub trait Ciz {
fn ciz(&self);
}
pub struct Ekran {
pub bilesenler: Vec<Box<dyn Ciz>>,
}
impl Ekran {
pub fn calistir(&self) {
for bilesen in self.bilesenler.iter() {
bilesen.ciz();
}
}
}ciz metodunu çağıran calistir metoduBu yaklaşım, trait sınırı kullanan jenerik bir struct tanımlamaktan farklıdır. Jenerik kullanırsanız aynı anda yalnızca tek somut türle çalışırsınız. Örneğin 18-6 numaralı listedeki gibi yazsaydık:
pub trait Ciz {
fn ciz(&self);
}
pub struct Ekran<T: Ciz> {
pub bilesenler: Vec<T>,
}
impl<T> Ekran<T>
where
T: Ciz,
{
pub fn calistir(&self) {
for bilesen in self.bilesenler.iter() {
bilesen.ciz();
}
}
}Ekran ve calistir için jenerik ve trait sınırı kullanan alternatif yaklaşımBu durumda bir Ekran örneğindeki bütün bileşenler ya Dugme olurdu ya da tek
başka bir tür olurdu. Yalnızca homojen koleksiyonlarınız varsa jenerikler daha
iyi seçimdir; çünkü derleyici somut türler için monomorfizasyon yapar.
Trait nesneleri kullandığımızdaysa tek bir Ekran, içinde hem Dugme hem de
SecimKutusu gibi farklı türleri aynı anda taşıyabilir.
Trait’i Uygulamak
Şimdi Ciz trait’ini uygulayan türler ekleyelim. Önce Dugme türünü
tanımlayacağız.
pub trait Ciz {
fn ciz(&self);
}
pub struct Ekran {
pub bilesenler: Vec<Box<dyn Ciz>>,
}
impl Ekran {
pub fn calistir(&self) {
for bilesen in self.bilesenler.iter() {
bilesen.ciz();
}
}
}
pub struct Dugme {
pub genislik: u32,
pub yukseklik: u32,
pub etiket: String,
}
impl Ciz for Dugme {
fn ciz(&self) {
// bir dugmeyi gercekten cizmek icin kod
}
}Ciz trait’ini uygulayan Dugme struct’ıDugme içindeki genislik, yukseklik ve etiket alanları, başka
bileşenlerin alanlarından farklı olabilir. Örneğin SecimKutusu da genişlik ve
yükseklik taşırken ek olarak secenekler alanına sahip olabilir. Ekranda
çizilmesini istediğimiz her tür Ciz trait’ini uygular, ama ciz metodu içinde
her tür kendine özgü davranışı tanımlar.
Kütüphanemizi kullanan biri de 18-8 numaralı listedeki gibi kendi
SecimKutusu türünü yazıp Ciz trait’ini uygulayabilir.
use arayuz::Ciz;
struct SecimKutusu {
genislik: u32,
yukseklik: u32,
secenekler: Vec<String>,
}
impl Ciz for SecimKutusu {
fn ciz(&self) {
// bir secim kutusunu gercekten cizmek icin kod
}
}
fn main() {}arayuz crate’ini kullanan başka bir crate’in SecimKutusu için Ciz trait’ini uygulamasıArtık kütüphaneyi kullanan kişi main içinde bir Ekran örneği oluşturabilir.
Bu ekrana hem SecimKutusu hem Dugme ekleyip calistir metodunu çağırdığında,
Ekran her bileşen üzerinde ciz metodunu çağıracaktır.
use arayuz::Ciz;
struct SecimKutusu {
genislik: u32,
yukseklik: u32,
secenekler: Vec<String>,
}
impl Ciz for SecimKutusu {
fn ciz(&self) {
// bir secim kutusunu gercekten cizmek icin kod
}
}
use arayuz::{Dugme, Ekran};
fn main() {
let ekran = Ekran {
bilesenler: vec![
Box::new(SecimKutusu {
genislik: 75,
yukseklik: 10,
secenekler: vec![
String::from("Evet"),
String::from("Belki"),
String::from("Hayir"),
],
}),
Box::new(Dugme {
genislik: 50,
yukseklik: 10,
etiket: String::from("Tamam"),
}),
],
};
ekran.calistir();
}Kütüphaneyi yazarken birilerinin SecimKutusu ekleyeceğini bilmiyorduk. Ama
SecimKutusu, Ciz trait’ini uyguladığı için Ekran onu da problemsiz şekilde
çalıştırabiliyor.
Bu yaklaşım, dinamik dillerdeki ördek tiplemesi fikrine biraz benzer: ördek
gibi yürüyüp ördek gibi ses çıkarıyorsa ördektir. Ekran içindeki calistir
metodu, bileşenin somut türünün Dugme mi SecimKutusu mu olduğunu bilmek
zorunda değildir. Onun için önemli olan, ciz metodunun çağrılabilir olmasıdır.
Trait nesneleri ve Rust’ın tür sistemi sayesinde bunu güvenli biçimde yaparız. Belirli bir metodun var olup olmadığını çalışma zamanında ayrıca sınamamız gerekmez. Eğer değer ilgili trait’i uygulamıyorsa, kod zaten derlenmez.
Örneğin 18-10 numaralı listedeki gibi Ekran içine String koymaya
kalkarsak, String Ciz trait’ini uygulamadığı için derleyici hata verir:
use arayuz::Ekran;
fn main() {
let ekran = Ekran {
bilesenler: vec![Box::new(String::from("Merhaba"))],
};
ekran.calistir();
}error[E0277]: the trait bound `String: Ciz` is not satisfied
--> src/main.rs:5:21
|
5 | bilesenler: vec![Box::new(String::from("Merhaba"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Ciz` is not implemented for `String`
|
= help: the following other types implement trait `Ciz`:
Dugme
= note: required for the cast from `Box<String>` to `Box<dyn Ciz>`
Bu hata bize ya yanlış tür verdiğimizi ya da gerçekten istiyorsak String için
Ciz trait’ini uygulamamız gerektiğini söyler.
Dinamik Dağıtım Yapmak
- bölümde, jenerik kullanan kodların performansını anlatırken monomorfizasyon sürecinden söz etmiştik. Derleyici, jenerik fonksiyonlar ve metotlar için kullandığınız her somut tür adına somut sürümler üretir. Bu şekilde oluşan kod statik dağıtım (static dispatch) yapar; yani hangi metodun çağrılacağı derleme zamanında bellidir.
Buna karşılık dinamik dağıtım (dynamic dispatch) durumunda derleyici, hangi metodun çağrılacağını derleme zamanında bilemez. Gerekli kodu üretir; ama hangi metodun seçileceği çalışma zamanında belli olur.
Trait nesneleri kullandığımızda Rust dinamik dağıtım yapmak zorundadır. Çünkü o kodu hangi türlerin kullanacağını baştan bilemez. Bu yüzden trait nesnesinin içindeki işaretçiler ve tablolar yardımıyla çalışma zamanında doğru metod bulunur.
Bunun bir çalışma zamanı maliyeti vardır. Statik dağıtımda mümkün olan bazı iyileştirmeler dinamik dağıtımda yapılamaz. Yani burada biraz performans karşılığında ek esneklik kazanırız. 18-5’te yazdığımız kod ve 18-9’da sağlayabildiğimiz genişleyebilirlik, bu ödünleşimin ne kazandırdığını gösterir.
Nesne Yönelimli Bir Tasarım Desenini Uygulama
Nesne Yönelimli Bir Tasarım Desenini Uygulamak
Durum deseni (state pattern), nesne yönelimli tasarım desenlerinden biridir. Temel fikir şudur: Bir değerin içsel olarak bulunabileceği bir durum kümesi tanımlanır. Bu durumlar ayrı durum nesneleri ile temsil edilir ve değerin davranışı, içinde bulunduğu duruma göre değişir.
Bir blog gönderisi örneği üstünden gidelim. Gönderinin durumu taslak,
inceleme bekleyen veya yayınlanmış olabilir. İstediğimiz son davranış
şudur:
- Boş bir taslak gönderi oluşturabilmeliyiz.
- Taslak gönderiye metin ekleyebilmeliyiz.
- İnceleme isteyebilmeliyiz.
- Onay verebilmeliyiz.
- Yalnızca yayınlandıktan sonra içerik okunabilmeli.
18-11 numaralı liste, kullanmak istediğimiz API’yi gösteriyor.
use gunce::Gonderi;
fn main() {
let mut post = Gonderi::yeni();
post.metin_ekle("Bugun ogle yemeginde salata yedim");
assert_eq!("", post.icerik());
post.inceleme_iste();
assert_eq!("", post.icerik());
post.onayla();
assert_eq!("Bugun ogle yemeginde salata yedim", post.icerik());
}Bu tür, durum desenini kullanacak. İçinde üç olası durumdan birini temsil eden
bir değer taşıyacak: Taslak, IncelemeBekleyen veya Yayinlanmis.
Durum geçişleri Gonderi türünün içinde yönetilecek; kütüphaneyi kullanan
kişinin bunları doğrudan yönetmesi gerekmeyecek.
Gonderiyi Tanımlamak ve Yeni Bir Örnek Oluşturmak
Önce içerik tutan açık bir Gonderi struct’ı ve onun yeni örneğini oluşturan
ilişkili bir yeni fonksiyonu tanımlayalım. Aynı zamanda, gönderi durumlarının
ortak davranışını belirleyen gizli bir Durum trait’i de tanımlayacağız.
Gonderi, durum adlı gizli alanında Option<Box<dyn Durum>> tutacak.
Option<T> kullanımının neden gerekli olduğunu birazdan göreceğiz.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
}
trait Durum {}
struct Taslak {}
impl Durum for Taslak {}Gonderi struct’ı, yeni örnek üreten yeni fonksiyonu, Durum trait’i ve Taslak struct’ıDurum trait’i, gönderinin farklı durumlarının ortak davranış yüzeyini
belirler. Şimdilik içinde metot yok; önce yalnızca gönderinin başlangıç durumu
olan Taslakı tanımlıyoruz.
Yeni bir Gonderi oluşturduğumuzda, durum alanını Taslak örneğini tutan
bir Box ile Some yapıyoruz. Böylece her yeni gönderi otomatik olarak taslak
başlar. durum alanı gizli olduğu için, dışarıdan başka bir durumda Gonderi
oluşturmak mümkün değildir.
Gönderi İçeriğini Saklamak
18-11 numaralı listedeki kullanıma göre, gönderiye metin eklemek için
metin_ekle adında bir metodumuz olmalı. Bunu doğrudan icerik alanını pub
yaparak değil metod ile sunuyoruz; çünkü birazdan içeriğin hangi koşullarda
okunacağını biz denetlemek isteyeceğiz.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
// --snip--
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
}
trait Durum {}
struct Taslak {}
impl Durum for Taslak {}icerik alanına metin ekleyen metin_ekle metodunu uygulamakmetin_ekle, self için değiştirilebilir referans alır; çünkü gönderiyi
değiştirir. Verilen metni icerik dizgisinin sonuna ekler. Bu davranış gönderi
durumundan bağımsız olduğu için durum deseninin bir parçası değil, Gonderinin
genel API’sinin bir parçasıdır.
Taslak Gönderinin İçeriğinin Boş Görünmesini Sağlamak
metin_ekle ile içerik eklesek bile, gönderi hâlâ taslak durumunda olduğu için
icerik metodunun boş dizgi döndürmesini istiyoruz. Şimdilik en basit
uygulamayla başlayalım: her zaman boş dizgi döndürsün.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
// --snip--
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
pub fn icerik(&self) -> &str {
""
}
}
trait Durum {}
struct Taslak {}
impl Durum for Taslak {}icerik metoduBu haliyle 18-11 numaralı listedeki ilk assert_eq! beklendiği gibi çalışır.
İnceleme İstemek, Yani Gönderi Durumunu Değiştirmek
Sıradaki adım, gönderi için inceleme isteyebilmek. Bu, durumu Taslaktan
IncelemeBekleyene taşımalı.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
// --snip--
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
pub fn icerik(&self) -> &str {
""
}
pub fn inceleme_iste(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.inceleme_iste())
}
}
}
trait Durum {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum>;
}
struct Taslak {}
impl Durum for Taslak {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
Box::new(IncelemeBekleyen {})
}
}
struct IncelemeBekleyen {}
impl Durum for IncelemeBekleyen {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
}Gonderi ve Durum trait’i için inceleme_iste metodunu uygulamakGonderi, inceleme_iste adında açık bir metot alıyor. Bu metot, mevcut duruma
ait iç inceleme_iste metodunu çağırıyor. O iç metot mevcut durumu tüketip yeni
bir durum döndürüyor.
Burada önemli nokta şu: Durum trait’indeki metodun ilk parametresi self,
&self ya da &mut self değil; self: Box<Self>. Bu sayede eski durumun
sahipliğini alıp onu yeni bir duruma dönüştürebiliyoruz.
Tam da bu yüzden Gonderi içindeki durum alanını Option içine koymuştuk.
take çağrısı Some içindeki değeri alıp yerine None bırakır; böylece eski
durumu ödünç almak yerine gerçekten taşıyabiliriz. Sonra alanı yeni durumla
yeniden doldururuz.
Taslak için inceleme_iste, yeni bir IncelemeBekleyen üretir. Buna karşılık
zaten IncelemeBekleyen durumda olan bir gönderide aynı metodu çağırırsanız,
durum değişmeden aynı halde kalır.
onayla Metodunu Ekleyip icerik Davranışını Değiştirmek
onayla metodu da benzer şekilde çalışır: mevcut durum “onaylandığında”
hangi yeni duruma dönüşmesi gerekiyorsa ona geçer.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
// --snip--
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
pub fn icerik(&self) -> &str {
""
}
pub fn inceleme_iste(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.inceleme_iste())
}
}
pub fn onayla(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.onayla())
}
}
}
trait Durum {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum>;
fn onayla(self: Box<Self>) -> Box<dyn Durum>;
}
struct Taslak {}
impl Durum for Taslak {
// --snip--
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
Box::new(IncelemeBekleyen {})
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
self
}
}
struct IncelemeBekleyen {}
impl Durum for IncelemeBekleyen {
// --snip--
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
Box::new(Yayinlanmis {})
}
}
struct Yayinlanmis {}
impl Durum for Yayinlanmis {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
self
}
}Gonderi ve Durum trait’i için onayla metodunu uygulamakArtık Yayinlanmis adında yeni bir durumumuz var. Taslak için onayla
çağrısı etkisizdir ve durumu değiştirmez. IncelemeBekleyen için onayla
çağrısı ise Yayinlanmis duruma geçer. Yayinlanmis durumda hem
inceleme_iste hem onayla çağrıları yine aynı durumu korur.
Şimdi Gonderi::icerik metodunun davranışını gerçek duruma göre belirlemek
istiyoruz. Bunun için Gonderi, içindeki durum nesnesine bu sorumluluğu
devredecek.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
// --snip--
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
pub fn icerik(&self) -> &str {
self.durum.as_ref().unwrap().icerik(self)
}
// --snip--
pub fn inceleme_iste(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.inceleme_iste())
}
}
pub fn onayla(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.onayla())
}
}
}
trait Durum {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum>;
fn onayla(self: Box<Self>) -> Box<dyn Durum>;
}
struct Taslak {}
impl Durum for Taslak {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
Box::new(IncelemeBekleyen {})
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
self
}
}
struct IncelemeBekleyen {}
impl Durum for IncelemeBekleyen {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
Box::new(Yayinlanmis {})
}
}
struct Yayinlanmis {}
impl Durum for Yayinlanmis {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
self
}
}Gonderi::icerik metodunu Durum trait’indeki icerik metoduna devretmekAmaç, icerik ile ilgili bütün kuralları Durum trait’ini uygulayan türlerin
içine toplamaktır. Bunun için Durum trait’ine de bir icerik metodu ekleriz.
pub struct Gonderi {
durum: Option<Box<dyn Durum>>,
icerik: String,
}
impl Gonderi {
pub fn yeni() -> Gonderi {
Gonderi {
durum: Some(Box::new(Taslak {})),
icerik: String::new(),
}
}
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
pub fn icerik(&self) -> &str {
self.durum.as_ref().unwrap().icerik(self)
}
pub fn inceleme_iste(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.inceleme_iste())
}
}
pub fn onayla(&mut self) {
if let Some(s) = self.durum.take() {
self.durum = Some(s.onayla())
}
}
}
trait Durum {
// --snip--
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum>;
fn onayla(self: Box<Self>) -> Box<dyn Durum>;
fn icerik<'a>(&self, post: &'a Gonderi) -> &'a str {
""
}
}
// --snip--
struct Taslak {}
impl Durum for Taslak {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
Box::new(IncelemeBekleyen {})
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
self
}
}
struct IncelemeBekleyen {}
impl Durum for IncelemeBekleyen {
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
Box::new(Yayinlanmis {})
}
}
struct Yayinlanmis {}
impl Durum for Yayinlanmis {
// --snip--
fn inceleme_iste(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn onayla(self: Box<Self>) -> Box<dyn Durum> {
self
}
fn icerik<'a>(&self, post: &'a Gonderi) -> &'a str {
&post.icerik
}
}Durum trait’ine icerik metodunu eklemekBu metot için varsayılan uygulama boş dizgi döndürür. Böylece Taslak ve
IncelemeBekleyen durumlarında ayrıca icerik yazmamıza gerek kalmaz.
Yayinlanmis ise bu varsayılanı geçersiz kılıp gerçek gönderi içeriğini
döndürür.
Bu noktada 18-11 numaralı listedeki bütün davranışlar çalışır. Durum desenini
uygulamış olduk ve kurallar Gonderi içine dağılmak yerine durum nesnelerinin
içinde toplandı.
Neden Enum Değil?
“Durumlar için neden enum kullanmadık?” diye düşünebilirsiniz. Elbette bu da
mümkündür. Ama enum kullandığınızda, her kontrol noktasında bütün varyantları
ele alan match ifadeleri yazmanız gerekir. Bu da bazı durumlarda trait
nesnesi çözümünden daha tekrar eden bir yapıya dönüşebilir.
Durum Deseninin Artılarını ve Eksilerini Değerlendirmek
Bu tasarımın güçlü yanı, Gonderinin farklı durumlardaki davranışlarının
durum nesneleri içinde kapsüllenmesidir. Gonderi metotlarının ya da Gonderi
kullanan kodun, her yerde match ile durumu elle incelemesi gerekmez.
Ama eksileri de vardır. Bir durumun hangi başka duruma geçeceğini yine başka
durumlar bilmek zorundadır; yani durumlar birbirine bir miktar bağlıdır. Örneğin
IncelemeBekleyen ile Yayinlanmis arasına Planlandi gibi yeni bir durum
eklerseniz, IncelemeBekleyen kodunu da değiştirmek gerekir.
Ayrıca biraz tekrar vardır. Gonderi üzerindeki bazı metotlar Option::take
ile durumu çıkarır, karşılık gelen durumsal metodu çağırır ve sonucu tekrar
alan içine koyar. Bu tekrar çok artarsa makro gibi başka araçlar düşünmek
isteyebilirsiniz.
Durumları ve Davranışı Türlerin Kendisi Olarak Kodlamak
Şimdi durum desenini Rust’a daha doğal gelen başka bir yaklaşımla yeniden düşünelim. Bu kez durumları trait nesneleriyle saklamak yerine, doğrudan farklı türler olarak kodlayacağız. Böylece Rust’ın tür denetimi, geçersiz durumları ve geçersiz geçişleri derleme zamanında yakalayabilecek.
18-11 numaralı listedeki kullanımın ilk kısmına tekrar bakalım:
use gunce::Gonderi;
fn main() {
let mut post = Gonderi::yeni();
post.metin_ekle("Bugun ogle yemeginde salata yedim");
assert_eq!("", post.icerik());
post.inceleme_iste();
assert_eq!("", post.icerik());
post.onayla();
assert_eq!("Bugun ogle yemeginde salata yedim", post.icerik());
}Yeni yaklaşımda, gönderi taslakken icerik metodunun hiç olmamasını
sağlayacağız. Böylece taslak gönderinin içeriğini okumaya çalışan kod derleme
hatası alır. 18-19 numaralı liste, Gonderi ile TaslakGonderi türlerini
gösteriyor.
pub struct Gonderi {
icerik: String,
}
pub struct TaslakGonderi {
icerik: String,
}
impl Gonderi {
pub fn yeni() -> TaslakGonderi {
TaslakGonderi {
icerik: String::new(),
}
}
pub fn icerik(&self) -> &str {
&self.icerik
}
}
impl TaslakGonderi {
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
}icerik metoduna sahip Gonderi ile icerik metodu olmayan TaslakGonderiHem Gonderi hem TaslakGonderi içinde gizli icerik alanı vardır. Ama artık
durum alanı yoktur; çünkü durumu struct türünün kendisi ifade eder. Gonderi
yayınlanmış gönderiyi temsil eder. Gonderi::yeni ise Gonderi değil,
TaslakGonderi döndürür. Böylece her gönderi taslak olarak başlamak zorunda
kalır.
TaslakGonderi üstünde metin_ekle vardır; ama icerik yoktur. Yani taslak
gönderinin içeriğini okumaya çalışan kod derlenmez.
Şimdi geçişleri de tür dönüşümleri olarak ifade edelim. TaslakGonderi
üzerindeki inceleme_iste, IncelemeBekleyenGonderi döndürsün; onun üstündeki
onayla da Gonderi döndürsün.
pub struct Gonderi {
icerik: String,
}
pub struct TaslakGonderi {
icerik: String,
}
impl Gonderi {
pub fn yeni() -> TaslakGonderi {
TaslakGonderi {
icerik: String::new(),
}
}
pub fn icerik(&self) -> &str {
&self.icerik
}
}
impl TaslakGonderi {
// --snip--
pub fn metin_ekle(&mut self, text: &str) {
self.icerik.push_str(text);
}
pub fn inceleme_iste(self) -> IncelemeBekleyenGonderi {
IncelemeBekleyenGonderi {
icerik: self.icerik,
}
}
}
pub struct IncelemeBekleyenGonderi {
icerik: String,
}
impl IncelemeBekleyenGonderi {
pub fn onayla(self) -> Gonderi {
Gonderi {
icerik: self.icerik,
}
}
}TaslakGonderi için inceleme_iste, IncelemeBekleyenGonderi için onayla tanımlamakBu metotlar selfin sahipliğini alır; yani eski tür tüketilir ve yerine yeni
durumu temsil eden yeni tür üretilir. Böylece örneğin bir kez incelemeye
gönderdiğiniz taslağı eski haliyle kullanmayı sürdüremezsiniz.
Bu yeni tasarım nedeniyle main içindeki kullanım da biraz değişir. Her geçişte
yeni tür döndüğü için, sonucu tekrar aynı değişken adına bağlamamız gerekir.
use gunce::Gonderi;
fn main() {
let mut post = Gonderi::yeni();
post.metin_ekle("Bugun ogle yemeginde salata yedim");
let post = post.inceleme_iste();
let post = post.onayla();
assert_eq!("Bugun ogle yemeginde salata yedim", post.icerik());
}mainBu sürüm artık klasik nesne yönelimli durum desenini birebir izlemiyor; çünkü
durum geçişleri tamamen Gonderi içinde saklı değil. Ama önemli bir kazanç
sağlıyor: geçersiz durumlar tür sistemi yüzünden artık mümkün değil. Yani
yayınlanmamış gönderinin içeriğini göstermeye çalışan hata türü, üretime
çıkmadan önce derleme sırasında yakalanır.
Özet
Bu bölümün sonunda Rust’ı nesne yönelimli sayıp saymamanızdan bağımsız olarak, Rust’ta trait nesneleriyle bazı nesne yönelimli özellikleri elde edebileceğinizi görmüş oldunuz. Dinamik dağıtım biraz çalışma zamanı maliyeti getirir; ama buna karşılık daha esnek yapılar kurabilirsiniz.
Ayrıca Rust, nesne yönelimli dillerde bulunmayan sahiplik gibi güçlü araçlara da sahiptir. Bu yüzden nesne yönelimli desenler Rust’ta her zaman en iyi çözüm olmayabilir. Yine de gerektiğinde kullanabileceğiniz geçerli bir araç olarak ellerinizin altındadır.
Sıradaki bölümde desenlere bakacağız. Kitap boyunca onlara birkaç kez değindik; ama şimdiye kadar tüm güçlerini görmedik. Şimdi buna geçelim.
Desenler ve Eşleştirme
Desenler, Rust’ta türlerin yapısına karşı eşleştirme yapmayı sağlayan özel bir
sözdizimidir. Basit ya da karmaşık veri yapıları üzerinde aynı fikirle
çalışırlar. Desenleri match ifadeleri ve başka yapılarla birlikte kullanmak,
programın kontrol akışı üzerinde daha ince denetim sağlar. Bir desen şu
parçaların bir birleşiminden oluşabilir:
- Sabit değerler
- Ayrıştırılmış dizi, enum, struct veya demetler
- Değişkenler
- Joker desenler
- Yer tutucular
Örneğin x, (a, 3) ve Some(Renk::Kirmizi) birer desendir. Desenlerin
geçerli olduğu bağlamlarda bu bileşenler, verinin şeklini tarif eder. Program
da bir değeri desenle karşılaştırıp, ilgili kod parçasının çalışmaya devam
edebilmesi için verinin doğru biçimde olup olmadığını belirler.
Bir deseni kullanmak için onu bir değerle karşılaştırırız. Eğer desen değerle
eşleşirse, değerin parçalarını kod içinde kullanabiliriz. 6. bölümde gördüğünüz
match ifadeleri buna örnekti. Değer desenin şekline uyuyorsa, o desende ad
verilmiş parçaları kullanabiliriz. Uymuyorsa o desenle ilişkili kod
çalıştırılmaz.
Bu bölüm, desenlerle ilgili her şey için bir başvuru bölümü niteliğinde. Desenlerin kullanılabildiği yerleri, çürütülebilir ve çürütülemez desenler arasındaki farkı ve görebileceğiniz temel desen sözdizimlerini ele alacağız. Bölümün sonunda, birçok kavramı açık ve güçlü biçimde ifade etmek için desenleri nasıl kullanacağınızı biliyor olacaksınız.
Desenlerin Kullanılabileceği Tüm Yerler
Desenlerin Kullanılabildiği Tüm Yerler
Desenler Rust’ta pek çok yerde karşımıza çıkar ve farkında olmadan onları sıkça kullanmışsınızdır. Bu bölüm, desenlerin geçerli olduğu yerleri tek tek ele alır.
match Kolları
- bölümde konuştuğumuz gibi,
matchifadelerinin kollarında desen kullanırız. Biçimsel olarak birmatchifadesi,matchanahtar sözcüğü, eşleştirilecek bir değer ve her biri bir desen ile o desene uyunca çalışacak ifadeden oluşan bir veya daha fazla koldan oluşur:
match DEGER {
DESEN => IFADE,
DESEN => IFADE,
DESEN => IFADE,
}Örneğin 6. bölümdeki Option<i32> eşleştirmesinde desenler None ve Some(i)
idi. Okun solunda kalan bu kısımlar, her kolun desen kısmıdır.
match ifadelerinin önemli bir şartı, kapsamlı olmalarıdır. Yani match
edilen değer için bütün olasılıklar ele alınmış olmalıdır. Bunu sağlamanın bir
yolu, son kola her şeyi yakalayan bir desen koymaktır. Herhangi bir değerle
eşleşen değişken adı desenleri buna örnek verilebilir.
Özel _ deseni de her şeyle eşleşir; ama hiçbir değeri bağlamaz. Bu yüzden
özellikle son kolda sık kullanılır. _ desenini bölümün ilerleyen kısmında
daha ayrıntılı göreceğiz.
let İfadeleri
Bu bölüme kadar desenlerin match ve if let içinde kullanıldığını açıkça
konuşmuştuk; ama aslında let ifadelerinde de desen kullanıyoruz. Örneğin şu
çok sıradan görünen atama bile bir desen içerir:
#![allow(unused)]
fn main() {
let x = 5;
}Biçimsel olarak bir let ifadesi şöyledir:
let DESEN = IFADE;Buradaki x, “buraya gelen değeri x adına bağla” diyen basit bir desendir.
Desen eşleştirme yönünü daha net görmek için 19-1 numaralı listeye bakalım.
Burada let, bir demeti ayrıştırmak için kullanılıyor.
fn main() {
let (birinci, ikinci, ucuncu) = (1, 2, 3);
}Burada (1, 2, 3) değeri (birinci, ikinci, ucuncu) desenine karşı
eşleştiriliyor. Öğe sayısı aynı olduğu için eşleşme başarılı oluyor ve sırasıyla
1, 2, 3 değerleri bu adlara bağlanıyor.
Eğer desendeki öğe sayısı ile değerdeki öğe sayısı uyuşmazsa, türler de uyuşmaz ve derleyici hata verir. 19-2 numaralı liste bunun başarısız örneğini gösteriyor.
fn main() {
let (birinci, ikinci) = (1, 2, 3);
}Bu kodu derlemeye çalıştığınızda tür hatası alırsınız:
Checking desenler v0.1.0 (/home/hakanbiris/github/kitap/listings/ch19-patterns-and-matching/listing-19-02)
error[E0308]: mismatched types
--> src/main.rs:3:9
|
3 | let (birinci, ikinci) = (1, 2, 3);
| ^^^^^^^^^^^^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `desenler` (bin "desenler") due to 1 previous error
Bu tür durumlarda çözüm ya _ veya .. ile bazı değerleri yok saymak ya da
desendeki değişken sayısını değerin yapısına uygun hale getirmektir.
Koşullu if let İfadeleri
- bölümde
if letyapısını, tek durumu ilgilendiren kısamatchbiçimi olarak görmüştük. İsterseniz bunaelseveyaelse if letkolları da ekleyebilirsiniz.
19-3 numaralı liste, if let, else if, else if let ve else yapılarını
birlikte kullanmanın mümkün olduğunu gösteriyor.
fn main() {
let favori_renk: Option<&str> = None;
let sali_mi = false;
let yas: Result<u8, _> = "34".parse();
if let Some(renk) = favori_renk {
println!("Arka plan olarak favori rengin olan {renk} kullaniliyor");
} else if sali_mi {
println!("Sali gunu yesil gunu!");
} else if let Ok(yas) = yas {
if yas > 30 {
println!("Arka plan rengi olarak mor kullaniliyor");
} else {
println!("Arka plan rengi olarak turuncu kullaniliyor");
}
} else {
println!("Arka plan rengi olarak mavi kullaniliyor");
}
}if let, else if, else if let ve else yapılarını karıştırmakBu kod, birkaç koşula göre arka plan rengini seçiyor. Kullanıcının favori rengi varsa onu kullanıyor. Favori renk yoksa ve bugün salıysa yeşil kullanıyor. Yok, yaş bilgisi dizgi olarak verildiyse ve başarıyla sayıya çevrilebildiyse bu kez yaşa göre mor veya turuncu seçiyor. Bunların hiçbiri yoksa maviye düşüyor.
Bu yapı bize match’ten daha fazla esneklik verir; çünkü tek bir değer üstünde
eşleştirme yapmak zorunda değiliz.
Burada önemli bir ayrıntı da şudur: if let Ok(yas) = yas satırı, dışarıdaki
yas değişkenini gölgeleyen yeni bir yas üretir. Bu yüzden yas > 30
kontrolünü o bloğun içinde yapmak zorundayız.
if let ifadelerinin dezavantajı, derleyicinin kapsamlılık denetimi yapmamasıdır.
Yani son else kolunu unutursanız olası bir mantık hatası hakkında uyarı
almazsınız.
Koşullu while let Döngüleri
if let ile benzer biçimde, while let de desen eşleştiği sürece döngüyü
devam ettirir. 19-4 numaralı listede, bu yapıyı bir kanaldan gelen iletileri
yazdırmak için kullanıyoruz.
fn main() {
let (gonderici, alici) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for deger in [1, 2, 3] {
gonderici.send(deger).unwrap();
}
});
while let Ok(deger) = alici.recv() {
println!("{deger}");
}
}alici.recv() Ok döndürdüğü sürece değerleri yazdırmak için while let kullanmakBu örnek 1, 2 ve 3 yazar. recv, gönderici taraf açık olduğu sürece
Ok(deger) döndürür; gönderici kapandığında ise Err gelir. while let, bu
yapıyı doğal biçimde ifade etmemizi sağlar.
for Döngüleri
for döngüsünde for anahtar sözcüğünden hemen sonra gelen kısım da bir
desendir. Örneğin for x in y ifadesinde x bir desendir. 19-5 numaralı
liste, demeti ayrıştırmak için for içinde desen kullanımını gösteriyor.
fn main() {
let vektor = vec!['a', 'b', 'c'];
for (indeks, deger) in vektor.iter().enumerate() {
println!("{deger}, {indeks}. indekste");
}
}for döngüsünde desen kullanmakBu kod şu çıktıyı üretir:
a, 0. indekste
b, 1. indekste
c, 2. indekste
Burada enumerate, yineleyiciyi (indeks, deger) demetleri üretecek biçimde
uyarlıyor. Desen de bu demeti iki parçaya ayırıp her birini ayrı adla
kullanabilmemizi sağlıyor.
Fonksiyon Parametreleri
Fonksiyon parametreleri de desendir. 19-6 numaralı listedeki foo fonksiyonuna
bakın:
fn bir_fonksiyon(deger: i32) {
// code goes here
}
fn main() {}Buradaki deger de bir desendir. Tıpkı let gibi, fonksiyon parametreleri
yerinde de demet ayrıştırması yapabilirsiniz. 19-7 numaralı liste bunu
gösteriyor.
fn koordinatlari_yazdir(&(x, y): &(i32, i32)) {
println!("Güncel konum: ({x}, {y})");
}
fn main() {
let nokta = (3, 5);
koordinatlari_yazdir(&nokta);
}Bu kod Güncel konum: (3, 5) yazar. &(3, 5) değeri &(x, y) desenine
eşleşir; böylece x ile y sırasıyla 3 ve 5 olur.
Kapanış parametrelerinde de aynı şekilde desen kullanabilirsiniz; çünkü kapanışlar bu açıdan fonksiyonlara benzer.
Bu noktada desenlerin birkaç farklı yerde kullanılabildiğini gördünüz. Ancak her yerde aynı tür desenler kullanılamaz. Bazı yerlerde desenlerin çürütülemez olması gerekir; bazı yerlerde çürütülebilir desenler de kabul edilir. Şimdi buna bakalım.
Çürütülebilirlik (Refutability): Bir Desenin Eşleşmeme İhtimali
Çürütülebilirlik: Bir Desenin Eşleşememe İhtimali
Desenler iki ana biçime ayrılır: çürütülebilir ve çürütülemez. Her olası
değerle eşleşen desenlere çürütülemez denir. Örneğin let x = 5;
ifadesindeki x böyledir; çünkü her şeyle eşleşir. Bazı olası değerlerde
eşleşmesi başarısız olabilen desenler ise _çürütülebilir_desendir. Örneğin
if let Some(x) = bir_deger ifadesindeki Some(x) böyledir; çünkü değer
None olursa desen eşleşmez.
Fonksiyon parametreleri, let ifadeleri ve for döngüleri yalnızca
çürütülemez desen kabul eder. Çünkü eşleşme başarısız olduğunda programın o
bağlamda anlamlı biçimde ne yapacağı belli değildir. if let, while let ve
let...else ise çürütülebilir desenlerle çalışmak için tasarlanmıştır.
Genelde bu ayrımı düşünmeniz gerekmez. Ama hata mesajlarında çürütülebilirlik karşınıza çıkınca, ya deseni ya da onu kullandığınız yapıyı değiştirmeniz gerektiğini anlamanız önemlidir.
Önce, çürütülebilir bir deseni let içinde kullanmaya çalıştığımız bir örneğe
bakalım. 19-8 numaralı liste bunu gösteriyor.
fn main() {
let bir_secenek_degeri: Option<i32> = None;
let Some(x) = bir_secenek_degeri;
}let ile çürütülebilir desen kullanmaya çalışmakEğer bir_secenek_degeri, Some yerine None olsaydı, Some(x) deseni
eşleşemezdi. Ama let yalnızca çürütülemez desen kabul ettiği için derleyici
hata verir:
Checking desenler v0.1.0 (/home/hakanbiris/github/kitap/listings/ch19-patterns-and-matching/listing-19-08)
error[E0005]: refutable pattern in local binding
--> src/main.rs:4:9
|
4 | let Some(x) = bir_secenek_degeri;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let...else` to handle the variant that isn't matched
|
4 | let Some(x) = bir_secenek_degeri else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `desenler` (bin "desenler") due to 1 previous error
Sorun, Some(x) deseninin bütün olasılıkları kapsamamasıdır.
Eğer çürütülebilir bir desene gerçekten ihtiyacımız varsa, let yerine
let...else kullanabiliriz. Böylece desen eşleşmezse süslü parantez içindeki
kod çalışır. 19-9 numaralı liste bunu gösteriyor.
fn main() {
let bir_secenek_degeri: Option<i32> = None;
let Some(x) = bir_secenek_degeri else {
return;
};
}let yerine let...else kullanmakBu biçimde desene bir çıkış yolu vermiş oluruz; desen eşleşmezse else
kolundaki kod devreye girer.
Ama bu kez de ters durum mümkündür: let...else içine zaten her zaman
eşleşecek bir desen koyarsanız, derleyici bunun anlamsız olduğunu söyler.
19-10 numaralı liste buna örnek:
fn main() {
let x = 5 else {
return;
};
}let...else ile çürütülemez desen kullanmaya çalışmakBurada desen her zaman başarılı olduğu için else kolunun hiçbir anlamı kalmaz
ve Rust uyarı verir:
warning: irrefutable `let...else` pattern
--> src/main.rs:3:5
|
3 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: unused variable: `x`
--> src/main.rs:3:9
|
3 | let x = 5 else {
| ^ help: if this is intentional, prefix it with an underscore: `_x`
|
= note: `#[warn(unused_variables)]` (part of `#[warn(unused)]`) on by default
warning: `desenler` (bin "desenler") generated 2 warnings (run `cargo fix --bin "desenler" -p desenler` to apply 1 suggestion)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Bu nedenle match kolları genelde çürütülebilir desenler kullanır; son kol ise
genellikle kalan her şeyi yakalayan çürütülemez bir desen olur.
Artık desenlerin nerede kullanılabileceğini ve çürütülebilirlik ayrımını gördük. Sırada, desen oluştururken kullanabileceğimiz sözdizimlerinin tamamı var.
Desen Sözdizimi
Desen Sözdizimi
Bu bölümde desenlerde geçerli olan temel sözdizimlerini bir araya toplayacağız ve her birinin ne zaman işe yaradığını göreceğiz.
Sabit Değerlerle Eşleşmek
- bölümde gördüğünüz gibi, desenleri sabit değerlerle doğrudan eşleştirebiliriz:
fn main() {
let x = 1;
match x {
1 => println!("bir"),
2 => println!("iki"),
3 => println!("üç"),
_ => println!("herhangi bir şey"),
}
}Bu kod bir yazar; çünkü deger içindeki sayı 1’dir. Belirli somut
değerlere göre farklı davranmak istediğinizde bu sözdizimi çok kullanışlıdır.
Adlandırılmış Değişkenlerle Eşleşmek
Adlandırılmış değişkenler çürütülemez desenlerdir ve her değerle eşleşir.
Kitap boyunca onları çok kullandık. Ama match, if let ve while let
içinde kullanırken dikkat edilmesi gereken bir nokta vardır: Bu yapılar yeni
bir kapsam başlatır. Dolayısıyla desenin içinde tanımlanan değişkenler, dışarıda
aynı ada sahip değişkenleri gölgeler.
19-11 numaralı liste bunun tipik örneğidir.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("50 alındı"),
Some(y) => println!("Eşleşti, y = {y}"),
_ => println!("Varsayılan durum, x = {x:?}"),
}
println!("sonda: x = {x:?}, y = {y}");
}y değişkenini gölgeleyen yeni değişken tanımlayan match koluBurada dışarıda y = 10 vardır. Ama match içindeki Some(y) deseni, dışarıdaki
yyi kullanmaz; yeni bir y üretir. Bu yeni değişken Some içindeki değere
bağlanır. Bu yüzden Some(5) durumunda yazılan çıktı Eşleşti, y = 5 olur;
ama match bittikten sonra dışarıdaki y yine 10 olarak kalır.
Eğer dışarıdaki y ile karşılaştırma yapmak istiyorsak, desen içinde aynı adı
yeniden tanımlamak yerine match guard kullanmamız gerekir. Bunu birazdan
göreceğiz.
Birden Fazla Deseni Eşleştirmek
match içinde | kullanarak birden fazla desen yazabilirsiniz. Bu, desenler
arasında veya anlamına gelir:
fn main() {
let x = 1;
match x {
1 | 2 => println!("bir ya da iki"),
3 => println!("üç"),
_ => println!("herhangi bir şey"),
}
}Bu kod bir ya da iki yazar.
..= ile Değer Aralıklarını Eşleştirmek
..= sözdizimi, kapsayıcı aralıklarla eşleşmemizi sağlar:
fn main() {
let x = 5;
match x {
1..=5 => println!("birden beşe kadar"),
_ => println!("başka bir şey"),
}
}Burada değer 1 ile 5 arasındaysa ilk kol çalışır. Bunu 1 | 2 | 3 | 4 | 5
yerine yazmak çok daha kısadır.
Rust, aralığın boş olup olmadığını yalnızca sayısal türler ve char için
derleme zamanında anlayabildiği için, aralık desenleri yalnız bu türlerle
kullanılabilir. char örneği şöyle görünür:
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("erken ASCII harfi"),
'k'..='z' => println!("geç ASCII harfi"),
_ => println!("başka bir şey"),
}
}Burada 'c', ilk aralığa düştüğü için erken ASCII harfi yazılır.
Ayrıştırarak Değeri Parçalarına Bölmek
Desenleri struct, enum ve demetleri parçalara ayırmak için de kullanabiliriz.
Struct’lar
19-12 numaralı listede, Nokta struct’ının alanlarını let ile ayrı
değişkenlere ayırıyoruz.
struct Nokta {
x: i32,
y: i32,
}
fn main() {
let nokta = Nokta { x: 0, y: 7 };
let Nokta { x: a, y: b } = nokta;
assert_eq!(0, a);
assert_eq!(7, b);
}Burada alan adları ile desen içindeki değişken adları aynı olmak zorunda değildir. Ama sık kullanılan kısa biçimde, aynı adı iki kez yazmadan struct alan adı doğrudan kullanılır. 19-13 numaralı listedeki sürüm aynı işi daha kısa yapar.
struct Nokta {
x: i32,
y: i32,
}
fn main() {
let nokta = Nokta { x: 0, y: 7 };
let Nokta { x, y } = nokta;
assert_eq!(0, x);
assert_eq!(7, y);
}Desenin içinde bazı alanları sabit değerle eşleştirip bazılarını değişkene de bağlayabilirsiniz. 19-14 numaralı liste bunu gösteriyor.
struct Nokta {
x: i32,
y: i32,
}
fn main() {
let nokta = Nokta { x: 0, y: 7 };
match nokta {
Nokta { x, y: 0 } => println!("x ekseni uzerinde: {x}"),
Nokta { x: 0, y } => println!("y ekseni uzerinde: {y}"),
Nokta { x, y } => {
println!("Hicbir eksen uzerinde degil: ({x}, {y})");
}
}
}Burada noktanın x ekseni üzerinde, y ekseni üzerinde ya da hiçbir eksende
olmaması farklı kollarda ele alınıyor.
Enum’lar
Kitap boyunca enum ayrıştırması yaptık; ama şimdi bunu açıkça adlandırıyoruz.
Bir enum varyantını ayrıştıran desen, o varyantın nasıl tanımlandığına karşılık
gelir. 19-15 numaralı listede Mesaj enum’u üzerinde bunu görüyoruz.
enum Mesaj {
Cik,
Tasi { x: i32, y: i32 },
Yaz(String),
RenkDegistir(i32, i32, i32),
}
fn main() {
let mesaj = Mesaj::RenkDegistir(0, 160, 255);
match mesaj {
Mesaj::Cik => {
println!("Çık varyantında ayrışacak veri yok.");
}
Mesaj::Tasi { x, y } => {
println!("x yönünde {x}, y yönünde {y} taşı");
}
Mesaj::Yaz(text) => {
println!("Metin mesajı: {text}");
}
Mesaj::RenkDegistir(r, g, b) => {
println!("Rengi kırmızı {r}, yeşil {g}, mavi {b} olarak değiştir");
}
}
}Cik gibi veri taşımayan varyantlarda daha fazla ayrıştırma yapamayız.
Struct benzeri varyantlarda süslü parantezli, demet benzeri varyantlarda ise
demet desenlerine benzeyen sözdizimi kullanırız.
İç İçe Geçmiş Struct ve Enum’lar
Desenler bir seviyeden daha derine de inebilir. 19-16 numaralı listede Mesaj
içindeki Renk enum’unu ayrıştırıyoruz.
enum Renk {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Mesaj {
Cik,
Tasi { x: i32, y: i32 },
Yaz(String),
RenkDegistir(Renk),
}
fn main() {
let mesaj = Mesaj::RenkDegistir(Renk::Hsv(0, 160, 255));
match mesaj {
Mesaj::RenkDegistir(Renk::Rgb(r, g, b)) => {
println!("Rengi kırmızı {r}, yeşil {g}, mavi {b} olarak değiştir");
}
Mesaj::RenkDegistir(Renk::Hsv(h, s, v)) => {
println!("Rengi ton {h}, doygunluk {s}, değer {v} olarak değiştir");
}
_ => (),
}
}Burada tek bir match içinde hem dış enum varyantını hem de onun içindeki enum
değerini ayırabiliyoruz.
Struct ve Demetleri Karıştırmak
Ayrıştırma desenleri daha da karmaşık biçimde iç içe kullanılabilir:
fn main() {
struct Nokta {
x: i32,
y: i32,
}
let ((ayak, inc), Nokta { x, y }) = ((3, 10), Nokta { x: 3, y: -10 });
}Bu tür desenler, yalnız ilgilendiğiniz parçaları elde edip geri kalanı bir arada bırakmamak için çok kullanışlıdır.
Desende Değerleri Yoksaymak
Bazen desendeki bazı değerler ilgimizi çekmez. Bunun için birkaç yol vardır:
tek başına _, desende iç içe _, başında alt çizgi olan adlar ve ...
Tüm Bir Değeri _ ile Yoksaymak
_, her şeyle eşleşen ama değeri bağlamayan joker desendir. 19-17 numaralı
liste fonksiyon parametresinde kullanımını gösteriyor.
fn bir_fonksiyon(_: i32, y: i32) {
println!("Bu kod yalnızca y parametresini kullanıyor: {y}");
}
fn main() {
bir_fonksiyon(3, 4);
}_ kullanmakBu kod ilk parametreyi tamamen yok sayar ve yalnızca y değerini kullanır.
İç İçe _ ile Değerin Bir Parçasını Yoksaymak
Bir değerin yalnızca bazı parçalarını önemsiyorsanız, _yi başka desenlerin
içinde de kullanabilirsiniz. 19-18 numaralı listedeki örnek bunu gösteriyor.
fn main() {
let mut ayar_degeri = Some(5);
let yeni_ayar_degeri = Some(10);
match (ayar_degeri, yeni_ayar_degeri) {
(Some(_), Some(_)) => {
println!("Var olan özelleştirilmiş değerin üzerine yazılamaz");
}
_ => {
ayar_degeri = yeni_ayar_degeri;
}
}
println!("ayar değeri şu: {ayar_degeri:?}");
}Some içindeki gerçek değeri kullanmadan, yalnızca varyantın kendisiyle eşleşmek için _ kullanmakBurada ayar_degeri ile yeni_ayar_degeri ikisi de Some ise, içlerindeki
gerçek sayıları umursamıyoruz; yalnızca ikisinin de Some olmasını önemsiyoruz.
19-19 numaralı liste ise bir demette birden fazla öğeyi yoksaymayı gösteriyor.
fn main() {
let sayilar = (2, 4, 8, 16, 32);
match sayilar {
(birinci, _, ucuncu, _, besinci) => {
println!("Bazı sayılar: {birinci}, {ucuncu}, {besinci}");
}
}
}Başına _ Koyarak Kullanılmayan Değişkeni Susturmak
Bir değişken oluşturup henüz kullanmıyorsanız Rust normalde uyarı verir.
Ama değişken adını _ ile başlatırsanız bu uyarıyı susturabilirsiniz.
19-20 numaralı liste bunu gösteriyor.
fn main() {
let _x = 5;
let y = 10;
}_ koymakBurada _x için uyarı gelmez, ama y için gelir.
Fakat tek başına _ ile _ad arasında önemli fark vardır: _ad yine de
değeri bağlar; _ ise bağlamaz. Bu fark sahiplik açısından önemlidir.
19-21 numaralı liste bunu gösterir.
fn main() {
let dizgi = Some(String::from("Merhaba!"));
if let Some(_dizgi) = dizgi {
println!("bir dizgi bulundu");
}
println!("{dizgi:?}");
}_ olan kullanılmayan değişken yine de değeri bağlar ve sahipliği alabilirBurada s değeri _s içine taşındığı için daha sonra yeniden kullanılamaz.
Buna karşılık 19-22 numaralı listedeki gibi yalnızca _ kullanırsanız değer
bağlanmaz:
fn main() {
let dizgi = Some(String::from("Merhaba!"));
if let Some(_) = dizgi {
println!("bir dizgi bulundu");
}
println!("{dizgi:?}");
}_ kullanmak değeri bağlamaz.. ile Kalan Parçaları Yoksaymak
Bir değerin pek çok parçası varsa, .. ile kalan her şeyi topluca
yoksayabilirsiniz. 19-23 numaralı liste buna örnektir.
fn main() {
struct Nokta {
x: i32,
y: i32,
z: i32,
}
let koken = Nokta { x: 0, y: 0, z: 0 };
match koken {
Nokta { x, .. } => println!("x su: {x}"),
}
}Nokta içindeki yalnızca x alanını kullanıp geri kalanını .. ile yoksaymakBurada x alanı alınır; y ile z ise .. sayesinde tek tek yazılmadan
yoksayılır.
.., demetlerde de çalışır:
fn main() {
let sayilar = (2, 4, 8, 16, 32);
match sayilar {
(birinci, .., son) => {
println!("Bazı sayılar: {birinci}, {son}");
}
}
}Ama .. kullanımı belirsiz olmamalıdır. 19-25 numaralı listedeki gibi iki
tarafa birden yaymaya çalışırsanız derleyici hangi öğelerin gerçekten
eşleşeceğini anlayamaz:
fn main() {
let sayilar = (2, 4, 8, 16, 32);
match sayilar {
(.., ikinci, ..) => {
println!("Bazı sayılar: {ikinci}")
}
}
}.. sözdizimini belirsiz biçimde kullanma girişimiBu durumda derleme hatası alırsınız:
Checking desenler v0.1.0 (/home/hakanbiris/github/kitap/listings/ch19-patterns-and-matching/listing-19-25)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., ikinci, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `desenler` (bin "desenler") due to 1 previous error
Match Guard ile Ek Koşul Eklemek
Match guard, match kolundaki desenden sonra yazılan ek if koşuludur.
Desen eşleşse bile, kolun seçilebilmesi için bu koşulun da sağlanması gerekir.
19-26 numaralı listede ilk kolun deseni Some(x), guard’ı ise
if x % 2 == 0 koşuludur.
fn main() {
let sayi = Some(4);
match sayi {
Some(x) if x % 2 == 0 => println!("{x} sayısı çifttir"),
Some(x) => println!("{x} sayısı tektir"),
None => (),
}
}Bu örnek 4 sayısı çifttir yazar. Eğer değer Some(5) olsaydı, ilk desen
eşleşse bile guard yanlış olduğu için ikinci kola düşerdi.
Match guard’ın önemli bir kullanımı, gölgelenme sorununu çözmektir.
19-11’de dışarıdaki yyi kullanmak istememize rağmen içteki desen onu
gölgeliyordu. 19-27 numaralı liste, bunu guard ile çözüyor.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("50 alındı"),
Some(n) if n == y => println!("Eşleşti, n = {n}"),
_ => println!("Varsayılan durum, x = {x:?}"),
}
println!("sonda: x = {x:?}, y = {y}");
}Burada Some(n) if n == y deseni, yeni bir n tanımlar; ama dışarıdaki y
aynı kalır. Böylece gerçekten dış y ile karşılaştırma yapabiliriz.
| ile birden fazla deseni bir guard ile birleştirdiğinizde, guard hepsine bir
arada uygulanır. 19-28 numaralı liste bunu gösteriyor.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("evet"),
_ => println!("hayir"),
}
}Buradaki guard, yalnızca 6ya değil, tüm 4 | 5 | 6 grubuna uygulanır.
@ Bağlamaları Kullanmak
@ operatörü, bir değeri hem desene göre sınayıp hem de o anda bir değişkene
bağlamamızı sağlar. 19-29 numaralı liste bunun örneğidir.
fn main() {
enum Mesaj {
Merhaba { id: i32 },
}
let mesaj = Mesaj::Merhaba { id: 5 };
match mesaj {
Mesaj::Merhaba { id: id @ 3..=7 } => {
println!("Aralıkta bir kimlik bulundu: {id}")
}
Mesaj::Merhaba { id: 10..=12 } => {
println!("Başka bir aralıkta kimlik bulundu")
}
Mesaj::Merhaba { id } => println!("Başka bir kimlik bulundu: {id}"),
}
}@ ile değişkene bağlamakBurada id @ 3..=7, id alanının 3..=7 aralığında olup olmadığını test eder
ve eşleşirse aynı değeri id değişkenine bağlar. Böylece hem test hem bağlama
tek desende yapılmış olur.
Özet
Rust’taki desenler, farklı veri biçimlerini ayırt etmede son derece güçlüdür.
match ile kullanıldıklarında Rust, bütün olası değerleri ele almanızı
zorunlu kılar; aksi halde program derlenmez. let ifadeleri ve fonksiyon
parametrelerindeki desenler ise değerleri küçük parçalara ayırıp bu parçaları
ayrı değişkenlere bağlamanızı sağlar.
İhtiyacınıza göre çok basit ya da oldukça karmaşık desenler kurabilirsiniz.
Sıradaki bölümde, kitabın sondan bir önceki durağında, Rust özelliklerinin çeşitli gelişmiş yönlerine bakacağız.
Gelişmiş Özellikler
Buraya kadar Rust programlama dilinin en sık kullanılan kısımlarını öğrendiniz. 21. bölümde son bir proje daha yapmadan önce, ara sıra karşınıza çıkabilecek ama her gün kullanmayacağınız birkaç dil özelliğine bakacağız. Bilmediğiniz bir ayrıntıyla karşılaştığınızda bu bölümü başvuru kaynağı gibi kullanabilirsiniz. Burada ele alınan özellikler çok belirli durumlarda işe yarar. Sık sık eliniz gitmese bile, Rust’ın sunduğu imkânların tamamına genel olarak hâkim olmanızı istiyoruz.
Bu bölümde şunları ele alacağız:
- Güvensiz Rust: Rust’ın bazı garantilerinden bilinçli olarak çıkıp bu garantileri elle koruma sorumluluğunu üstlenmek
- Gelişmiş trait’ler (traits): ilişkili türler, varsayılan tür parametreleri, tam nitelikli sözdizimi, üst trait’ler ve trait’lerle ilişkili olarak newtype deseni
- Gelişmiş türler: newtype deseni hakkında daha fazlası, tür takma adları, never türü ve dinamik boyutlu türler
- Gelişmiş fonksiyonlar ve kapanışlar (closures): fonksiyon işaretçileri ve kapanış döndürme
- Makrolar: derleme zamanında daha fazla kod üreten kod tanımlama yolları
Bu bölüm, herkese hitap eden geniş bir Rust özellikleri seçkisi sunuyor. Haydi başlayalım!
Güvenli Olmayan (Unsafe) Rust
Güvensiz Rust
Şimdiye kadar ele aldığımız bütün kodlarda Rust’ın bellek güvenliği garantileri derleme zamanında uygulanıyordu. Ancak Rust’ın içinde bu garantileri zorunlu kılmayan ikinci bir katman daha vardır: buna güvensiz Rust denir. Güvensiz Rust, normal Rust gibi çalışır; sadece bize bazı ek “süper güçler” verir.
Güvensiz Rust vardır; çünkü doğası gereği statik çözümleme temkinlidir. Derleyici bir kodun garantileri koruyup korumadığını anlamaya çalışırken, bazı geçerli programları reddetmesi bazı geçersiz programları kabul etmesinden daha iyidir. Kod belki doğru olabilir; ama Rust derleyicisinin emin olması için yeterli bilgi yoksa kodu reddeder. İşte böyle durumlarda, güvensiz kodla derleyiciye “Bana güven, ne yaptığımı biliyorum” diyebilirsiniz. Ama bunun riski size aittir: güvensiz kodu yanlış kullanırsanız boş işaretçi çözümleme gibi bellek güvensizliği sorunları oluşabilir.
Rust’ın güvensiz bir alter egosunun olmasının başka bir nedeni de, alttaki bilgisayar donanımının doğası gereği güvenli olmamasıdır. Rust size güvensiz işlemler yapma imkânı vermeseydi bazı işleri yapamazdınız. İşletim sistemiyle doğrudan etkileşmek ya da kendi işletim sisteminizi yazmak gibi düşük seviyeli sistem programlama işleri buna dahildir. Düşük seviyeli sistem programlamayla çalışmak, dilin hedeflerinden biridir. Şimdi güvensiz Rust ile neler yapabildiğimize ve bunları nasıl yaptığımıza bakalım.
Güvensiz Süper Güçleri Kullanmak
Güvensiz Rust’a geçmek için unsafe anahtar kelimesini kullanır ve ardından güvensiz kodu tutacak yeni bir blok başlatırsınız. Güvensiz Rust içinde, güvenli Rust’ta yapamadığınız beş işlem yapabilirsiniz; bunlara güvensiz süper güçler diyoruz:
- Ham işaretçi çözümlemek
- Güvensiz bir fonksiyon ya da metod çağırmak
- Değiştirilebilir statik bir değişkene erişmek veya onu değiştirmek
- Güvensiz bir trait uygulamak
unionalanlarına erişmek
Şunu net anlamak gerekir: unsafe, ödünç alma denetleyicisini kapatmaz ve Rust’ın diğer güvenlik kontrollerini de devre dışı bırakmaz. Güvensiz kodda bir referans kullanırsanız yine denetlenir. unsafe anahtar kelimesi yalnızca, derleyicinin bellek güvenliği açısından denetlemediği bu beş özelliğe erişim verir. Yani unsafe blok içinde de belli bir güvenlik düzeyine sahip olmaya devam edersiniz.
Ayrıca unsafe, blok içindeki kodun mutlaka tehlikeli olduğu veya kesinlikle bellek güvenliği sorunları çıkaracağı anlamına gelmez. Buradaki fikir şudur: programcı olarak siz, unsafe blok içindeki kodun belleğe geçerli biçimde erişmesini sağlarsınız.
İnsan hata yapar; bu kaçınılmazdır. Ama bu beş güvensiz işlemin yalnızca unsafe ile işaretlenmiş blokların içinde yapılmasını zorunlu kıldığınızda, bellek güvenliğiyle ilgili hataların unsafe bloklarda aranması gerektiğini bilirsiniz. unsafe blokları küçük tutun; ileride bellek hatalarını araştırırken buna memnun kalırsınız.
Güvensiz kodu mümkün olduğunca yalıtmak için, bu kodu güvenli bir soyutlamanın içine kapatıp dışarıya güvenli bir API sunmak en iyi yoldur. Bunu birazdan, güvensiz fonksiyonlar ve metodları incelerken göreceğiz. Standart kütüphanenin bazı kısımları da denetlenmiş güvensiz kodların üzerine kurulmuş güvenli soyutlamalar olarak uygulanmıştır. Güvensiz kodu güvenli bir soyutlamanın içine sarmalamak, unsafe kullanımının siz ya da kullanıcılarınız o işlevselliği kullanmak istediğinde her yere yayılmasını engeller; çünkü güvenli soyutlamayı kullanmak güvenlidir.
Şimdi bu beş güvensiz süper gücün her birine sırayla bakalım. Ayrıca güvensiz koda güvenli arayüz sağlayan bazı soyutlamaları da inceleyeceğiz.
Ham İşaretçi Çözümlemek
- bölümdeki [“Sarkan Referanslar”][dangling-references] kısmında, derleyicinin referansların her zaman geçerli olmasını sağladığından söz etmiştik. Güvensiz Rust, referanslara benzeyen ama ham işaretçi denilen iki yeni tür sunar. Referanslarda olduğu gibi ham işaretçiler de değiştirilemez ya da değiştirilebilir olabilir; sırasıyla
*const Tve*mut Tbiçiminde yazılırlar. Buradaki yıldız işareti çözümleme işleci değildir; tür adının bir parçasıdır. Ham işaretçiler bağlamında değiştirilemez demek, işaretçinin çözümlemesinden sonra ona doğrudan atama yapılamaması demektir.
Referans ve akıllı işaretçilerden farklı olarak ham işaretçiler:
- Aynı konuma hem değiştirilemez hem değiştirilebilir işaretçi ya da birden fazla değiştirilebilir işaretçi oluşturarak ödünç alma kurallarını görmezden gelebilir
- Geçerli belleği işaret ettikleri garanti edilmez
- Boş (
null) olabilir - Otomatik temizlik sağlamaz
Rust’ın bu garantileri zorunlu kılmasından çıkıp, bunun karşılığında daha yüksek performans ya da Rust garantilerinin geçerli olmadığı başka bir dil veya donanımla etkileşim kurma imkânı elde edersiniz.
Liste 20-1, değiştirilemez ve değiştirilebilir bir ham işaretçinin nasıl oluşturulduğunu gösteriyor.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}Bu kodda unsafe anahtar kelimesi yok; çünkü ham işaretçileri güvenli kodda oluşturabiliriz. Sadece onları unsafe blok dışında çözümleyemeyiz; birazdan bunu göreceksiniz.
Burada ham ödünç alma işleçlerini kullandık: &raw const num, *const i32 türünde değiştirilemez ham işaretçi; &raw mut num ise *mut i32 türünde değiştirilebilir ham işaretçi oluşturur. Bunları doğrudan yerel bir değişkenden ürettiğimiz için bu belirli ham işaretçilerin geçerli olduğunu biliyoruz; ama bunu her ham işaretçi için varsayamayız.
Bunu göstermek için, geçerliliğinden o kadar da emin olamayacağımız bir ham işaretçi oluşturacağız. Ham ödünç alma işleci yerine, bir değeri dönüştürmek için as anahtar kelimesini kullanacağız. Liste 20-2, bellekte keyfi bir konuma ham işaretçi oluşturmayı gösterir. Keyfi belleği kullanmaya çalışmak tanımsız davranıştır: o adreste veri olabilir de olmayabilir de, derleyici kodu öyle optimize edebilir ki hiç bellek erişimi olmaz, ya da program bölümleme hatasıyla sonlanabilir. Genellikle böyle kod yazmak için iyi bir neden yoktur; özellikle de bunun yerine ham ödünç alma işleci kullanabildiğiniz durumlarda. Yine de mümkündür.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}Ham işaretçileri güvenli kodda oluşturabildiğimizi hatırlayın; ama onları çözümleyip işaret ettikleri veriyi okuyamayız. Liste 20-3’te, bir ham işaretçi üzerinde çözümleme işleci * kullanıyoruz; bu da unsafe blok gerektiriyor.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}unsafe blok içinde ham işaretçileri çözümlemekBir işaretçi oluşturmak tek başına zararlı değildir; risk, onun işaret ettiği değere erişmeye çalıştığımız anda başlar.
Ayrıca Liste 20-1 ve 20-3’te, aynı bellek konumunu işaret eden hem *const i32 hem de *mut i32 ham işaretçileri oluşturduğumuza dikkat edin; bu konum num değerinin saklandığı yerdi. Bunun yerine num için bir değiştirilemez ve bir değiştirilebilir referans oluşturmaya çalışsaydık kod derlenmezdi; çünkü Rust’ın sahiplik kuralları, değiştirilebilir bir referans varken herhangi bir değiştirilemez referansa izin vermez. Ham işaretçilerle ise aynı konuma hem değiştirilebilir hem değiştirilemez işaretçi oluşturabilir ve değiştirilebilir işaretçi üzerinden veriyi değiştirerek veri yarışı yaratabiliriz. Dikkatli olun.
Bütün bu risklere rağmen neden ham işaretçi kullanalım? En önemli kullanım alanlarından biri C koduyla etkileşimdir; bunu bir sonraki kısımda göreceksiniz. Bir diğer kullanım alanı ise ödünç alma denetleyicisinin anlayamadığı güvenli soyutlamalar kurmaktır. Şimdi güvensiz fonksiyonlara geçelim; ardından güvensiz kod kullanan güvenli bir soyutlama örneği göreceğiz.
Güvensiz Fonksiyon ya da Metod Çağırmak
unsafe blok içinde yapabileceğiniz ikinci işlem, güvensiz fonksiyon çağırmaktır. Güvensiz fonksiyon ve metodlar görünüş olarak normal fonksiyon ve metodlarla aynıdır; tek fark, tanımın başında fazladan unsafe bulunmasıdır. Bu bağlamda unsafe, bu fonksiyonu çağırırken bizim korumamız gereken bazı koşullar olduğunu söyler; çünkü Rust bunları yerine getirdiğimizi garanti edemez. Bir güvensiz fonksiyonu unsafe blok içinde çağırdığımızda, “Bu fonksiyonun belgelerini okudum, nasıl kullanılacağını anladım ve sözleşmesini yerine getirme sorumluluğunu üstleniyorum” demiş oluruz.
Gövdesinde hiçbir şey yapmayan dangerous adlı güvensiz bir fonksiyon:
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}dangerous fonksiyonunu ayrı bir unsafe blok içinde çağırmalıyız. unsafe blok olmadan çağırmaya çalışırsak hata alırız:
$ cargo run
Compiling guvensiz-ornek v0.1.0 (file:///projects/guvensiz-ornek)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:5:5
|
5 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `guvensiz-ornek` (bin "guvensiz-ornek") due to 1 previous error
unsafe blok ile Rust’a, fonksiyon belgelerini okuyup doğru kullanımını anladığımızı ve sözleşmesini yerine getirdiğimizi beyan etmiş oluruz.
Bir unsafe fonksiyonun gövdesi içinde güvensiz işlem yaparken de ayrıca unsafe blok kullanmanız gerekir; tıpkı normal fonksiyonda olduğu gibi. Bunu unutursanız derleyici uyarır. Bu da unsafe blokları olabildiğince küçük tutmamıza yardımcı olur.
Güvensiz Kod Üzerine Güvenli Soyutlama Kurmak
Bir fonksiyon içinde güvensiz kod olması, bütün fonksiyonun unsafe olmasını gerektirmez. Hatta güvensiz kodu güvenli bir fonksiyon içine sarmalamak oldukça yaygın bir soyutlamadır. Örnek olarak, standart kütüphanedeki split_at_mut fonksiyonunu inceleyelim; bu fonksiyon biraz güvensiz kod gerektirir. Nasıl uygulanabileceğini görelim. Bu güvenli metod, değiştirilebilir dilimler üzerinde tanımlıdır: bir dilim alır ve verilen indiste onu ikiye böler. Liste 20-4, split_at_mut kullanımını gösteriyor.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}split_at_mut fonksiyonunu kullanmakBu fonksiyonu yalnızca güvenli Rust ile uygulayamıyoruz. Deneysel bir sürüm Liste 20-5’teki gibi olabilir; ama derlenmez. Basitlik için split_at_mut metod değil, fonksiyon olarak; ayrıca jenerik bir T türü yerine yalnızca i32 dilimleri için uygulanmıştır.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut uygulama denemesiBu fonksiyon önce dilimin toplam uzunluğunu alır. Sonra parametre olarak verilen indis değerinin, uzunluğa küçük ya da eşit olup olmadığını denetleyerek dilimin içinde kaldığını doğrular. Bu doğrulama şu anlama gelir: eğer uzunluktan büyük bir indis verirsek, fonksiyon o indisi kullanmaya çalışmadan önce panikler.
Ardından bir demet içinde iki değiştirilebilir dilim döndürürüz: biri orijinal dilimin başından mid indisine kadar, diğeri de mid indisten sona kadar.
Liste 20-5’teki kodu derlemeye çalışırsak hata alırız:
$ cargo check
Checking guvensiz-ornek v0.1.0 (file:///projects/guvensiz-ornek)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:7:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
7 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `guvensiz-ornek` (bin "guvensiz-ornek") due to 1 previous error
Rust’ın ödünç alma denetleyicisi, dilimin farklı parçalarını ödünç aldığımızı anlayamaz; yalnızca aynı dilimden iki kez ödünç aldığımızı görür. Oysa bir dilimin farklı parçalarını ödünç almak temelde güvenlidir; çünkü iki dilim çakışmaz. Rust bunu anlayacak kadar akıllı değildir. Kodun doğru olduğunu bildiğimiz, ama Rust’ın bilemediği durumlarda unsafe devreye girer.
Liste 20-6, split_at_mut uygulamasını çalıştırmak için unsafe blok, ham işaretçi ve bazı güvensiz fonksiyon çağrılarını nasıl kullanacağımızı gösteriyor.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut fonksiyonunun uygulanışında güvensiz kod kullanmak- bölümdeki [“Dilim Türü”][the-slice-type] kısmından hatırlayın: dilim, bir veriye işaretçi ve dilimin uzunluğundan oluşur. Dilimin uzunluğunu
lenile, ham işaretçisini deas_mut_ptrile alıyoruz. Buradai32değerlerinden oluşan değiştirilebilir bir dilimimiz olduğundanas_mut_ptr,*mut i32türünde ham işaretçi döndürür; bunuptrdeğişkeninde tutuyoruz.
mid indeksinin dilim içinde olduğunu doğrulayan assert! çağrısını koruyoruz. Sonra güvensiz koda geçiyoruz: slice::from_raw_parts_mut, bir ham işaretçi ve uzunluk alıp dilim üretir. Bunu, ptr ile başlayan ve mid eleman uzunluğunda bir dilim oluşturmak için kullanıyoruz. Sonra ptr.add(mid) ile mid konumundan başlayan yeni ham işaretçiyi alıp, kalan eleman sayısıyla ikinci dilimi oluşturuyoruz.
slice::from_raw_parts_mut güvensizdir; çünkü kendisine verilen ham işaretçinin geçerli olduğuna güvenmek zorundadır. Ham işaretçilerdeki add metodu da güvensizdir; çünkü ofsetlenmiş konumun da geçerli işaretçi olduğuna güvenir. Bu yüzden bu çağrıları unsafe blok içine koyduk. Koda bakarak ve mid <= len doğrulamasını ekleyerek, unsafe blokta kullanılan tüm ham işaretçilerin dilim içindeki verilere ait geçerli işaretçiler olduğunu görebiliriz. Bu, unsafe için uygun ve kabul edilebilir bir kullanım örneğidir.
Sonuçta oluşan split_at_mut fonksiyonunu unsafe olarak işaretlememiz gerekmez; ayrıca bu fonksiyonu güvenli Rust kodundan çağırabiliriz. Yani güvensiz kodun üzerine güvenli bir soyutlama kurmuş olduk.
Buna karşılık, Liste 20-7’deki slice::from_raw_parts_mut kullanımı büyük olasılıkla dilim kullanıldığında programı çökertir. Bu kod, keyfi bir bellek konumu alıp 10.000 eleman uzunluğunda bir dilim oluşturur.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}Bu keyfi konumdaki belleğe sahip değiliz; ayrıca bu kodun oluşturduğu dilimin geçerli i32 değerleri içerdiğine dair hiçbir garanti yoktur. values değişkenini geçerli dilimmiş gibi kullanmaya çalışmak tanımsız davranış üretir.
Dış Kodu Çağırmak İçin extern Fonksiyonlarını Kullanmak
Bazen Rust kodunuzun başka bir dilde yazılmış kodla etkileşmesi gerekir. Bunun için Rust’ta Yabancı Fonksiyon Arayüzü (Foreign Function Interface, FFI) oluşturmaya ve kullanmaya yarayan extern anahtar kelimesi vardır.
Liste 20-8, C standart kütüphanesindeki abs fonksiyonuyla bütünleşmenin nasıl kurulacağını gösteriyor. extern blokları içinde bildirilen fonksiyonlar genellikle Rust’tan çağrılırken güvensiz sayılır; bu yüzden extern blokları da unsafe olmalıdır. Nedeni basittir: diğer diller Rust’ın kurallarını ve garantilerini uygulamaz, Rust da bunları denetleyemez; dolayısıyla sorumluluk programcıya düşer.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("C'ye gore -3'un mutlak degeri: {}", abs(-3));
}
}extern fonksiyonunu bildirmek ve çağırmakunsafe extern "C" blok içinde, başka bir dilden çağırmak istediğimiz dış fonksiyonların adlarını ve imzalarını yazarız. Buradaki "C" kısmı, dış fonksiyonun kullandığı uygulama ikili arayüzünü (application binary interface, ABI) belirtir. ABI, fonksiyonun assembly düzeyinde nasıl çağrılacağını tanımlar. "C" ABI’si en yaygın olanıdır ve C dilinin ABI’sini izler. Rust’ın desteklediği bütün ABI’ler hakkında bilgi [Rust Reference][ABI] içinde bulunabilir.
unsafe extern blok içinde bildirilen her öğe örtük olarak güvensizdir. Ancak bazı FFI fonksiyonlarını çağırmak gerçekten güvenli olabilir. Örneğin C standart kütüphanesindeki abs fonksiyonunun bellek güvenliğiyle ilgili ek bir şartı yoktur; herhangi bir i32 ile çağrılabilir. Böyle durumlarda, bu özel fonksiyonun güvenle çağrılabildiğini belirtmek için safe anahtar kelimesini kullanabiliriz. Bu değişikliği yaptıktan sonra artık çağrı için unsafe blok gerekmez; bunu Liste 20-9’da görebilirsiniz.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("C'ye gore -3'un mutlak degeri: {}", abs(-3));
}unsafe extern blok içindeki fonksiyonu açıkça safe diye işaretlemek ve güvenle çağırmakBir fonksiyonu safe diye işaretlemek onu sihirli biçimde güvenli yapmaz. Bu, Rust’a verdiğiniz bir söz gibidir. O sözün tutulduğundan emin olmak yine sizin görevinizdir.
Rust Fonksiyonlarını Başka Dillerden Çağırmak
extern ile başka dillerin Rust fonksiyonlarını çağırabileceği bir arayüz de oluşturabiliriz. Bunun için ayrı bir extern blok yazmak yerine, ilgili fn öncesine extern anahtar kelimesi ile kullanılacak ABI’yi ekleriz. Ayrıca Rust derleyicisinin bu fonksiyonun adını değiştirmemesini söylemek için #[unsafe(no_mangle)] açıklamasını eklemeliyiz. Mangling, derleyicinin fonksiyon adını derleme sürecinin diğer kısımları için daha fazla bilgi taşıyan ama insan açısından daha az okunur bir biçime dönüştürmesidir. Her dil derleyicisi bunu biraz farklı yapar. Bir Rust fonksiyonunun diğer dillerce adıyla bulunabilmesi için bu ad değişimini kapatmamız gerekir. Bu da güvensizdir; çünkü yerleşik ad dönüştürmesi olmayınca kütüphaneler arasında ad çakışmaları olabilir. Güvenli bir ad seçmek bizim sorumluluğumuzdur.
Aşağıdaki örnekte call_from_c fonksiyonunu, paylaşılan kütüphane olarak derlenip C tarafından bağlandıktan sonra C koduna açıyoruz:
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Az önce C'den bir Rust fonksiyonu çağrıldı!");
}
Bu extern kullanımında unsafe, extern blok üzerinde değil yalnızca öznitelikte gerekir.
Değiştirilebilir Statik Değişkene Erişmek ya da Onu Değiştirmek
Bu kitapta henüz küresel değişkenlerden söz etmedik. Rust bunları destekler; ama sahiplik kurallarıyla birlikte sorunlu olabilirler. Örneğin iki iş parçacığı aynı değiştirilebilir küresel değişkene erişirse veri yarışı oluşabilir.
Rust’ta küresel değişkenlere statik değişken denir. Liste 20-10, değeri string dilimi olan bir statik değişken bildirimi ve kullanımını gösteriyor.
static HELLO_WORLD: &str = "Hello, Rust!";
fn main() {
println!("deger: {HELLO_WORLD}");
}Statik değişkenler, 3. bölümde sözünü ettiğimiz sabitlere benzer. Ancak adlandırma kuralı gereği statik değişken adları genellikle SCREAMING_SNAKE_CASE ile yazılır. Statik değişkenler yalnızca 'static ömürlü referanslar tutabilir; yani Rust derleyicisi bu ömrü kendi çıkarabilir, bizim ayrıca yazmamız gerekmez. Değiştirilemez statik değişkene erişmek güvenlidir.
Sabitlerle değiştirilemez statik değişkenler arasındaki ince farklardan biri şudur: statik değişkenlerdeki değerlerin bellekte sabit bir adresi vardır. Bu değeri kullanmak her zaman aynı veriye erişir. Sabitler ise kullanıldıkları yerde kopyalanabilir. Bir diğer fark da statik değişkenlerin değiştirilebilir olabilmesidir. Değiştirilebilir statik değişkenlere erişmek ve onları değiştirmek güvensizdir. Liste 20-11, COUNTER adlı değiştirilebilir statik değişkenin nasıl bildirildiğini, erişildiğini ve değiştirildiğini gösteriyor.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling tselams from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: Tselams is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}Normal değişkenlerde olduğu gibi, değiştirilebilirliği mut ile belirtiriz. COUNTER üzerinde okuma veya yazma yapan her kod unsafe blok içinde olmalıdır. Liste 20-11’deki kod tek iş parçacıklı olduğundan derlenir ve beklediğimiz gibi COUNTER: 3 yazdırır. Birden çok iş parçacığının COUNTER’a erişmesi ise veri yarışı üretmeye çok açıktır; bu da tanımsız davranıştır. Bu nedenle fonksiyonun tamamını unsafe işaretleyip güvenlik sınırlamasını belgelememiz gerekir.
Güvensiz bir fonksiyon yazdığımızda, çağıranın güvenle kullanabilmesi için ne yapması gerektiğini açıklayan SAFETY ile başlayan yorumlar yazmak yaygın bir Rust geleneğidir. Aynı şekilde güvensiz bir işlem yaptığımızda da güvenlik kurallarını nasıl koruduğumuzu anlatan SAFETY yorumları yazmak yerleşik bir pratiktir.
Ayrıca derleyici, değiştirilebilir statik değişkene referans oluşturma girişimlerini varsayılan olarak engeller. Bunun için ya #[allow(static_mut_refs)] ile bu lint korumasını açıkça devre dışı bırakmanız ya da ham ödünç alma işleçlerinden biriyle oluşturulmuş ham işaretçi üzerinden erişmeniz gerekir. Buna, burada println! içinde olduğu gibi referansın görünmeden oluşturulduğu durumlar da dahildir. Statik değiştirilebilir değişkenlere referansların ham işaretçi üzerinden oluşturulmasını zorunlu kılmak, güvenlik şartlarını daha görünür hâle getirir.
Genel erişime açık değiştirilebilir veriyle çalışırken veri yarışı olmadığını garanti etmek zordur; bu yüzden Rust değiştirilebilir statik değişkenleri güvensiz kabul eder. Mümkün olduğunda, 16. bölümde ele aldığımız eşzamanlılık tekniklerini ve iş parçacığı güvenli akıllı işaretçileri kullanmak daha iyidir.
Güvensiz Trait Uygulamak
unsafe ile güvensiz bir trait de uygulayabiliriz. Bir trait, derleyicinin doğrulayamadığı en az bir değişmezi varsa güvensizdir. Bir trait’i unsafe ilan etmek için trait öncesine unsafe koyarız ve uygulamasını da unsafe ile işaretleriz. Bunu Liste 20-12’de görebilirsiniz.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}unsafe impl ile, derleyicinin denetleyemediği değişmezleri bizim koruyacağımıza söz vermiş oluruz.
Örnek olarak, 16. bölümdeki [“Send ve Sync ile Genişletilebilir Eşzamanlılık”][send-and-sync] kısmında ele aldığımız Send ve Sync işaretleyici trait’lerini hatırlayın. Türlerimiz yalnızca Send ve Sync uygulayan türlerden oluşuyorsa, derleyici bu trait’leri otomatik uygular. Eğer ham işaretçiler gibi Send ya da Sync uygulamayan bir tür içeren bir yapı tanımlayıp bunu Send veya Sync olarak işaretlemek istersek unsafe kullanmamız gerekir. Rust, türümüzün iş parçacıkları arasında güvenli biçimde gönderilebildiğini ya da birden çok iş parçacığından güvenle erişilebildiğini doğrulayamaz; bu yüzden bu denetimi elle yapıp bunu unsafe ile belirtmemiz gerekir.
union Alanlarına Erişmek
Yalnızca unsafe ile yapılabilen son işlem, bir union alanına erişmektir. union, struct’a benzer; ancak belirli bir anda yalnızca bir bildirilen alanın kullanıldığı varsayılır. union’lar en çok C kodundaki union’larla etkileşim için kullanılır. Rust, union örneğinde o anda hangi tür verinin tutulduğunu garanti edemediği için alan erişimi güvensizdir. union’lar hakkında daha fazla bilgiyi [Rust Reference][unions] içinde bulabilirsiniz.
Güvensiz Kodu Denetlemek İçin Miri Kullanmak
Güvensiz kod yazarken, yazdığınız şeyin gerçekten güvenli ve doğru olup olmadığını denetlemek isteyebilirsiniz. Bunun en iyi yollarından biri Miri kullanmaktır. Miri, tanımsız davranışı saptamak için geliştirilmiş resmî bir Rust aracıdır. Ödünç alma denetleyicisi derleme zamanında çalışan statik bir araçken, Miri çalışma zamanında çalışan dinamik bir araçtır. Programınızı ya da test paketinizi çalıştırıp, Rust’ın çalışma kurallarını ihlal ettiğiniz yerleri yakalar.
Miri kullanmak için Rust’ın nightly sürümü gerekir. Bunu [Ek G: Rust Nasıl Yapılır ve “Nightly Rust”][nightly] kısmında ayrıntılı ele alacağız. Gece sürümü ve Miri aracını rustup +nightly component add miri ile kurabilirsiniz. Bu, projenizin kullandığı Rust sürümünü değiştirmez; yalnızca aracı sisteminize ekler. Bir projede Miri’yi cargo +nightly miri run ya da cargo +nightly miri test ile çalıştırabilirsiniz.
Bunun ne kadar yararlı olabileceğini görmek için, Liste 20-7 üzerinde çalıştırdığımızda ne olduğuna bakalım.
Gelişmiş Trait'ler
Gelişmiş Trait’ler
Trait’leri ilk olarak 10. bölümdeki “Trait’lerle Ortak Davranış Tanımlamak” kısmında ele almıştık; ancak daha ileri ayrıntılara girmemiştik. Artık Rust hakkında daha fazla şey bildiğinize göre, biraz daha derine inebiliriz.
İlişkili Türlerle Trait Tanımlamak
İlişkili türler (associated types), bir trait içindeki yer tutucu türü trait ile bağlar; böylece trait metodlarının imzalarında bu yer tutucu türler kullanılabilir. Trait’i uygulayan taraf, o uygulama için yer tutucu yerine kullanılacak somut türü belirtir. Böylece, bir trait’in bazı türleri kullanacağını söyleyebilir ama trait uygulanana kadar bu türlerin tam olarak ne olacağını bilmek zorunda kalmayız.
Bu bölümde anlattığımız gelişmiş özelliklerin çoğunu “nadiren gerekli” diye tanımladık. İlişkili türler ise ortada bir yerdedir: kitabın geri kalanındaki ana özelliklerden daha az kullanılırlar ama bu bölümdeki bazı diğer özelliklerden daha yaygındırlar.
İlişkili tür kullanan trait’e örnek olarak standart kütüphanedeki Iterator trait’ini verebiliriz. İlişkili türün adı Item’dır ve Iterator trait’ini uygulayan türün yinelediği değerlerin türünü temsil eder. Iterator trait’inin tanımı Liste 20-13’te gösteriliyor.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Item adlı ilişkili tür içeren Iterator trait’inin tanımıBuradaki Item bir yer tutucudur. next metodunun tanımı da Option<Self::Item> döndüreceğini söyler. Iterator trait’ini uygulayan türler Item için somut türü belirler; next de bu somut türden bir değer içeren Option döndürür.
İlişkili türler ilk bakışta jeneriklere benziyormuş gibi görünebilir. Çünkü jenerikler de bir fonksiyonun hangi türlerle çalışacağını belirtmeden tanımlanmasını sağlar. Aradaki farkı görmek için Sayac adlı bir tür üzerinde Iterator uygulamasına bakalım; burada Item türü u32 olarak belirtilmiştir:
struct Sayac {
count: u32,
}
impl Sayac {
fn new() -> Sayac {
Sayac { count: 0 }
}
}
impl Iterator for Sayac {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Bu sözdizimi jeneriklere benzer görünüyor. O hâlde neden Iterator trait’ini doğrudan jeneriklerle tanımlamayalım? Liste 20-14’te bunun varsayımsal bir sürümünü görebilirsiniz.
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Iterator trait’inin jeneriklerle yazılmış varsayımsal tanımıFark şu: jenerik kullandığımızda, Liste 20-14’te olduğu gibi, her uygulamada türleri ayrıca açıklamamız gerekir. Çünkü Sayac için istersek Iterator<String>, istersek başka bir Iterator<T> uygulaması daha yazabiliriz. Yani trait jenerik parametre alıyorsa, aynı trait aynı tür için birden çok kez uygulanabilir; her seferinde jenerik parametrelerin somut türleri değişebilir. Böyle olsaydı, Sayac üzerinde next çağırırken hangi Iterator uygulamasını kastettiğimizi ayrıca belirtmemiz gerekirdi.
İlişkili türlerde buna gerek kalmaz; çünkü aynı trait’i aynı tür için birden fazla kez uygulayamayız. Liste 20-13’te ilişkili tür kullanan tanımda Item türünü yalnızca bir kez seçebiliriz; çünkü Sayac için ancak tek bir impl Iterator yazılabilir. Böylece Sayac üzerinde next çağırdığımız her yerde bunun u32 değerleri döndüren yineleyici olduğunu tekrar tekrar belirtmemiz gerekmez.
İlişkili türler, trait’in sözleşmesinin de bir parçasıdır: trait’i uygulayanlar ilişkili tür yer tutucusuna karşılık gelecek bir tür vermek zorundadır. Bu yüzden ilişkili türlere genellikle kullanımını anlatan anlamlı adlar verilir; API belgelerinde bunları ayrıca açıklamak iyi bir pratiktir.
Varsayılan Jenerik Parametreler ve Operatör Aşırı Yükleme
Jenerik tür parametreleri kullandığımızda, o jenerik tür için varsayılan bir somut tür de belirtebiliriz. Böylece varsayılan tür iş görüyorsa trait’i uygulayanların ayrıca tür belirtmesine gerek kalmaz. Varsayılan türü <YerTutucuTur=SomutTur> sözdizimiyle tanımlarız.
Bu tekniğin faydalı olduğu güzel örneklerden biri operatör aşırı yükleme dir; yani belirli durumlarda bir operatörün (+ gibi) davranışını özelleştirmek.
Rust kendi operatörlerinizi tanımlamanıza ya da rastgele operatörleri aşırı yüklemenize izin vermez. Ancak std::ops içindeki işlemleri ve bunlara karşılık gelen trait’leri uygulayarak özelleştirebilirsiniz. Örneğin Liste 20-15’te iki Nokta örneğini toplamak için + operatörünü aşırı yüklüyoruz. Bunu Nokta struct’ı üzerinde Add trait’ini uygulayarak yapıyoruz.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Nokta {
x: i32,
y: i32,
}
impl Add for Nokta {
type Output = Nokta;
fn add(self, other: Nokta) -> Nokta {
Nokta {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Nokta { x: 1, y: 0 } + Nokta { x: 2, y: 3 },
Nokta { x: 3, y: 3 }
);
}Nokta örnekleri için + operatörünü aşırı yüklemek üzere Add trait’ini uygulamakadd metodu iki Nokta örneğinin x değerlerini ve y değerlerini toplayıp yeni bir Nokta üretir. Add trait’inde Output adlı ilişkili tür vardır; add metodunun döndüreceği türü bu belirler.
Bu örnekteki varsayılan jenerik tür, Add trait’inin tanımı içindedir:
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}Bu kod size tanıdık gelmiş olmalı: tek metodlu, ilişkili tür içeren bir trait. Yeni kısım Rhs=Self ifadesidir. Buna varsayılan tür parametresi denir. Rhs jenerik tür parametresi (“sağ taraf” anlamındaki right-hand side’ın kısaltmasıdır), add metodundaki rhs parametresinin türünü belirler. Add trait’ini uygularken Rhs için somut tür vermezsek Self kullanılır; yani Add’i uyguladığımız türün kendisi.
Nokta için Add uygularken Rhs için varsayılanı kullandık; çünkü iki Nokta toplamak istiyorduk. Şimdi Rhs türünü özelleştirdiğimiz bir örneğe bakalım.
Elimizde farklı birimlerde değer tutan Milimetreler ve Metreler yapıları olduğunu düşünelim. Var olan bir türü başka bir struct ile ince biçimde sarmalama yaklaşımına newtype deseni denir; bunu birazdan daha ayrıntılı ele alacağız. Diyelim ki milimetre cinsinden değerlerle metre cinsinden değerleri toplamak istiyoruz ve Add uygulaması dönüşümü doğru yapsın istiyoruz. Bunun için Milimetreler üzerinde, Rhs türü Metreler olacak şekilde Add uygulayabiliriz; Liste 20-16 bunu gösteriyor.
use std::ops::Add;
struct Milimetreler(u32);
struct Metreler(u32);
impl Add<Metreler> for Milimetreler {
type Output = Milimetreler;
fn add(self, other: Metreler) -> Milimetreler {
Milimetreler(self.0 + (other.0 * 1000))
}
}Milimetreler üzerinde Add uygulayarak Milimetreler ile Metreler toplamakMilimetreler ile Metreler toplayabilmek için impl Add<Metreler> yazarız; böylece Rhs parametresi Self yerine Metreler olur.
Varsayılan tür parametrelerini başlıca iki amaçla kullanırsınız:
- Var olan kodu bozmadan bir türü ya da trait’i genişletmek
- Çoğu kullanıcının ihtiyaç duymayacağı belirli durumlarda özelleştirme imkânı sunmak
Standart kütüphanedeki Add trait’i ikinci amaca güzel örnektir: çoğu zaman aynı türden iki değeri toplarsınız; ama Add gerektiğinde bundan fazlasını da yapabilmenizi sağlar. Add tanımındaki varsayılan tür parametresi sayesinde, çoğu durumda bu ek parametreyi yazmanız gerekmez. Yani biraz fazladan tekrarlayan koddan kurtulmuş olursunuz.
İlk amaç da buna benzer, ama ters yönde işler: var olan bir trait’e yeni tür parametresi eklemek isterseniz buna varsayılan değer vererek trait’in işlevini genişletebilir, mevcut uygulama kodlarını bozmamış olursunuz.
Aynı Adlı Metodlar Arasında Ayrım Yapmak
Rust’ta bir trait’in, başka bir trait’teki metodla aynı adda metod tanımlamasını engelleyen bir kural yoktur. Hatta aynı tür üzerinde bu iki trait’in ikisini birden uygulayabilirsiniz. Ayrıca türün kendisi üzerinde, trait metodlarıyla aynı ada sahip bir metod da tanımlayabilirsiniz.
Aynı isimli metodlar çağrılırken Rust’a hangisini kullanmak istediğinizi söylemeniz gerekir. Liste 20-17’de bunun örneğini görüyoruz: Pilot ve Buyucu adlı iki trait tanımlıyoruz; ikisinde de fly adlı metod var. Sonra her iki trait’i de zaten fly metodu olan Insan türü üzerinde uyguluyoruz. Her fly farklı bir şey yapıyor.
trait Pilot {
fn fly(&self);
}
trait Buyucu {
fn fly(&self);
}
struct Insan;
impl Pilot for Insan {
fn fly(&self) {
println!("Kaptanınız konuşuyor.");
}
}
impl Buyucu for Insan {
fn fly(&self) {
println!("Yukarı!");
}
}
impl Insan {
fn fly(&self) {
println!("*çok selamlı kol çırpıyor*");
}
}
fn main() {}Pilot hem Buyucu içinde fly metodu tanımlanması, bunların Insan üzerinde uygulanması ve Insan üzerinde ayrıca doğrudan fly metodunun bulunmasıBir Insan örneğinde fly çağırdığımızda, derleyici varsayılan olarak türün kendisi üzerinde tanımlı olan metodu seçer. Bunu Liste 20-18’de görebilirsiniz.
trait Pilot {
fn fly(&self);
}
trait Buyucu {
fn fly(&self);
}
struct Insan;
impl Pilot for Insan {
fn fly(&self) {
println!("Kaptanınız konuşuyor.");
}
}
impl Buyucu for Insan {
fn fly(&self) {
println!("Yukarı!");
}
}
impl Insan {
fn fly(&self) {
println!("*çok selamlı kol çırpıyor*");
}
}
fn main() {
let person = Insan;
person.fly();
}Insan örneğinde fly çağırmakBu kod çalıştırıldığında *waving arms furiously* yazdırır; yani Rust, doğrudan Insan üzerinde uygulanmış fly metodunu çağırır.
Pilot veya Buyucu trait’lerindeki fly metodlarını çağırmak için daha açık bir sözdizimi kullanmamız gerekir. Liste 20-19 bunu gösteriyor.
trait Pilot {
fn fly(&self);
}
trait Buyucu {
fn fly(&self);
}
struct Insan;
impl Pilot for Insan {
fn fly(&self) {
println!("Kaptanınız konuşuyor.");
}
}
impl Buyucu for Insan {
fn fly(&self) {
println!("Yukarı!");
}
}
impl Insan {
fn fly(&self) {
println!("*çok selamlı kol çırpıyor*");
}
}
fn main() {
let person = Insan;
Pilot::fly(&person);
Buyucu::fly(&person);
person.fly();
}fly metodunu çağırmak istediğimizi açıkça belirtmekMetod adından önce trait adını yazmak, Rust’a hangi fly uygulamasını istediğimizi açıkça söyler. İstersek Insan::fly(&person) da yazabilirdik; bu, person.fly() ile eşdeğerdir. Ama ayrım yapmaya ihtiyacımız yoksa daha uzundur.
Bu kodun çıktısı şöyledir:
Kaptanınız konuşuyor.
Yukarı!
*çok selamlı kol çırpıyor*
fly metodu self parametresi aldığı için, aynı trait’i uygulayan iki farklı tür olsa bile Rust self türüne bakarak hangi uygulamanın kullanılacağını anlayabilir.
Ama metod olmayan ilişkili fonksiyonlarda self parametresi yoktur. Aynı adlı metod olmayan fonksiyonları birden fazla tür ya da trait tanımladığında, tam nitelikli sözdizimi kullanmazsanız Rust her zaman neyi kastettiğinizi anlayamaz. Örneğin Liste 20-20’de, bir hayvan barınağının bütün yavru köpeklere Karabaş adını vermek istediğini düşünelim. Hayvan adlı bir trait oluşturuyoruz; burada metod olmayan ilişkili fonksiyon baby_name var. Kopek struct’ı bu trait’i uyguluyor; ayrıca Kopek üzerinde doğrudan yine baby_name adlı bir ilişkili fonksiyon tanımlıyoruz.
trait Hayvan {
fn baby_name() -> String;
}
struct Kopek;
impl Kopek {
fn baby_name() -> String {
String::from("Karabaş")
}
}
impl Hayvan for Kopek {
fn baby_name() -> String {
String::from("yavru köpek")
}
}
fn main() {
println!("Bir yavru köpeğe {}", Kopek::baby_name());
}Tüm yavru köpeklere Karabaş adını verme kodunu, Kopek üzerinde tanımlı baby_name ilişkili fonksiyonunda yazıyoruz. Kopek ayrıca bütün hayvanların ortak özelliklerini anlatan Hayvan trait’ini de uygular. Yavru köpeklerin “yavru köpek” diye anılması da, Hayvan trait’inin Kopek üzerindeki baby_name uygulamasında ifade edilir.
main içinde Kopek::baby_name çağırdığımızda, doğrudan Kopek üzerinde tanımlı ilişkili fonksiyon çağrılır. Bu kod şu çıktıyı verir:
Bir yavru köpeğe Karabaş
Ama istediğimiz bu değildir. Biz Kopek için uyguladığımız Hayvan trait’inin baby_name fonksiyonunu çağırmak istiyoruz; böylece kod Bir yavru köpeğe yavru köpek denir anlamına gelen çıktıyı üretsin. Liste 20-19’da kullandığımız teknik burada işe yaramaz. main fonksiyonunu Liste 20-21’deki gibi değiştirirsek derleme hatası alırız.
trait Hayvan {
fn baby_name() -> String;
}
struct Kopek;
impl Kopek {
fn baby_name() -> String {
String::from("Karabaş")
}
}
impl Hayvan for Kopek {
fn baby_name() -> String {
String::from("yavru köpek")
}
}
fn main() {
println!("Bir yavru köpeğe {}", Hayvan::baby_name());
}Hayvan trait’indeki baby_name fonksiyonunu çağırmaya çalışmak; ama Rust hangi uygulamanın kullanılacağını bilemezHayvan::baby_name bir self parametresi almadığı ve Hayvan trait’ini uygulayan başka türler de olabileceği için, Rust hangi uygulamayı kastettiğimizi anlayamaz. Derleyiciden şu hatayı alırız:
$ cargo run
Compiling trait-ornekleri v0.1.0 (file:///projects/trait-ornekleri)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:19:39
|
2 | fn baby_name() -> String;
| ------------------------- `Hayvan::baby_name` defined here
...
19 | println!("Bir yavru köpeğe {}", Hayvan::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
19 | println!("Bir yavru köpeğe {}", <Kopek as Hayvan>::baby_name());
| +++++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `trait-ornekleri` (bin "trait-ornekleri") due to 1 previous error
Rust’a özellikle Kopek için uygulanmış Hayvan sürümünü kullanmak istediğimizi söylemek için tam nitelikli sözdizimi (fully qualified syntax) kullanmamız gerekir. Liste 20-22 bunu gösteriyor.
trait Hayvan {
fn baby_name() -> String;
}
struct Kopek;
impl Kopek {
fn baby_name() -> String {
String::from("Karabaş")
}
}
impl Hayvan for Kopek {
fn baby_name() -> String {
String::from("yavru köpek")
}
}
fn main() {
println!("Bir yavru köpeğe {}", <Kopek as Hayvan>::baby_name());
}Kopek üzerinde uygulanmış Hayvan trait’indeki baby_name fonksiyonunu çağırmak istediğimizi tam nitelikli sözdizimiyle belirtmekAçılı ayraçlar içinde Rust’a bir tür açıklaması veriyoruz; yani bu fonksiyon çağrısı için Kopek türüne Hayvan gibi davranılmasını istediğimizi söylüyoruz. Böylece tam istediğimiz çıktı elde edilir:
Bir yavru köpeğe yavru köpek
Genel biçim şöyledir:
<Type as Trait>::function(receiver_if_method, next_arg, ...);Metod olmayan ilişkili fonksiyonlarda receiver kısmı bulunmaz; yalnızca diğer argümanlar kalır. Aslında fonksiyon ve metod çağırdığınız her yerde bu sözdizimini kullanabilirsiniz. Ama Rust programdaki diğer bilgilerden neyi kastettiğinizi çıkarabiliyorsa bazı kısımları yazmadan geçmenize izin verir. Bu daha uzun sözdizimine yalnızca aynı adı kullanan birden fazla uygulama olduğunda ihtiyaç duyarsınız.
Üst Trait’leri Kullanmak
Bazen bir trait tanımınız başka bir trait’e dayanır. Yani bir türün ilk trait’i uygulayabilmesi için ikinci trait’i de uygulamasını şart koşmak istersiniz. Bunu, trait tanımınızın ikinci trait’teki öğeleri kullanabilmesi için yaparsınız. Trait’inizin dayandığı bu trait’e üst trait denir.
Örneğin CerceveliYazdir adlı bir trait oluşturmak istediğimizi varsayalım. Bunun outline_print metodu, verilen değeri yıldızlarla çerçeveleyerek yazdırsın. Diyelim ki (x, y) biçiminde çıktı üreten Display uygulamasına sahip bir Nokta yapımız var. x = 1 ve y = 3 olan bir Nokta üzerinde outline_print çağrıldığında şu sonucu görmek istiyoruz:
**********
* *
* (1, 3) *
* *
**********
outline_print içinde Display trait’inin sunduğu işlevselliği kullanmak istiyoruz. Bu yüzden CerceveliYazdir trait’inin yalnızca Display uygulayan türlerde çalışacağını belirtmeliyiz. Bunu trait tanımında CerceveliYazdir: Display diyerek yaparız. Bu teknik, trait’e trait sınırı eklemeye benzer. Liste 20-23, CerceveliYazdir uygulamasını gösteriyor.
use std::fmt;
trait CerceveliYazdir: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}Display işlevselliğine ihtiyaç duyan CerceveliYazdir trait’ini uygulamakCerceveliYazdir trait’inin Display gerektirdiğini belirttiğimiz için, Display uygulayan her tür için otomatik olarak gelen to_string fonksiyonunu kullanabiliyoruz. Eğer trait adından sonra : Display yazmasaydık, &Self türü için geçerli kapsamda to_string adlı metod bulunamadığına dair hata alırdık.
Şimdi Display uygulamayan bir tür, örneğin Nokta, üzerinde CerceveliYazdir uygulamaya çalıştığımızda ne olacağına bakalım:
use std::fmt;
trait CerceveliYazdir: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Nokta {
x: i32,
y: i32,
}
impl CerceveliYazdir for Nokta {}
fn main() {
let p = Nokta { x: 1, y: 3 };
p.outline_print();
}Derleyici bize Display gerektiğini ama uygulanmadığını söyler:
$ cargo run
Compiling trait-ornekleri v0.1.0 (file:///projects/trait-ornekleri)
error[E0277]: `Nokta` doesn't implement `std::fmt::Display`
--> src/main.rs:19:25
|
19 | impl CerceveliYazdir for Nokta {}
| ^^^^^ `Nokta` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Nokta`
note: required by a bound in `CerceveliYazdir`
--> src/main.rs:3:24
|
3 | trait CerceveliYazdir: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `CerceveliYazdir`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `trait-ornekleri` (bin "trait-ornekleri") due to 1 previous error
Bunu düzeltmek için Nokta üzerinde Display uygular, böylece CerceveliYazdir’in istediği koşulu karşılarız:
trait CerceveliYazdir: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Nokta {
x: i32,
y: i32,
}
impl CerceveliYazdir for Nokta {}
use std::fmt;
impl fmt::Display for Nokta {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Nokta { x: 1, y: 3 };
p.outline_print();
}Bundan sonra Nokta üzerinde CerceveliYazdir uygulamak sorunsuz derlenir; outline_print çağrısıyla değeri yıldızlı çerçeve içinde yazdırabiliriz.
Dış Trait’leri Newtype Deseniyle Uygulamak
- bölümdeki “Bir Trait’i Bir Türe Uygulamak” kısmında yetim kuralından söz etmiştik: bir trait’i bir tür üzerinde ancak trait ya da türden en az biri kendi crate’imize aitse uygulayabiliriz. Bu kısıtlamayı aşmanın yollarından biri newtype desenidir. Bunun için bir demet struct içinde yeni bir tür oluştururuz. (Demet struct’ları 5. bölümdeki “Demet Struct’larla Farklı Türler Oluşturmak” kısmında görmüştük.) Bu demet struct tek alanlı, ince bir sarmalayıcı olur. Böylece sarmalayıcı tür bizim crate’imize ait olduğundan, trait’i onun üzerinde uygulayabiliriz. Newtype terimi Haskell’den gelir. Bu desenin çalışma zamanında ek bir maliyeti yoktur; sarmalayıcı tür derleme zamanında ortadan kaldırılır.
Örneğin, Vec<T> üzerinde Display uygulamak istediğimizi düşünelim. Yetim kuralı buna doğrudan izin vermez; çünkü hem Display hem de Vec<T> bizim crate’imizin dışında tanımlanmıştır. Bunun yerine Vec<T> örneğini tutan Sarmalayici adlı bir struct oluşturabiliriz. Sonra Display trait’ini Sarmalayici üzerinde uygular ve içteki Vec<T> değerini kullanırız. Liste 20-24 bunu gösteriyor.
use std::fmt;
struct Sarmalayici(Vec<String>);
impl fmt::Display for Sarmalayici {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Sarmalayici(vec![String::from("dunya"), String::from("Rust")]);
println!("w = {w}");
}Display uygulayabilmek için Vec<String> etrafında Sarmalayici türü oluşturmakDisplay uygulaması, Sarmalayici bir demet struct olduğu ve Vec<T> de demetin 0 numaralı öğesi olduğu için içteki Vec<T>’ye self.0 ile erişir. Böylece Sarmalayici üzerinde Display işlevselliğini kullanabiliriz.
Bu tekniğin dezavantajı, Sarmalayici’ın yeni bir tür olmasıdır; dolayısıyla sardığı değerin metodlarına otomatik olarak sahip değildir. Sarmalayici’ın tam olarak Vec<T> gibi davranmasını istersek, Vec<T> metodlarını Sarmalayici üzerinde tek tek yazar ve bunları self.0’a yönlendiririz. Yeni türün iç türdeki bütün metodlara sahip olmasını istersek Deref trait’ini uygulayıp iç türü döndürmek çözüm olabilir. Bunu 15. bölümdeki “Akıllı İşaretçileri Normal Referanslar Gibi Ele Almak” kısmında incelemiştik. Buna karşılık, Sarmalayici’ın iç türün bütün metodlarını görmesini istemiyorsak, yalnızca istediğimiz metodları elle uygularız.
Newtype deseni yalnızca trait’lerle sınırlı değildir. Trait’lerle devam etmeden önce Rust’ın tür sistemiyle etkileşmenin başka gelişmiş yollarına bakalım.
Gelişmiş Türler
Gelişmiş Türler
Rust’ın tür sisteminde şimdiye kadar adını anıp ayrıntısına girmediğimiz bazı özellikler var. Önce newtype deseninin neden yararlı olduğunu anlatarak başlayacağız. Sonra newtype’a benzeyen ama anlamı biraz farklı olan tür takma adlarına geçeceğiz. Ardından ! türünü ve dinamik boyutlu türleri ele alacağız.
Newtype Deseniyle Tür Güvenliği ve Soyutlama
Bu bölüm, daha önceki “Dış Trait’leri Newtype Deseniyle Uygulamak” kısmını okuduğunuzu varsayar. Newtype deseni, şimdiye kadar ele aldığımızın ötesinde işler için de kullanışlıdır. Bunların arasında değerlerin birbiriyle karışmasını derleme zamanında önlemek ve bir değerin birimini açıkça göstermek de vardır. Liste 20-16’da bunun bir örneğini görmüştük: Milimetreler ve Metreler yapıları, u32 değerlerini newtype olarak sarmalıyordu. Eğer bir fonksiyon Milimetreler parametresi alıyorsa, ona yanlışlıkla Metreler ya da doğrudan u32 vermeye çalışan bir program derlenmez.
Newtype desenini, bir türün bazı uygulama ayrıntılarını gizlemek için de kullanabiliriz. Yeni tür, içteki gizli türden farklı bir açık API sunabilir.
Newtype’lar iç uygulamayı da gizleyebilir. Örneğin, isimlerle kimlik numaralarını eşleyen HashMap<i32, String> yapısını sarmalayan People adlı bir tür sunabiliriz. People kullanan kod yalnızca dışarı sunduğumuz açık API ile, örneğin koleksiyona isim ekleyen bir metodla etkileşir. İçeride isimlere i32 kimlik atadığımızı bilmesi gerekmez. Newtype deseni, 18. bölümdeki “Uygulama Ayrıntılarını Gizleyen Kapsülleme” kısmında anlattığımız kapsüllemeyi elde etmenin hafif bir yoludur.
Tür Eşanlamlıları ve Tür Takma Adları
Rust, var olan bir türe başka bir ad vermek için tür takma adı tanımlamanıza izin verir. Bunun için type anahtar kelimesini kullanırız. Örneğin i32 için Kilometreler adında bir takma ad oluşturabiliriz:
fn main() {
type Kilometreler = i32;
let x: i32 = 5;
let y: Kilometreler = 5;
println!("x + y = {}", x + y);
}Artık Kilometreler, i32 için bir eşanlamlıdır. Liste 20-16’da oluşturduğumuz Milimetreler ve Metreler türlerinden farklı olarak Kilometreler yeni ve ayrı bir tür değildir. Kilometreler türündeki değerler i32 ile tamamen aynı kabul edilir:
fn main() {
type Kilometreler = i32;
let x: i32 = 5;
let y: Kilometreler = 5;
println!("x + y = {}", x + y);
}Kilometreler ile i32 aynı tür olduğu için her iki türden değerleri toplayabilir, i32 bekleyen fonksiyonlara Kilometreler geçebiliriz. Ama bu yaklaşım, newtype desenindeki tür denetimi avantajlarını vermez. Yani bir yerde Kilometreler ile i32 değerlerini karıştırırsak derleyici hata vermez.
Tür eşanlamlılarının başlıca kullanım nedeni tekrarları azaltmaktır. Örneğin şöyle uzun bir türümüz olabilir:
Box<dyn Fn() + Send + 'static>Böyle uzun bir türü fonksiyon imzalarında ve tür açıklamalarında tekrar tekrar yazmak yorucu ve hataya açıktır. Kodu bu şekilde dolu bir proje hayal edin; Liste 20-25 buna örnektir.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("selam"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// --snip--
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// --snip--
Box::new(|| ())
}
}Tür takma adı, tekrarları azaltarak bu kodu daha yönetilebilir hâle getirir. Liste 20-26’da ayrıntılı tür için ErtelenenIs adlı bir takma ad tanımlıyoruz ve bütün kullanımları buna çeviriyoruz.
fn main() {
type ErtelenenIs = Box<dyn Fn() + Send + 'static>;
let f: ErtelenenIs = Box::new(|| println!("selam"));
fn takes_long_type(f: ErtelenenIs) {
// --snip--
}
fn returns_long_type() -> ErtelenenIs {
// --snip--
Box::new(|| ())
}
}ErtelenenIs adlı bir tür takma adı tanıtmakBu sürüm okumayı ve yazmayı çok kolaylaştırır. Takma ad için anlamlı bir isim seçmek de niyetinizi daha iyi anlatır. Örneğin thunk, daha sonra değerlendirilecek kod parçası anlamında kullanılan yerleşik bir terimdir; bu yüzden saklanan bir kapanış için uygun addır.
Tür takma adları, tekrarları azaltmak amacıyla Result<T, E> ile de çok sık kullanılır. Standart kütüphanedeki std::io modülünü düşünün. Girdi/çıktı işlemleri, işlem başarısız olabileceği için çoğu zaman Result<T, E> döndürür. Bu modülde tüm olası G/Ç hatalarını temsil eden std::io::Error yapısı vardır. std::io içindeki pek çok fonksiyonun dönüş türü, E kısmı std::io::Error olan Result<T, E> olur. Write trait’indeki şu fonksiyonlar buna örnektir:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Buradaki Result<..., Error> ifadesi tekrar tekrar yazılıyor. Bu yüzden std::io modülü şu tür takma adını tanımlar:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Bu bildirim std::io modülü içinde olduğundan, std::io::Result<T> tam nitelikli takma adını kullanabiliriz; yani E kısmı std::io::Error ile doldurulmuş bir Result<T, E>. Böylece Write trait’inin imzaları şu hâle gelir:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Bu tür takma adı iki açıdan faydalıdır: kodu yazmayı kolaylaştırır ve std::io genelinde tutarlı bir arayüz sunar. Sonuçta bu yalnızca bir takma addır; yani aslında yine Result<T, E> kullanıyoruz. Bu yüzden Result<T, E> üzerinde çalışan metodların hepsini ve ? gibi özel sözdizimlerini bununla da kullanabiliriz.
Hiç Dönmeyen Never Türü
Rust’ta ! adında özel bir tür vardır. Tür kuramında buna boş tür denir; çünkü hiç değeri yoktur. Biz buna never türü demeyi tercih ediyoruz; çünkü bir fonksiyon hiç dönmeyecekse, dönüş türünün yerine bu yazılır. Örnek:
fn bar() -> ! {
// --snip--
panic!();
}Bu kodu “bar fonksiyonu hiç dönmez” diye okuruz. Hiç dönmeyen fonksiyonlara ayrışan fonksiyonlar denir. ! türünde değer üretemeyeceğimiz için bar hiçbir koşulda gerçekten dönemeyecektir.
Peki hiç değeri olmayan bir tür ne işe yarar? Bunun için sayı tahmin oyunundan Liste 2-5’i hatırlayın; o kodun küçük bir parçasını burada Liste 20-27 olarak yeniden veriyoruz.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Sayıyı tahmin et!");
let gizli_sayi = rand::thread_rng().gen_range(1..=100);
println!("Gizli sayı: {gizli_sayi}");
loop {
println!("Lütfen tahmininizi girin.");
let mut tahmin = String::new();
// --snip--
io::stdin()
.read_line(&mut tahmin)
.expect("Satır okunamadı");
let tahmin: u32 = match tahmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Tahmininiz: {tahmin}");
// --snip--
match tahmin.cmp(&gizli_sayi) {
Ordering::Less => println!("Çok küçük!"),
Ordering::Greater => println!("Çok büyük!"),
Ordering::Equal => {
println!("Kazandınız!");
break;
}
}
}
}continue ile biten bir matchO sırada bu kodun bazı ayrıntılarını atlamıştık. 6. bölümdeki “match Kontrol Akışı Yapısı” kısmında, match kollarının aynı türü döndürmesi gerektiğini konuşmuştuk. Örneğin şu kod çalışmaz:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "dunya",
};
}Burada guess değişkeninin aynı anda hem tamsayı hem string olması gerekirdi; ama Rust bir değişkenin tek türü olmasını ister. O hâlde continue ne döndürüyor? Liste 20-27’de bir kolda u32, diğer kolda continue olmasına nasıl izin verildi?
Tahmin ettiğiniz gibi continue ifadesinin türü !’dir. Rust, guess türünü hesaplarken bir kolun u32, diğer kolun ! olduğuna bakar. ! hiçbir değere sahip olamayacağı için Rust, guess türünün u32 olduğuna karar verir.
Bunun resmi açıklaması şudur: ! türündeki ifadeler başka herhangi bir türe zorlanabilir. Bu yüzden match kolunu continue ile bitirebiliriz; çünkü continue bir değer döndürmez, denetimi döngünün başına geri taşır. Dolayısıyla Err durumunda guess’e hiçbir zaman değer atamayız.
Never türü panic! makrosunda da işe yarar. Option<T> üzerinde çağırdığımız unwrap fonksiyonunu hatırlayın; ya içteki değeri üretir ya da panikler. Tanımı şöyledir:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("`Option::unwrap()` `None` degeri uzerinde cagrildi"),
}
}
}Burada, Liste 20-27’deki match ile aynı durum gerçekleşir: Rust val değişkeninin türünü T, panic! ifadesinin türünü ise ! olarak görür. Böylece tüm match ifadesinin sonucu T olur. Bu kod geçerlidir; çünkü panic! bir değer üretmez, programı sonlandırır. None durumunda unwrap içinden değer döndürmeyiz.
! türüne sahip son bir ifade daha vardır: döngü.
fn main() {
print!("sonsuzca ");
loop {
print!("ve hep ");
}
}Burada döngü hiç bitmediği için ifadenin değeri ! olur. Ama break koysaydık bu doğru olmazdı; çünkü döngü break noktasında sonlanırdı.
Dinamik Boyutlu Türler ve Sized Trait’i
Rust’ın türleri hakkında bazı ayrıntıları bilmesi gerekir; örneğin belli bir türden değer için ne kadar alan ayrılacağı gibi. Bu yüzden tür sisteminin ilk bakışta kafa karıştırıcı görünen bir köşesi vardır: dinamik boyutlu türler. Bunlara bazen DST ya da unsized type da denir. Bu türler, boyutunu ancak çalışma zamanında bilebileceğimiz değerlerle çalışabilmemizi sağlar.
Kitap boyunca kullandığımız str buna örnektir. Evet, &str değil, doğrudan str bir DST’dir. Kullanıcının girdiği metin gibi pek çok durumda, string’in uzunluğunu ancak çalışma zamanında bilebiliriz. Bu yüzden str türünde bir değişken oluşturamayız ve str türünde parametre alamayız. Aşağıdaki kod bu nedenle çalışmaz:
fn main() {
let s1: str = "Merhaba orada!";
let s2: str = "Nasil gidiyor?";
}Rust, herhangi bir türdeki değer için ne kadar bellek ayrılacağını bilmek zorundadır ve aynı türden tüm değerler aynı miktarda bellek kullanmalıdır. Eğer buna izin verseydi, bu iki str değeri de aynı kadar yer kaplamak zorunda olurdu. Oysa uzunlukları farklıdır: s1 için 12 bayt, s2 için 15 bayt gerekir. Bu yüzden dinamik boyutlu türü doğrudan tutan değişken oluşturamayız.
Peki ne yaparız? Cevabı zaten biliyorsunuz: s1 ve s2 türünü str yerine string dilimi (&str) yaparız. 4. bölümdeki “String Dilimleri” kısmından hatırlayın: dilim veri yapısı yalnızca başlangıç konumu ve uzunluğu saklar. Dolayısıyla &T, T’nin bulunduğu adresi tutan tek bir değerken; string dilimi iki değer içerir: str’nin adresi ve uzunluğu. Bu yüzden string dilimi değerinin boyutunu derleme zamanında biliriz; her zaman bir usize’nin iki katıdır. Başvurduğu string ne kadar uzun olursa olsun, string diliminin boyutu bellidir.
Genel olarak Rust’ta dinamik boyutlu türler böyle kullanılır: dinamik bilginin boyutunu tutan ek meta verilerle birlikte, bir işaretçinin arkasında tutulurlar. Kural şudur: dinamik boyutlu türlerin değerlerini her zaman bir tür işaretçinin arkasına koymalıyız.
str’yi farklı işaretçilerle birleştirebiliriz: örneğin Box<str> ya da Rc<str>. Aslında bunu başka bir DST ile zaten görmüştünüz: trait’ler. Her trait de dinamik boyutlu türdür ve adına bakarak ancak bir işaretçi arkasından başvurabiliriz. 18. bölümdeki “Trait Nesneleriyle Ortak Davranışı Soyutlamak” kısmında bunu &dyn Trait, Box<dyn Trait> ve benzer örneklerle görmüştük.
DST’lerle çalışabilmek için Rust, bir türün boyutunun derleme zamanında bilinip bilinmediğini anlamaya yarayan Sized trait’ini sunar. Boyutu derleme zamanında bilinen her tür için bu trait otomatik uygulanır. Ayrıca Rust, her jenerik fonksiyona örtük olarak Sized sınırı ekler. Yani şu türden bir jenerik fonksiyon:
fn generic<T>(t: T) {
// --snip--
}aslında şu şekilde ele alınır:
fn generic<T: Sized>(t: T) {
// --snip--
}Varsayılan olarak jenerik fonksiyonlar yalnızca boyutu derleme zamanında bilinen türlerde çalışır. Ama bu kısıtı gevşetmek için özel bir sözdizimi kullanabilirsiniz:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}?Sized tür sınırı, “T, Sized olabilir de olmayabilir de” anlamına gelir. Bu gösterim, jenerik türlerin derleme zamanında bilinen boyuta sahip olma varsayılanını geçersiz kılar. Bu anlamdaki ?Trait sözdizimi yalnızca Sized için vardır; diğer trait’ler için yoktur.
Ayrıca t parametresinin türünü T yerine &T yaptığımıza dikkat edin. Çünkü tür Sized olmayabilir; bu yüzden onu bir tür işaretçinin arkasından kullanmamız gerekir. Burada referans seçtik.
Sırada fonksiyonlar ve kapanışlar var!
Gelişmiş Fonksiyonlar ve Kapanışlar
Gelişmiş Fonksiyonlar ve Kapanışlar
Bu bölümde fonksiyonlar ve kapanışlarla ilgili bazı daha ileri özelliklere bakacağız. Bunların arasında fonksiyon işaretçileri ve kapanış döndürme de var.
Fonksiyon İşaretçileri
Kapanışları fonksiyonlara nasıl geçireceğimizi görmüştük; ama normal fonksiyonları da başka fonksiyonlara parametre olarak verebilirsiniz. Bu teknik, yeni bir kapanış tanımlamak yerine önceden tanımladığınız bir fonksiyonu geçirmek istediğinizde işe yarar. Fonksiyonlar, Fn kapanış trait’iyle karıştırılmaması gereken fn türüne zorlanır. fn türüne fonksiyon işaretçisi denir. Fonksiyon işaretçileri sayesinde fonksiyonları başka fonksiyonlara argüman olarak geçirebiliriz.
Bir parametrenin fonksiyon işaretçisi olduğunu belirtmenin sözdizimi, kapanışlara benzerdir. Liste 20-28’de add_one adlı, parametresine 1 ekleyen bir fonksiyon tanımlıyoruz. do_twice iki parametre alır: i32 alıp i32 döndüren herhangi bir fonksiyona işaret eden fonksiyon işaretçisi ve bir i32 değeri. do_twice, aldığı f fonksiyonunu arg değeriyle iki kez çağırır ve iki sonucu toplar. main ise do_twice’ı add_one ve 5 ile çağırır.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("Cevap: {answer}");
}fn türünü kullanmakBu kod Cevap: 12 yazar. do_twice içindeki f parametresinin, bir i32 alıp i32 döndüren fn olduğunu belirtiyoruz. Sonra do_twice gövdesinde f’yi çağırabiliyoruz. main içinde de add_one fonksiyon adını ilk argüman olarak geçiyoruz.
Kapanışlardan farklı olarak fn bir trait değil, bir türdür. Bu yüzden parametre türü olarak doğrudan fn yazarız; trait sınırıyla jenerik parametre tanımlamayız.
Fonksiyon işaretçileri kapanış trait’lerinin üçünü de (Fn, FnMut, FnOnce) uygular. Yani kapanış bekleyen bir fonksiyona her zaman fonksiyon işaretçisi de geçebilirsiniz. Bu nedenle genellikle fonksiyonları, kapanış trait’lerinden biriyle sınırlandırılmış jenerik tür alacak şekilde yazmak daha esnektir; böylece hem fonksiyon hem kapanış kabul ederler.
Bununla birlikte, yalnızca fn kabul etmek isteyeceğiniz bir durum da vardır: kapanış kavramı olmayan dış kodla etkileşmek. Örneğin C fonksiyonları, fonksiyonları argüman olarak alabilir ama kapanışları alamaz.
Hem satır içinde tanımlanmış kapanış hem de isimli fonksiyon kullanılabilen bir örnek olarak standart kütüphanedeki Iterator trait’inin map metoduna bakalım. Sayılardan oluşan vektörü string vektörüne dönüştürmek için Liste 20-29’daki gibi kapanış kullanabiliriz.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}map metodu ile kapanış kullanmakAynı işi, kapanış yerine isimli bir fonksiyon vererek de yapabiliriz. Liste 20-30 bunu gösteriyor.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}map ile String::to_string fonksiyonunu kullanmakBurada, aynı adlı birden çok fonksiyon bulunduğu için, 20-02 bölümünde anlattığımız tam nitelikli sözdizimine ihtiyaç duyarız.
Burada kullandığımız to_string, standart kütüphanenin Display uygulayan her tür için sağladığı ToString trait’indeki fonksiyondur.
Ayrıca 6. bölümdeki “Enum Değerleri” kısmından hatırlayın: tanımladığımız her enum varyantının adı, aynı zamanda başlatıcı fonksiyon olur. Bu başlatıcıları, kapanış trait’lerini uygulayan fonksiyon işaretçileri gibi kullanabiliriz. Liste 20-31, bunu map ile gösteriyor.
fn main() {
enum Durum {
Deger(u32),
Dur,
}
let list_of_statuses: Vec<Durum> = (0u32..20).map(Durum::Deger).collect();
}Durum örnekleri üretmek için map içinde enum başlatıcısı kullanmakBurada, map çağrılan aralıktaki her u32 değeri için Durum::Deger başlatıcısını kullanarak Durum::Deger örnekleri oluşturuyoruz. Bazı geliştiriciler bu tarzı tercih eder, bazıları kapanış kullanmayı daha açık bulur. İkisi de aynı koda derlenir; sizin için hangisi daha anlaşılırsa onu kullanın.
Kapanış Döndürmek
Kapanışlar trait’lerle temsil edilir; bu yüzden doğrudan kapanış döndüremezsiniz. Trait döndürmek istediğiniz çoğu yerde, onun trait’i uygulayan somut türünü dönüş türü yapabilirsiniz. Ancak kapanışlarda bu çoğu zaman mümkün değildir; çünkü genellikle doğrudan yazılabilir somut bir dönüş türleri yoktur. Ayrıca, kapanış kapsamından değer yakalıyorsa onu fn dönüş türü olarak da kullanamazsınız.
Bunun yerine, genellikle 10. bölümde öğrendiğimiz impl Trait sözdizimini kullanırsınız. Fn, FnOnce ve FnMut kullanarak işlevsel bir tür döndürebilirsiniz. Örneğin Liste 20-32’deki kod sorunsuz derlenir.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}impl Trait sözdizimiyle kapanış döndürmekAma 13. bölümdeki “Kapanış Türlerini Çıkarsamak ve Açıklamak” kısmında belirttiğimiz gibi, her kapanış kendi başına ayrı bir türdür. Aynı imzaya sahip ama farklı uygulamalara sahip birden fazla işlevle çalışmanız gerekiyorsa, bunlar için trait nesnesi kullanmanız gerekir. Liste 20-33’te böyle bir durumda ne olduğuna bakalım.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}impl Fn türleri döndüren fonksiyonlarla tanımlanmış kapanışlardan Vec<T> oluşturmaya çalışmakBurada returns_closure ve returns_initialized_closure adlı iki fonksiyon var; ikisi de impl Fn(i32) -> i32 döndürüyor. Fakat döndürdükleri kapanışlar farklı. Bu kodu derlemeye çalışırsak Rust bunun çalışmayacağını söyler:
error[E0308]: mismatched types
--> src/main.rs:2:43
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
8 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
12 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
Hata mesajı bize şunu söyler: impl Trait döndürdüğümüzde Rust benzersiz bir opak tür oluşturur. Bu, iç ayrıntılarını göremediğimiz ve kendi başımıza yazamayacağımız bir türdür. Dolayısıyla iki fonksiyon da aynı trait’i (Fn(i32) -> i32) uygulayan kapanış döndürse bile, Rust’ın bu iki dönüş için ürettiği opak türler birbirinden farklıdır. Bu, 17. bölümde gördüğümüz; aynı çıktı türüne sahip olsalar bile ayrı async bloklarının ayrı somut türlere sahip olmasına benzer. Bu sorunun çözümünü daha önce birkaç kez gördük: trait nesnesi kullanmak. Liste 20-34 bunu gösteriyor.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}Box<dyn Fn> döndüren fonksiyonlarla kapanışlardan Vec<T> oluşturmakBu sürüm sorunsuz derlenir. Trait nesneleri hakkında daha fazlası için 18. bölümdeki “Trait Nesneleriyle Ortak Davranışı Soyutlamak” kısmına bakabilirsiniz.
Sırada makrolar var!
Makrolar
Makrolar
Bu kitap boyunca println! gibi makroları kullandık; ama makronun ne olduğunu ve nasıl çalıştığını ayrıntılı ele almadık. Makro terimi, Rust’taki şu özellik ailesini ifade eder: macro_rules! ile tanımlanan bildirime dayalı makrolar ve üç tür yordam tabanlı makro:
- Struct ve enum’larda kullanılan
deriveözniteliğiyle eklenecek kodu belirleyen özel#[derive]makroları - Her türlü öğe üzerinde kullanılabilen özel öznitelikler tanımlayan öznitelik benzeri makrolar
- Fonksiyon çağrısına benzeyen ama argüman olarak verilen belirteçler üzerinde çalışan fonksiyon benzeri makrolar
Bunların her birini sırayla ele alacağız. Ama önce, elimizde zaten fonksiyonlar varken makrolara neden ihtiyaç duyduğumuza bakalım.
Makrolar ile Fonksiyonlar Arasındaki Fark
Temelde makrolar, başka kod yazan kod yazmanın bir yoludur; buna metaprogramlama denir. Ek C’de, çeşitli trait uygulamalarını sizin yerinize üreten derive özniteliğinden söz etmiştik. Ayrıca kitap boyunca println! ve vec! makrolarını da kullandık. Bu makroların hepsi, sizin elle yazdığınızdan daha fazla kod üretmek için genişler.
Metaprogramlama, yazmanız ve bakımını yapmanız gereken kod miktarını azaltır; bu, fonksiyonların da görevlerinden biridir. Ama makroların, fonksiyonlarda olmayan bazı ek güçleri vardır.
Fonksiyon imzası, aldığı parametrelerin sayısını ve türünü belirtmek zorundadır. Makrolar ise değişken sayıda parametre alabilir. Örneğin println!("hello") tek argümanla da çağrılabilir, println!("hello {}", name) iki argümanla da. Ayrıca makrolar, derleyici kodun anlamını yorumlamadan önce genişletilir. Bu yüzden bir makro, örneğin verilen tür üzerinde bir trait uygulaması üretebilir. Fonksiyon bunu yapamaz; çünkü çalışma zamanında çağrılır, oysa trait uygulaması derleme zamanında var olmalıdır.
Fonksiyon yerine makro yazmanın dezavantajı da buradadır: makro tanımları daha karmaşıktır; çünkü Rust kodu üreten Rust kodu yazarsınız. Bu dolaylılık nedeniyle makro tanımları, fonksiyon tanımlarına göre genelde daha zor okunur, anlaşılır ve korunur.
Makrolarla fonksiyonlar arasındaki önemli farklardan biri daha vardır: Makroları kullanmadan önce tanımlamalı ya da kapsam içine almalısınız. Fonksiyonları ise dosyanın herhangi bir yerinde tanımlayıp herhangi bir yerinde çağırabilirsiniz.
Genel Metaprogramlama İçin Bildirime Dayalı Makrolar
Rust’ta en yaygın makro biçimi bildirime dayalı makro dur. Bunlara bazen “örnekle makrolar”, “macro_rules! makroları” ya da kısaca “makrolar” da denir. Özünde, bildirime dayalı makrolar Rust’taki match ifadesine benzeyen bir yapı sunar. 6. bölümde gördüğümüz gibi match, bir ifadeyi alır, onun sonucunu desenlerle karşılaştırır ve eşleşen desene bağlı kodu çalıştırır. Makrolar da bir değeri, belirli koda bağlı desenlerle karşılaştırır. Buradaki “değer”, makroya geçirilen Rust kaynak kodunun kendisidir. Desenler bu kaynak kodun yapısıyla karşılaştırılır; eşleşen desene bağlı kod ise makroya verilen kodun yerine geçer. Bütün bunlar derleme sırasında olur.
Makro tanımlamak için macro_rules! yapısını kullanırız. Nasıl çalıştığını görmek için vec! makrosunun tanımına bakalım. 8. bölümde vec! makrosunu belirli değerlerle yeni vektör oluşturmak için kullanmıştık. Örneğin şu çağrı, üç tamsayı içeren yeni bir vektör üretir:
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}Aynı makro ile iki tamsayılık vektör de, beş string dilimli vektör de üretebiliriz. Bunu fonksiyonla yapamazdık; çünkü baştan kaç değer geleceğini ya da bunların türünü bilmezdik.
Liste 20-35, vec! makrosunun biraz sadeleştirilmiş tanımını gösteriyor.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}vec! makrosu tanımının sadeleştirilmiş bir sürümüNot: Standart kütüphanedeki gerçek
vec!tanımı, baştan doğru miktarda bellek ayıran ek kod içerir. Burada örneği daha sade tutmak için o optimizasyonu göstermiyoruz.
#[macro_export] açıklaması, bu makronun tanımlandığı crate kapsam içine alındığında makronun da erişilebilir olmasını sağlar. Bu açıklama olmadan makroyu kapsam içine alamazsınız.
Ardından macro_rules! ve makronun adını, ünlem işareti olmadan, yazarız. Burada ad vec’tir. Sonrasındaki süslü ayraçlar makro tanımının gövdesini tutar.
vec! gövdesindeki yapı, match ifadesine benzer. Burada ( $( $x:expr ),* ) desenine sahip tek bir kol var; ardından => ve bu desene bağlı kod bloğu geliyor. Desen eşleşirse bu koda genişlenir. Bu makroda tek desen olduğu için yalnızca tek geçerli eşleşme vardır; başka her desen hata üretir. Daha karmaşık makrolarda birden fazla kol bulunur.
Makro tanımlarındaki geçerli desen sözdizimi, 19. bölümde gördüğümüz desen sözdiziminden farklıdır. Çünkü makro desenleri değerlerle değil, Rust kodunun yapısıyla eşleşir. Şimdi Liste 20-35’teki desenin parçalarına bakalım; tam sözdizimi için [Rust Reference][ref] belgesine bakabilirsiniz.
Önce tüm deseni saran parantezleri kullanıyoruz. Ardından desene uyan Rust kodunu tutacak bir değişken tanımlamak için dolar işareti ($) kullanıyoruz. Bu işaret, bunun normal Rust değişkeni değil makro sistemi değişkeni olduğunu açıkça gösterir. Sonra, parantez içindeki desene uyan değerleri yakalayıp yerine geçecek kısımda kullanmamızı sağlayan başka bir parantez grubu geliyor. $() içindeki $x:expr, herhangi bir Rust ifadesiyle eşleşir ve bu ifadeye $x adını verir.
$() sonrasındaki virgül, $() ile eşleşen her kod parçası arasında gerçek bir virgül bulunması gerektiğini belirtir. Sonraki * ise, yıldızdan önce gelen şeyin sıfır ya da daha çok kez eşleşebileceğini söyler.
Bu makroyu vec![1, 2, 3]; diye çağırdığımızda, $x deseni üç kez eşleşir: 1, 2 ve 3 ifadeleriyle.
Şimdi de bu kola bağlı kod bloğundaki desene bakalım: $()* içindeki temp_vec.push() ifadesi, desende $() ile eşleşen her parça için sıfır ya da daha çok kez üretilir. $x, eşleşen her ifadeyle yer değiştirir. vec![1, 2, 3]; çağrısında üretilen kod şu olur:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Böylece, istediğiniz türden ve istediğiniz sayıda argüman alıp, verilen öğeleri içeren vektör oluşturacak kod üreten bir makro tanımlamış olduk.
Makro yazımı hakkında daha fazla bilgi için çevrimiçi belgelere ya da Daniel Keep tarafından başlatılıp Lukas Wirth tarafından sürdürülen [“The Little Book of Rust Macros”][tlborm] gibi kaynaklara bakabilirsiniz.
Özniteliklerden Kod Üreten Yordam Tabanlı Makrolar
Makroların ikinci biçimi yordam tabanlı makrolardır. Bunlar, bildirime dayalı makrolardan ziyade fonksiyonlara daha çok benzer. Yordam tabanlı makrolar girdi olarak kod alır, o kod üzerinde işlem yapar ve çıktı olarak yeni kod üretir. Yani desen eşleştirip kodu başka kodla değiştirmek yerine, giriş kodunu işlerler. Üç tür yordam tabanlı makro vardır: özel derive, öznitelik benzeri ve fonksiyon benzeri. Üçü de benzer mantıkla çalışır.
Yordam tabanlı makro oluştururken tanımlar özel bir crate türüne sahip ayrı bir crate içinde olmalıdır. Bunun karmaşık teknik nedenleri vardır; ileride kalkmasını umuyoruz. Liste 20-36’da yordam tabanlı makro tanımının genel biçimi var; buradaki some_attribute, belirli makro türü için yer tutucudur.
use proc_macro::TokenStream;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Yordam tabanlı makroyu tanımlayan fonksiyon, girdi olarak TokenStream alır ve çıktı olarak yine TokenStream üretir. TokenStream, Rust ile birlikte gelen proc_macro crate’inde tanımlıdır ve belirteç dizisini temsil eder. Makronun özü budur: makronun üzerinde çalıştığı kaynak kod girdi TokenStream’ini, ürettiği kod da çıktı TokenStream’ini oluşturur. Fonksiyondaki öznitelik ise hangi tür yordam tabanlı makro yazdığımızı söyler. Aynı crate içinde birden çok yordam tabanlı makro türü bulunabilir.
Şimdi farklı yordam tabanlı makro türlerine bakalım. Özel derive makrosuyla başlayacağız; sonra diğer biçimlerin küçük farklarını göreceğiz.
Özel derive Makroları
MerhabaMakro adlı bir trait tanımlayan merhaba_makro isimli bir crate oluşturalım. Bu trait’in tek bir ilişkili fonksiyonu olsun: merhaba_makro. Kullanıcıların MerhabaMakro trait’ini her tür için tek tek uygulamasını istemiyoruz; bunun yerine, türlerini #[derive(MerhabaMakro)] ile işaretleyebilecekleri bir yordam tabanlı makro sağlayacağız. Varsayılan uygulama Merhaba, Makro! Benim adım TurAdi! yazdıracak; burada TurAdi, trait’in uygulandığı türün adı olacak. Yani crate’imizi kullanan bir programcının, Liste 20-37’deki gibi kod yazabilmesini sağlayacağız.
use merhaba_makro::MerhabaMakro;
use merhaba_makro_turet::MerhabaMakro;
#[derive(MerhabaMakro)]
struct Krepler;
fn main() {
Krepler::merhaba_makro();
}İşimiz bittiğinde bu kod Merhaba, Makro! Benim adım Krepler! yazdıracak. İlk adım, şöyle yeni bir kütüphane crate’i oluşturmaktır:
$ cargo new merhaba_makro --lib
Sonra, Liste 20-38’de MerhabaMakro trait’ini ve ilişkili fonksiyonunu tanımlayacağız.
pub trait MerhabaMakro {
fn merhaba_makro();
}derive makrosuyla birlikte kullanacağımız basit bir traitArtık elimizde trait ve fonksiyonu var. Bu noktada crate kullanıcısı, istediği işlevi elde etmek için trait’i kendisi uygulayabilir; Liste 20-39 bunu gösteriyor.
use merhaba_makro::MerhabaMakro;
struct Krepler;
impl MerhabaMakro for Krepler {
fn merhaba_makro() {
println!("Merhaba, Makro! Benim adım Krepler!");
}
}
fn main() {
Krepler::merhaba_makro();
}MerhabaMakro trait’ini elle uygulasaydı kodun nasıl görüneceğiAma bu durumda, merhaba_makro ile kullanmak istedikleri her tür için ayrı bir uygulama bloğu yazmaları gerekir. Biz onları bu zahmetten kurtarmak istiyoruz.
Ayrıca şu anda, trait’in uygulandığı türün adını yazdıran bir varsayılan merhaba_makro uygulaması da veremiyoruz; çünkü Rust’ta çalışma zamanında tür adını geriye dönük öğrenmeye yarayan reflection desteği yoktur. İhtiyacımız olan şey, derleme zamanında kod üreten bir makrodur.
Sonraki adım yordam tabanlı makroyu tanımlamak. Bu yazının yazıldığı sırada yordam tabanlı makrolar ayrı crate içinde olmak zorunda. İleride bu kısıt kalkabilir. Crate ve makro crate’lerini adlandırma kuralı şöyledir: foo adlı crate için özel derive crate’i foo_derive adını alır. Bu yüzden merhaba_makro projesinin içinde merhaba_makro_turet adlı yeni crate oluşturalım:
$ cargo new merhaba_makro_turet --lib
Bu iki crate birbirine sıkı sıkıya bağlıdır; bu yüzden yordam tabanlı makro crate’ini merhaba_makro crate’inin dizini içinde oluşturuyoruz. merhaba_makro içindeki trait tanımını değiştirirsek, merhaba_makro_turet içindeki yordam tabanlı makroyu da değiştirmemiz gerekir. Bu iki crate ayrı ayrı yayımlanacaktır; bunları kullanan programcılar da ikisini bağımlılık olarak ekleyip ikisini de kapsam içine alacaktır. İstersek merhaba_makro crate’ini, merhaba_makro_turet crate’ine bağımlı yapıp yordam tabanlı makroyu yeniden dışa aktarabilirdik. Ama burada seçtiğimiz yapı, derive işlevini istemeyen kullanıcıların yalnızca merhaba_makro crate’ini kullanabilmesine de izin verir.
merhaba_makro_turet crate’inin yordam tabanlı makro crate’i olduğunu belirtmeliyiz. Ayrıca birazdan göreceğiniz gibi syn ve quote crate’lerine de ihtiyaç var; bu yüzden onları bağımlılık olarak eklemeliyiz. merhaba_makro_turet içindeki Cargo.toml dosyasına şu satırları ekleyin:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Yordam tabanlı makroyu tanımlamaya başlamak için, Liste 20-40’taki kodu merhaba_makro_turet crate’inin src/lib.rs dosyasına koyun. impl_merhaba_makro fonksiyonunu ekleyene kadar bu kod derlenmeyecektir.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(MerhabaMakro)]
pub fn merhaba_makro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_merhaba_makro(&ast)
}Kodu iki parçaya ayırdığımıza dikkat edin: merhaba_makro_derive fonksiyonu TokenStream’i ayrıştırmaktan, impl_merhaba_makro ise söz dizim ağacını dönüştürmekten sorumlu. Bu ayrım yordam tabanlı makro yazmayı daha rahat hâle getirir. Dış fonksiyondaki kod (merhaba_makro_derive) gördüğünüz ya da yazacağınız neredeyse bütün yordam tabanlı makro crate’lerinde benzer olacaktır. İç fonksiyondaki kod (impl_merhaba_makro) ise makronun amacına göre değişir.
Burada üç yeni crate kullandık: proc_macro, [syn][syn] ve [quote][quote]. proc_macro Rust ile birlikte geldiği için onu Cargo.toml’a ayrıca eklemedik. proc_macro, derleyicinin Rust kodunu okumamıza ve dönüştürmemize imkân veren API’sidir.
syn crate’i Rust kodunu string’den, üzerinde işlem yapabileceğimiz veri yapısına dönüştürür. quote crate’i ise syn veri yapılarını tekrar Rust koduna çevirir. Bu crate’ler işi büyük ölçüde kolaylaştırır; çünkü Rust kodu için tam bir ayrıştırıcı yazmak hiç kolay değildir.
Kullanıcı #[derive(MerhabaMakro)] yazdığında merhaba_makro_derive fonksiyonu çağrılır. Bu mümkün olur; çünkü fonksiyonu proc_macro_derive ile işaretleyip trait adımızla aynı olan MerhabaMakro adını verdik. Çoğu yordam tabanlı makro bu geleneği izler.
merhaba_makro_derive önce input içindeki TokenStream’i, yorumlayıp üzerinde işlem yapabileceğimiz bir veri yapısına dönüştürür. Burada syn devreye girer. syn::parse, TokenStream alıp ayrıştırılmış Rust kodunu temsil eden DeriveInput yapısını döndürür. Liste 20-41, struct Krepler; kodunu ayrıştırdığımızda elde ettiğimiz DeriveInput içindeki ilgili kısımları gösteriyor.
DeriveInput {
// --snip--
ident: Ident {
ident: "Krepler",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}DeriveInput örneğiBu yapının alanları, ayrıştırdığımız Rust kodunun ident değeri Krepler olan birim struct olduğunu gösterir. Elbette bu yapıda her türlü Rust kodunu anlatmaya yarayan çok daha fazla alan vardır; ayrıntı için [syn içindeki DeriveInput belgelerine][syn-docs] bakabilirsiniz.
Birazdan impl_merhaba_makro fonksiyonunu tanımlayacağız; işte yeni Rust kodunu burada üreteceğiz. Ama önce önemli bir noktayı görelim: derive makromuzun çıktısı da bir TokenStream olacak. Dönen TokenStream, kullanıcı crate’inin yazdığı koda eklenir. Yani kullanıcı crate’i derlendiğinde, bizim değiştirilmiş TokenStream ile sağladığımız ek işlevselliği kazanır.
Burada syn::parse başarısız olursa merhaba_makro_derive fonksiyonunun paniklemesi için unwrap çağırdığımızı fark etmiş olabilirsiniz. Bunun nedeni yordam tabanlı makroların hata durumunda Result değil TokenStream döndürmek zorunda olmasıdır. Bu örneği basitleştirmek için unwrap kullandık; üretim kodunda neyin yanlış gittiğini daha açık anlatan panic! ya da expect mesajları vermelisiniz.
Artık açıklamalı Rust kodunu TokenStream’den DeriveInput örneğine çevirebiliyoruz. Şimdi, açıklama eklenmiş tür üzerinde MerhabaMakro trait’ini uygulayan kodu üretelim; Liste 20-42 bunu gösteriyor.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(MerhabaMakro)]
pub fn merhaba_makro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_merhaba_makro(&ast)
}
fn impl_merhaba_makro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl MerhabaMakro for #name {
fn merhaba_makro() {
println!("Merhaba, Makro! Benim adım {}!", stringify!(#name));
}
}
};
generated.into()
}MerhabaMakro trait’ini uygulamakast.ident ile açıklama eklenen türün adını taşıyan Ident örneğini alıyoruz. Liste 20-41’deki yapıdan da gördüğünüz gibi, bu fonksiyon Liste 20-37’deki kod üzerinde çalıştığında ident alanının değeri "Krepler" olur. Yani Liste 20-42’deki name değişkeni, ekrana yazdırıldığında "Krepler" olacak Ident örneğini tutar.
quote! makrosu, döndürmek istediğimiz Rust kodunu yazmamızı sağlar. Derleyici, quote! sonucunun doğrudan hâlinden farklı bir şey beklediği için bunu into ile TokenStream’e çeviririz.
quote! çok kullanışlı bir şablon mekanizması da sunar: #name yazdığınızda, bunu name değişkenindeki değerle değiştirir. Hatta normal makrolardaki gibi tekrarlar da yapabilirsiniz. Ayrıntılı anlatım için [ quote crate’i belgelerine][quote-docs] bakın.
Yordam tabanlı makromuzun, kullanıcının açıkladığı tür için MerhabaMakro trait’ini uygulayan kod üretmesini istiyoruz. Bunu #name ile elde ediyoruz. Trait uygulamasında tek fonksiyon merhaba_makro; gövdesi de istediğimiz davranışı içeriyor: Merhaba, Makro! Benim adım yazdırıp ardından açıklanan türün adını ekrana vermek.
Burada kullanılan stringify! makrosu Rust’ın içine gömülüdür. 1 + 2 gibi bir Rust ifadesi alır ve derleme zamanında bunu "1 + 2" gibi string sabitine çevirir. Bu, ifadeyi değerlendirip sonra String’e çeviren format! ya da println!’den farklıdır. #name girdisi düz yazı olarak yazdırılacak bir ifade olabileceğinden stringify! kullanıyoruz. Ayrıca bu, #name’i derleme zamanında string sabitine dönüştürdüğü için ek bellek ayırma da gerektirmez.
Bu noktada, hem merhaba_makro hem merhaba_makro_turet içinde cargo build başarılı olmalıdır. Şimdi bu crate’leri Liste 20-37’deki koda bağlayıp yordam tabanlı makroyu çalışırken görelim. projects dizininizde cargo new krepler ile yeni bir ikili proje oluşturun. krepler crate’inin Cargo.toml dosyasına merhaba_makro ve merhaba_makro_turet bağımlılıklarını eklememiz gerekir. Eğer kendi sürümlerinizi crates.io üstüne yayımlıyorsanız bunlar normal bağımlılık olur; değilse, aşağıdaki gibi path bağımlılığı kullanabilirsiniz:
[dependencies]
merhaba_makro = { path = "../hello_macro" }
merhaba_makro_turet = { path = "../hello_macro/hello_macro_derive" }
Liste 20-37’deki kodu src/main.rs içine koyup cargo run çalıştırın: Merhaba, Makro! Benim adım Krepler! yazdırmalıdır. MerhabaMakro trait uygulaması, krepler crate’inin bunu elle yazmasına gerek kalmadan yordam tabanlı makro tarafından eklendi; #[derive(MerhabaMakro)] bunu sağladı.
Şimdi diğer yordam tabanlı makro türlerinin, özel derive makrolardan nasıl farklılaştığına bakalım.
Öznitelik Benzeri Makrolar
Öznitelik benzeri makrolar, özel derive makrolara benzer. Ama derive özniteliği için kod üretmek yerine yeni öznitelikler tanımlamanıza izin verir. Ayrıca daha esnektir: derive yalnızca struct ve enum üzerinde çalışır; öznitelikler ise fonksiyon gibi başka öğelere de uygulanabilir. Örneğin bir web çerçevesi kullanırken fonksiyonları işaretleyen route adlı özniteliğiniz olduğunu düşünün:
#[route(GET, "/")]
fn index() {Bu #[route] özniteliği çerçevenin sağladığı yordam tabanlı makro olurdu. Tanım fonksiyonunun imzası şöyle görünürdü:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Burada iki TokenStream parametresi var. İlki özniteliğin içeriği için: GET, "/" kısmı. İkincisi ise özniteliğin eklendiği öğenin gövdesi için: burada fn index() {} ve fonksiyonun kalanı.
Bunun dışında, öznitelik benzeri makrolar özel derive makrolarla aynı mantıkta çalışır: proc-macro türünde crate oluşturur ve istediğiniz kodu üreten fonksiyonu yazarsınız.
Fonksiyon Benzeri Makrolar
Fonksiyon benzeri makrolar, görünüşte fonksiyon çağrısı gibi duran makrolardır. macro_rules! makroları gibi fonksiyonlardan daha esnektirler; örneğin bilinmeyen sayıda argüman alabilirler. Ancak macro_rules! makroları yalnızca biraz önce gördüğümüz match benzeri sözdizimiyle tanımlanabilir. Fonksiyon benzeri makrolar ise TokenStream alır ve diğer iki yordam tabanlı makro türü gibi bu TokenStream üzerinde Rust koduyla işlem yapar. Örnek olarak, şöyle çağrılabilecek sql! makrosunu düşünebiliriz:
let sql = sql!(SELECT * FROM posts WHERE id=1);Bu makro, içindeki SQL ifadesini ayrıştırıp sözdizimsel olarak geçerli olup olmadığını denetleyebilir. Bu, macro_rules! makrosunun yapabileceğinden çok daha karmaşık bir işlemdir. sql! makrosu şöyle tanımlanırdı:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Bu tanım, özel derive makrosunun imzasına benzer: parantez içindeki belirteçleri alır, üretmek istediğimiz kodu döndürür.
Özet
Derin bir nefes. Ara sıra kullanacağınız, ama gerektiğinde işinize çok yarayacak bazı Rust özelliklerini artık tanıyorsunuz. Burada birkaç karmaşık konuyu özellikle tanıttık; çünkü hata mesajlarında ya da başkasının kodunda karşınıza çıktıklarında bunları tanıyabilmeniz önemli. Gerektiğinde çözüme ulaşmak için bu bölümü başvuru kaynağı gibi kullanın.
Final Proje: Çok İş Parçacıklı Bir Web Sunucusu Geliştirmek
Uzun bir yol geldik; kitabın sonuna ulaştık. Bu bölümde, son bölümlerde öğrendiğimiz kavramların bir kısmını bir araya getiren son bir projeyi birlikte geliştireceğiz. Aynı zamanda önceki bölümlerden bazı önemli fikirleri de kısaca pekiştireceğiz.
Bu final projesinde, tarayıcıda “Merhaba!” diyen basit bir web sunucusu yazacağız. Hedefimiz, Şekil 21-1’deki gibi görünen bir sayfa üretmek.
Web sunucusunu şu planla oluşturacağız:
- TCP ve HTTP hakkında ihtiyaç duyduğumuz kadar bilgi edinmek
- Bir soket üzerinden TCP bağlantılarını dinlemek
- Az sayıda HTTP isteğini ayrıştırmak
- Geçerli bir HTTP yanıtı oluşturmak
- İş parçacığı havuzu ile sunucunun aktarım kapasitesini artırmak
Şekil 21-1: Finalde birlikte geliştireceğimiz proje
Başlamadan önce iki noktayı belirtelim. Birincisi, burada kullanacağımız yöntem Rust ile web sunucusu geliştirmenin en iyi ya da en pratik yolu değildir. Topluluk üyeleri, crates.io üzerinde üretime uygun pek çok web sunucusu ve iş parçacığı havuzu crate’i yayımlamıştır. Ama bu bölümün amacı sizi hazır çözümü kullanmaya yöneltmek değil, alttaki fikirleri öğretmektir. Rust bir sistem programlama dili olduğu için hangi soyutlama düzeyinde çalışacağımıza biz karar veririz.
İkincisi, bu bölümde async ve await kullanmayacağız. İş parçacığı havuzu kurmak tek başına yeterince büyük bir iştir; buna bir de asenkron çalışma zamanı eklemeyeceğiz. Yine de, burada karşılaşacağımız bazı problemlerde async ve await’in nasıl devreye girebileceğine ara ara değineceğiz. Sonuçta 17. bölümde de belirttiğimiz gibi, birçok asenkron çalışma zamanı işlerini yönetmek için zaten iş parçacığı havuzları kullanır.
Bu nedenle temel HTTP sunucusunu ve iş parçacığı havuzunu elle yazacağız. Böylece ileride kullanabileceğiniz hazır crate’lerin arkasındaki genel yaklaşımı daha sağlam biçimde öğrenmiş olacaksınız.
Tek Kanallı (Single-Threaded) Web Sunucusu Geliştirme
Tek İş Parçacıklı Bir Web Sunucusu Geliştirmek
İşe çalışan, tek iş parçacıklı bir web sunucusuyla başlayacağız. Kod yazmadan önce, web sunucularında karşımıza çıkan iki temel protokole çok kısa bakalım: Aktarım Denetim Protokolü (Transmission Control Protocol, TCP) ve Hiper Metin Aktarım Protokolü (Hypertext Transfer Protocol, HTTP). Bu protokollerin bütün ayrıntıları bu kitabın kapsamı dışında; ama ihtiyacımız olan kadarını bilirsek devam etmek kolay olur.
TCP, verinin bir makineden diğerine nasıl taşındığını anlatan daha düşük seviyeli protokoldür. HTTP ise TCP’nin üstünde çalışır ve istekle yanıtın içeriğini tanımlar. Teknik olarak HTTP başka protokollerle de kullanılabilir; fakat pratikte büyük çoğunlukla TCP üzerinden taşınır. Bu bölümde TCP ve HTTP istek/yanıtlarının ham baytlarıyla doğrudan çalışacağız.
TCP Bağlantısını Dinlemek
Web sunucumuz önce bir TCP bağlantısını dinlemeli. Bunun için standart kütüphanedeki std::net modülünü kullanabiliriz. Önce her zamanki gibi yeni bir proje oluşturalım:
$ cargo new merhaba
Created binary (application) `merhaba` project
$ cd merhaba
Şimdi Liste 21-1’deki kodu src/main.rs içine yazın. Bu kod, yerel 127.0.0.1:7878 adresinde gelen TCP akışlarını dinler. Yeni bir akış geldiğinde de Bağlantı kuruldu! yazar.
use std::net::TcpListener;
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
println!("Bağlantı kuruldu!");
}
}TcpListener ile 127.0.0.1:7878 adresindeki TCP bağlantılarını dinliyoruz. İki nokta üst üste işaretinden önceki bölüm bilgisayarınızın IP adresidir; 7878 ise port numarasıdır. Bu portu iki nedenle seçtik: genelde HTTP trafiği bu portta çalışmaz, dolayısıyla başka bir sunucuyla çakışma ihtimali düşüktür; ayrıca 7878, telefon tuş takımında rust kelimesine karşılık gelir.
Buradaki bind fonksiyonu, anlam olarak new gibidir; yeni bir TcpListener döndürür. Ağ programlamasında bir portu dinlemeye başlamak “bir porta bağlanmak” olarak adlandırıldığı için fonksiyon adı bind’dır.
bind, Result<T, E> döndürür; çünkü bağlanma işlemi başarısız olabilir. Örneğin aynı programdan iki tane açıp aynı portu dinlemeye kalkarsanız biri başarısız olur. Biz burada eğitim amaçlı basit bir sunucu yazdığımız için ayrıntılı hata yönetimi yapmayacağız; hata olursa program dursun diye unwrap kullanacağız.
TcpListener üzerindeki incoming metodu, bize bir akışlar dizisi veren yineleyici döndürür. Daha doğrusu bunlar TcpStream türündeki akışlardır. Tek bir akış, istemciyle sunucu arasındaki açık bağlantıyı temsil eder. İstemcinin bağlanması, sunucunun yanıt üretmesi ve bağlantının kapanması sürecinin tamamına bağlantı deriz. Dolayısıyla istemcinin ne gönderdiğini görmek için TcpStream üzerinden okuyacak, yanıtı geri göndermek için de aynı akışa yazacağız.
Şimdilik yaptığımız tek şey, akışta hata varsa unwrap ile programı durdurmak; hata yoksa ileti yazmak. Bir sonraki listede başarılı durumda daha fazlasını yapacağız.
Bu kodu cargo run ile çalıştırıp tarayıcıda 127.0.0.1:7878 adresini açın. Tarayıcı hata gösterecektir; çünkü sunucu henüz veri döndürmüyor. Ama terminalde birkaç kez Bağlantı kuruldu! yazdığını görmelisiniz.
Bir tarayıcı isteği için birden fazla ileti görmeniz normaldir. Tarayıcı bazen sayfanın kendisine ek olarak sekmedeki küçük simge gibi başka kaynakları da istemeye çalışır. Ayrıca, sunucu henüz geçerli veri dönmediği için bazı tarayıcılar bağlantıyı yeniden denemeye çalışır.
Önemli nokta şu: artık gerçekten bir TCP bağlantısını ele alabiliyoruz.
İsteği Okumak
Sırada tarayıcının gönderdiği isteği okumak var. Bağlantıyı almak ile bağlantı üzerinde iş yapmak sorumluluklarını ayırmak için, bağlantıları işleyecek ayrı bir fonksiyon yazacağız. baglantiyi_isle adlı bu yeni fonksiyonda TCP akışından gelen veriyi okuyup ekrana basacağız. Böylece tarayıcının neler yolladığını görebileceğiz. Kodunuzu Liste 21-2’deki gibi değiştirin.
use std::{
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let http_istegi: Vec<_> = tamponlu_okuyucu
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("İstek: {http_istegi:#?}");
}TcpStream içinden okumak ve gelen veriyi yazdırmakstd::io::BufReader ile std::io::prelude::* öğelerini kapsam içine alıyoruz; çünkü akıştan okuma ve yazma için bunlara ihtiyacımız var. main içindeki for döngüsünde artık ileti yazdırmak yerine yeni baglantiyi_isle fonksiyonunu çağırıp akis değerini ona veriyoruz.
baglantiyi_isle içinde, akis referansını saran bir BufReader oluşturuyoruz. BufReader, std::io::Read trait’i çağrılarını tamponlayarak bize daha rahat bir okuma arayüzü sunar.
Tarayıcının gönderdiği istek satırlarını toplamak için http_istegi adlı bir değişken oluşturuyoruz. Satırları vektörde toplayacağımızı belirtmek için Vec<_> tür açıklamasını ekliyoruz.
BufReader, std::io::BufRead trait’ini uygular; bu trait de lines metodunu verir. lines, her satır sonu görüldüğünde akışı bölen ve Result<String, std::io::Error> döndüren bir yineleyicidir. Her String değerini alabilmek için map içinde unwrap kullanıyoruz. Gerçek bir uygulamada bu hataları daha nazik biçimde ele almak gerekirdi; ama burada örneği sade tutmak istiyoruz.
Tarayıcı, arka arkaya iki yeni satır göndererek HTTP isteğinin bittiğini belirtir. Bu yüzden boş satır gelene kadar satırları alıyoruz. Sonra bunları vektörde toplayıp biçimli hata ayıklama çıktısıyla ekrana yazdırıyoruz.
Programı yeniden çalıştırıp tarayıcıdan bir istek gönderin. Tarayıcı yine hata sayfası gösterecek; ama terminalde buna benzer bir çıktı göreceksiniz:
$ cargo run
Compiling merhaba v0.1.0 (file:///projects/merhaba)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/merhaba`
İstek: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
...
]
Tarayıcınıza göre satırlar biraz farklı olabilir. Ama artık sunucuya hangi HTTP isteğinin geldiğini açıkça görebiliyoruz.
HTTP İsteğine Daha Yakından Bakmak
HTTP metin tabanlı bir protokoldür ve istek genel olarak şu biçimdedir:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
İlk satır istek satırı dır. İstemcinin ne istediğine dair temel bilgiyi taşır. İlk bölüm kullanılan metottur; örneğin GET ya da POST. Tarayıcımız burada GET kullanıyor; yani bilgi istiyor.
Sonraki bölüm istenen URI değeridir. Burada / geliyor; yani kök yol isteniyor. Son bölüm HTTP sürümüdür. Satır da CRLF ile biter. CRLF, daktilo günlerinden gelen carriage return ve line feed ifadelerinin kısaltmasıdır; Rust içinde bunu çoğu zaman \r\n olarak görürüz.
İstek satırından sonra Host: ile başlayan kısım başlıklar bölümüdür. GET isteğinde çoğu zaman gövde bulunmaz.
Şimdi farklı bir adres, örneğin 127.0.0.1:7878/test, isteyip gelen verinin nasıl değiştiğine bakabilirsiniz.
Yanıt Yazmak
Artık tarayıcı isteğini okuyabildiğimize göre istemciye veri de geri gönderebiliriz. HTTP yanıtları kabaca şu biçimdedir:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
İlk satır durum satırı dır. Burada HTTP sürümü, sayısal durum kodu ve metinsel açıklama yer alır.
Örnek olarak, HTTP 1.1 kullanan, durum kodu 200, açıklaması OK olan ve gövdesi bulunmayan minimal bir başarılı yanıt şöyledir:
HTTP/1.1 200 OK\r\n\r\n
Şimdi bunu akışa yazarak istemciye ilk yanıtımızı gönderelim. Liste 21-3’te, baglantiyi_isle fonksiyonu bunu yapıyor.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let http_istegi: Vec<_> = tamponlu_okuyucu
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let yanit = "HTTP/1.1 200 OK\r\n\r\n";
akis.write_all(yanit.as_bytes()).unwrap();
}yanit adlı string’i as_bytes ile baytlara çevirip write_all ile akışa yazıyoruz. Hata durumunda yine unwrap ile ilerliyoruz.
Bu kodla tarayıcı artık hata yerine boş bir sayfa gösterecektir. Yani HTTP isteği alıp geçerli HTTP yanıtı dönmeyi elle başarmış olduk.
Gerçek HTML Döndürmek
Boş sayfa yerine gerçek içerik gösterelim. Projenin kök dizininde, src içinde değil, merhaba.html adlı yeni dosya oluşturun. Liste 21-4 örnek bir içerik gösteriyor.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Merhaba!</title>
</head>
<body>
<h1>Merhaba!</h1>
<p>Rust'tan selam</p>
</body>
</html>
Sunucu bir istek aldığında bu dosyanın içeriğini okuyup yanıt gövdesi olarak ekleyeceğiz. Liste 21-5 bunu gösteriyor.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// --snip--
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let http_istegi: Vec<_> = tamponlu_okuyucu
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let durum_satiri = "HTTP/1.1 200 OK";
let icerik = fs::read_to_string("merhaba.html").unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}Burada fs modülünü de kullanıma ekledik. Dosyayı string olarak okuyup format! ile HTTP yanıtının gövdesine ekliyoruz. Ayrıca geçerli bir HTTP yanıtı olması için Content-Length başlığını da ekliyoruz.
Kodu çalıştırıp tarayıcıyı yenilerseniz artık HTML içeriğinin çizildiğini görmelisiniz.
İsteği Doğrulamak ve Seçici Yanıt Vermek
Şu anda istemci ne isterse istesin, sunucu hep aynı HTML dosyasını döndürüyor. Biraz daha gerçekçi davranıp yalnızca / yoluna doğru biçimde gelen isteğe HTML dönelim; diğer tüm isteklerde hata sayfası gösterelim. Bunun için baglantiyi_isle fonksiyonunu Liste 21-6’daki gibi değiştiriyoruz.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
// --snip--
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
if istek_satiri == "GET / HTTP/1.1" {
let durum_satiri = "HTTP/1.1 200 OK";
let icerik = fs::read_to_string("merhaba.html").unwrap();
let uzunluk = icerik.len();
let yanit = format!(
"{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}"
);
akis.write_all(yanit.as_bytes()).unwrap();
} else {
// some other request
}
}Artık isteğin yalnızca ilk satırını okuyoruz. Tamamını vektöre toplamak yerine next ile ilk öğeyi alıyoruz. istek_satiri, / için gelen GET isteğiyle eşleşiyorsa HTML dosyasını döndürüyoruz; aksi durumda başka bir şey yapacağız.
Şimdi else bloğunu da dolduralım. Liste 21-7, başka her istek için 404 NOT FOUND durum kodu ve hata sayfası döndürüyor.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
if istek_satiri == "GET / HTTP/1.1" {
let durum_satiri = "HTTP/1.1 200 OK";
let icerik = fs::read_to_string("merhaba.html").unwrap();
let uzunluk = icerik.len();
let yanit = format!(
"{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}"
);
akis.write_all(yanit.as_bytes()).unwrap();
// --snip--
} else {
let durum_satiri = "HTTP/1.1 404 NOT FOUND";
let icerik = fs::read_to_string("404.html").unwrap();
let uzunluk = icerik.len();
let yanit = format!(
"{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}"
);
akis.write_all(yanit.as_bytes()).unwrap();
}
}Bu durumda yanıtın gövdesi 404.html dosyasından geliyor. Önce bu dosyayı oluşturmanız gerekir. Liste 21-8 örnek içerik gösteriyor.
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Merhaba!</title>
</head>
<body>
<h1>Hay aksi!</h1>
<p>Üzgünüm, ne istediğinizi anlayamadım.</p>
</body>
</html>
Bu değişikliklerden sonra 127.0.0.1:7878 adresi merhaba.html içeriğini, örneğin 127.0.0.1:7878/foo gibi diğer adresler ise 404.html içeriğini göstermelidir.
Yeniden Düzenleme
Şu an if ile else bloklarında ciddi tekrar var: iki durumda da dosya okuyor ve yanıt yazıyoruz; yalnızca durum satırı ile dosya adı değişiyor. Bunu sadeleştirmek için, farklı olan kısmı bir demet içinde iki değere ayırıp geri kalan ortak kodu tek noktaya toplayabiliriz. Liste 21-9 sonuçta ortaya çıkan sürümü gösteriyor.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
// --snip--
fn baglantiyi_isle(mut akis: TcpStream) {
// --snip--
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = if istek_satiri == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "merhaba.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}if ve else bloklarını yalnızca farklı kodu içerecek şekilde yeniden düzenlemekArtık if ve else, yalnızca durum_satiri ile dosya_adi değerlerini seçiyor. Dosyayı okuma ve yanıt yazma kodu ortak olduğu için dışarı alındı. Böylece iki durum arasındaki fark daha görünür, ortak davranış daha kolay değiştirilebilir hâle geliyor.
Yaklaşık 40 satırlık Rust koduyla, bir isteğe içerik döndüren ve diğer bütün isteklerde 404 veren basit bir web sunucumuz oldu.
Ancak sunucu hâlâ tek iş parçacıklı çalışıyor; yani aynı anda yalnızca tek isteği işleyebiliyor. Şimdi bunun neden sorun olabileceğine bakalım, sonra da iş parçacığı havuzu ile sunucuyu çok iş parçacıklı hâle getirelim.
Tek Kanallıdan Çok Kanallı Sunucuya Geçiş
Tek İş Parçacıklı Sunucudan Çok İş Parçacıklı Sunucuya
Şu anda sunucu istekleri sırayla işliyor. Yani ilk bağlantı bitmeden ikincisine geçemiyor. Kısa süren istekler ile uzun süren istekler karışınca bu yaklaşım verimsiz hâle geliyor. Özellikle uzun süren bir istek geldiğinde, arkasından gelen bütün istekler gereksiz yere beklemek zorunda kalıyor. Önce bu sorunu görünür hâle getireceğiz, sonra çözeceğiz.
Yavaş Bir İsteği Taklit Etmek
Sorunu görmek için /sleep yoluna gelen isteği yapay olarak yavaşlatalım. Liste 21-10, bu istekte yanıt göndermeden önce beş saniye bekleyen sürümü gösteriyor.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// --snip--
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
baglantiyi_isle(akis);
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
// --snip--
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = match &istek_satiri[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "merhaba.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "merhaba.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// --snip--
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}Artık üç durumumuz olduğu için if yerine match kullanıyoruz. istek_satiri dilimini eşleştirerek:
- / isteğinde başarılı sayfayı
- /sleep isteğinde beş saniye bekledikten sonra yine başarılı sayfayı
- diğer bütün isteklerde 404 sayfasını
döndürüyoruz.
Sunucuyu çalıştırıp iki tarayıcı sekmesi açın: biri http://127.0.0.1:7878, diğeri http://127.0.0.1:7878/sleep. Önce /sleep isteğini gönderip sonra / isteğini yenilerseniz, ikinci isteğin de beklemek zorunda kaldığını görürsünüz. Sorun tam olarak bu: tek iş parçacıklı yapı, bağımsız istekleri birbirinin arkasına diziyor.
İş Parçacığı Havuzuyla Aktarım Kapasitesini Artırmak
İş parçacığı havuzu (thread pool), önceden başlatılmış ve görev bekleyen bir iş parçacıkları grubudur. Program yeni görev aldığında, havuzdaki uygun iş parçacıklarından biri bu görevi üstlenir. İşini bitiren iş parçacığı tekrar havuza döner ve yeni görev bekler.
Bu yaklaşım sayesinde bağlantıları eşzamanlı işleyebilir, dolayısıyla sunucunun toplam aktarım kapasitesini artırabiliriz.
Havuzdaki iş parçacığı sayısını küçük bir sabit sayı ile sınırlayacağız. Eğer her istek geldiğinde yeni iş parçacığı oluştursaydık, çok sayıda istek gönderen biri tüm sistem kaynaklarını tüketebilir ve sunucuyu kullanılmaz hâle getirebilirdi.
Biz bunun yerine, sabit sayıda iş parçacığı oluşturup gelen istekleri bu havuza vereceğiz. Havuz bir görev kuyruğu tutacak. Her iş parçacığı bu kuyruktan görev alacak, görevi çalıştıracak ve sonra yeni görev isteyecek. Böylece aynı anda en fazla N istek işlenebilir; burada N, havuzdaki iş parçacığı sayısıdır.
Bu, aktarım kapasitesini artırmanın tek yolu değildir. fork/join, tek iş parçacıklı asenkron G/Ç, çok iş parçacıklı asenkron G/Ç gibi başka modeller de vardır. Ama burada bizim hedefimiz düşük seviyede temel fikri öğrenmek.
Her İstek İçin Ayrı İş Parçacığı Oluşturmak
İlk olarak, sanki her bağlantı için yeni iş parçacığı açacakmışız gibi düşünelim. Bu nihai çözümümüz olmayacak; ama çok iş parçacıklı çalışan ilk sürümü görmek için iyi bir başlangıçtır. Liste 21-11, for döngüsünde her akış için yeni iş parçacığı başlatan kodu gösteriyor.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
thread::spawn(|| {
baglantiyi_isle(akis);
});
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = match &istek_satiri[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "merhaba.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "merhaba.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}Bu sürümü çalıştırıp bir sekmede /sleep, başka sekmelerde / isteği gönderirseniz, kısa isteklerin artık uzun isteği beklemediğini görürsünüz. Ama bu yaklaşımın da sınırı yoktur; istek geldikçe yeni iş parçacığı açılır. Uzun vadede bu sistemi zorlar.
- bölümde gördüğümüz
asyncveawaittam da böyle senaryolarda çok güçlüdür. Ama burada önce iş parçacığı havuzunu elle kuracağız.
Sınırlı Sayıda İş Parçacığı Oluşturmak
Amacımız, thread::spawn ile çok benzer bir arayüze sahip bir iş parçacığı havuzu yazmak. Böylece kodu kullanan taraf için geçiş çok büyük olmaz. Liste 21-12, kullanmak istediğimiz hayali IsParcacigiHavuzu arayüzünü gösteriyor.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
let havuz = IsParcacigiHavuzu::new(4);
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
havuz.calistir(|| {
baglantiyi_isle(akis);
});
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = match &istek_satiri[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "merhaba.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "merhaba.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}IsParcacigiHavuzu arayüzüBurada IsParcacigiHavuzu::new(4) ile dört iş parçacıklı yeni havuz oluşturuyoruz. Ardından havuz.calistir(...) ile her bağlantı için çalıştırılacak kapanışı veriyoruz. Kod henüz derlenmeyecek; ama bu iyi. Derleyicinin yönlendirmesiyle adım adım havuzu oluşturacağız.
Derleyici Yönlendirmeli Geliştirme ile IsParcacigiHavuzu Kurmak
Önce Liste 21-12’deki değişikliği yapıp cargo check çalıştırın. İlk hata, bize bir IsParcacigiHavuzu türü ya da modülü eksik olduğunu söyleyecektir. Güzel; şimdi onu yazalım.
Bu havuz uygulamasının web sunucusundan bağımsız olmasını istiyoruz. Bu yüzden merhaba crate’ini yalnızca ikili crate olmaktan çıkarıp kütüphane crate olarak da kullanalım. src/lib.rs içine Liste 21-13’teki en basit yapıyı ekleyin.
pub struct IsParcacigiHavuzu;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
IsParcacigiHavuzu
}
// --snip--
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}IsParcacigiHavuzu tanımıSonra main.rs içine bu türü kapsam içine alan satırı ekleyin:
use merhaba::IsParcacigiHavuzu;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
let havuz = IsParcacigiHavuzu::new(4);
for akis in dinleyici.incoming() {
let akis = akis.unwrap();
havuz.calistir(|| {
baglantiyi_isle(akis);
});
}
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = match &istek_satiri[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "merhaba.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "merhaba.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}Şimdi derleyici bize new metodunun eksik olduğunu söyleyecek. En basit biçimiyle bunu yazalım:
pub struct IsParcacigiHavuzu;
impl IsParcacigiHavuzu {
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
IsParcacigiHavuzu
}
}Burada boyut için usize kullanıyoruz; çünkü negatif sayıda iş parçacığı zaten anlamlı değildir ve koleksiyon boyutları için Rust’ta doğal tür usize’dır.
Bir sonraki hata, calistir metodunun eksik olduğunu söyleyecek. Şimdilik en basit sürümünü tanımlayalım:
pub struct IsParcacigiHavuzu;
impl IsParcacigiHavuzu {
// --snip--
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
IsParcacigiHavuzu
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}calistir, bir kapanış alıyor. Bu kapanış için FnOnce + Send + 'static sınırını kullanıyoruz. Bunun nedeni, görevi tek seferlik çalıştıracak olmamız, bu görevin başka iş parçacığına aktarılabilmesi gerekmesi ve ömrünün çağıran kapsamdan bağımsız olmasıdır.
Bu noktada kod derlenir; ama havuz henüz hiçbir şey yapmaz. Yine de arayüzün iskeleti hazır.
new İçinde İş Parçacığı Sayısını Doğrulamak
boyut = 0 da usize için geçerli bir değer olduğu hâlde, sıfır iş parçacıklı havuz anlamsızdır. Bu yüzden new içinde assert! ile boyut > 0 kontrolü yapacağız. Liste 21-13’teki belgeli sürüm bunu gösteriyor.
Bu örnekte new panikler. İstersek bunun yerine build adında Result döndüren bir API de tasarlayabilirdik; ama burada sıfır iş parçacıklı havuz oluşturmayı kurtarılamaz hata sayıyoruz.
İş Parçacıklarını Saklayacak Yer Açmak
Şimdi geçerli sayıda iş parçacığı oluşturup bunları havuz içinde saklamamız gerekiyor. thread::spawn bize JoinHandle<T> döndürür. Bizim kapanışlarımız bir değer döndürmeyeceği için bu tür JoinHandle<()> olur.
Liste 21-14, doğrudan iş parçacıklarını tutan vektörlü ilk sürümü gösteriyor.
use std::thread;
pub struct IsParcacigiHavuzu {
is_parcacigis: Vec<thread::JoinHandle<()>>,
}
impl IsParcacigiHavuzu {
// --snip--
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let mut is_parcacigis = Vec::with_capacity(boyut);
for _ in 0..boyut {
// create some is_parcacigis and store them in the vector
}
IsParcacigiHavuzu { is_parcacigis }
}
// --snip--
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}IsParcacigiHavuzu içinde iş parçacıklarını tutacak vektör oluşturmakBu sürüm henüz gerçek iş parçacığı oluşturmuyor; ama yapıyı hazırlıyor.
IsParcacigiHavuzu İçinden İş Parçacığına Kod Göndermek
Asıl zorluk burada başlıyor: thread::spawn, iş parçacığı oluşturulduğu anda çalıştırılacak kod bekler. Oysa biz iş parçacıklarını önceden oluşturup, çalıştıracakları işi daha sonra vermek istiyoruz.
Bunu çözmek için araya yeni bir yapı ekleyeceğiz: Calisan. Her Calisan, bir JoinHandle<()> ve ayırt edici bir kimlik taşıyacak. Böylece:
Calisan,kimlikveJoinHandle<()>tutacakIsParcacigiHavuzu, doğrudan iş parçacıkları yerineCalisanvektörü tutacakCalisan::new, birkimlikalıp boş kapanışla başlatılmış iş parçacığına sahipCalisandöndürecekIsParcacigiHavuzu::new, buCalisanörneklerini oluşturup saklayacak
Liste 21-15 bu düzeni gösteriyor.
use std::thread;
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
}
impl IsParcacigiHavuzu {
// --snip--
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik));
}
IsParcacigiHavuzu { calisanlar }
}
// --snip--
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize) -> Calisan {
let thread = thread::spawn(|| {});
Calisan { kimlik, thread }
}
}Calisan örnekleri tutacak şekilde IsParcacigiHavuzu yapısını değiştirmekIsParcacigiHavuzu içindeki alan adı artık doğrudan iş parçacığı tutmadığı için calisanlar oldu. Calisan ve onun new fonksiyonu dış dünyaya açık değil; bu, havuzun iç ayrıntısı.
Kanallar Üzerinden Görev Göndermek
Şimdi calistir metodunun aldığı kapanışı, önceden çalışan Calisan iş parçacıklarına nasıl ulaştıracağımızı çözmeliyiz. Bunun için 16. bölümde gördüğümüz kanalları kullanacağız.
Fikir şu:
IsParcacigiHavuzu, bir kanal oluşturup gönderici tarafını tutacak- Her
Calisan, alıcı tarafına erişecek - Kapanışları taşımak için
Gorevadlı bir tür tanımlayacağız calistir, gelen görevi kanal üzerinden gönderecek- Her
Calisan, kendi iş parçacığında alıcıyı dinleyip gelen görevi çalıştıracak
Liste 21-16, bu yapının başlangıcını gösteriyor.
use std::{sync::mpsc, thread};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
struct Gorev;
impl IsParcacigiHavuzu {
// --snip--
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik));
}
IsParcacigiHavuzu { calisanlar, gonderici }
}
// --snip--
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize) -> Calisan {
let thread = thread::spawn(|| {});
Calisan { kimlik, thread }
}
}Gorev örneklerini ileten kanalın göndericisini saklayacak biçimde IsParcacigiHavuzu yapısını değiştirmekArdından alıcıyı her Calisan içine geçirmeye çalışıyoruz. Ama bir alıcıyı birden çok Calisan arasında paylaşmak istediğimizde derleyici hata verir; çünkü Rust’ın kanal modeli tek tüketicilidir.
Bu yüzden alıcıyı Arc<Mutex<T>> içine koymamız gerekir. Arc, birden fazla Calisanın aynı alıcıyı paylaşmasını; Mutex ise aynı anda yalnızca bir Calisanın görev çekmesini sağlar. Liste 21-18 bunu gösteriyor.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
struct Gorev;
impl IsParcacigiHavuzu {
// --snip--
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu { calisanlar, gonderici }
}
// --snip--
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
// --snip--
let thread = thread::spawn(|| {
alici;
});
Calisan { kimlik, thread }
}
}Arc ve Mutex kullanarak Calisan örnekleri arasında paylaşmakcalistir Metodunu Uygulamak
Şimdi Gorev türünü, calistir içinde aldığımız kapanışı tutan Box<dyn FnOnce() + Send + 'static> takma adı hâline getirebiliriz. Liste 21-19 bunu yapıyor.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
// --snip--
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
// --snip--
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu { calisanlar, gonderici }
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.send(gorev).unwrap();
}
}
// --snip--
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(|| {
alici;
});
Calisan { kimlik, thread }
}
}Box için Gorev takma adı oluşturmak ve görevi kanal üzerinden göndermekSonrasında, Calisan::new içinde başlatılan iş parçacığının gerçekten görev alıp çalıştırmasını sağlamalıyız. Liste 21-20’de, her Calisanın sürekli olarak kanaldan görev çekip bunları çalıştırdığı sürüm var.
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici,
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.send(gorev).unwrap();
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || loop {
let gorev = alici.lock().unwrap().recv().unwrap();
println!("Çalışan {kimlik} bir görev aldı; çalıştırılıyor.");
gorev();
});
Calisan { kimlik, thread }
}
}Calisan iş parçacığı içinde görevleri alıp çalıştırmakBurada önce lock ile Mutex kilidi alıyoruz, sonra recv ile kanaldan görev bekliyoruz. recv engelleyicidir; yani görev yoksa iş parçacığı bekler. Yeni görev geldiğinde de onu çalıştırır.
Bu noktada havuz artık gerçekten çalışır. cargo run ile çalıştırıp birkaç istek gönderdiğinizde, dört farklı Calisanın sırayla görev aldığını görmelisiniz.
İsterseniz burada durup şunu da düşünebilirsiniz: Eğer kapanış yerine Future çalıştırıyor olsaydık neler farklı olurdu? Hangi türler değişirdi, hangileri aynı kalırdı?
Son olarak, while let kullanarak başka bir yazım biçimi de mümkün. Liste 21-21 bunu gösteriyor; ama orada kilidin yaşam süresi daha uzun kaldığı için tercih etmiyoruz.
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici,
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.send(gorev).unwrap();
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || {
while let Ok(gorev) = alici.lock().unwrap().recv() {
println!("Çalışan {kimlik} bir görev aldı; çalıştırılıyor.");
gorev();
}
});
Calisan { kimlik, thread }
}
}Calisan::new için while let kullanan alternatif uygulamaBu sürümde gorev() çağrısı bitene kadar kilit tutulabildiği için diğer Calisanlar yeni görev alamaz. Bu da istemediğimiz bir darboğaz yaratır.
Zarif Kapanış (Graceful Shutdown) ve Temizlik
Zarif Kapanış ve Temizlik
Liste 21-20’deki kod artık istekleri iş parçacığı havuzu üzerinden eşzamanlı işliyor. Ancak calisanlar, kimlik ve thread gibi alanların dolaylı kullanıldığına dair uyarılar alıyoruz; bu da aslında henüz hiçbir şeyi temizlemediğimizi hatırlatıyor. Ana iş parçacığını kaba biçimde ctrl-C ile durdurduğumuzda, diğer iş parçacıkları da o anda ne yapıyor olurlarsa olsunlar aniden kesiliyor.
Şimdi Drop trait’ini uygulayarak havuzdaki her iş parçacığı üzerinde join çağıracağız. Böylece kapanmadan önce üzerinde çalıştıkları istekleri bitirebilecekler. Sonra da onlara yeni görev almayı bırakıp kapanmaları gerektiğini bildireceğiz.
IsParcacigiHavuzu Üzerinde Drop Uygulamak
İlk adım Drop uygulaması. Havuz kapsam dışına çıktığında, bütün iş parçacıklarının işini bitirip birleşmesini istiyoruz. Liste 21-22 ilk denemeyi gösteriyor.
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici,
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.send(gorev).unwrap();
}
}
impl Drop for IsParcacigiHavuzu {
fn drop(&mut self) {
for calisan in &mut self.calisanlar {
println!("Çalışan kapatılıyor: {}", calisan.kimlik);
calisan.thread.join().unwrap();
}
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || loop {
let gorev = alici.lock().unwrap().recv().unwrap();
println!("Çalışan {kimlik} bir görev aldı; çalıştırılıyor.");
gorev();
});
Calisan { kimlik, thread }
}
}Burada her Calisan üzerinde dönüp onun iş parçacığına join çağırıyoruz. Ama derleyici hata verir; çünkü join, sahiplik alır. Bizde ise yalnızca ödünç alınmış calisan vardır.
Bunu çözmek için iş parçacığını Calisan içinden dışarı taşımamız gerekir. Bunun bir yolu alanı Option<thread::JoinHandle<()>> yapmak ve take ile içinden almak olabilir. Ancak bunu her yerde taşımak kodu gereksiz yere karmaşıklaştırabilir.
Bu bölümde daha temiz bir yaklaşım kullanacağız: Vec::drain. drain(..) ile vektördeki bütün öğeleri dışarı alıp onları tüketebiliriz. Güncel drop uygulaması şöyle görünür:
#![allow(unused)]
fn main() {
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: mpsc::Sender<Gorev>,
}
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici,
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.send(gorev).unwrap();
}
}
impl Drop for IsParcacigiHavuzu {
fn drop(&mut self) {
for calisan in self.calisanlar.drain(..) {
println!("Çalışan kapatılıyor: {}", calisan.kimlik);
calisan.thread.join().unwrap();
}
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || loop {
let gorev = alici.lock().unwrap().recv().unwrap();
println!("Çalışan {kimlik} bir görev aldı; çalıştırılıyor.");
gorev();
});
Calisan { kimlik, thread }
}
}
}Bu sürüm derleyici hatasını çözer. Yine de bir sorun daha var: bu hâliyle kapanış istediğimiz gibi çalışmıyor.
İş Parçacıklarına Yeni Görev Dinlemeyi Bırakmalarını Söylemek
Sorun şu: Calisan iş parçacıkları sonsuz döngü içinde sürekli görev bekliyor. Biz join çağırınca, onlar hâlâ beklediği için ana iş parçacığı sonsuza kadar bloklanabilir.
Bunu düzeltmek için önce gonderici tarafını açıkça düşürmemiz gerekiyor. Kanalın gönderici tarafı kapanınca, recv hata döndürür; bu da alıcı tarafta döngüden çıkma sinyali olarak kullanılabilir.
Liste 21-23, gonderici değerini Option içine alıp drop içinde take() ile kapattığımız sürümü gösteriyor.
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: Option<mpsc::Sender<Gorev>>,
}
// --snip--
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
// --snip--
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici: Some(gonderici),
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.as_ref().unwrap().send(gorev).unwrap();
}
}
impl Drop for IsParcacigiHavuzu {
fn drop(&mut self) {
drop(self.gonderici.take());
for calisan in self.calisanlar.drain(..) {
println!("Çalışan kapatılıyor: {}", calisan.kimlik);
calisan.thread.join().unwrap();
}
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || loop {
let gorev = alici.lock().unwrap().recv().unwrap();
println!("Çalışan {kimlik} bir görev aldı; çalıştırılıyor.");
gorev();
});
Calisan { kimlik, thread }
}
}Calisan iş parçacıklarını birleştirmeden önce gonderici değerini açıkça düşürmekBu değişiklikten sonra kanal kapanır. Böylece Calisan tarafında recv artık hata döndürmeye başlayabilir. Şimdi döngüyü buna göre güncelleyelim. Liste 21-24, recv hata döndürdüğünde döngüden zarif biçimde çıkan sürümü gösteriyor.
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: Option<mpsc::Sender<Gorev>>,
}
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici: Some(gonderici),
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.as_ref().unwrap().send(gorev).unwrap();
}
}
impl Drop for IsParcacigiHavuzu {
fn drop(&mut self) {
drop(self.gonderici.take());
for calisan in self.calisanlar.drain(..) {
println!("Çalışan kapatılıyor: {}", calisan.kimlik);
calisan.thread.join().unwrap();
}
}
}
struct Calisan {
kimlik: usize,
thread: thread::JoinHandle<()>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || loop {
let mesaj = alici.lock().unwrap().recv();
match mesaj {
Ok(gorev) => {
println!(
"Çalışan {kimlik} bir görev aldı; çalıştırılıyor."
);
gorev();
}
Err(_) => {
println!(
"Çalışan {kimlik} bağlantısı kesildi; kapatılıyor."
);
break;
}
}
});
Calisan { kimlik, thread }
}
}recv hata döndürdüğünde döngüden açıkça çıkmakArtık her Calisan, kanalın kapandığını görünce yeni görev beklemeyi bırakır, bir ileti yazar ve döngüden çıkar.
Sunucuyu Sınırlı İstekten Sonra Kapatmak
Bu davranışı gözle görmek için, main fonksiyonunu yalnızca iki isteği kabul edecek şekilde değiştirebiliriz. Liste 21-25 bunu gösteriyor.
use merhaba::IsParcacigiHavuzu;
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
let havuz = IsParcacigiHavuzu::new(4);
for akis in dinleyici.incoming().take(2) {
let akis = akis.unwrap();
havuz.calistir(|| {
baglantiyi_isle(akis);
});
}
println!("Kapatılıyor.");
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = match &istek_satiri[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "merhaba.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "merhaba.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}Gerçek bir web sunucusunun iki istekten sonra kapanmasını istemezsiniz. Buradaki amaç yalnızca zarif kapanışın gerçekten çalıştığını göstermek.
take(2), yineleyicinin en fazla ilk iki öğesini almasını sağlar. main sonlandığında IsParcacigiHavuzu da kapsam dışına çıkar ve drop çalışır.
Sunucuyu cargo run ile başlatıp üç istek gönderirseniz, üçüncü isteğin başarısız olduğunu ve terminalde buna benzer iletiler gördüğünüzü fark edersiniz:
$ cargo run
Compiling merhaba v0.1.0 (file:///projects/merhaba)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/merhaba`
Çalışan 0 bir görev aldı; çalıştırılıyor.
Kapatılıyor.
Çalışan kapatılıyor: 0
Çalışan 3 bir görev aldı; çalıştırılıyor.
Çalışan 1 bağlantısı kesildi; kapatılıyor.
Çalışan 2 bağlantısı kesildi; kapatılıyor.
Çalışan 3 bağlantısı kesildi; kapatılıyor.
Çalışan 0 bağlantısı kesildi; kapatılıyor.
Çalışan kapatılıyor: 1
Çalışan kapatılıyor: 2
Çalışan kapatılıyor: 3
İletilerin sırası sizde farklı olabilir. Ama genel akış şudur:
- İlk iki isteği bazı
Calisanlar alır. - Sunucu artık yeni bağlantı kabul etmeyi bırakır.
drop,gondericideğerini düşürür.- Her
Calisan, kanal kapandığını fark eder ve döngüden çıkar. - Havuz da her iş parçacığı üzerinde
joinçağırıp temiz kapanış yapar.
İlginç bir ayrıntı daha var: ana iş parçacığı, bazı Calisanlar hata alıp döngüden çıkmadan önce ilk join çağrısını yapabilir. Bu durumda kısa süre bloklanır; ama diğer iş parçacıkları işlerini bitirdikçe hepsi sırayla kapanır.
Böylece projemizi tamamlamış olduk. Artık elimizde iş parçacığı havuzu kullanan, istekleri eşzamanlı ele alan ve zarif biçimde kapanabilen temel bir web sunucusu var.
Tam sürüm için aşağıdaki iki dosyaya bakabilirsiniz:
use merhaba::IsParcacigiHavuzu;
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let dinleyici = TcpListener::bind("127.0.0.1:7878").unwrap();
let havuz = IsParcacigiHavuzu::new(4);
for akis in dinleyici.incoming().take(2) {
let akis = akis.unwrap();
havuz.calistir(|| {
baglantiyi_isle(akis);
});
}
println!("Kapatılıyor.");
}
fn baglantiyi_isle(mut akis: TcpStream) {
let tamponlu_okuyucu = BufReader::new(&akis);
let istek_satiri = tamponlu_okuyucu.lines().next().unwrap().unwrap();
let (durum_satiri, dosya_adi) = match &istek_satiri[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "merhaba.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "merhaba.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let icerik = fs::read_to_string(dosya_adi).unwrap();
let uzunluk = icerik.len();
let yanit =
format!("{durum_satiri}\r\nContent-Length: {uzunluk}\r\n\r\n{icerik}");
akis.write_all(yanit.as_bytes()).unwrap();
}use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct IsParcacigiHavuzu {
calisanlar: Vec<Calisan>,
gonderici: Option<mpsc::Sender<Gorev>>,
}
type Gorev = Box<dyn FnOnce() + Send + 'static>;
impl IsParcacigiHavuzu {
/// Yeni bir IsParcacigiHavuzu olusturur.
///
/// Boyut, havuzdaki is parcacigi sayisidir.
///
/// # Panics
///
/// `new` fonksiyonu, boyut sifirsa panikler.
pub fn new(boyut: usize) -> IsParcacigiHavuzu {
assert!(boyut > 0);
let (gonderici, alici) = mpsc::channel();
let alici = Arc::new(Mutex::new(alici));
let mut calisanlar = Vec::with_capacity(boyut);
for kimlik in 0..boyut {
calisanlar.push(Calisan::new(kimlik, Arc::clone(&alici)));
}
IsParcacigiHavuzu {
calisanlar,
gonderici: Some(gonderici),
}
}
pub fn calistir<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let gorev = Box::new(f);
self.gonderici.as_ref().unwrap().send(gorev).unwrap();
}
}
impl Drop for IsParcacigiHavuzu {
fn drop(&mut self) {
drop(self.gonderici.take());
for calisan in &mut self.calisanlar {
println!("Çalışan kapatılıyor: {}", calisan.kimlik);
if let Some(thread) = calisan.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Calisan {
kimlik: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Calisan {
fn new(kimlik: usize, alici: Arc<Mutex<mpsc::Receiver<Gorev>>>) -> Calisan {
let thread = thread::spawn(move || loop {
let mesaj = alici.lock().unwrap().recv();
match mesaj {
Ok(gorev) => {
println!(
"Çalışan {kimlik} bir görev aldı; çalıştırılıyor."
);
gorev();
}
Err(_) => {
println!(
"Çalışan {kimlik} bağlantısı kesildi; kapatılıyor."
);
break;
}
}
});
Calisan {
kimlik,
thread: Some(thread),
}
}
}Bu projeyi geliştirmeye devam etmek isterseniz:
IsParcacigiHavuzuve açık metodlarına daha fazla belge ekleyebilirsiniz.- Kütüphane işlevleri için testler yazabilirsiniz.
unwrapçağrılarını daha sağlam hata yönetimiyle değiştirebilirsiniz.IsParcacigiHavuzunu web sunucusu dışında başka görevlerde kullanabilirsiniz.- crates.io üstündeki hazır bir havuz crate’i ile benzer sunucuyu yeniden yazıp API farklarını inceleyebilirsiniz.
Özet
Kitabın sonuna geldiniz. Artık kendi Rust projelerinizi geliştirecek, başkalarının projelerine katkı verecek ve daha ileri konuları anlamlandıracak temel bilgiye sahipsiniz. Takıldığınız yerde yardım alabileceğiniz, canlı ve destekleyici bir Rust topluluğu da var.
Ekler
Aşağıdaki bölümler, Rust yolculuğunuzda faydalı bulabileceğiniz referans materyalleri içermektedir.
A - Anahtar Kelimeler
Ek A: Anahtar Kelimeler
Aşağıdaki listeler, Rust dili tarafından mevcut veya gelecekteki kullanım için ayrılmış olan anahtar kelimeleri (keywords) içerir. Bu nedenle, tanımlayıcı (identifier) olarak kullanılamazlar (ancak “Ham Tanımlayıcılar” bölümünde tartışacağımız gibi ham tanımlayıcılar (raw identifiers) olarak kullanılabilirler). Tanımlayıcılar (Identifiers); fonksiyonların, değişkenlerin, parametrelerin, struct alanlarının, modüllerin, crate’lerin, sabitlerin (constants), makroların, statik değerlerin, niteliklerin (attributes), türlerin, trait’lerin veya ömürlerin isimleridir.
Şu Anda Kullanımda Olan Anahtar Kelimeler
Aşağıda, şu anda kullanımda olan anahtar kelimelerin işlevleriyle birlikte listesi verilmiştir.
as: İlkel tür dönüştürme (primitive casting) yapar, bir öğeyi içeren belirli trait’in belirsizliğini giderir veyauseifadelerinde öğeleri yeniden adlandırır.async: Mevcut thread’i (iş parçacığını) bloke etmek yerine birFuturedöndürür.await: BirFuture’ın sonucu hazır olana kadar yürütmeyi askıya alır.break: Bir döngüden anında çıkar.const: Sabit (constant) öğeleri veya sabit ham işaretçileri (raw pointers) tanımlar.continue: Bir sonraki döngü iterasyonuna atlar.crate: Bir modül yolunda (path), crate kökünü (root) ifade eder.dyn: Bir trait nesnesine dinamik dağıtım (dynamic dispatch) yapar.else:ifveif letkontrol akışı yapılarında, koşulun sağlanmadığı durumlar için (fallback) kullanılır.enum: Bir numaralandırma (enumeration) tanımlar.extern: Harici bir fonksiyonu veya değişkeni bağlar (link).false: Boolean yanlış (false) literali.fn: Bir fonksiyon veya fonksiyon işaretçisi türünü tanımlar.for: Bir iteratörden gelen öğeler üzerinde döngü oluşturur, bir trait’i uygular veya daha yüksek dereceli (higher ranked) bir ömrü belirtir.if: Bir koşullu ifadenin sonucuna göre dallanma (branch) yapar.impl: Doğal (inherent) veya bir trait işlevselliğini uygular.in:fordöngüsü sözdiziminin bir parçasıdır.let: Bir değişkeni bağlar (bind).loop: Koşulsuz olarak döngü oluşturur.match: Bir değeri desenlerle (patterns) eşleştirir.mod: Bir modül tanımlar.move: Bir closure’ın (kapanışın) yakaladığı tüm değerlerin sahipliğini almasını sağlar.mut: Referanslarda, ham işaretçilerde (raw pointers) veya desen bağlamalarında değiştirilebilirliği (mutability) belirtir.pub: Struct alanlarında,implbloklarında veya modüllerde genel görünürlüğü belirtir.ref: Referans olarak bağlar.return: Fonksiyondan dönüş yapar.Self: Tanımladığımız veya uyguladığımız tür için bir tür takma adı (type alias).self: Metot öznesi veya mevcut modül.static: Tüm program yürütmesi boyunca süren küresel değişken (global variable) veya ömür.struct: Bir yapı tanımlar.super: Mevcut modülün üst modülü.trait: Bir trait tanımlar.true: Boolean doğru (true) literali.type: Bir tür takma adı (type alias) veya ilişkili tür (associated type) tanımlar.union: Bir union tanımlar; yalnızca bir union bildirimi (declaration) içinde kullanıldığında anahtar kelimedir.unsafe: Güvenli olmayan (unsafe) kodu, fonksiyonları, trait’leri veya implementasyonları belirtir.use: Sembolleri kapsama dahil eder.where: Bir türü kısıtlayan yan tümceleri (clauses) belirtir.while: Bir ifadenin sonucuna göre koşullu olarak döngü oluşturur.
Gelecekteki Kullanım İçin Ayrılmış Anahtar Kelimeler
Aşağıdaki anahtar kelimelerin henüz herhangi bir işlevi yoktur, ancak potansiyel gelecekteki kullanım için Rust tarafından ayrılmıştır:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Ham Tanımlayıcılar (Raw Identifiers)
Ham tanımlayıcılar (raw identifiers), normalde izin verilmeyen yerlerde anahtar kelimeleri kullanmanızı sağlayan bir sözdizimidir (syntax). Bir anahtar kelimenin önüne r# ekleyerek bir ham tanımlayıcı kullanırsınız.
Örneğin, match bir anahtar kelimedir. Adı olarak match’i kullanan aşağıdaki fonksiyonu derlemeye çalışırsanız:
Dosya Adı: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}şu hatayı alırsınız:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Hata, match anahtar kelimesini fonksiyon tanımlayıcısı olarak kullanamayacağınızı gösteriyor. match kelimesini bir fonksiyon adı olarak kullanmak için, aşağıdaki gibi ham tanımlayıcı sözdizimini kullanmanız gerekir:
Dosya Adı: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}Bu kod hiçbir hata olmadan derlenecektir. Fonksiyon adının tanımındaki ve fonksiyonun main içinde çağrıldığı yerdeki r# ön ekine dikkat edin.
Ham tanımlayıcılar, rezerve edilmiş bir anahtar kelime olsa bile, seçtiğiniz herhangi bir kelimeyi tanımlayıcı olarak kullanmanıza olanak tanır. Bu, tanımlayıcı adlarını seçme konusunda bize daha fazla özgürlük vermenin yanı sıra, bu kelimelerin anahtar kelime olmadığı bir dilde yazılmış programlarla entegre olmamızı sağlar. Ek olarak, ham tanımlayıcılar, crate’inizin kullandığından farklı bir Rust sürümünde (edition) yazılmış kütüphaneleri kullanmanıza olanak tanır. Örneğin, try 2015 sürümünde bir anahtar kelime değildir, ancak 2018, 2021 ve 2024 sürümlerinde bir anahtar kelimedir. 2015 sürümü kullanılarak yazılmış ve bir try fonksiyonu olan bir kütüphaneye bağımlıysanız, daha sonraki sürümlerde o fonksiyonu kodunuzdan çağırmak için ham tanımlayıcı sözdizimini, bu durumda r#try’ı kullanmanız gerekecektir. Sürümler (editions) hakkında daha fazla bilgi için Ek E’ye bakın.
B - Operatörler ve Semboller
Ek B: Operatörler ve Semboller
Bu ek, operatörler ve tek başlarına veya yollar (paths), jenerikler, trait sınırları, makrolar, nitelikler (attributes), yorumlar, demetler (tuples) ve parantezler bağlamında ortaya çıkan diğer semboller dahil olmak üzere Rust’ın sözdizimi (syntax) sözlüğünü içerir.
Operatörler
Tablo B-1, Rust’taki operatörleri, operatörün bağlam içinde nasıl görüneceğine dair bir örneği, kısa bir açıklamayı ve bu operatörün aşırı yüklenebilir (overloadable) olup olmadığını içerir. Bir operatör aşırı yüklenebiliyorsa, o operatörü aşırı yüklemek için kullanılacak ilgili trait listelenmiştir.
Tablo B-1: Operatörler
| Operatör | Örnek | Açıklama | Aşırı Yüklenebilir mi? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Makro genişletmesi (Macro expansion) | |
! | !expr | Bit düzeyinde (bitwise) veya mantıksal tümleme (complement) | Not |
!= | expr != expr | Eşitsizlik karşılaştırması | PartialEq |
% | expr % expr | Aritmetik kalan (mod alma) | Rem |
%= | var %= expr | Aritmetik kalan ve atama | RemAssign |
& | &expr, &mut expr | Ödünç alma (Borrow) | |
& | &type, &mut type, &'a type, &'a mut type | Ödünç alınan işaretçi türü (Borrowed pointer type) | |
& | expr & expr | Bit düzeyinde VE (AND) | BitAnd |
&= | var &= expr | Bit düzeyinde VE ve atama | BitAndAssign |
&& | expr && expr | Kısa devre (Short-circuiting) mantıksal VE | |
* | expr * expr | Aritmetik çarpma | Mul |
*= | var *= expr | Aritmetik çarpma ve atama | MulAssign |
* | *expr | Referansı kaldırma (Dereference) | Deref |
* | *const type, *mut type | Ham işaretçi (Raw pointer) | |
+ | trait + trait, 'a + trait | Bileşik tür kısıtlaması (Compound type constraint) | |
+ | expr + expr | Aritmetik toplama | Add |
+= | var += expr | Aritmetik toplama ve atama | AddAssign |
, | expr, expr | Argüman ve eleman ayırıcı | |
- | - expr | Aritmetik negatifleme (negation) | Neg |
- | expr - expr | Aritmetik çıkarma | Sub |
-= | var -= expr | Aritmetik çıkarma ve atama | SubAssign |
-> | fn(...) -> type, |…| -> type | Fonksiyon ve closure dönüş türü | |
. | expr.ident | Alan (field) erişimi | |
. | expr.ident(expr, ...) | Metot çağrısı | |
. | expr.0, expr.1 ve benzeri | Demet (Tuple) indeksleme | |
.. | .., expr.., ..expr, expr..expr | Sağdan dışlayıcı (Right-exclusive) aralık literali | PartialOrd |
..= | ..=expr, expr..=expr | Sağdan kapsayıcı (Right-inclusive) aralık literali | PartialOrd |
.. | ..expr | Struct literali güncelleme sözdizimi | |
.. | variant(x, ..), struct_type { x, .. } | “Ve geri kalanı” desen bağlaması (pattern binding) | |
... | expr...expr | (Kullanımdan kaldırıldı, yerine ..= kullanın) Bir desende: kapsayıcı aralık deseni | |
/ | expr / expr | Aritmetik bölme | Div |
/= | var /= expr | Aritmetik bölme ve atama | DivAssign |
: | pat: type, ident: type | Kısıtlamalar (Constraints) | |
: | ident: expr | Struct alanı başlatıcısı (initializer) | |
: | 'a: loop {...} | Döngü etiketi (Loop label) | |
; | expr; | İfade (statement) ve öğe sonlandırıcı | |
; | [...; len] | Sabit boyutlu dizi (fixed-size array) sözdiziminin bir parçası | |
<< | expr << expr | Sola kaydırma (Left-shift) | Shl |
<<= | var <<= expr | Sola kaydırma ve atama | ShlAssign |
< | expr < expr | Küçüktür karşılaştırması | PartialOrd |
<= | expr <= expr | Küçük veya eşittir karşılaştırması | PartialOrd |
= | var = expr, ident = type | Atama/denklik (Assignment/equivalence) | |
== | expr == expr | Eşitlik karşılaştırması | PartialEq |
=> | pat => expr | match kolu sözdiziminin bir parçası | |
> | expr > expr | Büyüktür karşılaştırması | PartialOrd |
>= | expr >= expr | Büyük veya eşittir karşılaştırması | PartialOrd |
>> | expr >> expr | Sağa kaydırma (Right-shift) | Shr |
>>= | var >>= expr | Sağa kaydırma ve atama | ShrAssign |
@ | ident @ pat | Desen bağlama (Pattern binding) | |
^ | expr ^ expr | Bit düzeyinde özel VEYA (XOR) | BitXor |
^= | var ^= expr | Bit düzeyinde özel VEYA ve atama | BitXorAssign |
| | pat | pat | Desen alternatifleri | |
| | expr | expr | Bit düzeyinde VEYA (OR) | BitOr |
|= | var |= expr | Bit düzeyinde VEYA ve atama | BitOrAssign |
|| | expr || expr | Kısa devre mantıksal VEYA | |
? | expr? | Hata yayılımı (Error propagation) |
Operatör Olmayan Semboller (Non-operator Symbols)
Aşağıdaki tablolar, operatör olarak işlev görmeyen; yani bir fonksiyon veya metot çağrısı gibi davranmayan tüm sembolleri içerir.
Tablo B-2, tek başlarına görünen ve çeşitli yerlerde geçerli olan sembolleri gösterir.
Tablo B-2: Bağımsız Sözdizimi (Stand-alone Syntax)
| Sembol | Açıklama |
|---|---|
'ident | Adlandırılmış ömür (Named lifetime) veya döngü etiketi |
Hemen ardından u8, i32, f64, usize vb. gelen rakamlar | Belirli bir türün sayısal literali |
"..." | Dize literali (String literal) |
r"...", r#"..."#, r##"..."## ve benzeri | Ham dize literali (Raw string literal); kaçış karakterleri (escape characters) işlenmez |
b"..." | Bayt dize literali (Byte string literal); bir dize yerine bayt dizisi oluşturur |
br"...", br#"..."#, br##"..."## ve benzeri | Ham bayt dize literali; ham ve bayt dize literalinin birleşimi |
'...' | Karakter literali (Character literal) |
b'...' | ASCII bayt literali |
|…| expr | Kapanış (Closure) |
! | Iraksayan (diverging) fonksiyonlar için her zaman boş taban türü (bottom type) |
_ | “Görmezden gelinen” (Ignored) desen bağlaması; ayrıca tamsayı literallerini okunabilir yapmak için de kullanılır |
Tablo B-3, modül hiyerarşisinde bir öğeye giden bir yol (path) bağlamında görünen sembolleri gösterir.
Tablo B-3: Yolla İlgili Sözdizimi (Path-Related Syntax)
| Sembol | Açıklama |
|---|---|
ident::ident | Ad alanı yolu (Namespace path) |
::path | Crate köküne (root) göreceli yol (yani açıkça mutlak bir yol - absolute path) |
self::path | Mevcut modüle göreceli yol (yani açıkça göreceli bir yol - relative path) |
super::path | Mevcut modülün üst modülüne göreceli yol |
type::ident, <type as trait>::ident | İlişkili sabitler, fonksiyonlar ve türler |
<type>::... | Doğrudan adlandırılamayan bir tür için ilişkili öğe (örneğin, <&T>::..., <[T]>::... vb.) |
trait::method(...) | Bir metot çağrısının belirsizliğini (disambiguating), onu tanımlayan trait’i adlandırarak giderme |
type::method(...) | Bir metot çağrısının belirsizliğini, tanımlandığı türü adlandırarak giderme |
<type as trait>::method(...) | Bir metot çağrısının belirsizliğini trait ve türü adlandırarak giderme |
Tablo B-4, jenerik (generic) tür parametrelerinin kullanıldığı bağlamlarda görünen sembolleri gösterir.
Tablo B-4: Jenerikler (Generics)
| Sembol | Açıklama |
|---|---|
path<...> | Bir türdeki jenerik bir türe parametreleri belirtir (örneğin, Vec<u8>) |
path::<...>, method::<...> | Bir ifadedeki jenerik bir türe, fonksiyona veya metoda parametreleri belirtir; genellikle turbofish olarak adlandırılır (örneğin, "42".parse::<i32>()) |
fn ident<...> ... | Jenerik fonksiyon tanımlar |
struct ident<...> ... | Jenerik struct (yapı) tanımlar |
enum ident<...> ... | Jenerik enum (numaralandırma) tanımlar |
impl<...> ... | Jenerik implementasyon tanımlar |
for<...> type | Daha yüksek dereceli (Higher ranked) ömür sınırları |
type<ident=type> | Bir veya daha fazla ilişkili türün belirli atamaları olduğu jenerik bir tür (örneğin, Iterator<Item=T>) |
Tablo B-5, jenerik tür parametrelerinin trait sınırlarıyla kısıtlandığı bağlamlarda görünen sembolleri gösterir.
Tablo B-5: Trait Sınırı Kısıtlamaları (Trait Bound Constraints)
| Sembol | Açıklama |
|---|---|
T: U | Jenerik parametre T, U’yu uygulayan türlerle kısıtlanmıştır |
T: 'a | Jenerik tür T, 'a ömründen daha uzun yaşamalıdır (outlive) (yani tür, geçişli olarak 'a’dan daha kısa ömürlü referanslar içeremez) |
T: 'static | Jenerik tür T, 'static olanlar dışında ödünç alınmış referans içermez |
'b: 'a | Jenerik ömür 'b, 'a ömründen daha uzun yaşamalıdır |
T: ?Sized | Jenerik tür parametresinin dinamik olarak boyutlandırılmış bir tür (dynamically sized type) olmasına izin verir |
'a + trait, trait + trait | Bileşik tür kısıtlaması (Compound type constraint) |
Tablo B-6, makroların çağrıldığı veya tanımlandığı ve bir öğe üzerinde niteliklerin (attributes) belirtildiği bağlamlarda görünen sembolleri gösterir.
Tablo B-6: Makrolar ve Nitelikler (Macros and Attributes)
| Sembol | Açıklama |
|---|---|
#[meta] | Dış nitelik (Outer attribute) |
#![meta] | İç nitelik (Inner attribute) |
$ident | Makro yer değiştirmesi (substitution) |
$ident:kind | Makro meta-değişkeni (metavariable) |
$(...)... | Makro tekrarı (repetition) |
ident!(...), ident!{...}, ident![...] | Makro çağrısı (invocation) |
Tablo B-7, yorum (comment) oluşturan sembolleri gösterir.
Tablo B-7: Yorumlar (Comments)
| Sembol | Açıklama |
|---|---|
// | Satır yorumu |
//! | İç satır dokümantasyon yorumu (Inner line doc comment) |
/// | Dış satır dokümantasyon yorumu (Outer line doc comment) |
/*...*/ | Blok yorumu |
/*!...*/ | İç blok dokümantasyon yorumu (Inner block doc comment) |
/**...*/ | Dış blok dokümantasyon yorumu (Outer block doc comment) |
Tablo B-8, parantezlerin (parentheses) kullanıldığı bağlamları gösterir.
Tablo B-8: Parantezler (Parentheses)
| Sembol | Açıklama |
|---|---|
() | Boş demet (aka birim - unit), hem literal hem de tür olarak |
(expr) | Parantez içine alınmış ifade (Parenthesized expression) |
(expr,) | Tek elemanlı demet ifadesi |
(type,) | Tek elemanlı demet türü |
(expr, ...) | Demet ifadesi |
(type, ...) | Demet türü |
expr(expr, ...) | Fonksiyon çağrısı ifadesi; ayrıca tuple struct’larını ve tuple enum varyantlarını başlatmak için de kullanılır |
Tablo B-9, süslü parantezlerin (curly brackets) kullanıldığı bağlamları gösterir.
Tablo B-9: Süslü Parantezler (Curly Brackets)
| Bağlam | Açıklama |
|---|---|
{...} | Blok ifadesi |
Type {...} | Struct literali |
Tablo B-10, köşeli parantezlerin (square brackets) kullanıldığı bağlamları gösterir.
Tablo B-10: Köşeli Parantezler (Square Brackets)
| Bağlam | Açıklama |
|---|---|
[...] | Dizi (Array) literali |
[expr; len] | expr’nin len kadar kopyasını içeren dizi literali |
[type; len] | type’ın len kadar örneğini içeren dizi türü |
expr[expr] | Koleksiyon (Collection) indeksleme; aşırı yüklenebilir (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Koleksiyon indekslemesinin koleksiyon dilimlemeymiş (slicing) gibi davranması, indeks olarak Range, RangeFrom, RangeTo veya RangeFull kullanımı |
C - Türetilebilir Trait'ler
Ek C: Türetilebilir Trait’ler
Kitabın çeşitli yerlerinde, bir struct veya enum tanımına uygulayabileceğiniz derive niteliğinden (attribute) bahsettik. derive niteliği, derive sözdizimi ile açıklamalı (annotated) hale getirdiğiniz tür üzerinde, kendi varsayılan uygulamasıyla (default implementation) birlikte bir trait’i uygulayacak kodu üretir.
Bu ekte, standart kütüphanedeki derive ile kullanabileceğiniz tüm trait’lerin bir referansını sunuyoruz. Her bölüm şunları kapsar:
- Bu trait’i türetmenin (deriving) hangi operatörleri ve metotları etkinleştireceği
derivetarafından sağlanan trait uygulamasının ne yaptığı- Trait’i uygulamanın, tür hakkında ne anlama geldiği
- Trait’i uygulamanıza izin verilen veya verilmeyen koşullar
- Trait’i gerektiren işlem örnekleri
Eğer derive niteliği tarafından sağlanan davranıştan farklı bir davranış istiyorsanız, bunları manuel olarak nasıl uygulayacağınızla ilgili ayrıntılar için her bir trait’in standart kütüphane dokümantasyonuna başvurun.
Burada listelenen trait’ler, derive kullanılarak kendi türlerinizde uygulanabilen, standart kütüphane tarafından tanımlanmış yegane trait’lerdir. Standart kütüphanede tanımlanan diğer trait’lerin mantıklı bir varsayılan davranışı yoktur, bu nedenle onları başarmaya çalıştığınız şeye uygun şekilde uygulamak size kalmıştır.
Türetilemeyen (cannot be derived) bir trait örneği, son kullanıcılar için formatlamayı yöneten Display trait’idir. Bir türü son kullanıcıya uygun şekilde göstermenin yolunu her zaman düşünmelisiniz. Türün hangi kısımlarını son kullanıcının görmesine izin verilmeli? Hangi kısımlarını ilgili bulurlar? Verilerin hangi formatı onlar için en uygun olurdu? Rust derleyicisi bu öngörüye sahip değildir, bu yüzden sizin için uygun varsayılan davranışı sağlayamaz.
Bu ekte sağlanan türetilebilir (derivable) trait’lerin listesi kapsamlı değildir: Kütüphaneler kendi trait’leri için derive uygulayabilir, bu da derive ile kullanabileceğiniz trait listesini gerçekten ucu açık hale getirir. derive uygulamak (implementing), Bölüm 20’deki “Özel derive Makroları” kısmında ele alınan prosedürel makroları (procedural macros) kullanmayı içerir.
Programcı Çıktısı İçin Debug
Debug trait’i, {} yer tutucuları içine :? ekleyerek belirttiğiniz format dizelerinde (format strings) hata ayıklama formatlamasını (debug formatting) etkinleştirir.
Debug trait’i, hata ayıklama amacıyla bir türün örneklerini yazdırmanıza olanak tanır, böylece siz ve türünüzü kullanan diğer programcılar, bir programın yürütülmesindeki belirli bir noktada bir örneği inceleyebilirsiniz.
Debug trait’i, örneğin assert_eq! makrosunun kullanımında gereklidir. Bu makro, eğer eşitlik iddiası (equality assertion) başarısız olursa, programcıların iki örneğin neden eşit olmadığını görebilmeleri için argüman olarak verilen örneklerin değerlerini yazdırır.
Eşitlik Karşılaştırmaları İçin PartialEq ve Eq
PartialEq trait’i, eşitliği kontrol etmek için bir türün örneklerini karşılaştırmanıza olanak tanır ve == ile != operatörlerinin kullanımını etkinleştirir.
PartialEq türetmek (deriving), eq metodunu uygular. PartialEq struct’larda türetildiğinde, iki örnek yalnızca tüm alanlar (fields) eşitse eşittir ve eğer herhangi bir alan eşit değilse örnekler eşit değildir. Enum’larda türetildiğinde, her varyant kendine eşittir ve diğer varyantlara eşit değildir.
PartialEq trait’i, örneğin, eşitlik için bir türün iki örneğini karşılaştırması gereken assert_eq! makrosunun kullanımıyla gereklidir.
Eq trait’inin hiçbir metodu yoktur. Amacı, açıklama eklenmiş türün (annotated type) her değeri için, değerin kendisine eşit olduğunu bildirmektir. Eq trait’i yalnızca aynı zamanda PartialEq uygulayan türlere uygulanabilir, ancak PartialEq uygulayan tüm türler Eq uygulayamaz. Bunun bir örneği kayan noktalı sayı (floating-point number) türleridir: Kayan noktalı sayıların uygulaması, sayı değil (NaN - not-a-number) değerinin iki örneğinin birbirine eşit olmadığını belirtir.
Eq’in gerekli olduğu bir duruma örnek olarak, HashMap<K, V>’nin iki anahtarın aynı olup olmadığını anlayabilmesi için bir HashMap<K, V>’deki anahtarlar (keys) verilebilir.
Sıralama Karşılaştırmaları İçin PartialOrd ve Ord
PartialOrd trait’i, sıralama amacıyla bir türün örneklerini karşılaştırmanıza olanak tanır. PartialOrd uygulayan bir tür <, >, <= ve >= operatörleriyle kullanılabilir. PartialOrd trait’ini yalnızca aynı zamanda PartialEq uygulayan türlere uygulayabilirsiniz.
PartialOrd türetmek, verilen değerler bir sıralama üretmediğinde None olacak bir Option<Ordering> döndüren partial_cmp metodunu uygular. O türdeki çoğu değer karşılaştırılabilmesine rağmen sıralama üretmeyen bir değere örnek, NaN kayan noktalı değeridir. Herhangi bir kayan noktalı sayı ve NaN kayan noktalı değeri ile partial_cmp çağırmak None döndürecektir.
Struct’larda türetildiğinde, PartialOrd iki örneği, her bir alandaki değeri struct tanımında göründükleri sıraya göre karşılaştırarak karşılaştırır. Enum’larda türetildiğinde, enum tanımında daha önce bildirilen (declared) enum varyantlarının, daha sonra listelenen varyantlardan daha küçük olduğu kabul edilir.
PartialOrd trait’i, örneğin, rand crate’inden gelen ve bir aralık ifadesi (range expression) tarafından belirtilen aralıkta rastgele bir değer üreten gen_range metodu için gereklidir.
Ord trait’i, açıklama eklenmiş türün (annotated type) herhangi iki değeri için geçerli (valid) bir sıralama var olacağını bilmenizi sağlar. Ord trait’i, her zaman geçerli bir sıralama mümkün olacağı için Option<Ordering> yerine Ordering döndüren cmp metodunu uygular. Ord trait’ini yalnızca aynı zamanda PartialOrd ve Eq uygulayan türlere uygulayabilirsiniz (Eq de PartialEq gerektirir). Struct’lar ve enum’larda türetildiğinde, cmp, partial_cmp için türetilen uygulamanın (derived implementation) PartialOrd ile aynı şekilde davranır.
Ord’un gerekli olduğu duruma örnek olarak, verileri değerlerin sıralama düzenine (sort order) göre saklayan bir veri yapısı olan BTreeSet<T>’de değerleri saklamak verilebilir.
Değerleri Kopyalamak İçin Clone ve Copy
Clone trait’i, bir değerin derin kopyasını (deep copy) açıkça oluşturmanıza olanak tanır ve çoğaltma (duplication) süreci keyfi kod (arbitrary code) çalıştırmayı ve heap verilerini kopyalamayı içerebilir. Clone hakkında daha fazla bilgi için Bölüm 4’teki “Clone ile Etkileşime Giren Değişkenler ve Veriler” kısmına bakın.
Clone türetmek (deriving), tüm tür için uygulandığında türün parçalarının her birinde clone çağıran clone metodunu uygular. Bu, Clone türetmek için türdeki tüm alanların veya değerlerin de Clone uygulaması (implement Clone) gerektiği anlamına gelir.
Clone’un gerekli olduğu duruma bir örnek, bir dilim (slice) üzerinde to_vec metodunu çağırmaktır. Dilim, içerdiği tür örneklerine sahip değildir, ancak to_vec’den döndürülen vektörün kendi örneklerine sahip olması gerekecektir, bu nedenle to_vec her öğe üzerinde clone çağırır. Böylece, dilimde saklanan tür Clone uygulamalıdır.
Copy trait’i, bir değeri yalnızca yığında (stack) saklanan bitleri kopyalayarak çoğaltmanıza olanak tanır; keyfi bir kod gerekli değildir. Copy hakkında daha fazla bilgi için Bölüm 4’teki “Yalnızca Yığın Verileri: Copy” kısmına bakın.
Copy trait’i, programcıların bu metotları aşırı yüklemesini (overloading) ve keyfi hiçbir kodun çalıştırılmadığı varsayımını ihlal etmesini önlemek için hiçbir metot tanımlamaz. Bu sayede tüm programcılar bir değeri kopyalamanın çok hızlı olacağını varsayabilir.
Tüm parçaları Copy uygulayan (implement Copy) herhangi bir tür üzerinde Copy türetebilirsiniz (derive). Copy uygulayan bir tür, Clone’u da uygulamalıdır, çünkü Copy uygulayan bir tür, Copy ile aynı görevi yerine getiren önemsiz (trivial) bir Clone uygulamasına sahiptir.
Copy trait’i nadiren zorunludur; Copy uygulayan türlerin optimizasyonları mevcuttur, yani clone çağırmak zorunda kalmazsınız, bu da kodu daha öz hale getirir.
Copy ile mümkün olan her şeyi Clone ile de başarabilirsiniz, ancak kod daha yavaş olabilir veya yer yer clone kullanmak zorunda kalabilir.
Bir Değeri Sabit Boyutlu Bir Değerle Eşlemek İçin Hash
Hash trait’i, rastgele boyuttaki (arbitrary size) bir türün örneğini almanıza ve bu örneği bir hash (karma) fonksiyonu kullanarak sabit boyutlu bir değerle eşlemenize olanak tanır. Hash türetmek hash metodunu uygular. hash metodunun türetilen uygulaması, türün parçalarının her birinde hash çağrısının sonucunu birleştirir, bu da Hash türetmek için tüm alanların veya değerlerin de Hash uygulaması gerektiği anlamına gelir.
Hash’in gerekli olduğu duruma bir örnek, verileri verimli bir şekilde saklamak için bir HashMap<K, V>’de anahtarları saklamaktır.
Varsayılan Değerler İçin Default
Default trait’i, bir tür için varsayılan (default) bir değer oluşturmanıza olanak tanır. Default türetmek default fonksiyonunu uygular. default fonksiyonunun türetilen uygulaması (derived implementation), türün her bir parçasında default fonksiyonunu çağırır, bu da Default türetmek için türdeki tüm alanların veya değerlerin de Default uygulaması gerektiği anlamına gelir.
Default::default fonksiyonu, genellikle Bölüm 5’teki “Struct Güncelleme Sözdizimi ile Diğer Örneklerden Örnekler Oluşturma” kısmında tartışılan struct güncelleme sözdizimi ile birlikte kullanılır. Bir struct’ın birkaç alanını özelleştirebilir ve ardından ..Default::default() kullanarak alanların geri kalanı için varsayılan bir değeri ayarlayabilir ve kullanabilirsiniz.
Örneğin, Option<T> örneklerinde unwrap_or_default metodunu kullandığınızda Default trait’i gereklidir. Eğer Option<T> None ise, unwrap_or_default metodu, Option<T> içinde saklanan T türü için Default::default sonucunu döndürecektir.
D - Faydalı Geliştirme Araçları
Ek D: Faydalı Geliştirme Araçları
Bu ekte, Rust projesinin sağladığı bazı faydalı geliştirme araçlarından bahsedeceğiz. Otomatik formatlama, uyarı düzeltmelerini hızlıca uygulamanın yolları, bir linter ve IDE’lerle entegrasyona bakacağız.
rustfmt ile Otomatik Formatlama
rustfmt aracı, kodunuzu topluluk kod stiline göre yeniden formatlar. Birçok ortak proje, Rust yazarken hangi stilin kullanılacağı konusunda tartışmaları önlemek için rustfmt kullanır: Herkes kodunu bu aracı kullanarak formatlar.
Rust kurulumları varsayılan olarak rustfmt içerir, bu nedenle sisteminizde zaten rustfmt ve cargo-fmt programları bulunmalıdır. Bu iki komut, rustfmt’in daha ince ayarlı (finer grained) kontrole izin vermesi ve cargo-fmt’in Cargo kullanan bir projenin kurallarını (conventions) anlaması bakımından rustc ve cargo’ya benzer. Herhangi bir Cargo projesini formatlamak için şunu girin:
$ cargo fmt
Bu komutu çalıştırmak, mevcut crate’teki tüm Rust kodunu yeniden formatlar. Bu, kodun anlamını (semantics) değil, yalnızca kod stilini değiştirmelidir. rustfmt hakkında daha fazla bilgi için kendi dokümantasyonuna bakın.
rustfix ile Kodunuzu Düzeltin
rustfix aracı, Rust kurulumlarına dahildir ve sorunu düzeltmek için muhtemelen sizin de isteyeceğiniz net bir yolu olan derleyici uyarılarını otomatik olarak düzeltebilir. Muhtemelen daha önce derleyici uyarıları görmüşsünüzdür. Örneğin, şu kodu düşünün:
Dosya Adı: src/main.rs
fn main() {
let mut x = 42;
println!("{x}");
}Burada x değişkenini değiştirilebilir olarak tanımlıyoruz, ancak aslında onu hiç değiştirmiyoruz. Rust bizi bu konuda uyarır:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
Uyarı, mut anahtar kelimesini kaldırmamızı öneriyor. cargo fix komutunu çalıştırarak, rustfix aracını kullanarak bu öneriyi otomatik olarak uygulayabiliriz:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
src/main.rs dosyasına tekrar baktığımızda, cargo fix’in kodu değiştirdiğini göreceğiz:
Dosya Adı: src/main.rs
fn main() {
let x = 42;
println!("{x}");
}x değişkeni artık değiştirilemez ve uyarı artık görünmüyor.
Kodunuzu farklı Rust sürümleri (editions) arasında geçirmek için de cargo fix komutunu kullanabilirsiniz. Sürümler Ek E’de ele alınmıştır.
Clippy ile Daha Fazla Lint
Clippy aracı, yaygın hataları yakalayabilmeniz ve Rust kodunuzu iyileştirebilmeniz için kodunuzu analiz eden bir lint koleksiyonudur. Clippy, standart Rust kurulumlarına dahildir.
Herhangi bir Cargo projesinde Clippy’nin lintlerini çalıştırmak için şunu girin:
$ cargo clippy
Örneğin, bu programın yaptığı gibi pi gibi matematiksel bir sabitin (constant) yaklaşık bir değerini kullanan bir program yazdığınızı varsayalım:
fn main() {
let x = 3.1415;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Bu projede cargo clippy çalıştırmak şu hatayla sonuçlanır:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Bu hata size Rust’ta zaten daha kesin bir PI sabitinin tanımlandığını ve sabiti kullanmanız halinde programınızın daha doğru olacağını bildirir. Daha sonra kodunuzu PI sabitini kullanacak şekilde değiştirirsiniz.
Aşağıdaki kod, Clippy’den herhangi bir hataya veya uyarıya neden olmaz:
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Clippy hakkında daha fazla bilgi için kendi dokümantasyonuna bakın.
rust-analyzer Kullanarak IDE Entegrasyonu
IDE entegrasyonuna yardımcı olmak için Rust topluluğu rust-analyzer kullanımını önerir. Bu araç, IDE’lerin ve programlama dillerinin birbiriyle iletişim kurması için bir spesifikasyon olan Language Server Protocol konuşan derleyici odaklı yardımcı programlar kümesidir. Farklı istemciler (clients), Visual Studio Code için Rust analyzer eklentisi gibi rust-analyzer’ı kullanabilir.
Kurulum talimatları için rust-analyzer projesinin ana sayfasını ziyaret edin, ardından kullandığınız IDE’de dil sunucusu (language server) desteğini kurun. IDE’niz otomatik tamamlama, tanıma gitme (jump to definition) ve satır içi hatalar (inline errors) gibi yetenekler kazanacaktır.
E - Sürümler
Ek E: Sürümler
Bölüm 1’de, cargo new komutunun Cargo.toml dosyanıza sürüm (edition) hakkında bir miktar meta veri eklediğini görmüştünüz. Bu ek, bunun ne anlama geldiğinden bahsediyor!
Rust dili ve derleyicisinin altı haftalık bir yayın döngüsü (release cycle) vardır, bu da kullanıcıların sürekli yeni özellikler akışı aldığı anlamına gelir. Diğer programlama dilleri daha büyük değişiklikleri daha az sıklıkta yayınlar; Rust daha küçük güncellemeleri daha sık yayınlar. Bir süre sonra tüm bu küçük değişiklikler birikir. Ancak sürümden sürüme geriye dönüp “Vay canına, Rust 1.10 ile Rust 1.31 arasında Rust ne kadar çok değişmiş!” demek zor olabilir.
Yaklaşık her üç yılda bir Rust ekibi yeni bir Rust sürümü (edition) üretir. Her sürüm, tam olarak güncellenmiş belgeler ve araçlarla, gelen özellikleri net bir paket halinde bir araya getirir. Yeni sürümler olağan altı haftalık yayın sürecinin bir parçası olarak gönderilir.
Sürümler farklı kişiler için farklı amaçlara hizmet eder:
- Aktif Rust kullanıcıları için yeni bir sürüm, artımlı değişiklikleri anlaşılması kolay bir pakette bir araya getirir.
- Kullanıcı olmayanlar için yeni bir sürüm, Rust’a yeniden bakmaya değer kılan bazı önemli ilerlemelerin (advancements) gerçekleştiğinin sinyalini verir.
- Rust’ı geliştirenler için yeni bir sürüm, projenin bütünü için bir toplanma noktası (rallying point) sağlar.
Bu yazının yazıldığı sırada, dört Rust sürümü mevcuttur: Rust 2015, Rust 2018, Rust 2021 ve Rust 2024. Bu kitap, Rust 2024 sürümü kuralları (idioms) kullanılarak yazılmıştır.
Cargo.toml dosyasındaki edition anahtarı, derleyicinin kodunuz için hangi sürümü kullanması gerektiğini belirtir. Anahtar yoksa, Rust geriye dönük uyumluluk (backward compatibility) nedenleriyle sürüm değeri olarak 2015’i kullanır.
Her proje, varsayılan 2015 sürümünden farklı bir sürümü seçebilir (opt in). Sürümler, koddaki tanımlayıcılarla (identifiers) çelişen yeni bir anahtar kelime eklemek gibi uyumsuz değişiklikler (incompatible changes) içerebilir. Ancak, bu değişiklikleri açıkça seçmediğiniz (opt in) sürece, kullandığınız Rust derleyici sürümünü yükseltseniz bile kodunuz derlenmeye devam edecektir.
Tüm Rust derleyici sürümleri, o derleyicinin yayınlanmasından önce var olan herhangi bir sürümü (edition) destekler ve desteklenen herhangi bir sürümdeki crate’leri birbirine bağlayabilir (link). Sürüm değişiklikleri, derleyicinin kodu başlangıçta nasıl ayrıştırdığını (parses) etkiler. Bu nedenle, Rust 2015 kullanıyorsanız ve bağımlılıklarınızdan (dependencies) biri Rust 2018 kullanıyorsa, projeniz derlenecek ve o bağımlılığı kullanabilecektir. Projenizin Rust 2018 kullandığı ve bir bağımlılığın Rust 2015 kullandığı zıt durum da işe yarar.
Açık olmak gerekirse: Çoğu özellik tüm sürümlerde mevcut olacaktır. Herhangi bir Rust sürümünü kullanan geliştiriciler, yeni kararlı sürümler (stable releases) yapıldıkça iyileştirmeleri görmeye devam edeceklerdir. Ancak bazı durumlarda, temel olarak yeni anahtar kelimeler eklendiğinde, bazı yeni özellikler yalnızca sonraki sürümlerde mevcut olabilir. Bu tür özelliklerden yararlanmak istiyorsanız sürümleri değiştirmeniz gerekecektir.
Daha fazla ayrıntı için Rust Sürüm Rehberi belgesine bakın. Bu, sürümler arasındaki farkları sıralayan ve cargo fix aracılığıyla kodunuzu yeni bir sürüme otomatik olarak nasıl yükselteceğinizi açıklayan eksiksiz bir kitaptır.
F - Kitabın Çevirileri
Ek F: Kitabın Çevirileri
İngilizce dışındaki dillerdeki kaynaklar için. Çoğu hâlâ devam etmektedir; yardım etmek veya yeni bir çeviriyi bize bildirmek için Çeviriler (Translations) etiketine bakın!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
G - Rust Nasıl Geliştirilir ve "Nightly Rust"
Ek G: Rust Nasıl Geliştirilir ve “Nightly Rust”
Bu ek, Rust’ın nasıl yapıldığı ve bunun bir Rust geliştiricisi olarak sizi nasıl etkilediği hakkındadır.
Durgunluk Olmadan İstikrar (Stability Without Stagnation)
Bir dil olarak Rust, kodunuzun istikrarını (stability) çok önemser. Rust’ın üzerine inşa edebileceğiniz kaya gibi sağlam bir temel olmasını istiyoruz ve eğer işler sürekli değişiyor olsaydı bu imkansız olurdu. Aynı zamanda, yeni özellikler üzerinde deney yapamazsak, önemli kusurları yayınlandıktan (release) sonraya kadar, yani artık bir şeyleri değiştiremeyeceğimiz zamana kadar öğrenemeyebiliriz.
Bu soruna bulduğumuz çözüm “durgunluk olmadan istikrar” dediğimiz şeydir ve yol gösterici ilkemiz şudur: Asla kararlı (stable) Rust’ın yeni bir sürümüne yükseltme (upgrade) yapmaktan korkmamalısınız. Her yükseltme acısız olmalı, ancak aynı zamanda size yeni özellikler, daha az hata (bug) ve daha hızlı derleme süreleri getirmelidir.
Çuf, Çuf! Sürüm Kanalları (Release Channels) ve Trenlere Binmek
Rust geliştirme süreci bir tren tarifesine (train schedule) göre işler. Yani tüm geliştirmeler Rust deposunun ana (main) dalında (branch) yapılır. Sürümler, Cisco IOS ve diğer yazılım projeleri tarafından kullanılan yazılım sürüm treni (software release train) modelini takip eder. Rust için üç sürüm kanalı vardır:
- Nightly (Gecelik)
- Beta
- Stable (Kararlı)
Çoğu Rust geliştiricisi öncelikle kararlı (stable) kanalı kullanır, ancak deneysel yeni özellikleri denemek isteyenler nightly veya beta kullanabilir.
Geliştirme ve yayınlama sürecinin nasıl işlediğine dair bir örnek: Varsayalım ki Rust ekibi Rust 1.5 sürümü üzerinde çalışıyor. Bu sürüm Aralık 2015’te gerçekleşti, ancak bize gerçekçi sürüm numaraları sağlayacaktır. Rust’a yeni bir özellik eklenir: ana dala yeni bir işleme (commit) gelir. Her gece Rust’ın yeni bir gecelik (nightly) sürümü üretilir. Her gün bir yayın günüdür ve bu sürümler yayın altyapımız tarafından otomatik olarak oluşturulur. Zaman geçtikçe sürümlerimiz her gece bir kez olacak şekilde şöyle görünür:
nightly: * - - * - - *
Her altı haftada bir, yeni bir sürüm hazırlama zamanı gelir! Rust deposunun beta dalı, nightly tarafından kullanılan ana daldan ayrılır. Artık iki sürüm vardır:
nightly: * - - * - - *
|
beta: *
Çoğu Rust kullanıcısı beta sürümlerini aktif olarak kullanmaz, ancak Rust’ın olası gerilemeleri (regressions) keşfetmesine yardımcı olmak için CI (Sürekli Entegrasyon) sistemlerinde beta’ya karşı test yaparlar. Bu arada, her gece hâlâ bir gecelik sürüm (nightly release) vardır:
nightly: * - - * - - * - - * - - *
|
beta: *
Diyelim ki bir gerileme (regression) bulundu. Gerileme kararlı (stable) bir sürüme sızmadan önce beta sürümünü test etmek için biraz zamanımız olması ne iyi! Düzeltme (fix) ana dala uygulanır, böylece nightly düzeltilmiş olur, ve ardından düzeltme beta dalına geri aktarılır (backported) ve yeni bir beta sürümü üretilir:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
İlk beta sürümünün oluşturulmasından altı hafta sonra, kararlı (stable) bir sürümün zamanı gelmiştir! stable dalı beta dalından üretilir:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Yaşasın! Rust 1.5 bitti! Ancak bir şeyi unuttuk: altı hafta geçtiği için bir sonraki Rust sürümü olan 1.6’nın yeni bir betasına da ihtiyacımız var. Bu yüzden stable beta’dan ayrıldıktan sonra, bir sonraki beta sürümü yine nightly’den ayrılır:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
Buna “tren modeli” denir, çünkü her altı haftada bir, bir sürüm “istasyondan ayrılır”, ancak kararlı bir sürüm olarak gelmeden önce yine de beta kanalı üzerinden bir yolculuğa çıkması gerekir.
Rust, saat gibi her altı haftada bir yeni sürüm yayınlar. Bir Rust sürümünün tarihini biliyorsanız, bir sonrakinin tarihini de bilebilirsiniz: Altı hafta sonradır. Her altı haftada bir sürümlerin planlanmasının güzel bir yönü, bir sonraki trenin yakında geliyor olmasıdır. Bir özellik belirli bir sürümü kaçırırsa endişelenmenize gerek yoktur: kısa bir süre sonra başka bir sürüm daha çıkacaktır! Bu, tam olarak hazır (unpolished) olmayan özellikleri sürüm tarihine yakın bir zamanda araya sıkıştırma baskısını azaltmaya yardımcı olur.
Bu süreç sayesinde, her zaman bir sonraki Rust derlemesine (build) göz atabilir ve yükseltmenin (upgrade) kolay olduğunu kendiniz doğrulayabilirsiniz: Beta sürümü beklendiği gibi çalışmazsa, durumu ekibe bildirebilir ve bir sonraki kararlı sürüm yayınlanmadan önce düzeltilmesini sağlayabilirsiniz! Bir beta sürümündeki kırılmalar (breakage) nispeten nadirdir, ancak rustc nihayetinde bir yazılımdır ve hatalar mevcuttur.
Bakım Süresi (Maintenance Time)
Rust projesi en son kararlı sürümü destekler. Yeni bir kararlı sürüm yayınlandığında, eski sürüm ömrünün sonuna (end of life - EOL) ulaşır. Bu, her sürümün altı hafta boyunca desteklendiği anlamına gelir.
Kararsız Özellikler (Unstable Features)
Bu sürüm modelinin bir püf noktası daha vardır: kararsız (unstable) özellikler. Rust, belirli bir sürümde hangi özelliklerin etkinleştirileceğini belirlemek için “özellik bayrakları” (feature flags) adı verilen bir teknik kullanır. Yeni bir özellik aktif geliştirme aşamasındaysa, ana dala (main branch), dolayısıyla gecelik sürüme (nightly) iner, ancak bir özellik bayrağının (feature flag) arkasında yer alır. Bir kullanıcı olarak devam eden (work-in-progress) bir özelliği denemek isterseniz, deneyebilirsiniz, ancak Rust’ın gecelik (nightly) bir sürümünü kullanıyor olmanız ve etkinleştirmek (opt in) için kaynak kodunuza uygun bayrakla açıklama eklemeniz gerekir.
Rust’ın beta veya kararlı bir sürümünü kullanıyorsanız hiçbir özellik bayrağını (feature flag) kullanamazsınız. Bu, yeni özellikleri sonsuza dek kararlı (stable) ilan etmeden önce pratikte kullanmamızı sağlayan anahtardır. En son teknolojiyi (bleeding edge) tercih etmek isteyenler bunu yapabilir ve kaya gibi sağlam bir deneyim isteyenler kararlı sürümde kalarak kodlarının bozulmayacağını bilirler. Durgunluk olmadan istikrar.
Bu kitap yalnızca kararlı (stable) özellikler hakkında bilgi içerir, çünkü geliştirilmekte olan özellikler hâlâ değişmektedir ve kesinlikle bu kitabın yazıldığı zamanla bunların kararlı derlemelerde (stable builds) etkinleştirileceği zaman arasında farklı olacaklardır. Yalnızca nightly sürüme özgü özelliklerin dokümantasyonunu çevrimiçi olarak bulabilirsiniz.
Rustup ve Rust Nightly’nin Rolü
Rustup, genel (global) olarak veya proje bazında farklı Rust sürüm kanalları (release channels) arasında geçiş yapmayı kolaylaştırır. Varsayılan olarak sisteminizde kararlı (stable) Rust yüklüdür. Örneğin, nightly sürümü kurmak için:
$ rustup toolchain install nightly
Aynı zamanda rustup ile yüklediğiniz tüm araç zincirlerini (toolchains - Rust sürümleri ve ilişkili bileşenler) görebilirsiniz. İşte yazarlarınızdan birinin Windows bilgisayarındaki bir örnek:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Gördüğünüz gibi kararlı (stable) araç zinciri varsayılandır. Çoğu Rust kullanıcısı zamanının çoğunda kararlı sürümü kullanır. Siz de zamanınızın çoğunda kararlı sürümü kullanmak isteyebilirsiniz, ancak yeni (cutting-edge) bir özelliği önemsediğiniz için belirli bir projede nightly kullanmak isteyebilirsiniz. Bunu yapmak için, o projenin dizinindeyken rustup’ın kullanması gereken araç zinciri olarak nightly sürümü ayarlamak üzere söz konusu dizinde rustup override komutunu kullanabilirsiniz:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Artık ~/projects/needs-nightly içinde rustc veya cargo’yu her çağırdığınızda, rustup varsayılan kararlı (stable) Rust yerine gecelik (nightly) Rust kullandığınızdan emin olacaktır. Bu, çok sayıda Rust projeniz olduğunda çok işe yarar!
RFC Süreci ve Ekipler
Peki bu yeni özellikleri nasıl öğrenirsiniz? Rust’ın geliştirme modeli Yorum İsteği (Request For Comments - RFC) sürecini takip eder. Rust’ta bir iyileştirme isterseniz, RFC adı verilen bir teklif yazabilirsiniz.
Rust’ı iyileştirmek için herkes RFC yazabilir ve teklifler, birçok konu alt ekibinden oluşan Rust ekibi tarafından incelenir ve tartışılır. Rust’ın web sitesinde, projenin her alanı için takımları içeren eksiksiz bir takım listesi vardır: dil tasarımı, derleyici uygulaması, altyapı, belgeleme ve daha fazlası. İlgili ekip teklifi ve yorumları okur, kendi yorumlarını yazar ve sonunda özelliği kabul etmek veya reddetmek için bir fikir birliğine varılır.
Özellik kabul edilirse, Rust deposunda bir sorun (issue) açılır ve birisi onu uygulayabilir. Özelliği çok iyi uygulayan kişi, özelliği ilk etapta öneren kişi olmayabilir! Uygulama hazır olduğunda, “Kararsız Özellikler” (Unstable Features) bölümünde tartıştığımız gibi, bir özellik geçidinin (feature gate) arkasında ana dala iner.
Bir süre sonra, gecelik (nightly) sürümleri kullanan Rust geliştiricileri yeni özelliği deneyebildiğinde, ekip üyeleri özelliği ve nightly sürümde nasıl çalıştığını tartışacak ve kararlı (stable) Rust’a geçip geçmeyeceğine karar verecektir. İlerlemeye karar verilirse, özellik geçidi (feature gate) kaldırılır ve özellik artık kararlı (stable) kabul edilir! Rust’ın yeni kararlı sürümüne giden trenlere biner.